Qu’est-ce qu’un plug-in ?
Les plug-ins sont un composant clé du noyau sémantique. Si vous avez déjà utilisé des plug-ins à partir d’extensions ChatGPT ou Copilot dans Microsoft 365, vous êtes déjà familiarisé avec eux. Avec les plug-ins, vous pouvez encapsuler vos API existantes dans une collection qui peut être utilisée par une IA. Cela vous permet de donner à votre IA la possibilité d’effectuer des actions qu’il ne serait pas en mesure de faire autrement.
En arrière-plan, le noyau sémantique tire parti de l'appel de fonction , une fonctionnalité native de la plupart des derniers LLMs, pour permettre aux LLMs d'effectuer du de planification et d'appeler vos API. Avec l'appel de fonction, les LLMs peuvent appeler une fonction spécifique. Le noyau sémantique marshale ensuite la requête à la fonction appropriée dans votre codebase et retourne les résultats au LLM afin que le LLM puisse générer une réponse finale.
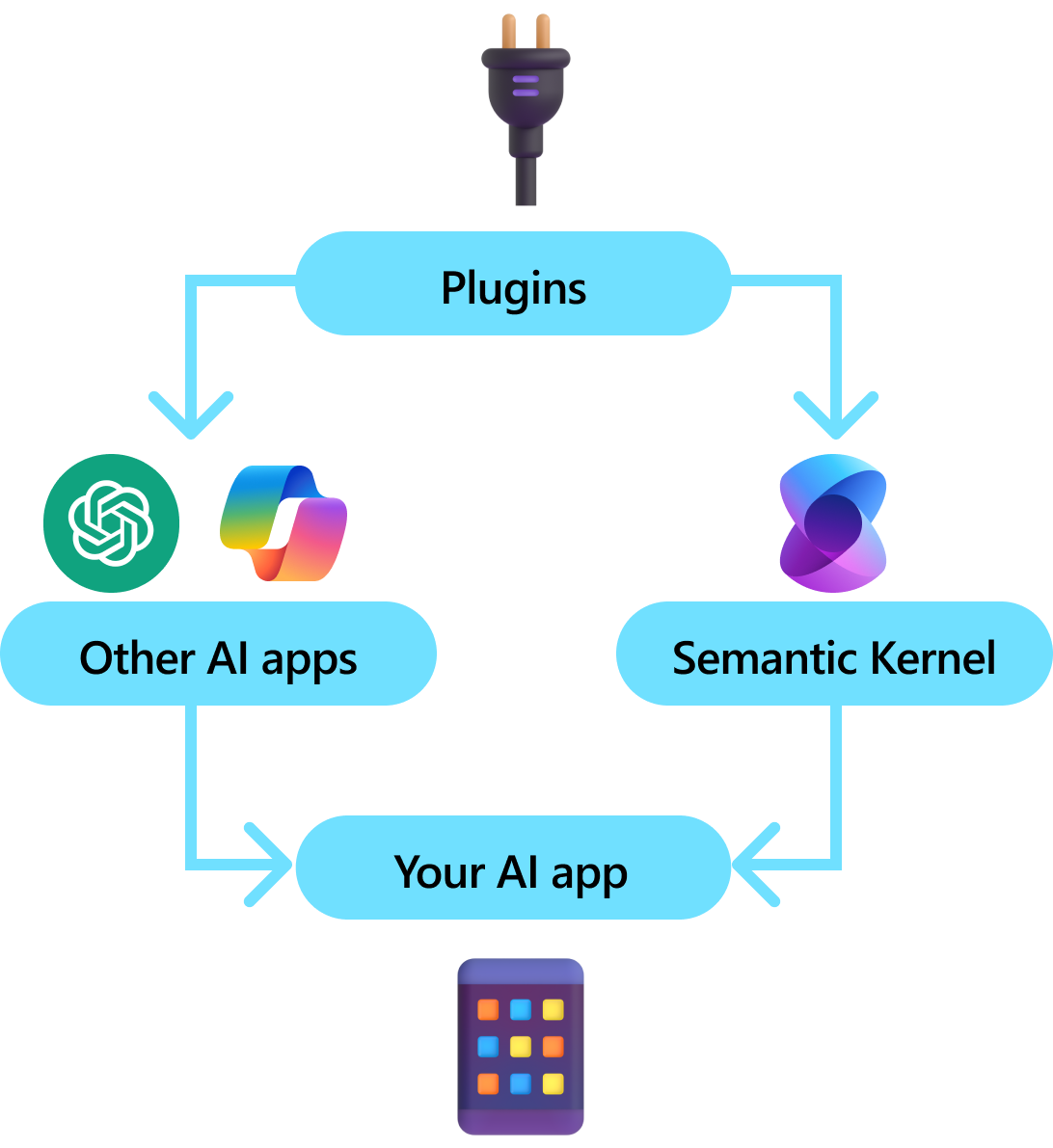
Tous les SDK IA n’ont pas un concept analogue aux modules complémentaires (la plupart ont simplement des fonctions ou des outils). Dans les scénarios d’entreprise, toutefois, les plug-ins sont utiles, car ils encapsulent un ensemble de fonctionnalités qui reflète la façon dont les développeurs d’entreprise développent déjà des services et des API. Les plug-ins jouent également bien avec l’injection de dépendances. Dans le constructeur d’un plug-in, vous pouvez injecter des services nécessaires pour effectuer le travail du plug-in (par exemple, connexions de base de données, clients HTTP, etc.). Cela est difficile à accomplir avec d’autres kits SDK qui manquent de plug-ins.
