Obtenir et préparer les données
Les données constituent la base du Machine Learning. La quantité et la qualité des données affectent l’exactitude du modèle.
Pour entraîner un modèle de Machine Learning, vous devez :
- Identifier la source de données et le format.
- Choisir comment servir les données.
- Concevoir une solution d’ingestion de données.
Pour obtenir et préparer les données à utiliser afin d’entraîner le modèle de Machine Learning, vous devez extraire les données d’une source et les mettre à la disposition du service Azure que vous souhaitez utiliser pour entraîner des modèles ou effectuer des prédictions.
Identifier la source de données et le format
Tout d’abord, vous devez identifier votre source de données et son format de données actuel.
| Identifiez la | Exemples |
|---|---|
| Source de données | Par exemple, les données peuvent être stockées dans un système de gestion des relations client (CRM), dans une base de données transactionnelle, comme une base de données SQL, ou être générées par un appareil IoT (Internet des objets). |
| Format de données | Vous devez comprendre le format actuel des données : données tabulaires ou structurées, données semi-structurées ou données non structurées. |
Ensuite, vous devez déterminer quelles données sont nécessaires pour entraîner votre modèle et dans quel format vous souhaitez que ces données soient servies au modèle.
Choisir comment servir les données
Afin d’accéder aux données pour l’entraînement des modèles de Machine Learning, vous voulez servir les données en les stockant dans un service de données cloud. En stockant les données séparément de votre calcul, vous réduisez les coûts et gagnez en flexibilité. Il est recommandé de stocker vos données dans un outil différent de celui que vous utilisez pour entraîner vos modèles.
L’outil ou le service que vous choisissez pour stocker vos données dépend du type de vos données et du service que vous utilisez pour l’entraînement du modèle. Voici quelques options couramment utilisées sur Azure :
- Stockage Blob Azure : option la plus économique pour stocker les données sous la forme de données non structurées. Idéal pour stocker des fichiers comme des images, du texte et du code JSON. Souvent utilisé également pour stocker des données sous forme de fichiers CSV, car les scientifiques des données préfèrent utiliser des fichiers CSV.
- Azure Data Lake Storage (Gen 2) : version plus avancée du Stockage Blob Azure. Stocke également les fichiers comme les fichiers CSV et les images sous forme de données non structurées. Un lac de données implémente également un espace de noms hiérarchique, qui permet plus facilement d’accorder à une personne l’accès à un fichier ou dossier spécifique. La capacité de stockage est pratiquement illimitée, ce qui est idéal pour stocker des grandes données.
- Azure SQL Database : stocke les données sous la forme de données structurées. Les données sont lues sous forme de table et un schéma est défini à la création de la table dans la base de données. Idéal pour les données qui ne changent pas au fil du temps.
Concevoir une solution d’ingestion de données
En général, on commence par extraire les données de la source avant de les analyser. Que vous utilisiez les données pour l’engineering données, l’analyse de données ou la science des données, vous devez extraire les données de leur source, les transformer et les charger dans une couche de service. Ce type de processus est également appelé Extraction, Transformation et Chargement (ETL) ou Extraction, Chargement et Transformation (ELT). La couche de service rend vos données disponibles pour le service que vous utilisez pour ensuite traiter les données, par exemple pour entraîner des modèles de Machine Learning.
Pour déplacer et transformer des données, vous pouvez utiliser un pipeline d’ingestion de données. Un pipeline d’ingestion de données est une séquence de tâches qui déplacent et transforment les données. En créant un pipeline, vous pouvez choisir de déclencher les tâches manuellement ou planifier le pipeline pour automatiser les tâches. Il est possible de créer ces pipelines avec des services Azure tels qu’Azure Synapse Analytics, Azure Databricks et Azure Machine Learning.
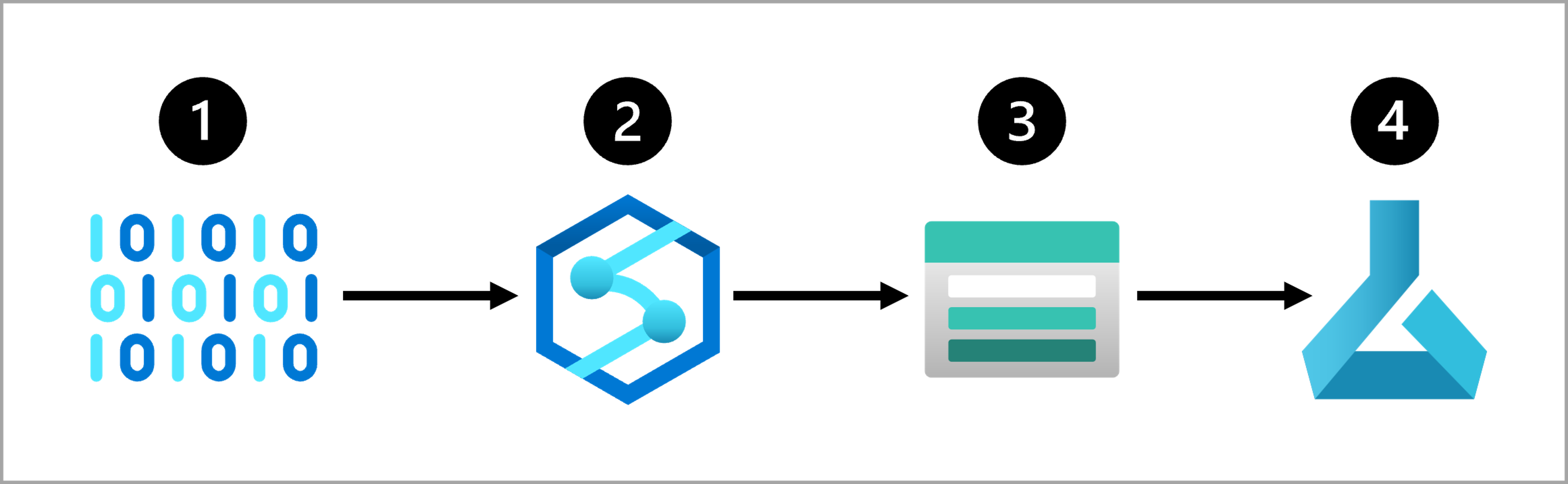
Une approche courante pour une solution d’ingestion de données consiste à :
- Extraire des données brutes de la source (comme un système CRM ou un appareil IoT).
