Création d’un cluster HDInsight
Il existe plusieurs méthodes pour créer un cluster HDInsight : vous pouvez utiliser le Portail Azure pour bénéficier d’une interface utilisateur conviviale ou bien écrire des scripts pour faciliter les déploiements automatisés. Le tableau suivant présente les différentes méthodes que vous pouvez utiliser pour créer un cluster HDInsight.
| Clusters créés avec | un navigateur Web | Ligne de commande | API REST | Kit SDK |
|---|---|---|---|---|
| Portail Azure | ✔ | |||
| Azure Data Factory | ✔ | ✔ | ✔ | ✔ |
| Azure CLI | ✔ | |||
| Azure PowerShell | ✔ | |||
| cURL | ✔ | ✔ | ||
| Kit de développement logiciel (SDK) .NET | ✔ | |||
| Modèle Azure Resource Manager | ✔ |
Toutes les configurations HDInsight nécessitent les informations de base suivantes :
Onglet Informations de base
Détails du projet
Abonnement
Définit l’abonnement Azure sous lequel HDInsight est facturé et géré.
Nom du groupe de ressources
Un groupe de ressources est un regroupement logique de technologies et de services Azure qui sont généralement liés à la même application ou au même cycle de vie d’application. Le regroupement de services dans le même groupe de ressources facilite la maintenance administrative.
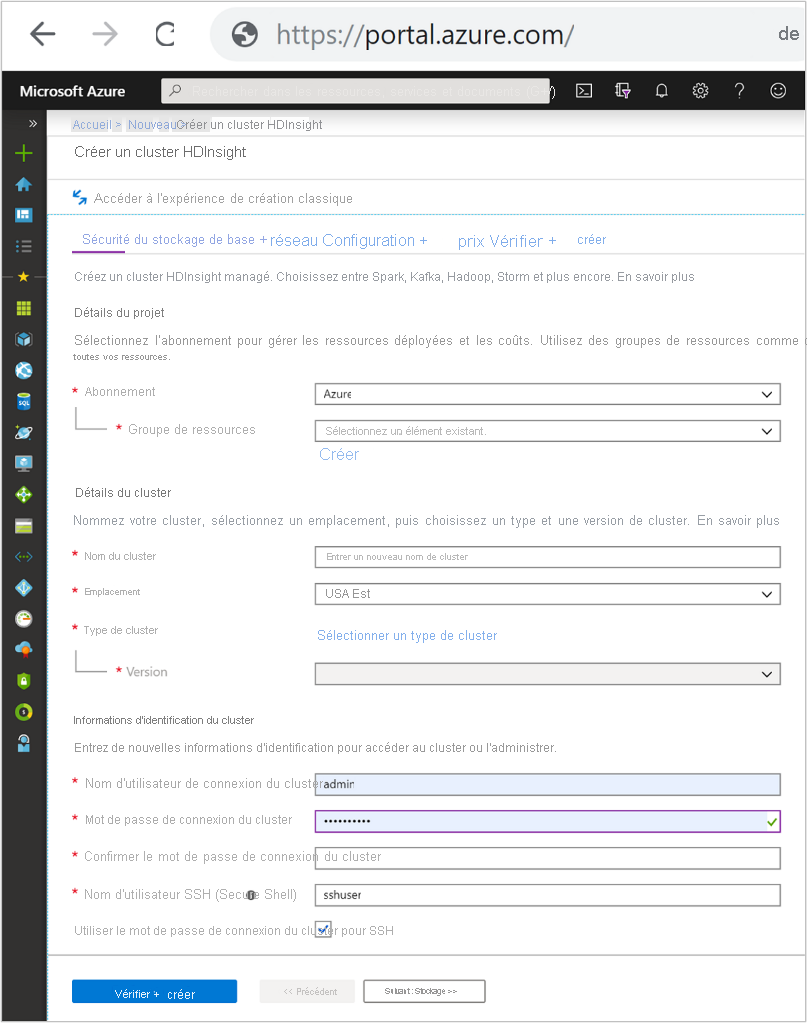
Détails du cluster
Nom du cluster
Les noms des clusters HDInsight présentent les restrictions suivantes :
- Caractères autorisés : a-z, 0-9, A-Z
- Longueur maximale : 59
- Noms réservés : apps
- L’étendue de l’affectation de noms de cluster porte sur l’ensemble d’Azure et sur l’ensemble des abonnements. Le nom du cluster doit donc être globalement unique.
