Exemples de pliage des requêtes
Cet article fournit des exemples de scénarios pour chacun des trois résultats possibles du Query Folding. Il inclut également des suggestions sur la façon de tirer le meilleur parti du mécanisme de Query Folding et de l’effet qu’il peut avoir dans vos requêtes.
Scénario
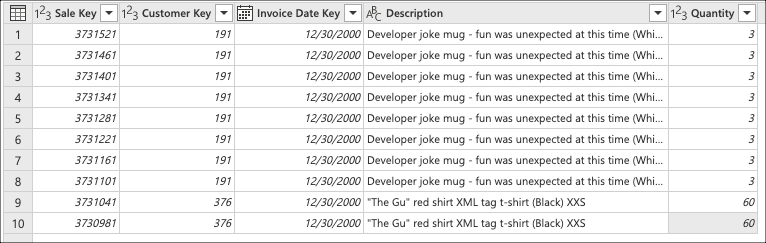
Imaginez un scénario dans lequel, à l’aide de la base de données Wide World Importers pour Azure Synapse base de données SQL Analytics, vous êtes chargé de créer une requête dans Power Query qui se connecte à la fact_Sale table et récupère les 10 dernières ventes avec uniquement les champs suivants :
- Clé de vente
- Customer Key
- Date de la facture
- Description
- Quantité
Remarque
À des fins de démonstration, cet article utilise la base de données décrite dans le didacticiel sur le chargement de la base de données Wide World Importers dans Azure Synapse Analytics. La principale différence dans cet article est que la table fact_Sale contient uniquement les données de l’année 2000, avec un total de 3 644 356 lignes.
Bien que les résultats ne correspondent pas exactement aux résultats que vous obtenez en suivant le tutoriel de la documentation Azure Synapse Analytics, l’objectif de cet article est de présenter les concepts fondamentaux et l’impact que le Query Folding peut avoir dans vos requêtes.
Cet article présente trois façons d’obtenir la même sortie avec différents niveaux de Query Folding :
- Sans Query Folding
- Query Folding partiel
- Query Folding complet
Exemple sans Query Folding
Important
Les requêtes qui s’appuient uniquement sur des sources de données non structurées ou qui n’ont pas de moteur de calcul, tels que des fichiers CSV ou Excel, n’ont pas de fonctionnalités de Query Folding. Cela signifie que Power Query évalue toutes les transformations de données requises à l’aide du moteur Power Query.
Après vous être connecté à votre base de données et en accédant à la table fact_Sale, vous sélectionnez la transformation Conserver les lignes inférieures dans le groupe Réduire les lignes de l’onglet Accueil .
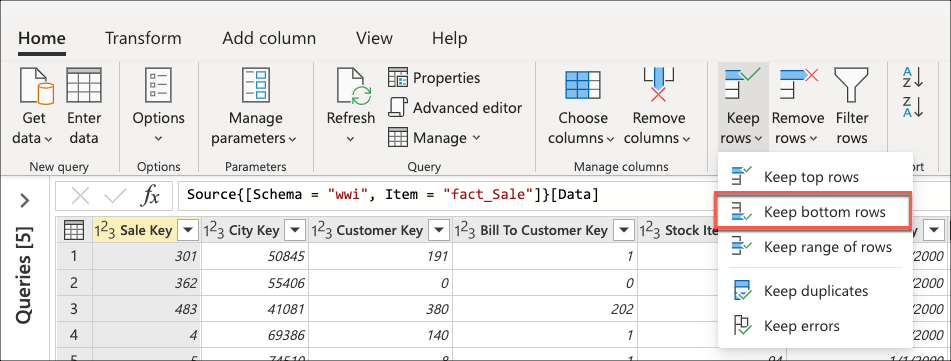
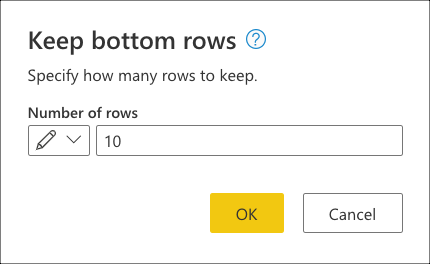
Après avoir sélectionné cette transformation, une nouvelle boîte de dialogue s’affiche. Dans cette nouvelle boîte de dialogue, vous pouvez entrer le nombre de lignes que vous souhaitez conserver. Dans ce cas, entrez la valeur 10, puis sélectionnez OK.
Conseil
Dans ce cas, l’exécution de cette opération génère le résultat des dix dernières ventes. Dans la plupart des scénarios, nous vous recommandons de fournir une logique plus explicite qui définit les lignes considérées en dernier en appliquant une opération de tri sur la table.
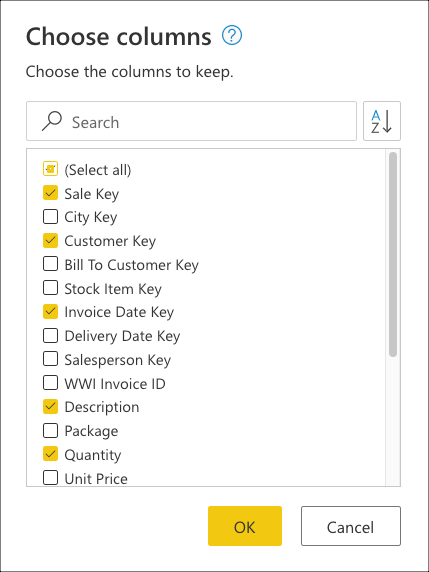
Ensuite, sélectionnez la transformation Choisir les colonnes trouvées dans le groupe Gérer les colonnes de l’onglet Accueil. Vous pouvez ensuite sélectionner les colonnes que vous souhaitez conserver de votre table et supprimer le reste.
Enfin, dans la boîte de dialogue Choisir des colonnes, sélectionnez les colonnes Sale Key, Customer Key, Invoice Date Key, Description, et Quantity puis sélectionnez OK.
