Configurer une instance de cluster de basculement RHEL pour SQL Server
S’applique à : ![]() SQL Server - Linux
SQL Server - Linux
Ce guide fournit des instructions pour créer un cluster de basculement de disque partagé à deux nœuds pour SQL Server sur Red Hat Enterprise Linux. La couche de clustering est basée sur le module complémentaire haute disponibilité Red Hat Enterprise Linux (RHEL) basé sur Pacemaker. L’instance est active sur un nœud ou sur l’autre.
Notes
L’accès à la documentation et au module complémentaire HA de Red Hat requiert un abonnement.
Comme le montre le diagramme suivant, le stockage est présenté à deux serveurs. Les composants de clustering, Corosync et Pacemaker, coordonnent les communications et la gestion des ressources. L’un des serveurs a la connexion active aux ressources de stockage et au SQL Server. Lorsque Pacemaker détecte une défaillance, les composants de clustering sont chargés de déplacer les ressources vers l'autre nœud.
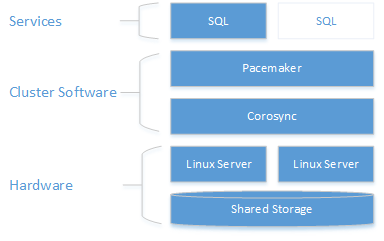
Pour plus d’informations sur la configuration du cluster, les options des agents de ressources et la gestion, consultez la documentation de référence de RHEL.
Remarque
À ce stade, l’intégration de SQL Server avec Pacemaker n’est pas aussi couplée qu’avec WSFC sur Windows. À partir de SQL Server, il n’y a aucune connaissance de la présence du cluster, l’ensemble de l’orchestration est en extérieur-intérieur et le service est contrôlé comme une instance autonome par Pacemaker. De plus, les clusters dmvs sys.dm_os_cluster_nodes et sys.dm_os_cluster_properties par exemple ne seront pas enregistrés.
Pour utiliser une chaîne de connexion qui pointe vers un nom de serveur de chaîne et ne pas utiliser l’adresse IP, ils doivent inscrire sur leur serveur DNS l’adresse IP utilisée pour créer la ressource d’adresse IP virtuelle (comme expliqué dans les sections suivantes) avec le nom de serveur choisi.
Les sections suivantes décrivent les étapes de configuration d’une solution de cluster de basculement.
Prérequis
Pour effectuer le scénario de bout en bout suivant, vous avez besoin de deux machines pour déployer le cluster à deux nœuds et d’un autre serveur pour configurer le serveur NFS. Les étapes suivantes décrivent la configuration de ces serveurs.
Installez et configurez le système d’exploitation sur chaque nœud du cluster
La première étape consiste à configurer le système d'exploitation sur les nœuds de cluster. Pour ce guide, utilisez RHEL avec un abonnement valide pour le module complémentaire de haute disponibilité.
Installer et configurer SQL Server sur chaque nœud du cluster
Installez et configurez SQL Server sur les deux nœuds. Pour obtenir des instructions détaillées, consultez Installer SQL Server sur Linux.
Désignez un nœud comme principal et l’autre comme secondaire, à des fins de configuration. Utilisez ces termes pour le présent guide.
Sur le nœud secondaire, arrêtez et désactivez SQL Server.
L’exemple suivant arrête et désactive SQL Server :
sudo systemctl stop mssql-server sudo systemctl disable mssql-server
Notes
Au moment de la configuration, une clé principale de serveur est générée pour l’instance et placée à l’adresse /var/opt/mssql/secrets/machine-key. Sur Linux, SQL Server s’exécute toujours en tant que compte local appelé mssql. Étant donné qu’il s’agit d’un compte local, son identité n’est pas partagée entre les nœuds. Par conséquent, vous devez copier la clé de chiffrement du nœud principal sur chaque nœud secondaire pour que chaque compte local mssql puisse y accéder pour déchiffrer la clé principale du serveur.
