Contrôler et atténuer la limitation de la capacité de traitement pour réduire la latence dans Azure Time Series Insights Gen1
Note
Le service Time Series Insights sera mis hors service le 7 juillet 2024. Envisagez de migrer des environnements existants vers d’autres solutions dès que possible. Pour plus d’informations sur la dépréciation et la migration, consultez notre documentation .
Prudence
Il s’agit d’un article Gen1.
Lorsque la quantité de données entrantes dépasse la configuration de votre environnement, vous pouvez rencontrer une latence ou une limitation dans Azure Time Series Insights.
Vous pouvez éviter la latence et le goulot d'étranglement en configurant correctement votre environnement pour la quantité de données que vous souhaitez analyser.
Vous êtes le plus susceptible de rencontrer une latence et une limitation lorsque vous :
- Ajoutez une source d’événement qui contient d’anciennes données qui peuvent dépasser votre taux d’entrée alloué (Azure Time Series Insights devra rattraper).
- Ajoutez d’autres sources d’événements à un environnement, ce qui entraîne un pic d’événements supplémentaires (ce qui peut dépasser la capacité de votre environnement).
- Envoyez de grandes quantités d’événements historiques à une source d’événement, ce qui entraîne un décalage (Azure Time Series Insights devra rattraper).
- Joignez des données de référence avec des données de télémétrie, ce qui entraîne une plus grande taille d’événement. La taille maximale autorisée du paquet est de 32 Ko ; les paquets de données supérieurs à 32 Ko sont tronqués.
Vidéo
