Comprendre et tester le modèle
Nous avons créé un modèle Machine Learning ! Testez-le pour vérifier son bon fonctionnement.
Performances du modèle
Custom Vision affiche trois métriques lorsque vous testez votre modèle. Les métriques sont des indicateurs qui peuvent vous aider à comprendre le fonctionnement de votre modèle. Les indicateurs ne révèlent pas à quel point le modèle est factuel ou juste. Ils affichent uniquement les performances du modèle avec les données que vous avez fournies. Les performances du modèle avec des données connues vous donnent une idée de ses performances avec de nouvelles données.
Les métriques suivantes sont fournies pour l’ensemble du modèle et pour chaque classe :
| Métrique | Description |
|---|---|
precision |
Si votre modèle prédit une étiquette, cette métrique indique la probabilité que la bonne étiquette ait été prédite. |
recall |
Parmi les étiquettes que le modèle doit correctement prédire, cette métrique indique le pourcentage d’étiquettes que votre modèle a correctement prédit. |
average precision |
Mesure les performances du modèle en calculant la précision et le rappel à des seuils différents. |
Lorsque nous testons notre modèle Custom Vision, nous verrons des valeurs pour chacune de ces métriques dans les résultats des tests d’itération.
Erreurs courantes
Avant de tester notre modèle, examinons quelques-unes des « erreurs de débutant » à éviter lorsque vous commencez à créer des modèles Machine Learning.
Utilisation de données déséquilibrées
Cet avertissement peut s’afficher lorsque vous déployez votre modèle :
Unbalanced data detected. The distribution of images per tag should be uniform to ensure model performance.
Cet avertissement indique que vous n’avez pas un nombre pair d’échantillons pour chaque classe de données. Même si ce scénario offre plusieurs options, un moyen courant de résoudre les données déséquilibrées consiste à utiliser la méthode Synthetic Minority Over-sampling Technique (SMOTE). SMOTE duplique les exemples d’entraînement de votre pool d’entraînement existant.
Notes
Dans notre modèle, vous ne verrez peut-être pas cet avertissement, en particulier si vous avez chargé une fraction du jeu de données. Le sous-ensemble de données de modèle Red-tailed Hawk (Dark morph) contient moins de 60 photos, alors que les autres modèles en ont plus de 100. L’utilisation de données déséquilibrées est quelque chose à surveiller dans tout modèle Machine Learning.
Surajustement du modèle
Si vous ne disposez pas de suffisamment de données ou que celles-ci ne sont pas assez diversifiées, votre modèle peut être surajusté. Quand un modèle est surajusté, il connaît bien le jeu de données fourni et il est surajusté aux modèles dans ces données. Dans ce cas, le modèle fonctionne correctement sur les données d’entraînement, mais il s’exécute de façon médiocre sur les nouvelles données qu’il n’a pas encore vues. Pour cette raison, nous utilisons toujours de nouvelles données pour tester un modèle.
Tests avec des données d’entraînement
Comme pour le surajustement, si vous testez le modèle à l’aide des mêmes données que celles utilisées pour l’entraînement du modèle, celui-ci semble bien fonctionner. Mais lorsque vous déployez le modèle en production, il est très probable qu’il s’exécute de façon médiocre.
Utilisation de données incorrectes
Une autre erreur courante est d’utiliser des données incorrectes pour entraîner le modèle. Certaines données risquent en fait de réduire la précision de votre modèle, par exemple, l’utilisation de données « bruyantes ». Avec les données bruyantes, le jeu de données contient trop d’informations inutiles, ce qui entraîne une confusion dans le modèle. Il ne suffit pas d’avoir beaucoup de données. Il faut aussi qu’elles soient de bonne qualité pour être exploitées par le modèle. Vous devrez peut-être nettoyer des données ou supprimer des fonctionnalités pour améliorer la précision de votre modèle.
Tester le modèle
Selon les métriques fournies par Custom Vision, notre modèle est assez performant. Testons notre modèle et voyons comment il fonctionne sur des données qu’il n’a jamais vues. Nous allons utiliser une image d’oiseau trouvée sur Internet.
Dans votre navigateur web, recherchez une image d’un oiseau qui correspond à l’une des espèces que vous avez entraîné le modèle à reconnaître. Copiez l’URL de l'image.
Dans le portail Custom Vision, sélectionnez le projet Bird Classification.
Dans la barre de menus supérieure, sélectionnez Test rapide.
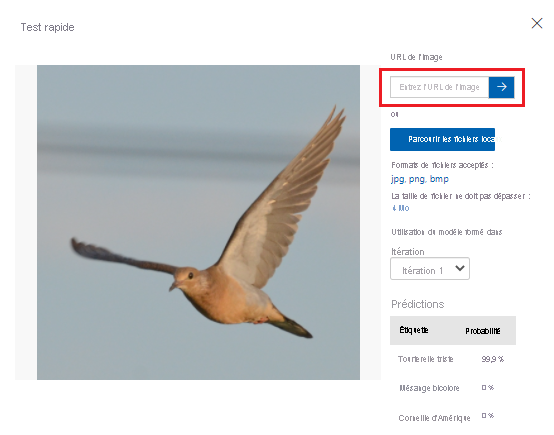
Dans Test rapide, collez l’URL dans URL de l’image, puis appuyez sur Entrée pour tester la précision du modèle. La prédiction est affichée dans la fenêtre.
Custom Vision analyse l’image pour tester la précision du modèle, puis affiche les résultats :
À l’étape suivante, nous allons déployer le modèle. Une fois le modèle déployé, nous pouvons effectuer des tests supplémentaires avec un point de terminaison que nous allons créer.