Connecteur CSV générique - Guide de référence technique (préversion)
Cet article décrit le connecteur CSV générique (GCSV). Cet article s’applique aux produits suivants :
- Agent d’approvisionnement Microsoft Entra Connect (ECMA2Host)
- Microsoft Identity Manager 2016 (MIM2016)
Pour MIM 2016, le connecteur est disponible en téléchargement à partir du Centre de téléchargement Microsoft.
Pour voir ce connecteur en action, consultez l’article Generic SQL Connector step-by-step .
Notes
Le service d’approvisionnement Azure AD fournit désormais une solution légère basée sur un agent pour approvisionner les utilisateurs en fichiers CSV, sans déploiement complet de synchronisation MIM. Nous vous recommandons d’évaluer s’il répond à vos besoins. Plus d’informations
Vue d’ensemble du connecteur CSV générique
Le connecteur CSV générique (GCSV) vous permet d’intégrer des données d’identité utilisateur et de groupe conservées dans des fichiers CSV à des produits Microsoft, tels que l’agent d’approvisionnement Microsoft Entra Connect (ECMA2Host) et Microsoft Identity Manager 2016 (MIM2016).
Il dispose de différentes fonctionnalités, telles que la possibilité d’orchestrer l’utilisation de PowerShell pour gérer les données d’identité avant ou après les opérations d’importation ou d’exportation. Il offre la prise en charge de plusieurs types de données, y compris les fichiers binaires et les références, la prise en charge des valeurs de chaîne qualifiée et les chaînes à valeurs multiples.
Cet article décrit les fonctionnalités et fonctions du connecteur CSV générique et comment le configurer pour MIM 2016.
Le tableau suivant répertorie les fonctionnalités prises en charge par la version actuelle du connecteur, du point de vue général :
| Fonctionnalité | Détails |
|---|---|
| Prise en charge de plusieurs produits | L’utilisation de ce connecteur est prise en charge avec les produits Microsoft suivants : |
| Fichiers CSV pris en charge | Ce connecteur prend en charge la gestion des utilisateurs (obligatoires) et des groupes (facultatif), par le biais de la configuration de trois fichiers CSV maximum : |
| Traitement pré/post-opération avec PowerShell | Ce connecteur prend en charge la configuration de jusqu’à quatre (4) scripts PowerShell pour faciliter le pré-traitement ou le post-traitement des données d’identité utilisateur et de groupe avant ou après les importations ou les exportations. |
| Encodage de fichiers CSV pris en charge | Le connecteur prend en charge tous les types d’encodage de serveur par défaut (ou installés) : (par exemple, Unicode, UTF-8, UTF-7, ASCII, etc.) |
| Types de données de champ CSV pris en charge | Le connecteur prend en charge les types de données d’attribut suivants : |
| Délimitation de champ CSV | Prise en charge des virgules (,) ou de tout caractère alphamérique imprimable pour qualifier le début et la fin d’une valeur de chaîne. |
| Prise en charge de la qualification de chaîne | Prise en charge des guillemets doubles (« ) ou de tout caractère alphamérique imprimable pour qualifier le début et la fin d’une valeur de chaîne. |
| Prise en charge des chaînes à valeurs multiples | Prise en charge des chaînes à valeurs multiples |
| Opérations de connecteur prises en charge | Le connecteur prend en charge les opérations suivantes : |
| schéma | La découverte de schéma est dynamique, mais nécessite une configuration manuelle pour l’achèvement. Les champs sont identifiés dynamiquement en fonction d’un délimiteur spécifié (ou appelé « séparateur de valeur »). Les types de données de champ sont désignés manuellement pendant la configuration. |
Prérequis
Avant d’utiliser le connecteur, vérifiez que vous disposez des éléments suivants sur le serveur de synchronisation :
- Microsoft .NET 4.6.2 Framework ou version ultérieure
- Fichiers CSV qui contiennent le schéma souhaité pour les types d’identité suivants :
- Fichier d’utilisateurs (obligatoire)
- Groupes (facultatif)
- Membres du groupe (obligatoires si des groupes sont utilisés)
- (Facultatif) Scripts PowerShell pour gérer le pré-traitement et le post-traitement pour les événements types d’opérations suivants :
- Pré-importation : ce script est exécuté avant l’exécution d’une opération d’importation.
- Post-importation : ce script est exécuté après l’exécution d’une opération d’importation.
- Pré-exportation : ce script est exécuté avant l’exécution d’une opération d’exportation.
- Post-exportation : ce script est exécuté après l’exécution d’une opération d’exportation.
Autorisations de compte de service de synchronisation MIM
Important
Le compte de service de synchronisation MIM 2016 est le contexte de sécurité qui effectue les opérations de fichier sur les fichiers CSV et exécute les scripts PowerShell de prétraitement/post-traitement. Ce compte de service a besoin d’autorisations en lecture/écriture pour tous les fichiers CSV et PowerShell configurés. Il a également besoin des autorisations d’exécution PowerShell appropriées pour exécuter tous les scripts configurés.
Créer un connecteur
La liste suivante présente une vue d’ensemble des étapes décrites dans ce guide. Pour commencer, un compte avec le rôle MIM Syncs Administration doit être utilisé pour effectuer ces tâches :
- Ouvrez la fenêtre Créer un agent de gestion (MA) à partir du Service Manager de synchronisation MIM.
- Sélectionnez le connecteur CSV générique comme type de connecteur.
- Indiquez le chemin d’accès au fichier et le nom du fichier CSV à importer ou exporter.
