Solution Network Performance Monitor : analyse des performances.
Important
À compter du 1er juillet 2021, vous ne pourrez plus ajouter de nouveaux tests dans un espace de travail existant ni activer un nouvel espace de travail dans Network Performance Monitor. Vous pouvez continuer à utiliser les tests créés avant le 1er juillet 2021. Pour réduire l’interruption de service de vos charges de travail actuelles, migrez vos tests de Network Performance Monitor vers le nouveau Moniteur de connexion dans Azure Network Watcher avant le 29 février 2024.
La fonctionnalité Analyseur de performances de Network Performance Monitor vous permet de surveiller la connectivité réseau entre les différents points de votre réseau. Vous pouvez surveiller les déploiements cloud et les emplacements locaux, plusieurs centres de données ainsi que les filiales et les applications/microservices multiniveaux stratégiques. Avec l’Analyseur de performances, vous pouvez détecter les problèmes réseau avant que vos utilisateurs ne se plaignent. Ses principaux avantages vous permettent de :
- Surveiller les pertes et la latence entre différents sous-réseaux et définir des alertes.
- Surveiller tous les chemins (notamment les chemins redondants) sur le réseau.
- Résoudre les problèmes réseau temporaires et ponctuels qui sont difficiles à répliquer.
- Déterminer le segment spécifique sur le réseau qui est responsable de la dégradation des performances.
- Surveiller l’intégrité du réseau sans SNMP.

Configuration
Pour ouvrir la configuration de Network Performance Monitor, ouvrez la solution Network Performance Monitor et sélectionnez Configurer.
Créer des réseaux
Dans Network Performance Monitor, un réseau est un conteneur logique de sous-réseaux. Cela vous permet d’organiser la surveillance de votre infrastructure réseau en fonction de vos besoins. Vous pouvez créer un réseau avec un nom convivial et lui ajouter des sous-réseaux selon votre logique métier. Par exemple, vous pouvez créer un réseau nommé Londres et y ajouter tous les sous-réseaux de votre centre de données de Londres. Ou vous pouvez créer un réseau nommé ContosoFrontEnd et y ajouter tous les sous-réseaux nommés Contoso qui servent le frontend de votre application. La solution crée automatiquement un réseau par défaut, qui contient tous les sous-réseaux découverts dans votre environnement.
Chaque fois que vous créez un réseau, vous y ajoutez un sous-réseau. Ce sous-réseau est alors supprimé du réseau par défaut. Si vous supprimez un réseau, toutes ses sous-réseaux sont automatiquement restitués au réseau par défaut. Le réseau par défaut joue le rôle de conteneur pour tous les sous-réseaux non contenus dans un réseau défini par un utilisateur. Vous ne pouvez pas modifier ou supprimer le réseau par défaut. Il reste toujours dans le système. Vous pouvez créer autant de réseaux personnalisés que nécessaire. Dans la plupart des cas, les sous-réseaux de votre organisation sont répartis sur plusieurs réseaux. Créez un ou plusieurs réseaux visant à regrouper vos sous-réseaux pour votre logique métier.
Pour créer un réseau :
- Sélectionnez l’onglet Réseaux.
- Sélectionnez Ajouter un réseau, puis entrez le nom et la description du réseau.
- Sélectionnez un ou plusieurs sous-réseaux, puis sélectionnez Ajouter.
- Sélectionnez Enregistrer pour enregistrer la configuration.
Créer des règles de surveillance
L’Analyseur de performances génère des événements d’intégrité lorsque le seuil des performances des connexions réseau entre deux sous-réseaux ou deux réseaux est dépassé. Le système peut apprendre ces seuils automatiquement. Vous pouvez également fournir des seuils personnalisés. Le système crée automatiquement une règle par défaut qui, à son tour, crée un événement d’intégrité chaque fois qu’une perte ou une latence entre une paire de liens réseau ou sous-réseau dépasse le seuil appris par le système. Ce processus permet à la solution de surveiller votre infrastructure réseau tant que vous n’avez pas créé explicitement de règles de surveillance. Si la règle par défaut est activée, tous les nœuds assurent la surveillance en envoyant des transactions synthétiques à tous les autres nœuds que vous avez activés. La règle par défaut est utile avec les réseaux de petite taille, par exemple si vous avez un petit nombre de serveurs qui exécutent un microservice et que vous souhaitez vous assurer que tous les serveurs sont connectés les uns aux autres.
