Plusieurs GPU et machines
1. Introduction
CNTK prend actuellement en charge quatre algorithmes SGD parallèles :
Prérequis
Pour exécuter une formation parallèle, assurez-vous qu’une implémentation de l’interface de transmission de message (MPI) est installée :
Sur Windows, installez la version 7 (7.0.12437.6) de Microsoft MPI (MS-MPI), une implémentation Microsoft de la norme d’interface de passage de message, à partir de cette page de téléchargement, marquée simplement comme « Version 7 » dans le titre de la page. Cliquez sur le bouton Télécharger, puis sélectionnez l’exécution (
MSMpiSetup.exe).Sur Linux, installez OpenMPI version 1.10.x. Suivez les instructions ci-dessous pour la créer vous-même.
2. Configuration de l’entraînement parallèle dans CNTK dans Python
Pour utiliser le SGD parallèle de données en Python, l’utilisateur doit créer et transmettre un apprenant distribué au formateur :
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 32, # non-quantized gradient accumulation
distributed_after = 0) # no warm start
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
Pour la boucle d’entraînement définie par l’utilisateur (au lieu de training_session), les utilisateurs doivent passer num_data_partitions et partition_index à MinibatchSource.next_minibatch() la méthode afin que différents nœuds MPI lisent des données à partir de différentes partitions de données (une fois distributed_after les exemples lus).
Notez qu’il Communicator.finalize() doit être appelé uniquement si l’entraînement distribué s’est terminé avec succès. Si un worker distribué échoue, cette méthode ne doit pas être appelée.
Pour obtenir un exemple entièrement fonctionnel, consultez l’exemple ConvNet.
3. Configuration de l’entraînement parallèle dans CNTK dans BrainScript
Pour activer l’entraînement parallèle dans CNTK BrainScript, il est tout d’abord nécessaire d’activer le commutateur suivant dans le fichier de configuration ou dans la ligne de commande :
parallelTrain = true
Deuxièmement, le SGD bloc dans le fichier de configuration doit contenir un sous-bloc nommé ParallelTrain avec les arguments suivants :
parallelizationMethod: (obligatoire) les valeurs légitimes sontDataParallelSGD,BlockMomentumSGDetModelAveragingSGD.Cela spécifie l’algorithme parallèle à utiliser.
distributedMBReading: (facultatif) accepte la valeur booléenne :trueoufalse; la valeur par défaut estfalseIl est recommandé d’activer la lecture de minibatch distribuée pour réduire le coût des E/S dans chaque travailleur. Si vous utilisez un lecteur de format de texte CNTK, un lecteur d’images ou un lecteur de données composite, distributedMBReading doit être défini sur true.
parallelizationStartEpoch: (facultatif) accepte la valeur entière ; la valeur par défaut est 1.Cela spécifie à partir de quelle époque, les algorithmes d’apprentissage parallèle sont utilisés ; avant que tous les travailleurs effectuent la même formation, mais qu’un seul travailleur est autorisé à enregistrer le modèle. Cette option peut être utile si l’entraînement parallèle nécessite une phase de « démarrage chaud ».
syncPerfStats: (facultatif) accepte la valeur entière ; la valeur par défaut est 0.Cela spécifie la fréquence à laquelle les statistiques de performances seront imprimées. Ces statistiques incluent le temps consacré à la communication et/ou au calcul dans une période de synchronisation, ce qui peut être utile pour comprendre le goulot d’étranglement des algorithmes d’apprentissage parallèles.
0 signifie qu’aucune statistique n’est imprimée. D’autres valeurs spécifient la fréquence à laquelle les statistiques seront imprimées. Par exemple,
syncPerfStats=5les statistiques sont imprimées après toutes les 5 synchronisations.Sous-bloc qui spécifie les détails de chaque algorithme d’entraînement parallèle. Le nom du sous-bloc doit être égal à
parallelizationMethod. (obligatoire)
Python offre plus de flexibilité et d’utilisations sont présentées ci-dessous pour différentes méthodes de parallélisation.
