CREATE EXTERNAL TABLE (Transact-SQL)
Crée une table externe.
Cet article fournit la syntaxe, les arguments, les notes, les autorisations et des exemples associés au produit SQL que vous choisissez.
Pour plus d’informations sur les conventions de la syntaxe, consultez Conventions de la syntaxe Transact-SQL.
Sélectionner un produit
Sur la ligne suivante, sélectionnez le nom du produit qui vous intéresse afin d’afficher uniquement les informations qui le concernent.
* SQL Server *
Présentation : SQL Server
Cette commande crée une table externe pour PolyBase, afin d’accéder à des données stockées dans un cluster Hadoop ou dans une table externe PolyBase Stockage Blob Azure qui fait référence à des données stockées dans un cluster Hadoop ou Stockage Blob Azure.
S’applique à : SQL Server 2016 (ou versions ultérieures)
Utilisez une table externe avec une source de données externe pour les requêtes PolyBase. Des sources de données externes sont utilisées pour établir la connectivité et prendre en charge ces principaux cas d’utilisation :
- Virtualisation des données et chargement des données à l’aide de PolyBase
- Opérations de chargement en masse à l’aide de SQL Server ou SQL Database avec
BULK INSERTouOPENROWSET
Voir aussi CREATE EXTERNAL DATA SOURCE et DROP EXTERNAL TABLE.
Syntaxe
-- Create a new external table
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'folder_or_filepath',
DATA_SOURCE = external_data_source_name,
[ FILE_FORMAT = external_file_format_name ]
[ , <reject_options> [ ,...n ] ]
)
[;]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage
| REJECT_VALUE = reject_value
| REJECT_SAMPLE_VALUE = reject_sample_value,
| REJECTED_ROW_LOCATION = '/REJECT_Directory'
}
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
Arguments
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
Nom (composé d’une à trois parties) de la table à créer. Pour une table externe, SQL stocke uniquement les métadonnées de la table avec des statistiques de base sur le fichier ou le dossier qui est référencé dans Hadoop ou Stockage Blob Azure. Aucune donnée n’est déplacée ni stockée dans SQL Server.
Important
Pour des performances optimales, si le pilote de source de données externe prend en charge un nom en trois parties, il est fortement recommandé de fournir ce nom en trois parties.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE prend en charge la possibilité de configurer le nom de colonne, le type de données, la possibilité d’une valeur Null et le classement. Vous ne pouvez pas utiliser DEFAULT CONSTRAINT sur des tables externes.
Les définitions de colonne, notamment les types de données et le nombre de colonnes, doivent correspondre aux données des fichiers externes. En cas de non-correspondance, les lignes du fichier sont rejetées lors de l’interrogation des données réelles.
LOCATION = 'folder_or_filepath'
Spécifie le dossier ou le chemin et le nom du fichier où se trouvent les données dans Hadoop ou Stockage Blob Azure. En outre, le stockage d’objets compatible S3 est pris en charge à partir de SQL Server 2022 (16.x). L’emplacement commence au dossier racine. Le dossier racine est l’emplacement de données qui est spécifié dans la source de données externe.
Dans SQL Server, l’instruction CREATE EXTERNAL TABLE crée le chemin et le dossier s’ils n’existent pas déjà. Vous pouvez ensuite utiliser INSERT INTO pour exporter les données d’une table SQL Server locale dans la source de données externe. Pour plus d’informations, consultez Requêtes PolyBase.
Si vous spécifiez LOCATION comme étant un dossier, une requête PolyBase qui sélectionne des données dans la table externe récupère les fichiers dans le dossier et dans tous ses sous-dossiers. Tout comme Hadoop, PolyBase ne retourne pas les dossiers masqués. Il ne retourne pas non plus les fichiers dont le nom commence par un trait de soulignement (_) ou un point (.).
Dans l’exemple d’image suivant, si LOCATION='/webdata/', une requête PolyBase retourne des lignes de mydata.txt et mydata2.txt. Elle ne retourne pas mydata3.txt, car ce fichier se trouve dans un sous-dossier masqué. Elle ne retourne pas non plus _hidden.txt car il s’agit d’un fichier masqué.
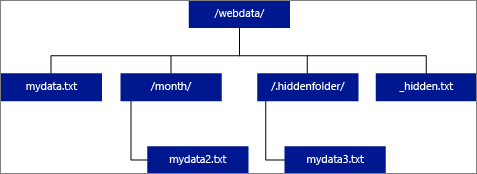
Pour modifier la valeur par défaut et uniquement lire les données du dossier racine, définissez l’attribut <polybase.recursive.traversal>sur 'false' dans le fichier de configuration core-site.xml. Ce fichier se trouve sous <SqlBinRoot>\PolyBase\Hadoop\Conf sous la racine bin de SQL Server. Par exemple : C:\Program Files\Microsoft SQL Server\MSSQL13.XD14\MSSQL\Binn.
DATA_SOURCE = external_data_source_name
Spécifie le nom de la source de données externe contenant l’emplacement des données externes. Cet emplacement est un système de fichiers Hadoop (HDFS), un conteneur Stockage Blob Azure ou Azure Data Lake Store. Pour créer une source de données externe, utilisez CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Spécifie le nom de l’objet de format de fichier externe qui stocke le type de fichier et la méthode de compression pour les données externes. Pour créer un format de fichier externe, utilisez CREATE EXTERNAL FILE FORMAT.
Les formats de fichiers externes peuvent être réutilisés par plusieurs fichiers externes similaires.
Options REJECT
Cette option peut être utilisée uniquement avec des sources de données externes où TYPE = HADOOP.
Vous pouvez spécifier les paramètres REJECT qui déterminent la façon dont PolyBase traite les enregistrements incorrects qu’il récupère à partir de la source de données externe. Un enregistrement de données est considéré comme « incorrect » si les types de données ou le nombre de colonnes ne correspondent pas aux définitions de colonnes de la table externe.
Si vous ne spécifiez pas ou ne changez pas les valeurs REJECT, PolyBase utilise les valeurs par défaut. Ces informations sur les paramètres REJECT sont stockées en tant que métadonnées supplémentaires lorsque vous créez une table externe avec l’instruction CREATE EXTERNAL TABLE. Quand une prochaine instruction SELECT ou SELECT INTO SELECT sélectionne des données dans la table externe, PolyBase utilise les options REJECT pour déterminer le nombre ou le pourcentage de lignes pouvant être rejetées avant de provoquer l’échec de la requête. La requête retourne des résultats (partiels) jusqu’à ce que le seuil de rejet soit dépassé. Ensuite, elle échoue avec le message d’erreur correspondant.
REJECT_TYPE = value | percentage
Précise si l’option REJECT_VALUE est spécifiée comme une valeur littérale ou un pourcentage.
value
REJECT_VALUE est une valeur littérale, et non un pourcentage. La requête échoue lorsque le nombre de lignes rejetées dépasse la valeur reject_value.
Par exemple, si REJECT_VALUE = 5 et REJECT_TYPE = value, la requête SELECT échoue au bout de cinq lignes rejetées.
percentage
REJECT_VALUE est un pourcentage, et non une valeur littérale. Une requête échoue lorsque le pourcentage de lignes ayant échoué dépasse la valeur reject_value. Le pourcentage de lignes ayant échoué est calculé à intervalles.
REJECT_VALUE = reject_value
Spécifie la valeur ou le pourcentage de lignes pouvant être rejetées avant de provoquer l’échec de la requête.
Pour REJECT_TYPE = value, reject_value doit être un entier compris entre 0 et 2 147 483 647.
Pour REJECT_TYPE = percentage, reject_value doit être une valeur float comprise entre 0 et 100.
REJECT_SAMPLE_VALUE = reject_sample_value
Cet attribut est nécessaire lorsque vous spécifiez REJECT_TYPE = percentage. Il détermine le nombre de lignes à tenter de récupérer avant que PolyBase ne recalcule le pourcentage de lignes rejetées.
Le paramètre reject_sample_value doit être un entier compris entre 0 et 2 147 483 647.
Par exemple, si REJECT_SAMPLE_VALUE = 1000, PolyBase calcule le pourcentage de lignes ayant échoué après avoir tenté d’importer 1000 lignes à partir du fichier de données externe. Si le pourcentage de lignes ayant échoué est inférieur à la valeur de reject_value, PolyBase tente de récupérer 1000 autres lignes. Il continue de recalculer le pourcentage de lignes ayant échoué après avoir tenté d’importer chacune des 1000 lignes supplémentaires.
Notes
Étant donné que PolyBase calcule le pourcentage de lignes ayant échoué à intervalles, le pourcentage de lignes ayant échoué peut dépasser la valeur de reject_value.
Exemple :
Cet exemple montre comment les trois options REJECT interagissent les unes avec les autres. Par exemple, si REJECT_TYPE = percentage, REJECT_VALUE = 30 et REJECT_SAMPLE_VALUE = 100, le scénario suivant peut se produire :
- PolyBase tente de récupérer les 100 premières lignes : la récupération échoue pour 25 d’entre elles, et réussit pour les 75 autres.
- Le pourcentage de lignes ayant échoué qui est obtenu est de 25 %, ce qui est inférieur à la valeur de rejet de 30 %. Par conséquent, PolyBase va continuer de récupérer les données à partir de la source de données externe.
- PolyBase tente de charger les 100 lignes suivantes. Cette fois-ci, le chargement réussit pour 25 lignes et échoue pour les 75 autres.
- Le pourcentage de lignes ayant échoué est recalculé et on obtient 50 %. Le pourcentage de lignes ayant échoué a donc dépassé la valeur de rejet de 30 %.
- La requête PolyBase échoue après le rejet de 50 % des 200 premières lignes qu’elle a tenté de retourner. Notez que les lignes correspondantes sont retournées avant que la requête PolyBase ne détecte que le seuil de rejet a été dépassé.
REJECTED_ROW_LOCATION = Emplacement de répertoire
S’applique à : SQL Server 2019 CU6 (et versions ultérieures) et Azure Synapse Analytics.
