Configurer un labo dans Azure Lab Services pour l’analytique du Big Data à l’aide du déploiement Docker de HortonWorks Data Platform
Important
Azure Lab Services sera mis hors service le 28 juin 2027. Pour plus d’informations, consultez le guide de mise hors service.
Remarque
Cet article fait référence aux fonctionnalités disponibles dans les plans de labo, qui ont remplacé les comptes de labo.
Cet article explique comment configurer un labo pour enseigner une classe d’analytique du Big Data. Un cours d’analytique du Big Data enseigne aux utilisateurs comment gérer de grands volumes de données. Elle leur enseigne également à appliquer des algorithmes d’apprentissage automatique et statistique pour dériver des insights sur les données. L’un des principaux objectifs est d’apprendre à utiliser des outils d’analytique données, tels que le package logiciel open source d’Apache Hadoop. Ce package logiciel fournit des outils pour le stockage, la gestion et le traitement du Big Data.
Dans ce labo, les utilisateurs du labo utilisent une version commerciale bien connue de Hadoop fournie par Cloudera, appelée Hortonworks Data Platform (HDP). Plus précisément, les utilisateurs du labo utilisent HDP Sandbox 3.0.1, qui est une version simplifiée et facile à utiliser de la plateforme. HDP Sandbox 3.0.1 est également gratuit, et destiné à l’apprentissage et à l’expérimentation. Bien que cette classe puisse utiliser des machines virtuelles Windows ou Linux avec HDP Sandbox déployé, Cet article explique comment utiliser Windows.
Un autre aspect intéressant est que vous déployez HDP Sandbox sur les machines virtuelles de labo à l’aide de conteneurs Docker. Chaque conteneur Docker fournit son propre environnement isolé pour que les applications logicielles s’y exécutent. Sur le plan conceptuel, les conteneurs Docker sont similaires aux machines virtuelles imbriquées et peuvent être utilisés pour déployer et exécuter facilement un large éventail d’applications logicielles basées sur des images conteneur fournies sur Docker Hub. Le script de déploiement de Cloudera pour HDP Sandbox extrait automatiquement l’image Docker de HDP Sandbox 3.0.1 à partir de Docker Hub et exécute deux conteneurs Docker :
- sandbox-hdp
- sandbox-proxy
Prérequis
Pour pouvoir configurer ce Lab, vous devez avoir accès à un abonnement Azure. Demandez à l’administrateur de votre organisation si vous pouvez accéder à un abonnement Azure existant. Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Configuration du laboratoire
Paramètres du plan de labo
Une fois que vous disposez d’un abonnement Azure, vous pouvez créer un plan de labo dans Azure Lab Services. Pour plus d’informations sur la création d’un nouveau plan de labo, consultez Démarrage rapide : configurer des ressources pour créer des labos. Vous pouvez aussi utiliser un plan de labo existant.
Ce labo utilise des images de la Place de marché Azure Windows 10 Professionnel comme image de machine virtuelle de base. Vous devez d’abord activer cette image dans votre plan de labo. Cela permet aux créateurs de labo de sélectionner l’image comme image de base pour leur labo.
Suivez ces étapes pour activer ces images de la Place de marché Azure disponibles pour les créateurs de labo. Sélectionnez l’une des images Windows 10 de la Place de marché Azure.
Paramètres du labo
Créez un labo pour votre plan de labo. Pour obtenir des instructions sur la création d'un labo, consultez Tutoriel : Configurer un labo. Utilisez les paramètres suivants pour la création du labo.
| Paramètres du labo | Valeur/instructions |
|---|---|
| Taille de la machine virtuelle | Moyenne (virtualisation imbriquée). Cette taille de machine virtuelle est idéale pour les bases de données relationnelles, la mise en cache en mémoire et l’analytique. Elle prend également en charge la virtualisation imbriquée. |
| Image de machine virtuelle | Windows 10 Professionnel |
Remarque
Utilisez la taille de machine virtuelle Moyenne (virtualisation imbriquée), car le déploiement de HDP Sandbox à l’aide de Docker nécessite Windows Hyper-V avec virtualisation imbriquée et au moins 10 Go de RAM.
Configuration du modèle de machine
Pour configurer le modèle de machine :
- Installation de Docker
- Déployer HDP Sandbox
- Utilisation de PowerShell et du Planificateur de tâches Windows pour démarrer automatiquement les conteneurs Docker
Installation de Docker
Les étapes de cette section sont basées sur les instructions de Cloudera pour un déploiement à l’aide de conteneurs Docker.
Pour utiliser des conteneurs Docker, vous devez d’abord installer Docker Desktop sur le modèle de machine virtuelle :
Suivez les étapes de la section Prerequisites (Configuration requise) pour installer Docker pour Windows.
