Écrire des messages d’événement dans Azure Data Lake Storage Gen2 avec l’API Apache Flink® DataStream
Important
Azure HDInsight sur AKS a été mis hors service le 31 janvier 2025. En savoir plus grâce à cette annonce.
Vous devez migrer vos charges de travail vers Microsoft Fabric ou un produit Azure équivalent pour éviter l’arrêt brusque de vos charges de travail.
Important
Cette fonctionnalité est actuellement en préversion. Les Conditions d’utilisation supplémentaires pour les préversions Microsoft Azure incluent des termes juridiques supplémentaires qui s’appliquent aux fonctionnalités Azure en version bêta, en préversion ou qui ne sont pas encore publiées en disponibilité générale. Pour plus d'informations sur cette préversion spécifique, consultez les informations en préversion d'Azure HDInsight sur AKS . Pour des questions ou des suggestions de fonctionnalités, envoyez une demande sur AskHDInsight avec les détails et suivez-nous pour plus de mises à jour sur Communauté Azure HDInsight.
Apache Flink utilise des systèmes de fichiers pour consommer et stocker de manière permanente les données, à la fois pour les résultats des applications et pour la tolérance de panne et la récupération. Dans cet article, découvrez comment écrire des messages d’événement dans Azure Data Lake Storage Gen2 avec l’API DataStream.
Conditions préalables
- cluster Apache Flink sur HDInsight sur AKS
-
Cluster Apache Kafka sur HDInsight
- Vous devez vous assurer que les paramètres réseau sont pris en charge comme décrit dans Utilisation d’Apache Kafka sur HDInsight. Assurez-vous que HDInsight sur AKS et les clusters HDInsight se trouvent dans le même réseau virtuel.
- Utiliser MSI pour accéder à ADLS Gen2
- IntelliJ pour le développement sur une machine virtuelle Azure dans HDInsight sur un réseau virtuel AKS
Connecteur Apache Flink Système de fichiers
Ce connecteur de système de fichiers fournit les mêmes garanties pour BATCH et STREAMING et est conçu pour fournir exactement une sémantique pour l’exécution de streaming. Pour plus d’informations, consultez Flink DataStream Filesystem.
Connecteur Apache Kafka
Flink fournit un connecteur Apache Kafka pour lire des données et écrire des données dans des rubriques Kafka avec exactement une seule garantie. Pour plus d’informations, consultez du connecteur Apache Kafka.
Générer le projet pour Apache Flink
pom.xml sur IntelliJ IDEA
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.17.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<kafka.version>3.2.0</kafka.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-files -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Programme pour le récepteur ADLS Gen2
abfsGen2.java
Note
Remplacez Apache Kafka sur le cluster HDInsight bootStrapServers par vos propres répartiteurs pour Kafka 3.2
package contoso.example;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.configuration.MemorySize;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import java.time.Duration;
public class KafkaSinkToGen2 {
public static void main(String[] args) throws Exception {
// 1. get stream execution env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Configuration flinkConfig = new Configuration();
flinkConfig.setString("classloader.resolve-order", "parent-first");
env.getConfig().setGlobalJobParameters(flinkConfig);
// 2. read kafka message as stream input, update your broker ip's
String brokers = "<update-broker-ip>:9092,<update-broker-ip>:9092,<update-broker-ip>:9092";
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("click_events")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
stream.print();
// 3. sink to gen2, update container name and storage path
String outputPath = "abfs://<container-name>@<storage-path>.dfs.core.windows.net/flink/data/click_events";
final FileSink<String> sink = FileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(2))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
.build();
stream.sinkTo(sink);
// 4. run stream
env.execute("Kafka Sink To Gen2");
}
}
package jar et envoyez-le à Apache Flink.
Chargez le fichier jar dans ABFS.