Spécifie le répertoire dans la Source de données externe dans lequel les lignes rejetées et le fichier d’erreur correspondant doivent être écrits.
Si le chemin spécifié n’existe pas, PolyBase en crée un en votre nom. Un répertoire enfant est créé sous le nom « _rejectedrows ». Le caractère « _ » garantit que le répertoire est placé dans une séquence d’échappement pour le traitement d’autres données, sauf s’il est explicitement nommé dans le paramètre d’emplacement. Dans ce répertoire se trouve un dossier créé d’après l’heure de soumission du chargement au format YearMonthDay -HourMinuteSecond (par exemple 20230330-173205). Dans ce dossier, deux types de fichiers sont écrits : le fichier _reason (raison) et le fichier de données. Cette option peut être utilisée uniquement avec des sources de données externes où TYPE = HADOOP et pour des tables externes avec DELIMITEDTEXT FORMAT_TYPE. Pour plus d’informations, consultez CREATE EXTERNAL DATA SOURCE et CREATE EXTERNAL FILE FORMAT.
Les fichiers de raison et les fichiers de données ont tous deux le queryID associé à l’instruction CTAS. Comme les données et la raison se trouvent dans des fichiers distincts, les fichiers correspondants ont un suffixe analogue.
Autorisations
Nécessite les autorisations utilisateur suivantes :
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT (s’applique uniquement aux sources de données externes Hadoop et Stockage Azure)
- CONTROL DATABASE (s’applique uniquement aux sources de données externes Hadoop et Stockage Azure)
Notez que la connexion distante spécifiée dans les informations d’identification DATABASE SCOPED utilisées dans la commande CREATE EXTERNAL TABLE doit disposer d’une autorisation en lecture pour le chemin/la table/la collection sur la source de données externe spécifiée dans le paramètre LOCATION. Si vous envisagez d’utiliser cette TABLE EXTERNE pour exporter des données vers une source de données externe Hadoop ou Stockage Azure, la connexion spécifiée doit disposer d’une autorisation en écriture sur le chemin spécifié dans LOCATION. Notez que Hadoop n’est actuellement pas pris en charge dans SQL Server 2022 (16.x).
Pour Stockage Blob Azure, lors de la configuration des clés d’accès et de la signature d’accès partagé (SAP) dans le portail Azure, les comptes de stockage Stockage Blob Azure ou ADLS Gen2, configurez les autorisations acceptées pour octroyer au moins des autorisations enlecture et en écriture. L’autorisation de liste peut également être requise en cas de recherche dans plusieurs dossiers. Vous devez également sélectionner Conteneur et Objet comme types de ressources autorisés.
Important
L’autorisation ALTER ANY EXTERNAL DATA SOURCE accorde à n’importe quel principal la possibilité de créer et de modifier tout objet de source de données externe. Par conséquent, elle permet également d’accéder à toutes les informations d’identification délimitées à la base de données. Cette autorisation doit être considérée comme fournissant des privilèges très élevés, et doit donc être accordée uniquement aux principaux de confiance du système.
Gestion des erreurs
Lors de l’exécution de l’instruction CREATE EXTERNAL TABLE, PolyBase tente de se connecter à la source de données externe. Si la tentative de connexion échoue, l’instruction échoue et la table externe n’est pas créée. L’échec de la commande peut prendre plusieurs minutes, car PolyBase tente plusieurs connexions avant que la requête n’échoue.
Remarques
Dans les scénarios de requête ad hoc, comme SELECT FROM EXTERNAL TABLE, PolyBase stocke les lignes qui sont récupérées de la source de données externe dans une table temporaire. Une fois la requête terminée, PolyBase supprime la table temporaire. Aucune donnée permanente n’est stockée dans les tables SQL.
En revanche, dans le scénario d’importation, comme avec SELECT INTO FROM EXTERNAL TABLE, PolyBase stocke les lignes qui sont extraites de la source de données externe sous forme de données permanentes dans la table SQL. La nouvelle table est créée lors de l’exécution de la requête, au moment où PolyBase récupère les données externes.
PolyBase peut envoyer (push) une partie du calcul des requêtes vers Hadoop pour améliorer les performances des requêtes. Cette action est appelée « poussée de prédicats ». Pour l’activer, spécifiez l’option d’emplacement du Gestionnaire de ressources Hadoop dans CREATE EXTERNAL DATA SOURCE.
Vous pouvez créer plusieurs tables externes qui référencent les mêmes sources de données externes ou des sources différentes.
Limitations et restrictions
Dans la mesure où les données d’une table externe ne sont pas sous le contrôle de gestion direct de SQL Server, elles peuvent être changées ou supprimées à tout moment par un processus externe. Par conséquent, il n’est pas garanti que les résultats d’une requête exécutée sur une table externe soient déterministes. La même requête peut retourner des résultats différents chaque fois qu’elle est exécutée sur une table externe. De même, une requête peut échouer si les données externes sont déplacées ou supprimées.
Vous pouvez créer plusieurs tables externes qui référencent chacune des sources de données externes différentes. Si vous exécutez simultanément plusieurs requêtes sur des sources de données Hadoop différentes, chaque source Hadoop doit utiliser le même paramètre de configuration de serveur « hadoop connectivity » (connectivité Hadoop). Par exemple, vous ne pouvez pas exécuter simultanément une requête sur un cluster Hadoop Cloudera et sur un cluster Hadoop Hortonworks, puisqu’ils utilisent des paramètres de configuration différents. Pour connaître les paramètres de configuration et les combinaisons prises en charge, consultez Configuration de la connectivité PolyBase.
Lorsque la table externe utilise DELIMITEDTEXT, CSV, PARQUET ou DELTA en tant que types de données, les tables externes prennent uniquement en charge les statistiques d’une colonne par commande CREATE STATISTICS.
Seules les instructions DDL suivantes sont autorisées avec les tables externes :
- CREATE TABLE et DROP TABLE
- CREATE STATISTICS et DROP STATISTICS
- CREATE VIEW et DROP VIEW
Les constructions et les opérations suivantes ne sont pas prises en charge :
- La contrainte DEFAULT sur les colonnes de table externe
- Les opérations DML delete, insert et update
Limitations des requêtes
PolyBase peut consommer un maximum de 33 000 fichiers par dossier lors de l’exécution simultanée de 32 requêtes PolyBase. Ce nombre maximal inclut les fichiers et les sous-dossiers de chaque dossier HDFS. Si le degré de concurrence est inférieur à 32, un utilisateur peut exécuter des requêtes PolyBase sur des dossiers dans des systèmes HDFS contenant plus de 33 000 fichiers. Il est recommandé de raccourcir au maximum les chemins de fichiers externes et de ne pas utiliser plus de 30 000 fichiers par dossier HDFS. Lorsque trop de fichiers sont référencés, une exception d’insuffisance de mémoire Java Virtual Machine (JVM) peut être levée.
Limitations concernant la largeur des tables
Dans SQL Server 2016, PolyBase a une limite de largeur de ligne de 32 Ko, basée sur la taille maximale d’une ligne valide par définition de table. Si la somme du schéma de colonne est supérieure à 32 Ko, PolyBase ne peut pas interroger les données.
Limitations des types de données
Les types de données suivants ne peuvent pas être utilisés dans des tables externes Polybase :
geographygeometryhierarchyidimagetextnTextxml- Tout type défini par l’utilisateur
Limitations propres à la source de données
Oracle
L’utilisation de synonymes Oracle avec PolyBase n’est pas prise en charge.
Tables externes aux collections MongoDB qui contiennent des tableaux
Pour créer des tables externes dans des collections MongoDB qui contiennent des tableaux, vous devez utiliser l’extension de virtualisation des données pour Azure Data Studio afin de produire une instruction CREATE EXTERNAL TABLE basée sur le schéma détecté par le pilote ODBC PolyBase pour MongoDB. Les actions d’aplatissement sont effectuées automatiquement par le pilote. Vous pouvez également utiliser sp_data_source_objects (Transact-SQL) pour détecter le schéma de collection (colonnes) et créer manuellement la table externe. La procédure stockée sp_data_source_table_columns effectue également automatiquement l’aplatissement via le pilote ODBC PolyBase pour MongoDB. L’extension de virtualisation des données pour Azure Data Studio et sp_data_source_table_columns utilise les mêmes procédures stockées internes pour interroger le schéma externe.
Verrouillage
Verrou partagé sur l’objet SCHEMARESOLUTION.
Sécurité
Les fichiers de données d’une table externe sont stockés dans Hadoop ou Stockage Blob Azure. Ces fichiers de données sont créés et gérés par vos propres processus. Il vous incombe de gérer la sécurité des données externes.
Exemples
R. Créer une table externe avec des données au format texte délimité
Cet exemple montre toutes les étapes nécessaires à la création d’une table externe dont les données sont des fichiers de texte délimité. Il définit la source de données externe mydatasource et le format de fichier externe myfileformat. Ces objets de niveau base de données sont ensuite référencés dans l’instruction CREATE EXTERNAL TABLE. Pour plus d’informations, consultez CREATE EXTERNAL DATA SOURCE et CREATE EXTERNAL FILE FORMAT.
CREATE EXTERNAL DATA SOURCE mydatasource
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat
WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS (FIELD_TERMINATOR ='|')
);
CREATE EXTERNAL TABLE ClickStream (
url varchar(50),
event_date date,
user_IP varchar(50)
)
WITH (
LOCATION='/webdata/employee.tbl',
DATA_SOURCE = mydatasource,
FILE_FORMAT = myfileformat
)
;
B. Créer une table externe avec des données au format RCFile
Cet exemple montre toutes les étapes nécessaires à la création d’une table externe contenant des données au format RCFile. Il définit la source de données externe mydatasource_rc et le format de fichier externe myfileformat_rc. Ces objets de niveau base de données sont ensuite référencés dans l’instruction CREATE EXTERNAL TABLE. Pour plus d’informations, consultez CREATE EXTERNAL DATA SOURCE et CREATE EXTERNAL FILE FORMAT.
