Conception de personnalisation évolutive : modèles de conceptions de transaction
Notes
Il s’agit de la quatrième d’une série de rubriques concernant la conception de personnalisation évolutive. Pour commencer dès le début, voir Conception de personnalisation évolutive dans Microsoft Dataverse.
Cette section décrit les modèles de conceptions à éviter ou à limiter et leurs implications. Chaque modèle de conception doit être soigneusement étudié dans le contexte d’un problème commercial à résoudre et peut être utile en guise d’options à prendre en compte.
N’hésitez pas à utiliser le verrouillage
Le verrouillage est un composant très important de SQL Server et de Dataverse, et est essentiel pour le fonctionnement sain et la cohérence du système. C’est la raison pour laquelle il est important que vous compreniez ses implications sur la conception, en particulier à l’échelle.
Utilisation des transactions : indicateur nolock
L’une des fonctionnalités de la plateforme Dataverse considérablement utilisée par les vues consiste à spécifier qu’une requête peut être exécutée avec un indicateur nolock, spécifiant à la base de données qu’aucun verrouillage n’est nécessaire pour cette requête.
Les vues utilisent cette approche, car il n’existe aucun lien direct entre l’acte de lancement de la vue et les actions consécutives. Un certain nombre d’autres activités peuvent être exécutées par cet utilisateur ou d’autres entre-temps, et il n’est ni pratique, ni utile de verrouiller l’ensemble de la table de données affichée par la vue en attendant que l’utilisateur passe à autre chose.
Comme une requête au sein d’un jeu de données volumineux signifie qu’elle affecte potentiellement d’autres utilisateurs essayant d’interagir avec l’une de ces données, pouvoir spécifier qu’aucun verrouillage n’est requis peut avoir un avantage important sur l’évolutivité du système.
Lors d’une requête de la plateforme dans tout le kit de développement logiciel, il peut être utile d’indiquer que le nolock peut être utilisé. Celui-ci indique que vous reconnaissez que cette requête n’a pas besoin d’un verrouillage de la lecture dans la base de données. Cela est particulièrement utile pour les requêtes où :
- Il existe une large étendue de données
- Des ressources hautement contestées sont interrogées
- La sérialisation n’est pas importante
L’indicateur nolock ne doit pas être utilisé si une action ultérieure dépend d’aucune modification des résultats, comme dans l’exemple de verrouillage de numérotation automatique précédent.
Un exemple de scénario où il peut être utile consiste à déterminer si un courrier électronique est associé à un incident existant. Le blocage d’autres utilisateurs pour les empêcher de créer des incidents afin de s’assurer qu’il n’y ait aucun risque d’incident généré auquel le courrier électronique puisse se lier ne serait pas un niveau de contrôle de cohérence bénéfique.
Au lieu de cela, effectuer un effort logique pour interroger des incidents associés et joindre le courrier électronique à un incident existant ou en créer un, tout en autorisant la génération d’autres incidents, est plus approprié. Plus spécifiquement, comme il n’y a pas de lien inhérent dans la chronologie entre ces deux actions, le courrier électronique pourrait facilement avoir été remis quelques secondes avant et aucun lien n’aurait été détecté.
Le fait que les indicateurs nolock soient valides ou non pour un scénario spécifique est généralement basé sur l’appréciation de la probabilité et de l’impact de conflits, et l’implication commerciale de ne pas garantir la cohérence des actions entre une action de récupération et les actions consécutives. Si éviter le verrouillage n’a aucun impact commercial, l’utilisation de nolocks serait un choix d’optimisation utile. En cas d’impact commercial potentiel, la conséquence peut être comparée aux avantages en termes de performances et d’évolutivité si vous évitez d’utiliser un verrouillage.
Prise en compte de l’ordre des verrouillages
Une autre méthode utile pour réduire l’impact du blocage, et en particulier en évitant un interblocage, consiste à adopter une approche cohérente de l’ordre des verrouillages au cours d’une mise en œuvre.