L’exemple de code suivant est le script M complet de la requête que vous avez créée :
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Kept bottom rows" = Table.LastN(Navigation, 10),
#"Choose columns" = Table.SelectColumns(#"Kept bottom rows", {"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"})
in
#"Choose columns""
Aucun Query Folding : Comprendre l’évaluation des requêtes
Sous Étapes appliquées dans l’éditeur Power Query, vous remarquerez que les indicateurs de Query Folding pour les lignes inférieures conservées et Choisir des colonnes sont marqués comme des étapes qui seront évaluées en dehors de la source de données ou, en d’autres termes, par le moteur de Power Query.
Vous pouvez cliquer avec le bouton droit sur la dernière étape de votre requête, celle nommée Choisir des colonnes, puis sélectionner l’option où vous lisez Afficher le plan de requête. L’objectif du plan de requête est de vous fournir une vue détaillée de la façon dont votre requête est exécutée. Pour en savoir plus sur cette fonctionnalité, consultez le Plan de requête.
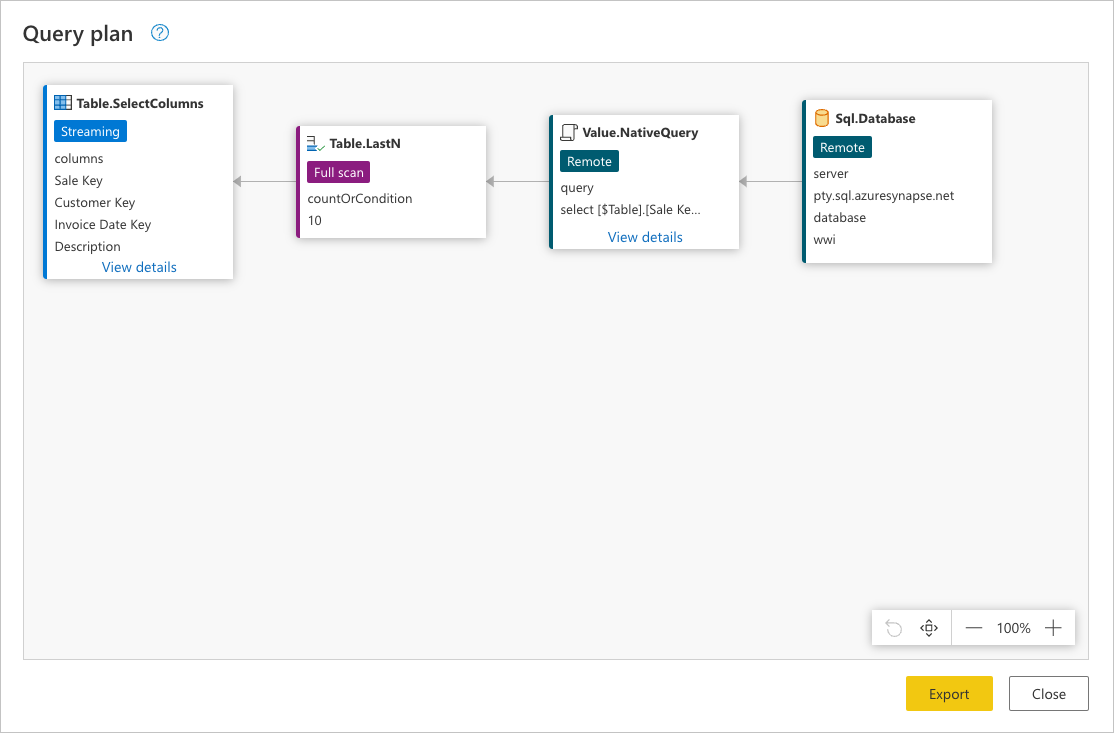
Chaque zone de l’image précédente est appelée nœud. Un nœud représente la répartition des opérations pour répondre à cette requête. Les nœuds qui représentent des sources de données, comme SQL Server dans l’exemple ci-dessus et le Value.NativeQuery nœud, représentent la partie de la requête qui est déchargée vers la source de données. Le reste des nœuds, dans ce cas Table.LastN et Table.SelectColumns mis en surbrillance dans le rectangle de l’image précédente, est évalué par le moteur Power Query. Ces deux nœuds représentent les deux transformations que vous avez ajoutées, les lignes inférieures conservées et Choisir des colonnes. Les autres nœuds représentent des opérations qui se produisent au niveau de votre source de données.
Pour afficher la demande exacte envoyée à votre source de données, sélectionnez Afficher les détails dans le Value.NativeQuery nœud.
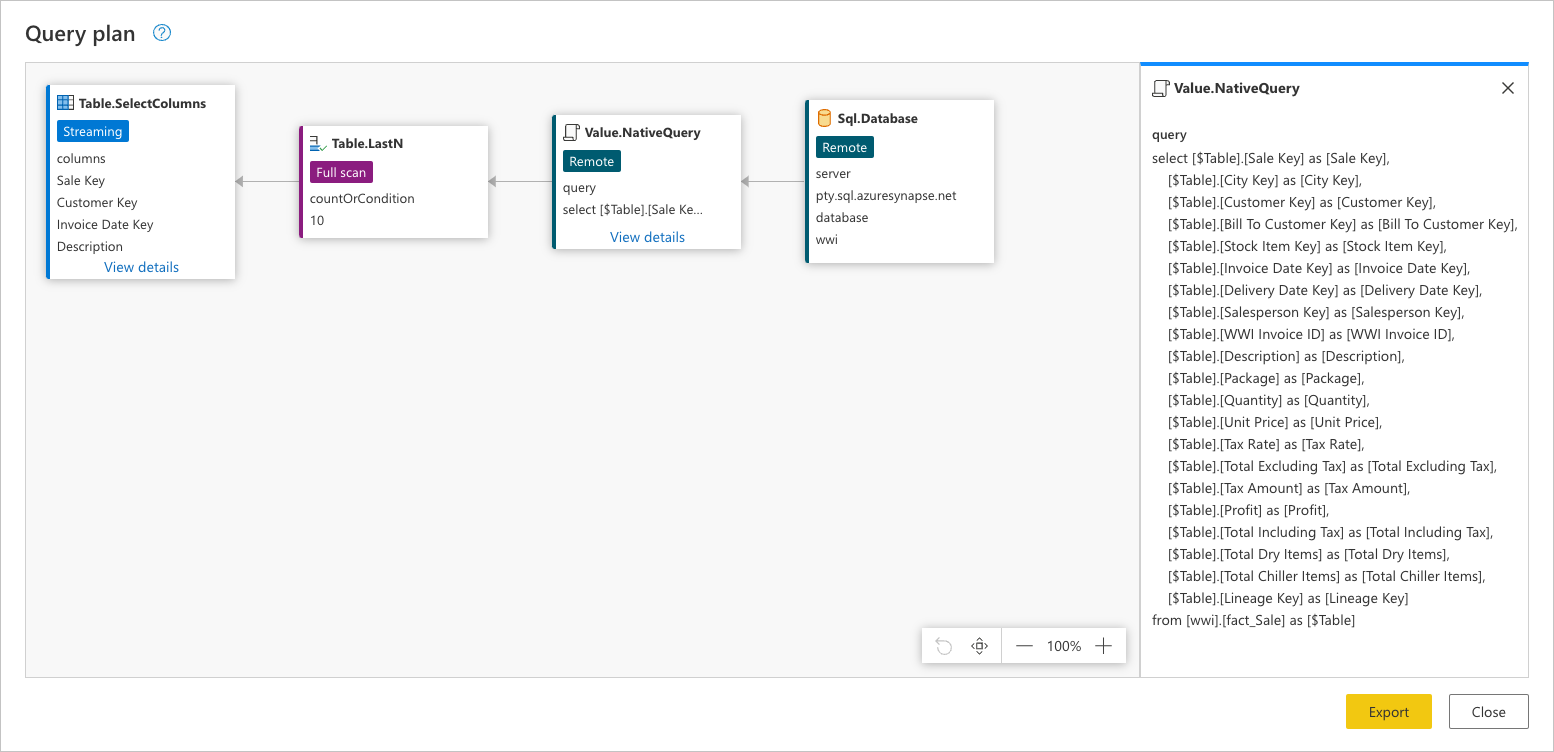
Cette demande de source de données se trouve dans le langage natif de votre source de données. Pour ce cas, ce langage est SQL et cette instruction représente une demande pour toutes les lignes et champs de la table fact_Sale.
La consultation de cette requête de source de données peut vous aider à mieux comprendre l’histoire que le plan de requête tente de transmettre :