4. Exécution d’une formation parallèle avec CNTK
La parallélisation dans CNTK est implémentée avec MPI.
4.1 Exécution de l’entraînement parallèle avec BrainScript
Étant donné l’une des configurations BrainScript parallèles ci-dessus, les commandes suivantes peuvent être utilisées pour démarrer un travail MPI parallèle :
Formation parallèle sur la même machine avec Linux :
mpiexec --npernode $num_workers $cntk configFile=$configFormation parallèle sur la même machine avec Windows :
mpiexec -n %num_workers% %cntk% configFile=%config%Formation parallèle sur plusieurs nœuds informatiques avec Linux :
Étape 1 : Créer un fichier hôte $hostfile à l’aide de votre éditeur favori
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
Où name_of_node(n) est simplement un nom DNS ou une adresse IP du nœud Worker.
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile $cntk configFile=$config
```
Formation parallèle sur plusieurs nœuds informatiques avec Windows :
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... %cntk% configFile=%config%
où $cntk doit faire référence au chemin d’accès de l’exécutable CNTK ($x est le moyen de l’interpréteur de commandes Linux de remplacer les variables d’environnement, l’équivalent dans l’interpréteur de %x% commandes Windows).
4.2 Exécution de l’entraînement parallèle avec Python
Voici quelques exemples d’entraînement distribué pour CNTK v2 avec Python :
Étant donné un script training.py Python CNTK v2, les commandes suivantes peuvent être utilisées pour démarrer un travail MPI parallèle :
Formation parallèle sur la même machine avec Linux :
mpiexec --npernode $num_workers python training.pyFormation parallèle sur la même machine avec Windows :
mpiexec -n %num_workers% python training.pyFormation parallèle sur plusieurs nœuds informatiques avec Linux :
Étape 1 : Créer un fichier hôte $hostfile à l’aide de votre éditeur favori
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
Où name_of_node(n) est simplement un nom DNS ou une adresse IP du nœud Worker.
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile python training.py
```
Formation parallèle sur plusieurs nœuds informatiques avec Windows :
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... python training.py
Formation 5 Data-Parallel avec SGD 1 bits
CNTK implémente la technique SGD 1 bits [1]. Cette technique permet de distribuer chaque minibatch sur K les travailleurs. Les dégradés partiels résultants sont ensuite échangés et agrégés après chaque minibatch. « 1 bits » fait référence à une technique développée à Microsoft pour réduire la quantité de données échangées pour chaque valeur de dégradé vers un seul bit.
5.1 L’algorithme « SGD 1 bits »
L’échange direct de dégradés partiels après chaque minibatch nécessite une bande passante de communication interdite. Pour résoudre ce problème, 1 bits SGD quantifie de manière agressive chaque valeur de dégradé... à un seul bit (!) par valeur. Pratiquement, cela signifie que les valeurs de dégradé volumineuses sont clippées, tandis que les petites valeurs sont artificiellement gonflées. Incroyablement, cela ne nuit pas à la convergence si, et seulement si, une astuce est utilisée.
L’astuce est que pour chaque minibatch, l’algorithme compare les dégradés quantifiés (qui sont échangés entre les travailleurs) avec les valeurs de dégradé d’origine (qui étaient censées être échangées). La différence entre les deux ( l’erreur de quantisation) est calculée et mémorisée en tant que résidu. Ce résidu est ensuite ajouté au minibatch suivant .
Par conséquent, malgré la quantisation agressive, chaque valeur de dégradé est finalement échangée avec une précision totale; juste à un retard. Les expériences montrent que, tant que ce modèle est combiné à un démarrage chaud (un modèle d’amorçage entraîné sur un petit sous-ensemble des données d’entraînement sans parallélisation), cette technique a montré qu’elle n’a pas ou très peu de perte de précision, tout en autorisant une accélération pas trop loin de linéaire (le facteur de limitation étant que les GPU deviennent inefficaces lors de l’informatique sur des sous-lots trop petits).
