Compétence de classification de texte personnalisée
La classification de texte personnalisée vous permet de mapper un passage d’un texte à différentes classes définies par l’utilisateur. Par exemple, vous pouvez entraîner un modèle sur le synopsis de la quatrième de couverture des livres pour identifier automatiquement le genre d’un livre. Vous utilisez ensuite ce genre identifié pour enrichir le moteur de recherche de votre boutique en ligne avec des informations sur le genre.
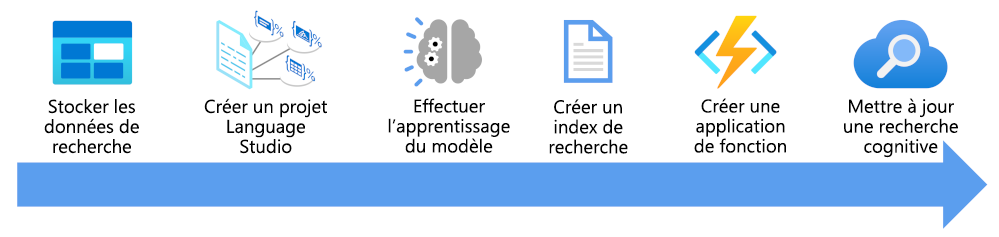
Vous allez voir ici ce que vous devez prendre en compte pour enrichir un index de recherche en utilisant un modèle de classification de texte personnalisé :
- Stocker vos documents pour que Language Studio et les indexeurs Recherche Azure AI puissent y accéder.
- Créez un projet de classification de texte personnalisée.
- Entraîner et tester votre modèle.
- Créer un index de recherche basé sur vos documents stockés.
- Créer une application de fonction qui utilise votre modèle entraîné déployé.
- Mettre à jour votre solution de recherche, votre index, votre indexeur et votre ensemble de compétences personnalisées.
Stocker vos données
Stockage Blob Azure est accessible depuis Language Studio et Azure AI Services. Le conteneur doit être accessible : l’option la plus simple est donc de choisir Conteneur, mais il est également possible d’utiliser des conteneurs privés moyennant une configuration supplémentaire.
En plus de vos données, vous avez également besoin d’un moyen d’affecter des classifications pour chaque document. Language Studio fournit un outil graphique que vous pouvez utiliser pour classifier manuellement chacun des documents.
Vous pouvez choisir entre deux types de projet différents. Si un document est mappé à une classe unique, utilisez un projet de classification d’étiquette unique. Si vous pouvez mapper un document à plusieurs classes, utilisez le projet de classification multi-étiquette.
Si vous ne voulez pas classifier manuellement chaque document, vous pouvez étiqueter tous vos documents avant de créer votre projet Azure AI Language. Ce processus implique la création d’un document JSON d’étiquettes au format suivant :
{
"projectFileVersion": "2022-05-01",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectKind": "CustomMultiLabelClassification",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectName": "{PROJECT-NAME}",
"multilingual": false,
"description": "Project-description",
"language": "en-us"
},
"assets": {
"projectKind": "CustomMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
}
]
}
Vous ajoutez vos classes au tableau classes. Vous ajoutez une entrée pour chaque document dans le tableau documents, y compris les classes auxquelles le document correspond.
Créer votre projet Azure AI Language
Il existe deux façons de créer votre projet Azure AI Language. Si vous commencez à utiliser Language Studio sans créer d’abord un service de langage dans le portail Azure, Language Studio vous propose d’en créer un pour vous.
La méthode la plus souple pour créer un projet Azure AI Language est de créer d’abord votre service de langage en utilisant le portail Azure. Si vous choisissez cette option, vous avez la possibilité d’ajouter des fonctionnalités personnalisées.