Sql.Database: ce nœud représente l’accès à la source de données. Se connecte à la base de données et envoie des requête de métadonnées pour comprendre ses fonctionnalités.Value.NativeQuery: Représente la requête générée par Power Query pour répondre à la requête. Power Query soumet les requête de données dans une instruction SQL native à la source de données. Dans ce cas, qui représente tous les enregistrements et champs (colonnes) de lafact_Saletable. Pour ce scénario, ce cas n’est pas souhaitable, car la table contient des millions de lignes et que seulement les 10 derniers sont intéressants.Table.LastN: une fois que Power Query reçoit tous les enregistrements de la tablefact_Sale, il utilise le moteur Power Query pour filtrer la table et conserver uniquement les 10 dernières lignes.Table.SelectColumns: Power Query utilisera la sortie du nœudTable.LastNet applique une nouvelle transformation appeléeTable.SelectColumns, qui sélectionne les colonnes spécifiques à conserver d’une table.
Pour son évaluation, cette requête devait télécharger toutes les lignes et tous les champs de la table fact_Sale. Cette requête a pris en moyenne 6 minutes et 1 seconde pour être traitée dans une instance standard de flux de données Power BI (qui compte pour l’évaluation et le chargement de données dans des flux de données).
Exemple avec Query Folding partiel
Après vous être connecté à la base de données et accédé à la table fact_Sale, vous commencez par sélectionner les colonnes que vous souhaitez conserver de votre table. Sélectionnez la transformation Choisir des colonnes trouvées dans le groupe Gérer les colonnes sous l’onglet Accueil . Cette transformation vous permet de sélectionner explicitement les colonnes que vous souhaitez conserver de votre table et de supprimer le reste.
Dans la boîte de dialogue Choisir des colonnes, sélectionnez les colonnes Sale Key, Customer Key, Invoice Date Key, Description, et Quantity puis sélectionnez OK.
Vous créez maintenant une logique qui triera la table pour avoir les dernières ventes en bas de la table. Sélectionnez la Sale Key colonne, qui est la clé primaire et la séquence incrémentielle ou l’index de la table. Triez la table en utilisant uniquement ce champ dans l’ordre croissant dans le menu contextuel de la colonne.
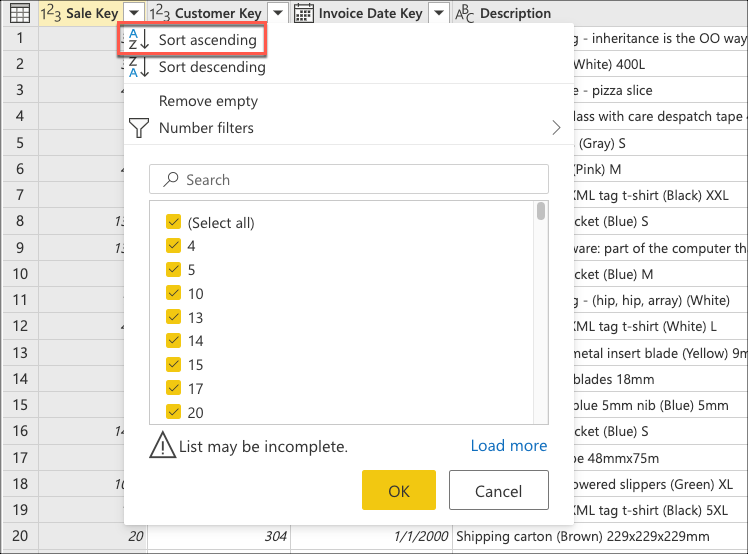
Ensuite, sélectionnez le menu contextuel du tableau et choisissez la transformation Conserver les lignes inférieures.
