Résilience dans la conception et la stratégie
« Continuité d’activité » est probablement l’expression qui accompagne le plus souvent « Reprise d’activité ». Continuité a une connotation positive. Elle évoque la situation idéale, qui est de confiner un sinistre entre les murs du centre de données, voire à quelque chose de plus petit.
Mais « continuité » n’est pas un terme d’ingénierie, en dépit des efforts pour changer cela. Il n’existe pas de formule, de méthodologie ou de recette unique pour la continuité d’activité. Chaque organisation peut suivre un ensemble unique de bonnes pratiques qui dépendent du type de son activité et de sa façon de l’exercer. La continuité consiste à mettre correctement en œuvre ces pratiques pour parvenir à un résultat positif.
Signification de la résilience
Les ingénieurs comprennent le concept de résilience. Quand un système fonctionne bien dans des circonstances changeantes, il est dit résilient. Un gestionnaire des risques estime qu’une entreprise est bien préparée si elle a mis en place des mesures de sécurité et des procédures de reprise d’activité à même de répondre à tout impact qui pourrait lui être préjudiciable. Un ingénieur ne qualifie pas forcément l’environnement dans lequel fonctionne un système fonctionne de « normal », « à risque », « en sécurité » et « sinistré ». Cette personne perçoit le système sur lequel s’appuie une entreprise comme étant en bon état de marche quand il offre des niveaux de service continus et prévisibles en dépit de circonstances défavorables.
En 2011, époque où le cloud computing commençait à avoir le vent en poupe dans les centres de données, l’Agence Européenne chargée de la sécurité des réseaux et de l’information (ou ENISA, entité de l’Union européenne) émit un rapport à la demande d’un État membre de l’Union européenne qui souhaitait des éclaircissements sur la résilience des systèmes où étaient recueillies et regroupées les informations. Le rapport indiquait clairement qu’il n’existait pas encore de consensus parmi son personnel TIC (en Europe, « TIC » est l’équivalent de « IT », acronyme qui inclut « communications ») autour de la signification exacte de « résilience » ni de méthodes pour la mesurer.
C’est alors que l’ENISA découvrit un projet lancé par une équipe de chercheurs de l’Université du Kansas (KU), dirigée par le professeur James P. G. Sterbenz, et qui devait être déployé dans le Département de la Défense des États-Unis. Cette initiative est appelée ResiliNets (Resilient and Survivable Networking Initiative) 1 et il s’agit d’une méthode destinée à visualiser l’état de résilience fluctuant des systèmes d’information dans diverses circonstances. ResiliNets était le prototype d’un modèle consensuel de stratégie de résilience au sein des organisations.
Le modèle KU s’appuie sur un certain nombre de métriques connues et faciles à expliquer, dont certaines ont déjà été présentées dans ce chapitre. Ces métriques sont les suivantes :
Tolérance de panne – Comme expliqué précédemment, il s’agit de la capacité d’un système à maintenir les niveaux de service attendus en présence de défaillances
Tolérance d’interruption de service – Capacité de ce même système à maintenir les niveaux de service attendus en dépit de circonstances imprévisibles et souvent extrêmes non causées par le système lui-même (par exemple, pannes électriques, manque de bande passante Internet et pics de trafic).
Survivabilité – Estimation de la capacité d’un système à fournir des niveaux de performance de service raisonnables, voire toujours normaux, dans toutes les circonstances possibles, y compris les catastrophes naturelles.
La principale théorie avancée par ResiliNets est que l’augmentation quantifiable de la résilience des systèmes d’information est le fait à la fois de l’ingénierie système et des efforts humains. C’est ce que font les personnes (ou plus exactement, ce qu’elles continuent de faire au quotidien) qui rend les systèmes plus forts.
