Présentation des travaux de calcul parallèle
Les types les plus courants de travaux informatiques parallèles que vous pouvez exécuter sur un cluster HPC Pack sont les suivants : travaux MPI, travaux de balayage paramétrique, tâches de flux de tâches, travaux SOA (Service Oriented Architecture)et calcul Microsoft Excel décharger travaux. HPC Pack fournit des propriétés de travail et de tâche, des outils et des API qui vous aident à définir et à soumettre différents types de travaux informatiques parallèles.
Dans cette rubrique :
Travail MPI
MS-MPI, une implémentation Microsoft de l’interface de transmission de messages (MPI) développée pour Windows, permet aux applications MPI de s’exécuter en tant que tâches sur un cluster HPC.
Une tâche MPI est intrinsèquement parallèle. Une tâche parallèle peut prendre plusieurs formes, en fonction de l’application et du logiciel qui le prend en charge. Pour une application MPI, une tâche parallèle se compose généralement d’un seul exécutable qui s’exécute simultanément sur plusieurs cœurs, avec communication entre les processus.
Le diagramme suivant illustre une tâche parallèle :
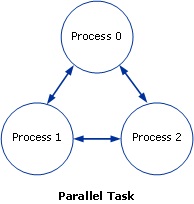 de communication bidirectionnelle
de communication bidirectionnelle
Pour une tâche qui exécute une application MPI, la commande de tâche doit être précédée de mpiexec: par conséquent, les commandes pour les tâches parallèles doivent être au format suivant : mpiexec [mpi_options] <myapp.exe> [arguments], où myapp.exe est le nom de l’application à exécuter. La commande mpiexec prend un certain nombre d’arguments qui vous permettent de contrôler l’emplacement du processus MPI, l’affinité réseau et d’autres paramètres d’exécution. Pour plus d’informations sur ces paramètres, consultez la Informations de référence sur la ligne de commande Microsoft HPC Pack.
Note
Pour les tâches parallèles, Windows HPC Server 2008 inclut un package MPI basé sur la norme MPICH2 du Laboratoire national d’Argone. L’implémentation de MPI de Microsoft, appelée MS-MPI, inclut le lanceur mpiexec, un service MPI pour chaque nœud et un Kit de développement logiciel (SDK) pour le développement d’applications utilisateur. Windows HPC Server 2008 prend également en charge les applications qui fournissent leurs propres mécanismes de traitement parallèle.
Pour plus d’informations sur le Kit de développement logiciel (SDK), consultez Microsoft HPC Pack.
Pour plus d’informations sur la création d’une tâche unique ou d’un travail MPI, consultez Définir une tâche de base ou MPI - Gestionnaire de travaux.
Travail de balayage paramétrique
Un travail de balayage paramétrique se compose de plusieurs instances de la même application, généralement une application série, s’exécutant simultanément et avec une entrée fournie par un fichier d’entrée et une sortie dirigée vers un fichier de sortie. Les entrées et sorties sont généralement un ensemble de fichiers indexés (par exemple, input1, input2, input3..., output1, output2, output3...) configurés pour résider dans un dossier commun unique ou dans des dossiers communs distincts. Il n’y a pas de communication ou d’interdépendance entre les tâches. Les tâches peuvent ou non s’exécuter en parallèle, en fonction des ressources disponibles sur un cluster lors de l’exécution du travail.
Le diagramme suivant illustre un travail de balayage paramétrique :
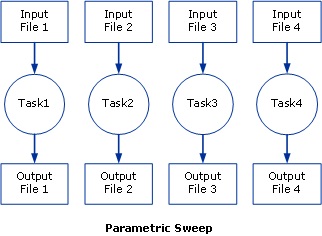
Pour plus d’informations sur la création d’un travail de balayage paramétrique, consultez Définir une tâche de balayage paramétrique - Gestionnaire de travaux.
Tâche de flux de tâches
Dans un travail de flux de tâches, un ensemble de tâches contrairement aux tâches sont exécutées dans un ordre prescrit, généralement parce qu’une tâche dépend du résultat d’une autre tâche. Un travail peut contenir de nombreuses tâches, dont certaines sont paramétriques, certaines séries et certaines tâches parallèles. Par exemple, vous pouvez créer un travail de flux de tâches composé de tâches MPI et de tâches paramétriques. Vous pouvez établir l’ordre dans lequel les tâches sont exécutées en définissant des dépendances entre les tâches.
Le diagramme suivant illustre un travail de flux de tâches :
travail de flux de tâches 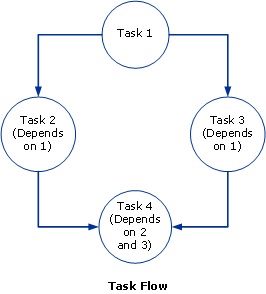
La tâche 1 s’exécute en premier. Notez que seules les tâches 2 et 3 peuvent s’exécuter en parallèle, car aucun des deux n’est dépendant de l’autre. La tâche 4 s’exécute une fois les tâches 2 et 3 terminées.
Pour plus d’informations sur la création d’un travail de flux de tâches, consultez Définir des dépendances de tâche - Gestionnaire de travaux.
