Identifier votre source de données et le format des données
Les données sont l’entrée la plus importante pour vos modèles Machine Learning. Vous devez accéder aux données pour l’entraînement des modèles Machine Learning, et le modèle entraîné a besoin de données en entrée pour générer des prédictions.
Imaginez que vous êtes un scientifique des données à qui l’on a demandé d’entraîner un modèle Machine Learning.
Vous souhaitez effectuer les six étapes suivantes pour planifier, entraîner, déployer et superviser le modèle :

- Définir le problème : déterminez ce que le modèle doit prédire et quand la prédiction est réussie.
- Obtenir les données : recherchez des sources de données et obtenez l’accès à celles-ci.
- Préparer les données : explorez les données. Nettoyez et transformez les données en fonction des exigences du modèle.
- Entraîner le modèle : choisissez un algorithme et des valeurs d’hyperparamètre en fonction des tests effectués au préalable.
- Intégrer le modèle : déployez le modèle sur un point de terminaison pour générer des prédictions.
- Monitorer le modèle : suivez les performances du modèle.
Notes
Le diagramme est une représentation simplifiée du processus de machine learning. En règle générale, le processus est itératif et continu. Par exemple, lors du monitoring du modèle, vous pouvez décider de revenir en arrière et de réentraîner le modèle.
Pour obtenir et préparer les données que vous utiliserez afin d’entraîner le modèle Machine Learning, vous devez extraire les données d’une source et les mettre à la disposition du service Azure que vous souhaitez utiliser pour entraîner des modèles ou effectuer des prédictions.
En général, on commence par extraire les données de la source avant de les analyser. Que vous utilisiez les données pour l’ingénierie des données, l’analyse des données ou la science des données, vous devez extraire les données de la source, les transformer et les charger dans une couche de service. Ce type de processus est également appelé Extraire, Transformer et Charger (ETL) ou Extraire, Charger et Transformer (ELT). La couche de service rend vos données disponibles pour le service que vous choisissez et qui doit ensuite traiter les données, par exemple, pour entraîner des modèles Machine Learning.
Avant de pouvoir concevoir le processus ETL ou ELT, vous devez identifier votre source de données et le format de vos données.
Identifier la source de données
Quand vous démarrez un nouveau projet de machine learning, commencez par identifier l’emplacement de stockage des données.
Les données nécessaires à votre modèle Machine Learning peuvent déjà être stockées dans une base de données ou générées par une application. Par exemple, les données peuvent être stockées dans un système de gestion des relations client (CRM), dans une base de données transactionnelle comme une base de données SQL, ou être générées par un appareil IoT (Internet des objets).
En d’autres termes, votre organisation a peut-être déjà des processus métier en place qui génèrent et stockent les données. Si vous n’avez pas accès aux données dont vous avez besoin, il existe d’autres méthodes. Vous pouvez collecter de nouvelles données en implémentant un nouveau processus, acquérir de nouvelles données en utilisant des jeux de données disponibles publiquement ou acheter des jeux de données organisés.
Identifier le format de données
En fonction de la source de vos données, vos données peuvent être stockées dans un format spécifique. Vous devez comprendre le format actuel des données et déterminer le format requis pour vos charges de travail Machine Learning.
En règle générale, nous référençons trois formats différents :
Données tabulaires ou structurées : toutes les données ont les mêmes champs ou propriétés, qui sont définis dans un schéma. Les données tabulaires sont souvent représentées dans une ou plusieurs tables, où les colonnes représentent des caractéristiques et les lignes représentent des points de données. Par exemple, un fichier Excel ou CSV représente des données tabulaires :
Patient ID Pregnancies Diastolic Blood Pressure BMI Diabetes Pedigree Age Diabétique 1354778 0 80 43,50973 1,213191 21 0 1147438 8 93 21,24058 0,158365 23 1 Données semi-structurées : les données n’ont pas toutes les mêmes champs ou propriétés. À la place, chaque point de données est représenté par une collection de paires clé-valeur. Les clés représentent les caractéristiques et les valeurs représentent les propriétés du point de données individuel. Par exemple, les applications en temps réel comme les appareils IoT (Internet des objets) génèrent un objet JSON :
{ "deviceId": 29482, "location": "Office1", "time":"2021-07-14T12:47:39Z", "temperature": 23 }Données non structurées : fichiers qui n’adhèrent à aucune règle en matière de structure. Par exemple, les documents, les images, les fichiers audio et vidéo sont considérés comme des données non structurées. En les stockant comme des fichiers non structurés, vous n’avez pas à définir de schéma ou de structure, mais vous ne pouvez pas non plus interroger les données dans la base de données. Vous devez spécifier comment lire ce type de fichier pour la consommation des données.
Conseil
En savoir plus sur les concepts de base des données sur Learn
Identifier le format de données souhaité
Quand vous extrayez les données d’une source, vous pouvez transformer les données pour changer leur format afin qu’il soit plus approprié à l’entraînement du modèle.
Par exemple, vous pouvez entraîner un modèle de prévision pour effectuer une maintenance prédictive sur une machine. Vous pouvez utiliser des fonctionnalités comme la température de la machine pour prédire un problème avec la machine. Si vous recevez une alerte indiquant qu’un problème se produit, avant même que la machine tombe en panne, vous pouvez réduire les coûts en corrigeant le problème dès le début.
