Stream messages du bot
Remarque
- Les messages de bot en streaming sont disponibles uniquement pour les conversations individuelles et dans la préversion publique pour les développeurs.
- Les messages de bot en streaming ne sont pas disponibles avec l’appel de fonction et le modèle OpenAI
o1. - La diffusion en continu de messages de bot est prise en charge sur le web, le bureau et les appareils mobiles (Android). Il n’est pas pris en charge sur iOS.
Vous pouvez diffuser en continu des messages de bot pour fournir les réponses d’un bot à l’utilisateur sous forme de petites mises à jour pendant que la réponse complète est générée pour améliorer l’expérience utilisateur. Souvent, les bots mettent beaucoup de temps à générer des réponses sans mettre à jour l’interface utilisateur, ce qui entraîne une expérience moins attrayante.
Lorsque les utilisateurs observent que le bot traite leur demande en temps réel, cela peut augmenter leur satisfaction et leur confiance. Cette réactivité et cette transparence perçues améliorent l’engagement des utilisateurs et réduisent l’abandon des conversations avec le bot.
Les messages de bot en streaming ont deux types de mises à jour :
Mises à jour informatives : les mises à jour informatives s’affichent sous la forme d’une barre de progression bleue au bas de la conversation. Il informe l’utilisateur des actions en cours du bot pendant la génération d’une réponse.

Diffusion en continu de la réponse : la diffusion en continu des réponses s’affiche sous la forme d’un indicateur de saisie. Il révèle la réponse du bot à l’utilisateur sous forme de petites mises à jour pendant la génération de la réponse complète.

Vous pouvez implémenter des messages de bot en streaming dans votre application de l’une des manières suivantes :
Stream message via la bibliothèque IA Teams
La bibliothèque IA Teams offre la possibilité de diffuser en continu des messages pour les bots basés sur l’IA. La diffusion en continu des messages du bot permet de réduire le délai de réponse, tandis que le modèle LLM (Large Language Model) génère la réponse complète. Les principaux facteurs qui contribuent au temps de réponse lent incluent plusieurs étapes de prétraitement, telles que les appels de Retrieval-Augmented génération (RAG) ou de fonction, et le temps nécessaire par le LLM pour générer une réponse complète.
Remarque
Les messages de bot en streaming ne sont pas disponibles avec l’appel de fonction.
Grâce à la diffusion en continu, votre bot alimenté par l’IA peut offrir une expérience attrayante et réactive pour l’utilisateur. Configurez les fonctionnalités suivantes pour la diffusion en continu de messages pour votre application basée sur l’IA :
Activer la diffusion en continu pour le bot basé sur l’IA :
Les messages de bot peuvent être diffusés en continu via le KIT de développement logiciel (SDK) IA. Le bot basé sur l’IA envoie des segments à l’utilisateur lorsque le modèle génère la réponse. Texte de prise en charge des messages de diffusion en continu. Toutefois, la pièce jointe, l’étiquette IA, la boucle de commentaires et les étiquettes de confidentialité sont disponibles uniquement pour le message de diffusion en continu final.
Définir le message informatif :
Vous pouvez définir un message informatif pour votre bot alimenté par l’IA. Ce message s’affiche pour l’utilisateur chaque fois que le bot envoie une mise à jour. Voici quelques exemples de messages informatifs que vous pouvez définir dans votre application :
- Analyse des documents
- Résumé du contenu
- Recherche d’éléments de travail pertinents
L’exemple suivant montre les mises à jour des informations dans un bot alimenté par l’IA :
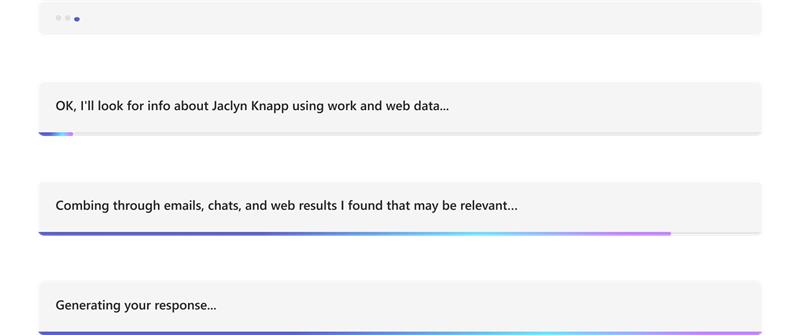
Mettez en forme le message diffusé en continu final :
À l’aide du SDK AI, les messages texte et markdown simples peuvent être mis en forme pendant qu’ils sont diffusés en continu. Toutefois, pour les cartes adaptatives, les images ou le code HTML enrichi, la mise en forme peut être appliquée une fois le message final terminé. Le bot peut envoyer des pièces jointes uniquement dans le bloc final diffusé en continu.