CREATE EXTERNAL DATA SOURCE mydatasource_rc
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat_rc
WITH (
FORMAT_TYPE = RCFILE,
SERDE_METHOD = 'org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe'
)
;
CREATE EXTERNAL TABLE ClickStream_rc (
url varchar(50),
event_date date,
user_ip varchar(50)
)
WITH (
LOCATION='/webdata/employee_rc.tbl',
DATA_SOURCE = mydatasource_rc,
FILE_FORMAT = myfileformat_rc
)
;
C. Créer une table externe avec des données au format ORC
Cet exemple montre toutes les étapes nécessaires à la création d’une table externe contenant des données au format ORC. Il définit une source de données externe, mydatasource_orc, et un format de fichier externe, myfileformat_orc. Ces objets de niveau base de données sont ensuite référencés dans l’instruction CREATE EXTERNAL TABLE. Pour plus d’informations, consultez CREATE EXTERNAL DATA SOURCE et CREATE EXTERNAL FILE FORMAT.
CREATE EXTERNAL DATA SOURCE mydatasource_orc
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat_orc
WITH (
FORMAT = ORC,
COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
;
CREATE EXTERNAL TABLE ClickStream_orc (
url varchar(50),
event_date date,
user_ip varchar(50)
)
WITH (
LOCATION='/webdata/',
DATA_SOURCE = mydatasource_orc,
FILE_FORMAT = myfileformat_orc
)
;
D. Interroger des données Hadoop
ClickStream est une table externe qui se connecte au fichier texte délimité employee.tbl dans un cluster Hadoop. La requête suivante ressemble à une requête exécutée sur une table standard. Toutefois, cette requête récupère les données dans Hadoop, puis calcule les résultats.
SELECT TOP 10 (url) FROM ClickStream WHERE user_ip = 'xxx.xxx.xxx.xxx';
E. Joindre des données Hadoop à des données SQL
Cette requête ressemble à une requête JOIN standard exécutée sur deux tables SQL. La différence réside dans le fait que PolyBase récupère les données clickStream dans Hadoop, puis les joint à la table UrlDescription. L’une des tables est une table externe, et l’autre est une table SQL standard.
SELECT url.description
FROM ClickStream cs
JOIN UrlDescription url ON cs.url = url.name
WHERE cs.url = 'msdn.microsoft.com';
F. Importer des données Hadoop dans une table SQL
Cet exemple crée une table SQL, ms_user, qui stocke de façon permanente le résultat d’une jointure entre la table SQL standard user et la table externe ClickStream.
SELECT DISTINCT user.FirstName, user.LastName
INTO ms_user
FROM user INNER JOIN (
SELECT * FROM ClickStream WHERE cs.url = 'www.microsoft.com'
) AS ms
ON user.user_ip = ms.user_ip;
G. Créer une table externe pour SQL Server
Avant la création d’informations d’identification délimitées à la base de données, la base de données utilisateur doit avoir une clé principale pour protéger les informations d’identification. Pour plus d’informations, consultez CREATE MASTER KEY et CREATE DATABASE SCOPED CREDENTIAL.
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'S0me!nfo';
GO
/* specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL SqlServerCredentials
WITH IDENTITY = 'username', Secret = 'password';
GO
Créez une source de données externe nommée SQLServerInstance et une table externe nommée sqlserver.customer :
/* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE SQLServerInstance
WITH (
LOCATION = 'sqlserver://SqlServer',
-- PUSHDOWN = ON | OFF,
CREDENTIAL = SQLServerCredentials
);
GO
CREATE SCHEMA sqlserver;
GO
/* LOCATION: sql server table/view in 'database_name.schema_name.object_name' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE sqlserver.customer(
C_CUSTKEY INT NOT NULL,
C_NAME VARCHAR(25) NOT NULL,
C_ADDRESS VARCHAR(40) NOT NULL,
C_NATIONKEY INT NOT NULL,
C_PHONE CHAR(15) NOT NULL,
C_ACCTBAL DECIMAL(15,2) NOT NULL,
C_MKTSEGMENT CHAR(10) NOT NULL,
C_COMMENT VARCHAR(117) NOT NULL
)
WITH (
LOCATION='tpch_10.dbo.customer',
DATA_SOURCE=SqlServerInstance
);
I. Créer une table externe pour Oracle
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/*
* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = 'oracle://<server address>[:<port>]',
-- PUSHDOWN = ON | OFF,
CREDENTIAL = credential_name)
/*
* LOCATION: Oracle table/view in '<database_name>.<schema_name>.<object_name>' format. Note this may be case sensitive in the Oracle database.
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customers(
[O_ORDERKEY] DECIMAL(38) NOT NULL,
[O_CUSTKEY] DECIMAL(38) NOT NULL,
[O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL,
[O_TOTALPRICE] DECIMAL(15,2) NOT NULL,
[O_ORDERDATE] DATETIME2(0) NOT NULL,
[O_ORDERPRIORITY] CHAR(15) COLLATE Latin1_General_BIN NOT NULL,
[O_CLERK] CHAR(15) COLLATE Latin1_General_BIN NOT NULL,
[O_SHIPPRIORITY] DECIMAL(38) NOT NULL,
[O_COMMENT] VARCHAR(79) COLLATE Latin1_General_BIN NOT NULL
)
WITH (
LOCATION='DB1.mySchema.customer',
DATA_SOURCE= external_data_source_name
);
J. Créer une table externe pour Teradata
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = teradata://<server address>[:<port>],
-- PUSHDOWN = ON | OFF,
CREDENTIAL =credential_name
);
/* LOCATION: Teradata table/view in '<database_name>.<object_name>' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customer(
L_ORDERKEY INT NOT NULL,
L_PARTKEY INT NOT NULL,
L_SUPPKEY INT NOT NULL,
L_LINENUMBER INT NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR NOT NULL,
L_LINESTATUS CHAR NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL
)
WITH (
LOCATION='customer',
DATA_SOURCE= external_data_source_name
);
K. Créer une table externe pour MongoDB
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/* LOCATION: Location string should be of format '<type>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = mongodb://<server>[:<port>],
-- PUSHDOWN = ON | OFF,
CREDENTIAL = credential_name
);
/* LOCATION: MongoDB table/view in '<database_name>.<schema_name>.<object_name>' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customers(
[O_ORDERKEY] DECIMAL(38) NOT NULL,
[O_CUSTKEY] DECIMAL(38) NOT NULL,
[O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL,
[O_TOTALPRICE] DECIMAL(15,2) NOT NULL,
[O_ORDERDATE] DATETIME2(0) NOT NULL,
[O_COMMENT] VARCHAR(79) COLLATE Latin1_General_BIN NOT NULL
)
WITH (
LOCATION='customer',
DATA_SOURCE= external_data_source_name
);
L. Interroger le stockage d’objets compatible S3 via une table externe
S’applique à : SQL Server 2022 (16.x) et versions ultérieures
L’exemple suivant illustre l’utilisation de T-SQL pour interroger un fichier parquet stocké dans un stockage d’objets compatible S3 via l’interrogation d’une table externe. L’exemple utilise un chemin relatif dans la source de données externe.
CREATE EXTERNAL DATA SOURCE s3_ds
WITH
( LOCATION = 's3://<ip_address>:<port>/'
, CREDENTIAL = s3_dc
);
GO
CREATE EXTERNAL FILE FORMAT ParquetFileFormat WITH(FORMAT_TYPE = PARQUET);
GO
CREATE EXTERNAL TABLE Region(
r_regionkey BIGINT,
r_name CHAR(25),
r_comment VARCHAR(152) )
WITH (LOCATION = '/region/', DATA_SOURCE = 's3_ds',
FILE_FORMAT = ParquetFileFormat);
GO
Étapes suivantes
En savoir plus sur les concepts associés dans les articles suivants :
* Azure SQL Database *
Présentation : Azure SQL Database
Dans Azure SQL Database, une table externe est créée pour les requêtes élastiques (en préversion).
Voir également CRÉER UNE SOURCE DE DONNÉES EXTERNES.
Syntaxe
-- Create a table for use with elastic query
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH ( <sharded_external_table_options> )
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<sharded_external_table_options> ::=
DATA_SOURCE = external_data_source_name,
SCHEMA_NAME = N'nonescaped_schema_name',
OBJECT_NAME = N'nonescaped_object_name',
[DISTRIBUTION = SHARDED(sharding_column_name) | REPLICATED | ROUND_ROBIN]]
)
[;]
Arguments
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
Nom (composé d’une à trois parties) de la table à créer. Pour une table externe, SQL stocke uniquement les métadonnées de la table avec des statistiques de base sur le fichier ou le dossier qui est référencé dans Azure SQL Database. Aucune donnée n’est déplacée ni stockée dans Azure SQL Database.
Important
Pour des performances optimales, si le pilote de source de données externe prend en charge un nom en trois parties, il est fortement recommandé de fournir ce nom en trois parties.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE prend en charge la possibilité de configurer le nom de colonne, le type de données, la possibilité d’une valeur Null et le classement. Vous ne pouvez pas utiliser DEFAULT CONSTRAINT sur des tables externes.
Notes
Text, nText etXML ne sont pas des types de données pris en charge pour les colonnes de tables externes dans Azure SQL Database.
Les définitions de colonne, notamment les types de données et le nombre de colonnes, doivent correspondre aux données des fichiers externes. En cas de non-correspondance, les lignes du fichier sont rejetées lors de l’interrogation des données réelles.
Options de table externe partitionnée
Spécifie la source de données externe (source de données non-SQL Server) et une méthode de distribution pour la requête élastique.
DATA_SOURCE
La clause DATA_SOURCE définit la source de données externe (une carte de partitions) utilisée pour la table externe. Pour obtenir un exemple, consultez Créer des tables externes.
Important
Azure SQL Database prend en charge la création de tables externes dans les types de sources de données externes RDMS et SHARD_MAP_MANAGER, Azure SQL Database ne prend pas en charge la création de tables externes dans Stockage Blob Azure.
