QUESTIONS ET RÉPONSES SQL Sauvegarde compression, la redirection de clients avec la mise en miroir et bien plus encore
Paul S. Randal
q: nous allons être mise à niveau la plupart de nos serveurs vers SQL Server 2008, et une des fonctionnalités que je recherche vers l'avant à placer dans la production est compression sauvegarde. Je sais que je pouvez l'activer par défaut pour toutes les bases de données sur chaque serveur, mais j'ai entendu que je ne souhaitez peut-être faire pas. Je ne sais pas pourquoi je ne souhaite que la fonction activée par défaut, comme il semble que j'ai rien à perdre. Pouvez vous vous expliquer le raisonnement derrière ce que j'ai entendu ?
A la réponse est Mes favoris vivace : elle dépend. Laissez-moi donner certaines notions pour expliquer.
L'essentiel à prendre en considération est le taux de compression chaque sauvegarde de base de données aura lorsque la sauvegarde la compression est activée. Le taux de tout être compressé par n'importe quel algorithme de compression est déterminé par les données réelles est compressées.
Vous recherchez des conseils SQL Server ?
Pour obtenir des conseils sur SQL Server, visitez le Conseils SQL Server Magazine TechNet page.
Pour plus de conseils sur d'autres produits, visitez le Index TechNet Magazine pourboires.
Des données aléatoires (entier petit valeurs, par exemple) ne compresse pas très bien, afin que la valeur des tables et index dans la base de données va déterminer, pour l'essentiel, le taux de compression qui peut être atteinte.
Voici quelques exemples de lors de la compression sauvegarde peut ne pas produire un taux de compression élevé :
- Si la base de données comporte chiffrement des données transparent activé, puis le taux de compression sera très faible car les données compressées en cours sont des valeurs aléatoires petites.
- Si la plupart des données dans la base de données est chiffré au niveau colonne, puis le taux de compression sera faible, nouveau car le chiffrement de colonne randomizes essentiellement les données.
- Si la plupart des tables de la base de données compression des données activée, puis le taux de compression sera faible ; compression des données qui sont déjà principalement compressées généralement a peu d'effet.
Dans le cas lorsque le taux de compression est faible, le problème est pas le faible taux, mais le fait que les ressources du processeur sont utilisées pour exécuter l'algorithme de compression pour aucun gain. Quel degré un bloc de données peut être compressé, ressources du processeur sont toujours utilisées pour exécuter les algorithmes de compression et de décompression.
Cela signifie que vous devez vérifier le bon fonctionnement chaque base de données compresse dans une sauvegarde avant de décider à utiliser la compression sauvegarde pour cette base de données tout le temps. Sinon, vous pouvez éventuellement être perdre ressources du processeur. Ceci est la base de ce que vous avez entendu.
Pour résumer, si la majorité des bases de données tirera parti de compression de sauvegarde, il est judicieux pour activer la compression de sauvegarde au niveau du serveur et modifier manuellement les quelques tâches de sauvegarde spécifiquement utiliser l'option WITH NO_COMPRESSION. Sinon, si la majorité des bases de données bénéficieront pas de compression de sauvegarde, il est judicieux de laisser compression sauvegarde désactivée au niveau du serveur et modifier manuellement quelques tâches de sauvegarde spécifiquement utiliser l'option WITH COMPRESSION.
mise à q: année précédente nous niveau notre bases de données ont la mise en miroir de base de données afin que cas d'un échec, nous puissent basculement sur le miroir et l'application continue. Pendant que nous ont été création du système, nous entraîné effectuant des basculements de la base de données et tout fonctionnait correctement. Semaine dernière, nous avions un échec réel et le basculement de la base de données s'est produite, mais toutes les transactions application arrêtées et l'application n'a pas à se connecter au serveur de basculement. Dans le futur, comment peuvent je configurer SQL Server afin que qu'il n'est pas supprimer les connexions d'application pendant le basculement les transactions peuvent continuer ?
