Domaine de sécurité : sécurité opérationnelle
Le domaine de sécurité opérationnelle garantit que les éditeurs de logiciels indépendants implémentent un ensemble solide de techniques d’atténuation de la sécurité contre une myriade de menaces auxquelles sont confrontés les acteurs des menaces. Il est conçu pour protéger l’environnement d’exploitation et les processus de développement logiciel afin de créer des environnements sécurisés.
Formation de sensibilisation
La formation de sensibilisation à la sécurité est importante pour les organisations, car elle permet de réduire les risques liés aux erreurs humaines, qui sont impliquées dans plus de 90 % des violations de sécurité. Il aide les employés à comprendre l’importance des mesures et des procédures de sécurité. Lorsque la formation de sensibilisation à la sécurité est proposée, elle renforce l’importance d’une culture sensible à la sécurité dans laquelle les utilisateurs savent comment reconnaître les menaces potentielles et y répondre. Un programme de formation efficace de sensibilisation à la sécurité doit inclure du contenu qui couvre un large éventail de sujets et de menaces auxquels les utilisateurs peuvent être confrontés, tels que l’ingénierie sociale, la gestion des mots de passe, la confidentialité et la sécurité physique.
Contrôle n° 1
Fournissez la preuve que :
L’organisation fournit une formation de sensibilisation à la sécurité établie aux utilisateurs du système d’information (y compris les gestionnaires, les cadres supérieurs et les sous-traitants) :
Dans le cadre de la formation initiale pour les nouveaux utilisateurs.
Lorsque les modifications apportées au système d’information l’exigent.
Fréquence définie par l’organisation de la formation de sensibilisation.
Documente et surveille les activités individuelles de sensibilisation à la sécurité du système d’information et conserve les enregistrements de formation individuels sur une fréquence définie par l’organisation.
