Planification et réglage de la capacité de base de données pour Microsoft HPC Pack
Les fonctionnalités de gestion des clusters Windows HPC dans Microsoft HPC Pack s’appuient sur plusieurs bases de données Microsoft SQL Server pour prendre en charge la gestion, la planification des travaux, les diagnostics, les rapports et la fonctionnalité de supervision. Lorsque vous installez HPC Pack sur un serveur pour créer un nœud principal, le programme d’installation par défaut installe l’édition Express de Microsoft SQL Server (si aucune autre édition de SQL Server n’est détectée) et crée les bases de données nécessaires sur le nœud principal. L’édition Express n’a pas de frais de licence supplémentaires et est incluse pour fournir une expérience prête à l’emploi pour les clusters de preuve de concept ou de développement, et pour les petits clusters de production. Selon la taille, le débit et les exigences de votre cluster, vous pouvez installer une autre édition de SQL Server sur le nœud principal ou installer les bases de données sur des serveurs distants. Les informations contenues dans ce document sont destinées à vous aider à déterminer la configuration de la base de données et d’autres options de réglage appropriées pour votre cluster.
Dans cette rubrique :
versions applicables de Microsoft HPC Pack et de Microsoft SQL Server
Options de base pour la configuration de la base de données dans microsoft HPC Pack
Choisir l’édition appropriée de SQL Server pour votre de cluster
Versions applicables de Microsoft HPC Pack et De Microsoft SQL Server
Les instructions de cette rubrique s’appliquent aux versions de HPC Pack et SQL Server répertoriées dans le tableau suivant.
| Version de Microsoft HPC Pack | Bases de données de cluster | Versions prises en charge de Microsoft SQL Server | Notes |
| HPC Pack 2016 | - HPCManagement - HPCScheduler - HPCReporting - HPCDiagnostics - HPCMonitoring |
- SQL Server 2014 et versions ultérieures - Azure SQL Database |
- La version de SQL Server Express limite chaque base de données à 10 Go. |
| HPC Pack 2012 R2 et HPC Pack 2012 | - HPCManagement - HPCScheduler - HPCReporting - HPCDiagnostics - HPCMonitoring |
- SQL Server 2008 R2 et versions ultérieures - Azure SQL Database |
- La version de SQL Server Express limite chaque base de données à 10 Go. - Azure SQL Database est pris en charge uniquement pour HPC Pack 2012 R2 Update 3 build 4.5.5194 ou version ultérieure |
Options de base pour la configuration de la base de données dans Microsoft HPC Pack
Cette section fournit des informations générales sur trois options de base pour la configuration de la base de données avec HPC Pack. Pour obtenir des conseils sur le choix d’une option appropriée pour votre déploiement, consultez Choisir l’édition appropriée de SQL Server pour votre cluster dans cette rubrique.
SQL Server Express sur le nœud principal
Il s’agit de l’expérience prête à l’emploi. Cela est généralement utilisé pour les clusters de preuve de concept ou de développement, ou pour les petits clusters de production. Comme indiqué dans le tableau de la section précédente, si elle est prise en charge par votre version de HPC Pack, SQL Server 2016 Express, SQL Server 2014 Express ou SQL Server 2012 Express autorise les tailles de base de données jusqu’à 10 Go. Les étapes de base de cette configuration sont les suivantes :
Installez HPC Pack sur un serveur pour créer un nœud principal.
Si vous le souhaitez, spécifiez les emplacements des fichiers journaux et de base de données dans l’Assistant Installation (ou acceptez les valeurs par défaut).
SQL Server Express est installé automatiquement et les bases de données HPC sont créées automatiquement.
Déployer des nœuds.
SQL Server Standard sur le nœud principal
Il s’agit d’une configuration de base pour les clusters de taille moyenne. L’édition SQL Server Standard (ou une autre édition complète, non Compact) permet aux bases de données plus volumineuses et aux capacités de gestion supplémentaires de prendre en charge davantage de nœuds et un débit de travail plus élevé. Les étapes de base de cette configuration sont les suivantes :
Installez une version de SQL Server Standard edition prise en charge par votre version de HPC Pack sur le serveur qui servira de nœud principal.
Installez HPC Pack sur le serveur pour créer un nœud principal.
Si vous le souhaitez, spécifiez les emplacements des fichiers journaux et de base de données dans l’Assistant Installation (ou acceptez les valeurs par défaut).