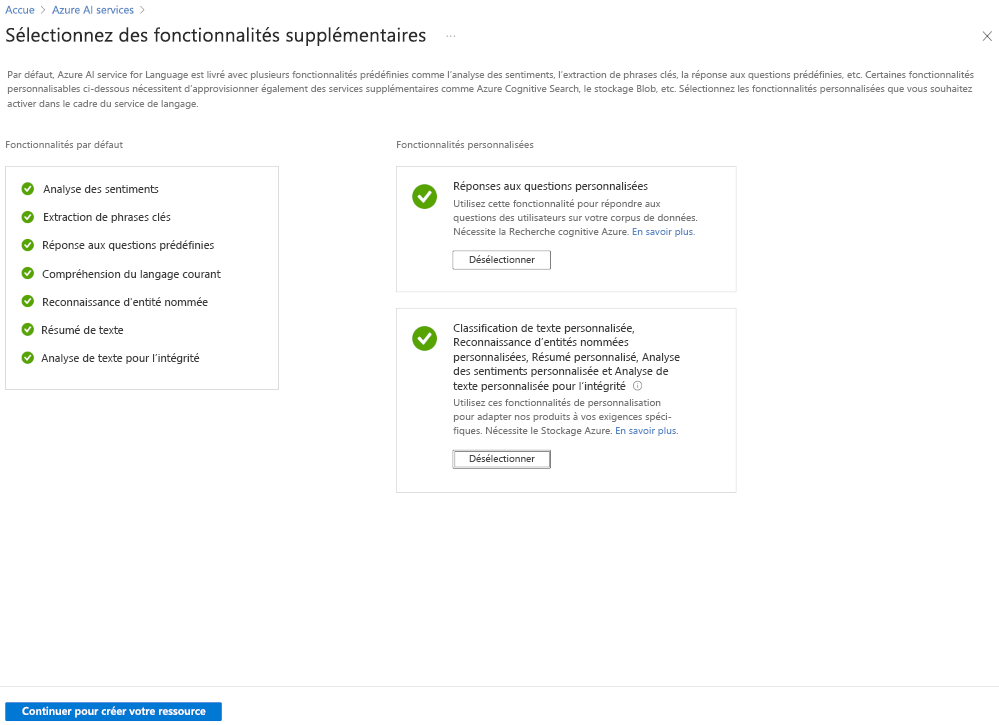
Comme vous allez créer une classification de texte personnalisée, sélectionnez cette fonctionnalité personnalisée lors de la création de votre service de langage. Vous allez aussi lier le service de langage à un compte de stockage en utilisant cette méthode.
Une fois la ressource déployée, vous pouvez accéder directement à Language Studio à partir du volet Vue d’ensemble du service de langage. Vous pouvez ensuite créer un projet de classification de texte personnalisée.
Remarque
Si vous avez créé votre service de langage depuis Language Studio, il peut être nécessaire de suivre ces étapes. Définissez des rôles pour votre ressource Azure Language et votre compte de stockage pour connecter votre conteneur de stockage à votre projet de classification de texte personnalisée.
Entraîner votre modèle de classification de texte
Comme avec tous les modèles IA, vous devez avoir identifié les données que vous pouvez utiliser pour l’entraîner. Le modèle doit voir des exemples montrant comment mapper des données à une classe et avoir des exemples qu’il peut utiliser pour tester le modèle. Vous pouvez choisir de laisser le modèle diviser automatiquement vos données d’apprentissage. Par défaut, il utilise 80 % des documents pour effectuer l’apprentissage du modèle et 20 % pour le tester en aveugle. Si vous avez des documents spécifiques avec lesquels vous voulez tester votre modèle, vous pouvez étiqueter des documents à des fins de test.

Dans Language Studio, dans votre projet, sélectionnez Étiquetage des données. Vous allez voir tous vos documents. Sélectionnez chaque document que vous voulez ajouter au jeu de test, puis sélectionnez Tester les performances du modèle. Enregistrez vos étiquettes mises à jour, puis créez un travail d’entraînement.
Créer un index de recherche
Il n’y a rien de spécifique à faire pour créer un index de recherche qui sera enrichi par un modèle de classification de texte personnalisée. Suivez les étapes décrites dans Créer une solution Recherche Azure AI. Vous allez mettre à jour l’index, l’indexeur et la compétence personnalisée une fois que vous aurez créé une application de fonction.