- Les six premiers caractères doivent être uniques au sein d’un réseau virtuel
Lieu
Spécifie l’emplacement de stockage du type de cluster. Si aucun emplacement n’est défini, le cluster est colocalisé au même emplacement que le stockage par défaut. L’emplacement doit être le plus proche possible de vos utilisateurs pour réduire la latence.
Types de cluster
Définit la pile technologique approvisionnée sur votre cluster de ressources. Sélectionnez un type de cluster en fonction du type de données dont vous disposez et du type de traitement dont vous avez besoin pour votre scénario. Les types de cluster disponibles sont présentés dans le tableau suivant.
| Type de cluster | Description |
|---|---|
| Apache Hadoop | Framework qui utilise HDFS et un simple modèle de programmation MapReduce pour traiter et analyser les données par lots. |
| Apache Spark | infrastructure de traitement parallèle open source qui prend en charge le traitement en mémoire pour améliorer les performances des applications d’analyse du Big Data. |
| HBase | base de données NoSQL basée sur Hadoop qui fournit un accès aléatoire et une forte cohérence pour de vastes quantités de données non structurées et semi-structurées (potentiellement, des milliards de lignes multipliées par des millions de colonnes). |
| Interactive Query Apache | mise en cache pour des requêtes Hive interactives et plus rapides. |