Les bases de données HPC sont créées automatiquement.
Si vous le souhaitez, ajustez les bases de données selon les besoins à l’aide de SQL Server Management Studio.
Déployer des nœuds.
bases de données distantes (SQL Server Standard ou SQL Server Express)
L’installation d’une ou plusieurs bases de données HPC sur un serveur distant est une configuration recommandée pour les clusters plus volumineux ou pour les clusters configurés pour la haute disponibilité du nœud principal. Pour plus d’informations, consultez Déploiement d’un cluster HPC Pack avec des bases de données distantes pas à pas. Pour les nœuds principaux à haute disponibilité, vous utilisez généralement l’édition Standard de SQL Server pour prendre en charge la haute disponibilité des bases de données (qui est différente de la haute disponibilité des services de gestion HPC). Pour plus d’informations, consultez le guide de prise en main pour HPC Pack 2016. Les étapes de base de cette configuration sont les suivantes :
Installez une version de SQL Server Standard edition prise en charge par votre version de HPC Pack sur un serveur distant.
Créez manuellement les bases de données HPC distantes et ajustez-les selon les besoins à l’aide de SQL Server Management Studio.
Effectuez d’autres étapes de configuration sur le serveur distant exécutant SQL Server en fonction de votre version de HPC Pack.
Installez HPC Pack sur un serveur pour créer un nœud principal.
Dans l’Assistant Installation, spécifiez les informations de connexion pour les bases de données distantes.
Déployer des nœuds.
Choix de l’édition appropriée de SQL Server pour votre cluster
Les instructions générales suivantes peuvent vous aider à déterminer l’édition de SQL Server à utiliser pour votre cluster. Les numéros de débit de nœud et de travail sont destinés uniquement à des instructions générales, car les performances varient en fonction du matériel et de la topologie que vous sélectionnez pour le cluster, ainsi que de la charge de travail prise en charge par votre cluster.
Envisagez d’utiliser l’édition Standard (ou une autre édition complète, pas Compact) de SQL Server si l’une des conditions suivantes s’applique :
Le cluster a de nombreux nœuds. Les informations telles que les propriétés de nœud, les configurations, les métriques et l’historique des performances sont stockées dans les bases de données. Les clusters plus volumineux nécessitent davantage de place dans les bases de données. En règle générale, l’édition Express est suffisante pour jusqu’à 64 nœuds avec SQL Server Express 2012 ou jusqu’à 128 nœuds avec une version ultérieure de SQL Server Express.
Le cluster prend en charge un débit de travail très élevé ( par exemple, plus de 10 000 tâches ou tâches subordonnées par jour). Chaque tâche, tâche et sous-tâche contient des entrées dans la base de données pour stocker les propriétés et les informations d’allocation et l’historique. La période de rétention par défaut pour ces données est de 5 jours. Vous pouvez ajuster la période de rétention pour réduire vos besoins en capacité. Consultez paramètres de rétention des données HPC dans cette rubrique.
Le cluster est configuré pour la haute disponibilité du nœud principal et vous souhaitez également configurer la haute disponibilité pour SQL Server.
Vous devez stocker les données de travail et de tâche dans la base de données HPCScheduler pendant une période prolongée et dépasser la limite de base de données imposée par votre version de SQL Server Express.
Vous utilisez fortement la base de données HPCReporting et éventuellement utilisez les fonctionnalités d’extensibilité des données pour les rapports personnalisés. Pour plus d’informations sur la désactivation de l’extensibilité des rapports et la réduction des exigences de taille pour la base de données de création de rapports, consultez paramètres de rétention des données HPC dans cette rubrique.
Vous avez besoin de la fiabilité, des performances et de la flexibilité supplémentaires fournies par les outils SQL Server Management Studio (y compris la prise en charge des plans de maintenance). Par exemple, l’édition SQL Server Standard fournit les fonctionnalités suivantes (entre autres) qui peuvent être utiles aux administrateurs de cluster HPC :
Taille illimitée de la base de données
Prise en charge des configurations à haute disponibilité
Utilisation illimitée de la RAM pour la mise en cache de base de données
Remarque
SQL Server Management Studio n’est pas automatiquement inclus dans l’édition Express de SQL Server. Vous pouvez le télécharger séparément si vous souhaitez modifier les paramètres de vos bases de données HPC.