Pour une efficacité maximale, la technique doit être combinée avec la mise à l’échelle automatique du minibatch, où chaque fois et ensuite, le formateur tente d’augmenter la taille du minibatch. Évaluer sur un petit sous-ensemble de l’époque à venir des données, le formateur sélectionne la plus grande taille de minibatch qui n’a pas de préjudice à la convergence. Ici, il est pratique que CNTK spécifie le taux d’apprentissage et les hyperparamètres d’élan d’une manière agnostique de taille minibatch.
5.2 Utilisation de SGD 1 bits dans BrainScript
Le SGD 1 bits lui-même n’a aucun paramètre autre que celui de l’activer et après quelle époque il doit commencer. En outre, la mise à l’échelle automatique de minibatch doit être activée. Ces paramètres sont configurés en ajoutant les paramètres suivants au bloc SGD :
SGD = [
...
ParallelTrain = [
DataParallelSGD = [
gradientBits = 1
]
parallelizationStartEpoch = 2 # warm start: don't use 1-bit SGD for first epoch
]
AutoAdjust = [
autoAdjustMinibatch = true # enable automatic growing of minibatch size
minibatchSizeTuningFrequency = 3 # try to enlarge after this many epochs
]
]
Notez que Data-Parallel SGD peut également être utilisé sans quantisation 1 bits. Toutefois, dans les scénarios classiques, en particulier les scénarios dans lesquels chaque paramètre de modèle est appliqué une seule fois comme pour un DNN de transfert de flux, cela ne sera pas efficace en raison de besoins élevés en bande passante de communication.
La section 2.2.3 ci-dessous montre les résultats de SGD 1 bits sur une tâche vocale, en comparant avec la méthode SGD Block-Momentum décrite ci-dessous. Les deux méthodes n’ont pas ou presque aucune perte de précision au rythme quasi linéaire.
5.3 Utilisation de SGD 1 bits dans Python
Pour utiliser le SGD parallèle de données en Python, éventuellement avec SGD 1 bits, l’utilisateur doit créer et transmettre un apprenant distribué au formateur :
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 1, # change to 32 for non-quantized gradient accumulation
distributed_after = distributed_after) # warm start: no parallelization is used for the first 'distributed_after' samples
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
La modification num_quantization_bits à 32 lors de la création de distributed_learner permet d’utiliser des Data-Parallel SGD non quantifiés. Il n’y a pas besoin de démarrer au chaud dans ce cas.
6 Block-Momentum SGD
Block-Momentum SGD est l’implémentation de la « mise à jour et filtrage du modèle de bloc » ou bmUF, algorithme, short Block Momentum [2].
6.1 L’algorithme SGD Block-Momentum
La figure suivante récapitule la procédure dans l’algorithme Block-Momentum.

6.2 Configuration Block-Momentum SGD dans BrainScript
Pour utiliser Block-Momentum SGD, il est nécessaire d’avoir un sous-bloc nommé BlockMomentumSGD dans le SGD bloc avec les options suivantes :
syncPeriod. Ceci est similaire à celuisyncPerioddansModelAveragingSGD, qui spécifie la fréquence à laquelle une synchronisation de modèle est effectuée. La valeur par défaut estBlockMomentumSGDde 120 000.resetSGDMomentum. Cela signifie qu’après chaque point de synchronisation, le dégradé lisse utilisé dans le SGD local sera défini sur 0. La valeur par défaut de cette variable est true.useNesterovMomentum. Cela signifie que la mise à jour de l’élan de style Nesterov est appliquée au niveau du bloc. Pour plus d’informations, consultez [2]. La valeur par défaut de cette variable est true.