SCHEMA_NAME et OBJECT_NAME
Les clauses SCHEMA_NAME et OBJECT_NAME mappent la définition de table externe à une table dans un schéma différent. En cas d’omission, le schéma de l’objet distant est supposé être « dbo » et son nom est supposé être identique au nom de la table externe en cours de définition. Ceci est particulièrement utile si le nom de votre table distante est déjà utilisé dans la base de données dans laquelle vous souhaitez créer la table externe. Par exemple, vous souhaitez définir une table externe pour obtenir une vue agrégée des affichages de catalogue ou de vues de gestion dynamiques sur la couche des données mise à l’échelle. Dans la mesure où les affichages catalogue et les vues de gestion dynamique existent déjà localement, vous ne pouvez pas utiliser leur nom pour la définition de la table externe. Vous devez utiliser un autre nom ainsi que le nom de la vue de catalogue ou de la vue de gestion dynamique dans les clauses SCHEMA_NAME et/ou OBJECT_NAME. Pour obtenir un exemple, consultez Créer des tables externes.
DISTRIBUTION
facultatif. Cet argument est obligatoire uniquement pour les bases de données de type SHARD_MAP_MANAGER. Cet argument contrôle si une table est traitée comme une table shardée ou une table répliquée. Avec les tables SHARDED (nom de colonne), les données des différentes tables ne se chevauchent pas. REPLICATED spécifie que les tables contiennent les mêmes données sur chaque partition. ROUND_ROBIN indique qu’une méthode spécifique à l’application est utilisée pour distribuer les données.
La clause DISTRIBUTION spécifie la distribution des données utilisée pour cette table. Le processeur de requêtes utilise les informations fournies dans la clause DISTRIBUTION pour créer les plans de requête les plus efficaces.
- SHARDED signifie que les données sont partitionnées horizontalement entre les bases de données. La clé de partitionnement pour la distribution des données figure dans le paramètre
sharding_column_name. - REPLICATED signifie que des copies identiques de la table sont présentes sur chaque base de données. La responsabilité de vous assurer que les réplicas sont identiques d’une base de données à l’autre vous incombe.
- ROUND_ROBIN signifie que la table est partitionnée horizontalement à l’aide d’une méthode de distribution liée à l’application.
Autorisations
Les utilisateurs ayant accès à la table externe acquièrent un accès automatique aux tables distantes sous-jacentes avec les informations d’identification fournies dans la définition de source de données externe. Évitez une élévation de privilèges non souhaitée par le biais d’informations d'identification de la source de données externe. Utilisez GRANT ou REVOKE pour une table externe, comme s'il s'agissait d'une table standard. Une fois votre table externe et votre source de données externe définies, vous pouvez utiliser l’ensemble T-SQL complet sur vos tables externes.
Gestion des erreurs
Lors de l’exécution de l’instruction CREATE EXTERNAL TABLE, si la tentative de connexion échoue, l’instruction échoue et la table externe n’est pas créée. L’échec de la commande peut prendre plusieurs minutes, car SQL Database tente plusieurs connexions avant que la requête n’échoue.
Remarques
Dans les scénarios de requête ad hoc, comme SELECT FROM EXTERNAL TABLE, SQL Database stocke les lignes qui sont récupérées de la source de données externe dans une table temporaire. Une fois la requête terminée, SQL Database supprime la table temporaire. Aucune donnée permanente n’est stockée dans les tables SQL.
En revanche, dans le scénario d’importation, comme avec SELECT INTO FROM EXTERNAL TABLE, SQL Database stocke les lignes qui sont extraites de la source de données externe sous forme de données permanentes dans la table SQL. La nouvelle table est créée lors de l’exécution de la requête, au moment où SQL Database récupère les données externes.
Vous pouvez créer plusieurs tables externes qui référencent les mêmes sources de données externes ou des sources différentes.
Vous pouvez créer plusieurs tables externes qui référencent chacune des sources de données externes différentes.
Limitations
sémantique d’isolation: l’accès aux données via une table externe n’est pas conforme à la sémantique d’isolation dans SQL Server. Cela signifie que l’interrogation d’une table externe n’impose aucune isolation de verrouillage ou d’instantané. Par conséquent, le retour de données peut changer si les données de la source de données externe changent. La même requête peut retourner des résultats différents chaque fois qu’elle est exécutée sur une table externe. De même, une requête peut échouer si les données externes sont déplacées ou supprimées.
Constructions et opérations non prises en charge:
- La contrainte DEFAULT sur les colonnes de table externe.
- Les opérations DML delete, insert et update.
- Dynamic Data Masking sur les colonnes de table externe.
- Les curseurs ne sont pas pris en charge pour les tables externes dans Azure SQL Database.
Seuls les prédicats littéraux: seuls les prédicats littéraux définis dans une requête peuvent être poussés vers la source de données externe. Cela diffère des serveurs liés et de l’accès où les prédicats définis au moment de l’exécution de la requête peuvent être utilisés, c’est-à-dire quand ils sont utilisés avec une boucle imbriquée dans un plan de requête. Cela conduit souvent à la copie locale de l’ensemble de la table externe, puis à la jointure.
Dans l’exemple suivant, si
External.Ordersest une table externe etCustomerest une table locale, la requête copie la table externe entière localement, car le prédicat nécessaire n’est pas connu au moment de la compilation.SELECT Orders.OrderId, Orders.OrderTotal FROM External.Orders WHERE CustomerId IN ( SELECT TOP 1 CustomerId FROM Customer WHERE CustomerName = 'MyCompany' );Aucun parallélisme: l’utilisation de tables externes empêche l’utilisation du parallélisme dans le plan de requête.
exécuté en tant que requête distante: les tables externes sont implémentées en tant que requête distante, de sorte que le nombre estimé de lignes retournées est généralement de 1 000. Il existe d’autres règles basées sur le type de prédicat utilisé pour filtrer la table externe. Il s’agit d’estimations basées sur des règles au lieu d’estimations basées sur les données réelles contenues dans la table externe. L’optimiseur n’accède pas à la source de données distante pour obtenir une estimation plus précise.
Non pris en charge pour lesde point de terminaison privé : les requêtes de table externe ne sont pas prises en charge lorsque la connexion à une table distante est un point de terminaison privé.
Limitations des types de données
Les types de données suivants ne peuvent pas être utilisés dans des tables externes Polybase :
geographygeometryhierarchyidimagetextnTextxml- Tout type défini par l’utilisateur
Verrouillage
Verrou partagé sur l’objet SCHEMARESOLUTION.
Exemples
R. Créer une table externe pour Azure SQL Database
CREATE EXTERNAL TABLE [dbo].[CustomerInformation]
( [CustomerID] [int] NOT NULL,
[CustomerName] [varchar](50) NOT NULL,
[Company] [varchar](50) NOT NULL)
WITH
( DATA_SOURCE = MyElasticDBQueryDataSrc)
B. Créer une table externe pour une source de données partitionnée
Cet exemple remappe une vue de gestion dynamique à distance vers une table externe à l’aide des clauses SCHEMA_NAME et OBJECT_NAME.
CREATE EXTERNAL TABLE [dbo].[all_dm_exec_requests]([session_id] smallint NOT NULL,
[request_id] int NOT NULL,
[start_time] datetime NOT NULL,
[status] nvarchar(30) NOT NULL,
[command] nvarchar(32) NOT NULL,
[sql_handle] varbinary(64),
[statement_start_offset] int,
[statement_end_offset] int,
[cpu_time] int NOT NULL)
WITH
(
DATA_SOURCE = MyExtSrc,
SCHEMA_NAME = 'sys',
OBJECT_NAME = 'dm_exec_requests',
DISTRIBUTION=ROUND_ROBIN
);
Étapes suivantes
En savoir plus sur les tables externes dans Azure SQL Database dans les articles suivants :
* Azure Synapse
Analytics *
Présentation : Azure Synapse Analytics
Utilisez une table externe pour :
- Les pools SQL dédiés peuvent interroger, importer et stocker des données à partir de Hadoop, du Stockage Blob Azure et d’Azure Data Lake Storage Gen1 et Gen2.
- Les pools SQL serverless peuvent interroger, importer et stocker des données à partir du Stockage Blob Azure et d’Azure Data Lake Storage Gen1 et Gen2. Le serverless ne prend pas en charge
TYPE=Hadoop.
Voir aussi CREATE EXTERNAL DATA SOURCE et DROP EXTERNAL TABLE.
Pour obtenir des instructions et des exemples sur l'utilisation de tables externes avec Azure Synapse, consultez Utiliser des tables externes avec Synapse SQL.
Syntaxe
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'hdfs_folder_or_filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ ,...n ] ]
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage,
| REJECT_VALUE = reject_value,
| REJECT_SAMPLE_VALUE = reject_sample_value,
| REJECTED_ROW_LOCATION = '/REJECT_Directory'
}
Arguments
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
Nom (composé d’une à trois parties) de la table à créer. Pour une table externe, uniquement les métadonnées de la table avec des statistiques de base sur le fichier ou le dossier qui sont référencées dans Azure Data Lake, Hadoop ou Stockage Blob Azure. Aucune donnée réelle n’est déplacée ni stockée lors de la création de tables externes.
Important
Pour des performances optimales, si le pilote de source de données externe prend en charge un nom en trois parties, il est fortement recommandé de fournir ce nom en trois parties.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE prend en charge la possibilité de configurer le nom de colonne, le type de données, la possibilité d’une valeur Null et le classement. Vous ne pouvez pas utiliser DEFAULT CONSTRAINT sur des tables externes.
Notes
Les types de données dépréciés text, ntext et XML ne sont pas pris en charge pour les colonnes des tables externes dans Synapse Analytics.
- Pour la lecture de fichiers délimités, les définitions de colonnes (notamment les types de données et le nombre de colonnes) doivent correspondre aux données des fichiers externes. En cas de non-correspondance, les lignes du fichier sont rejetées lors de l’interrogation des données réelles.
- Lors de la lecture à partir de fichiers Parquet, vous pouvez spécifier uniquement les colonnes que vous souhaitez lire et ignorer le reste.