S’inspirant des méthodes employées par les soldats, les matelots et les Marines engagés sur des théâtres d’opérations actifs pour apprendre et mémoriser des principes de déploiement tactique, l’équipe KU a proposé un mnémonique simple pour mémoriser le cycle de vie de la pratique ResiliNets : D2R2 + DR. Comme illustré dans la Figure 9, la forme développée de ces variables est indiquée ci-dessous, dans cet ordre :**
Defend (Défendre) le système contre les menaces et assurer son fonctionnement normal
Detect (Détecter) les effets néfastes de défaillances possibles ainsi que de circonstances extérieures
Remediate (Remédier) à l’impact possible de ces effets sur le système, même si cet impact n’a pas encore été subi
Recover (Rétablir) les niveaux de service normaux
Diagnose (Diagnostiquer) les causes à l’origine des événements
Refine (Redéfinir) si nécessaire les comportements futurs afin d’être mieux préparé s’ils se reproduisent
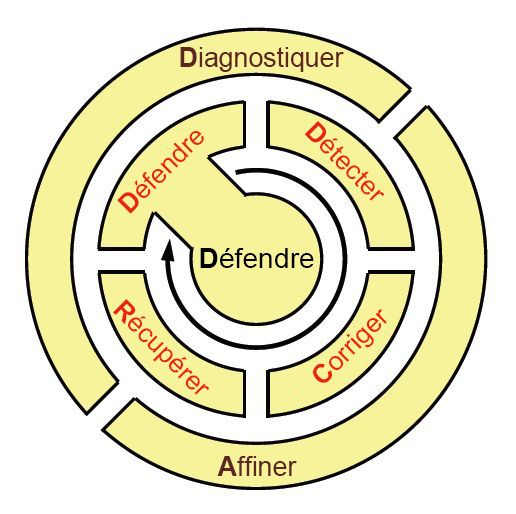
Figure 9 : Cycle de vie des activités recommandées dans un environnement qui utilise ResiliNets.
À chacune de ces étapes, certaines métriques de performance et d’opérations sont obtenues, à la fois pour les personnes et les systèmes. En combinant ces métriques, vous obtenez des points qui peuvent être placés sur un graphique comme celui illustré dans la Figure 9.10, qui consiste en un plan géométrique euclidien. Chaque métrique peut être réduite à deux valeurs à une dimension : une qui correspond à des paramètres de niveau de service P et une autre qui représente l’état opérationnel N. Comme les six étapes du cycle ResiliNets sont mises en œuvre et répétées, l’état du service S est placé sur le graphique aux coordonnées (N, P).
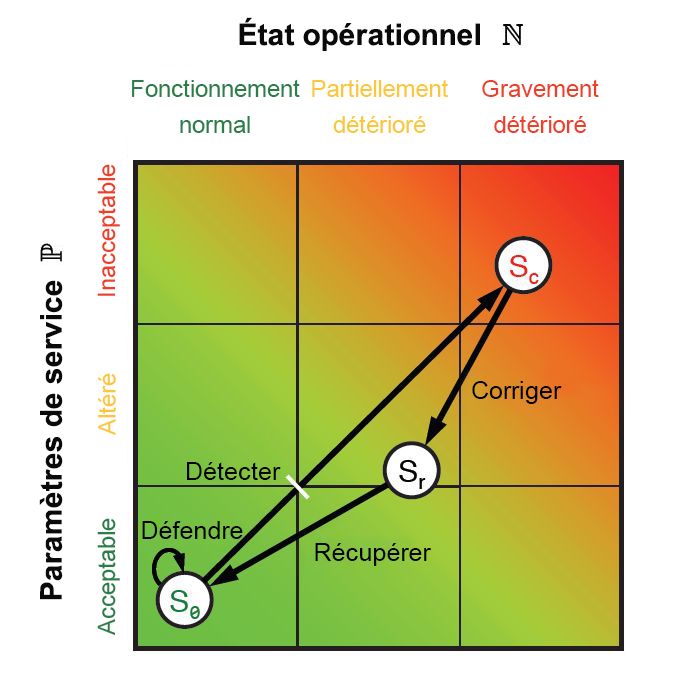
Figure 10 : Boucle interne de stratégie et d’espace d’état ResiliNets.
Pour une organisation qui atteint ses objectifs en matière de service, son état S se situe tout près de l’angle inférieur gauche du graphique, avec l’espoir qu’il y reste ou qu’il ne s’en éloigne pas trop pendant toute la durée de ce qui s’appelle la boucle interne. Quand les objectifs de service se détériorent, l’état se déplace sur un vecteur indésirable en direction du coin supérieur droit.
Bien que le modèle ResiliNets ne soit pas devenu une représentation omniprésente de la résilience informatique dans l’entreprise, son adoption dans certaines organisations importantes, en particulier dans le secteur public, a provoqué certains changements qui ont servi de catalyseur à la révolution du cloud :
Visualisation du niveau de performance. La résilience ne doit pas nécessairement être une philosophie consistant à communiquer son état actuel aux parties prenantes concernées. En effet, il peut être représenté en moins d’un mot. Les plateformes de gestion des performances modernes qui intègrent les métriques du cloud proposent des tableaux de bord et des outils similaires qui s’avèrent tout aussi efficaces.
