Explorer les performances et la sécurité
L’écosystème Azure offre plusieurs options de performances et de sécurité pour une instance SQL Server sur une machine virtuelle Azure. Chaque option propose plusieurs fonctionnalités, telles que différents types de disques qui répondent aux besoins de capacité et de performance de votre charge de travail.
Considérations relatives au stockage
SQL Server nécessite de bonnes performances de stockage pour assurer des performances d’application robustes, qu’il s’agisse d’une instance locale ou d’une installation sur une machine virtuelle Azure. Azure fournit un large éventail de solutions de stockage pour répondre aux besoins de votre charge de travail. Même si Azure offre différents types de stockage (objets blob, fichiers, files d’attente, tables), dans la plupart des cas, les charges de travail SQL Server utilisent des disques managés Azure. Les exceptions sont qu’une instance de cluster de basculement peut être générée sur un stockage de fichiers et que les sauvegardes utilisent le stockage d’objets blob. Les disques managés par Azure servent de dispositif de stockage au niveau du bloc, qui est présenté à votre machine virtuelle Azure. Les disques managés offrent plusieurs avantages, dont une disponibilité de 99,999 %, un déploiement scalable (vous pouvez avoir jusqu’à 50 000 disques de machines virtuelles par abonnement par région) et une intégration dans des groupes à haute disponibilité et des zones de disponibilité pour offrir des niveaux de résilience plus élevés en cas de défaillance.
Les disques managés par Azure offrent tous deux types de chiffrement. Le chiffrement côté serveur Azure est fourni par le service de stockage et fait office de chiffrement au repos fourni par le service de stockage. Azure Disk Encryption utilise BitLocker sur Windows et DM-Crypt sur Linux pour fournir le chiffrement du système d’exploitation et des disques de données à l’intérieur de la machine virtuelle. Les deux technologies s’intègrent à Azure Key Vault pour vous permettre d’apporter votre propre clé de chiffrement.
Au moins deux disques sont associés à chaque machine virtuelle :
Disque du système d’exploitation – Chaque machine virtuelle nécessite un disque de système d’exploitation qui contient le volume de démarrage. Ce disque correspond au lecteur C: pour une machine virtuelle de la plateforme Windows, ou à /dev/sda1 sur Linux. Le système d’exploitation est automatiquement installé sur le disque du système d’exploitation.
Disque temporaire – Chaque machine virtuelle contient un seul disque utilisé pour le stockage temporaire. Ce stockage est destiné à être utilisé pour des données qui n’ont pas besoin d’être durables, comme des fichiers d’échange. Étant donné que le disque est temporaire, vous ne devez pas l’utiliser pour stocker des informations critiques comme des fichiers de bases de données ou de journaux de transactions, car elles seront perdues à l’issue d’une opération de maintenance ou d’un redémarrage de la machine virtuelle. Ce lecteur est monté en tant que D:\ sur Windows et /dev/sdb1 sur Linux.
Par ailleurs, vous pouvez et devez ajouter des disques de données supplémentaires à vos machines virtuelles Azure exécutant SQL Server.
- Disques de données – Le terme « disque de données » est utilisé dans le portail Azure, mais dans la pratique, il s’agit simplement de disques managés supplémentaires ajoutés à une machine virtuelle. Ces disques peuvent être mis en pool pour augmenter les IOPS et la capacité de stockage disponibles, en utilisant des espaces de stockage sur Windows ou la gestion des volumes logiques sur Linux.
En outre, chaque disque peut relever de l’un des types suivants :
| Fonctionnalité | Disque Ultra | SSD Premium | SSD Standard | HDD Standard |
|---|---|---|---|---|
| Type de disque | SSD | SSD | SSD | HDD |
| Idéal pour | Charge de travail gourmande en E/S | Charge de travail sensible aux performances | Charges de travail légères | Sauvegardes, charges de travail non critiques |
| Taille maximale du disque | 65 536 Gio | 32 767 Gio | 32 767 Gio | 32 767 Gio |
| Débit max. | 2 000 Mo/s | 900 Mo/s | 750 Mo/s | 500 Mo/s |
| Nb max. d’E/S par seconde | 160 000 | 20 000 | 6 000 | 2 000 |
Les bonnes pratiques liées à SQL Server sur Azure recommandent d’utiliser des disques Premium mis en pool pour obtenir des IOPS et une capacité de stockage accrues. Les fichiers de données doivent être stockés dans leur propre pool avec une mise en cache en lecture sur les disques Azure.