Vous planifiez un déploiement important de nœuds Windows Azure , par exemple, plusieurs centaines d’instances de rôle Windows Azure ou plus. Pour plus d’informations sur les déploiements de nœuds Windows Azure volumineux, consultez Meilleures pratiques pour les déploiements volumineux de nœuds Windows Azure avec Microsoft HPC Pack.
Meilleures pratiques de configuration et de réglage
Cette section contient des instructions et des bonnes pratiques pour l’optimisation des performances des bases de données HPC. Les exemples de paramètres de configuration d’un cluster à grande échelle sont décrits dans la liste ci-dessous. Ces paramètres diffèrent considérablement de ceux configurés par défaut par HPC Pack. Vous trouverez plus d’informations sur ces options dans les sections suivantes.
Sur un serveur avec trois plateaux (disques physiques) configurez :
Système d’exploitation sur un plateau dédié.
Bases de données de cluster sur un plateau dédié.
Fichiers journaux de base de données de cluster sur un plateau dédié.
Dans SQL Server Management Studio, configurez :
Base de données HPCManagement : taille initiale de 20 Go, taux de croissance de 100%
Journaux de base de données HPCManagement : taille initiale de 2 Go
Base de données HPCScheduler : taille initiale de 30 Go, taux de croissance de 0%
Remarque
Dans un cluster volumineux, pour éviter l’arrêt inattendu du planificateur de travaux HPC en raison de la base de données HPCScheduler qui approche de ses limites de taille, nous vous recommandons de ne pas configurer les paramètres de croissance automatique pour cette base de données.
Journaux de base de données HPCScheduler : taille initiale de 2 Go
Base de données HPCReporting : Taille initiale de 30 Go, taux de croissance de 100%
Journaux de base de données HPCReporting : Taille initiale de 2 Go
Base de données et journaux HPCDiagnostics : Utilisez les valeurs par défaut
Base de données HPCMonitoring : 1 Go, taux de croissance de 10%
Journaux de base de données HPCMonitoring : Utiliser les valeurs par défaut
Remarque
La base de données HPCMonitoring est configurée à partir de HPC Pack 2012.
Pour les bases de données hébergées sur le nœud principal, dans SQL Server Management Studio, configurez la mémoire de la base de données pour qu’elle soit environ une moitié de la mémoire physique sur le nœud. Par exemple, pour un nœud principal avec 16 Go de mémoire physique, configurez les tailles de base de données de 8 à 10 Go.
Pour les bases de données hébergées sur le nœud principal, dans SQL Server Management Studio, définissez l’indicateur de parallélisation sur 1 (0 est la valeur par défaut).
Configuration requise pour le modèle de récupération SQL Server et l’espace disque
Par défaut, dans l’édition SQL Server Standard, le modèle de récupération SQL Server pour chaque base de données est défini sur complet. Ce modèle peut entraîner la croissance des fichiers journaux très volumineux en raison de la maintenance manuelle requise. Pour récupérer de l’espace journal et conserver la taille de l’espace disque requis, vous pouvez modifier le modèle de récupération pour chaque base de données en simple. Le modèle de récupération que vous sélectionnez dépend de vos besoins de récupération. Si vous utilisez le modèle complet, veillez à planifier suffisamment d’espace pour les fichiers journaux et à connaître les exigences de maintenance régulières. Pour plus d’informations, consultez Vue d’ensemble du modèle de récupération.
Remarque
Si vous choisissez le modèle complet, car les bases de données HPC doivent rester cohérentes logiquement, vous devrez peut-être implémenter des procédures spéciales pour garantir la récupération de ces bases de données. Pour plus d’informations, consultez récupération des bases de données associées contenant des transactions marquées.
Dimensionnement initial et croissance automatique pour les bases de données et les fichiers journaux
La croissance automatique signifie que lorsqu’une base de données ou un fichier journal manque d’espace, elle augmente automatiquement sa taille par un pourcentage prédéfini (tel que défini par le paramètre de croissance automatique). Pendant le processus de croissance automatique, la base de données est verrouillée. Cela a un impact sur les opérations et les performances du cluster et peut entraîner des interblocages et des délais d’expiration des opérations. Le dimensionnement préalable de vos bases de données vous permet d’éviter ces problèmes de performances et en configurant un pourcentage de croissance automatique plus important, vous réduisez la fréquence des opérations de croissance automatique. Toutefois, un fichier initial volumineux dimensionné couplé à un paramètre de croissance automatique qui approche de 100% peut nécessiter un temps important pour développer la base de données. Il est important de comprendre les performances de votre sous-système de disque afin de déterminer les valeurs qui ne bloquent pas l’accès à la base de données pendant une période prolongée.