Les mesures et procédures de récupération n’attendent pas nécessairement un sinistre. Un système d’information en règle et bien conçu, suivi en permanence par des ingénieurs et des opérateurs vigilants, mettra régulièrement en œuvre des procédures de maintenance qui se différencient peu ou pas des procédures correctives de crise. Dans un environnement de reprise d’activité de serveur de secours, par exemple, le fait de corriger le problème de niveau de service peut en fait devenir automatique : le routeur principal détourne simplement le trafic en provenance des composants impactés. En d’autres termes, se préparer à une défaillance ne doit pas être pareil que d’attendre qu’elle se produise.
Les systèmes d’information sont constitués de personnes. L’automatisation peut contribuer à améliorer l’efficacité du travail des employés et de la fabrication des produits. Mais elle ne saurait remplacer les personnes dans un système où il est nécessaire de répondre à des changements de circonstances et d’environnement qui ne peuvent pas être anticipés.
Concept ROC (Recovery-Oriented Computing)
ResiliNets est une des mises en œuvre d’un concept en partie inventé par Microsoft au début du siècle appelé ROC (Recovery-Oriented Computing).2 Son principe clé est que les défaillances et les bogues sont inhérents à l’environnement informatique. Plutôt que de passer un temps excessif à « désinfecter » cet environnement, les organisations ont peut-être plus intérêt à appliquer des mesures de bon sens qui contribuent à immuniser l’environnement. Il s’agit de l’équivalent informatique du concept radical, introduit un peu avant la fin du 20e siècle, qui consiste à se laver les mains plusieurs fois par jour.
La résilience dans le cloud public
Les fournisseurs de services de cloud public adhèrent tous aux principes et cadres de référence de la résilience, même quand ils choisissent de ne pas la nommer ainsi. Cependant, une plateforme cloud n’ajoute pas la résilience au centre de données d’une organisation, à moins qu’elle absorbe en intégralité les ressources d’informations de cette organisation dans le cloud. Une implémentation de cloud hybride n’est pas aussi résiliente que ses administrateurs les moins scrupuleux. Si nous pouvons supposer que les administrateurs d’un fournisseur de solutions cloud adhèrent scrupuleusement à la résilience (faute de quoi, ils ne respecteraient pas les termes de leur contrat SLA), c’est toujours au client qu’il doit revenir d’assurer la résilience du système complet.
Cadre de référence de la résilience Azure
Les recommandations internationales en matière de stratégie de continuité d’activité sont fixées par la norme ISO 22301. Comme pour les autres cadres de référence de l’Organisation internationale de normalisation (ISO), cette norme précise les lignes directrice des bonnes pratiques et des opérations auxquelles une organisation doit se conformer pour pouvoir bénéficier d’une certification professionnelle.
Ce cadre de référence ISO ne définit pas réellement la continuité d’activité ni d’ailleurs la résilience. En revanche, il définit ce que signifie la continuité dans le contexte propre de l’organisation : « L’organisation identifier et effectuer un choix parmi les stratégies de continuité d’activité », comme l’indique son document de référence, « en fonction des résultats de l’analyse d’impact professionnel et de l’évaluation des risques. Les stratégies de continuité d’activité doivent être constituées d’une ou plusieurs solutions ».3
La Figure 11 est la représentation de Microsoft de la mise en conformité graduelle d’Azure à la norme ISO 22301. Notez l’inclusion des objectifs de durée d’activité du Contrat de niveau de service (SLA). Pour les clients qui choisissent ce niveau de résilience, Azure réplique les centres de données virtuels dans leurs zones de disponibilité locales, mais provisionne des réplicas distincts séparés géographiquement de plusieurs centaines de kilomètres. Cependant, pour des raisons juridiques (en particulier pour rester en conformité avec à la législation de l’Union européenne relative à la protection de la vie privée), cette redondance géolocalisée est généralement limitée aux « limites de résidence des données », comme l’Amérique du Nord ou l’Europe.
