Expliquer comment optimiser le stockage Azure pour les machines virtuelles SQL Server
Les performances de stockage sont un composant essentiel d’une application gourmande en E/S, comme un moteur de base de données. Azure offre un large choix d’options de stockage et peut même créer votre solution de stockage pour répondre à vos besoins de charge de travail.
Le Stockage Azure est une plateforme de stockage sécurisée et hautement scalable qui offre une gamme de solutions pour répondre aux besoins de nombreuses applications. Étant donné que ce cours est axé sur les bases de données, vous découvrirez les aspects du stockage qui s’appliquent aux charges de travail SQL Server, à savoir le stockage sur disque, de fichiers et de blobs. Notez que tous les types de stockage ci-dessus prennent en charge le chiffrement au repos avec une clé de chiffrement gérée par Microsoft ou définie par l’utilisateur.
Stockage de blobs - Le stockage de blobs est ce que l’on appelle un stockage basé sur les objets et comprend des niveaux de stockage froid, chaud et archive. Dans un environnement SQL Server, le stockage de blobs est généralement utilisé pour les sauvegardes de bases de données avec la fonctionnalité de sauvegarde sur URL de SQL Server.
Stockage de fichiers - Le stockage de fichiers est un partage de fichiers qui peut être monté dans une machine virtuelle, sans avoir à installer de matériel. SQL Server peut utiliser le stockage de fichiers en tant que cible de stockage pour une instance de cluster de basculement.
Stockage sur disque - Les disques managés Azure offrent un stockage de bloc présenté à une machine virtuelle. Ces disques sont managés de la même façon qu’un disque physique sur un serveur local, à ceci près qu’ils sont virtualisés. Il existe plusieurs niveaux de performances dans les disques managés, en fonction de votre charge de travail. Ce type de stockage est le plus couramment utilisé pour les fichiers de données et de journaux de transactions SQL Server.
Disques managés Azure
Les disques managés Azure sont des volumes de stockage de niveau bloc qui sont présentés aux machines virtuelles Azure. Le stockage de niveau bloc fait référence à des volumes bruts de stockage qui sont créés et peuvent être traités comme un disque dur individuel. Ces dispositifs de bloc peuvent être gérés dans le système d’exploitation, et le niveau de stockage n’a pas connaissance du contenu du disque. L’alternative au stockage de bloc est le stockage d’objets, où les fichiers et leurs métadonnées sont stockés sur le système de stockage sous-jacent. Le stockage Blob Azure est un exemple de modèle de stockage d’objets. Même si le stockage d’objets fonctionne bien pour de nombreuses solutions de développement modernes, la plupart des charges de travail exécutées sur des machines virtuelles utilisent le stockage de bloc.
La configuration de vos disques managés est importante pour les performances de vos charges de travail SQL Server. Si vous venez d’un environnement local, il est important de capturer les métriques comme la moyenne de lectures/seconde sur disque et la moyenne d’écritures/seconde sur disque dans l’Analyseur de performances, comme détaillé précédemment. Une autre métrique à capturer est le nombre d’opérations d’E/S par seconde, qui peuvent être relevées avec les compteurs SQL Server : statistiques des pools de ressources, E/S de lecture sur le disque par seconde, E/S d’écriture sur le disque par seconde, qui vous indiquent le nombre d’E/S par seconde que traite SQL Server à son maximum. Il est important de comprendre vos charges de travail. Vous devez concevoir votre stockage et votre machine virtuelle pour répondre aux besoins de ces pics de charge de travail sans avoir à subir une latence importante. Notez que chaque type de machine virtuelle Azure a une limite d’E/S par seconde.
Les disques managés Azure se présentent sous quatre types :
Disque Ultra - Les disques Ultra prennent en charge les charges de travail aux E/S élevées pour les bases de données critiques avec une faible latence.
Disque SSD Premium - Les disques SSD Premium ont un débit élevé et une latence faible, et peuvent répondre aux besoins de la plupart des charges de travail de base de données exécutées dans le cloud.