- Spécifiez l’encodage de fichier, le séparateur de valeurs, le séparateur à valeurs multiples et le qualificateur de texte pour le fichier CSV.
- Choisissez d’utiliser ou non les valeurs de la première ligne comme champs d’en-tête.
- Sélectionnez les types d’objets et les attributs à importer ou exporter à partir du fichier CSV.
- Configurez la partition, le profil d’exécution et les détails de mappage pour l’agent de gestion.
- Fournissez les chemins d’accès et les paramètres de script pour les scripts PowerShell, le cas échéant.
- Exécutez l’agent de gestion pour effectuer les opérations d’importation, de synchronisation ou d’exportation.
Pour créer un connecteur CSV générique, dans Service de synchronisation , sélectionnez Agent de gestion et Créer. Sélectionnez le connecteur CSV générique (Microsoft).
Connectivité
La page Connectivité contient les emplacements de fichiers des fichiers CSV Utilisateurs, Groupes et Membres du groupe.
L’image suivante est un exemple de page Connectivité .
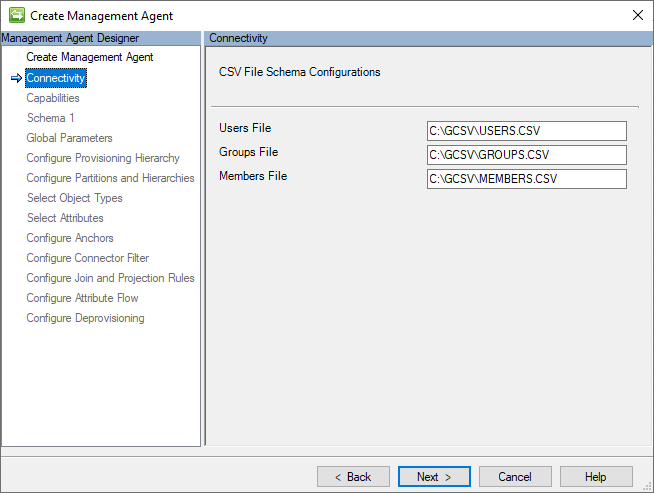
Les emplacements des fichiers CSV suivants sont spécifiés sur cette page :
- Fichier utilisateurs : chemin d’accès complet du fichier CSV qui contient les enregistrements utilisateur et leurs valeurs d’attribut. Ce fichier est obligatoire.
- Fichier de groupes : chemin d’accès complet du fichier CSV qui contient les enregistrements de groupe. Ce fichier est facultatif.
- Fichier membres : chemin d’accès complet du fichier CSV qui contient les enregistrements de référence des membres du groupe.
Important
Le compte de service MIM Sync doit disposer des autorisations de lecture et d’écriture sur tous les fichiers CSV désignés. Comme mentionné précédemment, les fichiers de groupe et de membre ne sont pas nécessaires si seuls les utilisateurs sont configurés.
L’écran Connectivité est le premier qui s’affiche lorsque vous créez un nouveau connecteur SQL générique. Vous devez d’abord fournir les informations de section suivantes :
Fonctionnalités
Cette page décrit les fonctionnalités du connecteur. Les fonctionnalités du connecteur sont fixes et ne peuvent pas être modifiées, mais elles sont expliquées ici pour fournir des informations sur le fonctionnement du connecteur.
L’image suivante est un exemple de la page Fonctionnalités .
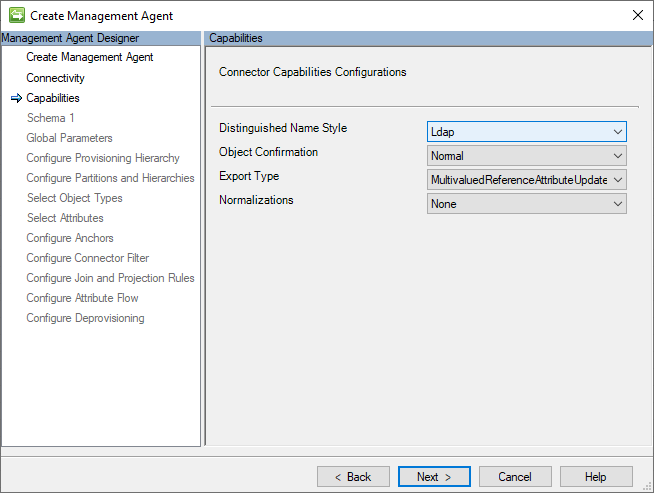
La section suivante répertorie les configurations individuelles et leurs significations :
- Ldap (Distinguished Name Style) : le connecteur GCSV utilise la syntaxe LDAP (Lightweight Directory Access Protocol) pour construire le DN (nom unique) afin d’identifier de manière unique chaque objet User ou Group dans son espace connecteur. Toutes les valeurs DN sont exprimées au format suivant : CN=[ANCHOR_VALUE],Object=[User|Groupe],O=CSV.
-
Confirmation de l’objet (normal) : normalement, le moteur de synchronisation suppose qu’il peut récupérer l’objet dans une importation delta ultérieure après une exportation. C’est ainsi que le moteur de synchronisation fonctionne généralement, mais tous les systèmes connectés ne fonctionnent pas de cette façon. Ce paramètre normal garantit qu’il n’y a aucun
exported-change-not-reimportedavertissement dans l’importation de suivi. - Type d’exportation (MultivaluedReferenceAttributeUpdate) : le type d’exportation spécifie comment les objets sont mis en forme et envoyés au système cible pendant la synchronisation. MultivaluedReferenceAttributeUpdate est un type d’exportation conçu pour fonctionner avec Microsoft Entra ID. Il envoie uniquement les attributs qui ont changé. Pour les attributs de type valeur, il utilise AttributeReplace et pour les attributs de référence, il utilise AttributeUpdate.