Créer une application de fonction Azure
Vous pouvez choisir le langage et les technologies souhaités pour votre application de fonction. L’application doit pouvoir passer du JSON au point de terminaison de classification de texte personnalisée, par exemple :
{
"displayName": "Extracting custom text classification",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "en-us",
"text": "This film takes place during the events of Get Smart. Bruce and Lloyd have been testing out an invisibility cloak, but during a party, Maraguayan agent Isabelle steals it for El Presidente. Now, Bruce and Lloyd must find the cloak on their own because the only non-compromised agents, Agent 99 and Agent 86 are in Russia"
}
]
},
"tasks": [
{
"kind": "CustomMultiLabelClassification",
"taskName": "Multi Label Classification",
"parameters": {
"project-name": "movie-classifier",
"deployment-name": "test-release"}
}
]
}
Elle doit ensuite traiter la réponse JSON provenant du modèle, par exemple :
{
"jobId": "be1419f3-61f8-481d-8235-36b7a9335bb7",
"lastUpdatedDateTime": "2022-06-13T16:24:27Z",
"createdDateTime": "2022-06-13T16:24:26Z",
"expirationDateTime": "2022-06-14T16:24:26Z",
"status": "succeeded",
"errors": [],
"displayName": "Extracting custom text classification",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "CustomMultiLabelClassificationLROResults",
"taskName": "Multi Label Classification",
"lastUpdateDateTime": "2022-06-13T16:24:27.7912131Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "1",
"class": [
{
"category": "Action",
"confidenceScore": 0.99
},
{
"category": "Comedy",
"confidenceScore": 0.96
}
],
"warnings": []
}
],
"errors": [],
"projectName": "movie-classifier",
"deploymentName": "test-release"
}
}
]
}
}
La fonction retourne ensuite un message JSON structuré à un ensemble de compétences personnalisées dans Recherche AI, par exemple :
[{"category": "Action", "confidenceScore": 0.99}, {"category": "Comedy", "confidenceScore": 0.96}]
L’application de fonction a besoin de cinq choses :
- Le texte à classifier.
- Le point de terminaison pour votre modèle déployé de classification de texte personnalisée entraîné.
- La clé principale du projet de classification de texte personnalisée.
- Nom du projet.
- Le nom du déploiement.
Le texte à classifier est passé de votre ensemble de compétences personnalisé dans Recherche AI à la fonction en tant qu’entrée. Les quatre éléments restants sont disponibles dans Language Studio.

Les noms du point de terminaison et du déploiement se trouvent dans le volet Déploiement du modèle.

Le nom du projet et la clé principale se trouvent dans le volet Paramètres du projet.
Mettre à jour votre solution Recherche Azure AI
Vous devez apporter trois modifications dans le portail Azure pour enrichir votre index de recherche :
- Vous devez ajouter un champ à votre index pour stocker l’enrichissement de la classification de texte personnalisée.
- Vous devez ajouter un ensemble de compétences personnalisées pour appeler votre application de fonction avec le texte à classifier.
- Vous devez mapper la réponse de l’ensemble de compétences dans l’index.
Ajouter un champ à un index existant
Dans le portail Azure, accédez à votre ressource Recherche AI, sélectionnez l’index, puis ajoutez du JSON dans ce format :
{
"name": "classifiedtext",
"type": "Collection(Edm.ComplexType)",
"analyzer": null,
"synonymMaps": [],
"fields": [
{
"name": "category",
"type": "Edm.String",
"facetable": true,
"filterable": true,
"key": false,
"retrievable": true,
"searchable": true,
"sortable": false,
"analyzer": "standard.lucene",
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
},
{
"name": "confidenceScore",
"type": "Edm.Double",
"facetable": true,
"filterable": true,
"retrievable": true,
"sortable": false,
"analyzer": null,
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
}
]
}
Ce JSON ajoute un champ composé à l’index pour stocker la classe dans un champ category pouvant faire l’objet d’une recherche. Le deuxième champ confidenceScore stocke le pourcentage de confiance dans un champ double.
Modifier l’ensemble de compétences personnalisées
Dans le portail Azure, sélectionnez l’ensemble de compétences et ajoutez le JSON dans ce format :
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "Genre Classification",
"description": "Identify the genre of your movie from its summary",
"context": "/document",
"uri": "https://learn-acs-lang-serives.cognitiveservices.azure.com/language/analyze-text/jobs?api-version=2022-05-01",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 1,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "lang",
"source": "/document/language"
},
{
"name": "text",
"source": "/document/content"
}
],
"outputs": [
{
"name": "text",
"targetName": "class"
}
],
"httpHeaders": {}
}
Cette définition de compétence WebApiSill spécifie que la langue et le contenu d’un document sont passés comme entrées à l’application de fonction. L’application va retourner un texte JSON nommé class.
Mapper la sortie de l’application de fonction dans l’index
La dernière modification consiste à mapper la sortie dans l’index. Dans le portail Azure, sélectionnez l’indexeur et modifiez le JSON pour avoir un nouveau mappage de sortie :
{
"sourceFieldName": "/document/class",
"targetFieldName": "classifiedtext"
}
L’indexeur sait maintenant que la sortie de l’application de fonction document/class doit être stockée dans le champ classifiedtext. Comme ceci a été défini en tant que champ composé, l’application de fonction doit retourner un tableau JSON contenant un champ category et confidenceScore.
Vous pouvez maintenant effectuer des recherches dans un index de recherche enrichi pour votre texte classifié personnalisé.