Anatomie d’un plug-in
À un niveau élevé, un plug-in est un groupe de fonctions qui peuvent être exposées aux applications et services IA. Les fonctions au sein des plug-ins peuvent ensuite être orchestrées par une application IA pour effectuer des requêtes utilisateur. Dans le noyau sémantique, vous pouvez appeler ces fonctions automatiquement grâce à l'appel de fonction.
Remarque
Dans d’autres plateformes, les fonctions sont souvent appelées « outils » ou « actions ». Dans le noyau sémantique, nous utilisons le terme « fonctions », car elles sont généralement définies comme fonctions natives dans votre codebase.
Cependant, fournir des fonctions uniquement n'est pas suffisant pour créer un plug-in. Pour alimenter l’orchestration automatique avec l’appel de fonction, les plug-ins doivent également fournir des détails qui décrivent sémantiquement leur comportement. Tout ce qui provient de l’entrée, de la sortie et des effets secondaires de la fonction doit être décrit de manière à ce que l’IA puisse comprendre, sinon, l’IA n’appelle pas correctement la fonction.
Par exemple, l’exemple de plug-in WriterPlugin à droite a des fonctions avec des descriptions sémantiques qui décrivent ce que fait chaque fonction. Un LLM peut ensuite utiliser ces descriptions pour choisir les meilleures fonctions à appeler pour répondre à la demande d’un utilisateur.
Dans l’image à droite, un LLM appellerait probablement les fonctions ShortPoem et StoryGen pour satisfaire la demande des utilisateurs grâce aux descriptions sémantiques fournies.