Découvrez le comportement d’entrée des données Azure Time Series Insights et comment le planifier.
Surveiller la latence et la gestion de débit à l'aide d'alertes
Les alertes peuvent vous aider à diagnostiquer et à atténuer les problèmes de latence qui se produisent dans votre environnement.
Dans le portail Azure, sélectionnez votre environnement Azure Time Series Insights. Sélectionnez ensuite Alertes.
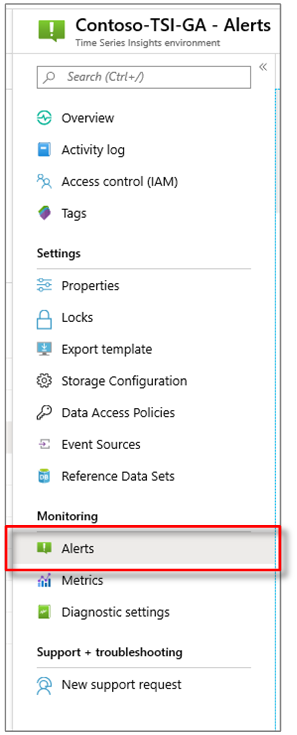
Sélectionnez + Nouvelle règle d’alerte. Le panneau Créer une règle s’affiche ensuite. Sélectionnez Ajouter sous CONDITION.
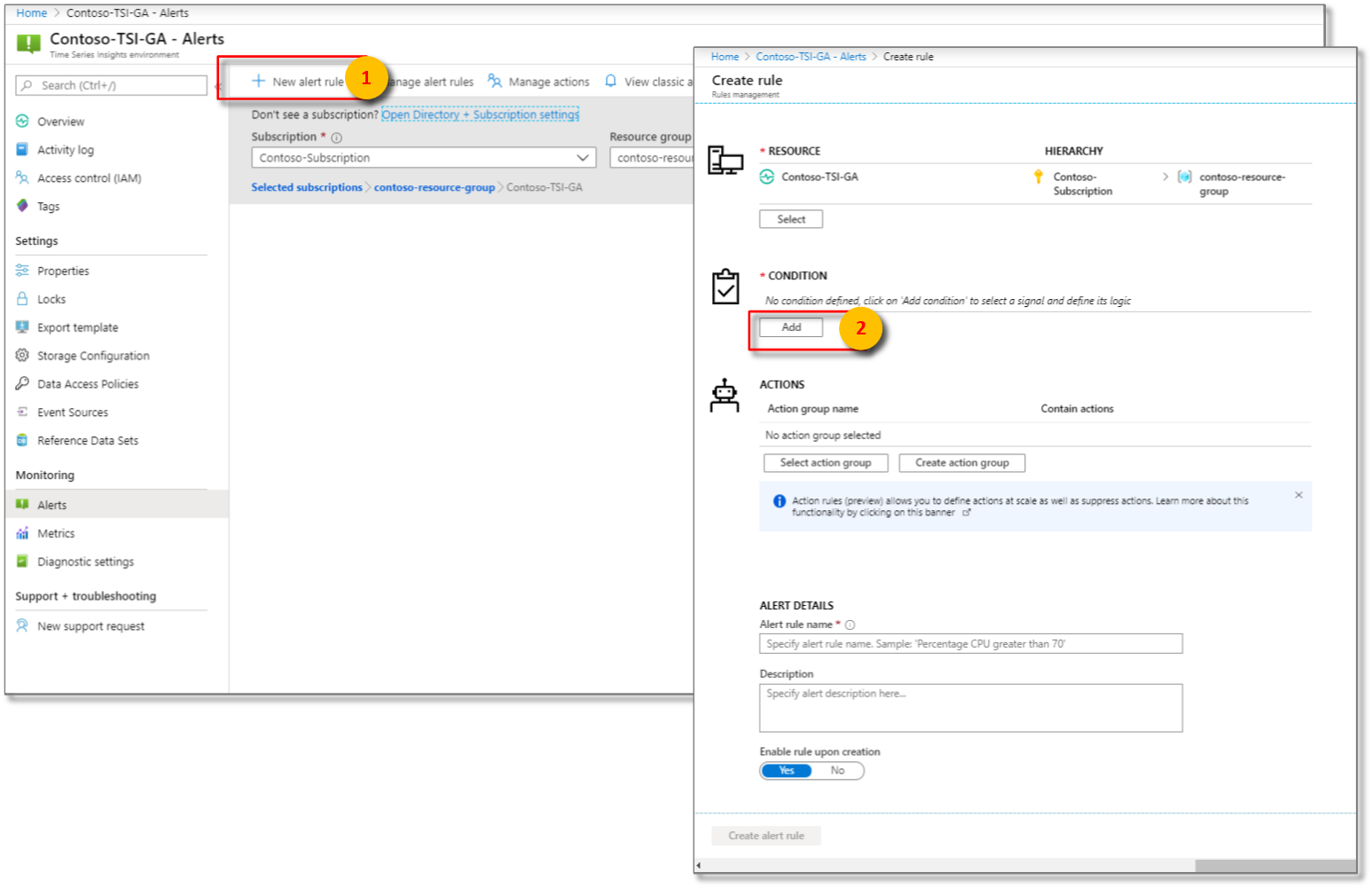
Ensuite, configurez les conditions exactes de la logique de signal.
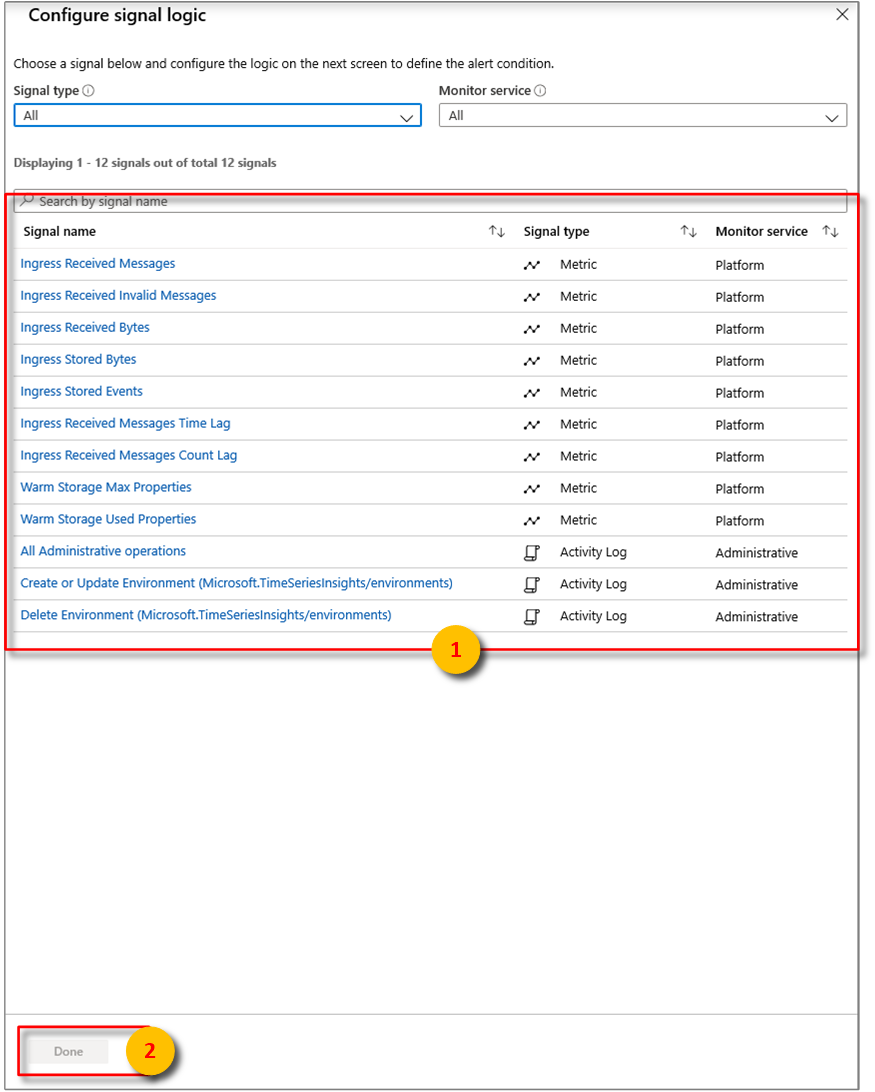
À partir de là, vous pouvez configurer des alertes à l’aide de certaines des conditions suivantes :
Métrique Description Octets reçus à l'entrée Nombre d’octets bruts lus à partir de sources d’événements. Le nombre brut inclut généralement le nom et la valeur de la propriété. Ingress a reçu des messages invalides Nombre de messages non valides lus à partir de toutes les sources d’événements Azure Event Hubs ou Azure IoT Hub. Messages reçus Nombre de messages lus à partir de toutes les sources d’événements Event Hubs ou IoT Hubs. octets entrants stockés Taille totale des événements stockés et disponibles pour la requête. La taille est calculée uniquement sur la valeur de la propriété. événements stockés d’entrée Nombre d’événements aplatis stockés et disponibles pour interrogation. délai de réception du message entrant Différence en secondes entre l’heure pendant laquelle le message est mis en file