Migration d’Azure Batch AI vers Azure Machine Learning service
Le service Azure Batch AI sera mis hors service en mars. Les fonctionnalités de formation et de notation à l’échelle de Batch AI sont désormais disponibles dans Azure Machine Learning service, qui a été mis à la disposition générale le 4 décembre 2018.
Entre autres fonctionnalités de Machine Learning, Azure Machine Learning service inclut une cible de calcul gérée sur le cloud pour les modèles Machine Learning de formation, de déploiement et de notation. Cette cible de calcul est appelée Capacité de calcul Machine Learning. Commencez à migrer et à l’utiliser dès aujourd’hui. Vous pouvez interagir avec Azure Machine Learning service via ses Kits de développement logiciel (SDK) Python, son interface de ligne de commande et le portail Azure.
La mise à niveau de Batch AI en préversion vers Azure Machine Learning service en disponibilité générale vous donne une meilleure expérience au travers de concepts qui sont plus faciles à utiliser, comme des estimateurs et des magasins de données. Il garantit également les contrats SLA et le support technique des clients du service Azure au niveau de la disponibilité générale.
Azure Machine Learning service offre également de nouvelles fonctionnalités, comme le Machine Learning automatisé, le réglage des hyperparamètres et les pipelines Machine Learning, qui sont utiles dans la plupart des charges de travail d’intelligence artificielle de grande échelle. La possibilité de déployer un modèle formé sans passer à un service distinct permet de terminer la boucle de science des données, depuis la préparation des données (avec le Kit de développement logiciel de préparation des données) jusqu’à l’opérationnalisation et à la supervision du modèle.
Démarrer la migration
Pour éviter les interruptions de vos applications et tirer parti des dernières fonctionnalités, procédez comme suit avant le 31 mars 2019 :
Créer un espace de travail Azure Machine Learning service et le prendre en main :
Installez le Kit de développement logiciel (SDK) Azure Machine Learning et le Kit de développement logiciel de préparation des données.
Configurez Capacité de calcul Machine Learning pour l’entraînement de modèle.
Mettez à jour vos scripts pour utiliser Capacité de calcul Machine Learning. Les sections suivantes montrent comment le code commun que vous utilisez pour Batch AI correspond au code pour Azure Machine Learning.
Créer des espaces de travail
Le concept d’initialisation d’un espace de travail avec un fichier configuration.json dans Azure Batch AI équivaut à utiliser un fichier de configuration dans Azure Machine Learning service.
Pour Batch AI, vous le faisiez ainsi :
sys.path.append('../../..')
import utilities as utils
cfg = utils.config.Configuration('../../configuration.json')
client = utils.config.create_batchai_client(cfg)
utils.config.create_resource_group(cfg)
_ = client.workspaces.create(cfg.resource_group, cfg.workspace, cfg.location).result()
Pour le service Azure Machine Learning, essayez :
from azureml.core.workspace import Workspace
ws = Workspace.from_config()
print('Workspace name: ' + ws.name,
'Azure region: ' + ws.location,
'Subscription id: ' + ws.subscription_id,
'Resource group: ' + ws.resource_group, sep = '\n')
En outre, vous pouvez également créer un espace de travail directement en spécifiant les paramètres de configuration comme
from azureml.core import Workspace
# Create the workspace using the specified parameters
ws = Workspace.create(name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group,
location = workspace_region,
create_resource_group = True,
exist_ok = True)
ws.get_details()
# write the details of the workspace to a configuration file to the notebook library
ws.write_config()
Découvrez plus d’informations sur la classe d’espace de travail Azure Machine Learning dans la documentation de référence du Kit de développement logiciel (SDK).
