Créer un cluster Spark dans HDInsight sur AKS (préversion)
Important
Azure HDInsight sur AKS a été mis hors service le 31 janvier 2025. En savoir plus avec cette annonce.
Vous devez migrer vos charges de travail vers Microsoft Fabric ou un produit Azure équivalent pour éviter l’arrêt brusque de vos charges de travail.
Important
Cette fonctionnalité est actuellement en préversion. Les Conditions d’utilisation supplémentaires pour les préversions Microsoft Azure incluent des termes juridiques supplémentaires qui s’appliquent aux fonctionnalités Azure en version bêta, en préversion ou qui ne sont pas encore publiées en disponibilité générale. Pour plus d’informations sur cette préversion spécifique, consultez informations sur la préversion d'Azure HDInsight sur AKS. Pour des questions ou des suggestions de fonctionnalités, envoyez une demande sur AskHDInsight avec les détails et suivez-nous pour plus de mises à jour sur Communauté Azure HDInsight.
Une fois que les prérequis de l'abonnement et les prérequis des ressources sont complétés, et après avoir déployé un pool de clusters, continuez à utiliser le portail Azure pour créer un cluster Spark. Vous pouvez utiliser le portail Azure pour créer un cluster Apache Spark dans le pool de clusters. Vous pouvez ensuite créer un notebook Jupyter et l’utiliser pour exécuter des requêtes Spark SQL sur des tables Apache Hive.
Dans le portail Azure, tapez "cluster pools" et sélectionnez "cluster pools" pour accéder à la page des "cluster pools". Dans la page pools de clusters, sélectionnez le pool de clusters dans lequel vous pouvez ajouter un nouveau cluster Spark.
Dans la page du pool de clusters spécifique, cliquez sur + Nouveau cluster.
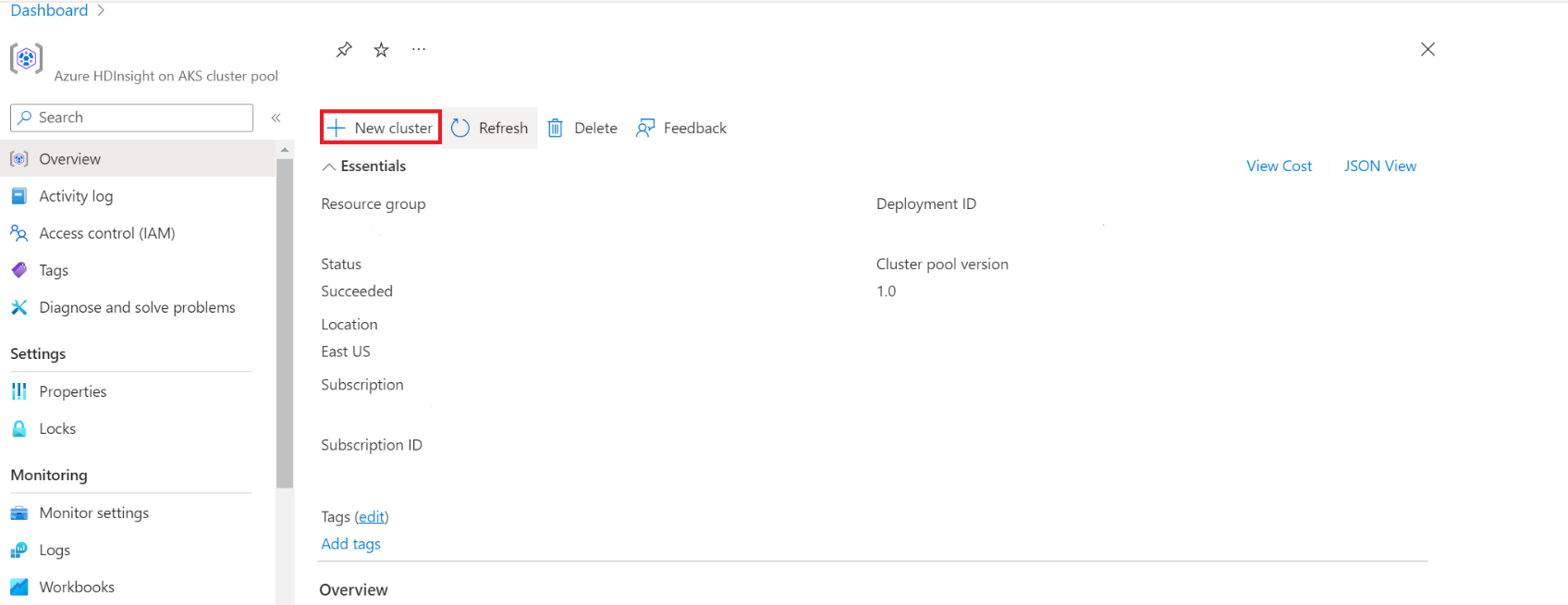
Cette étape ouvre la page de création de cluster.