L’élan de bloc et le taux d’apprentissage de bloc sont généralement définis automatiquement selon le nombre de travailleurs utilisés, c’est-à-dire,
block_momentum = 1.0 - 1.0/num_of_workers
block_learning_rate = 1.0
Notre expérience indique que ces paramètres produisent souvent une convergence similaire en tant qu’algorithme SGD standard jusqu’à 64 GPU, ce qui est la plus grande expérience que nous avons effectuée. Il est également possible de spécifier manuellement ces paramètres à l’aide des options suivantes :
blockMomentumAsTimeConstantspécifie la constante de temps du filtre à faible passage dans la mise à jour du modèle au niveau du bloc. Il est calculé comme suit :blockMomentumAsTimeConstant = -syncPeriod / log(block_momentum) # or inversely block_momentum = exp(-syncPeriod/blockMomentumAsTimeConstant)blockLearningRatespécifie le taux d’apprentissage de bloc.
Voici un exemple de Block-Momentum section de configuration SGD :
learningRatesPerSample=0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
# Use it for BlockMomentumSGD as well
ParallelTrain = [
parallelizationMethod = BlockMomentumSGD
distributedMBReading = true
syncPerfStats = 5
BlockMomentumSGD=[
syncPeriod = 120000
resetSGDMomentum = true
useNesterovMomentum = true
]
]
6.3 Utilisation de Block-Momentum SGD dans BrainScript
1. Réajuster les paramètres d’apprentissage
Pour obtenir un débit similaire par travailleur, il est nécessaire d’augmenter le nombre d’échantillons dans un minibatch proportionnel au nombre de travailleurs. Cela peut être réalisé en ajustant
minibatchSizeounbruttsineachrecurrentiteren fonction de l’utilisation de la randomisation en mode trame.Il n’est pas nécessaire d’ajuster le taux d’apprentissage (contrairement à Model-Averaging SGD, voir ci-dessous).
Il est recommandé d’utiliser Block-Momentum SGD avec un modèle de démarrage chaud. Sur nos tâches de reconnaissance vocale, la convergence raisonnable est obtenue lors du démarrage des modèles d’amorçage formés sur 24 heures (8,6 millions d’échantillons) à 120 heures (43,2 millions d’échantillons) à l’aide de SGD standard.
2. Expériences ASR
Nous avons utilisé les algorithmes SGD Block-Momentum Data-Parallel et SGD (1 bits) pour entraîner des DNN et des LSTMs sur une tâche de reconnaissance vocale de 2600 heures et comparer les précisions de reconnaissance vocale par rapport aux facteurs de vitesse. Les tableaux et les figures suivants montrent les résultats (*).
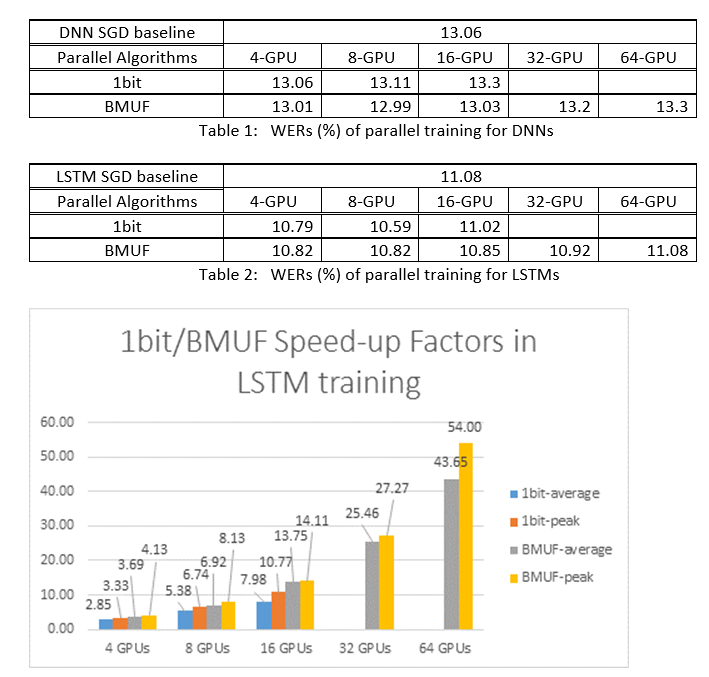
(*) : facteur de vitesse de pointe : pour le SGD 1 bits, mesuré par le facteur de vitesse maximal (par rapport à la base de référence SGD) atteint dans un minibatch ; pour Block Momentum, mesuré par la vitesse maximale obtenue en un bloc; Facteur d’accélération moyen : temps écoulé dans la base de référence SGD divisé par le temps écoulé observé. Ces deux métriques sont introduites en raison de la latence dans les E/S peut considérablement affecter la mesure moyenne du facteur d’accélération, en particulier lorsque la synchronisation est effectuée au niveau du mini-lot. En même temps, le facteur d’accélération maximal est relativement robuste.