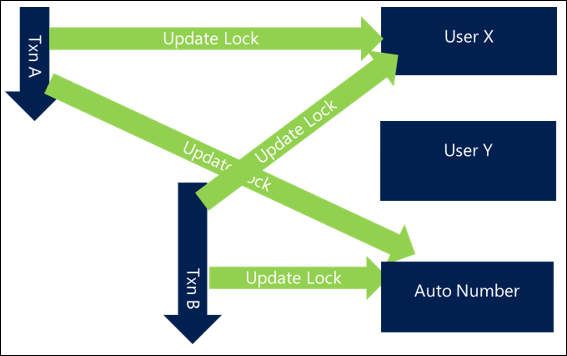
Un exemple simple et classique consiste à mettre à jour ou à interagir avec des groupes d’utilisateurs. Si vous avez des requêtes qui mettent à jour des utilisateurs associés (par exemple en ajoutant des membres à des équipes ou à mettre à jour tous les participants dans une activité), ne pas spécifier d’ordre peut signifier que si deux activités concurrentes essaient de mettre à jour les mêmes utilisateurs, vous pouvez vous retrouver avec le comportement suivant, qui aboutit à un interblocage :
- La transaction A essaie de mettre à jour l’utilisateur X puis l’utilisateur Y
- La transaction B essaie de mettre à jour l’utilisateur Y puis l’utilisateur X
Étant donné que les deux requêtes commencent ensemble, la transaction A peut obtenir un verrouillage de l’utilisateur X et la transaction B peut obtenir un verrouillage de l’utilisateur Y, mais dès que chacun d’eux essaie d’obtenir un verrouillage sur l’autre utilisateur ils se bloquent puis aboutissent à un interblocage.
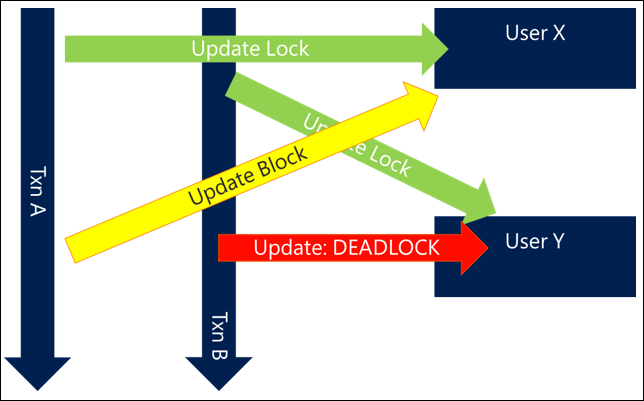
En ordonnant simplement les ressources auxquelles vous accédez de manière cohérente, vous pouvez éviter plusieurs interblocages. Le mécanisme d’ordonnancement n’est généralement pas important tant qu’il est cohérent et peut s’effectuer aussi efficacement possible. Par exemple, classer dans l’ordre les utilisateurs par nom ou même par GUID peut au moins garantir un niveau de cohérence qui évite les interblocages.
Dans un scénario utilisant cette approche, la transaction A reçoit l’utilisateur X, mais la transaction B essaye également maintenant d’accéder à l’utilisateur X plutôt qu’à l’utilisateur Y en premier. Même si cela signifie que la transaction B se bloque jusqu’à la fin de la transaction A, ce scénario permet d’éviter l’interblocage et se termine avec succès.
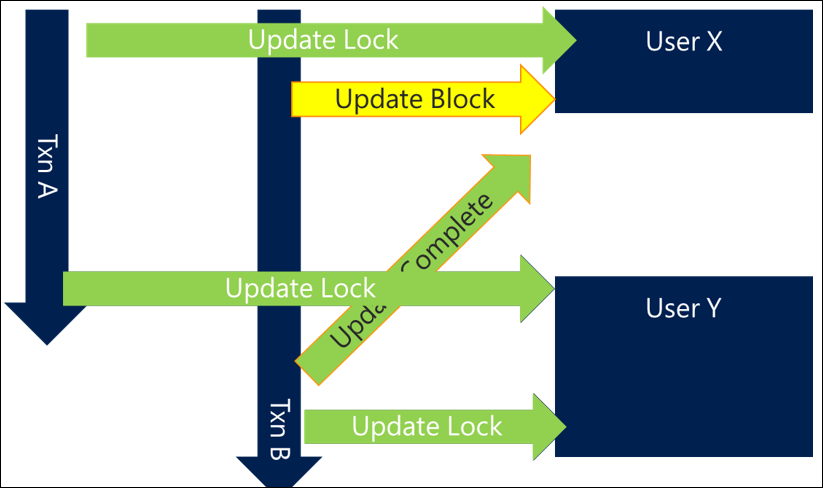
Dans les scénarios plus complexes et plus efficaces, il se peut que vous verrouilliez d’abord des utilisateurs moins fréquemment référencés et les utilisateurs plus fréquemment référencés en dernier, ce qui entraîne le modèle de conception suivant.