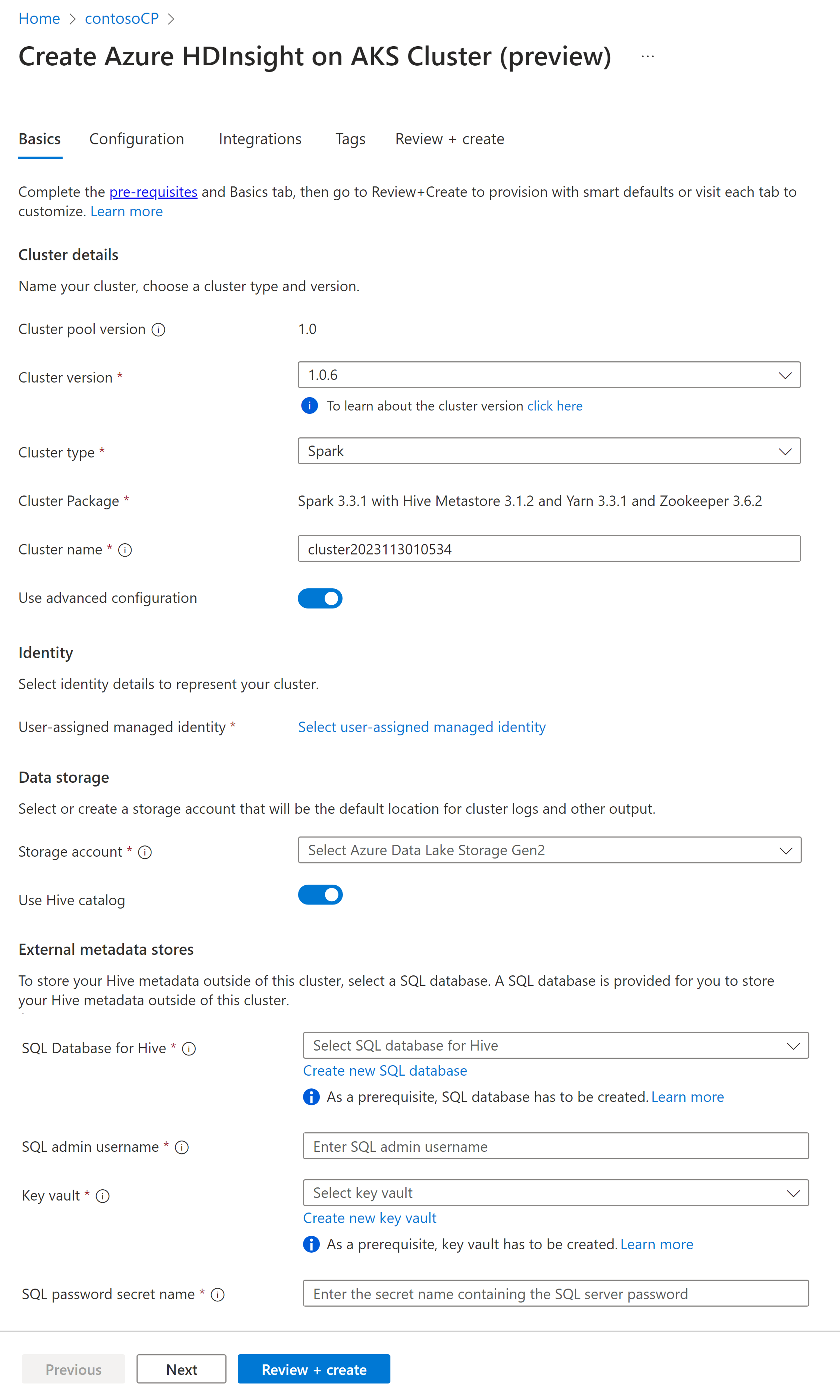
Propriété Description Abonnement L'abonnement Azure qui a été enregistré pour une utilisation avec HDInsight sur AKS dans la section "Conditions préalables" sera prérempli. Groupe de ressources Le même groupe de ressources que le pool de clusters sera prérempli. Région La région du pool de clusters et de l'entité virtuelle sera préremplie. Pool de clusters Le nom du pool de clusters est pré-rempli Version du pool HDInsight La version du pool de clusters est préremplie à partir de la sélection de création du pool HDInsight sur la version AKS Spécifier l'HDI dans la version AKS Type de cluster Dans la liste déroulante, sélectionnez Spark Version du Cluster Sélectionnez la version de l’image à utiliser Nom du cluster Entrez le nom du nouveau cluster Identité gérée assignée par l'utilisateur Sélectionnez l’identité managée affectée par l’utilisateur qui fonctionnera en tant que chaîne de connexion avec le stockage Compte de stockage Sélectionnez le compte de stockage précréé qui doit être utilisé comme stockage principal pour le cluster Nom du conteneur Sélectionnez le nom du conteneur (unique) s’il