L’exemple suivant montre la réponse de streaming dans un bot alimenté par l’IA :

L’exemple suivant montre la réponse finale diffusée en continu dans un bot alimenté par IA :

Activez les fonctionnalités basées sur l’IA pour le message final :
Vous pouvez activer les fonctionnalités basées sur l’IA suivantes pour le message final envoyé par le bot :
- Citations : la bibliothèque IA Teams inclut automatiquement des citations dans les réponses du bot. Il fournit des références pour les sources utilisées par le bot pour générer la réponse. Il permet aux utilisateurs de faire référence à la source par le biais de citations et de références dans le texte.
- Étiquette de confidentialité : utilisez l’étiquette de confidentialité pour aider les utilisateurs à comprendre la confidentialité d’un message.
- Boucle de commentaires : cela permet aux utilisateurs de fournir des commentaires positifs ou négatifs sur les messages du bot.
- Généré par l’IA : la bibliothèque IA Teams inclut automatiquement une étiquette Generated by AI dans les réponses du bot. Cette étiquette permet aux utilisateurs d’identifier qu’un message a été généré à l’aide de l’IA.
Pour plus d’informations sur la mise en forme des messages de bot optimisés par l’IA, consultez Messages de bot avec du contenu généré par l’IA.
Configurer des messages de bot en streaming
Pour configurer les messages de bot en streaming, procédez comme suit :
Activer la diffusion en continu pour le bot basé sur l’IA :
a. Utilisez la
DefaultAugmentationclasse dans leconfig.jsonfichier et dans l’une des classes d’application main suivantes de votre application bot :- Pour une application de bot C# : mettez à jour
Program.cs. - Pour une application JavaScript : mettez à jour
index.ts. - Pour une application Python : mettez à jour
bot.py.
b. Définissez sur
streamtrue dans laOpenAIModeldéclaration.- Pour une application de bot C# : mettez à jour
Définir le message informatif : spécifiez le message informatif dans la déclaration à l’aide
ActionPlannerde laStartStreamingMessageconfiguration.Mettez en forme le message diffusé en continu final :
- Définissez le bouton bascule de boucle de commentaires dans l’objet
AIOptionsdans la déclaration de l’application et spécifiez un gestionnaire.- Pour une application bot créée à l’aide de Python, définissez le bouton bascule de boucle de commentaires dans l’objet
ActionPlannerOptionsen plus de l’objetAIOptions.
- Pour une application bot créée à l’aide de Python, définissez le bouton bascule de boucle de commentaires dans l’objet
- Définissez les pièces jointes dans le bloc final à l’aide de dans
EndStreamHandlerlaActionPlannerdéclaration.