Sur le nœud principal, créez un compte de connexion SQL Server pour Pacemaker et octroyez l’autorisation de connexion pour exécuter
sp_server_diagnostics. Pacemaker utilise ce compte pour vérifier le nœud en cours d’exécution SQL Server.sudo systemctl start mssql-serverConnectez-vous à la base de données
masterSQL Server avec le compte sa et exécutez la commande suivante :USE [master] GO CREATE LOGIN [<loginName>] with PASSWORD= N'<loginPassword>' ALTER SERVER ROLE [sysadmin] ADD MEMBER [<loginName>]Vous pouvez aussi définir les autorisations à un niveau plus granulaire. La connexion à Pacemaker requiert
VIEW SERVER STATEpour demander l’état d’intégrité avecsp_server_diagnostics,setupadminetALTER ANY LINKED SERVERpour mettre à jour le nom de l’instance FCI avec le nom de la ressource en exécutantsp_dropserveretsp_addserver.Sur le nœud principal, arrêtez et désactivez SQL Server.
Sur chaque nœud de cluster, configurez le fichier hôtes. Le fichier hôtes doit inclure l’adresse IP et le nom de chaque nœud de cluster.
Vérifiez l’adresse IP de chaque nœud. Le script suivant affiche l’adresse IP de votre nœud actuel.
sudo ip addr showDéfinissez le nom de l’ordinateur sur chaque nœud. Donnez à chaque nœud un nom unique de 15 caractères ou moins. Définissez le nom de l’ordinateur en l'ajoutant à
/etc/hosts. Le script suivant vous permet de modifier/etc/hostsavecvi.sudo vi /etc/hostsL’exemple suivant présente
/etc/hostsavec des ajouts pour deux nœuds nomméssqlfcivm1etsqlfcivm2.127.0.0.1 localhost localhost4 localhost4.localdomain4 ::1 localhost localhost6 localhost6.localdomain6 10.128.18.128 sqlfcivm1 10.128.16.77 sqlfcivm2
Dans la section suivante, vous allez configurer le stockage partagé et déplacer vos fichiers de base de données vers ce stockage.
Configurer le stockage partagé et déplacer des fichiers de base de données
Il existe diverses solutions pour fournir un stockage partagé. Cette procédure pas à pas illustre la configuration du stockage partagé avec NFS. Nous vous recommandons de suivre les meilleures pratiques et d’utiliser Kerberos pour sécuriser NFS (vous pouvez trouver un exemple ici : https://www.certdepot.net/rhel7-use-kerberos-control-access-nfs-network-shares/).
Avertissement
Si vous ne sécurisez pas NFS, toute personne pouvant accéder à votre réseau et usurper l’adresse IP d’un nœud SQL pourra accéder à vos fichiers de données. Comme toujours, veillez à modéliser votre système de menaces avant de l’utiliser en production. Une autre option de stockage consiste à utiliser le partage de fichiers SMB.
Configurer le stockage partagé avec NFS
Important
L’hébergement de fichiers de base de données sur un serveur NFS avec la version <4 n’est pas pris en charge dans cette version. Cela comprend l’utilisation de NFS pour le clustering de basculement de disques partagés et pour les bases de données sur des instances non-cluster. Nous travaillons sur l’activation d’autres versions de serveur NFS dans les mpises en production à venir.
Effectuez les opérations suivantes sur le serveur NFS :
Installer
nfs-utilssudo yum -y install nfs-utilsActiver et démarrer
rpcbindsudo systemctl enable rpcbind && sudo systemctl start rpcbindActiver et démarrer
nfs-serversudo systemctl enable nfs-server && sudo systemctl start nfs-serverModifiez
/etc/exportspour exporter le répertoire que vous souhaitez partager. Vous avez besoin d’une ligne pour chaque partage de votre choix. Par exemple :/mnt/nfs 10.8.8.0/24(rw,sync,no_subtree_check,no_root_squash)Exporter les partages
sudo exportfs -ravVérifier que les chemins d’accès sont partagés/exportés, exécuter à partir du serveur NFS
sudo showmount -eAjouter une exception dans SELinux
sudo setsebool -P nfs_export_all_rw 1Ouvrez le pare-feu du serveur.
sudo firewall-cmd --permanent --add-service=nfs sudo firewall-cmd --permanent --add-service=mountd sudo firewall-cmd --permanent --add-service=rpc-bind sudo firewall-cmd --reload
Configurer tous les nœuds de cluster pour la connexion au stockage partagé NFS
Procédez comme suit sur tous les nœuds de cluster.
Installer
nfs-utilssudo yum -y install nfs-utilsOuvrir le pare-feu sur les clients et le serveur NFS
sudo firewall-cmd --permanent --add-service=nfs sudo firewall-cmd --permanent --add-service=mountd sudo firewall-cmd --permanent --add-service=rpc-bind sudo firewall-cmd --reloadVérifier que les partages NFS sont visibles sur les machines clients
sudo showmount -e <IP OF NFS SERVER>Répétez ces étapes sur tous les nœuds de cluster.