Important
Assurez-vous que l’option de configuration Utiliser des conteneurs Windows au lieu de conteneurs Linux n’est pas cochée.
Assurez-vous que les conteneurs Windows et les fonctionnalités Hyper-V sont activés.
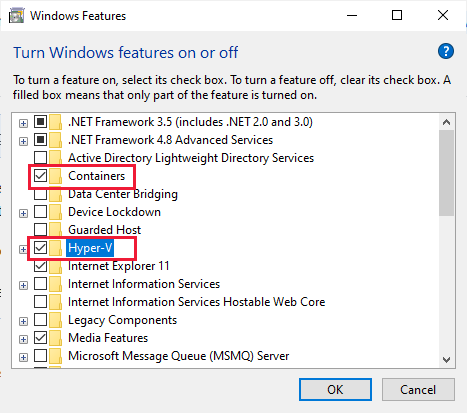
Suivez les étapes de la section Memory for Windows (Mémoire pour Windows) pour paramétrer la configuration de la mémoire de Docker.
Avertissement
Si vous cochez par inadvertance l’option Utiliser des conteneurs Windows au lieu de conteneurs Linux lors de l’installation de Docker, vous ne verrez pas les paramètres de configuration de la mémoire. Pour corriger ce problème, vous pouvez basculer vers l’utilisation de conteneurs Linux en cliquant sur l’icône Docker dans la barre d’état système de Windows ; lorsque le menu Docker Desktop s’ouvre, sélectionnez Basculer vers les conteneurs Linux.
Déployer HDP Sandbox
Ensuite, déployez HDP Sandbox puis accédez-y à l’aide du navigateur.
Vérifiez que vous avez installé Git Bash comme indiqué dans la section sur les prérequis du guide. Il est recommandé pour effectuer les étapes suivantes.
À l’aide du guide de Cloudera pour le déploiement et l’installation de Docker, effectuez les étapes décrites dans les sections suivantes :
- Déployer HDP Sandbox
- Vérifier HDP Sandbox
Avertissement
Lorsque vous téléchargez le fichier .zip le plus récent pour HDP, veillez à ne pas enregistrer le fichier .zip dans un chemin de répertoire qui comprend des espaces blancs.
Remarque
Si vous recevez une exception au cours du déploiement indiquant que le lecteur n’a pas été partagé, vous devez partager votre lecteur C avec Docker afin que les conteneurs Linux de HDP puissent accéder aux fichiers Windows locaux. Pour corriger ce problème, cliquez sur l’icône Docker dans la barre d’état système de Windows pour ouvrir le menu Docker Desktop et sélectionnez Paramètres. Lorsque la boîte de dialogue Paramètres de Docker s’ouvre, sélectionnez Ressources > Partage de fichiers et cochez le lecteur C. Vous pouvez ensuite répéter les étapes pour déployer HDP Sandbox.
Une fois les conteneurs Docker pour HDP Sandbox déployés et opérationnels, vous pouvez accéder à l’environnement en lançant votre navigateur. Suivez les instructions de Cloudera pour ouvrir la page d’accueil de Sandbox et lancer le tableau de bord HDP.
Remarque
Ces instructions supposent que vous avez d’abord mappé l’adresse IP locale de l’environnement du bac à sable à l’adresse sandbox-hdp.hortonworks.com dans le fichier hôte sur votre modèle de machine virtuelle. Si vous n’avez pas effectué ce mappage, vous pouvez accéder à la page d’accueil de Sandbox en accédant à l’adresse
http://localhost:8080.
Démarrer automatiquement les conteneurs Docker lorsque les utilisateurs du labo se connectent
Pour fournir une expérience simplifiée aux utilisateurs du labo, créez un script PowerShell qui effectue automatiquement les opérations suivantes :
- Démarre les conteneurs Docker HDP Sandbox lorsqu’un utilisateur du labo démarre sa machine virtuelle de labo et s’y connecte.
- Lance le navigateur et accède à la page d’accueil de Sandbox.
Utilisez le Planificateur de tâches Windows pour exécuter automatiquement ce script lorsqu’un utilisateur du labo se connecte à sa machine virtuelle. Pour configurer le Planificateur de tâches, effectuez les étapes suivantes : Création de scripts d’analytique du Big Data.
Conclusion
Cet article vous a présenté les étapes nécessaires à la création d’un labo pour une classe d’analytique du Big Data. La classe d’analytique du Big Data utilise Hortonworks Data Platform déployé avec Docker. La configuration de ce type de classe peut être utilisée pour des classes similaires d’Analytique données. Cette configuration peut également s’appliquer à d’autres types de classes qui utilisent Docker pour le déploiement.
Étapes suivantes
L’image du modèle peut à présent être publiée dans le labo. Pour plus d’informations, consultez Publier le modèle de machine virtuelle.
Au fil de la configuration de votre instance Lab, consultez les articles suivants :