Déployer des fichiers Bicep à l’aide d’un pipeline
Maintenant que vous avez créé un pipeline de base, vous êtes prêt à le configurer pour déployer vos fichiers Bicep. Dans cette unité, vous allez apprendre à déployer du code Bicep à partir d’un pipeline et comment vous pouvez configurer les étapes de déploiement.
Notes
Les commandes de cette unité sont présentées pour illustrer les concepts. N’exécutez pas encore les commandes. Vous allez bientôt mettre en pratique ce que vous apprenez ici.
Connexions de service
Lorsque vous déployez un fichier Bicep à partir de votre ordinateur, vous utilisez Azure CLI ou Azure PowerShell. Avant de pouvoir déployer votre code, vous devez vous connecter à Azure. En général, les outils vous demandent d’entrer votre adresse e-mail et votre mot de passe dans un navigateur. Une fois vos informations d’identification vérifiées, vos autorisations pour déployer des ressources sont confirmées et vous pouvez utiliser les outils pour déployer votre fichier Bicep.
Le déploiement par pipeline nécessite également une authentification. Comme les pipelines s’exécutent sans intervention humaine, ils s’authentifient auprès d’Azure en utilisant un principal de service. Les informations d’identification du principal de service se composent d’un ID d’application et d’un secret, qui est généralement une clé ou un certificat. Dans Azure Pipelines, vous utilisez une connexion de service pour stocker ces informations d’identification en toute sécurité afin que votre pipeline puisse les utiliser. La connexion de service comprend également d’autres informations pour aider votre pipeline à identifier l’environnement Azure sur lequel vous souhaitez effectuer le déploiement.
Conseil
Dans ce module, vous allez utiliser Azure DevOps pour créer automatiquement un principal de service au moment où une connexion de service est créée. Le module Authentifier votre pipeline de déploiement Azure à l’aide de principaux de service fournit une explication plus détaillée des principaux de service, notamment sur la façon dont ils fonctionnent, dont vous les créez, dont vous leur attribuez des rôles et dont vous les gérez.
Lorsque vous créez une connexion de service, vous lui donnez un nom. Les étapes font référence à la connexion de service à l’aide de ce nom, donc votre code YAML de pipeline n’a pas besoin de contenir d’informations secrètes.
Lorsque votre pipeline démarre, l’agent qui exécute vos étapes de déploiement a accès à la connexion de service, dont ces informations d’identification. Chaque étape de pipeline utilise ces informations d’identification pour se connecter à Azure, comme vous le faites vous-même. Ensuite, les actions définies dans l’étape utilisent l’identité du principal de service.
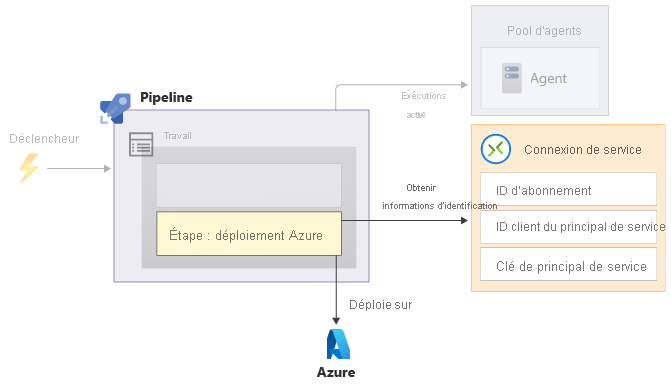
Vous devez vous assurer que votre principal de service dispose des autorisations nécessaires pour exécuter vos étapes de déploiement. Par exemple, vous devrez peut-être affecter le rôle contributeur au principal du service pour le groupe de ressources sur lequel il déploie vos ressources.
Avertissement
On pourrait croire qu’il est plus simple de simplement stocker les informations d’identification de votre principal de service dans le fichier YAML et de se connecter à l’aide de la commande az login. Vous ne devez jamais utiliser cette approche pour authentifier votre principal de service. Les informations d’identification sont stockées en texte clair dans le fichier YAML. Toute personne ayant accès à votre référentiel peut voir et utiliser les informations d’identification. Même si vous restreignez l’accès à votre organisation et votre projet Azure DevOps, chaque fois que quelqu’un clone votre référentiel, le fichier YAML contenant les informations d’identification se retrouve sur l’ordinateur de cette personne. Il est important d’utiliser une connexion de service chaque fois que vous travaillez avec Azure à partir d’un pipeline. Les connexions de service fournissent également d’autres fonctionnalités de sécurité et de contrôle d’accès.
Les connexions de service sont créées dans votre projet Azure DevOps. Une connexion de service unique peut être partagée par plusieurs pipelines. Toutefois, il est généralement judicieux de configurer une connexion de service et le principal du service correspondant pour chaque pipeline et chaque environnement sur lequel vous effectuez des déploiements. Cette pratique permet d’accroître la sécurité de vos pipelines et de réduire la probabilité de déployer ou de configurer accidentellement des ressources dans un environnement différent de celui attendu.
