Meilleures pratiques pour la conception et le développement de dataflows complexes
Si le flux de données que vous développez devient plus grand et plus complexe, voici quelques choses que vous pouvez faire pour améliorer votre conception d’origine.
Décomposez-le en plusieurs dataflows
Ne faites pas tout dans un flux de données. Non seulement un flux de données unique et complexe rend le processus de transformation de données plus long, il est également plus difficile de comprendre et de réutiliser le flux de données. Le fractionnement de votre dataflow en plusieurs dataflows peut être effectué en séparant des tables dans différents dataflows, ou même une table en plusieurs dataflows. Vous pouvez utiliser le concept d’une table calculée ou d’une table liée pour générer une partie de la transformation dans un dataflow et la réutiliser dans d’autres dataflows.
Séparer les dataflows de transformation de données des dataflows intermédiaires/d’extraction
Avoir des dataflows uniquement pour extraire des données (autrement dit, flux de données intermédiaires) et d’autres simplement pour transformer des données est utile non seulement pour créer une architecture multicouche, il est également utile de réduire la complexité des flux de données. Certaines étapes extraient simplement les données de la source de données, telles que l’obtention de données, la navigation et les modifications de type de données. En séparant les dataflows intermédiaires et les flux de données de transformation, vous simplifiez le développement de vos dataflows.
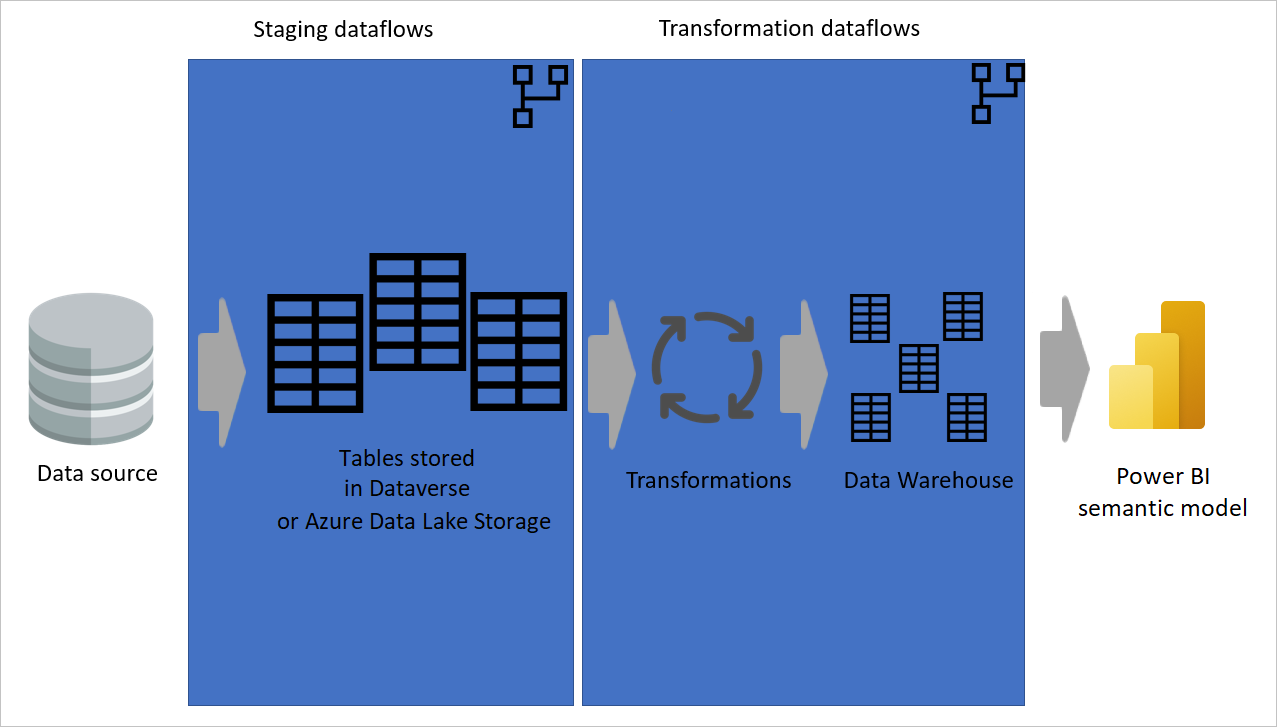
Image montrant les données extraites d’une source de données vers des dataflows intermédiaires, où les tables sont stockées dans Dataverse ou Azure Data Lake Storage. Ensuite, les données sont déplacées vers des dataflows de transformation où les données sont transformées et converties en structure de l’entrepôt de données. Ensuite, les données sont déplacées vers le modèle sémantique.
Utiliser des fonctions personnalisées
Les fonctions personnalisées sont utiles dans les scénarios où un certain nombre d’étapes doivent être effectuées pour un certain nombre de requêtes provenant de différentes sources. Les fonctions personnalisées peuvent être développées via l’interface graphique dans l’éditeur Power Query ou à l’aide d’un script M. Les fonctions peuvent être réutilisées dans un flux de données dans autant de tables que nécessaire.