![Figure 11 : infrastructure de la résilience Azure, qui protège les composants actifs à plusieurs niveaux, conformément à la norme ISO 22301. [Fournit par Microsoft]](../../cmu-cloud-admin/cmu-disaster-recovery-backup/media/fig9-11.jpg)
Figure 11 : Cadre de référence de la résilience Azure, qui protège les composants actifs à plusieurs niveaux, conformément à la norme ISO 22301. [Fourni par Microsoft]
Bien que la norme ISO 22301 soit associée à la résilience et qu’elle soit souvent décrite comme étant un ensemble de recommandations sur la résilience, les niveaux de résilience pour lesquels Azure a été testé sont applicables uniquement à la plateforme Azure, et non aux ressources client hébergées sur cette plateforme. Le client reste responsable de la gestion, de l’actualisation et de l’amélioration fréquente de ses processus, notamment de la façon dont ses ressources sont répliquées dans le cloud Azure et ailleurs.
Google Container Engine
Jusqu’il y a peu, les logiciels étaient perçus comme l’état d’une machine qui était fonctionnellement identique au matériel, mais sous une forme numérique. Vu sous cet angle, les logiciels étaient perçus comme un composant relativement statique dans un système d’information. Les protocoles de sécurité imposaient une mise à jour régulière des logiciels, à raison de plusieurs fois par an, à mesure que les mises à jour et les correctifs de bogues étaient mis à disposition.
Ce que la dynamique du cloud a permis, mais que de nombreux ingénieurs en informatique n’avaient pas anticipé, c’est la possibilité de faire évoluer les logiciels de manière incrémentielle (et fréquente). L’intégration continue et la livraison continue (CI/CD) consistent en un ensemble de principes récent selon lequel l’automatisation permet d’apporter des modifications fréquentes, souvent quotidiennes, et incrémentielles aux logiciels, aussi bien côté serveur que côté client. Les utilisateurs de smartphones font régulièrement l’expérience de CI/CD, dans la mesure où leurs applications sont parfois mises à jour plusieurs fois par semaine via les app stores. Chaque modification apportée par CI/CD peut être mineure, mais le fait même que les modifications mineures puissent être rapidement déployées sans difficulté a eu des répercussions inattendues, mais salutaires : des systèmes d’information beaucoup plus résilients.
Grâce aux modèles de déploiement CI/CD, des clusters de serveurs entièrement redondants sont provisionnés et tenus à jour, souvent sur une infrastructure de cloud public, exclusivement dans le but d’identifier les bogues dans les composants logiciels nouvellement produits, puis d’indexer ces derniers dans un environnement de travail simulé pour découvrir les défaillances potentielles. De cette façon, les processus de correction peuvent s’opérer dans un environnement sécurisé qui n’a aucun effet direct sur les niveaux de service orientés client ou utilisateur, tant que les corrections n’ont pas été appliquées, testées et approuvés pour le déploiement.
Google Container Engine (GKE, « K » signifiant « Kubernetes ») est l’environnement de Google Cloud Platform pour les clients déployant des applications et des services basés sur des conteneurs, plutôt que des applications basées sur des machines virtuelles. Un déploiement entièrement conteneurisé peut inclure des microservices (« μ-services »), des bases de données distinctes des charges de travail et conçues pour fonctionner de façon indépendante (« jeux de données avec état »), des bibliothèques de code dépendantes et des systèmes d’exploitation légers utilisés quand le code d’application doit s’appuyer sur le système de fichiers propre au conteneur. La Figure 9.12 illustre un déploiement de ce type, tel que Google le suggère à ses clients GKE.