- Copier et transformer des données dans Azure Synapse Analytics.
- Stocker les données préparées dans un Stockage Blob Azure.
- Entraîner le modèle avec Azure Machine Learning.
Explorer un exemple
Imaginez que vous souhaitiez entraîner un modèle de prévisions météorologiques. Vous préférez une table qui combine toutes les mesures de température de chaque minute. Vous souhaitez créer des agrégats des données et avoir une table de la température moyenne par heure. Pour créer la table, vous souhaitez transformer en données tabulaires les données semi-structurées ingérées à partir de l’appareil IoT qui mesure la température à certains intervalles.
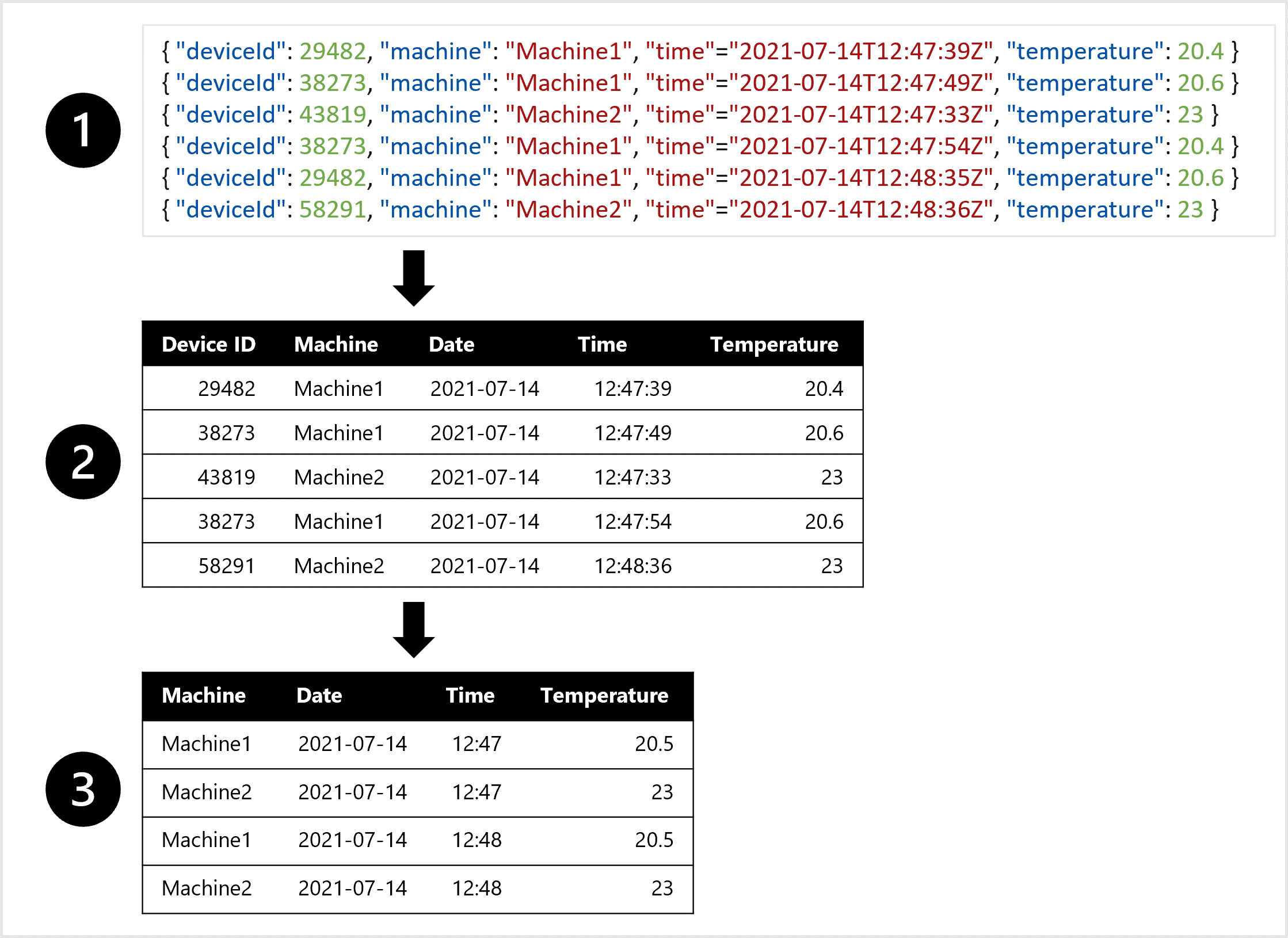
Par exemple, pour créer un jeu de données à utiliser pour entraîner le modèle de prévisions, vous pouvez :
- Extraire des mesures de données sous forme d’objets JSON à partir des appareils IoT.
- Convertir les objets JSON en table.
- Transformer les données pour obtenir la température par machine par minute.