Comprendre l’analyse de texte
Avant d’explorer les fonctionnalités d’analyse de texte du service Azure AI Language, examinons quelques principes généraux et techniques courantes utilisées pour effectuer une analyse de texte et d’autres tâches de traitement du langage naturel (NLP).
Certaines des premières techniques utilisées pour analyser du texte avec des ordinateurs impliquent une analyse statistique d’un corps de texte (un corpus) pour inférer une certaine signification sémantique. Autrement dit, si vous pouvez déterminer les mots les plus couramment utilisés dans un document donné, vous pouvez souvent avoir une bonne idée du sujet abordé dans le document.
Segmentation du texte en unités lexicales
La première étape de l’analyse d’un corpus consiste à le décomposer en jetons. Pour faire simple, vous pouvez considérer chaque mot distinct du texte d’apprentissage comme un jeton, même si en réalité, des jetons peuvent être générés pour des mots partiels, ou pour des combinaisons de mots et de ponctuation.
Par exemple, considérez cette phrase d’un célèbre discours d’un président américain : « we choose to go to the moon » (nous choisissons d’aller sur la lune). L’expression peut être divisée comme suit en jetons, avec des identificateurs numériques :
- we
- choose
- à
- go
- le
- moon
Notez que « to » (numéro de jeton 3) est utilisé deux fois dans le corpus. L’expression «we choose to go to the moon » peut être représentée par les jetons [1,2,3,4,3,5,6].
Remarque
Nous avons utilisé un exemple simple dans lequel des jetons sont identifiés pour chaque mot distinct du texte. Prenez cependant en compte les concepts suivants qui peuvent s’appliquer à la segmentation du texte en unités lexicales en fonction du type spécifique de problème de traitement du langage naturel que vous essayez de résoudre :
- Normalisation du texte : Avant de générer des jetons, vous pouvez choisir de normaliser le texte en supprimant la ponctuation et en mettant tous les mots en minuscules. Pour une analyse qui s’appuie uniquement sur la fréquence des mots, cette approche améliore les performances globales. Cependant, une certaine signification sémantique peut être perdue ; considérez par exemple la phrase « M. Banks a travaillé dans de nombreuses banques. ». Vous voulez que votre analyse différencie la personne M. Banks et les banques (banks) dans lesquelles il a travaillé. Vous voulez aussi considérer « banks. comme un jeton distinct de « banks », car l’inclusion d’un point donne l’information que le mot vient à la fin d’une phrase.
- Supprimez les mots vides. Les mots vides sont des mots qui doivent être exclus de l’analyse. Par exemple, des mots comme « le », « un » ou « il » rendent le texte plus facile à lire, mais ajoutent peu de signification sémantique. En excluant ces mots, une solution d’analyse de texte peut être mieux à même d’identifier les mots importants.
- Les n-grammes sont des expressions à plusieurs termes telles que « J’ai » ou « il marchait ». Une expression à un seul mot est un unigramme, une expression à deux mots est un bi-gramme, une expression à trois mots est un tri-gramme, et ainsi de suite. En considérant les mots en tant que groupes, un modèle Machine Learning peut mieux comprendre le texte.
- La recherche de radical est une technique dans laquelle des algorithmes sont appliqués pour normaliser les mots avant de les compter, pour que les mots ayant la même racine, comme « grandeur », « grand » et « grandir », soient interprétés comme étant le même jeton.
Analyse de la fréquence
Après avoir tokenisé les mots, vous pouvez effectuer une analyse pour compter le nombre d’occurrences de chaque jeton. Les mots les plus couramment utilisés (autres que les mots vides comme « un », « le », etc.) peuvent souvent fournir un indice sur le sujet principal d’un corpus de texte. Par exemple, les mots les plus courants dans le texte entier du discours « aller à la lune » que nous avons considéré précédemment incluent « new », « go », « space » et « moon ». Si nous voulons tokeniser le texte en tant que bigrammes (des paires de mots), nous voyons que le bigramme le plus courant dans le discours est « the moon ». À partir de ces informations, nous pouvons facilement supposer que le texte est principalement consacré au voyage dans l’espace et à aller sur la lune.
Conseil
Une analyse de fréquence simple dans laquelle vous comptez simplement le nombre d’occurrences de chaque jeton peut être un moyen efficace d’analyser un seul document, mais quand vous devez différencier plusieurs documents au sein du même corpus, vous avez besoin d’un moyen de déterminer quels jetons sont les plus pertinents dans chaque document. TF-IDF (Term Frequency - Inverse Document Frequency) est une technique courante dans laquelle un score est calculé en fonction de la fréquence à laquelle un mot ou un terme apparaît dans un document par rapport à sa fréquence plus générale dans l’ensemble de la collection de documents. Pour cette technique, un degré élevé de pertinence est supposé pour les mots qui apparaissent fréquemment dans un document particulier, mais relativement peu souvent dans un large éventail d’autres documents.
Machine Learning pour la classification de texte
Une autre technique d’analyse de texte utile consiste à utiliser un algorithme de classification, comme la régression logistique, pour effectuer l’apprentissage d’un modèle Machine Learning qui classifie le texte en fonction d’un ensemble connu de catégorisations. Une application courante de cette technique est d’effectuer l’apprentissage d’un modèle qui classifie le texte comme positif ou négatif afin d’effectuer une analyse des sentiments ou une exploration des opinions.