3. Mises en garde
Il est recommandé de définir
resetSGDMomentumla valeur true ; sinon, il conduit souvent à une divergences de critères d’entraînement. La réinitialisation de l’élan SGD à 0 après chaque synchronisation de modèle réduit essentiellement la contribution des derniers minibatches. Par conséquent, il est recommandé de ne pas utiliser un grand élan SGD. Par exemple, pour unsyncPeriodnombre de 120 000, nous observons une perte de précision significative si l’élan utilisé pour SGD est de 0,99. La réduction de l’élan SGD à 0,9, 0,5 ou même la désactivation de celle-ci donne une précision similaire à celle que l’algorithme SGD standard peut obtenir.Block-Momentum retards SGD et distribue les mises à jour du modèle d’un bloc sur les blocs suivants. Par conséquent, il est nécessaire de s’assurer que les synchronisations de modèles sont effectuées assez souvent dans l’entraînement. Une vérification rapide consiste à utiliser
blockMomentumAsTimeConstant. Il est recommandé que le nombre d’exemples d’entraînement uniques,Ndoit satisfaire l’équation suivante :N >= blockMomentumAsTimeConstant * num_of_workers ~= syncPeriod * num_of_workers^2
L’approximation provient des faits suivants : (1) Block Momentum est souvent défini comme (1-1/num_of_workers); (2) log(1-1/num_of_workers)~=-num_of_workers.
6.4 Utilisation de Block-Momentum dans Python
Pour activer Block-Momentum en Python, de la même façon que le SGD 1 bits, l’utilisateur doit créer et transmettre un apprenant distribué en bloc au formateur :
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_learner = cntk.distributed.block_momentum_distributed_learner(learner, block_size=block_size)
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
Pour obtenir un exemple entièrement fonctionnel, consultez l’exemple ConvNet.
7 Model-Averaging SGD
Model-Averaging SGD est une implémentation de l’algorithme de moyenne de modèle détaillé dans [3,4] sans utiliser de dégradé naturel. L’idée ici consiste à laisser chaque worker traiter un sous-ensemble de données, mais en moyenne les paramètres de modèle de chaque worker après une période spécifiée.
Model-Averaging SGD converge généralement plus lentement et vers un pire optimal, par rapport à SGD 1 bits et Block-Momentum SGD, de sorte qu’il n’est plus recommandé.
Pour utiliser Model-Averaging SGD, il est nécessaire d’avoir un sous-bloc nommé ModelAveragingSGD dans le SGD bloc avec les options suivantes :
syncPeriodspécifie le nombre d’échantillons que chaque worker doit traiter avant qu’une moyenne de modèle soit effectuée. La valeur par défaut est 40 000.