Chaque base de données a un fichier journal associé. Vous pouvez également régler la taille initiale et les paramètres de croissance automatique des fichiers journaux.
Les configurations par défaut pour les bases de données et les fichiers journaux (quelle que soit l’édition de SQL Server) sont indiquées dans le tableau suivant :
| Base de données ET journal HPC | Taille initiale (Mo) | Croissance automatique |
|---|---|---|
| HPCManagement | Base de données : 1024 Journal : 128 |
Base de données : 50% Journal : 50% |
| HPCScheduler | Base de données : 256 Journal : 64 |
Base de données : 10% Journal : 10% |
| HPCReporting | Base de données : 128 Journal : 64 |
Base de données : 10% Journal : 10% |
| HPCDiagnostics | Base de données : 256 Journal : 64 |
Base de données : 10% Journal : 10% |
| HPCMonitoring Remarque : la base de données HPCMonitoring est configurée à partir de HPC Pack 2012. | Base de données : 256 Journal : 138 |
Base de données : 10% Journal : 10% |
Par exemple, le tableau suivant répertorie les paramètres de taille initiale et de croissance automatique qui peuvent être appropriés pour un cluster avec plusieurs centaines de nœuds ou plus.
Remarque
La taille initiale de cette table est exprimée en gigaoctets (Go), et non en mégaoctets (Mo) comme dans le tableau précédent.
| Base de données ET journal HPC | Taille initiale (Go) | Croissance automatique |
|---|---|---|
| HPCManagement | Base de données : 20 Journal : 2 |
Base de données : 100% Journal : 10% |
| HPCScheduler | Base de données : 30 Journal : 2 |
Base de données : 0% Journal : 10% |
| HPCReporting | Base de données : 30 Journal : 2 |
Base de données : 100% Journal : 10% |
| HPCDiagnostics | Base de données : par défaut Journal : valeur par défaut |
Base de données : par défaut Journal : valeur par défaut |
| HPCMonitoring | Base de données : 1 Journal : valeur par défaut |
Base de données : par défaut Journal : valeur par défaut |
L’écran suivant illustre les bases de données HPC dans SQL Server Management Studio et la boîte de dialogue propriétés de base de données que vous pouvez utiliser pour configurer les paramètres de taille initiale et de croissance automatique des bases de données.
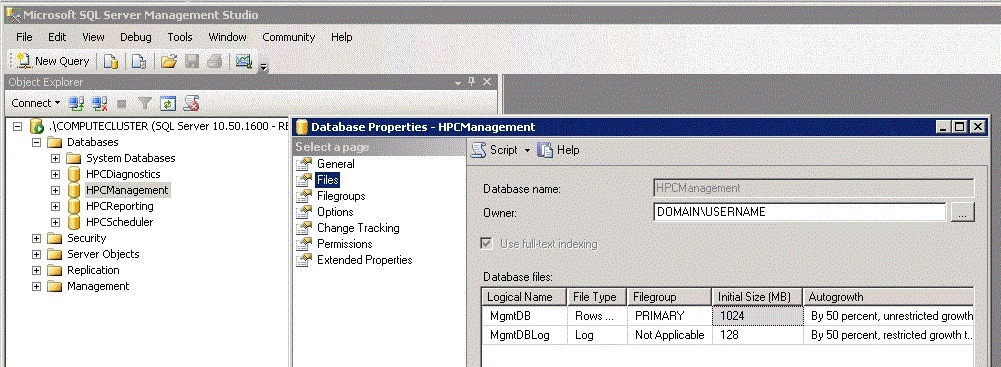
Emplacement du fichier journal et de la base de données
Vous pouvez améliorer les performances en créant les bases de données sur un plat distinct (disque physique) que les fichiers journaux. Cela s’applique aux bases de données qui se trouvent sur le nœud principal et aux bases de données distantes. Pour les bases de données sur le nœud principal, vous pouvez spécifier les emplacements des fichiers journaux et de base de données lors de l’installation (dans l’Assistant Installation). Dans l’idéal, placez la partition système, les données et les journaux sur des plateaux distincts.
Si la création de rapports est fortement utilisée, envisagez de déplacer la base de données HPCReporting vers un plat distinct.