Vous pouvez également configurer votre connexion de service afin qu’elle ne puisse être utilisée que dans des pipelines spécifiques. Par exemple, lorsque vous créez une connexion de service qui effectue un déploiement dans l’environnement de production de votre site web, il est judicieux de vous assurer que seul le pipeline de votre site web peut utiliser cette connexion de service. Restreindre une connexion de service à des pipelines spécifiques empêche quelqu’un d’autre d’utiliser accidentellement la même connexion de service pour un autre projet et de provoquer une panne de votre site web de production.
Déployer un fichier Bicep à l’aide de la tâche de déploiement de groupes de ressources Azure
Lorsque vous devez déployer un fichier Bicep à partir d’un pipeline, vous pouvez utiliser la tâche Déploiement de groupes de ressources Azure. Voici un exemple de la façon dont vous pouvez configurer une étape pour utiliser la tâche :
- task: AzureResourceManagerTemplateDeployment@3
inputs:
connectedServiceName: 'MyServiceConnection'
location: 'westus3'
resourceGroupName: Example
csmFile: deploy/main.bicep
overrideParameters: >
-parameterName parameterValue
La première ligne spécifie AzureResourceManagerTemplateDeployment@3. Cela indique à Azure Pipelines que la tâche que vous souhaitez utiliser pour cette étape s’appelle AzureResourceManagerTemplateDeployment et que vous souhaitez utiliser la version 3 de la tâche.
Lorsque vous utilisez la tâche de déploiement de groupes de ressources, vous spécifiez des entrées pour indiquer à la tâche ce qu’elle doit faire. Voici quelques entrées que vous pouvez spécifier lorsque vous utilisez la tâche :
connectedServiceNameest le nom de la connexion de service Azure à utiliser.locationdoit être spécifié même si sa valeur peut ne pas être utilisée. La tâche de déploiement de groupes de ressources Azure peut également créer un groupe de ressources pour vous et si elle le fait, elle doit connaître la région Azure dans laquelle créer le groupe de ressources. Dans ce module, vous allez spécifier la valeur d’entréelocation, mais sa valeur n’est pas utilisée.resourceGroupNamespécifie le nom du groupe de ressources auquel le fichier Bicep doit être déployé.overrideParameterscontient toutes les valeurs de paramètre que vous souhaitez transmettre dans votre fichier Bicep au moment du déploiement.
Lorsque la tâche démarre, elle utilise la connexion de service pour se connecter à Azure. Au moment où la tâche exécute le déploiement que vous avez spécifié, la tâche s’est authentifiée. Vous n’avez pas besoin d’exécuter az login.
Exécuter les commandes Azure CLI et Azure PowerShell
Deux des tâches intégrées les plus utiles dans Azure Pipelines sont les tâches Azure CLI et Azure PowerShell. Vous pouvez utiliser ces tâches pour exécuter une ou plusieurs commandes Azure CLI ou PowerShell.
Dans les futurs modules Microsoft Learn, vous verrez comment la commande Azure CLI peut vous aider à automatiser davantage de parties de votre processus de déploiement à partir d’un pipeline.
Variables
Souvent, vos pipelines contiennent des valeurs que vous souhaitez conserver séparément de votre fichier YAML. Par exemple, lorsque vous déployez un fichier Bicep dans un groupe de ressources, vous spécifiez le nom du groupe de ressources. Le nom du groupe de ressources est probablement différent lorsque vous effectuez un déploiement dans différents environnements. Vous devrez peut-être aussi fournir des paramètres à vos fichiers Bicep, notamment des secrets tels que des mots de passe de serveur de base de données. Ne les stockez pas dans votre fichier YAML de pipeline ou n’importe où ailleurs dans votre référentiel Git. Au lieu de cela, pour améliorer la sécurité et rendre les définitions de pipeline réutilisables, utilisez des variables.
Créer une variable
L’interface web Azure Pipelines comporte un éditeur dans lequel vous pouvez créer des variables pour votre pipeline :
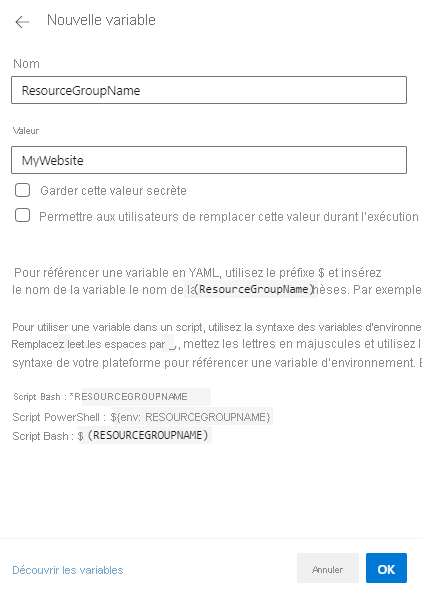
Vous pouvez définir une valeur de variable Azure Pipelines comme clé secrète. Lorsque vous définissez une valeur de variable comme étant un secret, vous ne pouvez pas afficher la valeur une fois que vous l’avez définie. Azure Pipelines est conçu pour ne pas révéler les valeurs secrètes dans vos journaux de pipeline.