Notes
Nous vous recommandons de désactiver la règle par défaut et de créer des règles de surveillance personnalisées, en particulier pour les réseaux importants dans lesquels vous utilisez un grand nombre de nœuds pour la surveillance. Les règles de surveillance personnalisées peuvent limiter le trafic généré par la solution et vous aider à organiser la surveillance de votre réseau.
Créez des règles de surveillance selon votre logique métier. Par exemple, vous voudrez peut-être surveiller les performances de la connectivité réseau entre deux sites de succursales et le siège social. Regroupez tous les sous-réseaux de succursale1 dans le réseau O1. Ensuite, regroupez tous les sous-réseaux de succursale2 dans le réseau O2. Pour finir, regroupez tous les sous-réseaux du siège social dans le réseau H. Créez deux règles de surveillance, une entre O1 et H et l’autre entre O2 et H.
Pour créer des règles de surveillance personnalisées :
- Sélectionnez Ajouter une règle sous l’onglet Surveiller, puis entrez le nom et la description de la règle.
- Sélectionnez la paire de liaisons réseau ou sous-réseau à surveiller dans les listes.
- Sélectionnez le réseau qui contient les sous-réseaux souhaités dans la liste déroulante de réseaux. Sélectionnez ensuite les sous-réseaux dans la liste déroulante de sous-réseaux correspondante. Si vous souhaitez surveiller tous les sous-réseaux dans un lien réseau, sélectionnez Tous les sous-réseaux. Sélectionnez de la même manière les autres sous-réseaux souhaités. Pour exclure la surveillance de liens de sous-réseau spécifiques dans les sélections effectuées, sélectionnez Ajouter une exception.
- Choisissez entre le protocole ICMP et le protocole TCP pour exécuter des transactions synthétiques.
- Si vous ne souhaitez pas créer d’événements d’intégrité pour les éléments que vous avez sélectionnés, désactivez l’option Activer la surveillance de l’intégrité sur les liens couverts par cette règle.
- Choisissez les conditions d’analyse. Si vous voulez définir des seuils personnalisés pour la génération d’événements d’intégrité, entrez des valeurs de seuil. Chaque fois que la valeur d’une condition dépasse son seuil sélectionné pour la paire de réseaux ou de sous-réseaux sélectionnée, un événement d’intégrité est généré.
- Sélectionnez Enregistrer pour enregistrer la configuration.
Vous pouvez intégrer la règle de surveillance que vous avez enregistrée dans Alert Management en sélectionnant Créer une alerte. Une règle d’alerte est créée automatiquement avec la requête de recherche. Les autres paramètres obligatoires sont renseignés automatiquement. En utilisant une règle d’alerte, vous pouvez recevoir des alertes par e-mail en plus des alertes qui existent dans Network Performance Monitor. Les alertes peuvent également déclencher des actions correctives avec des runbooks, ou s’intégrer aux solutions existantes de management des services à l’aide de webhooks. Sélectionnez Gérer l’alerte pour modifier les paramètres d’alerte.
Vous pouvez maintenant créer d’autres règles pour l’Analyseur de performances ou accéder au tableau de bord de la solution pour utiliser la fonctionnalité.
Choisir le protocole
Network Performance Monitor utilise des transactions synthétiques pour calculer les métriques de performances réseau comme la perte de paquets et la latence des liens. Pour mieux comprendre ce concept, prenez un agent Network Performance Monitor connecté à une extrémité d’un lien réseau. Cet agent Network Performance Monitor envoie des paquets de sondage à un deuxième agent Network Performance Monitor connecté à une autre extrémité du réseau. Le second agent répond avec des paquets de réponse. Ce processus se répète plusieurs fois. En mesurant le nombre de réponses et le temps nécessaire pour recevoir chaque réponse, le premier agent Network Performance Monitor évalue la latence des liens et les rejets de paquet.
Le format, la taille et la séquence de ces paquets sont déterminés par le protocole choisi au moment de la création des règles de surveillance. En fonction du protocole des paquets, les appareils réseau intermédiaires (tels que les routeurs et les commutateurs) peuvent traiter ces paquets différemment. Le protocole que vous choisissez a donc une incidence sur la précision des résultats. Il détermine également si des étapes manuelles sont nécessaires après le déploiement de la solution Network Performance Monitor.