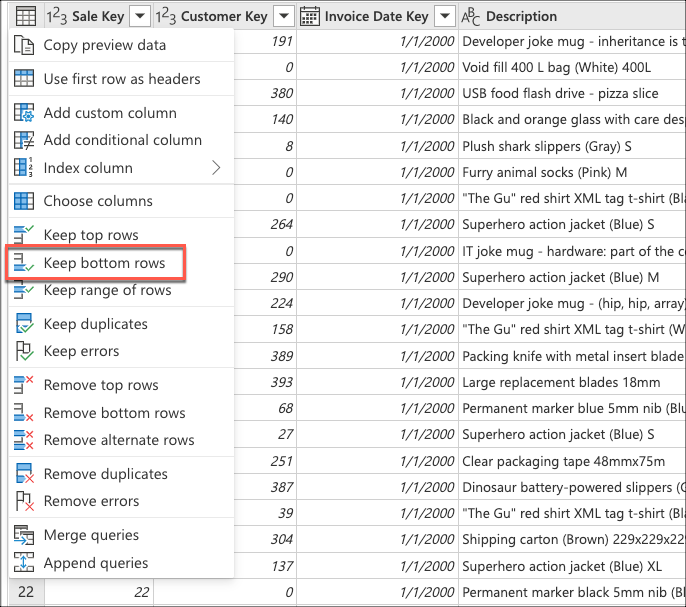
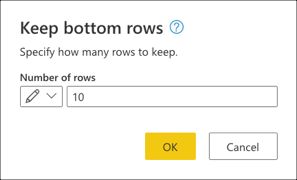
Dans Conserver les lignes inférieures, entrez la valeur 10, puis sélectionnez OK.
L’exemple de code suivant est le script M complet de la requête que vous avez créée :
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Choose columns" = Table.SelectColumns(Navigation, {"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"}),
#"Sorted rows" = Table.Sort(#"Choose columns", {{"Sale Key", Order.Ascending}}),
#"Kept bottom rows" = Table.LastN(#"Sorted rows", 10)
in
#"Kept bottom rows"
Exemple de Query Folding partiel : Comprendre l’évaluation des requêtes
En vérifiant le volet étapes appliquées, vous remarquez que les indicateurs de Query Folding montrent que la dernière transformation que vous avez ajoutée, Kept bottom rows, est marquée comme une étape qui sera évaluée en dehors de la source de données ou, en d’autres termes, par le moteur de Power Query.
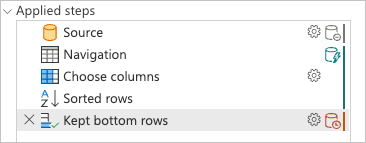
Vous pouvez cliquer avec le bouton droit sur la dernière étape de votre requête, celle nommée Kept bottom rows, puis sélectionner l’option de plan de requête pour mieux comprendre comment votre requête peut être évaluée.
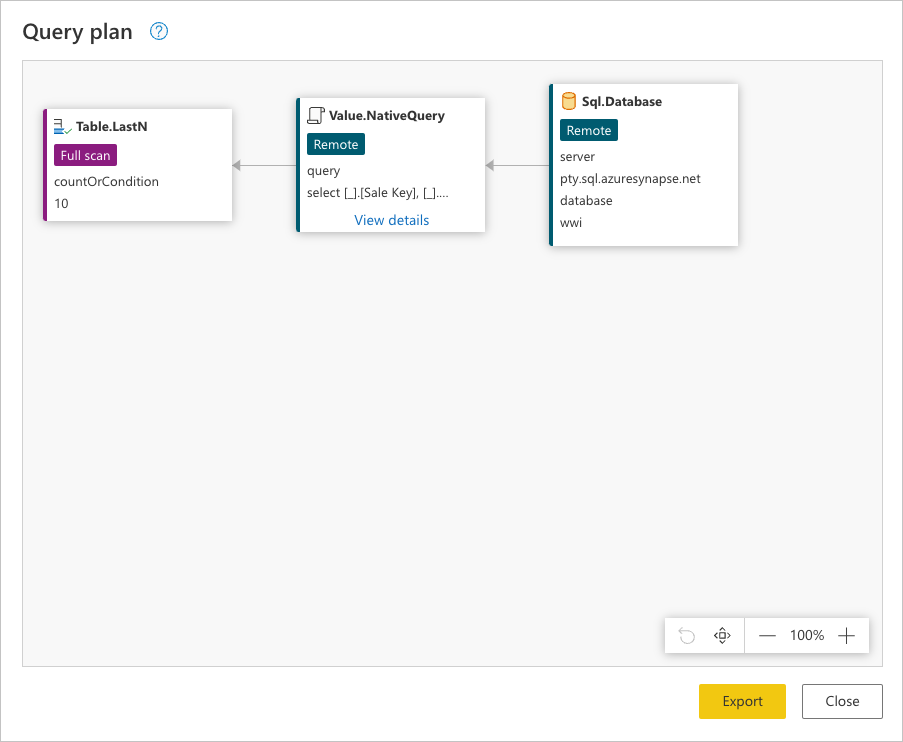
Chaque zone de l’image précédente est appelée nœud. Un nœud représente chaque processus qui doit se produire (de gauche à droite) afin que votre requête soit évaluée. Certains de ces nœuds peuvent être évalués à votre source de données, tandis que d’autres, comme le nœud pour Table.LastN, représenté par l’étape Lignes inférieures conservées, sont évalués à l’aide du moteur Power Query.
Pour afficher la demande exacte envoyée à votre source de données, sélectionnez Afficher les détails dans le Value.NativeQuery nœud.