description sémantique 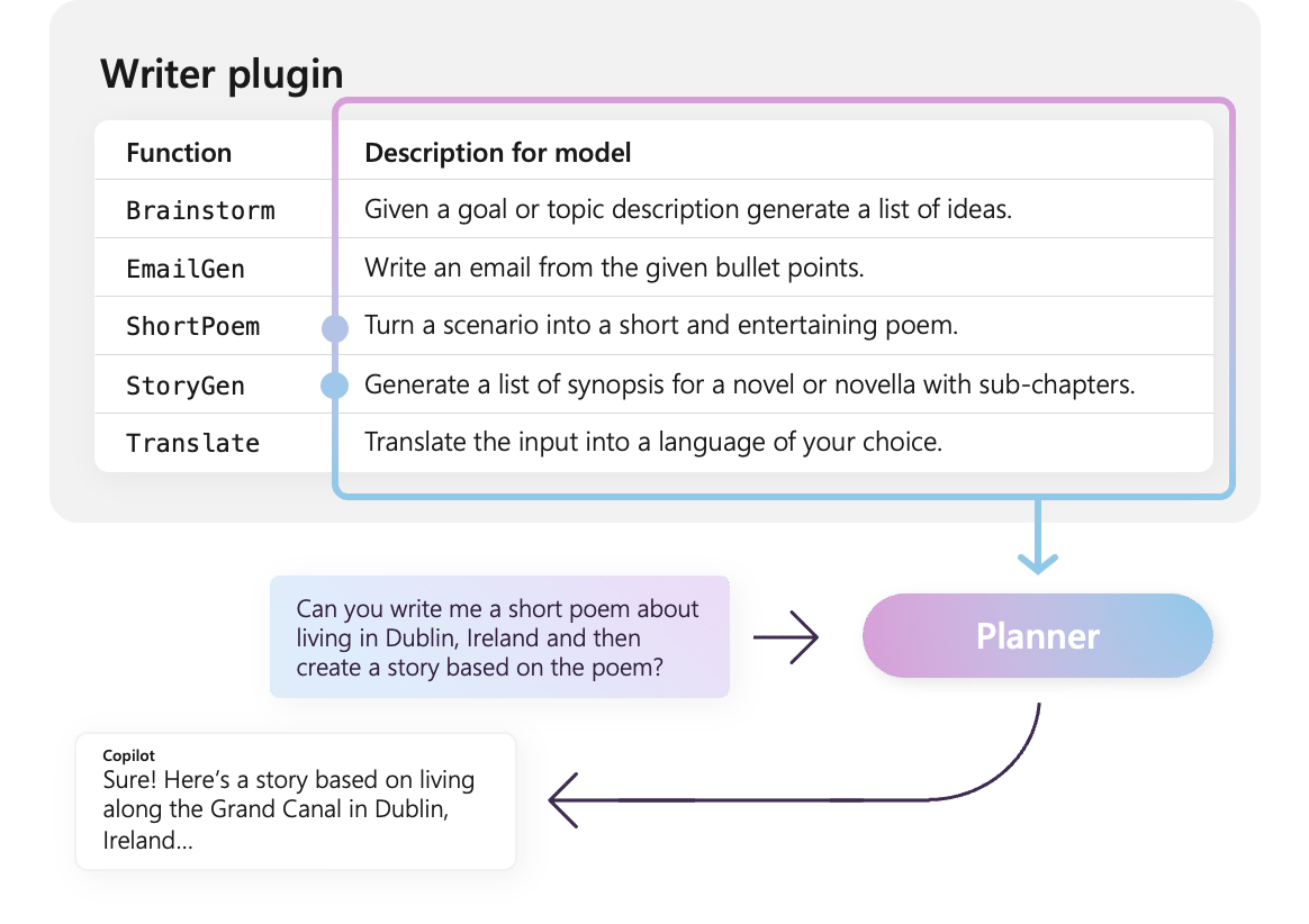
Importation de différents types de plug-ins
Il existe deux méthodes principales d’importation de plug-ins dans le noyau sémantique : à l’aide de code natif ou d’une spécification OpenAPI . L’ancien vous permet de créer des plug-ins dans votre base de code existante qui peuvent tirer parti des dépendances et des services que vous avez déjà. Ce dernier vous permet d’importer des plug-ins à partir d’une spécification OpenAPI, qui peut être partagée entre différents langages de programmation et plateformes.
Vous trouverez ci-dessous un exemple simple d’importation et d’utilisation d’un plug-in natif. Pour en savoir plus sur l’importation de ces différents types de plug-ins, consultez les articles suivants :
Pourboire
Lors de la prise en main, nous vous recommandons d’utiliser des plug-ins de code natif. À mesure que votre application arrive à maturité et que vous travaillez sur plusieurs équipes multiplateformes, vous pouvez envisager d’utiliser des spécifications OpenAPI pour partager des plug-ins entre différents langages et plateformes de programmation.