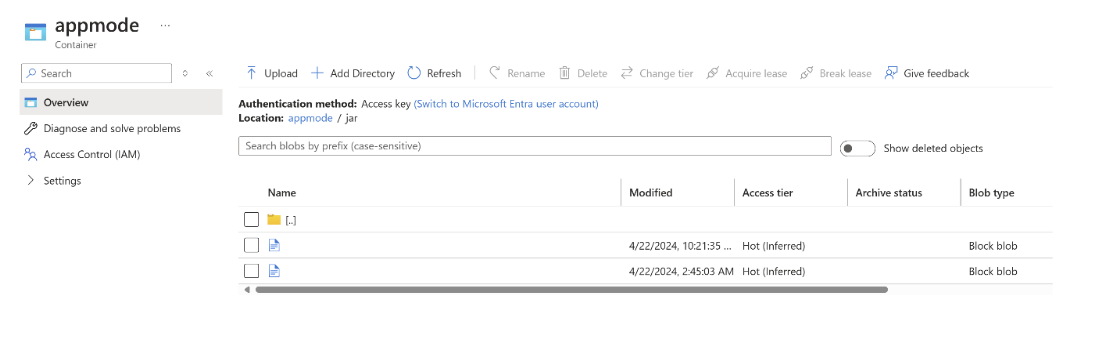
Transmettez les informations du job jar lors de la création du cluster
AppMode.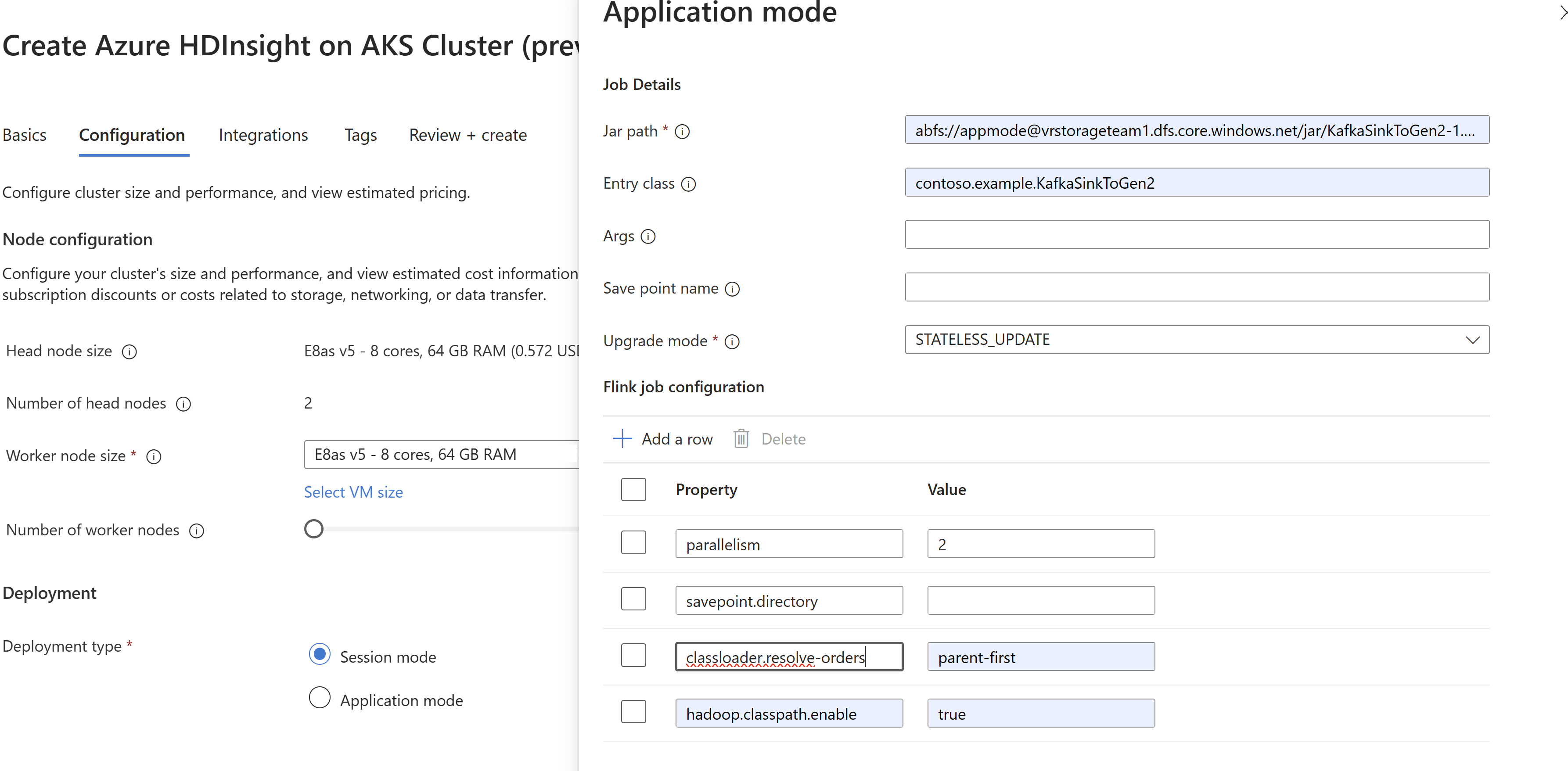
Note
Veillez à ajouter classloader.resolve-order en tant que « parent-first » et hadoop.classpath.enable en tant que
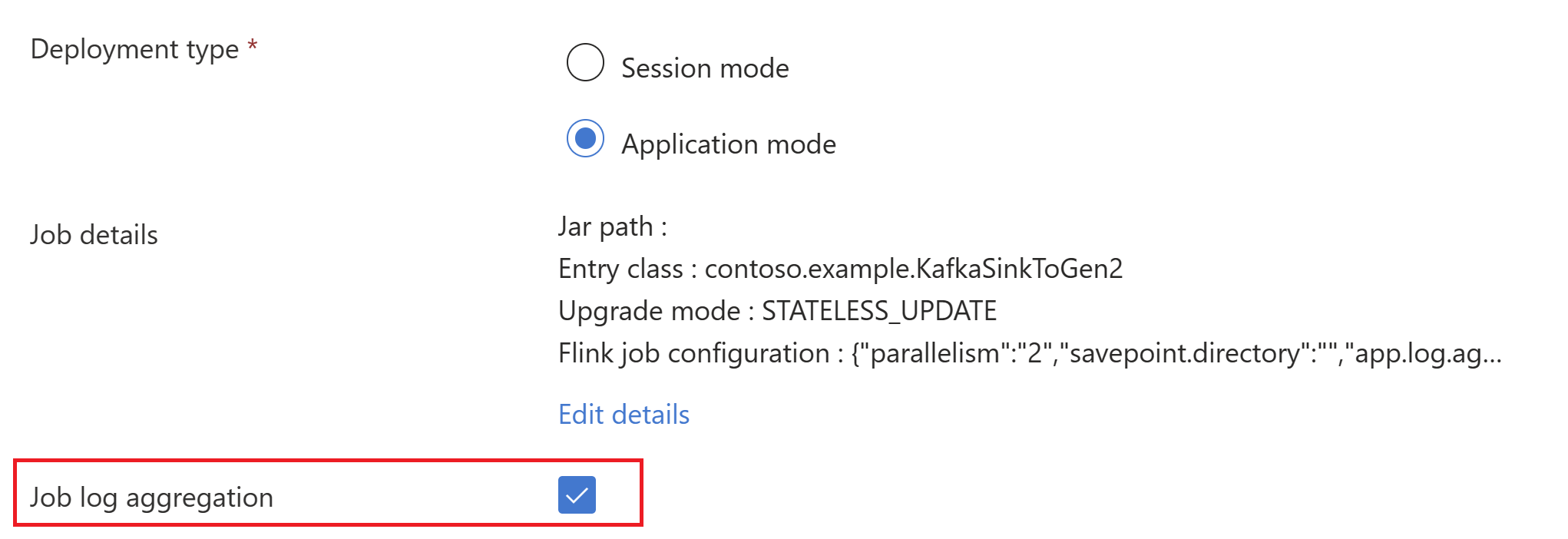
