Complément SharePoint : exemple de documents chargés en bloc
Remarque
L’exemple charge un fichier vers une bibliothèque de documents. Pour télécharger plusieurs fichiers, vous devez étendre l’exemple.
Le complément exemple Core.BulkDocumentUploader utilise une application console pour charger des fichiers à l’aide d’appels de l’API REST. Les paramètres de configuration sont spécifiés dans un fichier XML et un fichier CSV.
Utilisez cette solution si vous souhaitez :
- Télécharger vos fichiers vers SharePoint Online.
- Migrer vers Office 365 et utiliser un outil de migration personnalisé pour déplacer vos fichiers.
Avant de commencer
Pour commencer, téléchargez le complément exempleCore.BulkDocumentUploader à partir du projet Pratiques et modèles Office 365 Developer sur GitHub.
Remarque
Le code dans cet article est fourni tel quel, sans garantie d’aucune sorte, expresse ou implicite, y compris mais sans s’y limiter, aucune garantie implicite d’adéquation à un usage particulier, à une qualité marchande ou une absence de contrefaçon.
Avant d’exécuter cet exemple de code, procédez comme suit :
Modifier le fichier OneDriveUploader.xml avec les informations suivantes :
- L’emplacement dans lequel vous voulez enregistrer vos fichiers journaux texte et CSV.
- Le chemin d’accès de fichier vers votre fichier de mappage CSV (par exemple, C:\PnP\Samples\Core.BulkDocumentUploader\Input\SharePointSites.csv).
- L’emplacement des fichiers de stratégie d’entreprise à charger (par exemple, C:\PnP\Samples\Core.BulkDocumentUploader\Input\OneDriveFiles).
- Vos informations d’identification SharePoint Online.
- L’action de document à exécuter (téléchargement ou suppression).
- Le nouveau nom de fichier à appliquer au fichier une fois que le fichier est chargé dans la bibliothèque de documents (par exemple, DOCUMENT DE STRATÉGIE ENTREPRISE.xlsx).
Dans le fichier de mappage SharePointSites.csv, listez l’URL de la bibliothèque de document où télécharger des fichiers et le nom du fichier de stratégie d’entreprise à charger.
Ajoutez le chemin d’accès du fichier OneDriveUploader.xml comme argument de ligne de commande. Pour ce faire, ouvrez les propriétés du projet Core.BulkDocumentUploader dans l’Explorateur de solutions, puis choisissez Propriétés>Débogage.
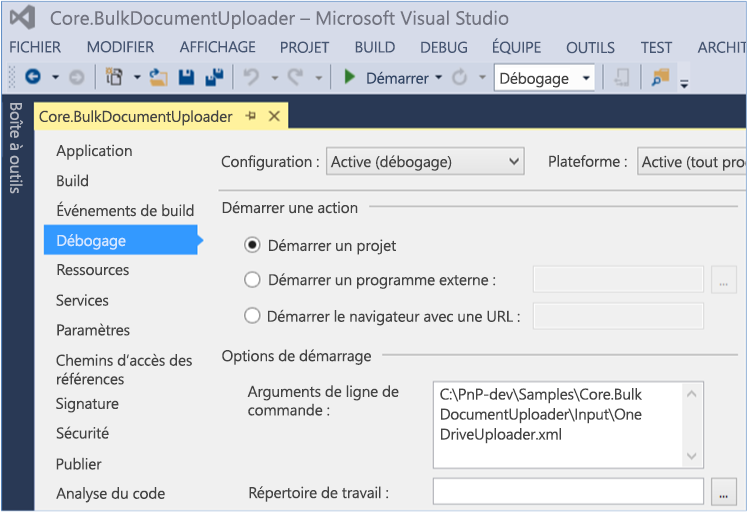
Utiliser le complément exemple Core.BulkDocumentUploader
À partir de la méthode Main dans Program.cs, la méthode RecurseActions appelle la méthode Run dans OneDriveMapper.cs. La méthode Run obtient l’emplacement du fichier à charger à partir de SharePointSites.csv, puis appelle la méthode IterateCollection.
public override void Run(BaseAction parentAction, DateTime CurrentTime, LogHelper logger)
{
CsvProcessor csvProcessor = new CsvProcessor();
logger.LogVerbose(string.Format("Attempting to read mapping CSV file '{0}'", this.UserMappingCSVFile));
using (StreamReader reader = new StreamReader(this.UserMappingCSVFile))
{
csvProcessor.Execute(reader, (entries, y) => { IterateCollection(entries, logger); }, logger);
}
}
Le fichier SharePointSite.csv répertorie un fichier à télécharger et la bibliothèque de documents où le télécharger. La méthode IterateCollection effectue ensuite les opérations suivantes pour charger le fichier dans la bibliothèque de documents :
Choisit le fichier à télécharger.
Vérifie que l’utilisateur dispose des autorisations pour ajouter des éléments.
