Exécuter la charge de travail d’inférence sur NVIDIA Triton Inference Server
Nous sommes maintenant prêts à exécuter l’exemple de script Python sur le serveur Triton. Si vous regardez dans le répertoire demo, vous voyez une collection de dossiers et de fichiers.
Il existe deux scripts Python dans le dossier demo/app. Le premier, frame_grabber.py, utilise le Serveur d’inférence Triton. Le deuxième, frame_grabber_onnxruntime.py, peut être utilisé de manière autonome. Le dossier utils situé dans le répertoire app contient des scripts Python pour pouvoir interpréter le tenseur de sortie du modèle.
Les deux scripts Python sont définis afin de surveiller le répertoire image_sink pour tous les fichiers image qui y sont placés. Dans le images-sample, vous trouverez une collection d’images que nous allons copier via la ligne de commande dans image_sink pour traitement. Les scripts Python suppriment automatiquement les fichiers de image_sink une fois l’inférence terminée.
Dans le dossier model-repo, vous trouvez un dossier pour le nom du modèle (gtc_onnx), qui contient le fichier config du modèle pour le Serveur d’inférence Triton et le fichier d’étiquette. Il existe également un dossier indiquant la version du modèle, qui contient le modèle Open Neural Network Exchange (ONNX) utilisé par que le serveur pour l’inférence.
Si le modèle détecte les objets sur lequel il a été entraîné, le script Python crée une annotation de cette inférence avec un cadre englobant, un nom de balise et un score de confiance. Le script enregistre l’image dans le dossier images-annotated avec un nom unique en utilisant un horodatage, que nous pouvons télécharger pour l’afficher en local. De cette façon, vous pouvez copier les mêmes images autant de fois que vous voulez dans le image_sink, mais avoir de nouvelles images annotées créées lors de chaque exécution à des fins d’illustration.
Exécuter une charge de travail d’inférence sur NVIDIA Triton Inference Server
Pour commencer avec l’inférence, nous voulons ouvrir deux fenêtres dans le Terminal Windows et
sshdans la machine virtuelle à partir de chaque fenêtre.Dans la première fenêtre, exécutez la commande suivante, mais changez d’abord l’espace réservé <votre nom d’utilisateur> en le remplaçant par votre nom d’utilisateur pour la machine virtuelle :
sudo docker run --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 --rm -p8000:8000 -p8002:8002 -v/home/<your username>/demo/model-repo:/models nvcr.io/nvidia/tritonserver:20.11-py3 tritonserver --model-repository=/modelsDans la deuxième fenêtre, copiez la commande suivante en remplaçant <votre nom d’utilisateur> par votre valeur, puis définissez le <seuil de probabilité> sur le niveau de confiance souhaité compris entre 0 et 1. Cette valeur est définie par défaut sur 0,6.
python3 demo/app/frame_grabber.py -u <your username> -p .07Dans la troisième fenêtre, copiez et collez cette commande pour copier les fichiers image du dossier
images_sampledans le dossierimage_sink:cp demo/images_sample/* demo/image_sink/Si vous revenez à votre deuxième fenêtre, vous pouvez voir l’exécution du modèle, notamment les statistiques du modèle et l’inférence retournée sous la forme d’un dictionnaire Python.