- Normalisations (Aucune) : les normalisations font référence à l’uniformisation des données dans un format cohérent. Aucun signifie qu’aucune règle de normalisation spécifique n’est appliquée. Les données restent telles quelles sans transformations supplémentaires par le connecteur.
Schéma 1 (configurations de format de fichier CSV)
Le connecteur GCSV utilise trois types de séparateurs (ou délimiteurs) pour délimiter et analyser les champs CSV et leurs valeurs.
Cette page contient les paramètres de valeur de caractère pour ces séparateurs et le type d’encodage utilisé pour créer le fichier au format CSV.
L’image suivante est une image de la page Schema 1 (Configurations du format de fichier CSV).
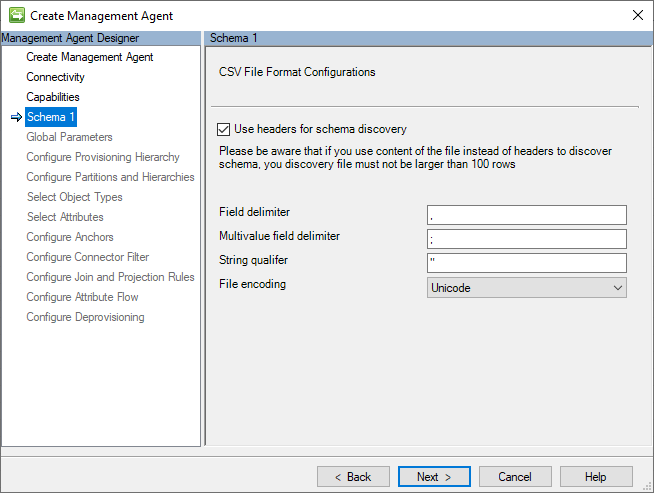
La section suivante répertorie les configurations individuelles :
- Utiliser des en-têtes pour la découverte de schéma : lorsque cette option est sélectionnée, elle indique au connecteur de traiter le premier enregistrement de chaque fichier CSV comme un enregistrement d’en-tête et non comme un enregistrement de données d’identité. Si cette option n’est pas sélectionnée, le connecteur affecte le nom Attribute avec une valeur entière incrémentée unique ajoutée (par exemple, Attribute1, Attribute2, etc.) et traite la première ligne de comme un enregistrement de données d’identité.
- Séparateur de valeurs : ce caractère sépare les champs (c’est-à-dire les valeurs) des enregistrements CSV. La virgule (,) est la valeur par défaut, mais tout caractère alphanumérique pouvant être imprimé est autorisé.
- Séparateur à valeurs multiples : ce type de séparateur est utilisé pour délimiter les valeurs individuelles d’une chaîne à valeurs multiples (par exemple, des adresses proxy) ou d’attributs de référence (par exemple, des subordonnés).) La valeur par défaut est un point-virgule (;) mais tout caractère alphanumérique imprimable est acceptable.
- Qualificateur de texte : lorsqu’une valeur de chaîne contient des caractères qui seraient autrement interprétés comme des délimiteurs (par exemple, des virgules), la valeur doit être qualifiée afin que l’analyseur CSV puisse interpréter correctement la chaîne comme un champ unique. Les guillemets doubles (« ) sont la valeur par défaut, mais tout caractère alphanumérique pouvant être imprimé est autorisé.
Notes
Bien que les schémas des fichiers CSV ne contiennent pas de champs à valeurs multiples ou ne contiennent pas de valeurs nécessitant une qualification de chaîne, la désignation d’un caractère imprimable unique pour chaque type de séparateur est requise.
- Encodage de fichier : ce paramètre indique l’encodage utilisé sur les fichiers CSV ajoutés sous l’onglet Connectivité. Assurez-vous qu’il correspond à l’encodage de vos fichiers CSV.
Notes
Si vous n’êtes pas sûr du type d’encodage de vos fichiers CSV, essayez d’utiliser le type d’encodage Unicode par défaut. Unicode est une norme courante qui prend en charge de nombreux caractères et symboles, ce qui en fait une bonne option pour l’encodage de données de texte dans la plupart des langues ou le jeu de caractères est utilisé.
Schéma 2 (configurations des champs d’identité et de référence)
La valeur d’ancre est un identificateur unique pour un enregistrement dans un fichier CSV. Il différencie un enregistrement des autres. Le connecteur GCSV utilise également cette valeur pour créer le nom unique (DN) qui identifie l’objet d’espace de connecteur associé.
Sur cette page, les paramètres d’attribut d’ancre sont configurés pour chacun des fichiers CSV répertoriés dans la page Connectivité.
L’image suivante est un exemple de la page Schema 2 (Identity and Reference Field Configurations).