Crée l’objet HttpWebRequest avec le cookie d’authentification, la chaîne de requête REST pour télécharger le document et la méthode d’action de requête HTTP.
Effectue le téléchargement de fichier.
Remarque
Le nom du fichier est écrasé, remplacé par la valeur de FileUploadName spécifiée dans OneDriveUploader.xml.
public override void IterateCollection(Collection<string> entries, LogHelper logger)
{
Stopwatch IterationSW = new Stopwatch();
IterationSW.Start();
logger.LogVerbose(string.Format(CultureInfo.CurrentCulture, "Establishing context object to: '{0}'", entries[this.SiteIndex]));
try
{
// Use the context of the current iteration URL for current user item.
using (ClientContext context = new ClientContext(entries[this.SiteIndex]))
{
using (SecureString password = new SecureString())
{
foreach (char c in this.Password.ToCharArray())
{
password.AppendChar(c);
}
context.Credentials = new SharePointOnlineCredentials(this.UserName, password);
// Get the file to upload from the directory.
FileInfo theFileToUpload = new FileInfo(Path.Combine(this.DirectoryLocation + "\\", entries[this.FileIndex] + ".xlsx"));
logger.LogVerbose(string.Format(CultureInfo.CurrentCulture, "Attempting to {0} file {1}", this.DocumentAction, theFileToUpload));
// Ensure that the account has permissions to access.
BasePermissions perm = new BasePermissions();
perm.Set(PermissionKind.AddListItems);
ConditionalScope scope = new ConditionalScope(context, () => context.Web.DoesUserHavePermissions(perm).Value);
using(scope.StartScope())
{
Stopwatch tempSW = new Stopwatch();
tempSW.Start();
int success = 0;
while(tempSW.Elapsed.TotalSeconds < 20)
{
var digest = context.GetFormDigestDirect();
string cookie = ((SharePointOnlineCredentials)context.Credentials).GetAuthenticationCookie(new Uri(entries[this.SiteIndex])).TrimStart("SPOIDCRL=".ToCharArray());
using (Stream s = theFileToUpload.OpenRead())
{
// Define REST string request to upload document to context. This string specifies the Documents folder, but you can specify another document library.
string theTargetUri = string.Format(CultureInfo.CurrentCulture, "{0}/_api/web/lists/getByTitle('Documents')/RootFolder/Files/add(url='{1}',overwrite='true')?", entries[this.SiteIndex], this.FileUploadName);
// Define REST HTTP request object.
HttpWebRequest SPORequest = (HttpWebRequest)HttpWebRequest.Create(theTargetUri);
// Define HTTP request action method.
if (this.DocumentAction == "Upload")
{
SPORequest.Method = "POST";
}
else if (this.DocumentAction == "Delete")
{
SPORequest.Method = "DELETE";
}
else
{
logger.LogVerbose(string.Format(CultureInfo.CurrentCulture, "There was a problem with the HTTP request in DocumentAction attribute of XML file"));
throw new Exception("The HTTP Request operation is not supported, please check the value of DocumentAction in the XML file");
}
// Build out additional HTTP request details.
SPORequest.Accept = "application/json;odata=verbose";
SPORequest.Headers.Add("X-RequestDigest", digest.DigestValue);
SPORequest.ContentLength = s.Length;
SPORequest.ContentType = "application/octet-stream";
// Handle authentication to context through cookie.
SPORequest.CookieContainer = new CookieContainer();
SPORequest.CookieContainer.Add(new Cookie("SPOIDCRL", cookie, string.Empty, new Uri(entries[this.SiteIndex]).Authority));
// Perform file upload/deletion.
using (Stream requestStream = SPORequest.GetRequestStream())
{
s.CopyTo(requestStream);
}
// Get HTTP response to determine success of operation.
HttpWebResponse SPOResponse = (HttpWebResponse)SPORequest.GetResponse();
logger.LogVerbose(string.Format(CultureInfo.CurrentCulture, "Successfully '{0}' file {1}", this.DocumentAction, theFileToUpload));
logger.LogOutcome(entries[this.SiteIndex], "SUCCCESS");
success = 1;
// Dispose of the HTTP response.
SPOResponse.Close();
break;
}
}
tempSW.Stop();
if (success != 1)
{
throw new Exception("The HTTP Request operation exceeded the timeout of 20 seconds");
}
}
}
}
}
catch(Exception ex)
{
logger.LogVerbose(string.Format(CultureInfo.CurrentCulture, "There was an issue performing '{0}' on to the URL '{1}' with exception: {2}", this.DocumentAction, entries[this.SiteIndex], ex.Message));
logger.LogOutcome(entries[this.SiteIndex], "FAILURE");
}
finally
{
IterationSW.Stop();
logger.LogVerbose(string.Format(CultureInfo.CurrentCulture, "Completed processing URL:'{0}' in {1} seconds", entries[this.SiteIndex], IterationSW.ElapsedMilliseconds/1000));
}
}