Quelle est la structure de stockage pour les flux de données analytiques ?
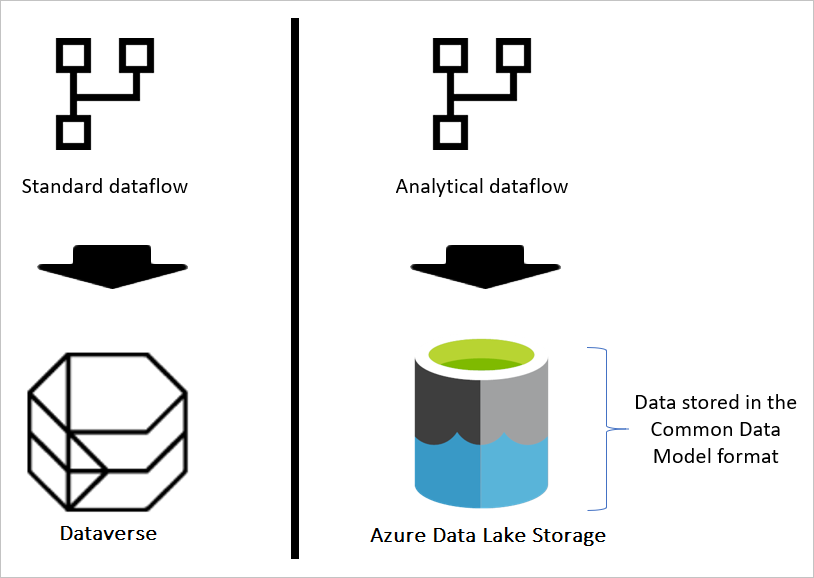
Les flux de données analytiques stockent les données et les métadonnées dans Azure Data Lake Storage. Les flux de données tirent parti d’une structure standard pour stocker et décrire les données créées dans le lac, appelées dossiers Common Data Model. Dans cet article, vous allez en savoir plus sur la norme de stockage que les flux de données utilisent en arrière-plan.
Le stockage a besoin d’une structure pour un flux de données analytique
Si le flux de données est standard, les données sont stockées dans Dataverse. Dataverse est comme un système de base de données ; il a le concept de tables, de vues, et ainsi de suite. Dataverse est une option de stockage de données structurée utilisée par les flux de données standard.
Toutefois, lorsque le flux de données est analytique, les données sont stockées dans Azure Data Lake Storage. Les données et métadonnées d’un flux de données sont stockées dans un dossier Common Data Model. Étant donné qu’un compte de stockage peut avoir plusieurs flux de données stockés dans celui-ci, une hiérarchie de dossiers et de sous-dossiers a été introduite pour aider à organiser les données. Selon le produit dans lequel le flux de données a été créé, les dossiers et sous-dossiers peuvent représenter des espaces de travail (ou des environnements), puis le dossier Common Data Model du flux de données. Dans le dossier Common Data Model, le schéma et les données des tables de flux de données sont stockés. Cette structure suit les normes définies pour Common Data Model.
Quelle est la structure de stockage du modèle commun de données ?
Common Data Model est une structure de métadonnées définie pour apporter la conformité et la cohérence pour l’utilisation de données sur plusieurs plateformes. Common Data Model n’est pas un stockage de données, c’est la façon dont les données sont stockées et définies.
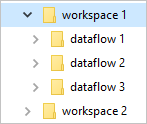
Les dossiers Common Data Model définissent la manière dont le schéma d’une table et ses données doivent être stockés. Dans Azure Data Lake Storage, les données sont organisées dans des dossiers. Les dossiers peuvent représenter un espace de travail ou un environnement. Sous ces dossiers, les sous-dossiers pour chaque flux de données sont créés.
Qu’est-ce qui se trouve dans un dossier de flux de données ?
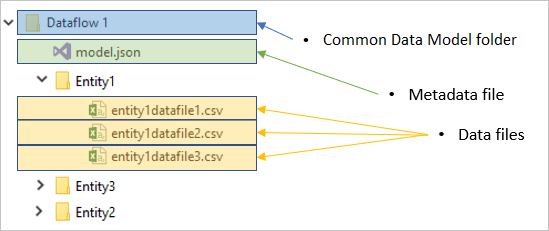
Chaque dossier de flux de données contient un sous-dossier pour chaque table et un fichier de métadonnées nommé model.json.
Le fichier de métadonnées : model.json
Le model.json fichier est la définition de métadonnées du flux de données. Il s’agit du fichier qui contient toutes les métadonnées de flux de données. Il inclut une liste de tables, les colonnes et leurs types de données dans chaque table, la relation entre les tables, et ainsi de suite. Vous pouvez exporter ce fichier à partir d’un flux de données facilement, même si vous n’avez pas accès à la structure de dossiers Common Data Model.
Vous pouvez utiliser ce fichier JSON pour migrer (ou importer) votre flux de données dans un autre espace de travail ou environnement.
Pour savoir exactement ce que le fichier de métadonnées model.json inclut, accédez au fichier de métadonnées (model.json) pour Common Data Model.
Fichiers de données
En plus du fichier de métadonnées, le dossier de flux de données inclut d’autres sous-dossiers. Un flux de données stocke les données de chaque table dans un sous-dossier portant le nom de la table. Les données d’une table peuvent être divisées en plusieurs partitions de données, stockées au format CSV.
Guide pratique pour voir ou accéder aux dossiers Common Data Model
Si vous utilisez des flux de données qui utilisent le stockage fourni par le produit dans lequel ils ont été créés, vous n’aurez pas accès directement à ces dossiers. Dans ce cas, l’obtention de données à partir des flux de données nécessite l’utilisation du connecteur de flux de données Microsoft Power Platform disponible dans l’expérience Obtenir des données dans les produits Service Power BI, Power Apps et Dynamics 35 Customer Insights, ou dans Power BI Desktop.
Pour savoir comment les flux de données et l’intégration interne Data Lake Storage fonctionnent, accédez aux Flux de données et à l’intégration d’Azure Data Lake (préversion).
Si votre organisation a activé les flux de données pour tirer parti de son compte Data Lake Storage et a été sélectionné comme cible de charge pour les flux de données, vous pouvez toujours obtenir des données à partir du flux de données à l’aide du connecteur de flux de données Power Platform comme mentionné ci-dessus. Toutefois, vous pouvez également accéder directement au dossier Common Data Model du flux de données via le lac, même en dehors des outils et services Power Platform. L’accès au lac est possible via les Portail Azure, Explorateur Stockage Microsoft Azure ou tout autre service ou expérience qui prend en charge Azure Data Lake Storage. Pour plus d’informations, voir : Connecter Azure Data Lake Storage Gen2 pour le stockage du flux de données
Étapes suivantes
Utiliser le modèle de données commun pour optimiser le stockage Azure Data Lake Gen2
Ajouter un dossier CDM à Power BI en tant que flux de données (préversion)
Connecter Azure Data Lake Storage Gen2 pour le stockage du flux de données
Flux de données et intégration à Azure Data Lake (préversion)
Configurer les paramètres de dataflow d’espace de travail (préversion)