Pour plus d’informations sur le déplacement d’une base de données, consultez Déplacer une base de données à l’aide du détachement et de l’attachement (Transact-SQL).
Paramètres d’instance SQL Server
Pour réduire la pagination de la mémoire, assurez-vous que votre instance SQL Server dispose d’une allocation suffisante de mémoire. Vous pouvez définir la mémoire de votre instance SQL Server via SQL Server Management Studio, dans les propriétés du serveur de l’instance. Par exemple, si vos bases de données se trouvent sur un nœud principal qui a 16 Go de mémoire, vous pouvez allouer 8 à 10 Go pour SQL Server.
Pour réduire la contention principale sur le nœud principal entre les processus SQL Server et les processus HPC, définissez l’indicateur de parallélisation pour l’instance SQL Server sur 1. Par défaut, l’indicateur est défini sur 0, ce qui signifie qu’il n’existe aucune limite au nombre de cœurs que SQL utilisera. En le définissant sur 1, vous limitez les processus SQL Server à 1 cœur.
Paramètres de rétention des données HPC
base de données HPCManagement
À compter de HPC Pack 2012 R2 Update 1, l’administrateur du cluster peut spécifier le nombre de jours avant que le service commence à archiver les données du journal des opérations dans la base de données HPCManagement et le nombre de jours pendant lesquels les données du journal des opérations archivées sont conservées. Par exemple, pour définir l’archivage du journal des opérations tous les 7 jours et pour être supprimé après la rétention pendant 180 jours, exécutez HPC PowerShell en tant qu’administrateur et tapez l’applet de commande suivante :
Set-HpcClusterProperty –OperationArchive 7
Set-HpcClusterProperty –OperationRetention 180
base de données HPCScheduler
Les propriétés, l’allocation et l’historique des travaux sont stockées dans la base de données HPCScheduler. Par défaut, les données sur les travaux terminés sont conservées pendant cinq jours. La période de rétention des enregistrements de travail (TtlCompletedJobs) détermine la durée de stockage des données pour les enregistrements suivants :
Données sur les travaux terminés (terminé, échecou annulé) dans la base de données HPCScheduler.
Données courantes SOA stockées dans le partage Runtime$.
Résultats et données des tests de diagnostic dans la base de données HPCDiagnostics.
Messages pour les sessions durables terminées stockées par le nœud broker à l’aide de MSMQ.
Les travaux qui se trouvent dans la Configuration de l’état de ne sont pas supprimés de la base de données. Les travaux doivent être annulés par le propriétaire du travail ou un administrateur de cluster (ou terminés d’une autre manière), puis ils seront supprimés en fonction de la stratégie d’historique des travaux.
Vous pouvez configurer cette propriété à l’aide de l’applet de commande Set-HpcClusterProperty. Par exemple, pour définir la période de rétention des enregistrements de travail sur trois jours, exécutez HPC PowerShell en tant qu’administrateur et tapez l’applet de commande suivante :
Set-HpcClusterProperty –TtlCompletedJobs 3
Cette propriété peut également être configurée dans les paramètres historique des travaux de la boîte de dialogue configuration du planificateur de travaux HPC.
base de données HPCReporting
Les données historiques sur le cluster, telles que l’utilisation du cluster, la disponibilité des nœuds et les statistiques de travaux, sont agrégées et stockées dans la base de données HPCReporting. La base de données stocke également des données brutes sur les travaux disponibles pour prendre en charge les rapports personnalisés lorsque l’extensibilité des données est activée (elle est activée par défaut). Par exemple, vous pouvez créer des rapports de rétrofacturation personnalisés qui correspondent aux méthodes de facturation utilisées par votre organisation. Pour plus d’informations sur l’utilisation des données brutes pour la création de rapports personnalisées, consultez le guide 'extensibilité de rapport pas à pas.