Comme les fichiers journaux de transactions ne bénéficient pas de cette mise en cache, ils doivent être placés dans leur propre pool sans mise en cache. La base de données TempDB peut éventuellement être placée dans son propre pool ou utiliser le disque temporaire de la machine virtuelle, ce qui offre une faible latence, car elle est physiquement attachée au serveur physique sur lequel les machines virtuelles sont exécutées. Un type SSD Premium correctement configuré permet d’obtenir une latence en millisecondes à un chiffre. Pour les charges de travail stratégiques nécessitant une latence encore inférieure, envisagez le type SSD Ultra.
Considérations relatives à la sécurité
Il existe plusieurs réglementations et standards du secteur auxquels Azure se conforme, ce qui permet de créer une solution conforme avec SQL Server exécuté sur une machine virtuelle.
Microsoft Defender pour SQL
Microsoft Defender pour SQL fournit des fonctionnalités de sécurité Azure Security Center, telles que les évaluations des vulnérabilités et les alertes de sécurité.
Azure Defender pour SQL peut être utilisé pour identifier et atténuer les vulnérabilités potentielles dans votre instance et votre base de données SQL Server. La fonctionnalité d’évaluation des vulnérabilités peut détecter les risques potentiels dans votre environnement SQL Server et vous aider à les atténuer. Elle offre aussi des informations sur l’état de votre sécurité et des procédures actionnables pour résoudre les problèmes de sécurité.
Azure Security Center
Azure Security Center est un système de gestion de la sécurité unifié qui évalue et offre des opportunités d’améliorer plusieurs aspects de la sécurité de votre environnement de données. Azure Security Center fournit une vue complète de l’intégrité de la sécurité de toutes vos ressources cloud hybrides.
Considérations relatives aux performances
La plupart des fonctionnalités de performances SQL Server locales existantes sont également disponibles sur les machines virtuelles Azure. Parmi les options proposées, la compression des données qui peut améliorer les performances des charges de travail gourmandes en E/S tout en diminuant la taille de la base de données. De même, le partitionnement de tables et d’index peut améliorer les performances des requêtes des grandes tables, tout en améliorant les performances et la scalabilité.
Partitionnement de tables
Le partitionnement de tables offre de nombreux avantages, mais souvent cette stratégie n’est envisagée que si la table devient suffisamment grande pour compromettre les performances des requêtes. L’identification des tables candidates au partitionnement de tables est une bonne pratique susceptible d’entraîner moins de perturbations et d’interventions. Lorsque vous filtrez vos données à l’aide de votre colonne de partition, seule une partie des données est accessible, pas la table entière. De même, les opérations de maintenance sur une table partitionnée réduisent la durée de maintenance, par exemple, en compressant des données spécifiques dans une partition particulière ou en recréant des partitions spécifiques d’un index.
Il existe quatre étapes principales requises lors de la définition d’une partition de tables :
- Création de groupes de fichiers, qui définit les fichiers impliqués lors de la création des partitions.
- Création de la fonction de partition, qui définit les règles de partition en fonction de la colonne spécifiée.
- Création du schéma de partition, qui définit le groupe de fichiers de chaque partition.
- Table à partitionner.
L’exemple ci-dessous montre comment créer une fonction de partition du 1er janvier 2021 au 1er décembre 2021 et distribuer les partitions entre différents groupes de fichiers.
-- Partition function
CREATE PARTITION FUNCTION PartitionByMonth (datetime2)
AS RANGE RIGHT
-- The boundary values defined is the first day of each month, where the table will be partitioned into 13 partitions
FOR VALUES ('20210101', '20210201', '20210301',
'20210401', '20210501', '20210601', '20210701',
'20210801', '20210901', '20211001', '20211101',
'20211201');
-- The partition scheme below will use the partition function created above, and assign each partition to a specific filegroup.
