Vue d’ensemble de l’analyse des causes profondes
L’analyse des causes profondes vous permet de trouver des connexions cachées dans vos données. Par exemple, cela vous aide à comprendre pourquoi certaines instances prennent plus de temps à être terminées que d’autres, ou pourquoi certaines instances restent bloquées dans les retraitements tandis que d’autres se déroulent sans problème. L’analyse des causes profondes vous montrera les principales différences entre de telles instances.
Données requises
RCA peut utiliser tous vos attributs, mesures et mesures personnalisées au niveau de l’instance et trouver des liens entre eux et une mesure de votre choix.
La meilleure façon est d’inclure toutes les données que vous pouvez en tant qu’attribut au niveau de l’instance et de laisser RCA choisir quel attribut influence réellement la mesure et lequel ne l’influence pas.
Fonctionnement d’RCA
L’algorithme RCA calcule une structure arborescente où chaque nœud répartit le jeu de données en deux parties plus petites. Ceci est basé sur une variable où il trouve la meilleure corrélation entre la répartition variable et la mesure cible. À partir de là, vous pouvez voir les connexions cachées dans les données. C’est là qu’il vous dira quelle combinaison d’attributs influencera l’instance et de quelle manière.
Comment RCA trouve-t-il la meilleure répartition ?
Tout d’abord, nous générons des centaines à des milliers de combinaisons de répartitions possibles. Ensuite, nous essayons chaque répartition pour découvrir la manière dont elle divisera réellement le jeu de données en deux parties. Nous calculons la variance de la mesure principale dans chaque partie de la division et calculons le score pour chaque division avec le calcul suivant :
scoresplit_x = variancegauche * nombre d’instancesgauche + variancedroite * nombre d’instancesdroite
Ensuite, nous trions toutes les divisions par ce score et les meilleures divisions sont prises depuis le début, avec le score le plus bas. Pour la mesure principale catégorielle (chaîne), nous calculons l’impureté de Gini plutôt que l’écart.
Exemple RCA
Dans cet exemple, nous souhaitons voir la cause profonde derrière la durée de l’instance. Dans les données, nous avons des attributs au niveau de l’instance pays du fournisseur, ville du fournisseur, matériau,montant total et centre de coûts. La durée moyenne d’une instance est de 46 heures.
En examinant chaque valeur de chaque attribut séparément, nous pouvons dire que le plus grand facteur d’influence de la durée de l’instance est le moment où ville du fournisseur est Graz ce qui augmente en moyenne la durée de l’instance de 15 heures supplémentaires. Depuis cette première analyse, on constate que les autres valeurs d’attributs influencent beaucoup moins la mesure cible. Cependant, lorsque nous calculons le modèle d’arborescence, nous pouvons voir que le calcul ci-dessus est trompeur (comme l’illustre la capture d’écran suivante).
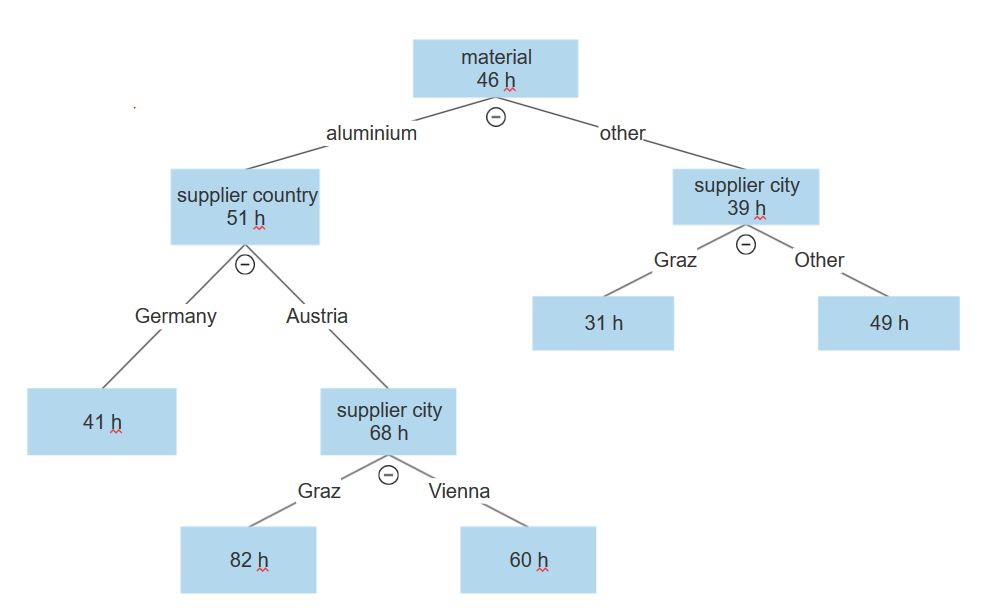
L’arborescence ressemble à ceci :
La première division correspond aux données associées à la variable matériau. Les données avec aluminium sont d’un côté et tous les autres matériaux se trouvent de l’autre côté.
Maintenant la branche aluminium est répartie davantate selon le pays du fournisseur, à savoir Allemagne et Autriche.
La branche Autriche continue d’être répartie selon la ville du fournisseur, avec Graz d’un côté et Vienne de l’autre.
Dans le nœud Graz, l’instance moyenne était de 36 heures plus lente que la durée moyenne globale de 46 heures.
Dans la même arborescence, nous pouvons voir que si nous avons un autre matériau que l’aluminium, il se répartit également selon la variable supplier city, où d’un côté se trouve Graz et de l’autre Vienna, Munich ou Frankfurt. Mais ici, les valeurs sont à l’opposé. Graz affiche de bien meilleures statistiques que Vienna ou n’importe quelle ville allemande, l’instance moyenne à Graz étant 15 heures plus rapide que la moyenne globale pour toutes les instances.
À partir de là, nous pouvons voir que les statistiques initiales sont trompeuses, car Graz a de mauvaises performances lorsque le matériau est l’aluminium, mais des performances supérieures à la moyenne lorsque le matériau est autre que l’aluminium et c’est complètement le contraire pour les autres villes.
L’influence de la durée de l’instance ne prend en compte qu’une seule valeur et peut donc parfois induire en erreur. RCA prend en compte leurs combinaisons pour vous donner plus d’informations sur votre processus.