LOCATION = 'folder_or_filepath'
Spécifie le dossier ou le chemin et le nom du fichier, où se trouvent les données réelles dans Azure Data Lake, Hadoop ou le Stockage Blob Azure. L’emplacement commence au dossier racine. Le dossier racine est l’emplacement de données qui est spécifié dans la source de données externe. L’instruction CREATE EXTERNAL TABLE AS SELECT crée le chemin et le dossier s’ils n’existent pas.
CREATE EXTERNAL TABLE ne crée pas le chemin et le dossier.
Si vous spécifiez LOCATION comme étant un dossier, une requête PolyBase qui sélectionne des données dans la table externe récupère les fichiers dans le dossier et dans tous ses sous-dossiers. Tout comme Hadoop, PolyBase ne retourne pas les dossiers masqués. Il ne retourne pas non plus les fichiers dont le nom commence par un trait de soulignement (_) ou un point (.).
Dans l’exemple d’image suivant, si LOCATION='/webdata/', une requête PolyBase retourne des lignes de mydata.txt et mydata2.txt. Elle ne retourne pas mydata3.txt, car il se trouve dans un sous-dossier d’un dossier masqué. Elle ne retourne pas non plus _hidden.txt car il s’agit d’un fichier masqué.
Contrairement aux tables externes Hadoop, les tables externes natives ne retournent pas de sous-dossiers, à moins que /** ne soit spécifié à la fin du chemin. Dans cet exemple, si LOCATION='/webdata/', une requête de pool SQL serverless retourne des lignes de mydata.txt. Il ne retourne pas mydata2.txt et mydata3.txt, car ces fichiers se trouvent dans un sous-dossier. Les tables Hadoop retournent tous les fichiers de tous les sous-dossiers.
Les tables externes Hadoop et natives ignorent les fichiers dont le nom commence par un trait de soulignement (_) ou un point (.).
DATA_SOURCE = external_data_source_name
Spécifie le nom de la source de données externe contenant l’emplacement des données externes. Cet emplacement figure dans Azure Data Lake. Pour créer une source de données externe, utilisez CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Spécifie le nom de l’objet de format de fichier externe qui stocke le type de fichier et la méthode de compression pour les données externes. Pour créer un format de fichier externe, utilisez CREATE EXTERNAL FILE FORMAT.
TABLE_OPTIONS
Spécifie l’ensemble d’options qui décrivent comment lire les fichiers sous-jacents. La seule option disponible est {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}. Celle-ci indique à la table externe d’ignorer les mises à jour appliquées aux fichiers sous-jacents, même si cela peut entraîner des opérations de lecture incohérentes. Utilisez cette option uniquement lorsque vous avez des fichiers auxquels sont fréquemment ajoutées des données. Cette option est disponible dans le pool SQL serverless pour le format CSV.
Options REJECT
Les options de rejet sont en préversion pour les pools SQL serverless dans Azure Synapse Analytics.
Cette option peut être utilisée uniquement avec des sources de données externes où TYPE = HADOOP.
Vous pouvez spécifier les paramètres REJECT qui déterminent la façon dont PolyBase traite les enregistrements incorrects qu’il récupère à partir de la source de données externe. Un enregistrement de données est considéré comme « incorrect » si les types de données ou le nombre de colonnes ne correspondent pas aux définitions de colonnes de la table externe.
Si vous ne spécifiez pas ou ne changez pas les valeurs REJECT, PolyBase utilise les valeurs par défaut. Ces informations sur les paramètres REJECT sont stockées en tant que métadonnées supplémentaires lorsque vous créez une table externe avec l’instruction CREATE EXTERNAL TABLE. Quand une prochaine instruction SELECT ou SELECT INTO SELECT sélectionne des données dans la table externe, PolyBase utilise les options REJECT pour déterminer le nombre ou le pourcentage de lignes pouvant être rejetées avant de provoquer l’échec de la requête. La requête retourne des résultats (partiels) jusqu’à ce que le seuil de rejet soit dépassé. Ensuite, elle échoue avec le message d’erreur correspondant.
L’option de format PARSER_VERSION n’est prise en charge que dans les pools SQL serverless.
REJECT_TYPE = value | percentage
Précise si l’option REJECT_VALUE est spécifiée comme une valeur littérale ou un pourcentage.
value
REJECT_VALUE est une valeur littérale, et non un pourcentage. La requête PolyBase échoue lorsque le nombre de lignes rejetées dépasse la valeur reject_value.
Par exemple, si REJECT_VALUE = 5 et REJECT_TYPE = value, la requête PolyBase SELECT échoue après le rejet de cinq lignes.
percentage
REJECT_VALUE est un pourcentage, et non une valeur littérale. Une requête PolyBase échoue lorsque le pourcentage de lignes ayant échoué dépasse la valeur reject_value. Le pourcentage de lignes ayant échoué est calculé à intervalles.
REJECT_VALUE = reject_value
Spécifie la valeur ou le pourcentage de lignes pouvant être rejetées avant de provoquer l’échec de la requête.
- Pour REJECT_TYPE = value, reject_value doit être un entier compris entre 0 et 2 147 483 647.
- Pour REJECT_TYPE = percentage, reject_value doit être une valeur float comprise entre 0 et 100. Le pourcentage n’est valide que pour les pools SQL dédiés pour lesquels
TYPE=HADOOP.
La requête échoue lorsque le nombre de lignes rejetées dépasse la valeur reject_value. Par exemple, si REJECT_VALUE = 5 et REJECT_TYPE = value, la requête SELECT échoue après le rejet de cinq lignes.
REJECT_SAMPLE_VALUE = reject_sample_value
Cet attribut est nécessaire lorsque vous spécifiez REJECT_TYPE = percentage. Il détermine le nombre de lignes à tenter de récupérer avant que PolyBase ne recalcule le pourcentage de lignes rejetées.
Le paramètre reject_sample_value doit être un entier compris entre 0 et 2 147 483 647.
Par exemple, si REJECT_SAMPLE_VALUE = 1000, PolyBase calcule le pourcentage de lignes ayant échoué après avoir tenté d’importer 1000 lignes à partir du fichier de données externe. Si le pourcentage de lignes ayant échoué est inférieur à la valeur de reject_value, PolyBase tente de récupérer 1000 autres lignes. Il continue de recalculer le pourcentage de lignes ayant échoué après avoir tenté d’importer chacune des 1000 lignes supplémentaires.
Notes
Étant donné que PolyBase calcule le pourcentage de lignes ayant échoué à intervalles, le pourcentage de lignes ayant échoué peut dépasser la valeur de reject_value.
Exemple :
Cet exemple montre comment les trois options REJECT interagissent les unes avec les autres. Par exemple, si REJECT_TYPE = percentage, REJECT_VALUE = 30 et REJECT_SAMPLE_VALUE = 100, le scénario suivant peut se produire :
- PolyBase tente de récupérer les 100 premières lignes : la récupération échoue pour 25 d’entre elles, et réussit pour les 75 autres.
- Le pourcentage de lignes ayant échoué qui est obtenu est de 25 %, ce qui est inférieur à la valeur de rejet de 30 %. Par conséquent, PolyBase va continuer de récupérer les données à partir de la source de données externe.
- PolyBase tente de charger les 100 lignes suivantes. Cette fois-ci, le chargement réussit pour 25 lignes et échoue pour les 75 autres.
- Le pourcentage de lignes ayant échoué est recalculé et on obtient 50 %. Le pourcentage de lignes ayant échoué a donc dépassé la valeur de rejet de 30 %.
- La requête PolyBase échoue après le rejet de 50 % des 200 premières lignes qu’elle a tenté de retourner. Notez que les lignes correspondantes sont retournées avant que la requête PolyBase ne détecte que le seuil de rejet a été dépassé.
REJECTED_ROW_LOCATION = Emplacement de répertoire
Spécifie le répertoire dans la Source de données externe dans lequel les lignes rejetées et le fichier d’erreur correspondant doivent être écrits.
Si le chemin spécifié n’existe pas, il est créé par l’outil. Un répertoire enfant est ajouté sous le nom _rejectedrows. Le caractère _ permet de placer le répertoire dans une séquence d’échappement pour les autres types de traitement de données, à moins qu’il ne soit explicitement nommé dans le paramètre d’emplacement.
- Dans les pools SQL serverless, le chemin est
YearMonthDay_HourMinuteSecond_StatementID. Vous pouvez utiliser l’ID d’instruction pour corréler le dossier avec la requête qui l’a généré. - Dans les pools SQL dédiés, le chemin est créé d’après l’heure de soumission du chargement au format
YearMonthDay -HourMinuteSecond, par exemple20180330-173205.
Dans ce dossier, deux types de fichiers sont écrits : le fichier _reason et le fichier de données.
Pour plus d’informations, consultez CRÉER UNE SOURCE DE DONNÉES EXTERNES.
Les fichiers de raison et les fichiers de données ont tous deux le queryID associé à l’instruction CTAS. Comme les données et la raison se trouvent dans des fichiers distincts, les fichiers correspondants ont un suffixe analogue.
Dans les pools SQL serverless, le fichier error.json contient un tableau JSON des erreurs rencontrées liées aux lignes rejetées. Chaque élément représentant une erreur contient les attributs suivants :
| Attribut | Description |
|---|---|
| Error | Raison pour laquelle la ligne est rejetée. |
| Ligne | Nombre ordinal de lignes rejetées dans le fichier. |
| Colonne | Nombre ordinal de colonnes rejetées. |
| Value | Valeur des colonnes rejetées. Si la valeur est supérieure à 100 caractères, seuls les 100 premiers caractères seront affichés. |
| Fichier | Chemin d’accès au fichier auquel la ligne appartient. |
Autorisations
Nécessite les autorisations utilisateur suivantes :
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT
Notes
Les autorisations de BASE DE DONNÉES DE CONTRÔLE sont requises pour créer uniquement la CLÉ PRINCIPALE, LES INFORMATIONS D’IDENTIFICATION DÉLIMITÉES À LA BASE DE DONNÉES et LA SOURCE DE DONNÉES EXTERNE
Notez que la connexion qui crée la source de données externe doit être autorisée à lire et à écrire dans la source de données externe, qui est située dans Hadoop ou Stockage Blob Azure.