Le tableau suivant décrit les propriétés du cluster qui contrôlent l’extensibilité des données et les périodes de rétention pour les données brutes. Ces paramètres n’affectent pas les données agrégées utilisées pour les rapports intégrés. Vous pouvez afficher les valeurs des propriétés avec l’applet de commande Get-HPCClusterProperty
Set-HpcClusterProperty –DataExtensibilityEnabled $false
| Propriété | Description |
|---|---|
| DataExtensibilityEnabled | Spécifie si le cluster stocke des informations pour la création de rapports personnalisées sur les travaux, les nœuds et l’allocation de travaux aux nœuds. True indique que le cluster stocke des informations pour la création de rapports personnalisées sur les travaux, les nœuds et l’allocation de travaux aux nœuds. False indique que le cluster ne stocke pas ces informations. La valeur par défaut est True. |
| DataExtensibilityTtl | Spécifie le nombre de jours pendant lesquels la base de données HPCReporting doit stocker toutes les informations sur les travaux et les nœuds, à l’exception de l’allocation des travaux aux nœuds. Ce paramètre a une valeur par défaut de 365. |
| AllocationHistoryTtl | Spécifie le nombre de jours pendant lesquels la base de données HPCReporting doit stocker des informations sur l’allocation de travaux aux nœuds. Ce paramètre a la valeur par défaut 5. |
| ReportingDBSize | Contient la taille actuelle de la base de données HPCReporting. Cette valeur est une chaîne qui inclut les unités de mesure pour la taille. Ce paramètre est en lecture seule. Pour afficher cette propriété, l’ordinateur exécutant HPC PowerShell doit pouvoir accéder à la base de données HPCReporting. Pour plus d’informations sur l’activation de l’accès à la base de données distante, consultez Déploiement d’un cluster avec des bases de données distantes pas à pas. |
Si vous souhaitez estimer la taille nécessaire pour la base de données HPCReporting dans votre cluster, consultez 'estimation de la taille de la base de données de création de rapports.
base de données HPCDiagnostics
Les informations et les résultats des exécutions de test de diagnostic sont stockés dans la base de données HPCDiagnostics. La période de rétention des enregistrements de travail (TtlCompletedJobs) détermine la durée de stockage des données sur les exécutions de test terminées.
base de données HPCMonitoring
Les données du compteur de performances collectées et agrégées à partir de nœuds de cluster par le service HPC Monitoring Server et le service client de surveillance HPC sont stockées dans la base de données HPCMonitoring.
Les données du compteur de performances sont agrégées par minute, par heure et par jour. La période de rétention des données pour les données du compteur de performances du nœud est définie par les propriétés du cluster dans le tableau suivant. Vous pouvez configurer ces propriétés à l’aide de l’applet de commande Set-HpcClusterProperty.
| Propriété | Description |
|---|---|
| MinuteCounterRetention | Spécifie la période de rétention en jours pour les données du compteur de performances de minute. La valeur par défaut est de 3 jours. |
| HourCounterRetention | Spécifie la période de rétention en jours pour les données du compteur de performances horaire. La valeur par défaut est de 30 jours. |
| DayCounterRetention | Spécifie la période de rétention en jours pour les données du compteur de performances de jour. La valeur par défaut est 180 jours. |
Vous pouvez estimer la taille nécessaire pour la base de données HpcMonitoring en fonction du nombre de nœuds, du nombre de compteurs de performances et de la période de rétention. Par exemple, à l’aide d’un MinuteCounterRetention par défaut période de 3 jours (4 320 minutes) et de 27 compteurs de performances avec chaque entrée de valeur de performance nécessitant environ 40 octets, chaque nœud nécessite :
4 320 x 27 x 40 = 4 665 600 octets, ou environ 5 Mo.
Pour un cluster avec 1 000 nœuds, environ 5 Go de stockage seraient nécessaires.
Instructions de maintenance
Un plan de maintenance SQL Server classique couvre les éléments suivants :
Sauvegarde de base de données
Vérifications de cohérence
Défragmentation d’index
Vous pouvez surveiller la fragmentation des index à l’aide de SQL Server Management Studio et des index de défragmentation si nécessaire via un plan de maintenance.
Nous vous recommandons généralement de reconstruire vos index après 250 000 travaux ou un mois (selon ce qui est plus court), sinon plus souvent. La fréquence à laquelle vous effectuez des vérifications de cohérence et des sauvegardes dépend des besoins de votre entreprise. Nous vous recommandons d’exécuter la maintenance uniquement lorsqu’il n’y a pas d’activité utilisateur, de préférence pendant un temps d’arrêt planifié (en particulier pour les clusters plus volumineux), car il peut avoir un impact grave sur le débit des travaux et l’expérience utilisateur.
Pour plus d’informations sur les meilleures pratiques en matière de maintenance de base de données, consultez Conseils principaux pour la maintenance efficace de la base de données.
Remarque
Pour plus d’informations sur la sauvegarde et la restauration des bases de données HPC, consultez sauvegarde et restauration dans Windows HPC Server.