| Apache Kafka | plateforme open source utilisée pour créer des applications et des pipelines de données de diffusion en continu. Kafka fournit également une fonctionnalité de file d’attente de messages qui vous permet de publier des flux de données et de vous abonner à ces derniers. |
Version
Définit la version de HDInsight pour ce cluster. HDInsight 4.0 est la version la plus récente et contient les infrastructures les plus récentes approvisionnées sur les clusters.
Informations d’identification du cluster
Les clusters HDInsight vous permettent de configurer deux comptes d’utilisateur lors de la création.
Identifiant de connexion et mot de passe du cluster
Le nom d’utilisateur par défaut est admin. Il utilise la configuration de base sur le Portail Azure. Parfois, le nom par défaut est « Utilisateur du cluster ».
Nom d’utilisateur et mot de passe SSH
sert à se connecter au cluster à l’aide de SSH.
Notes
Le package de sécurité d’entreprise vous permet d’intégrer HDInsight à Active Directory et Apache Ranger. Plusieurs utilisateurs peuvent être créés à l’aide du package de sécurité d’entreprise.
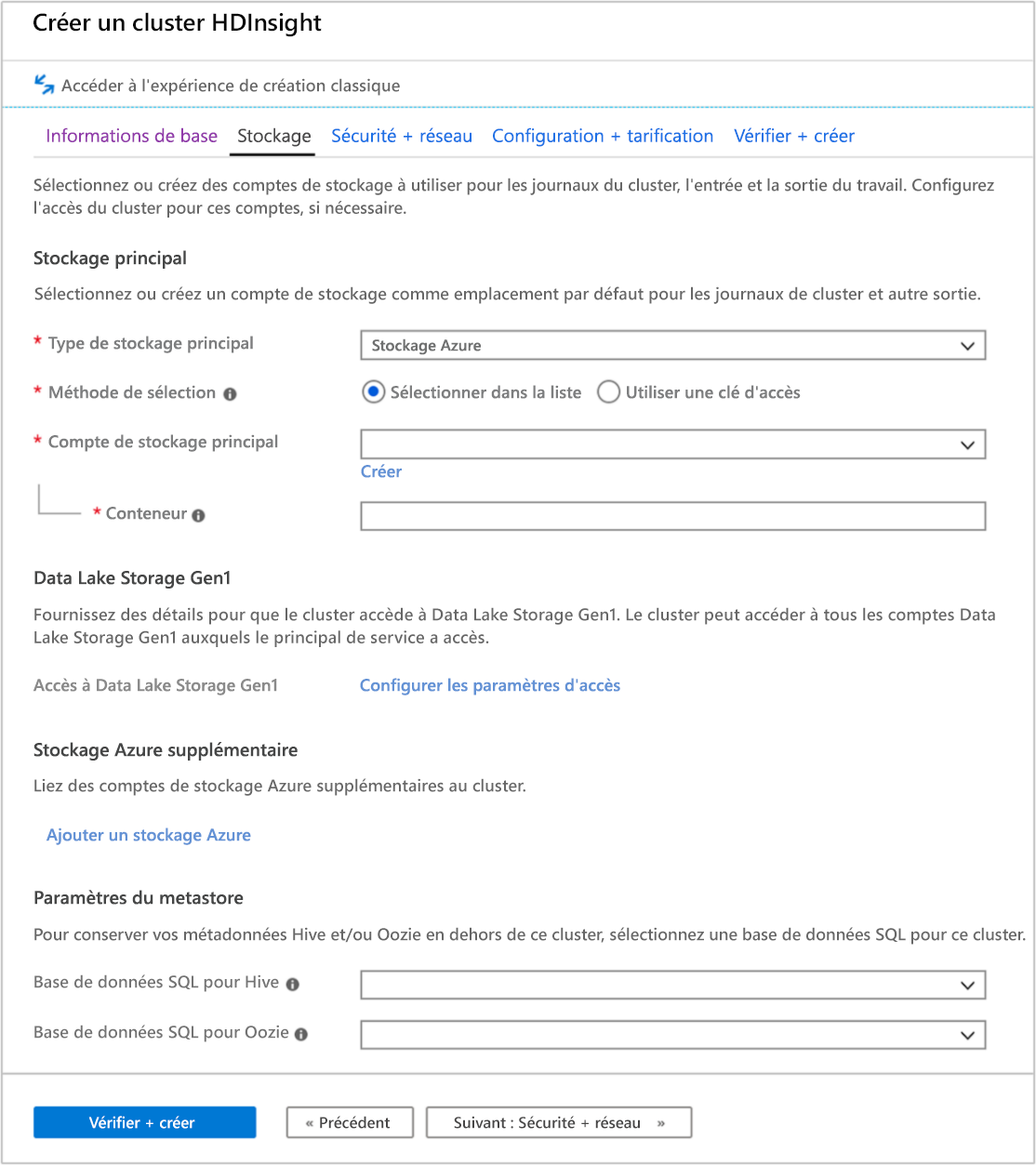
Onglet Stockage
Les clusters HDInsight peuvent utiliser les options de stockage suivantes, comme indiqué dans l’écran de stockage :
- Azure Data Lake Storage Gen2
- Azure Data Lake Storage Gen1
- Stockage Azure Usage général v2
- Stockage Azure Usage général v1
- Objet blob de blocs Stockage Azure (pris en charge uniquement comme stockage secondaire)