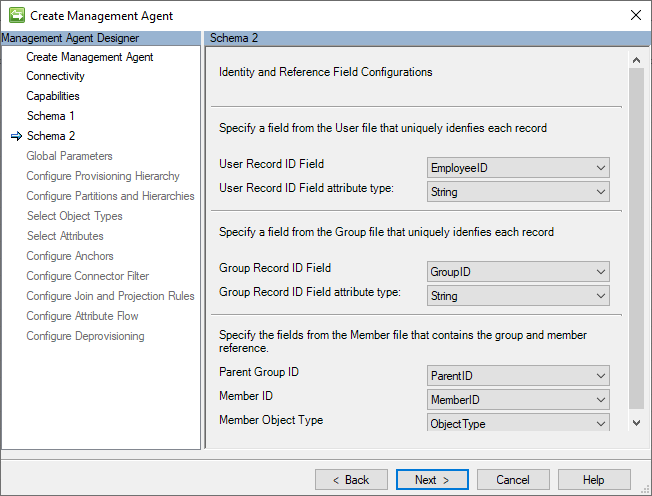
La section suivante répertorie les configurations individuelles de cette page :
-
Utilisateur
- Ancre utilisateur : champ dans le fichier Users qui sert de valeur d’ancre pour l’enregistrement utilisateur. Le premier champ d’en-tête dans le fichier Users est le choix par défaut.
- Type d’attribut User Anchor : il s’agit du type d’attribut de l’ancre sélectionnée.
-
Groupe
- Ancre de groupe : champ dans le fichier Groupes qui sert de valeur d’ancre pour l’enregistrement de groupe. Le premier champ d’en-tête dans le fichier Groupes est le choix par défaut.
- Type d’attribut d’ancre de groupe : il s’agit du type d’attribut de l’ancre sélectionnée.
-
Membre
- ID de groupe parent : champ dans le fichier Members qui a la même valeur (ancre) que le groupe parent dans le fichier CSV De groupes. Le premier champ du fichier Members est utilisé par défaut.
- ID de membre : champ dans le fichier Membres qui a la même valeur (ancre) que dans le fichier CSV Utilisateurs ou Groupes. Le deuxième champ du fichier Members est sélectionné par défaut.
- Type d’objet membre : champ qui contient une valeur de chaîne « Utilisateur » ou « Groupe » pour indiquer le type d’objet du membre. Ce champ n’est requis que si le fichier membre contient plus de deux champs. Le champ Type d’objet doit uniquement contenir la valeur de chaîne « User » ou un « Group ». Si ce champ est manquant, le connecteur part du principe que les enregistrements du fichier Members font référence à un membre de l’objet User. Le troisième champ trouvé dans le fichier Members est sélectionné par défaut.
Important
Les noms des attributs désignés pour être utilisés comme ancres doivent être uniques dans tous les schémas de type d’objet. Cela inclut les ancres spécifiées dans le fichier Membres du groupe.
Schéma 3 (configurations de schéma d’attribut de fichier d’utilisateurs)
Cette page permet de spécifier et d’expliquer le type de données de chacun des champs identifiés dans le schéma du fichier CSV Utilisateurs et de déterminer s’ils peuvent avoir plusieurs valeurs.
L’image suivante est un exemple de la page Schema 3 (Users File Attribute Schema Configurations).
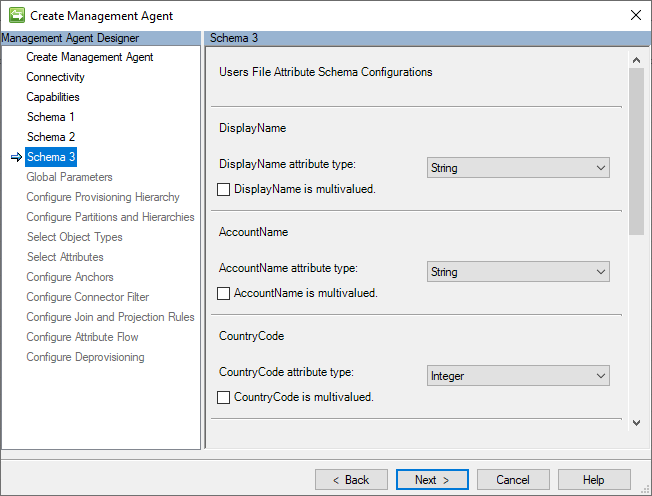
La section suivante répertorie les considérations relatives à l’attribution de types de données d’attribut.
Types de données pris en charge
Le connecteur GCSV prend en charge l’utilisation des types de données de section suivants :
- Boolean : valeur qui peut être true ou false.
- Binaire : valeur stockée sous la forme d’une séquence d’octets, généralement utilisée pour stocker des données telles que des images ou d’autres fichiers.
- Entier : valeur qui est un nombre entier, sans décimales.
- Chaîne : valeur qui est une séquence de caractères, généralement utilisée pour stocker des données de texte.
- Référence : valeur qui est une référence à un autre objet utilisateur. Pour spécifier une valeur de référence dans un fichier CSV, renseignez son champ avec la valeur d’ancrage de l’objet utilisateur référencé.
Important
Les attributs de référence utilisateur ou groupe peuvent uniquement être utilisés pour faire référence à des objets utilisateur. Cela ne s’applique pas à l’attribut Member des objets Group, qui peut contenir à la fois des références d’utilisateur ou de groupe tant que le champ de type d’objet est spécifié.
Types de données Multiple-Value pris en charge
Le connecteur prend en charge l’utilisation d’attributs à valeurs multiples uniquement pour les types de données suivants :
- String
Notes
Si le schéma des objets User et Group a tous deux un attribut (non ancre) du même nom, il se peut que des types de données différents ne soient pas attribués entre eux. Ils doivent tous deux partager le même type de données.
Schéma 4 (configurations de schéma d’attribut de fichier de groupes)
Cette page permet de spécifier et d’expliquer le type de données de chacun des champs identifiés dans le schéma du fichier CSV De groupes et de déterminer s’ils peuvent avoir plusieurs valeurs.