7.1 Utilisation de Model-Averaging SGD dans BrainScript
Pour rendre Model-Averaging SGD efficace et efficace, les utilisateurs doivent régler certains hyper-paramètres :
minibatchSizeounbruttsineachrecurrentiter. Supposons quenles travailleurs participent à la configuration SGD Model-Averaging, l’implémentation de lecture distribuée actuelle charge1/n-th du minibatch dans chaque worker. Par conséquent, pour vous assurer que chaque worker produit le même débit que le SGD standard, il est nécessaire d’agrandir la taillenminibatch -fold. Pour les modèles entraînés à l’aide de la randomisation en mode trame, cela peut être réalisé en s’agrandissantminibatchSizenpar temps ; pour les modèles sont entraînés à l’aide de la randomisation en mode séquence, comme les RNN, certains lecteurs nécessitent plutôt d’augmenternbruttsineachrecurrentiterparn.learningRatesPerSample. Notre expérience indique que pour obtenir une convergence similaire à la norme SGD, il est nécessaire d’augmenter leslearningRatesPerSampletemps.nVous trouverez une explication dans [2]. Étant donné que le taux d’apprentissage est augmenté, un soin supplémentaire est nécessaire pour s’assurer que la formation ne s’écarte pas- et c’est en fait la principale mise en garde de Model-Averaging SGD. Vous pouvez utiliser lesAutoAdjustparamètres pour recharger le meilleur modèle précédent si une augmentation du critère d’entraînement est observée.démarrage chaud. Il est constaté que Model-Averaging SGD converge généralement mieux s’il est démarré à partir d’un modèle d’amorçage qui est entraîné par l’algorithme SGD standard (sans parallélisation). Sur nos tâches de reconnaissance vocale, la convergence raisonnable est obtenue lors du démarrage des modèles d’amorçage formés sur 24 heures (8,6 millions d’échantillons) à 120 heures (43,2 millions d’échantillons) à l’aide de SGD standard.
Voici un exemple de section de ModelAveragingSGD configuration :
learningRatesPerSample = 0.002
# increase the learning rate by 4 times for 4-GPU training.
# learningRatesPerSample = 0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
ParallelTrain = [
parallelizationMethod = ModelAveragingSGD
distributedMBReading = true
syncPerfStats = 20
ModelAveragingSGD = [
syncPeriod=40000
]
]
7.2 Utilisation de Model-Averaging SGD dans Python
Il s’agit d’un travail en cours.
8 formation Data-Parallel avec le serveur de paramètres
Le serveur de paramètres est une infrastructure largement utilisée dans le Machine Learning distribué [5][6][7]. L’avantage le plus important qu’il apporte est la formation parallèle asynchrone avec de nombreux travailleurs. Il introduit le serveur de paramètres en tant que magasin de modèles distribué. Au lieu d’exploiter directement les primitives AllReduce pour synchroniser les mises à jour des paramètres entre les workers, l’infrastructure du serveur de paramètres fournit aux utilisateurs les interfaces telles que « Ajouter » et « Get » pour permettre aux travailleurs locaux de mettre à jour et de récupérer des paramètres globaux à partir du serveur de paramètres. De cette façon, les travailleurs locaux n’ont pas besoin d’attendre les uns les autres pendant le processus de formation, ce qui économise beaucoup de temps, en particulier lorsque le nombre de travailleurs est volumineux.
En outre, étant donné que les serveurs de paramètres sont une infrastructure distribuée qui stocke les paramètres du modèle, les travailleurs peuvent récupérer uniquement ces paramètres dont ils ont besoin pendant le processus d’apprentissage par mini-lot, ce qui offre une très bonne flexibilité dans la conception de la méthode d’entraînement distribuée et améliore également l’efficacité lors de la formation avec des mises à jour de modèle éparses. Dans cette version, nous allons nous concentrer sur l’entraînement parallèle asynchrone en premier, plus tard, nous allons donner plus d’introduction sur la façon d’exploiter l’infrastructure de serveur de paramètres pour l’entraînement de modèle efficace avec des mises à jour éparses.
8.1 Utilisation de Data-Parallel ASGD
- Pour utiliser des serveurs de paramètres pour le SGD asynchrone (abbr. asGD), vous devez générer CNTK avec Multiverso pris en charge, Multiverso est une infrastructure de serveur de paramètres générale pour la tâche de machine learning distribuée développée par l’équipe Microsoft Research Asia.