trueSélectionnez l'agrégation du journal de travaux pour envoyer les journaux de travaux vers le compte de stockage.
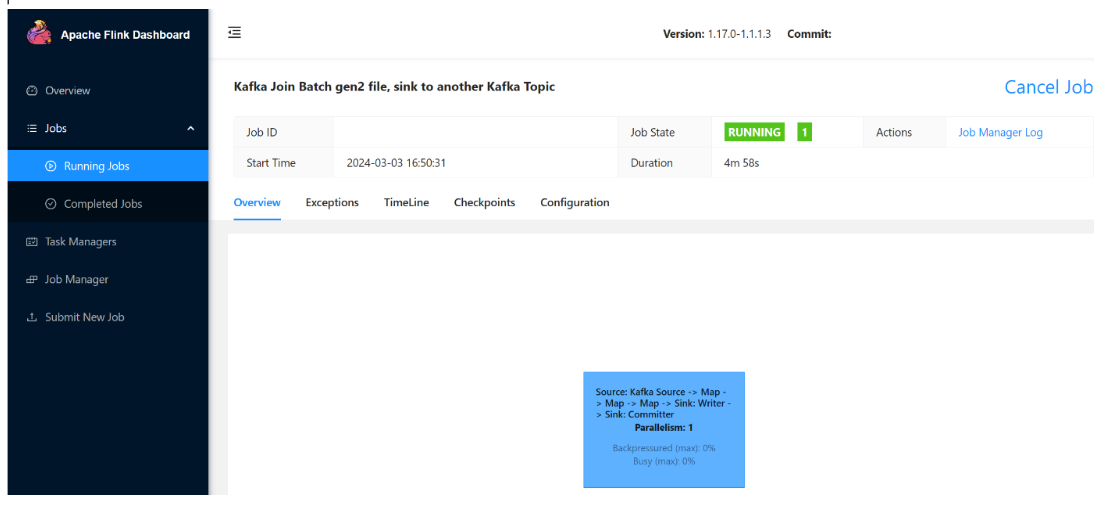
Vous pouvez voir la tâche en cours d'exécution.
capture d’écran




Valider les données de streaming sur ADLS Gen2
Nous voyons le flux click_events se diriger vers ADLS Gen2.