L’image suivante est un exemple de la page Schema 4 (Groups File Attribute Schema Configurations).
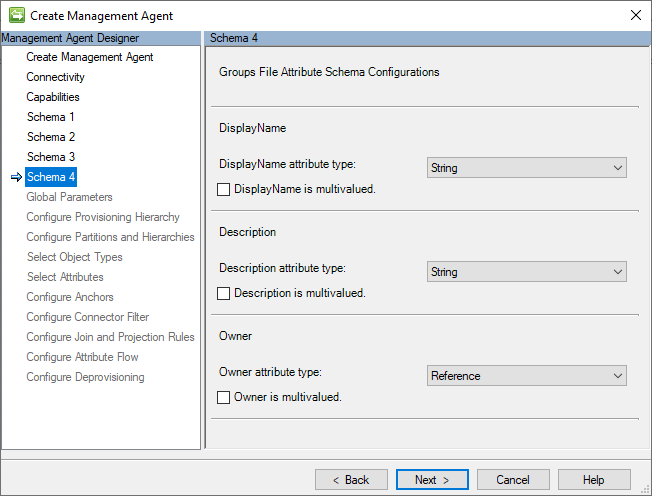
Les conseils proposés dans Schéma 3 (Configurations d’attributs de fichier utilisateurs ) s’appliquent également à cette section. .
Après l’exécution d’une opération d’importation complète initiale, l’espace connecteur ressemble à l’image suivante :
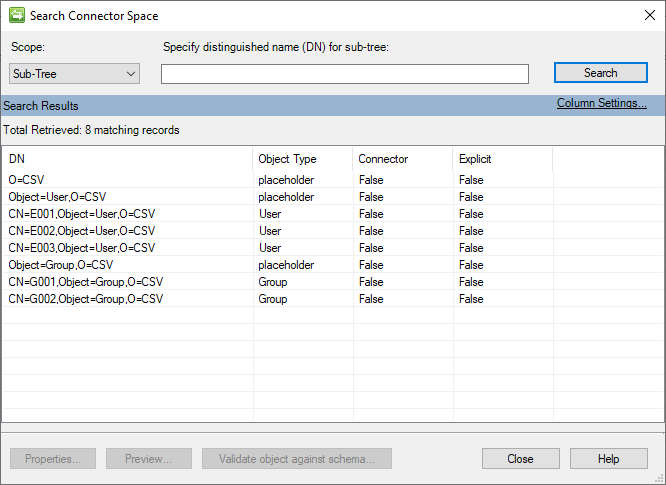
Paramètres globaux (configuration des scripts PowerShell)
Cette page permet de configurer des scripts PowerShell qui s’exécutent avant et/ou après les opérations d’importation et/ou d’exportation. Ces fonctionnalités offrent la possibilité d’effectuer un large éventail d’actions de pré-traitement et de post-traitement sur vos enregistrements d’utilisateur et de groupe d’identité.
L’image suivante est un exemple de la page Paramètres globaux .
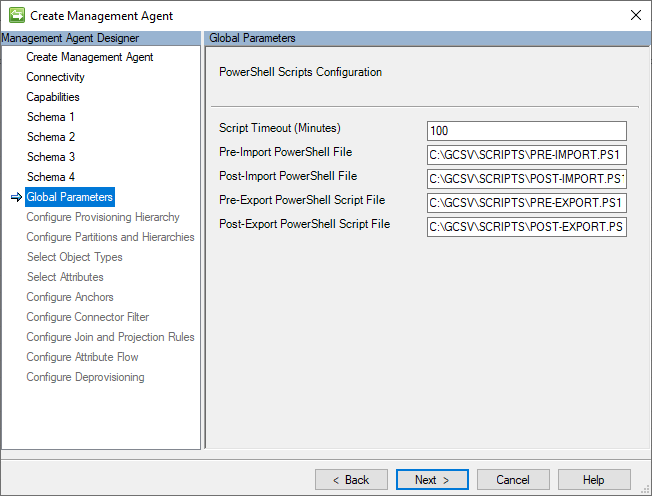
La section suivante répertorie les paramètres de configuration individuels de cette page :
- Délai d’expiration du script (minutes) : nombre de minutes pendant lesquelles un script s’exécute avant son abandon automatique. La valeur par défaut de ce paramètre est 100 et nécessite une valeur supérieure à zéro (0).
- Fichier de script de pré-importation : chemin d’accès complet au script PowerShell qui doit s’exécuter avant une importation. Ce paramètre est facultatif et ne nécessite pas de valeur.
- Fichier de script post-importation : chemin complet du script PowerShell qui doit s’exécuter après une importation. Ce paramètre est facultatif et ne nécessite pas de valeur.
- Fichier de script de pré-exportation : chemin d’accès complet au script PowerShell qui doit s’exécuter avant une exportation. Ce paramètre est facultatif et ne nécessite pas de valeur.
- Fichier de script post-exportation : chemin d’accès complet au script PowerShell qui doit s’exécuter après une exportation. Ce paramètre est facultatif et ne nécessite pas de valeur.
Paramètres d’exécution et d’entrée de script PowerShell
Le connecteur GCSV exécute chacun des scripts PowerShell configurés dans sa propre session et ne prend pas en charge le passage de paramètres entre les phases.