A Laissez-moi décomposer en deux parties, comment les applications puissent faire face basculements et comment gérer la redirection de clients avec la mise en miroir de base de données.
Lorsqu'un basculement se produit en utilisant les technologies haute disponibilité disponibles avec SQL Server, la connexion client vers le serveur a échoué est interrompue et les transactions de l'exécution sont perdues. Il est impossible de migrer une transaction entre les serveurs de l'exécution (dans une situation de basculement ou autre). En fonction de la technologie de haute disponibilité, la transaction de l'exécution soit n'existe pas du tout sur le serveur de basculement ou il existe en tant que l'exécution transaction mais est annulée cadre du processus pour importer la base de données en ligne sur le serveur de basculement de.
Avec tenir compte pour la mise en miroir, de base de données en permanence fourni enregistrements de journal des transactions à partir du serveur principal au serveur miroir, il est généralement de ce dernier cas, les transactions de l'exécution sont annulées dans Importation de la base de miroir données en ligne que l'entité de nouveau.
Par conséquent, sont deux choses une application doit pouvoir faire correctement lorsque exécuté sur un serveur avec la possibilité d'avoir à basculement vers un autre serveur :
- Il doit pouvoir gérer correctement la connexion au serveur en cours de suppression et réessayez de reconnecter après un intervalle de temps petit.
- Il doit être capables de gérer correctement une transaction est annulée et puis recommencer la transaction après une connexion est établie avec le serveur de basculement (éventuellement en utilisant un gestionnaire de transactions intermédiaires).
La seulement haute disponibilité technologie ici, qui ne nécessite aucun changement de client spécifiquement pour autoriser la redirection de la connexion client après un basculement est Gestion de clusters avec basculement. Clients de se connecter à un nom de serveur virtuel et sont en toute transparence redirigés vers n'importe quel nœud de cluster physique est actif.
Avec les technologies haute disponibilité, telles que l'envoi de journaux et de la réplication, le nom de serveur du serveur de basculement est différent, qui signifie que ce manuel de la redirection de connexions client est nécessaire après un basculement. Cette redirection manuelle peut être effectuée de plusieurs manières :
- Vous pouvez coder en dur le nom du serveur avec basculement dans le client pour la tentative de reconnexion au serveur de basculement est effectuée.
- Vous pouvez utiliser équilibrage de la charge réseau avec un 100/0, 0/100 configuration, qui permettra ensuite de la connexion à être passé au serveur de basculement.
- Vous pouvez utiliser quelque chose comme un alias de nom de serveur ou de changement des entrées dans une table DNS.
Avec la mise en miroir de base de données, une des ces options fonctionne. Mais la mise en miroir de base de données a également fonctionnalités direction client intégré. La chaîne de connexion cliente est en mesure d'explicitement spécifier le nom du serveur miroir, et si le serveur principal ne peut pas être contacté, le miroir est ensuite automatiquement essayé. Ce processus est appelé redirection explicite.
Si ne peut pas être modifiée la chaîne de connexion cliente, puis redirection implicite peut être possible si le serveur a échoué s'exécute maintenant en tant que le serveur miroir. Les connexions seront automatiquement redirigées vers l'entité de nouveau, mais cela ne fonctionne que si le serveur miroir est en cours d'exécution.
Le livre blanc SQL Server 2005 » L'implémentation de basculement d'application avec mise en miroir de base de données« présente ces options de manière plus détaillée.
q: nous avons mis lorsque à niveau vers SQL Server 2005, réinventé nous nos tables grands pour être partitionnée, ce qui nous peut tirer parti de maintenance partitionnée et le mécanisme faisant glisser la fenêtre. Vous cette décrite dans le versement 2008 août " Partitionnement, vérifications de cohérence et bien plus encore"). Mais nous avons a rencontré un problème. Il peut arriver que des requêtes simultanées application rencontrez blocage sur l'ensemble du tableau lorsque vous les requêtes ne sont pas encore accédez les mêmes partitions. J'ai entendu que SQL Server 2008 résout ce problème, pouvez vous Veuillez expliquer comment J'AI pouvez arrêter ce blocage ?