d’attente dans la source de l’événement et l’heure à laquelle il est traité en entrée. Délai du nombre de messages reçus en entrée Différence entre le numéro de séquence du dernier message mis en file d’attente dans la partition source de l’événement et le numéro de séquence du message en cours de traitement dans Ingress. Sélectionnez Terminé.
Après avoir configuré la logique de signal souhaitée, passez en revue visuellement la règle d’alerte choisie.
Vue de latence et graphiques
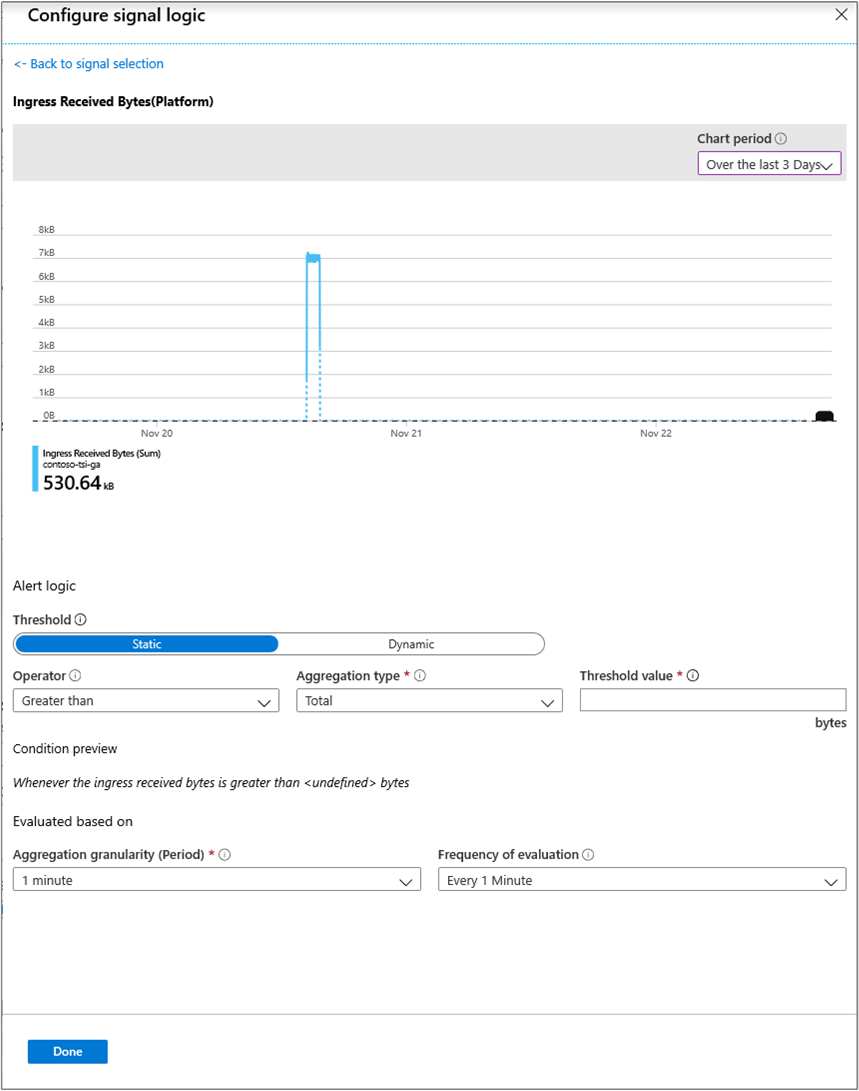




Gestion de la régulation du débit et de l'accès
Si vous subissez une limitation, une valeur pour le délai du message reçu en entrée sera enregistrée pour vous informer du nombre de secondes de retard de votre environnement Azure Time Series Insights par rapport à l'heure réelle à laquelle le message atteint la source de l'événement, cela n'inclut pas le temps d'indexation d'environ 30 à 60 secondes.
Ingress Retard du nombre de messages reçus doit également avoir une valeur, ce qui vous permet de déterminer de combien de messages vous êtes en retard. Le moyen le plus simple de se rattraper est d’augmenter la capacité de votre environnement à une taille qui vous permettra de surmonter la différence.
Par exemple, si votre environnement S1 affiche un décalage de 5 000 000 messages, vous pouvez augmenter la taille de votre environnement à six unités environ par jour pour se retrouver rattrapé. Vous pourriez augmenter encore davantage pour rattraper plus rapidement. La période de rattrapage est une occurrence courante lors de l’approvisionnement initial d’un environnement, en particulier lorsque vous le connectez à une source d’événement qui a déjà des événements dans celui-ci ou lorsque vous chargez en bloc un grand nombre de données historiques.