Clone Code: clonez le code sous le dossier racine de CNTK à l’aide de :
git submodule update --init Source/Multiverso
Linux: créez-le--asgd=yesdans le processus de configuration.Windows: ajoutezCNTK_ENABLE_ASGDà votre environnement système et définissez la valeur surtrue
- démarrage chaud. Dans certains cas, il est préférable d’avoir l’entraînement de modèle asynchrone démarré à partir d’un modèle initial (qui est entraîné par un algorithme SGD standard). En quelque sorte, le SGD asynchrone apporte plus de bruit pour l’entraînement en raison des mises à jour retardées de l’asynchronisme chez les travailleurs. Certains modèles sont très sensibles à ce bruit au début, ce qui peut entraîner des différences de formation de modèle. Dans ce cas, un démarrage chaud est nécessaire.
8.2 Configuration Data-Parallel ASGD dans BrainScript
Pour utiliser Data-Parallel ASGD dans CNTK, il est nécessaire d’avoir un sous-bloc DataParallelASGD dans le bloc SGD avec les options suivantes
-
syncPeriodPerWorkers. Il spécifie le nombre d’échantillons que chaque worker doit traiter avant de communiquer avec les serveurs de paramètres. La valeur par défaut est 256. Il est recommandé comme taille de minibatch. Il est évident que la synchronisation fréquente entraîne un coût de communication élevé important. Dans notre test, il n’est pas nécessaire de définir la valeur sur 1 dans la plupart des cas.
-
usePipeline. Il spécifie si l’activation du pipeline de récupération de modèle et le calcul local. L’activation du pipeline augmente considérablement le débit global de l’entraînement, car il masque certains ou l’ensemble des coûts de communication. Toutefois, il peut parfois ralentir le taux de convergence, car plus de retard sera introduit en ajoutant un pipeline. Dans l’ensemble, l’heure d’horloge sera enregistrée dans la plupart des cas avec le pipeline.
-
AdjustLearningRateAtBeginning. Selon le document récemment publié [5], l’ASGD de formation est moins stable et elle a besoin d’utiliser un taux d’apprentissage beaucoup plus petit pour éviter des explosions occasionnelles de la perte d’apprentissage, par conséquent, le processus d’apprentissage devient moins efficace. Toutefois, nous avons constaté que l’utilisation d’un taux d’apprentissage inférieur n’est pas nécessaire pour toutes les tâches. Et pour ces tâches sensibles au début, nous commençons l’entraînement avec un petit taux d’apprentissage, et agrandissons progressivement au début du processus de formation jusqu’à ce qu’il atteigne le taux d’apprentissage initial utilisé dans le SGD normal. De cette façon, la précision finale correspond à SGD avec la vitesse d’ASGD. Nous fournissons donc cette option aux utilisateurs ASGD pour tirer parti de cette astuce. Il s’agit d’un sous-bloc dans DataParallelASGD avec deux paramètres : adjustCoefficient et adjustNBMiniBatch. La logique est que le taux d’apprentissage commence par ajusterCoefficient du taux d’apprentissage initial SGD, et augmentez par ajustementCoefficient du taux d’apprentissage initial SGD chaque ajustementNBMiniBatch mini-lots.
Voici un exemple de section de DataParallelASGD configuration :
learningRatesPerSample = 0.0005
ParallelTrain = [
parallelizationMethod = DataParallelASGD
distributedMBReading = true
syncPerfStats = 20
DataParallelASGD = [
syncPeriodPerWorker=256
usePipeline = true
AdjustLearningRateAtBeginning = [
adjustCoefficient = 0.2
adjustNBMiniBatch = 1024
# Learning rate will be adjusted to original one after ((1 / adjustCoefficient) * adjustNBMiniBatch) samples
# which is 5120 in this case
]
]
]
8.3 Configuration Data-Parallel ASGD dans Python
Il s’agit d’un travail en cours.