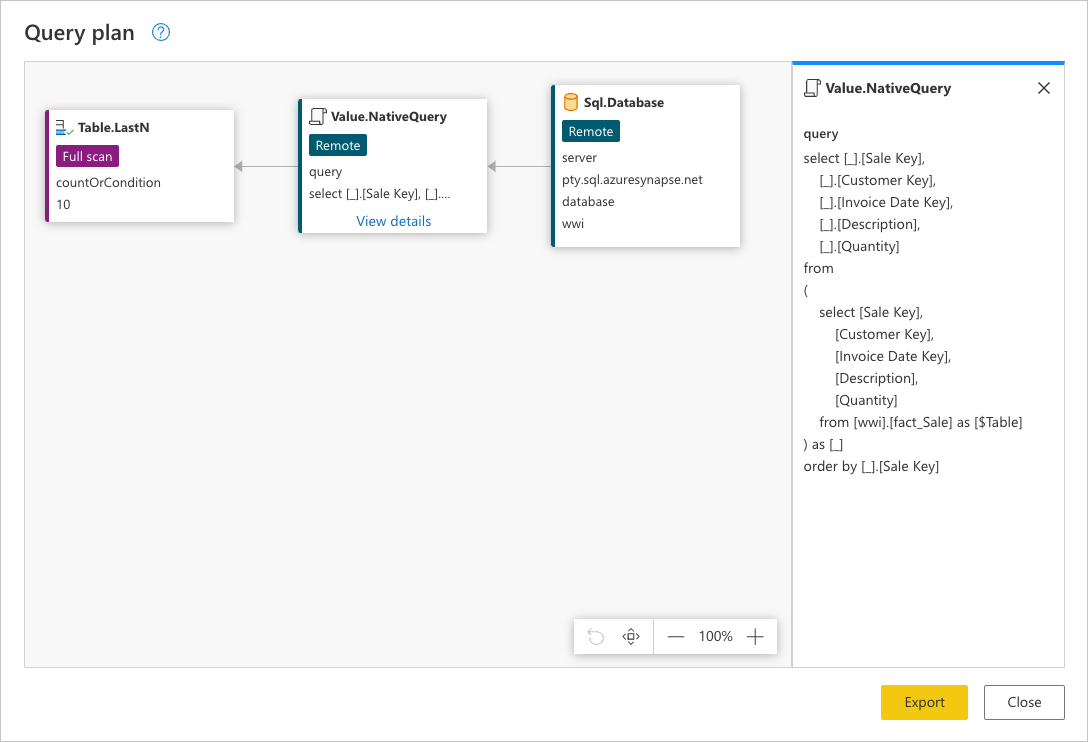
Cette demande se trouve dans le langage natif de votre source de données. Dans ce cas, ce langage est SQL et cette déclaration représente une requête pour toutes les lignes, avec uniquement les champs demandés de la fact_Sale table triée par le Sale Key champ.
La consultation de cette requête de source de données peut vous aider à mieux comprendre l’histoire que le plan de requête complet tente de transmettre. L’ordre des nœuds est un processus séquentiel qui commence par demander les données de votre source de données :
Sql.Database: Se connecte à la base de données et envoie des requête de métadonnées pour comprendre ses fonctionnalités.Value.NativeQuery: Représente la requête générée par Power Query pour répondre à la requête. Power Query soumet les requête de données dans une instruction SQL native à la source de données. Dans ce cas, cela représente tous les enregistrements, avec uniquement les champs demandés de lafact_Saletable dans la base de données triées par ordre croissant par leSales Keychamp.Table.LastN: une fois que Power Query reçoit tous les enregistrements de la tablefact_Sale, il utilise le moteur Power Query pour filtrer la table et conserver uniquement les 10 dernières lignes.
Pour son évaluation, cette requête devait télécharger toutes les lignes et seulement les champs de la table nécessaires fact_Sale. Elle a pris en moyenne 3 minutes et 4 secondes pour être traitée dans une instance standard de flux de données Power BI (qui compte pour l’évaluation et le chargement de données dans des flux de données).
Exemple avec Query Folding complet
Après vous être connecté à la base de données et avoir accédé à la table fact_Sale, commencez par sélectionner les colonnes que vous souhaitez conserver de votre table. Sélectionnez la transformation Choisir des colonnes trouvées dans le groupe Gérer les colonnes sous l’onglet Accueil . Cette transformation vous permet de sélectionner explicitement les colonnes que vous souhaitez conserver de votre table et de supprimer le reste.
Dans Choisir les colonnes,sélectionnez les colonnes Sale Key, Customer Key, Invoice Date Key, Description, et Quantity puis sélectionnez OK.
Vous créez maintenant une logique qui triera la table pour avoir les dernières ventes en haut de la table. Sélectionnez la Sale Key colonne, qui est la clé primaire et la séquence incrémentielle ou l’index de la table. Triez la table en utilisant uniquement ce champ dans l’ordre décroissant dans le menu contextuel de la colonne.
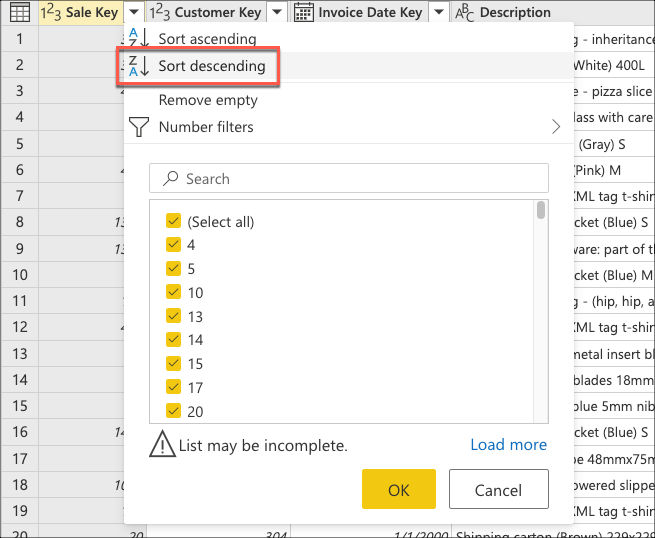
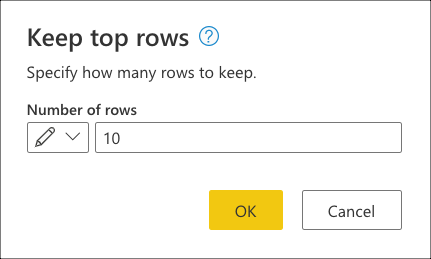
Ensuite, sélectionnez le menu contextuel du tableau et choisissez la transformation Conserver les lignes supérieures.