Maintenir des verrouillages controversés pendant la période la plus courte
Dans certains scénarios, tels que l’approche de numérotation automatique, où il est inévitable qu’il existe une ressource fortement contestée qui doit être verrouillée. Dans ce cas, le problème de blocage ne peut pas être entièrement évité, mais peut être limité.
Lorsque vous avez des ressources fortement contestées, une bonne conception consiste à ne pas inclure l’interaction avec cette ressource au point logique au niveau fonctionnel du processus, mais à déplacer l’interaction avec elle aussi près de la fin de la transaction que possible.
Avec cette approche, même s’il y a toujours un blocage sur cette ressource, elle permet de réduire le temps de verrouillage de la ressource, et par conséquent diminue la probabilité et la durée pendant laquelle les autres demandes sont bloquées en attendant la ressource.
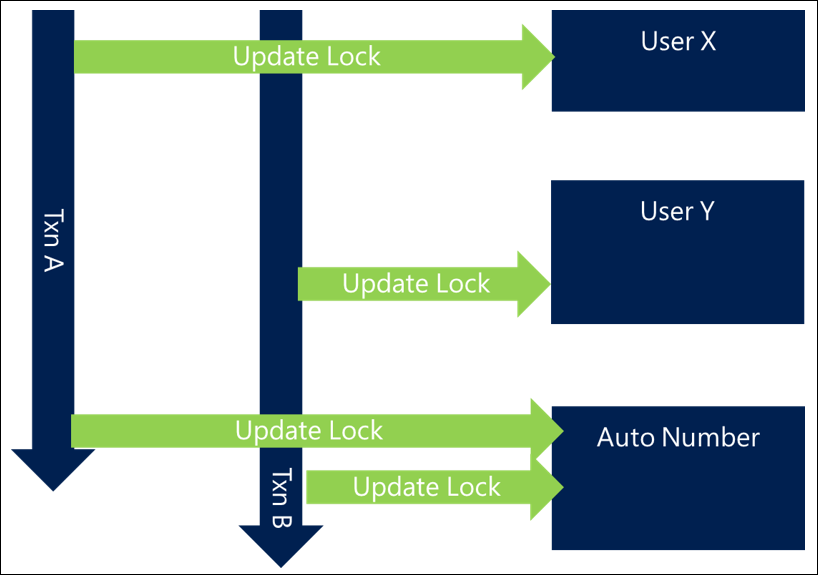
Réduction de la durée des transactions
D’une façon similaire, un verrouillage devient uniquement un problème de blocage si deux processus doivent accéder à la même ressource en même temps. Plus la transaction qui maintient un verrouillage est courte, moins il est probable que deux processus, même s’ils accèdent à la même ressource, en auront besoin exactement au même moment et provoqueront une collision. Plus la durée de conservation des transactions est courte, moins il est probable que le blocage deviendra un problème.
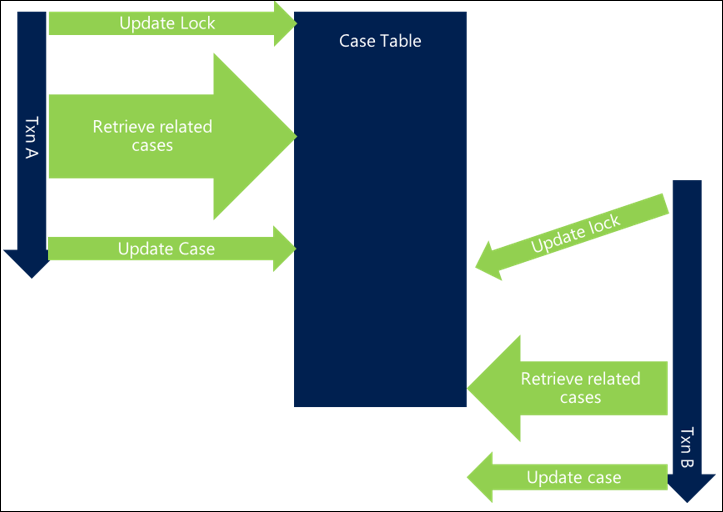
Dans l’exemple suivant, les mêmes verrouillages sont utilisés mais d’autres s’exécutent dans la transaction, ce qui signifie que la durée globale de la transaction est prolongée, ce qui entraîne un chevauchement des demandes des mêmes ressources. Cela signifie qu’un blocage se produit et que chaque demande est plus lente dans l’ensemble.