est précréé ou créez un conteneur Catalogue Hive (facultatif) Sélectionnez le metastore Hive précréé(Azure SQL DB) Une base de données SQL pour Hive Dans la liste déroulante, sélectionnez la base de données SQL dans laquelle ajouter des tables hive-metastore. Nom d’utilisateur administrateur SQL Entrez le nom d’utilisateur administrateur SQL Coffre-fort des clés Dans la liste déroulante, sélectionnez le coffre de clés, qui contient un secret avec mot de passe pour le nom d’utilisateur administrateur SQL Nom du secret de mot de passe SQL Entrez le nom du secret depuis le Key Vault où le mot de passe de la base de données SQL est stocké Note
- Actuellement, HDInsight prend uniquement en charge les bases de données MS SQL Server.
- En raison de la limitation Hive, le caractère « - » (trait d’union) dans le nom de la base de données du metastore n’est pas pris en charge.
Sélectionnez Suivant : Configuration + tarification pour continuer.
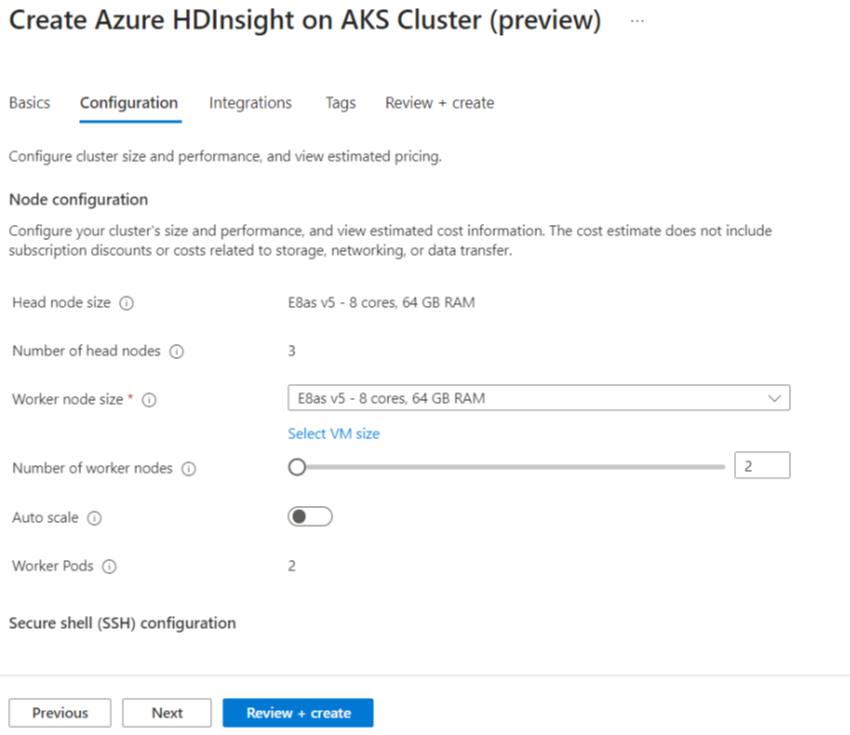
capture d’écran
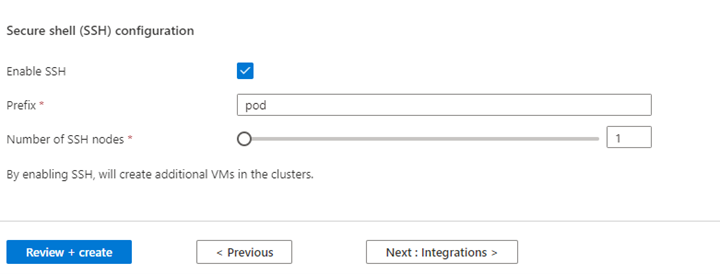
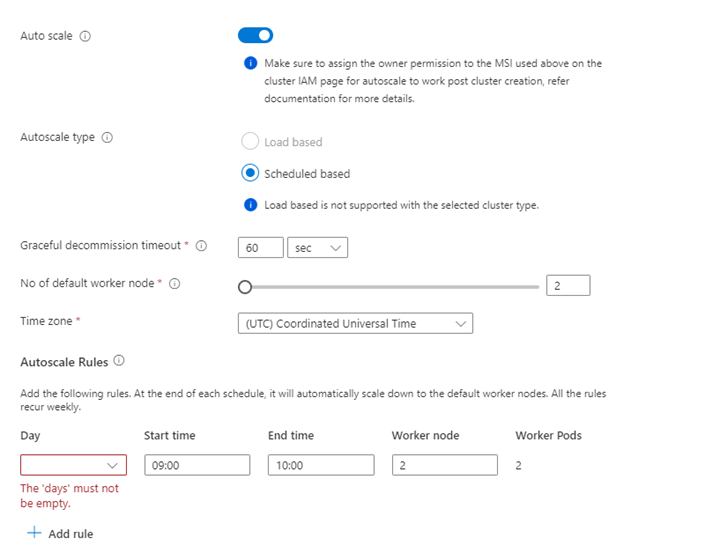
Propriété Description Taille du nœud Sélectionnez la taille du nœud à utiliser pour les nœuds Spark Nombre de nœuds de travail Sélectionnez le nombre de nœuds pour le cluster Spark. Parmi ceux-ci, trois nœuds sont réservés pour les services de coordination et système, les nœuds restants sont dédiés aux travailleurs Spark, un travailleur par nœud. Par exemple, dans un cluster à cinq nœuds, il y a deux workers Mise à l’échelle automatique Cliquez sur le bouton bascule pour activer la mise à l’échelle automatique Type de mise à l’échelle automatique Sélectionnez entre l’autoscaling basé sur le chargement ou sur l'horaire. Délai d'expiration de mise hors service gracieux Spécifier le délai de désactivation en douceur Nombre de nœuds de travail par défaut Sélectionner le nombre de nœuds pour la mise à l’échelle automatique Fuseau horaire Sélectionner le fuseau horaire Règles de mise à l’échelle automatique Sélectionnez le jour, l’heure de début, l’heure de fin, nombre de nœuds de calcul. Activer SSH Si cette option est activée, vous permet de définir le préfixe et le nombre de nœuds SSH Cliquez sur Suivant : Intégrations pour activer et sélectionner Log Analytics pour la journalisation.