L’utilisation d’une fonction personnalisée vous permet d’avoir une seule version du code source. Vous n’avez donc pas besoin de dupliquer le code. Par conséquent, la gestion de la logique de transformation Power Query et le flux de données entier est beaucoup plus facile. Pour plus d’informations, consultez le billet de blog suivant : Fonctions personnalisées faciles dans Power BI Desktop.
Note
Parfois, vous pouvez recevoir une notification indiquant qu’une capacité Premium est nécessaire pour actualiser un dataflow avec une fonction personnalisée. Vous pouvez ignorer ce message et rouvrir l’éditeur de flux de données. Cela résout généralement votre problème, sauf si votre fonction fait référence à une requête « load enabled ».
Placer des requêtes dans des dossiers
L’utilisation de dossiers pour les requêtes permet de regrouper les requêtes associées. Lorsque vous développez le flux de données, passez un peu plus de temps à organiser des requêtes dans des dossiers qui sont logiques. À l’aide de cette approche, vous pouvez trouver des requêtes plus facilement à l’avenir et maintenir le code est beaucoup plus facile.
Utiliser des tables calculées
Les tables calculées ne rendent pas seulement votre dataflow plus compréhensible, elles offrent également de meilleures performances. Lorsque vous utilisez une table calculée, les autres tables référencées à partir de celle-ci obtiennent des données à partir d’une table « déjà traitée et stockée ». La transformation est beaucoup plus simple et plus rapide.
Tirer parti du moteur de calcul amélioré
Pour les flux de données développés dans le portail d’administration Power BI, veillez à utiliser le moteur de calcul amélioré en effectuant d’abord des jointures et des transformations de filtre dans une table calculée avant d’effectuer d’autres types de transformations.
Diviser de nombreuses étapes en plusieurs requêtes
Il est difficile de suivre un grand nombre d’étapes dans un tableau. Au lieu de cela, vous devriez répartir un grand nombre d’étapes entre plusieurs tables. Vous pouvez utiliser Activer le chargement pour d'autres requêtes et les désactiver s'ils sont des requêtes intermédiaires, et ne charger que la table finale via le flux de données. Lorsque vous avez plusieurs requêtes avec des étapes plus petites dans chacune d’elles, il est plus facile d’utiliser le diagramme de dépendances et de suivre chaque requête pour une investigation plus approfondie, plutôt que de creuser dans des centaines d’étapes dans une seule requête.
Ajouter des propriétés pour les requêtes et les étapes
La documentation est la clé d’un code facile à gérer. Dans Power Query, vous pouvez ajouter des propriétés aux tables et également aux étapes. Le texte que vous ajoutez dans les propriétés s’affiche sous forme d’info-bulle lorsque vous pointez sur cette requête ou cette étape. Cette documentation vous aide à maintenir votre modèle à l’avenir. En un clin d’œil à une table ou à une étape, vous pouvez comprendre ce qui se passe là-bas, plutôt que de repenser et de mémoriser ce que vous avez fait à cette étape.
Vérifiez que la capacité se trouve dans la même région
Les flux de données ne prennent actuellement pas en charge plusieurs pays ou régions. La capacité Premium doit se trouver dans la même région que votre tenant Power BI.
Séparer les sources locales des sources cloud
Nous vous recommandons de créer un flux de données distinct pour chaque type de source, tel que local, cloud, SQL Server, Spark et Dynamics 365. La séparation des dataflows par type de source facilite la résolution rapide des problèmes et évite les limites internes lorsque vous actualisez vos dataflows.
Flux de données distincts en fonction de l’actualisation planifiée requise pour les tables
Si vous disposez d’une table de transactions commerciales qui est mise à jour dans le système source toutes les heures et que vous disposez d’une table de mappage de produits qui est mise à jour chaque semaine, divisez ces deux tables en deux dataflows avec des planifications d’actualisation des données différentes.
Évitez de prévoir l’actualisation des tables liées dans le même espace de travail
Si vous êtes régulièrement verrouillé hors de vos dataflows qui contiennent des tables liées, cela peut être dû à un flux de données correspondant dépendant dans le même espace de travail verrouillé lors de l’actualisation du flux de données. Ce verrouillage fournit une précision transactionnelle et garantit que les deux flux de données sont correctement actualisés, mais il peut vous empêcher de modifier.
Si vous configurez une planification distincte pour le flux de données lié, les dataflows peuvent être actualisés inutilement et vous empêcher de modifier le flux de données. Il existe deux recommandations pour éviter ce problème :
- Ne définissez pas de planification d’actualisation pour un flux de données lié dans le même espace de travail que le flux de données source.
- Si vous souhaitez configurer une planification d’actualisation séparément et que vous souhaitez éviter le comportement de verrouillage, déplacez le flux de données vers un espace de travail distinct.