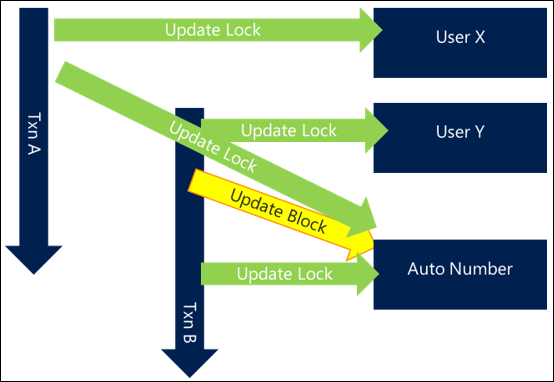
En raccourcissant la durée globale de la transaction, la première transaction se termine et publie ses verrouillages avant même que le deuxième demande commence, ce qui signifie qu’il ne se produit aucun blocage et que les deux transactions se terminent efficacement.
D’autres activités dans une demande qui prolongent la durée d’une transaction peuvent augmenter la possibilité de blocage, en particulier lorsqu’il existe plusieurs demandes se chevauchant, et peuvent conduire à un système sensiblement plus lent.
Il existe un certain nombre de façons de réduire la durée de la transaction.
Optimisation des demandes
Chaque transaction consiste en une série de demandes de base de données. Si chaque demande est effectuée aussi efficacement que possible, cela réduit la durée globale d’une transaction et les risques de collision.
Vérifiez chaque requête que vous effectuez pour déterminer si :
Votre requête demande uniquement ce dont elle a besoin, par exemple, des colonnes, des enregistrement, ou des types d’entités.
- Cela augmente le risque qu’un index puisse être utilisé pour traiter efficacement la requête
- Cela réduit le nombre de tables et de ressources auxquelles accéder, ce qui réduit la surcharge d’autres ressources dans le serveur de base de données et la durée de la requête
- Cela permet d’éviter un blocage potentiel sur les ressources dont vous n’avez pas besoin, en particulier si une jonction à une autre table est demandée mais pourrait être évitée ou est inutile
Un index est en place pour aider la requête, vous interrogez de manière efficace, et une recherche d’index plutôt qu’un balayage a lieu
Il est important de noter que l’introduction d’un index n’évite pas le verrouiller lors de la création/mise à jour d’enregistrements dans la table sous-jacente. Les entrées dans les index sont également verrouillées lorsque l’enregistrement associé est mis à jour alors que l’index lui-même fait l’objet de modifications. L’existence d’index ne permet pas d’éviter ce problème complètement.
Dans l’exemple suivant, la récupération d’incidents associés n’est pas optimisée et s’ajoute à la durée globale de la transaction, introduisant ainsi des blocages entre les threads.
En optimisant la requête, l’exécution de celle-ci est moins longue, et le risque de collision est réduit, ce qui minimise les blocages.
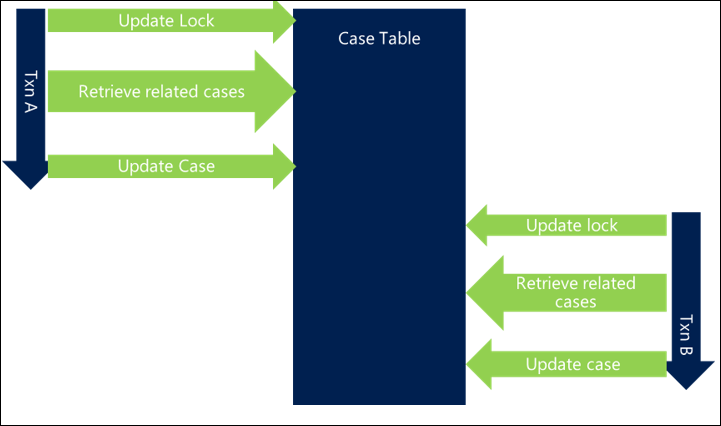
S’assurer que le serveur de base de données peut traiter votre requête aussi efficacement que possible peut considérablement diminuer la durée globale de vos transactions et réduire le risque de blocage.
Réduire la chaîne d’événements
Comme indiqué dans les exemples précédents, les conséquences de longues chaînes d’événements connexes peuvent avoir un impact matériel sur la durée globale de la transaction et par conséquent entraîner un risque de blocage. Ceci est particulièrement le cas lors du déclenchement de plug-ins et de workflows synchrones, qui déclenchent ensuite d’autres actions, qui à leur tour déclenchent d’autres plug-ins et workflows synchrones.