- Définissez le bouton bascule de boucle de commentaires dans l’objet
L’extrait de code suivant montre un exemple de messages de bot en streaming :
// Create OpenAI Model
builder.Services.AddSingleton<OpenAIModel > (sp => new(
new OpenAIModelOptions(config.OpenAI.ApiKey, "gpt-4o")
{
LogRequests = true,
Stream = true, // Set stream toggle
},
sp.GetService<ILoggerFactory>()
));
ResponseReceivedHandler endStreamHandler = new((object sender, ResponseReceivedEventArgs args) =>
{
StreamingResponse? streamer = args.Streamer;
if (streamer == null)
{
return;
}
AdaptiveCard adaptiveCard = new("1.6")
{
Body = [new AdaptiveTextBlock(streamer.Message) { Wrap = true }]
};
var adaptiveCardAttachment = new Attachment()
{
ContentType = "application/vnd.microsoft.card.adaptive",
Content = adaptiveCard,
};
streamer.Attachments = [adaptiveCardAttachment]; // Set attachments
});
// Create ActionPlanner
ActionPlanner<TurnState> planner = new(
options: new(
model: sp.GetService<OpenAIModel>()!,
prompts: prompts,
defaultPrompt: async (context, state, planner) =>
{
PromptTemplate template = prompts.GetPrompt("Chat");
return await Task.FromResult(template);
}
)
{
LogRepairs = true,
StartStreamingMessage = "Loading stream results...", // Set informative message
EndStreamHandler = endStreamHandler // Set final chunk handler
},
loggerFactory: loggerFactory
);
Développement de modèles et de Planificateur personnalisés
La StreamingResponse classe est la classe d’assistance pour la diffusion en continu des réponses au client. Il vous permet d’envoyer une série de mises à jour en une seule réponse, ce qui rend l’interaction plus fluide. Si vous utilisez votre propre modèle personnalisé, vous pouvez facilement utiliser cette classe pour diffuser en continu les réponses en continu. Il s’agit d’un excellent moyen de maintenir l’engagement de l’utilisateur.
Les messages de bot en streaming doivent utiliser la séquence suivante :
queueInformativeUpdate()queueTextChunk()endStream()
Une fois que votre modèle a appelé endStream(), le flux se termine et le bot ne peut plus envoyer d’autres mises à jour.
Voici une liste d’autres méthodes que vous pouvez utiliser pour personnaliser l’expérience de l’application :
setAttachmentssetSensitivityLabelsetFeedbackLoopsetGeneratedByAILabel
Limitations pour Azure OpenAI ou OpenAI
- Lorsque votre bot appelle l’API de streaming trop rapidement, cela peut entraîner des problèmes et interrompre l’expérience de diffusion en continu. Pour éviter cela, diffusez un message à la fois à un rythme cohérent. Si ce n’est pas le cas, la demande peut être limitée. Mettre en mémoire tampon les jetons du modèle pendant 1,5 à 2 secondes pour garantir une diffusion fluide.
- Les fonctionnalités basées sur l’IA, telles que les citations, l’étiquette de confidentialité, la boucle de commentaires et l’étiquette Générée par l’IA , sont prises en charge uniquement dans le segment final. Les citations sont définies pour chaque bloc de texte mis en file d’attente.
- Seul le texte enrichi peut être diffusé en continu.
- Vous ne pouvez définir qu’un seul message informatif. Votre bot réutilise ce message pour chaque mise à jour. Les exemples incluent :
- Analyse des documents
- Résumé du contenu
- Recherche d’éléments de travail pertinents
- Le modèle restitue le message informatif uniquement au début de chaque message retourné par le LLM.
- Les pièces jointes peuvent être envoyées uniquement dans le bloc final.
- Le streaming n’est pas encore disponible avec les appels de fonction du SDK IA et le modèle AOAI ou OAI
o1. - Voici les exigences à utiliser
streamSequencepour le KIT DE développement logiciel (SDK) IA :- La séquence doit commencer par le nombre « 1 ».
- Les nombres suivants (sauf final) doivent être un entier monotonique croissant (par exemple, 1-2-3>>).
- Pour le message final,
streamSequencene doit pas être défini.
Stream message via l’API REST
Les messages du bot peuvent être diffusés en continu via l’API REST. Les messages de streaming prennent en charge le texte enrichi et la citation. La pièce jointe, l’étiquette IA, le bouton de commentaires et les étiquettes de confidentialité sont disponibles uniquement pour le message de diffusion en continu final. Pour plus d’informations, consultez pièces jointes et messages de bot avec du contenu généré par l’IA.