Travail SOA
L’architecture orientée service (SOA) est une approche de la création de systèmes distribués et faiblement couplés. Dans un système SOA, des fonctions de calcul distinctes sont empaquetées en tant que modules logiciels appelés services. Les services peuvent être distribués sur un réseau et accessibles par d’autres applications. Par exemple, si les applications effectuent des calculs parallèles répétés, les calculs principaux peuvent être empaquetés en tant que services et déployés sur un cluster. Cela permet aux développeurs de résoudre des problèmes embarrassants parallèles sans réécrire le code de bas niveau et d’effectuer rapidement un scale-out des applications. Les applications peuvent s’exécuter plus rapidement en distribuant des calculs de base sur plusieurs hôtes de service (nœuds de calcul). Les utilisateurs finaux exécutent l’application sur leurs ordinateurs et nœuds de cluster effectuent des calculs.
Une application cliente fournit une interface permettant à l’utilisateur final d’accéder aux fonctionnalités d’un ou de plusieurs services. Les développeurs peuvent créer des applications clientes SOA de cluster pour fournir l’accès aux services déployés sur un cluster HPC Windows. Sur le serveur principal, l’application cliente envoie un travail qui contient une tâche Service au cluster, lance une session avec le nœud broker et envoie des demandes de service et reçoit des réponses (résultats de calcul). Le planificateur de travaux sur le nœud principal alloue des ressources au travail de service en fonction des stratégies de planification des travaux. Une instance du service s’exécute sur chaque ressource allouée et charge le service SOA. Le planificateur de travaux tente d’ajuster l’allocation de ressources en fonction du nombre de demandes de service.
Note
Si le client a créé une session durable, le répartiteur stocke tous les messages à l’aide de MSMQ. Les réponses stockées par le répartiteur peuvent être récupérées par le client à tout moment, même après une déconnexion intentionnelle ou involontaire.
Le diagramme suivant illustre l’exécution d’un travail SOA sur le cluster :
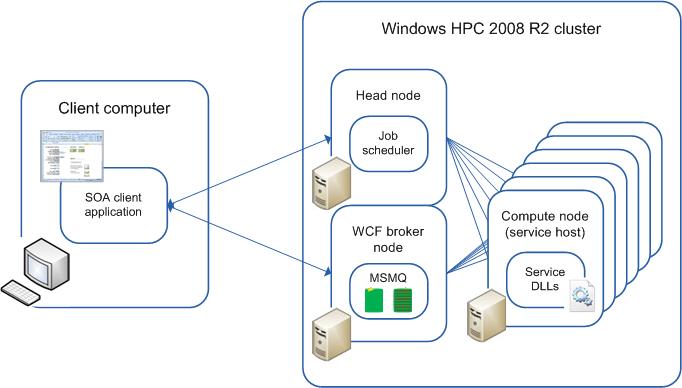
Pour plus d’informations sur la création de clients SOA pour un cluster HPC, consultez applications SOA et Microsoft HPC Pack.
Note
HPC Services pour Excel utilise l’infrastructure SOA pour faciliter le déchargement des calculs Microsoft Excel sur un cluster.
Déchargement du calcul Microsoft Excel
HPC Services pour Excel, inclus dans certaines versions de HPC Pack, prend en charge un certain nombre de modèles pour décharger les calculs Excel sur un cluster HPC Pack. Les classeurs adaptés à l’accélération du cluster incluent des calculs indépendants qui peuvent s’exécuter en parallèle. De nombreux classeurs complexes et longs s’exécutent de manière itérative, c’est-à-dire qu’ils effectuent un calcul unique plusieurs fois sur différents ensembles de données d’entrée. Ces classeurs peuvent contenir des fonctions Microsoft Visual Basic pour Applications (VBA) complexes ou des compléments XLL gourmands en calcul. HPC Services pour Excel prend en charge le déchargement de classeurs sur le cluster ou le déchargement des fonctions définies par l’utilisateur sur le cluster.
Microsoft Excel 2010 étend le modèle UDF au cluster en permettant aux fonctions définies par l’utilisateur d’Excel 2010 de s’exécuter dans un cluster HPC Windows. Lorsqu’un cluster pris en charge est disponible, les utilisateurs peuvent demander à Excel 2010 d’utiliser ce cluster en sélectionnant un connecteur de cluster et en spécifiant le nom du cluster dans les options
Pour plus d’informations, consultez HPC Services pour Excel.
Références supplémentaires
Pour plus d’informations sur les propriétés de tâche et de travail que vous pouvez utiliser pour définir vos travaux informatiques parallèles, consultez :
Présentation des tâches et des tâches - du Gestionnaire de travaux
Pour plus d’informations sur la création, l’envoi et la surveillance de travaux à l’aide de HPC Job Manager, consultez :
création et envoi de travaux - du Gestionnaire de travaux
Pour plus d’informations sur la création, l’envoi et la surveillance de travaux à l’aide d’une fenêtre d’invite de commandes ou HPC PowerShell, ainsi que pour les ressources de développeur, notamment des informations sur l’utilisation du Kit de développement logiciel (SDK), le modèle de programmation SOA et le déchargement des calculs Excel, consultez d’autres articles de cet ensemble de documentation.