Pour l’exécution des transactions synthétiques, Network Performance Monitor vous donne le choix entre le protocole ICMP et le protocole TCP. Si vous choisissez ICMP quand vous créez une règle de transaction synthétique, les agents Network Performance Monitor utilisent des messages ICMP ECHO pour calculer la latence du réseau et la perte de paquets. ICMP ECHO utilise le même message que celui envoyé par l’utilitaire ping traditionnel. Quand vous utilisez le protocole TCP, les agents Network Performance Monitor envoient un paquet TCP SYN sur le réseau. Cette étape est suivie par l’établissement d’une liaison TCP, puis la connexion est supprimée à l’aide de paquets RST.
Avant de choisir un protocole, tenez compte des informations suivantes :
Découverte de plusieurs routages réseau. TCP est plus précis lors de la découverte de plusieurs routages et nécessite moins d’agents dans chaque sous-réseau. Par exemple, un ou deux agents qui utilisent TCP peuvent découvrir tous les chemins redondants entre les sous-réseaux. Plusieurs agents utilisant ICMP sont nécessaires pour obtenir des résultats similaires. Avec ICMP, si vous avez un certain nombre de routages entre deux sous-réseaux, il vous faut plus de 5N agents dans un sous-réseau source ou de destination.
Précision des résultats. Les routeurs et les commutateurs ont tendance à accorder aux paquets ICMP ECHO une priorité inférieure à celle des paquets TCP. Dans certaines situations, quand les appareils réseau sont lourdement chargés, les données obtenues par TCP reflètent plus fidèlement la perte et la latence constatées par les applications. Cela vient du fait que la plupart du trafic des applications passe par TCP. Dans de tels cas, ICMP offre de moins bons résultats que TCP.
Configuration du pare-feu. Le protocole TCP nécessite l’envoi des paquets TCP à un port de destination. Le port par défaut utilisé par les agents Network Performance Monitor est 8084. Vous pouvez changer le port quand vous configurez les agents. Vérifiez que vos pare-feu réseau ou règles de groupe de sécurité réseau (NSG) (dans Azure) autorisent le trafic sur le port. Vous devez également veiller à ce que le pare-feu local sur les ordinateurs où les agents sont installés est configuré pour autoriser le trafic sur ce port. Vous pouvez utiliser des scripts PowerShell pour configurer des règles de pare-feu sur les ordinateurs Windows, mais vous devez configurer manuellement votre pare-feu réseau. Le protocole ICMP, quant à lui, ne fonctionne pas à l’aide d’un port. Dans la plupart des scénarios d’entreprise, le trafic ICMP est autorisé à franchir les pare-feu pour vous permettre d’utiliser des outils de diagnostic réseau comme l’utilitaire ping. Si un test ping effectué entre deux ordinateurs aboutit, vous pouvez utiliser le protocole ICMP sans avoir à configurer les pare-feu manuellement.
Notes
Certains pare-feu peuvent bloquer le protocole ICMP, ce qui peut entraîner la création d’un grand nombre d’événements dans votre système de gestion des événements et des informations de sécurité lors de la retransmission. Vérifiez que le protocole choisi n’est pas bloqué par un pare-feu réseau ou un groupe de sécurité réseau. Si c’est le cas, Network Performance Monitor ne peut pas surveiller le segment réseau. Nous vous recommandons d’utiliser le protocole TCP pour la surveillance. Utilisez le protocole ICMP dans les scénarios où vous ne pouvez pas utiliser TCP, par exemple quand :
- Vous utilisez des nœuds basés sur un client Windows, car les sockets bruts du protocole TCP ne sont pas autorisés dans les clients Windows.
- Votre pare-feu réseau ou règle de sécurité réseau bloque le protocole TCP.
- Vous ne savez pas comment changer de protocole.
Si vous avez choisi ICMP durant le déploiement, vous pouvez basculer vers TCP à tout moment en modifiant la règle de surveillance par défaut.
- Accédez à Performances réseau>Surveiller>Configurer>Surveiller. Puis sélectionnez Règle par défaut.