Lorsque votre bot appelle le streaming via l’API REST, veillez à appeler l’API de streaming suivante uniquement après avoir reçu une réponse réussie de l’appel d’API initial. Si votre bot utilise le Kit de développement logiciel (SDK), vérifiez que vous recevez un objet de réponse Null de la méthode d’activité d’envoi pour confirmer que l’appel précédent a été correctement transmis.
Lorsque votre bot appelle l’API de streaming trop rapidement, vous pouvez rencontrer des problèmes et l’expérience de diffusion en continu peut être interrompue. Nous vous recommandons que votre bot diffuse un message à la fois pour vous assurer qu’il appelle l’API de streaming à un rythme cohérent. Si ce n’est pas le cas, la demande peut être limitée. Mettre en mémoire tampon les jetons du modèle pendant 1,5 à deux secondes pour garantir un processus de diffusion en continu fluide. Nous vous recommandons que votre bot diffuse un message à la fois pour vous assurer qu’il appelle l’API de streaming à un rythme cohérent. Si ce n’est pas le cas, la demande peut être limitée. Mettre en mémoire tampon les jetons du modèle pendant 1,5 à deux secondes pour garantir un processus de diffusion en continu fluide.
Voici les propriétés de diffusion en continu des messages de bot :
| Propriété | Obligatoire | Description |
|---|---|---|
type |
✔️ | Les valeurs prises en charge sont ou typingmessage.
• typing: à utiliser lors de la diffusion en continu du message.
• message: à utiliser pour le message final diffusé en continu. |
text |
✔️ | Contenu du message qui doit être diffusé en continu. |
entities.type |
✔️ | Doit être streamInfo |
entities.streamId |
✔️ |
streamId à partir de la demande de streaming initiale, démarrez la diffusion en continu. |
entities.streamType |
Type de mises à jour en streaming. Les valeurs prises en charge sont informative, streamingou final. La valeur par défaut est streaming.
final est utilisé uniquement dans le message final. |
|
entities.streamSequence |
✔️ | Entier incrémentiel pour chaque requête. |
Remarque
Voici la configuration requise pour l’utilisation streamSequence des API REST :
- Le premier doit être le numéro « 1 ».
- Les nombres suivants (sauf final) doivent être un entier monotonique croissant (par exemple, 1-2-3>>).
- Pour le message final,
streamSequencene doit pas être défini.
Pour activer la diffusion en continu dans les bots, procédez comme suit :
Démarrer la diffusion en continu
Le bot peut envoyer un message informatif ou un message de diffusion en continu comme communication initiale. La réponse inclut , streamIdce qui est important pour l’exécution des appels suivants.
Votre bot peut envoyer plusieurs mises à jour informatives lors du traitement de la demande de l’utilisateur, telles que l’analyse des documents, le résumé du contenu et les éléments de travail pertinents trouvés. Vous pouvez envoyer ces mises à jour avant que votre bot génère sa réponse finale à l’utilisateur.
//Ex: A bot sends the first request with content & the content is informative loading message.
POST /conversations/<conversationId>/activities HTTP/1.1
{
"type": "typing",
"serviceurl": "https://smba.trafficmanager.net/amer/",
"channelId": "msteams",
"from": {
"id": "<botId>",
"name": "<BotName>"
},
"conversation": {
"conversationType": "personal",
"id": "<conversationId>"
},
"recipient": {
"id": "<recipientId>",
"name": "<recipientName>",
"aadObjectId": "<recipient aad objecID>"
},
"locale": "en-US",
"text": "Searching through documents...", //(required) first informative loading message.
"entities":[
{
"type": "streaminfo",
"streamType": "informative", // informative or streaming; default= streaming.
"streamSequence": 1 // (required) incremental integer; must be present for start and continue streaming request, but must not be set for final streaming request.
}
],
}
201 created { "id": "a-0000l" } // return stream id
L’image suivante est un exemple de démarrage de la diffusion en continu :

Continuer le streaming
Utilisez le streamId que vous avez reçu de la demande initiale pour envoyer des messages informatifs ou de diffusion en continu. Vous pouvez commencer par des mises à jour informatives et basculer ultérieurement vers le streaming de réponse lorsque la réponse finale est prête.