Avertissement
Par défaut, Azure Pipelines obfusque les valeurs des variables secrètes dans les journaux de pipeline, mais vous devez également suivre les bonnes pratiques. Vos étapes de pipeline ont accès à toutes les valeurs de variables, y compris les secrets. Si votre pipeline inclut une étape qui ne gère pas une variable sécurisée en toute sécurité, il est possible que la variable secrète soit affichée dans les journaux de pipeline.
Vous pouvez permettre aux utilisateurs de remplacer une valeur de variable lorsqu’ils exécutent votre pipeline manuellement. La valeur fournie par un utilisateur est utilisée uniquement pour cette exécution de pipeline spécifique. Le remplacement de variable peut être utile lorsque vous testez votre pipeline.
Utiliser une variable dans votre pipeline
Après avoir créé une variable, vous utiliserez une syntaxe spécifique pour faire référence à la variable dans le fichier YAML de votre pipeline :
- task: AzureResourceManagerTemplateDeployment@3
inputs:
connectedServiceName: $(ServiceConnectionName)
location: $(DeploymentDefaultLocation)
resourceGroupName: $(ResourceGroupName)
csmFile: deploy/main.bicep
overrideParameters: >
-environmentType $(EnvironmentType)
Le format de fichier de définition du pipeline inclut une syntaxe spéciale $(VariableName). Vous pouvez faire référence à n’importe quelle variable à l’aide de cette approche, qu’elle soit secrète ou non.
Conseil
Dans l’exemple précédent, notez que le nom du fichier Bicep n’est pas stocké dans une variable. Tout comme les paramètres Bicep, vous n’avez pas besoin de créer des variables pour tout. Il est judicieux de créer des variables pour tout ce qui peut changer d’un environnement à l’autre et tout ce qui est secret. Étant donné que le pipeline utilisera toujours le même fichier de modèle, vous n’avez pas besoin de créer de variable pour le chemin d’accès.
Variables système
Azure Pipelines utilise également des variables système. Les variables système contiennent des informations prédéfinies que vous pouvez utiliser dans votre pipeline. Voici quelques-unes des variables système que vous pouvez utiliser dans votre pipeline :
Build.BuildNumberest l’identificateur unique de l’exécution de votre pipeline. En dépit de son nom, la valeurBuild.BuildNumberest souvent une chaîne, et non un nombre. Vous pouvez utiliser cette variable pour nommer votre déploiement Azure afin de pouvoir retracer le déploiement vers l’exécution de pipeline qui l’a déclenchée.Agent.BuildDirectoryest le chemin d’accès au système de fichiers de votre ordinateur agent où sont stockés les fichiers de l’exécution de votre pipeline. Ces informations peuvent être utiles lorsque vous souhaitez référencer des fichiers sur l’agent de build.
Créer des variables dans le fichier YAML de votre pipeline
Outre l’utilisation de l’interface web Azure Pipelines pour créer des variables, vous pouvez définir des valeurs de variables dans le fichier YAML de votre pipeline. Vous pouvez utiliser cette option lorsque vous avez des valeurs qui ne sont pas secrètes, lorsque les valeurs peuvent être stockées dans votre référentiel, et lorsque vous voulez garder les valeurs des variables dans un même endroit dans le fichier, afin de pouvoir y faire référence tout au long de la définition du pipeline. Vous pouvez utiliser cette approche pour effectuer le suivi des modifications apportées à la variable dans votre système de contrôle de version.
Pour définir une variable dans votre fichier YAML, ajoutez une section variables :
trigger: none
pool:
vmImage: ubuntu-latest
variables:
ServiceConnectionName: 'MyServiceConnection'
EnvironmentType: 'Test'
ResourceGroupName: 'MyResourceGroup'
DeploymentDefaultLocation: 'westus3'
jobs:
- job:
steps:
- task: AzureResourceManagerTemplateDeployment@3
inputs:
connectedServiceName: $(ServiceConnectionName)
location: $(DeploymentDefaultLocation)
resourceGroupName: $(ResourceGroupName)
csmFile: deploy/main.bicep
overrideParameters: >
-environmentType $(EnvironmentType)
Cet exemple de pipeline définit quatre variables : ServiceConnectionName, EnvironmentType, ResourceGroupName et DeploymentDefaultLocation.
Plus loin dans ce module, vous verrez comment combiner des variables définies dans différents espaces d’un pipeline.