Disque SSD Standard - Les disques SSD Standard sont conçus pour les charges de travail dev/test peu utilisées ou les serveurs web qui présentent une petite quantité d’E/S, et demandent une latence prévisible.
Disque HDD Standard - Les disques HDD Standard conviennent aux sauvegardes et au stockage de fichiers auxquels vous n’accédez pas fréquemment.
En règle générale, les charges de travail SQL Server de production utilisent un disque Ultra ou SSD Premium, ou une combinaison des deux. Les disques Ultra sont généralement utilisés là où vous recherchez une latence de temps de réponse en sous-milliseconde. Les disques SSD Premium ont généralement un temps de réponse en millisecondes à un chiffre, mais leur prix est plus bas et leur conception plus souple. Les disques SSD Premium prennent également en charge la mise en cache de lecture, ce qui peut profiter aux charges de travail de base de données lourdes en lecture, car cela réduit le nombre de trajets sur le disque. Le cache de lecture est stocké sur le disque SSD local (D:\lecteur sur Windows ou /dev/sdb1/ sur Linux), ce qui permet de réduire le nombre d’allers-retours vers le disque réel.
Répartir les disques pour un débit maximal
L’une des façons d’optimiser les performances et le volume sur les disques Azure est de répartir les données sur plusieurs disques. Cette technique ne s’applique pas au disque Ultra, car vous pouvez adapter les E/S par seconde, le débit et la taille maximale indépendamment sur un seul disque. Toutefois, avec les disques SSD Premium, il peut être avantageux d’adapter les E/S par seconde et le volume de stockage. Pour répartir les disques dans Windows, il vous suffit d’ajouter le nombre de disques que vous souhaitez ajouter à la machine virtuelle, puis de créer un pool avec les espaces de stockage dans Windows. Ne configurez pas de redondance pour votre pool (ce qui limiterait vos performances), car celle-ci est fournie par le framework Azure, qui conserve trois copies de tous les disques dans la réplication synchrone pour se protéger d’une panne de disque. Lorsque vous créez un pool, votre pool contient la somme des E/S par seconde et la somme du volume de tous les disques de votre pool. Par exemple, si vous utilisez 10 disques P30 d’un To chacun avec 5 000 E/S par seconde par disque, vous aurez un volume de 10 To avec 50 000 E/S par seconde disponibles.
Bonnes pratiques pour configurer le stockage SQL Server
Voici quelques bonnes pratiques recommandées pour SQL Server sur les machines virtuelles Azure et leur configuration de stockage :
Créer un volume distinct pour les fichiers de données et de journaux des transactions
Activer la mise en cache de lecture sur le volume de fichiers de données
Ne pas activer de mise en cache sur le volume de fichiers journaux
Planifier 20 % supplémentaire d’E/S par seconde et de débit lors de la création de votre stockage pour votre machine virtuelle afin de gérer les pics de charge de travail
Utiliser le lecteur D: (le SSD attaché localement) pour les fichiers TempDB parce que TempDB est recréé lors du redémarrage du serveur, donc il n’y a aucun risque de perte de données
Activer l’initialisation instantanée des fichiers pour réduire l’impact des activités de croissance des fichiers
Déplacer les répertoires des fichiers de trace et des journaux des erreurs vers les disques de données
Pour les charges de travail nécessitant une latence de stockage inférieure à une milliseconde, envisagez d’utiliser un disque Ultra plutôt qu’un disque SSD Premium.
Fournisseur de ressources de machine virtuelle Azure
Pour réduire la complexité de la création du stockage pour votre instance SQL Server sur une machine virtuelle Azure, vous pouvez utiliser les modèles SQL Server de la Place de marché Azure, qui vous permettent de configurer votre stockage lors de votre déploiement, comme montré ci-dessous. Vous pouvez configurer les E/S par seconde en fonction des besoins et le modèle fera le travail de création de pools d’espaces de stockage dans Windows.