Le connecteur transmet un paramètre d’entrée dans chaque script nommé OperationType. La valeur de ce paramètre varie en fonction de l’opération Exécuter le profil qui est effectuée, et il peut s’agir de l’une des trois valeurs suivantes :
Important
La création dynamique de fichiers CSV avant les opérations d’importation ou d’exportation n’est pas prise en charge. Tous les fichiers CSV doivent être présents avant qu’aucun des profils d’exécution ne s’exécute.
Paramètre d’entrée PowerShell : OperationType
Bien que l’utilisation de paramètres d’entrée ne soit pas prise en charge, le connecteur GCSV passe un paramètre d’entrée dans l’exécution de chaque script PowerShell : OperationType.
- Full : cette valeur est fournie lors des opérations d’importation complète ou d’exportation complète.
- Delta : cette valeur est fournie pendant les opérations d’exportation.
Cette valeur de paramètre peut être utilisée dans la logique des scripts PowerShell pour déterminer l’opération ou l’action de pré/post-traitement appropriée à entreprendre.
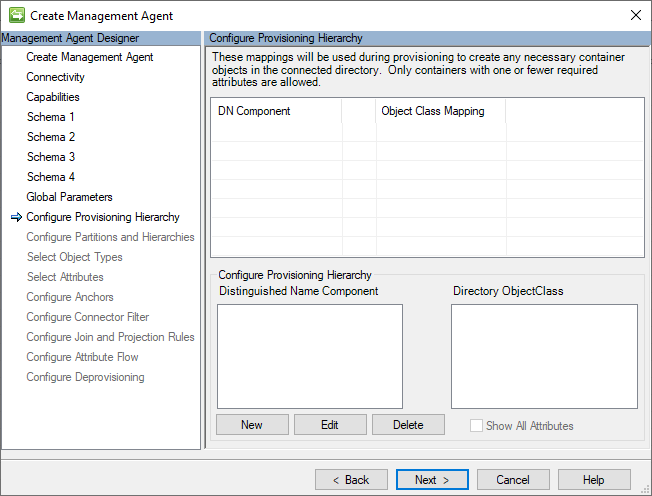
Hiérarchie d’approvisionnement
Étant donné que les fichiers CSV ne stockent pas d’informations dans une structure hiérarchique, le connecteur GCSV ne prend pas en charge les configurations d’approvisionnement hiérarchique.
L’image suivante est un exemple de la page Hiérarchie d’approvisionnement .
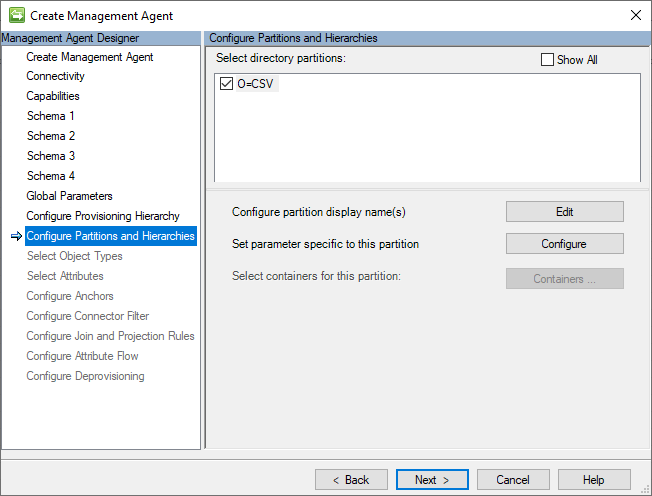
Partitions et hiérarchies
Le connecteur GCSV génère un nom unique (DN) distinct pour chaque enregistrement d’utilisateur et de groupe dans son espace de connecteur, en suivant ce format LDAP :
CN=[ANCHOR_VALUE],Object=User|Group,O=CSV
L’image suivante est un exemple de la page Partitions et hiérarchies .
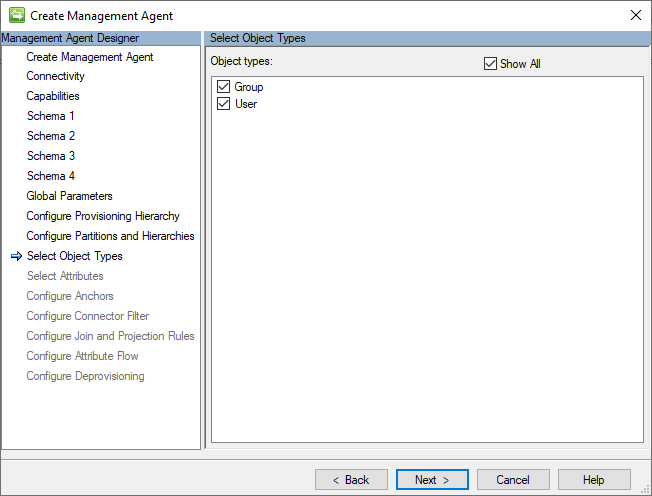
Types d’objet
Le connecteur GCSV nécessite qu’au moins le type d’objet User soit sélectionné. Le type d’objet Group est facultatif.
L’image suivante est un exemple de la page Types d’objets .
Attributs
Cette page affiche une liste normalisée de tous les attributs de tous les schémas de type d’objet sélectionnés.
L’image suivante est un exemple de la page Attributs .