Les différents types de fonctions de plug-in
Dans un plug-in, vous aurez généralement deux types de fonctions différents, ceux qui récupèrent des données pour la récupération de génération augmentée (RAG) et celles qui automatisent les tâches. Bien que chaque type soit fonctionnellement identique, ils sont généralement utilisés différemment dans les applications qui utilisent le noyau sémantique.
Par exemple, avec les fonctions de récupération, vous pouvez utiliser des stratégies pour améliorer les performances (par exemple, la mise en cache et l’utilisation de modèles intermédiaires moins chers pour résumer). Alors qu'avec les fonctions d'automatisation des tâches, vous voudrez probablement implémenter des processus d'approbation avec une intervention humaine pour vous assurer que les tâches sont correctement effectuées.
Pour en savoir plus sur les différents types de fonctions de plug-in, consultez les articles suivants :
- fonctions de récupération de données
- fonctions d’automatisation des tâches
Prise en main des plug-ins
L’utilisation de plug-ins dans le noyau sémantique est toujours un processus en trois étapes :
- Définissez votre plug-in
- Ajoutez le module d'extension à votre noyau
- Et ensuite, soit invoquer les fonctions du plug-in dans une demande avec appel de fonction
Ci-dessous, nous allons fournir un exemple de haut niveau d’utilisation d’un plug-in dans le noyau sémantique. Pour plus d’informations sur la création et l’utilisation de plug-ins, reportez-vous aux liens ci-dessus.
1) Définir votre plug-in
Le moyen le plus simple de créer un plug-in consiste à définir une classe et à annoter ses méthodes avec l’attribut KernelFunction. Cela indique au Semantic Kernel qu’il s’agit d’une fonction pouvant être appelée par une IA ou référencée dans une invite.
Vous pouvez également importer des plug-ins à partir d’une spécification OpenAPI .
Ci-dessous, nous allons créer un plug-in qui peut récupérer l’état des lumières et modifier son état.
Pourboire
Étant donné que la plupart des LLM ont été entraînés avec Python pour l’appel de fonction, il est recommandé d’utiliser la casse serpent pour les noms de fonctions et les noms de propriétés même si vous utilisez le kit sdk C# ou Java.
using System.ComponentModel;
using Microsoft.SemanticKernel;
public class LightsPlugin
{
// Mock data for the lights
private readonly List<LightModel> lights = new()
{
new LightModel { Id = 1, Name = "Table Lamp", IsOn = false, Brightness = 100, Hex = "FF0000" },
new LightModel { Id = 2, Name = "Porch light", IsOn = false, Brightness = 50, Hex = "00FF00" },
new LightModel { Id = 3, Name = "Chandelier", IsOn = true, Brightness = 75, Hex = "0000FF" }
};
[KernelFunction("get_lights")]
[Description("Gets a list of lights and their current state")]
[return: Description("An array of lights")]
public async Task<List<LightModel>> GetLightsAsync()
{
return lights
}
[KernelFunction("get_state")]
[Description("Gets the state of a particular light")]
[return: Description("The state of the light")]
public async Task<LightModel?> GetStateAsync([Description("The ID of the light")] int id)
{
// Get the state of the light with the specified ID
return lights.FirstOrDefault(light => light.Id == id);
}
[KernelFunction("change_state")]
[Description("Changes the state of the light")]
[return: Description("The updated state of the light; will return null if the light does not exist")]
public async Task<LightModel?> ChangeStateAsync(int id, LightModel LightModel)
{
var light = lights.FirstOrDefault(light => light.Id == id);
if (light == null)
{
return null;
}
// Update the light with the new state
light.IsOn = LightModel.IsOn;
light.Brightness = LightModel.Brightness;
light.Hex = LightModel.Hex;
return light;
}
}
public class LightModel
{
[JsonPropertyName("id")]
public int Id { get; set; }
[JsonPropertyName("name")]
public string Name { get; set; }
[JsonPropertyName("is_on")]
public bool? IsOn { get; set; }
[JsonPropertyName("brightness")]
public byte? Brightness { get; set; }
[JsonPropertyName("hex")]
public string? Hex { get; set; }
}
from typing import TypedDict, Annotated
class LightModel(TypedDict):
id: int
name: str
is_on: bool | None
brightness: int | None
hex: str | None
class LightsPlugin:
lights: list[LightModel] = [
{"id": 1, "name": "Table Lamp", "is_on": False, "brightness": 100, "hex": "FF0000"},
{"id": 2, "name": "Porch light", "is_on": False, "brightness": 50, "hex": "00FF00"},
{"id": 3, "name": "Chandelier", "is_on": True, "brightness": 75, "hex": "0000FF"},
]
@kernel_function
async def get_lights(self) -> Annotated[list[LightModel], "An array of lights"]:
"""Gets a list of lights and their current state."""