Azure Prometheus pour la surveillance et les métriques peut être activé après la création du cluster.
capture d’écran
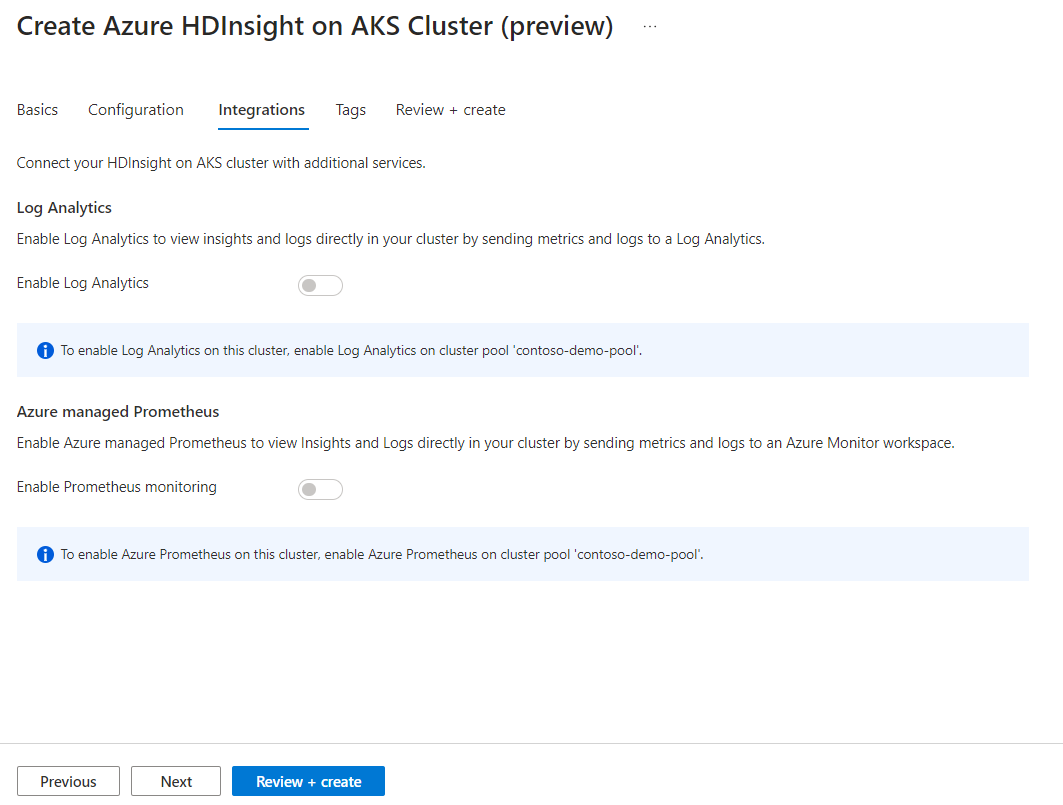
Cliquez sur Suivant : Balises pour passer à la page suivante.
capture d’écran

Dans la page Balises, entrez les balises que vous souhaitez ajouter à votre ressource.
Propriété Description Nom Optionnel. Entrez un nom tel que HDInsight sur AKS Private Preview pour identifier facilement toutes les ressources associées à vos ressources Valeur Laissez cette valeur vide Ressource Sélectionner toutes les ressources sélectionnées Cliquez sur Suivant : Vérifiez + créez.
Dans la page Vérification + création, recherchez le message de validation réussie en haut de la page, puis cliquez sur Créer.
Le déploiement est en cours page s’affiche sur laquelle le cluster est créé. La création du cluster prend 5 à 10 minutes. Une fois le cluster créé, votre déploiement est terminé message s’affiche. Si vous quittez la page, vous pouvez vérifier l’état de vos notifications.
Accédez à la page d'aperçu du cluster ; vous pouvez y voir des liens de point de terminaison.