Important
L’autorisation ALTER ANY EXTERNAL DATA SOURCE accorde à n’importe quel principal la possibilité de créer et de modifier tout objet de source de données externe. Par conséquent, elle permet également d’accéder à toutes les informations d’identification délimitées à la base de données. Cette autorisation doit être considérée comme fournissant des privilèges très élevés, et doit donc être accordée uniquement aux principaux de confiance du système.
Gestion des erreurs
Lors de l’exécution de l’instruction CREATE EXTERNAL TABLE, PolyBase tente de se connecter à la source de données externe. Si la tentative de connexion échoue, l’instruction échoue et la table externe n’est pas créée. L’échec de la commande peut prendre plusieurs minutes, car PolyBase tente plusieurs connexions avant que la requête n’échoue.
Remarques
Dans les scénarios de requête ad hoc, comme SELECT FROM EXTERNAL TABLE, PolyBase stocke les lignes qui sont récupérées de la source de données externe dans une table temporaire. Une fois la requête terminée, PolyBase supprime la table temporaire. Aucune donnée permanente n’est stockée dans les tables SQL.
En revanche, dans le scénario d’importation, comme avec SELECT INTO FROM EXTERNAL TABLE, PolyBase stocke les lignes qui sont extraites de la source de données externe sous forme de données permanentes dans la table SQL. La nouvelle table est créée lors de l’exécution de la requête, au moment où PolyBase récupère les données externes.
PolyBase peut envoyer (push) une partie du calcul des requêtes vers Hadoop pour améliorer les performances des requêtes. Cette action est appelée « poussée de prédicats ». Pour l’activer, spécifiez l’option d’emplacement du Gestionnaire de ressources Hadoop dans CREATE EXTERNAL DATA SOURCE.
Vous pouvez créer plusieurs tables externes qui référencent les mêmes sources de données externes ou des sources différentes.
Faites attention aux données sources qui utilisent le classement UTF-8. Pour toutes les données sources qui utilisent le classement UTF-8, vous devez fournir manuellement un classement non UTF-8 pour chaque colonne UTF-8 dans l’instruction CREATE EXTERNAL TABLE. Cela est dû au fait que la prise en charge d’UTF-8 ne s’étend pas aux tables externes. Lorsque vous tentez de créer une table externe avec un classement UTF-8, vous recevez le message d’erreur : Unsupported collation. Si le classement de base de données de la table externe est un classement UTF-8, la création de tables externes échouera, sauf si vous fournissez un classement de colonne non UTF-8 explicite, par exemple [UTF8_column] varchar(128) COLLATE LATIN1_GENERAL_100_CI_AS_KS_WS NOT NULL,.
Les pools SQL serverless et dédiés dans Azure Synapse Analytics utilisent des codebases différents pour la virtualisation des données. Les pools SQL serverless prennent en charge une technologie native de virtualisation de données. Les pools SQL dédiés, eux, sont compatibles avec la virtualisation des données native et PolyBase. La virtualisation des données PolyBase est utilisée lorsque la source de données externe (EXTERNAL DATA SOURCE) est créée avec TYPE=HADOOP.
Limitations et restrictions
Dans la mesure où les données d’une table externe ne sont pas sous le contrôle de gestion direct d’Azure Synapse, elles peuvent être changées ou supprimées à tout moment par un processus externe. Par conséquent, il n’est pas garanti que les résultats d’une requête exécutée sur une table externe soient déterministes. La même requête peut retourner des résultats différents chaque fois qu’elle est exécutée sur une table externe. De même, une requête peut échouer si les données externes sont déplacées ou supprimées.
Vous pouvez créer plusieurs tables externes qui référencent chacune des sources de données externes différentes.
Seules les instructions DDL suivantes sont autorisées avec les tables externes :
- CREATE TABLE et DROP TABLE
- CREATE STATISTICS et DROP STATISTICS
- CREATE VIEW et DROP VIEW
Les constructions et les opérations suivantes ne sont pas prises en charge :
- La contrainte DEFAULT sur les colonnes de table externe
- Les opérations DML delete, insert et update
- Dynamic Data Masking sur les colonnes de table externe
Limitations des requêtes
Il est recommandé de ne pas dépasser plus de 30 000 fichiers par dossier. Lorsque trop de fichiers sont référencés, une exception d’insuffisance de mémoire de machine virtuelle Java (JVM) peut être levée ou les performances peuvent se dégrader.
Limitations concernant la largeur des tables
Dans Azure Data Warehouse, PolyBase a une limite de largeur de ligne de 1 Mo, basée sur la taille maximale d’une ligne valide par définition de table. Si la somme du schéma de colonne est supérieure à 1 Mo, PolyBase ne peut pas interroger les données.
Limitations des types de données
Les types de données suivants ne peuvent pas être utilisés dans des tables externes Polybase :
geographygeometryhierarchyidimagetextnTextxml- Tout type défini par l’utilisateur
Verrouillage
Verrou partagé sur l’objet SCHEMARESOLUTION.
Exemples
R. Importer des données ADLS Gen 2 dans Azure Synapse Analytics
Pour obtenir des exemples de Gen ADLS Gen 1, consultez Créer une source de données externe.
-- These values come from your Azure Active Directory Application used to authenticate to ADLS Gen 2.
CREATE DATABASE SCOPED CREDENTIAL ADLUser
WITH IDENTITY = '<clientID>@\<OAuth2.0TokenEndPoint>',
SECRET = '<KEY>' ;
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH (TYPE = HADOOP,
LOCATION = 'abfss://data@pbasetr.azuredatalakestore.net'
);
CREATE EXTERNAL FILE FORMAT TextFileFormat
WITH
(
FORMAT_TYPE = DELIMITEDTEXT
, FORMAT_OPTIONS ( FIELD_TERMINATOR = '|'
, STRING_DELIMITER = ''
, DATE_FORMAT = 'yyyy-MM-dd HH:mm:ss.fff'
, USE_TYPE_DEFAULT = FALSE
)
);
CREATE EXTERNAL TABLE [dbo].[DimProduct_external]
( [ProductKey] [int] NOT NULL,
[ProductLabel] nvarchar NULL,
[ProductName] nvarchar NULL )
WITH
(
LOCATION='/DimProduct/' ,
DATA_SOURCE = AzureDataLakeStore ,
FILE_FORMAT = TextFileFormat ,
REJECT_TYPE = VALUE ,
REJECT_VALUE = 0
);
CREATE TABLE [dbo].[DimProduct]
WITH (DISTRIBUTION = HASH([ProductKey] ) )
AS SELECT * FROM
[dbo].[DimProduct_external] ;
B. Importer des données de Parquet dans Azure Synapse Analytics
L’exemple suivant crée une table externe : Il retourne ensuite la première ligne :
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
);
GO
SELECT TOP 1 * FROM census_external_table;
Étapes suivantes
En savoir plus sur les tables externes et les concepts associés dans les articles suivants :
* Analytics
Platform System (PDW) *
Présentation : Système de la plateforme d'analyse
Utilisez une table externe pour :
- Interroger des données Hadoop ou Stockage Blob Azure avec des instructions Transact-SQL.
- Importer des données Hadoop ou Stockage Blob Azure et les stocker dans Analytics Platform System.
Voir aussi CREATE EXTERNAL DATA SOURCE et DROP EXTERNAL TABLE.
Syntaxe
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'hdfs_folder_or_filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ ,...n ] ]
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage,
| REJECT_VALUE = reject_value,
| REJECT_SAMPLE_VALUE = reject_sample_value,
}
Arguments
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
Nom (composé d’une à trois parties) de la table à créer. Pour une table externe, Analytics Platform System stocke uniquement les métadonnées de la table avec des statistiques de base sur le fichier ou le dossier qui est référencé dans Hadoop ou Stockage Blob Azure. Aucune donnée réelle est déplacée ou stockée dans le système de la plateforme d’analyse.
Important
Pour des performances optimales, si le pilote de source de données externe prend en charge un nom en trois parties, il est fortement recommandé de fournir ce nom en trois parties.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE prend en charge la possibilité de configurer le nom de colonne, le type de données, la possibilité d’une valeur Null et le classement. Vous ne pouvez pas utiliser DEFAULT CONSTRAINT sur des tables externes.
Les définitions de colonne, notamment les types de données et le nombre de colonnes, doivent correspondre aux données des fichiers externes. En cas de non-correspondance, les lignes du fichier sont rejetées lors de l’interrogation des données réelles.
LOCATION = 'folder_or_filepath'
Spécifie le dossier ou le chemin et le nom du fichier où se trouvent les données dans Hadoop ou Stockage Blob Azure. L’emplacement commence au dossier racine. Le dossier racine est l’emplacement de données qui est spécifié dans la source de données externe.
Dans le système de la plateforme d’analyse, l’instruction CREATE EXTERNAL TABLE AS SELECT crée le chemin et le dossier s’ils n’existent pas.
CREATE EXTERNAL TABLE ne crée pas le chemin et le dossier.
Si vous spécifiez LOCATION comme étant un dossier, une requête PolyBase qui sélectionne des données dans la table externe récupère les fichiers dans le dossier et dans tous ses sous-dossiers. Tout comme Hadoop, PolyBase ne retourne pas les dossiers masqués. Il ne retourne pas non plus les fichiers dont le nom commence par un trait de soulignement (_) ou un point (.).
Dans l’exemple d’image suivant, si LOCATION='/webdata/', une requête PolyBase retourne des lignes de mydata.txt et mydata2.txt. Elle ne retourne pas mydata3.txt, car il se trouve dans un sous-dossier d’un dossier masqué. Elle ne retourne pas non plus _hidden.txt car il s’agit d’un fichier masqué.
Pour modifier la valeur par défaut et uniquement lire les données du dossier racine, définissez l’attribut <polybase.recursive.traversal>sur 'false' dans le fichier de configuration core-site.xml. Ce fichier se trouve sous <SqlBinRoot>\PolyBase\Hadoop\Conf\ sous la racine bin de SQL Server. Par exemple : C:\Program Files\Microsoft SQL Server\MSSQL13.XD14\MSSQL\Binn\.