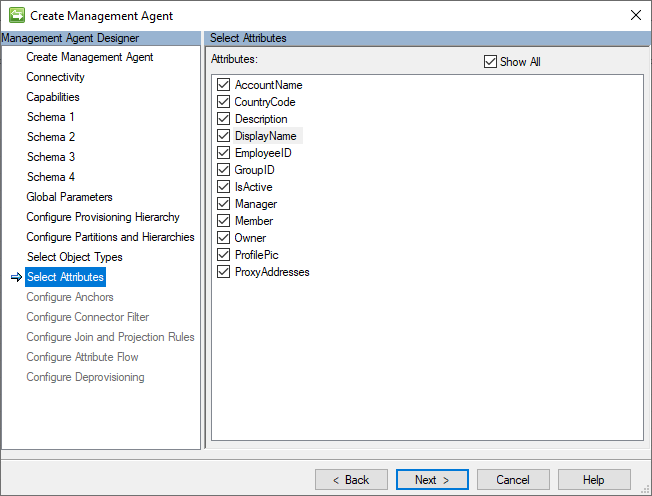
Notes
L’attribut Member n’existe que si groupes sont sélectionnés et contient les références aux objets conservés dans les fichiers CSV des membres du groupe.
Ancres
Le connecteur GCSV ne prend pas en charge l’utilisation d’ancres complexes ni de configurations d’attributs d’ancre qui diffèrent des champs d’ID d’ancre de leur fichier CSV correspondant.
Pour modifier les désignations d’ancre affichées sur cette page, revenez au Schéma 2 (Configurations d’ancre).
L’image suivante est un exemple de page Ancres .
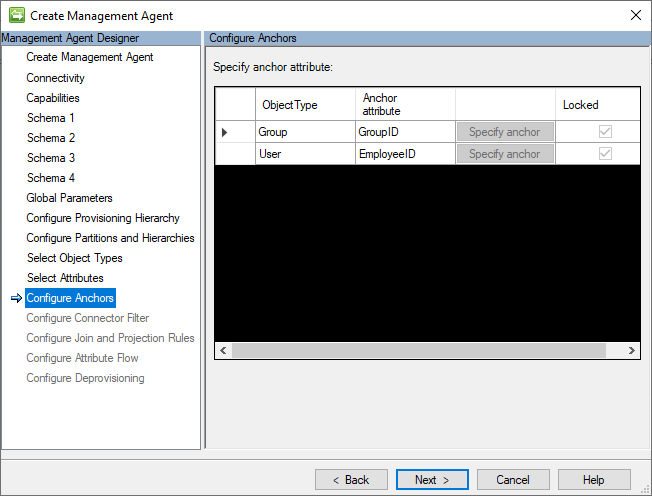
Provisionnement d’enregistrements CSV
Pour que le connecteur GCSV ajoute de nouveaux objets User ou Group dans leurs fichiers CSV correspondants, un nouvel objet d’espace connecteur doit être provisionné pour celui-ci.
Que vous utilisiez l’approvisionnement déclaratif MIM 2016 ou écriviez vos propres extensions de règles de synchronisation MIM, les nouveaux objets Espace connecteur doivent avoir un nom de domaine construit au format suivant :
CN=[ANCHOR_VALUE],Object=User|Groupe,O=CSV
Le tableau suivant fournit des détails sur chacune des valeurs de composant :
| Composant | Notes |
|---|---|
| CN=[VALEUR D’ANCRE] | Le nom commun (CN) doit être une valeur unique dans et sera écrit dans le champ d’ancrage désigné du fichier CSV. |
| Object=User/Group | Ce composant indique le type d’objet de ce connecteur. Prend en charge « Utilisateur » ou « Groupe » uniquement. |
| O=CSV | Composant racine commun à tous les objets d’espace de connecteur GCSV. |
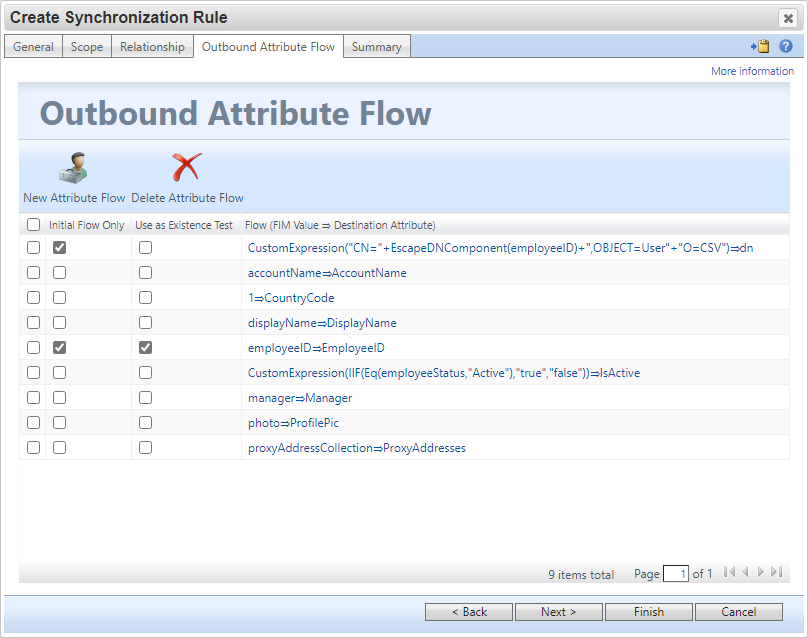
L’image suivante est une règle de synchronisation qui montre comment construire correctement un DN lors de l’approvisionnement d’un nouvel objet User dans un connecteur GCSV :
Le code suivant illustre la logique d’approvisionnement équivalente à l’aide des extensions de règles de métaverse.