Créer des clusters de calcul
Azure Machine Learning prend en charge plusieurs cibles de calcul : certaines d’entre elles sont gérées par le service et d’autres peuvent être attachées à votre espace de travail (par exemple un cluster HDInsight ou une machine virtuelle distante. Découvrez plus d’informations sur les différentes cibles de calcul. Le concept de création d’un cluster de calcul Azure Batch AI correspond à la création d’un cluster Capacité de calcul Machine Learning dans Azure Machine Learning service. La création d’un cluster Capacité de calcul Machine Learning prend en entrée une configuration de calcul d’une façon similaire à celle dont vous passez des paramètres dans Azure Batch AI. Une chose à noter est que la mise à l’échelle automatique est activée par défaut sur votre cluster Capacité de calcul Machine Learning, alors qu’il est désactivé par défaut dans Azure Batch AI.
Pour Batch AI, vous le faisiez ainsi :
nodes_count = 2
cluster_name = 'nc6'
parameters = models.ClusterCreateParameters(
vm_size='STANDARD_NC6',
scale_settings=models.ScaleSettings(
manual=models.ManualScaleSettings(target_node_count=nodes_count)
),
user_account_settings=models.UserAccountSettings(
admin_user_name=cfg.admin,
admin_user_password=cfg.admin_password or None,
admin_user_ssh_public_key=cfg.admin_ssh_key or None,
)
)
_ = client.clusters.create(cfg.resource_group, cfg.workspace, cluster_name, parameters).result()
Pour le service Azure Machine Learning, essayez :
from azureml.core.compute import ComputeTarget, AmlCompute
from azureml.core.compute_target import ComputeTargetException
# Choose a name for your CPU cluster
gpu_cluster_name = "nc6"
# Verify that cluster does not exist already
try:
gpu_cluster = ComputeTarget(workspace=ws, name=gpu_cluster_name)
print('Found existing cluster, use it.')
except ComputeTargetException:
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_NC6',
vm_priority='lowpriority',
min_nodes=1,
max_nodes=2,
idle_seconds_before_scaledown='300',
vnet_resourcegroup_name='<my-resource-group>',
vnet_name='<my-vnet-name>',
subnet_name='<my-subnet-name>')
gpu_cluster = ComputeTarget.create(ws, gpu_cluster_name, compute_config)
gpu_cluster.wait_for_completion(show_output=True)
Découvrez plus d’informations sur la classe d’espace de travail AML dans la documentation de référence du SDK. Notez que dans la configuration ci-dessus, seuls vm_size et max_nodes sont obligatoires, et que le reste des propriétés, comme VNets, concerne seulement la configuration avancée d’un cluster.
Superviser l’état de votre cluster
Cette tâche est plus simple dans Azure Machine Learning service, comme vous le verrez ci-dessous.
Pour Batch AI, vous le faisiez ainsi :
cluster = client.clusters.get(cfg.resource_group, cfg.workspace, cluster_name)
utils.cluster.print_cluster_status(cluster)
Pour le service Azure Machine Learning, essayez :
gpu_cluster.get_status().serialize()
Obtenir une référence à un compte de stockage
Le concept d’un stockage de données tel qu’un blob a été simplifié dans Azure Machine Learning service avec l’objet DataStore. Par défaut, votre espace de travail Machine Learning service crée un compte de stockage, mais vous pouvez aussi attacher votre propre stockage dans le cadre de la création de l’espace de travail.
Pour Batch AI, vous le faisiez ainsi :
azure_blob_container_name = 'batchaisample'
blob_service = BlockBlobService(cfg.storage_account_name, cfg.storage_account_key)
blob_service.create_container(azure_blob_container_name, fail_on_exist=False)
Pour le service Azure Machine Learning, essayez :
ds = ws.get_default_datastore()
print(ds.datastore_type, ds.account_name, ds.container_name)
Découvrez plus d’informations sur l’inscription de comptes de stockage supplémentaires ou sur l’obtention d’une référence à un autre magasin de données inscrit dans la documentation d’Azure Machine Learning service.
Charger et télécharger des données
Avec l’un ou l’autre de ces services, vous pouvez charger facilement les données dans le compte de stockage en utilisant la référence du magasin de données ci-dessus. Pour Azure Batch AI, nous déployons également le script d’apprentissage dans le cadre du partage de fichiers : vous verrez cependant comment vous pouvez le spécifier dans le cadre de la configuration de votre tâche dans le cas d’Azure Machine Learning service.