DATA_SOURCE = external_data_source_name
Spécifie le nom de la source de données externe contenant l’emplacement des données externes. Cet emplacement est soit Hadoop, soit Stockage Blob Azure. Pour créer une source de données externe, utilisez CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Spécifie le nom de l’objet de format de fichier externe qui stocke le type de fichier et la méthode de compression pour les données externes. Pour créer un format de fichier externe, utilisez CREATE EXTERNAL FILE FORMAT.
Options REJECT
Cette option peut être utilisée uniquement avec des sources de données externes où TYPE = HADOOP.
Vous pouvez spécifier les paramètres REJECT qui déterminent la façon dont PolyBase traite les enregistrements incorrects qu’il récupère à partir de la source de données externe. Un enregistrement de données est considéré comme « incorrect » si les types de données ou le nombre de colonnes ne correspondent pas aux définitions de colonnes de la table externe.
Si vous ne spécifiez pas ou ne changez pas les valeurs REJECT, PolyBase utilise les valeurs par défaut. Ces informations sur les paramètres REJECT sont stockées en tant que métadonnées supplémentaires lorsque vous créez une table externe avec l’instruction CREATE EXTERNAL TABLE. Quand une prochaine instruction SELECT ou SELECT INTO SELECT sélectionne des données dans la table externe, PolyBase utilise les options REJECT pour déterminer le nombre ou le pourcentage de lignes pouvant être rejetées avant de provoquer l’échec de la requête. La requête retourne des résultats (partiels) jusqu’à ce que le seuil de rejet soit dépassé. Ensuite, elle échoue avec le message d’erreur correspondant.
REJECT_TYPE = value | percentage
Précise si l’option REJECT_VALUE est spécifiée comme une valeur littérale ou un pourcentage.
value
REJECT_VALUE est une valeur littérale, et non un pourcentage. La requête PolyBase échoue lorsque le nombre de lignes rejetées dépasse la valeur reject_value.
Par exemple, si REJECT_VALUE = 5 et REJECT_TYPE = value, la requête PolyBase SELECT échoue après le rejet de cinq lignes.
percentage
REJECT_VALUE est un pourcentage, et non une valeur littérale. Une requête PolyBase échoue lorsque le pourcentage de lignes ayant échoué dépasse la valeur reject_value. Le pourcentage de lignes ayant échoué est calculé à intervalles.
REJECT_VALUE = reject_value
Spécifie la valeur ou le pourcentage de lignes pouvant être rejetées avant de provoquer l’échec de la requête.
Pour REJECT_TYPE = value, reject_value doit être un entier compris entre 0 et 2 147 483 647.
Pour REJECT_TYPE = percentage, reject_value doit être une valeur float comprise entre 0 et 100.
REJECT_SAMPLE_VALUE = reject_sample_value
Cet attribut est nécessaire lorsque vous spécifiez REJECT_TYPE = percentage. Il détermine le nombre de lignes à tenter de récupérer avant que PolyBase ne recalcule le pourcentage de lignes rejetées.
Le paramètre reject_sample_value doit être un entier compris entre 0 et 2 147 483 647.
Par exemple, si REJECT_SAMPLE_VALUE = 1000, PolyBase calcule le pourcentage de lignes ayant échoué après avoir tenté d’importer 1000 lignes à partir du fichier de données externe. Si le pourcentage de lignes ayant échoué est inférieur à la valeur de reject_value, PolyBase tente de récupérer 1000 autres lignes. Il continue de recalculer le pourcentage de lignes ayant échoué après avoir tenté d’importer chacune des 1000 lignes supplémentaires.
Notes
Étant donné que PolyBase calcule le pourcentage de lignes ayant échoué à intervalles, le pourcentage de lignes ayant échoué peut dépasser la valeur de reject_value.
Exemple :
Cet exemple montre comment les trois options REJECT interagissent les unes avec les autres. Par exemple, si REJECT_TYPE = percentage, REJECT_VALUE = 30 et REJECT_SAMPLE_VALUE = 100, le scénario suivant peut se produire :
- PolyBase tente de récupérer les 100 premières lignes : la récupération échoue pour 25 d’entre elles, et réussit pour les 75 autres.
- Le pourcentage de lignes ayant échoué qui est obtenu est de 25 %, ce qui est inférieur à la valeur de rejet de 30 %. Par conséquent, PolyBase va continuer de récupérer les données à partir de la source de données externe.
- PolyBase tente de charger les 100 lignes suivantes. Cette fois-ci, le chargement réussit pour 25 lignes et échoue pour les 75 autres.
- Le pourcentage de lignes ayant échoué est recalculé et on obtient 50 %. Le pourcentage de lignes ayant échoué a donc dépassé la valeur de rejet de 30 %.
- La requête PolyBase échoue après le rejet de 50 % des 200 premières lignes qu’elle a tenté de retourner. Notez que les lignes correspondantes sont retournées avant que la requête PolyBase ne détecte que le seuil de rejet a été dépassé.
Autorisations
Nécessite les autorisations utilisateur suivantes :
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT
- CONTROL DATABASE
Notez que la connexion qui crée la source de données externe doit être autorisée à lire et à écrire dans la source de données externe, qui est située dans Hadoop ou Stockage Blob Azure.
Important
L’autorisation ALTER ANY EXTERNAL DATA SOURCE accorde à n’importe quel principal la possibilité de créer et de modifier tout objet de source de données externe. Par conséquent, elle permet également d’accéder à toutes les informations d’identification délimitées à la base de données. Cette autorisation doit être considérée comme fournissant des privilèges très élevés, et doit donc être accordée uniquement aux principaux de confiance du système.
Gestion des erreurs
Lors de l’exécution de l’instruction CREATE EXTERNAL TABLE, PolyBase tente de se connecter à la source de données externe. Si la tentative de connexion échoue, l’instruction échoue et la table externe n’est pas créée. L’échec de la commande peut prendre plusieurs minutes, car PolyBase tente plusieurs connexions avant que la requête n’échoue.
Remarques
Dans les scénarios de requête ad hoc, comme SELECT FROM EXTERNAL TABLE, PolyBase stocke les lignes qui sont récupérées de la source de données externe dans une table temporaire. Une fois la requête terminée, PolyBase supprime la table temporaire. Aucune donnée permanente n’est stockée dans les tables SQL.
En revanche, dans le scénario d’importation, comme avec SELECT INTO FROM EXTERNAL TABLE, PolyBase stocke les lignes qui sont extraites de la source de données externe sous forme de données permanentes dans la table SQL. La nouvelle table est créée lors de l’exécution de la requête, au moment où PolyBase récupère les données externes.
PolyBase peut envoyer (push) une partie du calcul des requêtes vers Hadoop pour améliorer les performances des requêtes. Cette action est appelée « poussée de prédicats ». Pour l’activer, spécifiez l’option d’emplacement du Gestionnaire de ressources Hadoop dans CREATE EXTERNAL DATA SOURCE.
Vous pouvez créer plusieurs tables externes qui référencent les mêmes sources de données externes ou des sources différentes.
Limitations et restrictions
Dans la mesure où les données d’une table externe ne sont pas sous le contrôle de gestion direct de l’appliance, elles peuvent être changées ou supprimées à tout moment par un processus externe. Par conséquent, il n’est pas garanti que les résultats d’une requête exécutée sur une table externe soient déterministes. La même requête peut retourner des résultats différents chaque fois qu’elle est exécutée sur une table externe. De même, une requête peut échouer si les données externes sont déplacées ou supprimées.
Vous pouvez créer plusieurs tables externes qui référencent chacune des sources de données externes différentes. Si vous exécutez simultanément plusieurs requêtes sur des sources de données Hadoop différentes, chaque source Hadoop doit utiliser le même paramètre de configuration de serveur « hadoop connectivity » (connectivité Hadoop). Par exemple, vous ne pouvez pas exécuter simultanément une requête sur un cluster Hadoop Cloudera et sur un cluster Hadoop Hortonworks, puisqu’ils utilisent des paramètres de configuration différents. Pour connaître les paramètres de configuration et les combinaisons prises en charge, consultez Configuration de la connectivité PolyBase.
Seules les instructions DDL suivantes sont autorisées avec les tables externes :
- CREATE TABLE et DROP TABLE
- CREATE STATISTICS et DROP STATISTICS
- CREATE VIEW et DROP VIEW
Les constructions et les opérations suivantes ne sont pas prises en charge :
- La contrainte DEFAULT sur les colonnes de table externe
- Les opérations DML delete, insert et update
- Dynamic Data Masking sur les colonnes de table externe
Limitations des requêtes
PolyBase peut consommer un maximum de 33 000 fichiers par dossier lors de l’exécution simultanée de 32 requêtes PolyBase. Ce nombre maximal inclut les fichiers et les sous-dossiers de chaque dossier HDFS. Si le degré de concurrence est inférieur à 32, un utilisateur peut exécuter des requêtes PolyBase sur des dossiers dans des systèmes HDFS contenant plus de 33 000 fichiers. Il est recommandé de raccourcir au maximum les chemins de fichiers externes et de ne pas utiliser plus de 30 000 fichiers par dossier HDFS. Lorsque trop de fichiers sont référencés, une exception d’insuffisance de mémoire Java Virtual Machine (JVM) peut être levée.
Limitations concernant la largeur des tables
Dans SQL Server 2016, PolyBase a une limite de largeur de ligne de 32 Ko, basée sur la taille maximale d’une ligne valide par définition de table. Si la somme du schéma de colonne est supérieure à 32 Ko, PolyBase ne peut pas interroger les données.
Dans Azure Synapse Analytics, cette limitation a été augmentée à 1 Mo.
Limitations des types de données
Les types de données suivants ne peuvent pas être utilisés dans des tables externes Polybase :
geographygeometryhierarchyidimagetextnTextxml- Tout type défini par l’utilisateur
Verrouillage
Verrou partagé sur l’objet SCHEMARESOLUTION.