8.4 Expériences
La figure suivante montre les expériences de test ASGD avec le jeu de données CIFAR-10. Le modèle utilisé dans cette expérience est un resNet de 20 couches. L’algorithme asynchrone réduit le coût en attente de tous les nœuds Worker. ASGD, dans ce cas, est clairement plus rapide que les algorithmes synchrones, comme MA et SSGD. *Dans les expériences, tous les modes parallèles synchronisent les paramètres chaque itération (mise à jour mini-batch). Et pour SSGD, nous avons utilisé des mises à jour de paramètres 32 bits. L’algorithme asynchrone bénéficie d’un avantage significatif en termes de débit d’entraînement mesuré par la vitesse de traitement de l’exemple, en particulier lorsque le numéro de nœud de travail atteint 16.
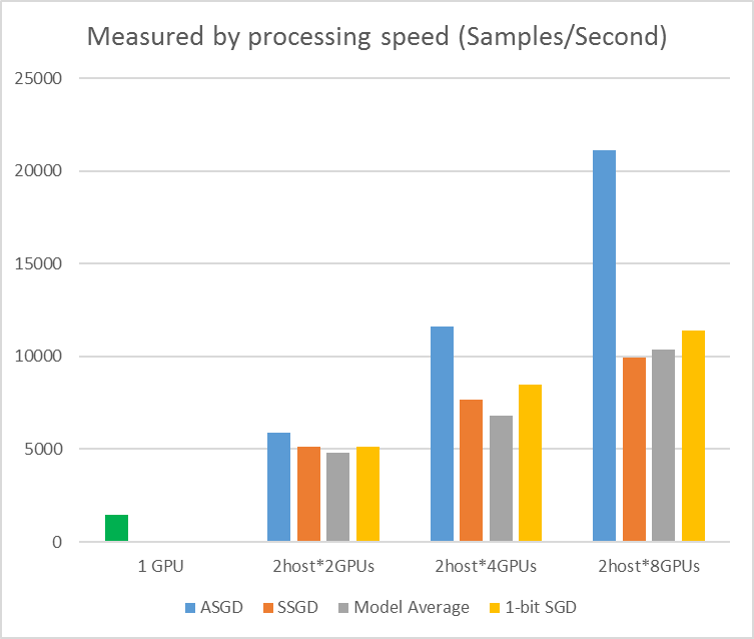 Figure 2.4 l’accélération des différentes méthodes d’apprentissage
Figure 2.4 l’accélération des différentes méthodes d’apprentissage
Références
[1] F. Seide, Hao Fu, Jasha Droppo, Gang Li et Dong Yu, « descente de dégradé stochastique 1 bits et son application à l’entraînement distribué en parallèle des données des DNN, » dans Les procédures d’Interspeech, 2014.
[2] K. Chen et Q. Huo, « Formation évolutive des machines deep learning par entraînement de blocs incrémentiels avec optimisation parallèle intra-bloc et filtrage de mise à jour de modèle de bloc », dans La procédure d’ICASSP, 2016.
[3] M. Zinkevich, M. Weimer, L. Li et A. J. Smola, « Descente de dégradé stochastique parallélisée », dans Les procédures des avances dans NIPS, 2010, pp. 2595-2603.
[4] D. Povey, X. Zhang et S. Khodanpur, « Formation parallèle des DNN avec dégradé naturel et moyenne de paramètre », dans Les procédures de la Conférence internationale sur les représentations d’apprentissage, 2014.
[5] Chen J, Monga R, Bengio S, et al. Revisiting Distributed Synchronous SGD. ICLR, 2016.
[6] Dean Jeffrey, Greg Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Mark Mao, Andrew Senior et al. Réseaux profonds distribués à grande échelle. Dans les systèmes de traitement des informations neuronales, pp. 1223-1231. 2012.
[7] Li Mu, Li Zhou, Zichao Yang, Aaron Li, Fei Xia, David G. Andersen et Alexander Smola. « Serveur de paramètres pour le Machine Learning distribué ». Dans l’atelier NIPS Big Learning, vol. 6, p. 2. (2013).