Voici un exemple de ce que vous devriez voir dans la deuxième fenêtre lorsque le script s’exécute :
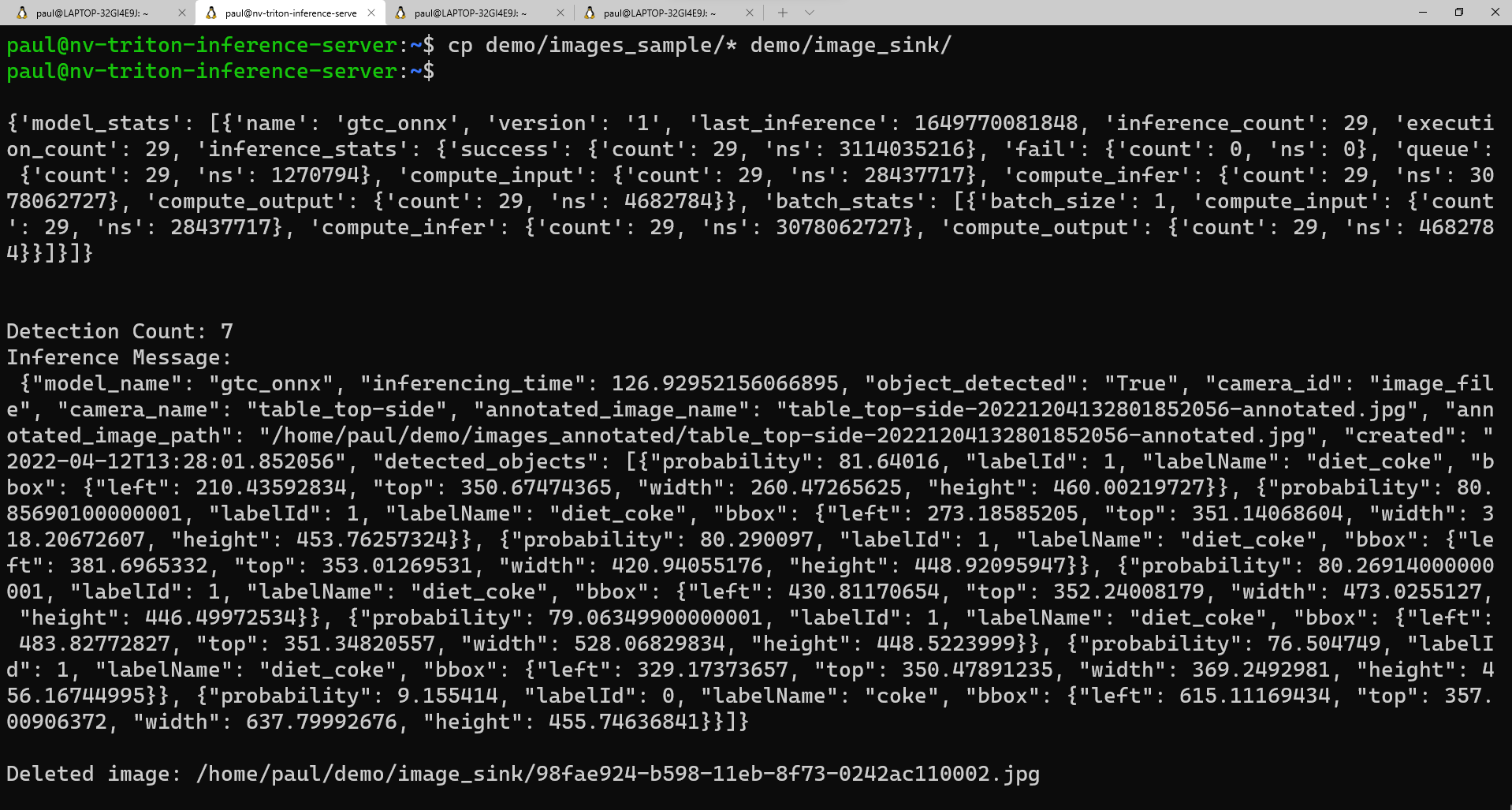
Si vous souhaitez voir la liste de vos images annotées, vous pouvez exécuter cette commande :
ls demo/annotated_imagesPour télécharger les images sur votre ordinateur local, nous allons d’abord créer un dossier pour recevoir les images. Dans une fenêtre de ligne de commande, utilisez
cdpour accéder au répertoire dans lequel vous souhaitez placer le nouveau dossier, puis exécutez :mkdir annotated_img_download scp <your usename>@x.x.x.x:/home/<your username>/demo/images_annotated/* annotated_img_download/Cette commande copie tous les fichiers de la machine virtuelle Ubuntu dans votre appareil local pour les afficher.