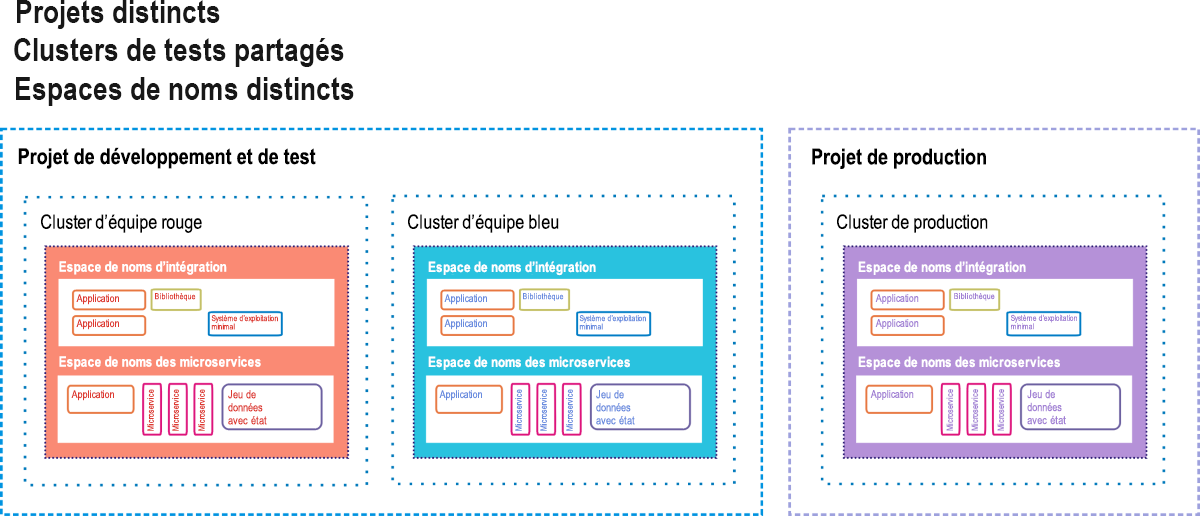
Figure 12 : Option de serveur de secours en guise d’environnement intermédiaire CI/CD pour Google Container Engine.
Dans GKE, un projet est comparable à un centre de données dans le sens où il est perçu comme étant constitué de toutes les ressources que doit normalement posséder un centre de données, sauf qu’il est virtuel. Un ou plusieurs clusters de serveurs peuvent être affectés à un projet. Les composants en conteneur existent dans leurs propres espaces de noms , qui sont semblables à leur univers d’origine. Chacun d’eux est constitué de tous les composants adressables auxquels ses conteneurs membres sont autorisés à accéder, et tout ce qui est extérieur à l’espace de noms doit être adressé avec des adresses IP distantes. Les ingénieurs de Google laissent entendre que les applications client/serveur à l’ancienne (appelées « monolithes » par les développeurs de conteneurs) peuvent coexister avec les applications en conteneur, à condition que chaque classe utilise son propre espace de noms pour la sécurité, tout en partageant le même projet.
Dans ce diagramme de déploiement suggéré figurent trois clusters actifs, chacun d’eux utilisant deux espaces de noms : un pour les anciens logiciels, l’autre pour les nouveaux. Deux de ces clusters sont délégués pour les tests : un pour les tests de développement initiaux et l’autre pour les tests de préproduction. Dans un pipeline CI/CD, les nouveaux conteneurs de code sont injectés dans un des clusters de test. Ils y subissent une batterie de tests automatisés qui visent à s’assurer qu’ils ne contiennent pas trop de bogues. En cas de succès, ils sont transférés en préproduction. Une deuxième batterie attend les conteneurs des nouveaux logiciels. Seul le code qui a passé les tests intermédiaires de second niveau avec succès peut être injecté dans le cluster de production dynamique qu’utilisent les clients finaux.
Toutefois, même à ce niveau, il existe des dispositifs de sécurité. Dans un scénario de déploiement A/B, le nouveau code et l’ancien coexistent pendant un certain temps. Si le nouveau code n’est pas conforme aux spécifications ou s’il introduit des erreurs dans le système, il peut être retiré et l’ancien conservé. Si le nouveau code fonctionne correctement à l’issue de la période de probation, l’ancien code est retiré.
Il s’agit pour les systèmes d’information d’un processus systématique et semi-automatisée qui leur permet d’éviter l’introduction d’erreurs conduisant à des défaillances. Cependant, ce système n’est pas en soi à l’abri d’incidents, à moins que le cluster de production soit lui-même répliqué en mode serveur de secours. Ce schéma de réplication utilise certainement de nombreuses ressources cloud. Ceci dit, les coûts qu’il fait supporter à une organisation restent nettement inférieurs à ceux qu’elle devrait subir si un système non protégé devait tomber en panne.
Références
Sterbenz, James P.G., et autres « ResiliNets: Multilevel Resilient and Survivable Networking Initiative. » https://resilinets.org/main_page.html.
Patterson, David, et al. "Recovery Oriented Computing: Motivation, Definition, Principles, and Examples." Microsoft Research, mars 2002. https://www.microsoft.com/research/publication/recovery-oriented-computing-motivation-definition-principles-and-examples/.
ISO. « Sécurité et résilience – Systèmes de management de la continuité d’activité – Exigences. » https://dri.ca/docs/ISO_DIS_22301_(E).pdf.