Examiner et concevoir soigneusement une mise en œuvre permettant d’éviter de longues chaînes d’événements se produisant de manière synchrone peut être salutaire pour réduire la durée globale d’une transaction. Cela permet à tous les verrouillages utilisés d’être libérés plus rapidement et de réduire le risque de blocage.
Cela permet aussi de limiter les risques que des verrouillages secondaires se transforment en problème majeur. Dans l’exemple de numérotation automatique lors de la création d’un compte, l’enjeu majeur est initialement d’accéder à la table de numérotation automatique, mais lorsque de nombreuses actions sont effectuées en une séquence, un blocage secondaire, tels que les mises à jour d’un enregistrement d’utilisateur associé, peut également se présenter. Une fois les nombreuses ressources contestées impliquées, il devient encore plus difficile d’empêcher les blocages.
Tenir compte du fait que certaines activités doivent être synchrones ou asynchrones peut signifier que les mêmes activités sont exécutées mais ont un impact initial moindre. Plus spécifiquement pour les actions plus longues à s’exécuter ou celles dépendant des ressources considérablement contestées, les séparer de la transaction principale en les effectuant dans une action asynchrone peuvent avoir des bénéfices importants. Cette approche ne fonctionne pas si l’action doit s’exécuter ou échouer avec l’étape de plateforme plus large, par exemple comme la mise à jour d’un rapport de police avec la prochaine valeur de numéro automatique garantissant un schéma de numéros séquentiel et continu est maintenue. Dans ces scénarios d’autres méthodes pour réduire l’impact doivent être adoptées.
Comme dans l’exemple suivant, simplement en déplaçant certaines actions dans un processus asynchrone, ce qui signifie les actions sont migrées en dehors de la plateforme de transaction, peut signifier que la durée de la transaction est abréviation et le potentiel de augmente traitantes simultanément.
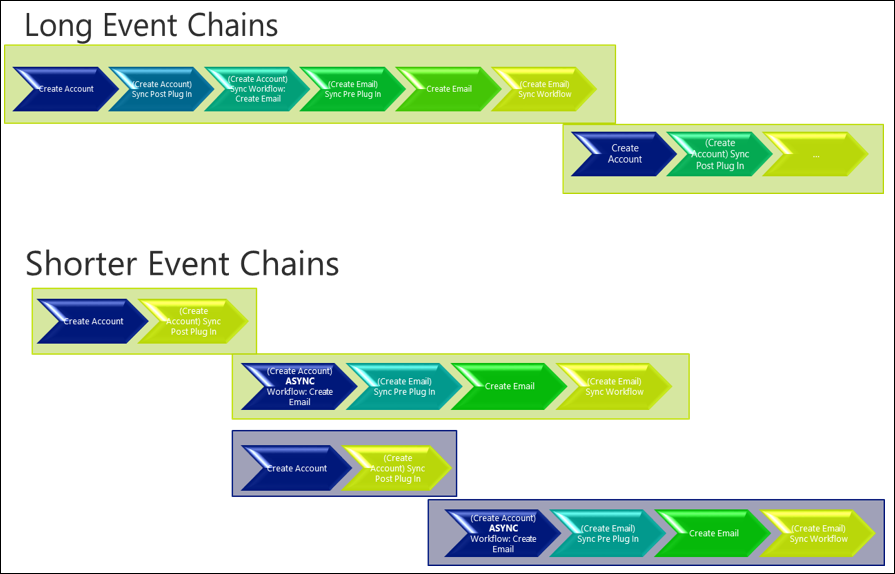
Éviter plusieurs mises à jour du même enregistrement
Lors de la conception de plusieurs couches d’activité fonctionnelle, bien qu’il soit recommandé de décomposer les actions nécessaires en flux d’activité logiques et facilement suivis, dans de nombreux cas cela entraîne plusieurs mises à jour distinctes du même enregistrement.
Dans le scénario de gestion d’incident, la mise à jour d’abord d’un incident avec un propriétaire par défaut en fonction du client pour lequel il est créé, puis de faire envoyer automatiquement ultérieurement par un processus distinct des communications à ce client et enfin mettre à jour la dernière date de contact concernant l’incident est une chose parfaitement logique à faire d’un point de vue fonctionnel.
Toutefois, cela signifie qu’il existe plusieurs demandes à Dataverse pour les applications de mettre à jour le même enregistrement, ce qui comporte un certain nombre d’implications :
- Chaque demande est une mise à jour de plateforme distincte, ajoutant une charge globale au serveur Dataverse et prolongeant la durée globale de la transaction, ce qui augmente la risque de blocage.
