Exécuter un script Python
Important
Le support de Machine Learning Studio (classique) prend fin le 31 août 2024. Nous vous recommandons de passer à Azure Machine Learning avant cette date.
À partir du 1er décembre 2021, vous ne pourrez plus créer de nouvelles ressources Machine Learning Studio (classique). Jusqu’au 31 août 2024, vous pouvez continuer à utiliser les ressources Machine Learning Studio (classique) existantes.
- Consultez les informations sur le déplacement des projets de machine learning de ML Studio (classique) à Azure Machine Learning.
- En savoir plus sur Azure Machine Learning.
La documentation ML Studio (classique) est en cours de retrait et ne sera probablement plus mise à jour.
Exécute un script Python à partir d’une expérience de Machine Learning
Catégorie : Modules de langage Python
Notes
S’applique à : Machine Learning Studio (classique) uniquement
Des modules par glisser-déposer similaires sont disponibles dans Concepteur Azure Machine Learning.
Vue d’ensemble du module
Cet article explique comment utiliser le module Exécuter un script Python dans Machine Learning Studio (classique) pour exécuter du code Python. Pour plus d’informations sur les principes d’architecture et de conception de Python dans Studio (classique), consultez l’article suivant.
Avec Python, vous pouvez effectuer des tâches qui ne sont actuellement pas prises en charge par des modules Studio (classiques) existants, tels que :
- visualisation des données à l’aide de
matplotlib; - utilisation de bibliothèques Python pour énumérer les jeux de données et les modèles de votre espace de travail ;
- lecture, chargement et manipulation de données à partir de sources non prises en charge par le module Importer des données.
Machine Learning Studio (classique) utilise la distribution Anaconda de Python, qui inclut de nombreux utilitaires courants pour le traitement des données.
Guide pratique pour exécuter un script Python
Le module Exécuter un script Python contient un exemple de code Python que vous pouvez utiliser comme point de départ. Pour configurer le module Exécuter un script Python, vous fournissez un ensemble d’entrées et de code Python à exécuter dans la zone de texte Script Python.
Ajoutez le module Exécuter un script Python à votre expérience.
Faites défiler jusqu’au bas du volet Propriétés et, pour la version de Python, sélectionnez la version des bibliothèques Python et le runtime à utiliser dans le script.
- Distribution Anaconda 2.0 pour Python 2.7.7
- Distribution Anaconda 4.0 pour Python 2.7.11
- Distribution Anaconda 4.0 pour Python 3.5 (par défaut)
Nous vous recommandons de définir la version avant de taper un nouveau code. Si vous modifiez la version ultérieurement, une invite vous demande de confirmer la modification.
Important
Si vous utilisez plusieurs instances du module d’exécution de script Python dans votre expérience, vous devez choisir une seule version de Python pour tous les modules de l’expérience.
Ajoutez et connectez-vous à Dataset1 à partir de Studio (classique) que vous souhaitez utiliser pour l’entrée. Référencez ce jeu de données dans votre script Python sous le nom DataFrame1.
L’utilisation d’un jeu de données est facultative, si vous souhaitez générer des données à l’aide de Python ou utiliser du code Python pour importer les données directement dans le module.
Ce module prend en charge l’ajout d’un deuxième jeu de données Studio (classique) sur Dataset2. Référencez ce second jeu de données dans votre script Python sous le nom DataFrame2.
Les jeux de données stockés dans Studio (classique) sont automatiquement convertis en data.frames pandas lorsqu’ils sont chargés avec ce module.
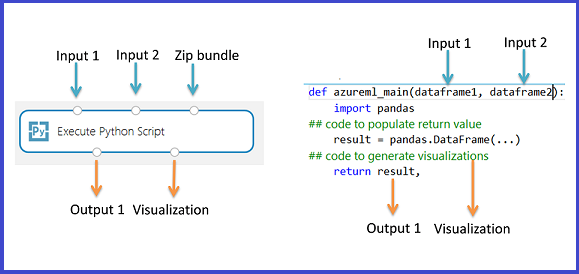
Pour inclure du code ou de nouveaux packages Python, ajoutez le fichier zip contenant ces ressources personnalisées dans Script groupé. L’entrée dans Script groupé doit correspondre à un fichier zip déjà chargé dans votre espace de travail. Pour plus d’informations sur la préparation et le chargement de ces ressources, consultez Décompresser les données compressées.
Tous les fichiers qui figurent dans l’archive zip chargée sont utilisables lors de l’exécution de l’expérience. Si l’archive inclut une structure de répertoires, cette structure est préservée, mais vous devez ajouter au chemin d’accès un répertoire appelé src.
Dans la zone de texte Script Python, saisissez ou collez un script Python valide.
La zone de texte Script Python est préremplie avec certaines instructions en commentaires, ainsi qu’avec un exemple de code pour l’accès aux données et la sortie. Vous devez modifier ou remplacer ce code. Veillez à suivre les conventions Python concernant la mise en retrait et la casse.
- Le script doit contenir une fonction nommée
azureml_maincomme point d’entrée pour ce module. - La fonction de point d’entrée peut contenir jusqu’à deux arguments d’entrée :
Param<dataframe1>etParam<dataframe2>. - Les fichiers zip connectés au troisième port d’entrée sont décompressés et stockés dans le répertoire
.\Script Bundle, qui est également ajouté à l’élémentsys.pathPython.
Par conséquent, si votre fichier zip contient
mymodule.py, importez-le à l’aide deimport mymodule.- Un jeu de données unique peut être retourné à Studio (classique), qui doit être une séquence de type
pandas.DataFrame. Vous pouvez créer d’autres sorties dans votre code Python et les écrire directement dans le stockage Azure, ou créer des visualisations à l’aide de l’appareil Python.