Commencer par des mises à jour informatives
Lorsque votre bot génère une réponse, envoyez des mises à jour informatives à l’utilisateur, telles que l’analyse des documents, le résumé du contenu et les éléments de travail pertinents trouvés. Vérifiez que vous effectuez les appels suivants uniquement une fois que le bot a reçu une réponse correcte des appels précédents.
// Ex: A bot sends the second request with content & the content is informative loading message.
POST /conversations/<conversationId>/activities HTTP/1.1
{
"type": "typing",
" serviceurl": "https://smba.trafficmanager.net/amer/",
"channelId": "msteams",
"from": {
"id": "<botId>",
"name": "<BotName>"
},
"conversation": {
"conversationType": "personal",
"id" : "<conversationId>"
},
"recipient": {
"id": "<recipientId>",
"name": "<recipientName>",
"aadObjectId": "<recipient aad objecID>"
},
"locale": "en -US",
"text ": "Searching through emails...", // (required) second informative loading message.
"entities":[
{
"type": "streaminfo",
"streamId": "a-0000l", // // (required) must be present for any subsequent request after the first chunk.
"streamType": "informative", // informative or streaming; default= streaming.
"streamSequence": 2 // (required) incremental integer; must be present for start and continue streaming request, but must not be set for final streaming request.
}
],
}
202 0K { }
L’image suivante est un exemple de bot fournissant des mises à jour informatives :

Basculer vers le streaming de réponse
Une fois que votre bot est prêt à générer son message final pour l’utilisateur, passez de la fourniture de mises à jour informatives à la diffusion en continu des réponses. Pour chaque mise à jour de diffusion en continu de réponse, le contenu du message doit être la dernière version du message final. Cela signifie que votre bot doit incorporer tous les nouveaux jetons générés par les modèles de langage volumineux (LLM). Ajoutez ces jetons à la version précédente du message, puis envoyez-les à l’utilisateur.
Lorsque le bot distribue une demande de diffusion en continu, assurez-vous que le bot envoie la requête à un débit minimal d’une requête par seconde.
// Ex: A bot sends the third request with content & the content is actual streaming content.
POST /conversations/<conversationId>/activities HTTP/1.1
{
"type": "typing",
" serviceurl" : "https://smba.trafficmanager.net/amer/ ",
"channelId": "msteams",
"from": {
"id": "<botId>",
"name": "<BotName>"
},
"conversation": {
"conversationType": "personal",
"id" : "<conversationId>"
},
"recipient": {
"id" : "<recipientId>",
"name": "<recipientName>",
"aadObjectId": "<recipient aad objecID>"
},
"locale": "en-US" ,
"text ": "A brown fox", // (required) first streaming content.
"entities":[
{
"type": "streaminfo",
"streamId": "a-0000l", // // (required) must be present for any subsequent request after the first chunk.
"streamType": "streaming", // informative or streaming; default= streaming.
"streamSequence": 3 // (required) incremental integer; must be present for start and continue streaming request, but must not be set for final streaming request.
}
],
}
202 0K{ }
// Ex: A bot sends the fourth request with content & the content is actual streaming content.
POST /conversations/<conversationId>/activities HTTP/1.1
{
"type": "typing",
" serviceurl" : "https://smba.trafficmanager.net/amer/ ",
"channelId": "msteams",
"from": {
"id": "<botId>",
"name": "<BotName>"
},
"conversation": {
"conversationType": "personal",
"id" : "<conversationId>"
},
"recipient": {
"id" : "<recipientId>",
"name": "<recipientName>",
"aadObjectId": "<recipient aad objecID>"
},
"locale": "en-US" ,
"text ": "A brown fox jumped over the fence", // (required) first streaming content.
"entities":[
{
"type": "streaminfo",
"streamId": "a-0000l", // // (required) must be present for any subsequent request after the first chunk.