- Cela signifie que l’enregistrement d’incident est verrouillée par la première action effectuée sur cet incident, autrement dit que le verrouillage est maintenu tout au long de la transaction. Si plusieurs processus parallèles accèdent à l’incident, cela peut provoquer le blocage d’autres activités.
La consolidation des mises à jour du même enregistrement en une seule étape de mise à jour, puis dans la transaction, peut être un avantage significatif à l’évolutivité générale, en particulier si l’enregistrement est fortement contesté ou que plusieurs personnes y accèdent rapidement après sa création, par exemple, comme avec un incident.
La décision relative à la consolidation des mises à jour avec le même enregistrement en un seul processus serait basé sur l’équilibrage de la complexité de la mise en service avec le potentiel de conflit que des mises à jour distinctes seraient susceptibles d’entraîner. Mais pour les systèmes à volumes élevés, cela peut être salutaire pour les ressources fortement contestées.
Mettez à jour uniquement les éléments nécessaires
Bien qu’il soit important de ne pas réduire l’avantage d’un système Dataverse en excluant des activités salutaires, les demandes sont souvent effectuées pour inclure des personnalisations qui ajoutent peu de valeur commerciale mais entraînent une complexité technique réelle.
Si chaque fois que nous créons une tâche nous mettons également l’enregistrement utilisateur à jour avec le nombre de tâches qui lui sont actuellement allouées, cela pourrait entraîner un niveau secondaire de blocage, car l’enregistrement utilisateur serait désormais également fortement contesté. Cela ajouterait une autre ressource que chaque demande pourrait avoir besoin de bloquer et d’attendre, même si elle n’est pas nécessairement essentielle à l’action. Dans cet exemple, examinez soigneusement si le stockage du nombre de tâches de l’utilisateur est important ou si le nombre peut être calculé à la demande ou stocké ailleurs par exemple à l’aide de fonctionnalités de hiérarchie et de champ cumulatif dans Dataverse en mode natif.
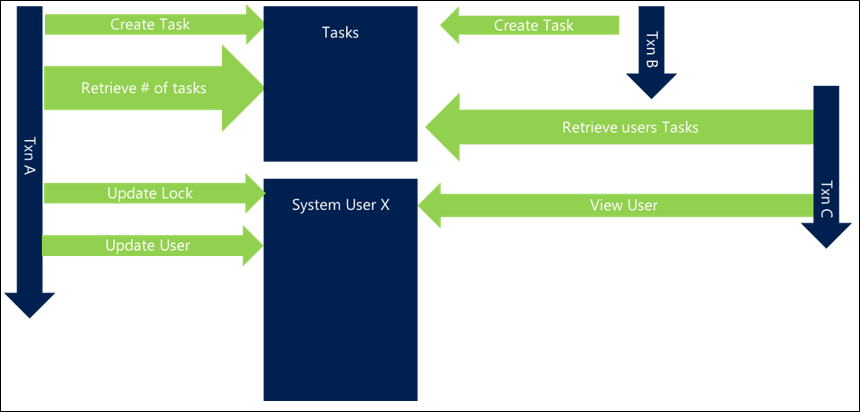
Comme nous le verrons plus tard, la mise à jour d’enregistrements utilisateur système peut avoir des conséquences négatives du point de vue de l’évolutivité.
Plusieurs personnalisations déclenchées sur le même événement
Le déclenchement de plusieurs actions sur le même événement peut entraîner un risque plus grande de collision, car de par la nature des demandes, ces actions sont susceptibles d’interagir avec les mêmes objets associés ou l’objet parent.
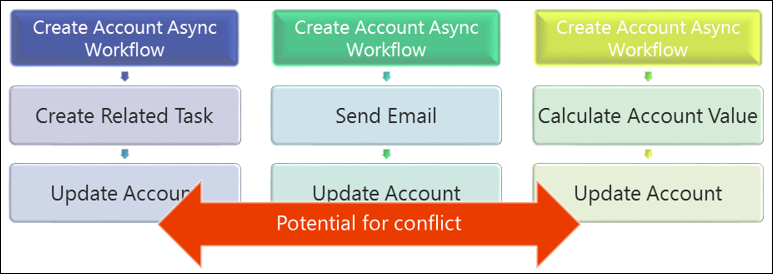
Il s’agit d’un modèle qui doit être soigneusement pris en compte ou évité, car il est très facile de survoler les conflits, en particulier lorsque différentes personnes mettent en œuvre les différents processus.