return self.lights
@kernel_function
async def get_state(
self,
id: Annotated[int, "The ID of the light"]
) -> Annotated[LightModel | None], "The state of the light"]:
"""Gets the state of a particular light."""
for light in self.lights:
if light["id"] == id:
return light
return None
@kernel_function
async def change_state(
self,
id: Annotated[int, "The ID of the light"],
new_state: LightModel
) -> Annotated[Optional[LightModel], "The updated state of the light; will return null if the light does not exist"]:
"""Changes the state of the light."""
for light in self.lights:
if light["id"] == id:
light["is_on"] = new_state.get("is_on", light["is_on"])
light["brightness"] = new_state.get("brightness", light["brightness"])
light["hex"] = new_state.get("hex", light["hex"])
return light
return None
public class LightsPlugin {
// Mock data for the lights
private final Map<Integer, LightModel> lights = new HashMap<>();
public LightsPlugin() {
lights.put(1, new LightModel(1, "Table Lamp", false));
lights.put(2, new LightModel(2, "Porch light", false));
lights.put(3, new LightModel(3, "Chandelier", true));
}
@DefineKernelFunction(name = "get_lights", description = "Gets a list of lights and their current state")
public List<LightModel> getLights() {
System.out.println("Getting lights");
return new ArrayList<>(lights.values());
}
@DefineKernelFunction(name = "change_state", description = "Changes the state of the light")
public LightModel changeState(
@KernelFunctionParameter(name = "id", description = "The ID of the light to change") int id,
@KernelFunctionParameter(name = "isOn", description = "The new state of the light") boolean isOn) {
System.out.println("Changing light " + id + " " + isOn);
if (!lights.containsKey(id)) {
throw new IllegalArgumentException("Light not found");
}
lights.get(id).setIsOn(isOn);
return lights.get(id);
}
}
Notez que nous fournissons des descriptions pour la fonction, la valeur de retour et les paramètres. Il est important pour l’IA de comprendre ce que fait la fonction et comment l’utiliser.
Pourboire
N'ayez pas peur de fournir des descriptions détaillées pour vos fonctions si une IA éprouve des difficultés à les appeler. Exemples de faible portée, recommandations sur quand utiliser (ou ne pas utiliser) la fonction, et des conseils sur comment obtenir les paramètres requis peuvent tous être utiles.
2) Ajouter le plug-in à votre noyau
Une fois que vous avez défini votre plug-in, vous pouvez l’ajouter à votre noyau en créant une nouvelle instance du plug-in et en l’ajoutant à la collection de plug-ins du noyau.