"streamType": "streaming", // informative or streaming; default= streaming.
"streamSequence": 4 // (required) incremental integer; must be present for start and continue streaming request, but must not be set for final streaming request.
}
],
}
202 0K{ }
L’image suivante est un exemple de bot fournissant des mises à jour en blocs :

Diffusion en continu finale
Une fois que votre bot a terminé de générer son message, envoyez le signal de fin de diffusion en continu avec le message final. Pour le message final, le de l’activité type est message. Ici, le bot définit tous les champs autorisés pour l’activité de message standard, mais final est la seule valeur autorisée pour streamType.
// Ex: A bot sends the second request with content && the content is informative loading message.
POST /conversations/<conversationId>/activities HTTP/1.1
{
"type": "message",
" serviceurl" : "https://smba.trafficmanager.net/amer/ ",
"channelId": "msteams",
"from": {
"id": "<botId>",
"name": "<BotName>"
},
"conversation": {
"conversationType": "personal",
"id" : "<conversationId>"
},
"recipient": {
"id" : "recipientId>",
"name": "<recipientName>",
"aadObjectId": "<recipient aad objecID>"
},
"locale": "en-US",
"text ": "A brown fox jumped over the fence.", // (required) first streaming content.
"entities":[
{
"type": "streaminfo",
"streamId": "a-0000l", // // (required) must be present for any subsequent request after the first chunk.
"streamType": "final", // (required) final is only allowed for the last message of the streaming.
}
],
}
202 0K{ }
L’image suivante est un exemple de la réponse finale du bot :

Codes de réponse
Voici les codes de réussite et d’erreur :
Codes de réussite
| Code status HTTP | Valeur renvoyée | Description |
|---|---|---|
201 |
streamId, il s’agit de la même chose que activityId par exemple {"id":"1728640934763"} |
Le bot retourne cette valeur après avoir envoyé la demande de streaming initiale.
Pour toutes les demandes de diffusion en continu suivantes, le streamId est requis. |
202 |
{} |
Code de réussite pour toutes les demandes de streaming suivantes. |
Codes d’erreur
| Code status HTTP | Code d’erreur | Message d’erreur | Description |
|---|---|---|---|
202 |
ContentStreamSequenceOrderPreConditionFailed |
PreCondition failed exception when processing streaming activity. |
Peu de demandes de streaming peuvent arriver hors séquence et être supprimées. La demande de diffusion en continu la plus récente, déterminée par streamSequence, est utilisée lorsque les demandes sont reçues de manière désordonnée. Veillez à envoyer chaque demande de manière séquentielle. |
400 |
BadRequest |
Selon le scénario, vous pouvez rencontrer différents messages d’erreur tels que Start streaming activities should include text |
La charge utile entrante n’adhère pas ou ne contient pas les valeurs nécessaires. |
403 |
ContentStreamNotAllowed |
Content stream is not allowed |
La fonctionnalité d’API de streaming n’est pas autorisée pour l’utilisateur ou le bot. |
403 |
ContentStreamNotAllowed |
Content stream is not allowed on an already completed streamed message |
Un bot ne peut pas diffuser en continu un message qui a déjà été diffusé et terminé. |
403 |
ContentStreamNotAllowed |
Content stream finished due to exceeded streaming time. |
Le bot n’a pas pu terminer le processus de diffusion en continu dans le délai strict de deux minutes. |
403 |
ContentStreamNotAllowed |
Message size too large |
Le bot a envoyé un message qui dépasse la restriction actuelle de taille de message . |
429 |
N/A | API calls quota exceeded |
Le nombre de messages diffusés en continu par le bot a dépassé le quota. |
Exemple de code
| Exemple de nom | Description | Node.js | C# | Python |
|---|---|---|---|---|
| Exemple de bot de streaming Teams | Cet exemple de code montre comment créer un bot connecté à un LLM et envoyer des messages via Teams. | N/A | View | N/A |
| Bot de streaming conversationnel | Il s’agit d’un bot de streaming conversationnel avec la bibliothèque IA Teams. | View | View | View |