CREATE PARTITION SCHEME PartitionByMonthSch
AS PARTITION PartitionByMonth
TO (FILEGROUP1, FILEGROUP2, FILEGROUP3, FILEGROUP4,
FILEGROUP5, FILEGROUP6, FILEGROUP7, FILEGROUP8,
FILEGROUP9, FILEGROUP10, FILEGROUP11, FILEGROUP12);
-- Creates a partitioned table called Order that applies PartitionByMonthSch partition scheme to partition the OrderDate column
CREATE TABLE Order ([Id] int PRIMARY KEY, OrderDate datetime2)
ON PartitionByMonthSch (OrderDate) ;
GO
Compression des données
SQL Server offre différentes options pour compresser les données. Même si SQL Server stocke toujours les données compressées sur des pages de 8 Ko, lors de la compression des données, un nombre plus important de lignes de données peut être stocké sur une page donnée, ce qui permet à la requête de lire moins de pages. La lecture d’un plus petit nombre de pages présente un double avantage : elle réduit le nombre d’E/S physiques effectuées et permet de stocker davantage de lignes dans le pool de mémoires tampons, optimisant ainsi l’utilisation de la mémoire. Nous vous recommandons d’activer la compression de page de base de données le cas échéant.
Le compromis tient dans la petite surcharge du processeur qui découle de la compression, mais dans la majorité des cas, les bénéfices obtenus sur les E/S de stockage compensent largement cette utilisation supplémentaire du processeur.
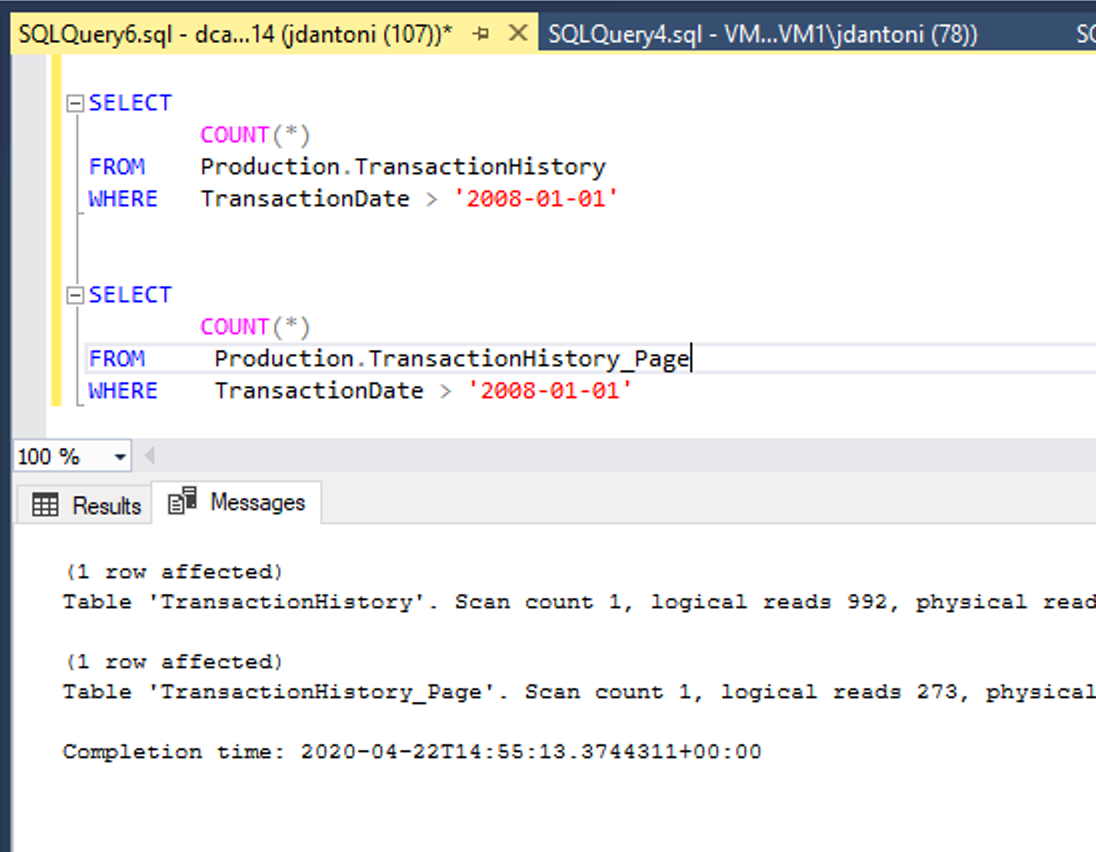
L’image ci-dessus illustre ce gain de performance. Ces tables sont dotées d’index sous-jacents identiques ; la seule différence réside dans les index cluster et non-cluster sur la table Production.TransactionHistory_Page qui sont à page compressée. La requête sur l’objet à page compressée effectue 72 % de lectures logiques de moins que la requête qui utilise les objets non compressés.