Cet exemple illustre le moyen le plus simple d’ajouter une classe en tant que plug-in avec la méthode AddFromType. Pour en savoir plus sur les autres façons d’ajouter des plug-ins, reportez-vous à l’article l’ajout de plug-ins natifs.
var builder = new KernelBuilder();
builder.Plugins.AddFromType<LightsPlugin>("Lights")
Kernel kernel = builder.Build();
kernel = Kernel()
kernel.add_plugin(
LightsPlugin(),
plugin_name="Lights",
)
// Import the LightsPlugin
KernelPlugin lightPlugin = KernelPluginFactory.createFromObject(new LightsPlugin(),
"LightsPlugin");
// Create a kernel with Azure OpenAI chat completion and plugin
Kernel kernel = Kernel.builder()
.withAIService(ChatCompletionService.class, chatCompletionService)
.withPlugin(lightPlugin)
.build();
3) Appeler les fonctions du plug-in
Enfin, vous pouvez avoir l’IA appeler les fonctions de votre plug-in à l’aide de l’appel de fonctions. Voici un exemple qui montre comment coaxer l’IA pour appeler la fonction get_lights à partir du plug-in Lights avant d’appeler la fonction change_state pour activer une lumière.
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.ChatCompletion;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Create a kernel with Azure OpenAI chat completion
var builder = Kernel.CreateBuilder().AddAzureOpenAIChatCompletion(modelId, endpoint, apiKey);
// Build the kernel
Kernel kernel = builder.Build();
var chatCompletionService = kernel.GetRequiredService<IChatCompletionService>();
// Add a plugin (the LightsPlugin class is defined below)
kernel.Plugins.AddFromType<LightsPlugin>("Lights");
// Enable planning
OpenAIPromptExecutionSettings openAIPromptExecutionSettings = new()
{
FunctionChoiceBehavior = FunctionChoiceBehavior.Auto()
};
// Create a history store the conversation
var history = new ChatHistory();
history.AddUserMessage("Please turn on the lamp");
// Get the response from the AI
var result = await chatCompletionService.GetChatMessageContentAsync(
history,
executionSettings: openAIPromptExecutionSettings,
kernel: kernel);
// Print the results
Console.WriteLine("Assistant > " + result);
// Add the message from the agent to the chat history
history.AddAssistantMessage(result);
import asyncio
from semantic_kernel import Kernel
from semantic_kernel.functions import kernel_function
from semantic_kernel.connectors.ai.open_ai import AzureChatCompletion
from semantic_kernel.connectors.ai.function_choice_behavior import FunctionChoiceBehavior
from semantic_kernel.connectors.ai.chat_completion_client_base import ChatCompletionClientBase
from semantic_kernel.contents.chat_history import ChatHistory
from semantic_kernel.functions.kernel_arguments import KernelArguments
from semantic_kernel.connectors.ai.open_ai.prompt_execution_settings.azure_chat_prompt_execution_settings import (
AzureChatPromptExecutionSettings,
)
async def main():
# Initialize the kernel
kernel = Kernel()
# Add Azure OpenAI chat completion
chat_completion = AzureChatCompletion(
deployment_name="your_models_deployment_name",
api_key="your_api_key",
base_url="your_base_url",
)
kernel.add_service(chat_completion)
# Add a plugin (the LightsPlugin class is defined below)
kernel.add_plugin(
LightsPlugin(),
plugin_name="Lights",
)
# Enable planning
execution_settings = AzureChatPromptExecutionSettings()
execution_settings.function_call_behavior = FunctionChoiceBehavior.Auto()
# Create a history of the conversation
history = ChatHistory()
history.add_message("Please turn on the lamp")
# Get the response from the AI
result = await chat_completion.get_chat_message_content(
chat_history=history,
settings=execution_settings,
kernel=kernel,
)
# Print the results
print("Assistant > " + str(result))
# Add the message from the agent to the chat history
history.add_message(result)
# Run the main function
if __name__ == "__main__":
asyncio.run(main())
// Enable planning
InvocationContext invocationContext = new InvocationContext.Builder()
.withReturnMode(InvocationReturnMode.LAST_MESSAGE_ONLY)
.withToolCallBehavior(ToolCallBehavior.allowAllKernelFunctions(true))
.build();
// Create a history to store the conversation
ChatHistory history = new ChatHistory();
history.addUserMessage("Turn on light 2");