Pour plus d'informations sur l’utilisation NFS, consultez les ressources suivantes :
- Serveurs NFS et pare-feu | Échange de pile
- Montage d’un volume NFS | Guide des administrateurs réseau Linux
- Configuration du serveur NFS | Portail client Red Hat
Monter le répertoire des fichiers de base de données pour pointer vers le stockage partagé
Sur le nœud principal seulement, enregistrez les fichiers de base de données dans l’emplacement temporaire. Le script suivant crée un nouveau répertoire temporaire, copie les fichiers de base de données et supprime les anciens fichiers de base de données. Comme SQL Server s’exécute en tant qu’utilisateur local
mssql, vous devez vous assurer qu’après le transfert des données vers le partage monté, l’utilisateur local dispose d’un accès en lecture-écriture au partage.sudo su mssql mkdir /var/opt/mssql/tmp cp /var/opt/mssql/data/* /var/opt/mssql/tmp rm /var/opt/mssql/data/* exitSur tous les nœuds du cluster, modifiez le fichier
/etc/fstabpour inclure la commande Monter.<IP OF NFS SERVER>:<shared_storage_path> <database_files_directory_path> nfs timeo=14,intrLe script suivant donne un exemple de la modification.
10.8.8.0:/mnt/nfs /var/opt/mssql/data nfs timeo=14,intr
Remarque
Si vous utilisez une ressource du système de fichiers (FS) comme recommandé ici, il est inutile de conserver la commande de montage dans /etc/fstab. Pacemaker s’occupe du montage du dossier lorsqu’il démarre la ressource en cluster FS. Avec l’aide de l’isolation, le FS n’est jamais monté deux fois.
Exécutez la commande
mount -apour que le système mette à jour les chemins d’accès montés.Copiez la base de données et les fichiers journaux que vous avez enregistrés sur
/var/opt/mssql/tmppour le partage nouvellement monté/var/opt/mssql/data. cette étape doit être effectuée sur le nœud principal. Veillez à accorder des autorisations d‘accès en lecture/écriture à l’utilisateur localmssql.sudo chown mssql /var/opt/mssql/data sudo chgrp mssql /var/opt/mssql/data sudo su mssql cp /var/opt/mssql/tmp/* /var/opt/mssql/data/ rm /var/opt/mssql/tmp/* exitVérifiez que SQL Server démarre correctement avec le nouveau chemin d’accès au fichier. Procédez de la sorte sur chaque nœud. À ce stade, un seul nœud doit exécuter SQL Server à la fois. Ils ne peuvent pas être exécutés en même temps, car ils essaient d’accéder simultanément aux fichiers de données (pour éviter de démarrer accidentellement SQL Server sur les deux nœuds, utilisez une ressource de cluster de système de fichiers pour vous assurer que le partage n’est pas monté deux fois par les différents nœuds). Les commandes suivantes démarrent SQL Server, vérifient l’état, puis, arrêtent SQL Server.
sudo systemctl start mssql-server sudo systemctl status mssql-server sudo systemctl stop mssql-server
À ce stade, les deux instances de SQL Server sont configurées pour s’exécuter avec les fichiers de base de données sur le stockage partagé. L’étape suivante consiste à configurer SQL Server pour Pacemaker.
Installer et configurer Pacemaker sur chaque nœud de cluster
Sur les deux nœuds du cluster, créez un fichier pour stocker le nom d’utilisateur et le mot de passe SQL Server du compte de connexion Pacemaker. La commande suivante a pour effet de créer et remplir ce fichier :
sudo touch /var/opt/mssql/secrets/passwd echo '<loginName>' | sudo tee -a /var/opt/mssql/secrets/passwd echo '<loginPassword>' | sudo tee -a /var/opt/mssql/secrets/passwd sudo chown root:root /var/opt/mssql/secrets/passwd sudo chmod 600 /var/opt/mssql/secrets/passwdSur les deux nœuds de cluster, ouvrez les ports de pare-feu Pacemaker. Pour ouvrir ces ports avec
firewalld, exécutez la commande suivante :sudo firewall-cmd --permanent --add-service=high-availability sudo firewall-cmd --reloadSi vous utilisez un autre pare-feu qui n’intègre pas de configuration à haute disponibilité intégrée, les ports suivants doivent être ouverts pour permettre à Pacemaker de communiquer avec les autres nœuds du cluster :
- TCP : Ports 2224, 3121, 21064
- UDP : Port 5405
Installez les packages Pacemaker sur chaque nœud.