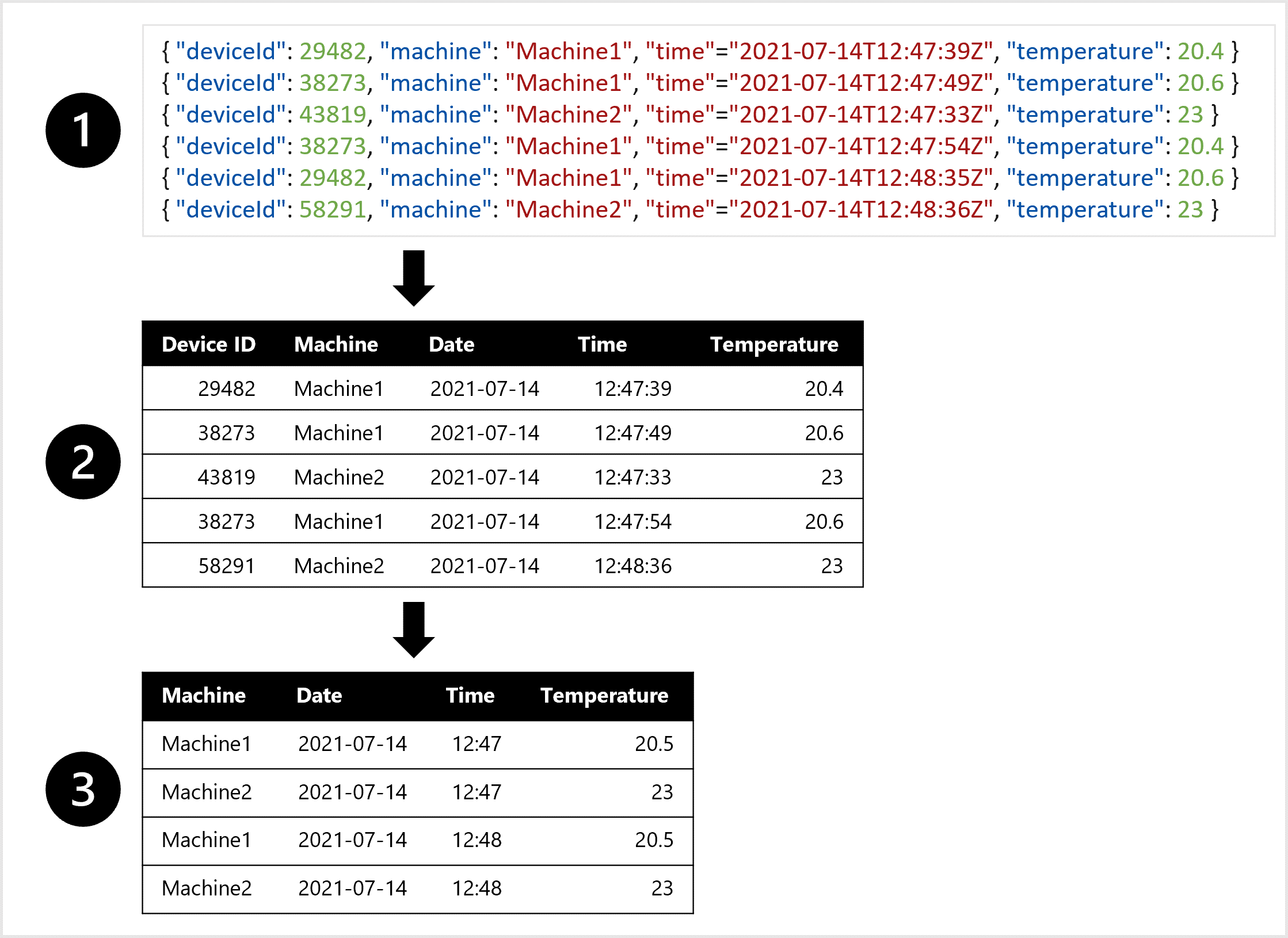
Imaginez que la machine ait un capteur qui mesure la température toutes les minutes. Toutes les minutes, chaque mesure ou entrée peut être stockée sous forme d’objet ou de fichier JSON.
Pour entraîner le modèle de prévision, vous pouvez choisir une table où combiner toutes les mesures de température de chaque minute. Vous pouvez créer des agrégats de données et avoir une table de la température moyenne par heure. Pour créer la table, vous devez transformer les données semi-structurées ingérées à partir de l’appareil IoT en données tabulaires.
Pour créer un jeu de données utilisable pour entraîner le modèle de prévision, vous pouvez :
- Extraire des mesures de données sous forme d’objets JSON à partir des appareils IoT.
- Convertir les objets JSON en table.
- Transformer les données pour obtenir la température par machine par minute.
Une fois que vous avez identifié la source de données, le format de données d’origine et le format de données souhaité, vous pouvez réfléchir à la façon dont vous voulez traiter les données. Ensuite, vous pouvez concevoir un pipeline d’ingestion de données pour extraire et transformer automatiquement les données dont vous avez besoin.