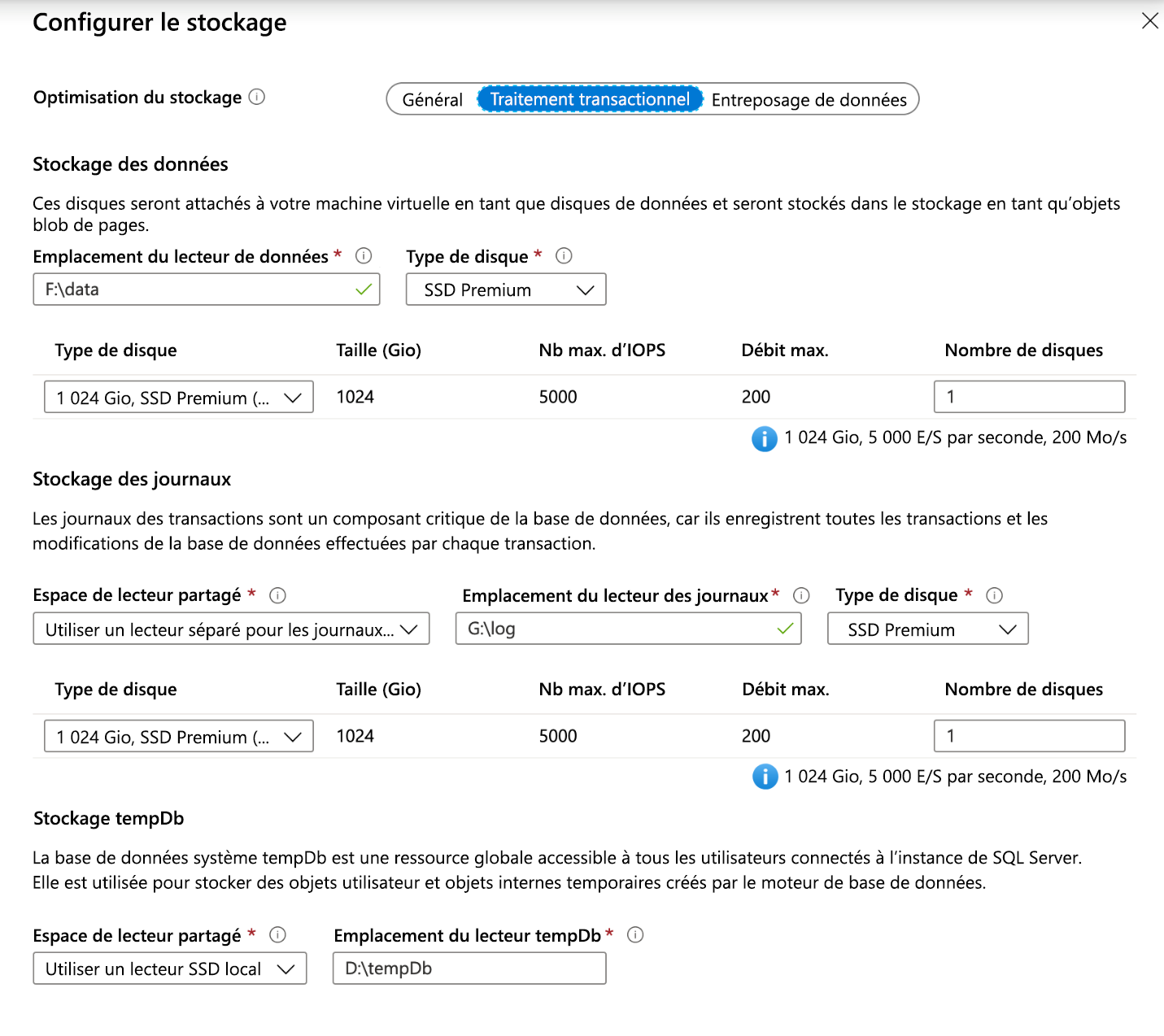
Ce fournisseur de ressources prend également en charge l’ajout de TempDB au disque SSD local et crée une tâche planifiée pour créer le dossier au démarrage.