La compression est implémentée dans SQL Server au niveau de l’objet. Chaque index ou table peut être compressé individuellement, et vous avez la possibilité de compresser des partitions au sein d’une table ou d’un index partitionné. Vous pouvez évaluer la quantité d’espace que vous allez économiser en utilisant la procédure stockée système sp_estimate_data_compression_savings. Avant SQL Server 2019, cette procédure ne prenait pas en charge les index columnstore ni la compression d’archivage columnstore.
Compression de ligne - La compression de ligne est assez simple et n’entraîne pas de surcharge importante. Toutefois, elle n’offre pas la même quantité de compression (mesurée par le pourcentage de réduction de l’espace de stockage nécessaire) que la compression de page peut offrir. La compression de ligne, globalement, stocke chaque valeur dans chaque colonne sur une ligne en utilisant la quantité minimale d’espace nécessaire pour stocker cette valeur. Elle utilise un format de stockage de longueur variable pour les types de données numériques, tels que integer, float et decimal, et stocke des chaînes de caractères à longueur fixe à l’aide du format de longueur variable.
Compression de page - La compression de page est un sur-ensemble de la compression de ligne, à partir du moment où toutes les pages sont initialement compressées par ligne avant l’application de la compression de page. Une combinaison de techniques nommées « préfixe » et « compression de dictionnaire » est ensuite appliquée aux données. La compression de préfixe élimine les données redondantes dans une colonne en stockant de nouveau les pointeurs dans l’en-tête de page. Faisant suite à cette étape, la compression de dictionnaire recherche les valeurs répétées sur une page et les remplace par des pointeurs, ce qui réduit encore le stockage. Plus la redondance de vos données est importante, plus les économies d’espace sont grandes quand vous compressez vos données.
Compression d’archivage columnstore - Les objets columnstore sont toujours compressés, mais ils peuvent l’être davantage au moyen de la compression d’archivage, qui utilise l’algorithme de compression Microsoft XPRESS sur les données. Ce type de compression est idéal pour les données qui sont lues rarement, mais qui doivent être conservées pour des raisons réglementaires ou commerciales. Bien que ces données soient plus compressées, le coût processeur de la décompression tend à l’emporter sur les gains de performances obtenus de la réduction des E/S.
Options supplémentaires
Vous trouverez ci-dessous une liste de fonctionnalités et d’actions SQL Server supplémentaires à prendre en compte pour les charges de travail de production :
- Activer la compression des sauvegardes
- Activer l’initialisation de fichiers instantanée pour les fichiers de données
- Limiter la croissance automatique sur la base de données
- Désactiver la réduction automatique/fermeture automatique pour les bases de données
- Déplacer toutes les bases de données vers des disques de données, y compris les bases de données système
- Déplacer les répertoires des journaux d’erreurs et des fichiers de trace SQL Server vers des disques de données
- Définir la limite maximale de mémoire SQL Server
- Activer le verrouillage des pages en mémoire
- Activer l’optimisation des charges de travail ad hoc pour les environnements OLTP lourds
- Activez le Magasin des requêtes.
- Planifier des tâches SQL Server Agent pour exécuter les travaux DBCC CHECKDB, index reorganize, index rebuild et update statistics
- Surveiller et gérer l’intégrité et la taille des fichiers journaux des transactions
Pour plus d’informations sur les bonnes pratiques relatives aux performances, consultez Bonnes pratiques pour SQL Server sur les machines virtuelles Azure.