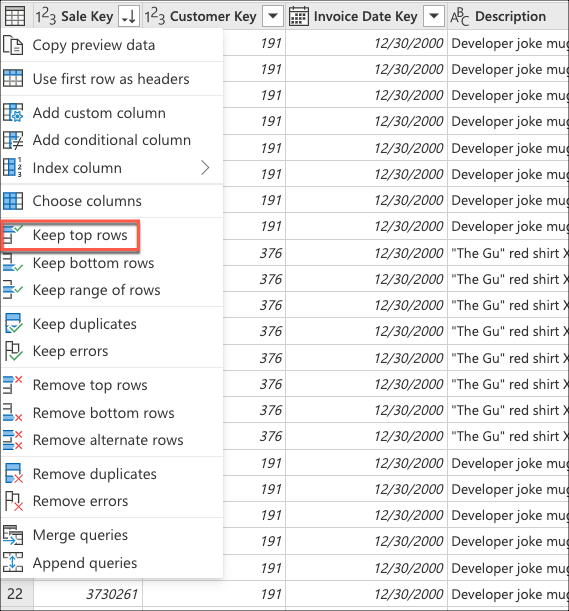
Dans Conserver les lignes supérieures, entrez la valeur 10, puis sélectionnez OK.
L’exemple de code suivant est le script M complet de la requête que vous avez créée :
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Choose columns" = Table.SelectColumns(Navigation, {"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"}),
#"Sorted rows" = Table.Sort(#"Choose columns", {{"Sale Key", Order.Descending}}),
#"Kept top rows" = Table.FirstN(#"Sorted rows", 10)
in
#"Kept top rows"
Exemple de Query Folding complet : Comprendre l’évaluation des requêtes
Lorsque vous vérifiez le volet des étapes appliquées, vous remarquerez que les indicateurs de Query Folding montrent que les transformations que vous avez ajoutées, Choisir des colonnes, Lignes triées et Lignes supérieures conservées comme des étapes qui seront évaluées à la source de données.

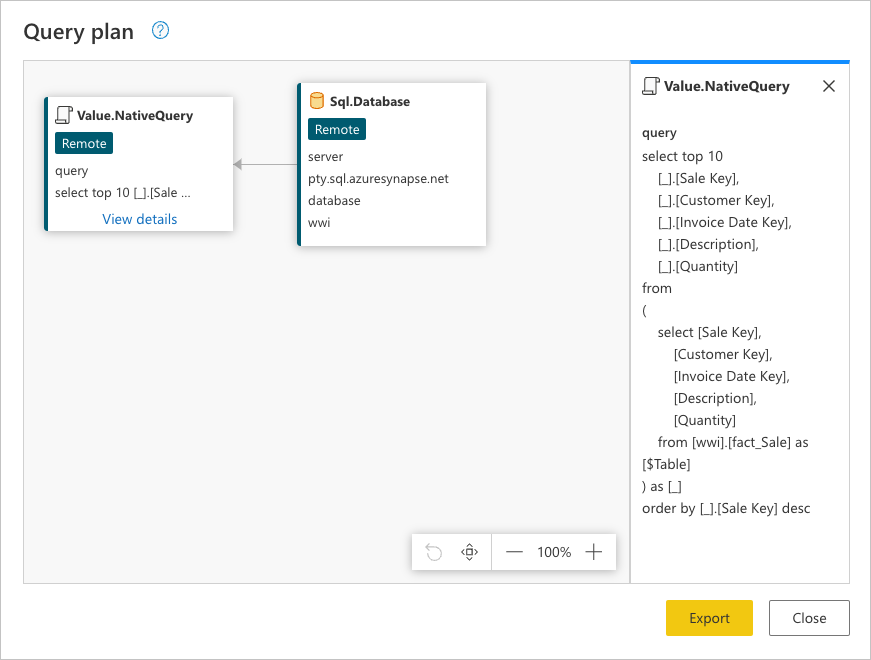
Vous pouvez cliquer avec le bouton droit sur la dernière étape de votre requête, celle nommée Lignes supérieures conservées, puis sélectionner l’option où vous lisez Plan de requête.
Cette demande se trouve dans le langage natif de votre source de données. Pour ce cas, ce langage est SQL et cette instruction représente une demande pour toutes les lignes et champs de la table fact_Sale.
La consultation de cette requête de source de données peut vous aider à mieux comprendre l’histoire que le plan de requête complet tente de transmettre :
Sql.Database: Se connecte à la base de données et envoie des requête de métadonnées pour comprendre ses fonctionnalités.Value.NativeQuery: Représente la requête générée par Power Query pour répondre à la requête. Power Query soumet les requête de données dans une instruction SQL native à la source de données. Dans ce cas, cela représente une requête pour les 10 premiers enregistrements de lafact_Saletable avec uniquement les champs requis après avoir été triés dans l’ordre décroissant à l’aide duSale Keychamp.
Remarque
Bien qu’il n’existe aucune clause qui peut être utilisée pour SÉLECTIONNER les lignes inférieures d’une table dans le langage T-SQL, il existe une clause TOP qui récupère les lignes supérieures d’une table.
Pour son évaluation, cette requête télécharge uniquement 10 lignes, avec uniquement les champs que vous avez demandés à partir de la table fact_Sale. Cette requête a pris en moyenne 31 secondes pour être traitée dans une instance standard de flux de données Power BI (qui compte pour l’évaluation et le chargement de données dans des flux de données).
Comparaison entre les performances
Pour mieux comprendre l’impact que le Query Folding a dans ces requêtes, vous pouvez actualiser vos requêtes, enregistrer le temps nécessaire pour actualiser entièrement chaque requête et les comparer. Par souci de simplicité, cet article fournit les minutages d’actualisation moyens capturés à l’aide du mécanicien d’actualisation des flux de données Power BI lors de la connexion à un environnement Azure Synapse Analytics dédié avec DW2000c comme niveau de service.