L’écran Stockage vous permet de définir le compte de stockage principal et le conteneur par défaut. Vous pouvez également lier un Stockage Azure supplémentaire au cluster. Les paramètres Metastore vous permettent de définir une base de données SQL externe pour stocker des tables Hive après la suppression d’un cluster et améliorer les performances de Oozie en stockant les métadonnées dans un magasin externe.
Sécurité et mise en réseau
Pour les types de cluster Hadoop, Spark, HBase, Kafka et Interactive Query, vous pouvez choisir d’activer le Pack Sécurité Entreprise. Vous pouvez utiliser ce package pour renforcer la sécurité d’une configuration de cluster à l’aide d’Apache Ranger et d’une intégration à Microsoft Entra ID.
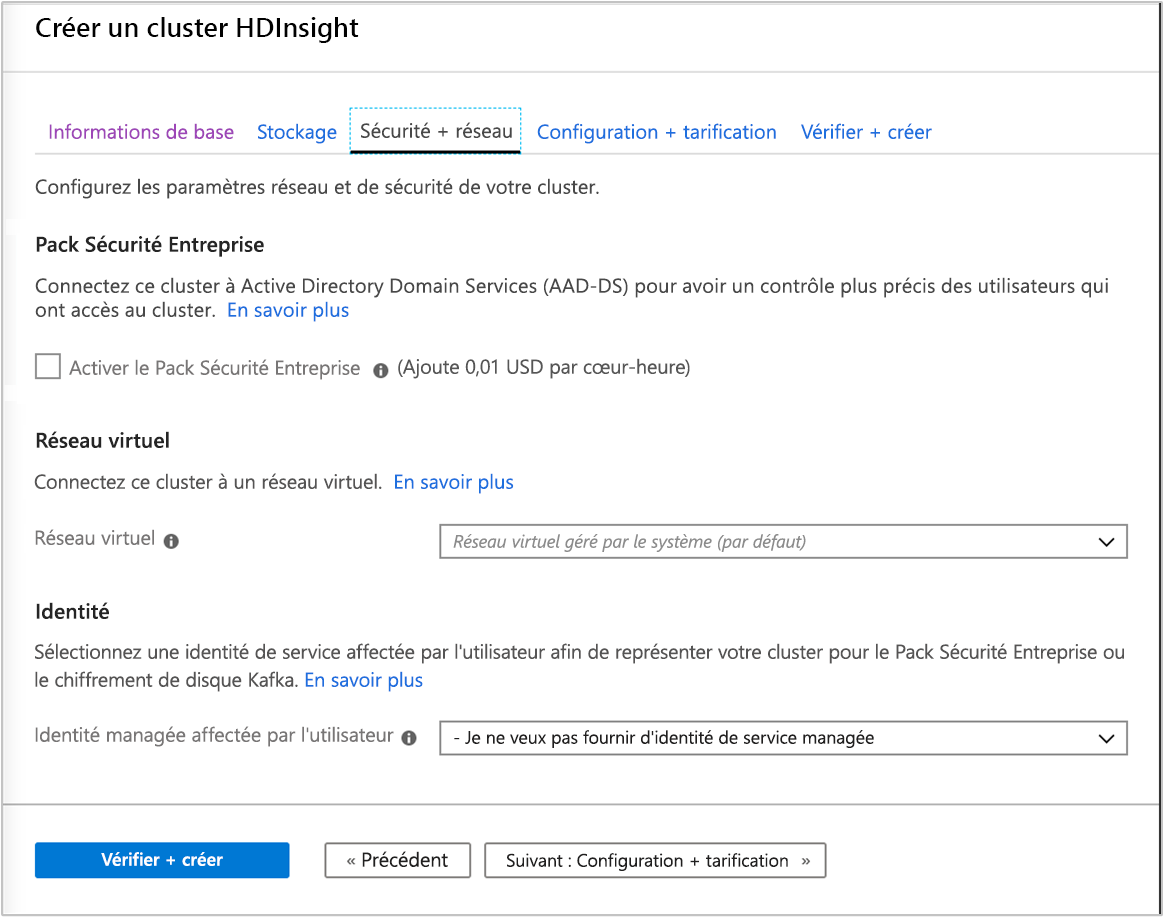
En outre, il est toujours recommandé de déployer des clusters HDInsight dans un réseau virtuel (VNet). Vous pouvez définir et configurer le réseau virtuel sur cet écran. Si votre solution nécessite des technologies qui sont réparties sur plusieurs types de clusters HDInsight, un réseau virtuel Azure peut connecter les types de cluster requis. Cette configuration permet aux clusters, et au code déployé sur ces clusters, de communiquer directement entre eux.
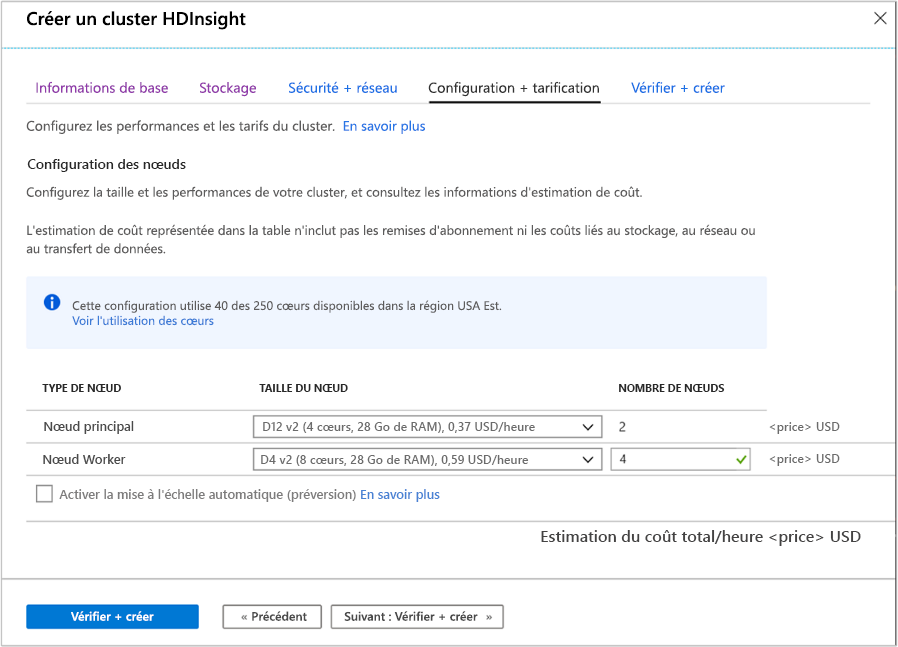
Configuration et tarification
Cette page vous permet de configurer la taille et les performances de votre cluster, et de consulter les informations d'estimation de coût. Dans cet écran, vous pouvez également définir les machines virtuelles qui seront utilisées pour les nœuds principaux et pour les nœuds Worker.