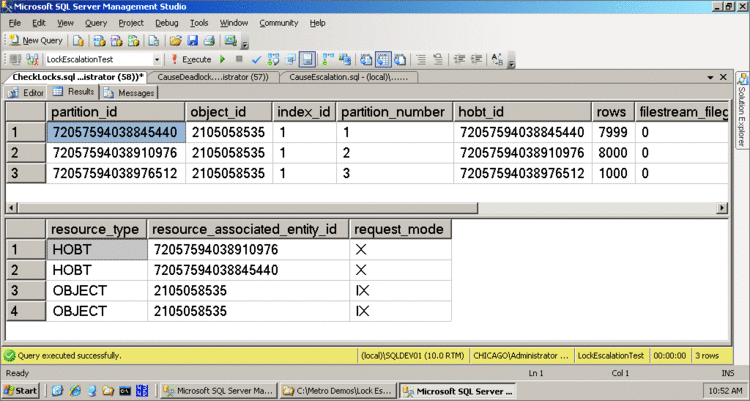
Figure 1 Examen des verrous sur une table partitionnée
A le problème vous vous voyez est provoqué par un mécanisme appelé promotion de verrous. SQL Server acquiert des verrous sur des données pour les protéger lorsqu'une requête est lire ou écrire les données. Il peut acquérir des verrous sur tables entières, les pages du fichier de données ou lignes de tableau individuels/index et chaque verrou occupe un peu de mémoire.
Si une requête génère trop de verrous être acquis, SQL Server pouvez décider de remplacer tous les verrous de lignes ou les pages dans une table un verrou unique sur toute la table (le seuil, lorsque cela se produit, est environ 5 000 verrous, mais l'algorithme exacte est complexe et configurable). Ce processus est appelé escalade du verrouillage.
Dans SQL Server 2005, si une requête fonctionne sur une partition unique d'une table et entraîne suffisamment verrous à prendre pour déclencher l'escalade du verrouillage, puis la table entière est verrouillée. Cela peut empêcher requête B fonctionner sur une partition différente de la même table. Par conséquent, la requête B est bloquée jusqu'à ce qu'une requête terminée et ses verrous sont ignorés.
Dans SQL Server 2008, le mécanisme d'escalade verrouillage a été amélioré pour permettre une table pour avoir escalade du verrouillage au niveau de partition. Utilisez l'exemple ci-dessus, cela signifie que la promotion de verrouillage provoquée par la requête QU'A serait verrouiller uniquement la requête à partition unique A est à l'aide, plutôt que la table entière.
Requête B pourront ensuite fonctionner sur une autre partition sans être bloqué. Requête B même déclenche escalade de verrouillage, qui serait puis verrouillez simplement la partition cette requête que B fonctionne, plutôt que la table entière.
Ce modèle d'escalade du verrouillage peut être définie à l'aide de la syntaxe suivante :
ALTER TABLE MyTable SET (LOCK_ESCALATION = AUTO);
GO
Cette syntaxe force le Gestionnaire de verrouillage SQL Server pour utiliser escalade du verrouillage au niveau de partition si la table est partitionnée et escalade de verrouillage de table-niveau normal si la table est partitionnée pas. Le comportement par défaut consiste à utiliser promotion de verrou au niveau table. Attention doit être prélevée lors de la définition de cette option, telle qu'elle pourrait entraîner les verrous mortels selon le comportement de vos requêtes.
Par exemple, si requêtes A et B tous deux entraîner escalade du verrouillage sur des partitions différentes d'une table, mais ils chaque essayer puis pour accéder à la partition qu'a verrouillé l'autre requête, un des requêtes est abandonnée par le processus de moniteur de blocage.