- Faites défiler la page jusqu’à la section Protocole et sélectionnez le protocole à utiliser.
- Sélectionnez Enregistrer pour appliquer le paramètre.
Même si la règle par défaut utilise un protocole spécifique, vous pouvez créer des règles avec un autre protocole. Vous pouvez même créer une combinaison de règles, certaines utilisant ICMP et d’autres TCP.
Procédure pas à pas
Examinons maintenant la cause racine d’un événement d’intégrité.
Dans le tableau de bord de la solution, un événement d’intégrité montre qu’une liaison réseau n’est pas saine. Pour examiner le problème, sélectionnez la vignette Liens réseau en cours de surveillance.
La page détaillée montre que le lien réseau DMZ2-DMZ1 n’est pas sain. Sélectionnez Afficher les liens de sous-réseau affectés pour ce lien réseau.
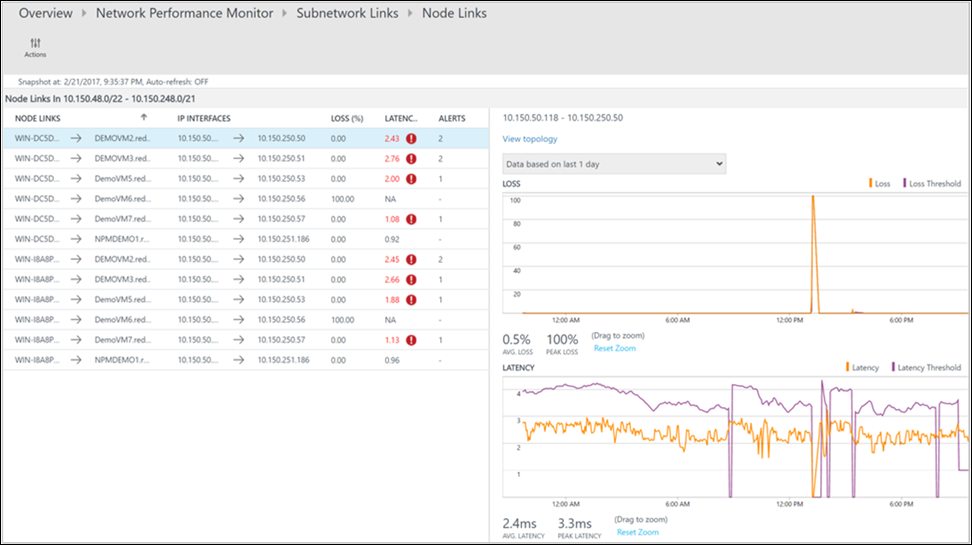
La page détaillée affiche tous les liens de sous-réseau du lien réseau DMZ2-DMZ1. Pour les deux liens de sous-réseau, la latence a dépassé le seuil. Le lien réseau est donc considéré comme non sain. Vous pouvez également voir les tendances de latence des deux liens de sous-réseau. La commande de sélection de plage horaire dans le graphe vous permet de vous concentrer sur la plage horaire requise. Vous pouvez voir l’heure à laquelle la latence a atteint son pic. Effectuez ensuite une recherche dans les journaux d’activité correspondant à cette période pour investiguer le problème. Sélectionnez Afficher les liens de nœud pour consulter des détails supplémentaires.

Comme la page précédente, la page détaillée relative au lien de sous-réseau concerné liste les liens de nœud qui le composent. Vous pouvez effectuer ici des actions similaires à celles que vous avez faites à l’étape précédente. Sélectionnez Afficher la topologie pour afficher la topologie entre les deux nœuds.