- Le script doit contenir une fonction nommée
Exécutez l’expérience, ou sélectionnez le module et cliquez sur Exécuter la sélection pour exécuter uniquement le script Python.
La totalité des données et du code sont chargés sur une machine virtuelle et s’exécutent à l’aide de l’environnement Python spécifié.
Résultats
Le module retourne ces sorties :
Jeu de données de résultats. Les résultats de tous les calculs effectués par le code Python incorporé doivent être fournis sous forme de data.frame pandas, qui est automatiquement converti au format de jeu de données Machine Learning, afin que vous puissiez utiliser les résultats avec d’autres modules de l’expérience. Le module est limité à un seul jeu de données en tant que sortie. Pour plus d’informations, consultez La table de données.
Appareil Python. Cette sortie prend en charge la sortie console et l'affichage des images PNG à l'aide de l'interpréteur Python.
Comment attacher des ressources de script
Le module Exécuter un script Python prend en charge les fichiers de script Python arbitraires en tant qu’entrées, à condition qu’ils soient préparés à l’avance et chargés dans votre espace de travail dans le cadre d’un fichier .ZIP.
Télécharger un fichier ZIP contenant du code Python dans votre espace de travail
Dans la zone d’expérience de Machine Learning Studio (classique), cliquez sur Jeux de données, puis sur Nouveau.
Sélectionnez l’option Dans le fichier local.
Dans la boîte de dialogue Télécharger un nouveau jeu de données, cliquez sur la liste déroulante pour Sélectionner un type pour le nouveau jeu de données, puis sélectionnez l’option Fichier zip (.zip).
Cliquez sur Parcourir pour localiser le fichier compressé.
Tapez un nouveau nom à utiliser dans l’espace de travail. Le nom que vous attribuez au jeu de données devient le nom du dossier de votre espace de travail où les fichiers contenus sont extraits.
Une fois que vous avez chargé le package compressé dans Studio (classique), vérifiez que le fichier compressé est disponible dans la liste jeux de données enregistrés , puis connectez le jeu de données au port d’entrée Script Bundle .
Tous les fichiers contenus dans le fichier ZIP sont disponibles pendant l’exécution : par exemple, des exemples de données, des scripts ou de nouveaux packages Python.
Si votre fichier compressé contient des bibliothèques qui ne sont pas déjà installées dans Machine Learning Studio (classique), vous devez installer le package de bibliothèque Python dans le cadre de votre script personnalisé.
S’il y avait une structure de répertoire présente, elle est conservée. Toutefois, vous devez modifier votre code pour ajouter le répertoire src au chemin d’accès.
Débogage du code Python
Le module d’exécution de script Python fonctionne mieux lorsque le code a été factorisé en tant que fonction avec des entrées et sorties clairement définies, plutôt qu’une séquence d’instructions exécutables faiblement associées.
Ce module Python ne prend pas en charge les fonctionnalités telles qu’IntelliSense et le débogage. Si le module échoue au moment de l’exécution, vous pouvez afficher des détails d’erreur dans le journal de sortie du module. Toutefois, la trace complète de la pile Python n’est pas disponible. Par conséquent, nous recommandons aux utilisateurs de développer et de déboguer leurs scripts Python dans un autre environnement, puis d’importer le code dans le module.
Voici quelques problèmes courants que vous pouvez rechercher :
Vérifiez les types de données dans la trame de données à partir de laquelle
azureml_mainvous revenez . Les erreurs sont probables si les colonnes contiennent des types de données autres que des types numériques et des chaînes.Supprimez les valeurs NA de votre jeu de données, à l’aide
dataframe.dropna()de l’exportation à partir du script Python. Lorsque vous préparez vos données, utilisez le module Nettoyer les données manquantes .Vérifiez que votre code incorporé contient des erreurs de retrait et d’espace blanc. Si vous obtenez l’erreur « IndentationError : un bloc mis en retrait attendu », consultez les ressources suivantes pour obtenir des conseils :
Limitations connues
Le runtime Python est en bac à sable (sandbox) et n’autorise pas l’accès au réseau ou au système de fichiers local de manière persistante.
Tous les fichiers enregistrés localement sont isolés et supprimés une fois que le module se termine. Le code Python ne peut pas accéder à la plupart des répertoires sur la machine qui les exécute, excepté le répertoire actuel et ses sous-répertoires.
Lorsque vous fournissez un fichier compressé en tant que ressource, les fichiers sont copiés de votre espace de travail vers l’espace d’exécution de l’expérience, décompressés, puis utilisés. La copie et la décompression de ressources peuvent consommer de la mémoire.
Le module peut générer une trame de données unique. Il n’est pas possible de retourner des objets Python arbitraires tels que des modèles entraînés directement au runtime Studio (classique). Toutefois, vous pouvez écrire des objets dans le stockage ou dans l’espace de travail. Une autre option consiste à utiliser
picklepour sérialiser plusieurs objets dans un tableau d’octets, puis retourner le tableau à l’intérieur d’une trame de données.
Exemples
Pour obtenir des exemples d’intégration de script Python avec des expériences Studio (classique), consultez ces ressources dans la galerie Azure AI :
- Exécuter un script Python : utilisez la tokenisation de texte, la sortie et d’autres traitements en langage naturel à l’aide du module Exécuter le script Python .
- Scripts R et Python personnalisés dans Azure ML : vous guide tout au long du processus d’ajout de code personnalisé a(R ou Python), de traitement des données et de visualisation des résultats.
- Analyse des données PyPI pour déterminer la prise en charge de Python 3 : estimez le point lorsque la demande pour Python 3 outstrips qui pour Python 2.7 à l’aide de Python.