List<ChatMessageContent<?>> results = chatCompletionService
.getChatMessageContentsAsync(history, kernel, invocationContext)
.block();
System.out.println("Assistant > " + results.get(0));
Avec le code ci-dessus, vous devez obtenir une réponse qui ressemble à ce qui suit :
| Rôle | Message |
|---|---|
| 🔵 utilisateur | S’il vous plaît activer la lampe |
| 🔴 Assistant (appel de fonction) | Lights.get_lights() |
| 🟢 outil | [{ "id": 1, "name": "Table Lamp", "isOn": false, "brightness": 100, "hex": "FF0000" }, { "id": 2, "name": "Porch light", "isOn": false, "brightness": 50, "hex": "00FF00" }, { "id": 3, "name": "Chandelier", "isOn": true, "brightness": 75, "hex": "0000FF" }] |
| 🔴 Assistant (appel de fonction) | Lights.change_state(1, { « isOn » : true }) |
| 🟢 outil | { "id": 1, "name": "Table Lamp", "isOn": true, "brightness": 100, "hex": "FF0000" } |
| 🔴 Assistant | La lampe est maintenant allumée |
Pourboire
Bien que vous puissiez appeler directement une fonction de plug-in, cela n’est pas recommandé, car l’IA doit être celle qui décide des fonctions à appeler. Si vous avez besoin d’un contrôle explicite sur les fonctions appelées, envisagez d’utiliser des méthodes standard dans votre codebase au lieu de plug-ins.
Recommandations générales pour la création de plug-ins
Compte tenu du fait que chaque scénario a des exigences uniques, utilise des conceptions de plug-in distinctes et peut incorporer plusieurs llMs, il est difficile de fournir un guide unique pour la conception du plug-in. Toutefois, vous trouverez ci-dessous quelques recommandations générales et lignes directrices pour vous assurer que les plug-ins sont adaptés pour l’IA et peuvent être facilement et efficacement exploités par les modèles de langage LLM.
Importer uniquement les plug-ins nécessaires
Importez uniquement les plug-ins qui contiennent des fonctions nécessaires pour votre scénario spécifique. Cette approche réduira non seulement le nombre de jetons d’entrée consommés, mais minimisera également l’occurrence d’appels incorrects à des fonctions qui ne sont pas utilisées dans le scénario. Dans l’ensemble, cette stratégie doit améliorer la précision des appels de fonction et diminuer le nombre de faux positifs.
En outre, OpenAI vous recommande d’utiliser plus de 20 outils dans un seul appel d’API ; idéalement, pas plus de 10 outils. Comme indiqué par OpenAI : « Nous vous recommandons d’utiliser pas plus de 20 outils dans un seul appel d’API. Les développeurs voient généralement une réduction de la capacité du modèle à sélectionner l’outil approprié une fois qu’ils ont défini entre 10 et 20 outils. »* Pour plus d’informations, vous pouvez consulter leur documentation à Guide d’appel de fonction OpenAI.
Rendre les plug-ins compatibles avec l’IA
Pour améliorer la capacité de LLM à comprendre et à utiliser les plug-ins, il est recommandé de suivre ces instructions :
Utiliser des noms de fonction descriptifs et concis : Assurez-vous que les noms de fonctions transmettent clairement leur objectif pour aider le modèle à comprendre quand sélectionner chaque fonction. Si un nom de fonction est ambigu, envisagez de le renommer pour plus de clarté. Évitez d’utiliser des abréviations ou des acronymes pour raccourcir les noms de fonction. Utilisez le
DescriptionAttributepour fournir un contexte et des instructions supplémentaires uniquement si nécessaire, ce qui réduit la consommation des jetons.Réduire les paramètres de fonction : Limiter le nombre de paramètres de fonction et utiliser des types primitifs dans la mesure du possible. Cette approche réduit la consommation de jetons et simplifie la signature de fonction, ce qui permet au LLM de mieux faire correspondre les paramètres de fonction.
Nommez clairement les paramètres de fonction : Attribuer des noms descriptifs aux paramètres de fonction pour clarifier leur objectif. Évitez d’utiliser des abréviations ou des acronymes pour raccourcir les noms de paramètres, car cela aidera le LLM à raisonner sur les paramètres et à fournir des valeurs précises. Comme avec les noms de fonction, utilisez le
DescriptionAttributeuniquement si nécessaire pour réduire la consommation de jetons.