La figure illustre un exemple d'interroger la vue de catalogue système sys.partitions (le premier jeu de résultats), le sys.dm_os_locks DMV (le deuxième jeu de résultats) pour examiner les verrous en cours détenus pour des requêtes sur une table partitionnée où escalade du verrouillage au niveau de la partition a eu lieu. Dans ce cas, il existe deux au niveau de partition exclusif verrous (les verrous HOBT dans les résultats), mais les verrous de table (les verrous d'objet dans la sortie) ne sont pas exclusifs, c'est pourquoi plusieurs requêtes peuvent accéder aux partitions bien escalade du verrouillage a eu lieu. Notez que les ID de ressource pour ces verrous partition deux correspondent à la partition d'ID pour les deux premières partitions de la table dans la sortie de sys.partitions.
Plus tôt cette année je blogged sur un affichage de script exemple comment verrouillage au niveau de partition promotion fonctionneet risque de blocages. La rubrique documentation en ligne de SQL Server 2008 appelée" Verrouillage dans le moteur de base de données« est une explication approfondie de tous les aspects de verrouillage dans SQL Server 2008.
Questions-réponses sur un de nos serveurs avait des problèmes avec le disque contenant le journal des transactions pour une base de données, et la base de données est devenu suspect. La sauvegarde complète la plus récente était de cinq semaines avant, et il devait être trop longue pour restaurer toutes les sauvegardes du journal, trop. Il était de heures lorsque le problème s'est produit, donc nous reconstruit le journal des transactions rompu afin d'éviter l'interruption. Dans certaines circonstances, cela peut entraîner des problèmes. Mais si rien n'a été l'accès aux données, puis je pense que nous sommes sûrs. Nous adoptent l'attitude ?
A la réponse simple qui est le seul cas que je serait Imaginez la reconstruction d'un journal des transactions est lorsqu'il est possible de récupérer à partir de sauvegardes. Bien que vous connaître les dangers de reconstruction d'un journal des transactions (pour les lecteurs qui sont ne voir pas mon blog valider » Dernier accède que personnes essayer tout d'abord...« le fait que la base de données s'est passé suspect signifie qu'il a échoué pendant la récupération, lors de l'exécution récupération sur incident soit lors de la restauration d'une transaction. Cela signifie qu'il est le risque réel d'une altération des données dans la base de données.
Bien que le problème s'est produit pendant la période silencieuse, vous envisager tâches planifiées et tâches en arrière-plan ? Un travail de maintenance aurait pu être en cours d'exécution qui a été reconstruction ou réorganisez un index organisé en clusters lorsque le journal est devenu endommagé. Une tâche d'arrière-plan peut avoir en cours exécution fantôme nettoyage sur les pages d'un tas ou un index organisé en clusters. Ces, par exemple, peuvent ont été apportées modifications structures d'index organisé en clusters qui, si pas correctement restaurée, créerait une altération dans la perte de données de base de données et possible.
La ligne inférieure est que reconstruction d'un journal des transactions doit être toujours le dernier recours absolue dans n'importe quel scénario de récupération après incident dû à un risque énorme de cause plus intégrité et des pertes de données. Au minimum, vous devez exécuter un DBCC CHECKDB complet sur cette base de données pour vérifier l'existence d'éventuels problèmes.
Déplacement vers l'avant, vous devez modifier votre stratégie de sauvegarde afin que vous peuvent effectuer des restaurations opportune et ne pas devoir recourir à radicale mesures, telles que la recréation de journal de transaction. Les étapes pour créer une stratégie de sauvegarde dépassent le cadre de cet article, mais je prévois de couvrant ce sujet dans un article fonction full-length à un certain moment de l'année à venir. Ainsi, Veuillez rester réglé !
S Paul Randal est le directeur Gestion de SQLskills.comet un MVP de SQL Server. HeHe travaillé sur l'équipe de moteur de stockage SQL Server de Microsoft à partir de 1999 à 2007. Paul écrit DBCC CHECKDB/réparation pour SQL Server 2005 et était responsable pour le moteur de stockage base pendant le développement de SQL Server 2008. Paul est un expert de la récupération après incident, haute disponibilité et la maintenance de base de données et un présentateur standard à des conférences dans le monde entier. Blogs il à SQLskills.com/blogs/paul.