Par exemple, considérez les évaluations de restaurants suivantes, qui sont déjà étiquetées 0 (négatif) ou 1 (positif) :
- La nourriture et le service étaient tous les deux très biens : 1
- Une expérience vraiment très mauvaise : 0
- Mmh ! nourriture savoureuse et ambiance agréable : 1
- Service lent et nourriture de faible qualité : 0
Avec suffisamment d’évaluations étiquetées, vous pouvez effectuer l’apprentissage d’un modèle de classification en utilisant du texte tokenisé comme caractéristiques et le sentiment (0 ou 1) comme étiquette. Le modèle va encapsuler une relation entre les jetons et le sentiment : par exemple, les évaluations avec des jetons pour des mots comme « bon », « savoureux » ou « amusant » sont plus susceptibles de retourner un sentiment 1 (positif), tandis que les évaluations avec des mots comme « mauvais », « lent » et « faible » sont plus susceptibles de retourner 0 (négatif).
Modèles de langage sémantique
L’état de l’art pour le traitement du langage naturel ayant progressé, la possibilité d’effectuer l’apprentissage de modèles qui encapsulent la relation sémantique entre les jetons a conduit à l’émergence de modèles de langage puissants. Au cœur de ces modèles se trouve le codage des jetons du langage en tant que vecteurs (des tableaux de nombres avec des valeurs multiples) appelés incorporations.
Il peut être utile de considérer les éléments d’un vecteur d’incorporation de jetons comme des coordonnées dans un espace multidimensionnel, où chaque jeton occupe un « emplacement » spécifique. Plus des jetons sont proches les uns des autres le long d’une dimension particulière, plus ils sont sémantiquement liés. En d’autres termes, des mots liés sont regroupés plus près les uns des autres. Pour prendre un exemple simple, supposons que les incorporations pour nos jetons se composent de vecteurs avec trois éléments, par exemple :
- 4 ("dog"): [10.3.2]
- 5 ("bark"): [10,2,2]
- 8 ("cat"): [10,3,1]
- 9 ("meow"): [10,2,1]
- 10 ("skateboard"): [3,3,1]
Nous pouvons représenter l’emplacement des jetons d’après ces vecteurs dans un espace tridimensionnel, comme suit :
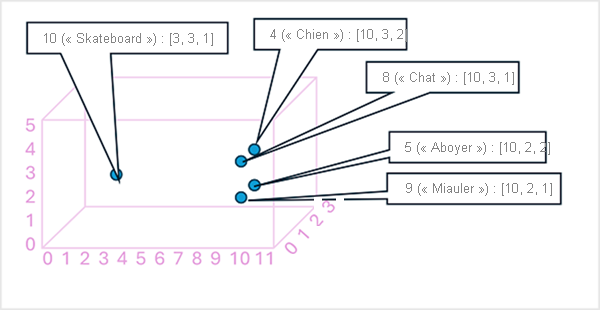
Les emplacements des jetons dans l’espace des incorporations incluent des informations sur la proximité avec laquelle les jetons sont liés les uns aux autres. Par exemple, le jeton pour « dog » est proche de « cat » et aussi de « bark ». Les jetons pour « cat » et « bark » sont proches de « meow ». Le jeton pour « skateboard » est plus éloigné des autres jetons.
Les modèles de langage que nous utilisons dans l’industrie sont basés sur ces principes, mais ont une plus grande complexité. Par exemple, les vecteurs généralement utilisés ont beaucoup plus de dimensions. Il existe également plusieurs façons de calculer les incorporations appropriées pour un ensemble donné de jetons. Différentes méthodes entraînent des prédictions différentes des modèles de traitement du langage naturel.
Le diagramme suivant montre donne une vue générale de la plupart des solutions de traitement du langage naturel modernes. Un grand corpus de texte brut est tokenisé et utilisé pour effectuer l’apprentissage des modèles de langage, qui peuvent prendre en charge de nombreux types différents de tâches de traitement du langage naturel.
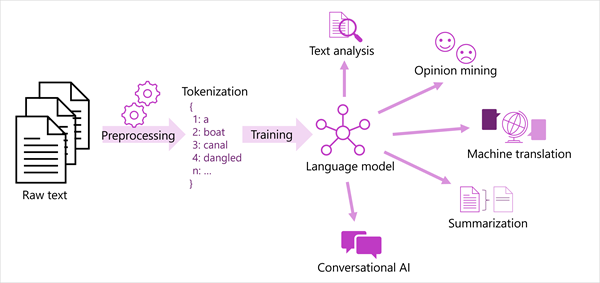
Les tâches de traitement du langage naturel courantes prises en charge par les modèles de langage sont les suivantes :
- Analyse de texte, comme l’extraction de termes clés ou l’identification d’entités nommées dans du texte.
- Analyse des sentiments et exploration des opinions pour catégoriser du texte comme positif ou négatif.
- Traduction automatique, où le texte est traduit automatiquement d’une langue dans une autre.
- Résumé, où les points principaux d’un grand corps de texte sont résumés.
- Les solutions d’IA conversationnelle comme les bots ou les assistants numériques, où le modèle de langage peut interpréter l’entrée en langage naturel et retourner une réponse appropriée.
Ces capacités et bien d’autres encore sont prises en charge par les modèles du service Azure AI Language, que nous explorerons plus loin.