Une autre technique consiste à définir un Événements stockés d’entrée alerte >= un seuil légèrement inférieur à la capacité totale de votre environnement pendant une période de 2 heures. Cette alerte peut vous aider à comprendre si vous êtes constamment à pleine capacité, ce qui indique une probabilité élevée de latence.
Par exemple, si vous avez trois unités S1 approvisionnées (ou 2100 événements par capacité d’entrée de minute), vous pouvez définir une alerte Événements stockés d’entrée pour >= 1900 événements pendant 2 heures. Si vous dépassez constamment ce seuil et, par conséquent, déclenchez votre alerte, vous êtes probablement sous-approvisionné.
Si vous pensez que vous êtes limité, vous pouvez comparer vos messages reçus d'entrée avec les messages sortants de votre source d’événement. Si l’entrée dans votre Hub d’événements est supérieure à vos Ingress Received Messages , vos insights Azure Time Series sont probablement régulés.
Amélioration des performances
Pour réduire la restriction ou pour atténuer la latence, la meilleure façon de corriger le problème consiste à augmenter la capacité de votre environnement.
Vous pouvez éviter les latences et limitations en configurant efficacement votre environnement pour traiter la quantité de données que vous souhaitez analyser. Pour plus d’informations sur l’ajout de capacité à votre environnement, lisez Mettre à l’échelle votre environnement.