Quand utiliser différents types de personnalisations
Chaque type de personnalisation a différentes implications dans son utilisation. Le tableau suivant met en évidence certains critères courants, à quel moment chacun doit être envisagé et utilisé, et à quel moment il n’est pas approprié de les utiliser.
Souvent un compromis entre différents comportements peut devoir être envisagé afin d’offrir des recommandations sur certaines des fonctionnalités et certains des scénarios usuels à prendre en compte mais chaque scénario doit être évalué et l’approche adéquate choisie selon tous les facteurs appropriés.
| Phase de pré/post-transition | Synchrone/asynchrone | Type de personnalisation | Situations d’utilisation de | Quand ne pas utiliser |
|---|---|---|---|---|
| Validation préalable | Synchrone | Plug-in | Validation à court terme des valeurs d’entrée | Actions longues. Lorsque vous créez des éléments associés devant être annulés si des étapes ultérieures échouent. |
| Opération préalable | Synchrone | Plug-in/workflow | Validation à court terme des valeurs d’entrée. Lorsque vous créez des éléments associés devant être annulés dans le cadre d’un échec d’étape de plateforme. |
Actions longues. Lorsque vous créez un élément et que le GUID qui en résulte doit être stocké selon l’élément que l’étape de plateforme doit créer/mettre à jour. |
| Opération postérieure | Synchrone | Plug-in/workflow | Actions courtes qui suivent naturellement l’étape de plateforme et doivent être annulées si les étapes ultérieures échouent, par exemple, la création d’une tâche pour le propriétaire d’un compte nouvellement créé. Création d’éléments associés qui nécessitent le GUID de l’élément créé et doivent annuler l’étape de plateforme en cas d’échec |
Actions longues. Dans le cas où l’échec ne doit pas affecter la fin de l’étape de pipeline de plateforme. |
| Pas dans le pipeline d’événements | Asynchrone | Plug-in/workflow | Actions moyennes susceptibles d’avoir des répercussions sur l’expérience utilisateur. Actions qui ne peuvent être annulées malgré tout en cas d’échec. Actions qui ne doivent pas forcer la restauration de l’étape de plateforme en cas d’échec. |
Actions très longues. Ces dernières ne doivent pas être gérées dans Dataverse. Actions à coût faible. La surcharge de la génération d’un comportement asynchrone pour les actions à coût très faible peut être prohibitive ; si possible, exécutez celles-ci de manière synchrone et évitez la surcharge du traitement asynchrone. |
| S.O. Prend le contexte de là où il est appelé |
Personnaliser les actions | Combinaisons d’actions lancées depuis une source externe, par exemple, depuis une ressource web | Quand elles sont toujours déclenchées en réponse à un événement de plateforme, utilisez le plug-in/workflow dans ces cas. |
Les plug-ins/workflows ne sont pas des mécanismes de traitement par lots
Les actions longues ou volumineuses ne sont pas destinées à être exécutées à partir de plug-ins ou de workflows. Dataverse n’est pas conçu pour être une plateforme de calcul et , en particulier, il n’est pas conçu comme contrôleur de groupes volumineux de mises à jour non liées.
Si vous avez un besoin de le faire, déchargez et exécutez à partir d’un service distinct, tel qu’un rôle de travail Azure.
Paramétrage de la sécurité
L’évolutivité du paramétrage de la sécurité est une zone d’escalade habituelle. Il s’agit d’une opération coûteuse, aussi lorsqu’elle est exécutée en volume, cela peut entraîner des défis si vous ne la comprenez pas bien, ni l’envisagez soigneusement.