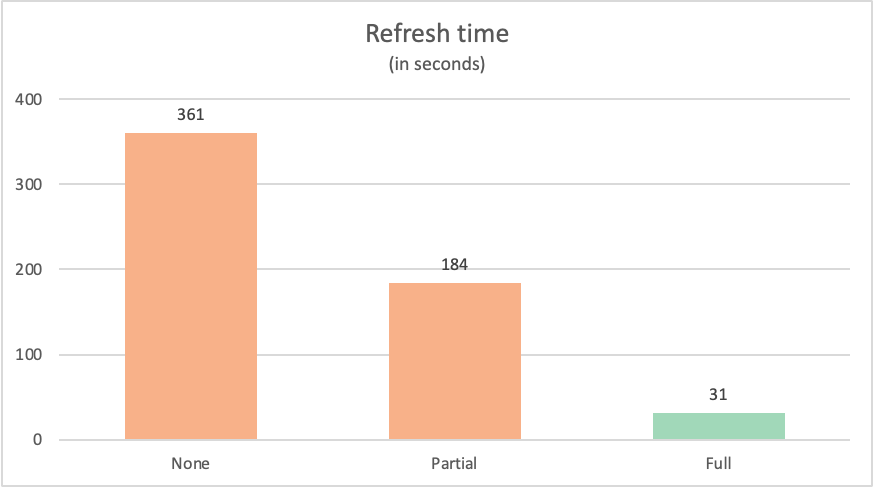
L’heure d’actualisation de chaque requête était la suivante :
| Exemple | Étiquette | Temps en secondes |
|---|---|---|
| Sans Query Folding | Aucun | 361 |
| Query Folding partiel | Partiel | 184 |
| Query Folding complet | Complet | 31 |
C’est souvent le cas qu’une requête qui effectue Query Folding complet à la source de données dépasse les requêtes similaires avec un Query Folding partiel vers la source de données. Il pourrait y avoir de nombreuses raisons pour lesquelles c’est le cas. Ces raisons vont de la complexité des transformations que votre requête effectue, aux optimisations de requête implémentées sur votre source de données, telles que les index et l’informatique dédiée et les ressources réseau. Toutefois, il existe deux processus clés spécifiques que le pliage de requêtes tente d’utiliser, ce qui réduit l’impact que ces deux processus ont avec Power Query :
- Données en transit
- Transformations exécutées par le moteur de Power Query
Les sections suivantes expliquent l’impact que ces deux processus ont dans les requêtes mentionnées précédemment.
Données en transit
Lorsqu’une requête est exécutée, elle tente d’extraire les données de la source de données en tant que première étape. Les données extraites de la source de données sont définies par le mécanisme de Query Folding. Ce mécanisme identifie les étapes de la requête qui peuvent être déchargées vers la source de données.
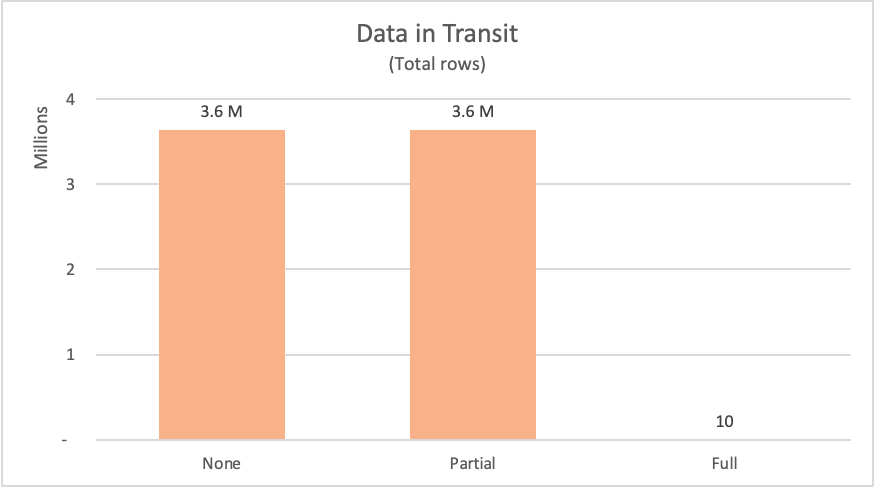
La table suivante répertorie le nombre de lignes demandées à partir de la fact_Sale table de la base de données. La table inclut également une brève description de l’instruction SQL envoyée pour demander ces données à la source de données.
| Exemple | Étiquette | Lignes demandées | Description |
|---|---|---|---|
| Sans Query Folding | Aucun | 3644356 | Demander tous les champs et tous les enregistrements de la fact_Sale table |
| Query Folding partiel | Partiel | 3644356 | Demander tous les enregistrements, mais uniquement les champs requis de la fact_Sale table après avoir été triés par le Sale Key champ |
| Query Folding complet | Complet | 10 | Demander uniquement les champs requis et les enregistrements TOP 10 de la fact_Sale table après avoir été triés dans l’ordre décroissant par le Sale Key champ |
Lors de la demande de données à partir d’une source de données, la source de données doit calculer les résultats de la demande, puis envoyer les données au demandeur. Bien que les ressources informatiques aient déjà été mentionnées, les ressources réseau de déplacement des données de la source de données vers Power Query, puis ont Power Query être en mesure de recevoir efficacement les données et de les préparer pour les transformations qui se produisent localement peut prendre un certain temps en fonction de la taille des données.
Pour les exemples présentés, Power Query devaient demander plus de 3,6 millions de lignes à la source de données pour les exemples sans Query Folding et de Query Folding partiel. Pour l’exemple de Query Folding complet, il n’a demandé que 10 lignes. Pour les champs demandés, l’exemple sans Query Folding a demandé tous les champs disponibles de la table. Les exemples de Query Folding partiels et de Query Folding complets n’ont envoyé qu’une demande pour les champs dont ils avaient besoin.
Attention
Nous vous recommandons d’implémenter des solutions d’actualisation incrémentielle qui tirent parti du pliage des requêtes pour les requêtes ou les tables contenant de grandes quantités de données. Différentes intégrations de produits de Power Query implémentent des délais d’attente pour mettre fin aux requêtes durables. Certaines sources de données implémentent également des délais d’expiration sur des sessions longues, essayant d’exécuter des requêtes coûteuses sur leurs serveurs. Informations supplémentaires : Utilisation de l’actualisation incrémentielle avec des flux de données et de l’actualisation incrémentielle pour les modèles sémantiques
Transformations exécutées par le moteur de Power Query
Cet article explique comment utiliser le Plan de requête pour mieux comprendre comment votre requête peut être évaluée. Dans le plan de requête, vous pouvez voir les nœuds exacts des opérations de transformation qui seront effectuées par le moteur Power Query.