Pour Batch AI, vous le faisiez ainsi :
mnist_dataset_directory = 'mnist_dataset'
utils.dataset.download_and_upload_mnist_dataset_to_blob(
blob_service, azure_blob_container_name, mnist_dataset_directory)
script_directory = 'tensorflow_samples'
script_to_deploy = 'mnist_replica.py'
blob_service.create_blob_from_path(azure_blob_container_name,
script_directory + '/' + script_to_deploy,
script_to_deploy)
Pour le service Azure Machine Learning, essayez :
import os
import urllib
os.makedirs('./data', exist_ok=True)
download_url = 'https://s3.amazonaws.com/img-datasets/mnist.npz'
urllib.request.urlretrieve(download_url, filename='data/mnist.npz')
ds.upload(src_dir='data', target_path='mnist_dataset', overwrite=True, show_progress=True)
path_on_datastore = ' mnist_dataset/mnist.npz' ds_data = ds.path(path_on_datastore) print(ds_data)
Créer des expériences
Comme mentionné ci-dessus, Azure Machine Learning service utilise un concept d’expérience similaire à celui d’Azure Batch AI. Chaque expérience peut ensuite avoir des exécutions individuelles, d’une façon similaire aux travaux dans Azure Batch AI. Azure Machine Learning service vous permet également d’avoir une hiérarchie sous chaque exécution parente, pour des exécutions enfants individuelles.
Pour Batch AI, vous le faisiez ainsi :
experiment_name = 'tensorflow_experiment'
experiment = client.experiments.create(cfg.resource_group, cfg.workspace, experiment_name).result()
Pour le service Azure Machine Learning, essayez :
from azureml.core import Experiment
experiment_name = 'tensorflow_experiment'
experiment = Experiment(ws, name=experiment_name)
Soumettre les travaux
Une fois que vous créez une expérience, vous avez différentes façons de soumettre une exécution. Dans cet exemple, nous essayons de créer un modèle d’apprentissage profond avec TensorFlow et nous utilisons pour cela un estimateur Azure Machine Learning service. Un estimateur est simplement une fonction wrapper sur la configuration d’exécution sous-jacente, ce qui facilite la soumission des exécutions ; les estimateurs sont actuellement pris en charge seulement pour Pytorch et TensorFlow. À travers le concept de magasins de données, vous verrez également combien il est devenu facile de spécifier les chemins de montage.
Pour Batch AI, vous le faisiez ainsi :
azure_file_share = 'afs'
azure_blob = 'bfs'
args_fmt = '--job_name={0} --num_gpus=1 --train_steps 10000 --checkpoint_dir=$AZ_BATCHAI_OUTPUT_MODEL --log_dir=$AZ_BATCHAI_OUTPUT_TENSORBOARD --data_dir=$AZ_BATCHAI_INPUT_DATASET --ps_hosts=$AZ_BATCHAI_PS_HOSTS --worker_hosts=$AZ_BATCHAI_WORKER_HOSTS --task_index=$AZ_BATCHAI_TASK_INDEX'
parameters = models.JobCreateParameters(
cluster=models.ResourceId(id=cluster.id),
node_count=2,
input_directories=[
models.InputDirectory(
id='SCRIPT',
path='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}/{1}'.format(azure_blob, script_directory)),
models.InputDirectory(
id='DATASET',
path='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}/{1}'.format(azure_blob, mnist_dataset_directory))],
std_out_err_path_prefix='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}'.format(azure_file_share),
output_directories=[
models.OutputDirectory(
id='MODEL',
path_prefix='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}'.format(azure_file_share),
path_suffix='Models'),
models.OutputDirectory(
id='TENSORBOARD',
path_prefix='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}'.format(azure_file_share),
path_suffix='Logs')
],
mount_volumes=models.MountVolumes(
azure_file_shares=[
models.AzureFileShareReference(
account_name=cfg.storage_account_name,
credentials=models.AzureStorageCredentialsInfo(
account_key=cfg.storage_account_key),
azure_file_url='https://{0}.file.core.windows.net/{1}'.format(
cfg.storage_account_name, azure_file_share_name),
relative_mount_path=azure_file_share)
],
azure_blob_file_systems=[
models.AzureBlobFileSystemReference(
account_name=cfg.storage_account_name,
credentials=models.AzureStorageCredentialsInfo(
account_key=cfg.storage_account_key),
container_name=azure_blob_container_name,
relative_mount_path=azure_blob)
]
),
container_settings=models.ContainerSettings(
image_source_registry=models.ImageSourceRegistry(image='tensorflow/tensorflow:1.8.0-gpu')),
tensor_flow_settings=models.TensorFlowSettings(
parameter_server_count=1,
worker_count=nodes_count,
python_script_file_path='$AZ_BATCHAI_INPUT_SCRIPT/'+ script_to_deploy,
master_command_line_args=args_fmt.format('worker'),
worker_command_line_args=args_fmt.format('worker'),
parameter_server_command_line_args=args_fmt.format('ps'),
)
)
La soumission de la tâche elle-même dans Azure Batch AI se fait via la fonction create.