Paramétrage d’équipe
- Ajoutez toujours des utilisateurs dans le même ordre : évitez les interblocages
- Mettez à jour uniquement les utilisateurs s’ils doivent être mis à jour : évitez d’invalider les caches des utilisateurs inutilement
Propriétaire et Équipes d’accès
- Si les équipes des utilisateurs changent régulièrement, faites attention à l’utilisation excessive des équipes de propriétaires ; chaque fois qu’elles changent, elles invalident le cache de l’utilisateur dans le serveur web
- Idéalement, apportez des modifications lorsque l’utilisateur ne travaille pas, réduisez l’impact, par exemple pendant la nuit
Nombreuses appartenances à une équipe/divisions
- Examinez soigneusement les scénarios comprenant un grand nombre d’ajouts d’équipes/divisions à la complexité de calcul
Comportement en cascade
- Envisagez le partage en cascade, par exemple, pour l’attribution
Mise à jour soigneuse des enregistrements utilisateur
- Ne mettez pas régulièrement à jour les enregistrements utilisateur système, à moins qu’un élément fondamental ait changé, car cela force le rechargement du cache et un nouveau calcul des privilèges de sécurité, une activité chère
- N’utilisez pas l’utilisateur système pour enregistrer le nombre d’activités ouvertes que l’utilisateur possède, par exemple
Diagramme des actions associées
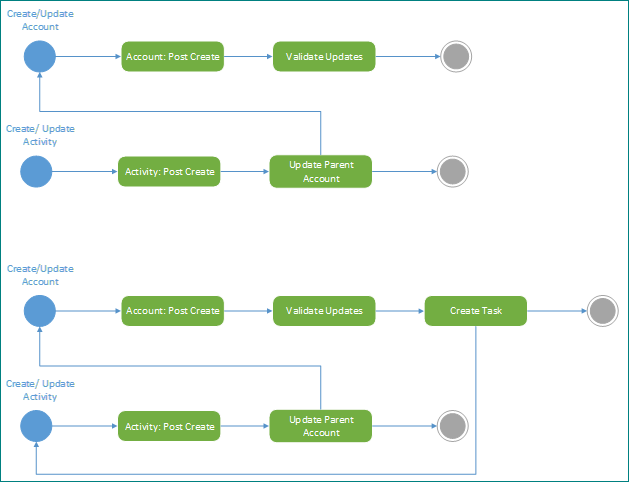
Une activité très salutaire comme mesure préventive, ainsi qu’un outil nécessaire pour diagnostiquer des problèmes de blocage, consiste à créer un diagramme des actions associées déclenchées dans la plateforme Dataverse. Lorsque vous procédez ainsi, cela permet de mettre en surbrillance les dépendances intentionnelles et involontaires et les déclencheurs dans le système. Si vous ne pouvez pas effectuer cela pour votre solution, vous ne disposerez peut-être pas d’une idée claire de ce que votre implémentation entraîne réellement. Créer un tel diagramme risque d’exposer des conséquences involontaires et est recommandé à tout moment dans une mise en œuvre.
L’exemple suivant met en évidence comment deux processus fonctionnent initialement parfaitement ensemble mais lors d’une maintenance en cours, l’ajout d’une nouvelle étape pour créer une tâche peut entraîner une boucle involontaire. L’utilisation de cette documentation technique peut mettre cela en surbrillance à la phase de conception et éviter que cela affecte le système.
Examiner la télémétrie et les traces
Vous pouvez mettre en place un environnement Application Insights pour recevoir la télémétrie sur les diagnostics et les performances capturés par la plateforme Dataverse. Découvrez comment analyser la télémétrie de Dataverse avec Application Insights
Une fois que vous avez un environnement Application Insights, vous pouvez utiliser l’interface Microsoft.Xrm.Sdk.PluginTelemetry.ILogger dans votre code de plug-in pour écrire la télémétrie dans Application Insights. Découvrez comment écrire la télémétrie dans votre ressource Application Insights en utilisant ILogger
Lorsque certaines erreurs se produisent, l’utilisation des fichiers de trace de serveur pour comprendre où des problèmes associés peuvent se produire dans la plateforme peut être utile. Pour plus d’informations, voir : Utiliser le suivi
Synthèse
Le contenu de Conception de personnalisation évolutive dans Dataverse et les articles suivants Transactions de base de données, Problèmes de concurrence et celui-ci ont décrit les concepts suivants avec des exemples et des stratégies qui vous aideront à comprendre comment concevoir et mettre en œuvre des personnalisations évolutives pour Dataverse.
Certaines notions clés à vous souvenir comprennent ce qui suit :
Verrouillages/transactions
- Les verrouillages et les transactions sont essentiels à un système sain
- Mais lorsqu’ils sont utilisés de manière incorrecte, cela peut entraîner des problèmes
Contraintes de plateforme
- Les contraintes de plateforme se présentent souvent sous la forme d’erreurs
- Mais la contrainte est rarement à l’origine du problème
- Elle est là pour empêcher la plateforme et d’autres activités d’être affectées
Conception pour l’utilisation de transaction
- Si des mises en œuvre sont conçues en tenant compte du comportement de transaction, cela peut aboutir à une évolutivité plus importante et à des performances utilisateur supérieures
Notes
Pouvez-vous nous indiquer vos préférences de langue pour la documentation ? Répondez à un court questionnaire. (veuillez noter que ce questionnaire est en anglais)
Le questionnaire vous prendra environ sept minutes. Aucune donnée personnelle n’est collectée (déclaration de confidentialité).