Trouver un juste équilibre entre le nombre de fonctions et leurs responsabilités
D’une part, avoir des fonctions avec une responsabilité unique est une bonne pratique qui permet de conserver des fonctions simples et réutilisables dans plusieurs scénarios. En revanche, chaque appel de fonction entraîne une surcharge en termes de latence d’aller-retour réseau et du nombre de jetons d’entrée et de sortie consommés : les jetons d’entrée sont utilisés pour envoyer la définition de fonction et l’appel au LLM, tandis que les jetons de sortie sont consommés lors de la réception de l’appel de fonction à partir du modèle.
Vous pouvez également implémenter une fonction unique avec plusieurs responsabilités pour réduire le nombre de jetons consommés et réduire la surcharge réseau, bien que cela soit dû à une réduction de la réutilisation dans d’autres scénarios.
Toutefois, la consolidation de nombreuses responsabilités dans une fonction unique peut augmenter le nombre et la complexité des paramètres de fonction et son type de retour. Cette complexité peut entraîner des situations où le modèle peut avoir du mal à correspondre correctement aux paramètres de fonction, ce qui entraîne des paramètres ou des valeurs manqués de type incorrect. Par conséquent, il est essentiel d’établir un juste équilibre entre le nombre de fonctions afin de réduire la surcharge réseau et le nombre de responsabilités dont chaque fonction a, ce qui garantit que le modèle peut correspondre avec précision aux paramètres de fonction.
Transformer des fonctions de noyau sémantique
Utilisez les techniques de transformation pour les fonctions de noyau sémantique, comme décrit dans Transformant les fonctions de noyau sémantique billet de blog pour :
Modifier le comportement de la fonction : Il existe des scénarios où le comportement par défaut d’une fonction peut ne pas s’aligner sur le résultat souhaité et qu’il n’est pas possible de modifier l’implémentation de la fonction d’origine. Dans ce cas, vous pouvez créer une fonction qui encapsule l’original et modifie son comportement en conséquence.
Fournissez des informations de contexte : Functions peut nécessiter des paramètres que le LLM ne peut pas ou ne doit pas déduire. Par exemple, si une fonction doit agir pour le compte de l’utilisateur actuel ou nécessite des informations d’authentification, ce contexte est généralement disponible pour l’application hôte, mais pas pour le LLM. Dans de tels cas, vous pouvez transformer la fonction pour appeler la fonction originale tout en fournissant les informations de contexte nécessaires à partir de l’application d’hébergement, ainsi que les arguments fournis par le LLM.
Modifier la liste des paramètres, les types et les noms : Si la fonction d’origine a une signature complexe que le LLM lutte pour interpréter, vous pouvez transformer la fonction en une avec une signature plus simple que le LLM peut comprendre plus facilement. Cela peut impliquer la modification des noms de paramètres, des types, du nombre de paramètres et de l’aplatissement ou de l’atténuation des paramètres complexes, entre autres ajustements.
Utilisation de l’état local
Lors de la conception de plug-ins qui fonctionnent sur des jeux de données relativement volumineux ou confidentiels, tels que des documents, des articles ou des e-mails contenant des informations sensibles, envisagez d’utiliser l’état local pour stocker les données d’origine ou les résultats intermédiaires qui n’ont pas besoin d’être envoyés au LLM. Les fonctions de ces scénarios peuvent accepter et retourner un ID d’état, ce qui vous permet de rechercher et d’accéder aux données localement au lieu de passer les données réelles au LLM, uniquement pour la recevoir en tant qu’argument pour l’appel de fonction suivant.
En stockant des données localement, vous pouvez conserver les informations privées et sécurisées tout en évitant la consommation inutile de jetons pendant les appels de fonction. Cette approche améliore non seulement la confidentialité des données, mais améliore également l’efficacité globale dans le traitement de jeux de données volumineux ou sensibles.