job_name = datetime.utcnow().strftime('tf_%m_%d_%Y_%H%M%S')
job = client.jobs.create(cfg.resource_group, cfg.workspace, experiment_name, job_name, parameters).result()
print('Created Job {0} in Experiment {1}'.format(job.name, experiment.name))
Vous trouverez toutes les informations pour cet extrait de code d’apprentissage (notamment le fichier mnist_replica.py que nous avions chargé sur le partage de fichiers ci-dessus) dans le dépôt GitHub d’exemples de notebooks Azure Batch AI.
Pour le service Azure Machine Learning, essayez :
from azureml.train.dnn import TensorFlow
script_params={
'--num_gpus': 1,
'--train_steps': 500,
'--input_data': ds_data.as_mount()
}
estimator = TensorFlow(source_directory=project_folder,
compute_target=gpu_cluster,
script_params=script_params,
entry_script='tf_mnist_replica.py',
node_count=2,
worker_count=2,
parameter_server_count=1,
distributed_backend='ps',
use_gpu=True)
Vous trouverez toutes les informations pour cet extrait de code d’entraînement (notamment le fichier tf_mnist_replica.py) dans le dépôt GitHub d’exemples de notebooks Azure Machine Learning service. Le magasin de données lui-même peut être monté sur les nœuds individuels ou bien les données d’entraînement peuvent être téléchargées sur le nœud lui-même. Vous trouverez plus d’informations sur le référencement du magasin de données dans votre estimateur dans la documentation d’Azure Machine Learning service.
La soumission d’une exécution dans Azure Machine Learning service se fait via la fonction submit.
run = experiment.submit(estimator)
print(run)
Il existe une autre façon de spécifier des paramètres pour votre exécution : avec une configuration d’exécution, ce qui est spécialement pratique pour la définition d’un environnement d’entraînement personnalisé. Vous trouverez plus d’informations dans cet exemple de notebook AmlCompute.
Surveiller les exécutions
Une fois que vous soumettez une exécution, vous pouvez attendre qu’elle se termine ou bien la superviser dans Machine Learning service avec des widgets Jupyter pratiques que vous pouvez appeler directement à partir de votre code. Vous pouvez aussi extraire le contexte de n’importe quelle exécution précédente en parcourant les différentes expériences d’un espace de travail et les exécutions individuelles au sein de chaque expérience.