void IMVSynchronization.Provision(MVEntry mventry)
{
if (mventry["employeeID"].IsPresent)
{
ConnectedMA GCSVConnector = = mventry.ConnectedMAs["Generic CSV Conenctor"];
if (GCSVConnector.Connectors.Count == 0)
{
CSEntry csentry = GCSVConnector.Connectors.StartNewConnector("user");
//Sets DN to "CN=[ANCHOR_VALUE],OBJECT=[User|Group],O=CSV"
csentry.DN = GCSVConnector.EscapeDNComponent("CN=" + mventry["employeeID"].Value).Concat("OBJECT=User,O=CSV");
csentry["AccountName"].StringValue = mventry["accountName"].StringValue;
csentry["CountryCode"].IntegerValue = 1;
csentry["DisplayName"].Value = mventry["displayName"].Value;
csentry["ProxyAddresses"].Value = mventry["proxyAddressCollection"].Value;
csentry["IsActive"].BooleanValue = true;
csentry["Manager"].Value = mventry["manager"].Value;
csentry["ProfilePic"].Value = mventry["pic"].Value;
csentry.CommitNewConnector();
}
}
}
Dans l’image précédente, notez l’utilisation de la EcapeDNComponent() fonction pour garantir que la valeur d’ancre est correctement échappée pour être conforme à sa syntaxe LDAP.
Important
L’échappement incorrect de la valeur d’ancre lors de la construction d’un DN génère une invalid‑dn erreur.
Exemples de mise en forme de champ CSV
Les sections suivantes répertorient des exemples de mise en forme de différents types de données dans des fichiers CSV. Tous les exemples La section suivante suppose l’utilisation des paramètres de délimiteur de champ par défaut du connecteur :
- Valeur séparée : Virgule (,)
- Séparateur à valeurs multiples : Semi-Colon (;)
- Qualificateur de texte : Guillemets doubles (« )
Exemple : Qualification de texte
Si une valeur de chaîne contient des caractères qui seraient autrement interprétés comme des délimiteurs (par exemple, des virgules), la valeur doit être qualifiée afin que l’analyseur CSV puisse interpréter correctement la chaîne comme un champ unique.
L’exemple CSV de la section suivante montre comment le champ DisplayName a des valeurs qui sont mises en forme en tant que texte qualifié :
EmployeeID,DisplayName
E001,"Smith, John"
E002,"Doe, Jane"
E003,"Perez, Juan"
Exemple : Limitation des chaînes à valeurs multiples
Pour fournir plusieurs valeurs de chaîne dans un champ de chaîne, délimitez les valeurs avec le séparateur à valeurs multiples. L’exemple CSV de section suivant montre comment le champ ProxyAddress avec plusieurs valeurs :
EmployeeID,DisplayName,ProxyAddresses
E001,"Smith, John",SMTP:john.smith@contoso.com;smtp:js001@contoso.com
E002,"Doe, Jane",SMTP:jane.doe@contoso.com;smtp:jd002@contoso.com
Notes
La chaîne à valeurs multiples prend également en charge l’utilisation de valeurs qualifiées de chaîne. Les valeurs qualifiées de texte peuvent être délimitées par des séparateurs à valeurs multiples.
Exemple : Champs de référence
Pour spécifier une valeur de référence dans un fichier CSV, renseignez son champ avec la valeur d’ancrage de l’objet utilisateur référencé. Dans l’exemple CSV de la section suivante, le champ Manager contient la valeur d’ancrage de l’enregistrement utilisateur auquel il fait référence :
EmployeeID,DisplayName,Manager
E001,"Smith, John",
E002,"Doe, Jane",E001
E003,"Doe, Jane",
E004,"Perez, Juan",
Exemple : Champs binaires
Pour exprimer des valeurs binaires dans des fichiers CSV, elles doivent être converties en chaînes en base64 qui utilisent le même type d’encodage que le fichier CSV. La fonction PowerShell de section suivante montre comment encoder une valeur de chaîne dans sa chaîne codée en base64 en Unicode :
function ConvertTo-Base64([string]$text)
{
$bytes = [System.Text.Encoding]::Unicode.GetBytes($text)
$encodedText = [System.Convert]::ToBase64String($bytes)
return $encodedText
}
Voici la fonction équivalente en C# qui accepte un paramètre d’entrée appelé text et retourne une chaîne codée en base64 en Unicode.
public static string ConvertToBase64(string text)
{
byte[] bytes = System.Text.Encoding.UTF8.GetBytes(text);
string encodedText = System.Convert.ToBase64String(bytes);
return encodedText;
}
Exemple : Champs booléens
Les fichiers CSV qui contiennent des champs booléens doivent utiliser le texte True ou False pour indiquer leur valeur. La section suivante est une
EmployeeID,DisplayName,IsActive
E001,"Smith, John",true
E002,"Doe, Jane",true
E003,"Perez, Juan",false
Limites connues
La liste suivante contient les limitations connues du connecteur GCSV.
-
Attributs de référence
- À part l’attribut membre du groupe, les attributs de référence à valeurs multiples ne sont pas pris en charge.
- La valeur de référence doit faire référence aux objets utilisateur. Les références aux objets de groupe ne sont pas prises en charge.
-
Ancres
- Les valeurs d’ancre en double entre les objets utilisateur et groupe ne sont pas prises en charge.
- Les noms des attributs d’ancre doivent être uniques dans les schémas utilisateur et de groupe.
-
PowerShell
- Le passage de variables d’entrée dans des scripts PowerShell n’est pas pris en charge.