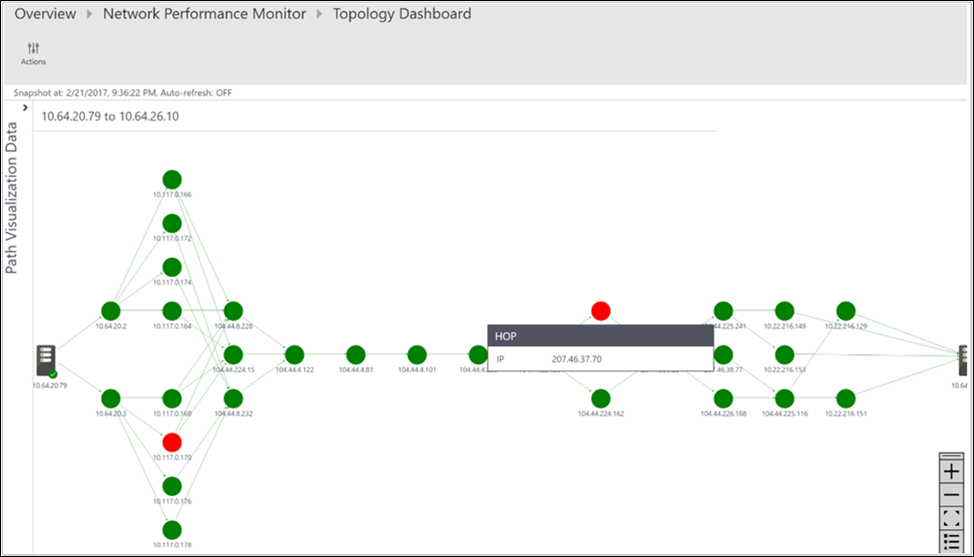
Tous les chemins entre les deux nœuds sélectionnés sont représentés dans la carte topologique. Vous pouvez visualiser, tronçon par tronçon, la topologie des itinéraires entre deux nœuds sur la carte topologique. Vous obtenez ainsi une vision claire du nombre d’itinéraires existant entre les nœuds et des chemins qu’empruntent les paquets de données. Les goulots d’étranglement des performances du réseau sont marqués en rouge. Pour localiser une connexion réseau ou un appareil réseau défectueux, examinez les éléments en rouge sur la carte topologique.
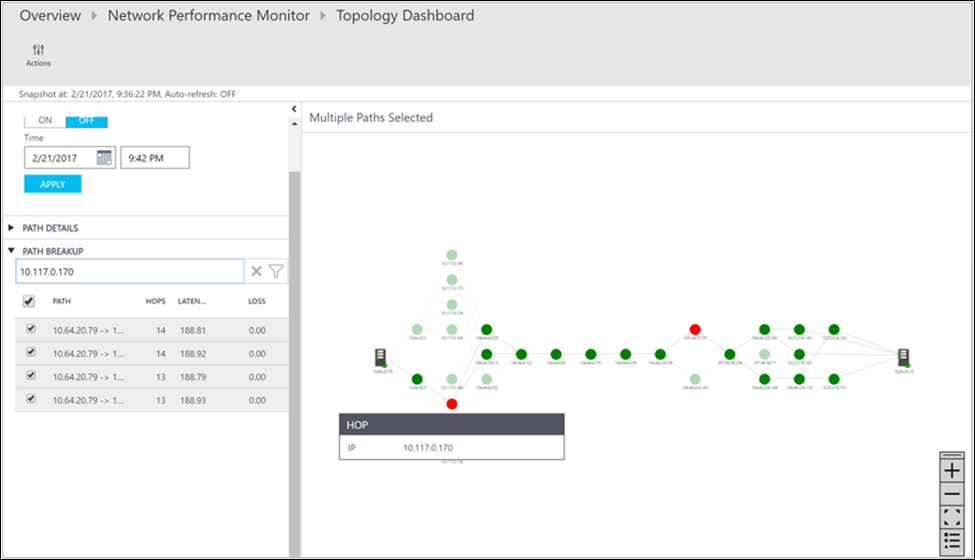
Vous pouvez consulter les pertes, la latence et le nombre de sauts de chaque chemin dans le volet Actions. Utilisez la barre de défilement pour afficher les détails des chemins non sains. Utilisez les filtres pour sélectionner les chemins d’accès avec le saut défectueux afin de tracer uniquement la topologie des chemins d’accès sélectionnés. Pour effectuer un zoom avant ou arrière sur la carte topologique, utilisez la roulette de votre souris.
Dans l’image suivante, la cause racine des zones à problème dans la section spécifique du réseau est représentée par un point rouge sur les chemins et tronçons. Sélectionnez un nœud dans la carte topologique pour révéler les propriétés du nœud, notamment son nom de domaine complet et son adresse IP. La sélection d’un tronçon affiche son adresse IP.
Étapes suivantes
Rechercher dans les journaux d’activité pour afficher des enregistrements de données détaillées sur les performances réseau.