Pour Batch AI, vous le faisiez ainsi :
utils.job.wait_for_job_completion(client, cfg.resource_group, cfg.workspace,
experiment_name, job_name, cluster_name, 'stdouterr', 'stdout-wk-0.txt')
files = client.jobs.list_output_files(cfg.resource_group, cfg.workspace, experiment_name, job_name,
models.JobsListOutputFilesOptions(outputdirectoryid='stdouterr'))
for f in list(files):
print(f.name, f.download_url or 'directory')
Pour le service Azure Machine Learning, essayez :
run.wait_for_completion(show_output=True)
from azureml.widgets import RunDetails
RunDetails(run).show()
Voici un instantané de la façon dont le widget se chargerait dans votre bloc-notes pour examiner vos journaux en temps réel : 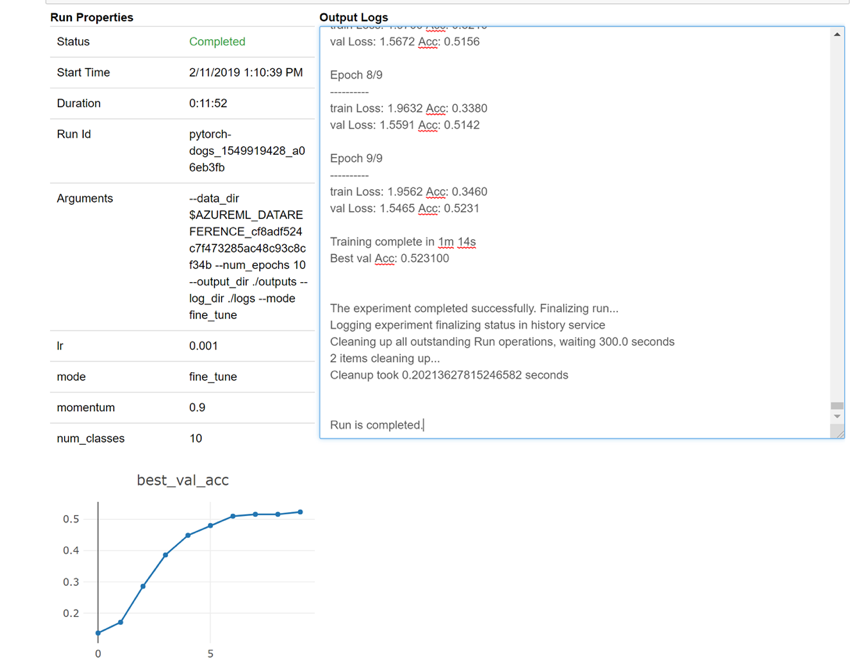
Modifier des clusters
La suppression d’un cluster est simple. En outre, Azure Machine Learning service vous permet de mettre à jour un cluster à partir du notebook si vous voulez le mettre à l’échelle avec un nombre de nœuds plus élevé ou augmenter la période d’inactivité avant une descente en puissance du cluster. Nous ne vous permettons pas de changer la taille de machine virtuelle du cluster lui-même, car cela nécessite un nouveau déploiement dans le back-end.
Pour Batch AI, vous le faisiez ainsi :
_ = client.clusters.delete(cfg.resource_group, cfg.workspace, cluster_name)
Pour le service Azure Machine Learning, essayez :
gpu_cluster.delete()
gpu_cluster.update(min_nodes=2, max_nodes=4, idle_seconds_before_scaledown=600)
Obtenir de l’aide
Batch AI est prévu pour mettre hors service le 31 mars et empêche déjà les nouveaux abonnements de s’inscrire auprès du service, sauf s’il est autorisé en soulevant une exception via le support. Contactez-nous sur Azure Batch AI Training Preview pour poser vos questions ou pour nous donner un feedback sur votre migration vers le service Azure Machine Learning.
Le service Azure Machine Learning est en disponibilité générale. Cela signifie qu’il est fourni avec un contrat SLA validé et un choix de différents plans de support.
La tarification de l’utilisation de l’infrastructure Azure par le biais du service IA Azure Batch ou du service Azure Machine Learning ne doit pas varier, car nous facturons uniquement le prix du calcul sous-jacent dans les deux cas. Pour plus d’informations, consultez la calculatrice de prix.
Vous trouverez la disponibilité des deux services selon les régions sur le portail Azure.
Étapes suivantes
Configurez une cible de calcul pour l’entraînement de modèle avec Azure Machine Learning service.
Passez en revue la feuille de route Azure pour découvrir d’autres mises à jour des services Azure.