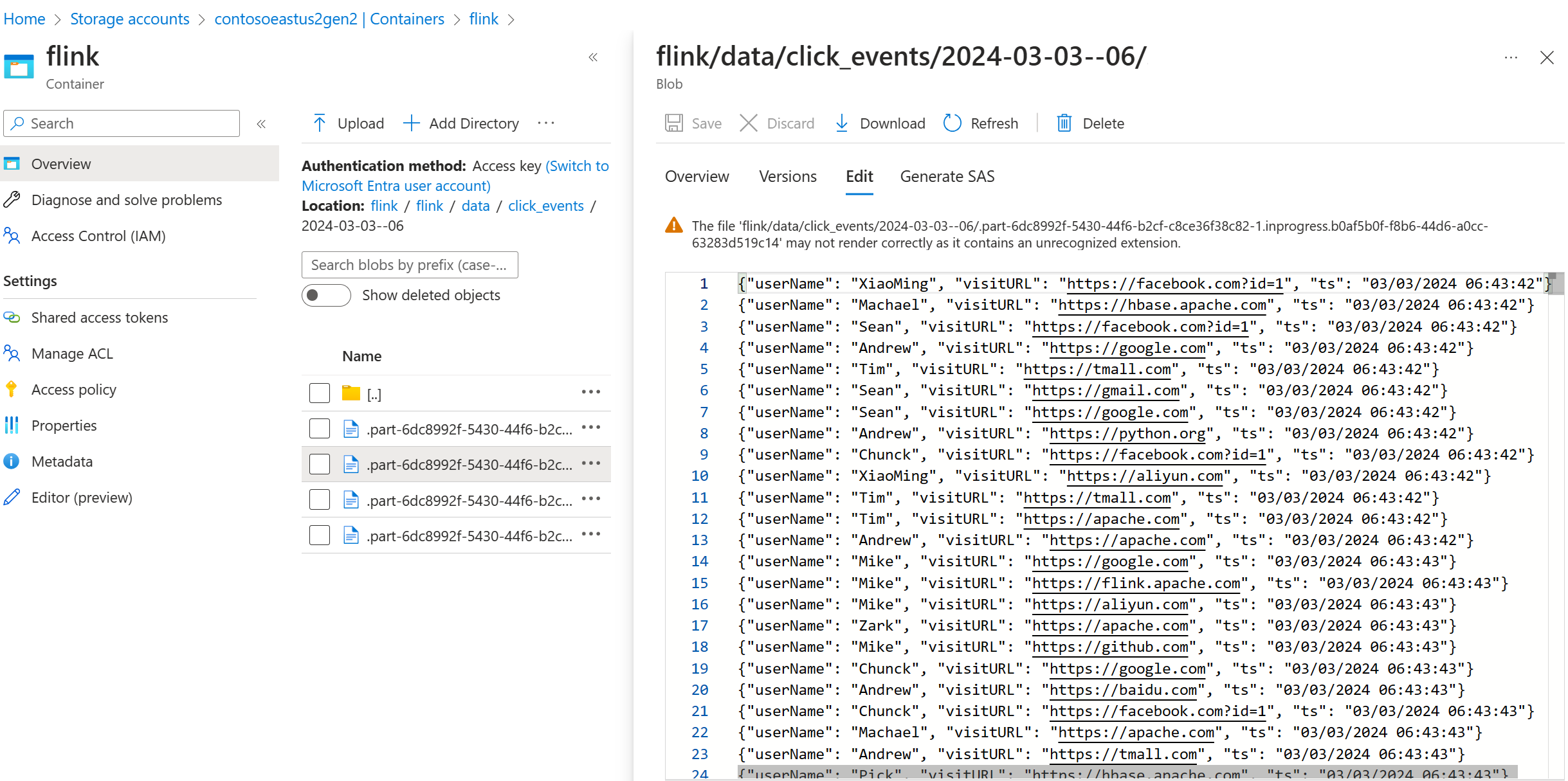
Vous pouvez spécifier une stratégie de rotation qui roule le fichier de partie en cours selon l'une des trois conditions suivantes :
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(5))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
Référence
- Connecteur Apache Kafka
- Flink DataStream Filesystem
- Site Web Apache Flink
- Apache, Apache Kafka, Kafka, Apache Flink, Flink et les noms de projet open source associés sont marques déposées de la Apache Software Foundation (ASF).