sudo yum install pacemaker pcs fence-agents-all resource-agentsDéfinissez le mot de passe pour l’utilisateur par défaut qui est créé pendant l’installation des packages Pacemaker et Corosync. Utilisez le même mot de passe sur les deux nœuds.
sudo passwd haclusterActivez et démarrez le service
pcsdet Pacemaker. Cela permettra aux nœuds de rejoindre le cluster après le redémarrage. Exécutez la commande suivante sur les deux nœuds.sudo systemctl enable pcsd sudo systemctl start pcsd sudo systemctl enable pacemakerInstallez l’agent de ressources FCI pour SQL Server. Exécutez les commandes suivantes sur les deux nœuds.
sudo yum install mssql-server-ha
Configurer l’agent d’isolation
Un appareil STONITH fournit un agent d’isolation. Configuration de Pacemaker sur Red Hat Entreprise Linux dans Azure fournit un exemple de création d’un appareil STONITH pour ce cluster dans Azure. Modifiez les instructions pour votre environnement.
Créer le cluster
Sur l’un des nœuds, créez le cluster.
sudo pcs cluster auth <nodeName1 nodeName2 ...> -u hacluster sudo pcs cluster setup --name <clusterName> <nodeName1 nodeName2 ...> sudo pcs cluster start --allConfigurez les ressources de cluster pour SQL Server, le système de fichiers et les ressources d’adresse IP virtuelle, et envoyez (push) la configuration au cluster. Les informations suivantes sont nécessaires :
- Nom de la ressource SQL Server : nom de la ressource SQL Server clusterisée.
- Nom de la ressource IP flottante : nom de la ressource d’adresse IP virtuelle.
- Adresse IP : l’adresse IP que les clients utilisent pour se connecter à l’instance en cluster de SQL Server.
- Nom de la ressource de système de fichiers : nom de la ressource de système de fichiers.
- device : chemin du partage NFS
- device : chemin local monté sur le partage
- fstype : type de partage de fichiers (par ex.
nfs)
Mettez à jour les valeurs du script suivant pour votre environnement. Exécutez sur un nœud pour configurer et démarrer le service en cluster.
sudo pcs cluster cib cfg sudo pcs -f cfg resource create <sqlServerResourceName> ocf:mssql:fci sudo pcs -f cfg resource create <floatingIPResourceName> ocf:heartbeat:IPaddr2 ip=<ip Address> sudo pcs -f cfg resource create <fileShareResourceName> Filesystem device=<networkPath> directory=<localPath> fstype=<fileShareType> sudo pcs -f cfg constraint colocation add <virtualIPResourceName> <sqlResourceName> sudo pcs -f cfg constraint colocation add <fileShareResourceName> <sqlResourceName> sudo pcs cluster cib-push cfgPar exemple, le script suivant crée une ressource SQL Server en cluster nommée
mssqlhaet une ressource d’adresse IP flottantes avec l’adresse IP10.0.0.99. Il crée également une ressource FileSystem et ajoute des contraintes afin que toutes les ressources soient colocalisées sur le même nœud que la ressource SQL.sudo pcs cluster cib cfg sudo pcs -f cfg resource create mssqlha ocf:mssql:fci sudo pcs -f cfg resource create virtualip ocf:heartbeat:IPaddr2 ip=10.0.0.99 sudo pcs -f cfg resource create fs Filesystem device="10.8.8.0:/mnt/nfs" directory="/var/opt/mssql/data" fstype="nfs" sudo pcs -f cfg constraint colocation add virtualip mssqlha sudo pcs -f cfg constraint colocation add fs mssqlha sudo pcs cluster cib-push cfgUne fois la configuration envoyée, SQL Server démarre sur un nœud.
Vérifiez que SQL Server a démarré.
sudo pcs statusLes exemples suivants affichent les résultats quand Pacemaker a démarré avec succès une instance en cluster de SQL Server.
fs (ocf::heartbeat:Filesystem): Started sqlfcivm1 virtualip (ocf::heartbeat:IPaddr2): Started sqlfcivm1 mssqlha (ocf::mssql:fci): Started sqlfcivm1 PCSD Status: sqlfcivm1: Online sqlfcivm2: Online Daemon Status: corosync: active/disabled pacemaker: active/enabled pcsd: active/enabled