Le tableau suivant présente les nœuds des plans de requête des requêtes précédentes qui auraient été évaluées par le moteur Power Query.
| Exemple | Étiquette | Nœuds de transformation du moteur Power Query |
|---|---|---|
| Sans Query Folding | Aucun | Table.LastN, Table.SelectColumns |
| Query Folding partiel | Partiel | Table.LastN |
| Query Folding complet | Complet | — |
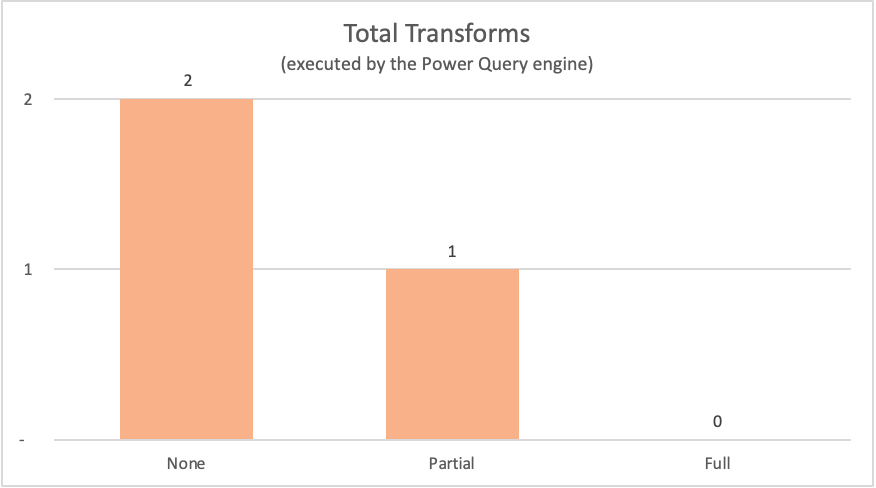
Pour les exemples présentés dans cet article, l’exemple deQuery Folding complet ne nécessite aucune transformation à l’intérieur du moteur Power Query, car la table de sortie nécessaire provient directement de la source de données. En revanche, les deux autres requêtes ont requis un calcul pour se produire au moteur Power Query. En raison de la quantité de données qui doivent être traitées par ces deux requêtes, le processus pour ces exemples prend plus de temps que l’exemple de Query Folding complet.
Ces avantages peuvent être regroupés dans les catégories suivantes :
| Type d'Opérateur | Description |
|---|---|
| À distance | Opérateurs qui sont des nœuds de source de données. L’évaluation de ces opérateurs se produit en dehors de Power Query. |
| Streaming | Les opérateurs sont des opérateurs pass-through. Par exemple, Table.SelectRows avec un filtre simple, vous pouvez généralement filtrer les résultats au fur et à mesure qu’ils passent par l’opérateur et n’ont pas besoin de collecter toutes les lignes avant de déplacer les données. Table.SelectColumns et Table.ReorderColumns sont d’autres exemples de ces types d’opérateurs. |
| Analyse complète | Opérateurs qui doivent collecter toutes les lignes avant que les données puissent passer à l’opérateur suivant de la chaîne. Par exemple, pour trier les données, Power Query doit collecter toutes les données. D’autres exemples d’opérateurs d’analyse complète sont Table.Group, Table.NestedJoinet Table.Pivot. |
Conseil
Bien que toutes les transformations ne sont pas identiques du point de vue des performances, dans la plupart des cas, l’utilisation de moins de transformations est généralement meilleure.
Considérations et suggestions
- Suivez les meilleures pratiques lors de la création d’une requête, comme indiqué dans Les meilleures pratiques dans Power Query.
- Utilisez les indicateurs de pliage de requête pour vérifier les étapes qui empêchent le repli de votre requête. Réorganisez-les si nécessaire pour augmenter le repli.
- Utilisez le plan de requête pour déterminer les transformations qui se produisent au moteur Power Query pour une étape particulière. Envisagez de modifier votre requête existante en réaménageant vos étapes. Vérifiez ensuite le plan de requête de la dernière étape de votre requête et voyez si le plan de requête semble mieux que celui précédent. Par exemple, le nouveau plan de requête a moins de nœuds que le précédent, et la plupart des nœuds sont des nœuds « Streaming » et non « analyse complète ». Pour les sources de données qui prennent en charge le pliage, tous les nœuds du plan de requête autres que
Value.NativeQueryles nœuds d’accès aux sources de données représentent des transformations qui n’ont pas été pliés. - Lorsque vous êtes disponible, vous pouvez utiliser l’option Afficher la requête native (ou afficher la requête de source de données) pour vous assurer que votre requête peut être pliée vers la source de données. Si cette option est désactivée pour votre étape et que vous utilisez une source qui l’active normalement, vous avez créé une étape qui arrête le Query Folding. Si vous utilisez une source qui ne prend pas en charge cette option, vous pouvez vous appuyer sur les indicateurs de pliage des requêtes et le plan de requête.
- Utilisez les outils de diagnostic de requête pour mieux comprendre les demandes envoyées à votre source de données lorsque les fonctionnalités de Query Folding sont disponibles pour le connecteur.
- Lors de la combinaison de données sources à partir de l’utilisation de plusieurs connecteurs, Power Query tente d’envoyer autant de travail que possible aux deux sources de données tout en respectant les niveaux de confidentialité définis pour chaque source de données.
- Lisez l’article sur les niveaux de confidentialité pour protéger vos requêtes contre une erreur de pare-feu de confidentialité des données.
- Utilisez d’autres outils pour vérifier le Query Folding du point de vue de la demande reçue par la source de données. En fonction de l’exemple de cet article, vous pouvez utiliser microsoft SQL Server Profiler pour vérifier les demandes envoyées par Power Query et reçues par Microsoft SQL Server.
- Si vous ajoutez une nouvelle étape à une requête entièrement pliée et que la nouvelle étape plie également, Power Query peut envoyer une nouvelle requête à la source de données au lieu d’utiliser une version mise en cache du résultat précédent. Dans la pratique, ce processus peut causer des opérations apparemment simples sur une petite quantité de données à prendre plus de temps que prévu pour actualiser dans la préversion. Cette actualisation plus longue est due à Power Query qui soumet de nouveau une requête de à la source de données plutôt que de travailler sur une copie locale des données.