Sécurité
Les fichiers de données d’une table externe sont stockés dans Hadoop ou Stockage Blob Azure. Ces fichiers de données sont créés et gérés par vos propres processus. Il vous incombe de gérer la sécurité des données externes.
Exemples
R. Joindre des données HDFS avec des données du système de la plateforme d’analyse
SELECT cs.user_ip FROM ClickStream cs
JOIN [User] u ON cs.user_ip = u.user_ip
WHERE cs.url = 'www.microsoft.com';
B. Importer des données de ligne à partir de HDFS dans une table du système de la plateforme d’analyse distribuée
CREATE TABLE ClickStream_PDW
WITH ( DISTRIBUTION = HASH (url) )
AS SELECT url, event_date, user_ip FROM ClickStream;
C. Importer des données de ligne à partir de HDFS dans une table du système de la plateforme d’analyse répliquée
CREATE TABLE ClickStream_PDW
WITH ( DISTRIBUTION = REPLICATE )
AS SELECT url, event_date, user_ip
FROM ClickStream;
Étapes suivantes
En savoir plus sur les tables externes dans Analytics Platform System dans les articles suivants :
* Azure SQL Managed Instance *
Présentation : Azure SQL Managed Instance
Crée une table de données externe dans Azure SQL Managed Instance. Pour obtenir des informations complètes, consultez Virtualisation des données avec Azure SQL Managed Instance.
La virtualisation des données dans Azure SQL Managed Instance permet d’accéder aux données externes dans divers formats de fichiers dans Azure Data Lake Storage Gen2 ou Stockage Blob Azure, de les interroger avec des instructions T-SQL, voire de combiner des données avec des données relationnelles stockées localement avec des jointures.
Voir aussi CREATE EXTERNAL DATA SOURCE et DROP EXTERNAL TABLE.
Syntaxe
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
Arguments
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
Nom (composé d’une à trois parties) de la table à créer. Pour une table externe, uniquement les métadonnées de la table avec des statistiques de base sur le fichier ou le dossier qui sont référencées dans Azure Data Lake ou Stockage Blob Azure. Aucune donnée réelle n’est déplacée ni stockée lors de la création de tables externes.
Important
Pour des performances optimales, si le pilote de source de données externe prend en charge un nom en trois parties, il est fortement recommandé de fournir ce nom en trois parties.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE prend en charge la possibilité de configurer le nom de colonne, le type de données, la possibilité d’une valeur Null et le classement. Vous ne pouvez pas utiliser DEFAULT CONSTRAINT sur des tables externes.
Les définitions de colonne, notamment les types de données et le nombre de colonnes, doivent correspondre aux données des fichiers externes. En cas de non-correspondance, les lignes du fichier sont rejetées lors de l’interrogation des données réelles.
LOCATION = 'folder_or_filepath'
Spécifie le dossier, ou le chemin et le nom du fichier, des données réelles dans Azure Data Lake ou Stockage Blob Azure. L’emplacement commence au dossier racine. Le dossier racine est l’emplacement de données qui est spécifié dans la source de données externe.
CREATE EXTERNAL TABLE ne crée pas le chemin et le dossier.
Si vous spécifiez LOCATION comme dossier, la requête d’Azure SQL Managed Instance qui sélectionne des données dans la table externe récupère les fichiers du dossier mais pas tous ses sous-dossiers.
Azure SQL Managed Instance ne peut pas trouver de fichiers dans des sous-dossiers ou des dossiers masqués. Il ne retourne pas non plus les fichiers dont le nom commence par un trait de soulignement (_) ou un point (.).
Dans l’exemple d’image suivant, si LOCATION='/webdata/', une requête retourne des lignes de mydata.txt. Elle ne retourne pas mydata2.txt car il se trouve dans un sous-dossier, ne retourne pas mydata3.txt car il se trouve dans un dossier masqué et ne retourne pas _hidden.txt car il s’agit d’un fichier masqué.
DATA_SOURCE = external_data_source_name
Spécifie le nom de la source de données externe contenant l’emplacement des données externes. Cet emplacement figure dans Azure Data Lake. Pour créer une source de données externe, utilisez CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Spécifie le nom de l’objet de format de fichier externe qui stocke le type de fichier et la méthode de compression pour les données externes. Pour créer un format de fichier externe, utilisez CREATE EXTERNAL FILE FORMAT.
Autorisations
Nécessite les autorisations utilisateur suivantes :
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT
Notes
Les autorisations de BASE DE DONNÉES DE CONTRÔLE sont requises pour créer uniquement la CLÉ PRINCIPALE, LES INFORMATIONS D’IDENTIFICATION DÉLIMITÉES À LA BASE DE DONNÉES et LA SOURCE DE DONNÉES EXTERNE
Notez que la connexion qui crée la source de données externe doit être autorisée à lire et à écrire dans la source de données externe, qui est située dans Hadoop ou Stockage Blob Azure.
Important
L’autorisation ALTER ANY EXTERNAL DATA SOURCE accorde à n’importe quel principal la possibilité de créer et de modifier tout objet de source de données externe. Par conséquent, elle permet également d’accéder à toutes les informations d’identification délimitées à la base de données. Cette autorisation doit être considérée comme fournissant des privilèges très élevés, et doit donc être accordée uniquement aux principaux de confiance du système.
Remarques
Dans les scénarios de requête ad hoc, comme SELECT FROM EXTERNAL TABLE, les lignes récupérées de la source de données externe sont stockées dans une table temporaire. Une fois la requête terminée, les lignes sont supprimées et la table temporaire est supprimée. Aucune donnée permanente n’est stockée dans les tables SQL.
En revanche, dans le scénario d’importation, comme SELECT INTO FROM EXTERNAL TABLE, les lignes récupérées de la source de données externe sont stockées sous forme de données permanentes dans la table SQL. La nouvelle table est créée lors de l’exécution de la requête quand les données externes sont récupérées.
Actuellement, la virtualisation des données avec Azure SQL Managed Instance est en lecture seule.
Vous pouvez créer plusieurs tables externes qui référencent les mêmes sources de données externes ou des sources différentes.
Limitations et restrictions
Dans la mesure où les données d’une table externe ne sont pas sous le contrôle de gestion direct d’Azure SQL Managed Instance, elles peuvent être changées ou supprimées à tout moment par un processus externe. Par conséquent, il n’est pas garanti que les résultats d’une requête exécutée sur une table externe soient déterministes. La même requête peut retourner des résultats différents chaque fois qu’elle est exécutée sur une table externe. De même, une requête peut échouer si les données externes sont déplacées ou supprimées.
Vous pouvez créer plusieurs tables externes qui référencent chacune des sources de données externes différentes.
Seules les instructions DDL suivantes sont autorisées avec les tables externes :
- CREATE TABLE et DROP TABLE
- CREATE STATISTICS et DROP STATISTICS
- CREATE VIEW et DROP VIEW
Les constructions et les opérations suivantes ne sont pas prises en charge :
- La contrainte DEFAULT sur les colonnes de table externe
- Les opérations DML delete, insert et update
Limitations concernant la largeur des tables
La limite de largeur de ligne de 1 Mo est basée sur la taille maximale d’une ligne valide par définition de table. Si la somme du schéma de colonne est supérieure à 1 Mo, les requêtes de virtualisation des données échouent.
Limitations des types de données
Les types de données suivants ne peuvent pas être utilisés dans des tables externes dans Azure SQL Managed Instance :
geographygeometryhierarchyidimagetextnTextxml- Tout type défini par l’utilisateur
Verrouillage
Verrou partagé sur l’objet SCHEMARESOLUTION.
Exemples
R. Interroger des données externes à partir d’Azure SQL Managed Instance avec une table externe
Pour obtenir d’autres exemples, consultez Créer une source de données externe ou Virtualisation des données avec Azure SQL Managed Instance.
Créez la clé principale de la base de données si elle n’existe pas.
-- Optional: Create MASTER KEY if it doesn't exist in the database: CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<Strong Password>' GOCréez les informations d’identification délimitées à la base de données en utilisant un jeton SAS. Vous pouvez également utiliser une identité managée.
CREATE DATABASE SCOPED CREDENTIAL MyCredential WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<KEY>' ; --Removing leading '?' GOCréez la source de données externe en utilisant les informations d’identification.
--Create external data source pointing to the file path, and referencing database-scoped credential: CREATE EXTERNAL DATA SOURCE MyPrivateExternalDataSource WITH ( LOCATION = 'abs://public@pandemicdatalake.blob.core.windows.net/curated/covid-19/bing_covid-19_data/latest' CREDENTIAL = [MyCredential] ) GOCréez un format de fichier externe (EXTERNAL FILE FORMAT) et une table externe (EXTERNAL TABLE) pour interroger les données comme s’il s’agissait d’une table locale.
-- Or, create an EXTERNAL FILE FORMAT and an EXTERNAL TABLE --Create external file format CREATE EXTERNAL FILE FORMAT DemoFileFormat WITH ( FORMAT_TYPE=PARQUET ) GO --Create external table: CREATE EXTERNAL TABLE tbl_TaxiRides( vendorID VARCHAR(100) COLLATE Latin1_General_BIN2, tpepPickupDateTime DATETIME2, tpepDropoffDateTime DATETIME2, passengerCount INT, tripDistance FLOAT, puLocationId VARCHAR(8000), doLocationId VARCHAR(8000), startLon FLOAT, startLat FLOAT, endLon FLOAT, endLat FLOAT, rateCodeId SMALLINT, storeAndFwdFlag VARCHAR(8000), paymentType VARCHAR(8000), fareAmount FLOAT, extra FLOAT, mtaTax FLOAT, improvementSurcharge VARCHAR(8000), tipAmount FLOAT, tollsAmount FLOAT, totalAmount FLOAT ) WITH ( LOCATION = 'yellow/puYear=*/puMonth=*/*.parquet', DATA_SOURCE = NYCTaxiExternalDataSource, FILE_FORMAT = MyFileFormat ); GO --Then, query the data via an external table with T-SQL: SELECT TOP 10 * FROM tbl_TaxiRides; GO
Étapes suivantes
En savoir plus sur les tables externes et les concepts associés dans les articles suivants :