Intention : formation pour les nouveaux utilisateurs
Ce sous-point est axé sur l’établissement d’un programme obligatoire de formation sur la sécurité conçu pour tous les employés et pour les nouveaux employés qui rejoignent l’organisation, quel que soit leur rôle. Cela inclut les gestionnaires, les cadres supérieurs et les sous-traitants. Le programme de sensibilisation à la sécurité doit comprendre un programme complet conçu pour transmettre des connaissances fondamentales sur les protocoles, les stratégies et les meilleures pratiques de sécurité des informations de l’organisation afin de garantir que tous les membres de l’organisation sont alignés sur un ensemble unifié de normes de sécurité, créant ainsi un environnement de sécurité des informations résilient.
Recommandations : formation pour les nouveaux utilisateurs
La plupart des organisations utilisent une combinaison de formations de sensibilisation à la sécurité basées sur les plateformes et de documentation administrative, telles que la documentation et les enregistrements de stratégie, pour suivre la fin de la formation pour tous les employés de l’organisation. Les éléments de preuve fournis doivent démontrer que les employés ont terminé la formation, et cela doit être accompagné de politiques/procédures connexes décrivant les exigences de sensibilisation à la sécurité.
Exemple de preuve : formation pour les nouveaux utilisateurs
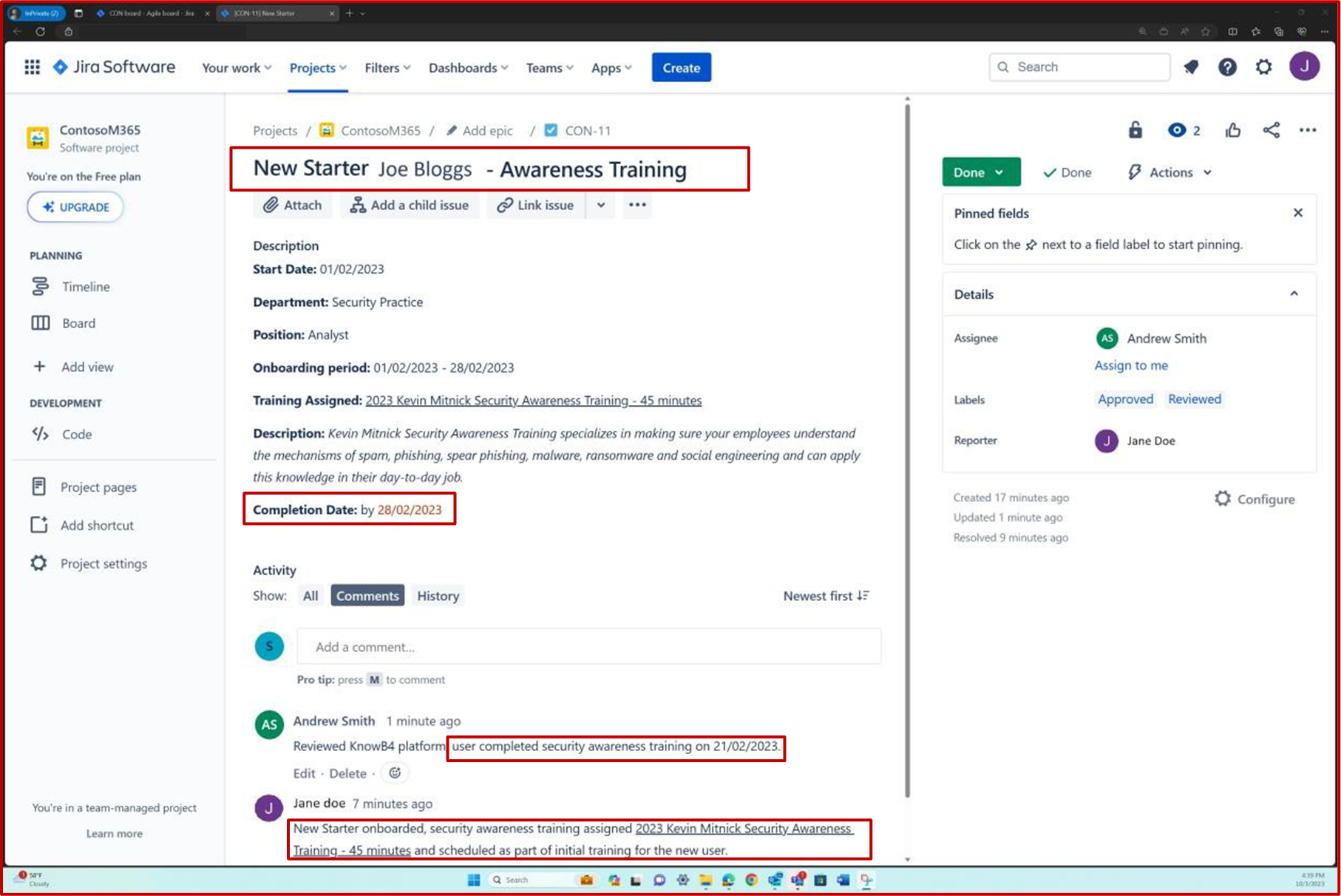
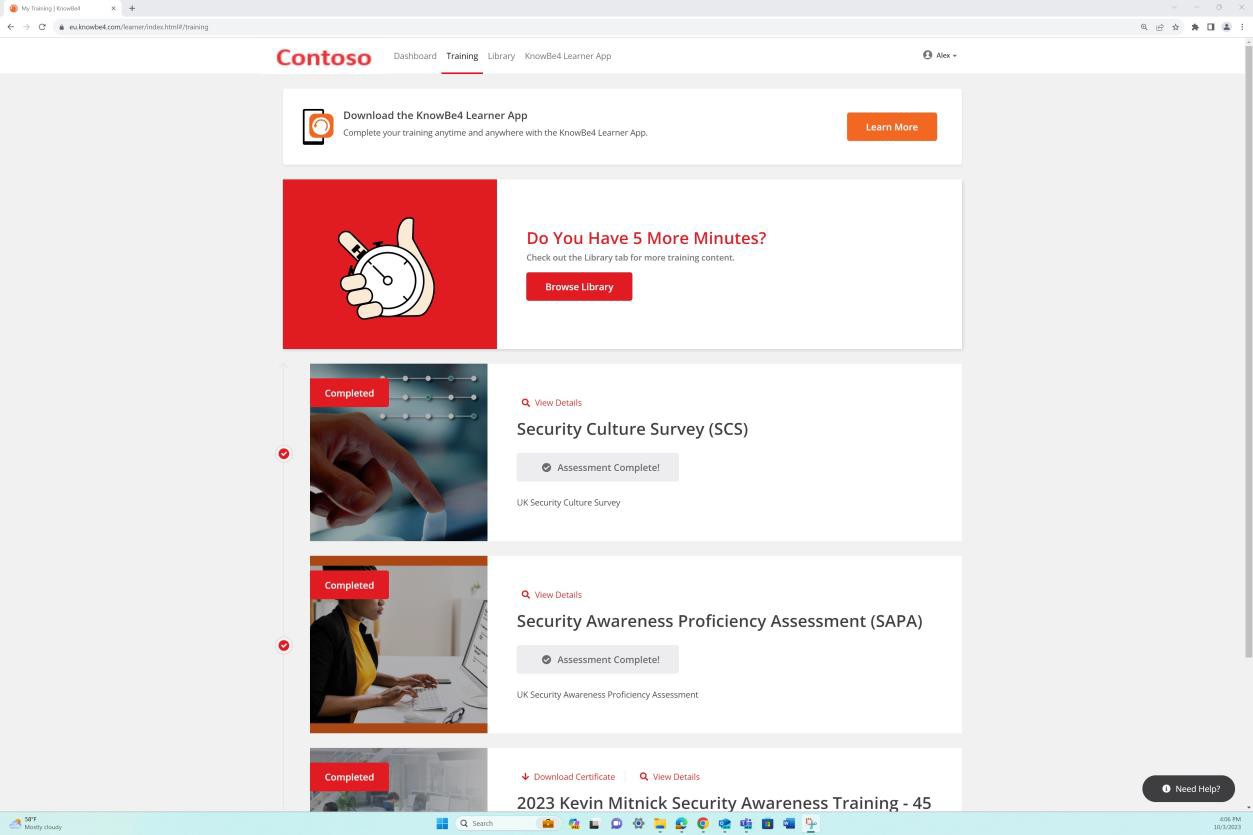
La capture d’écran suivante montre la plateforme Confluence utilisée pour suivre l’intégration des nouveaux employés. Un ticket JIRA a été généré pour le nouvel employé, y compris son affectation, son rôle, son service, etc. Avec le nouveau processus de démarrage, la formation de sensibilisation à la sécurité a été sélectionnée et attribuée à l’employé, qui doit être terminée avant la date d’échéancedu 28 février 2023.
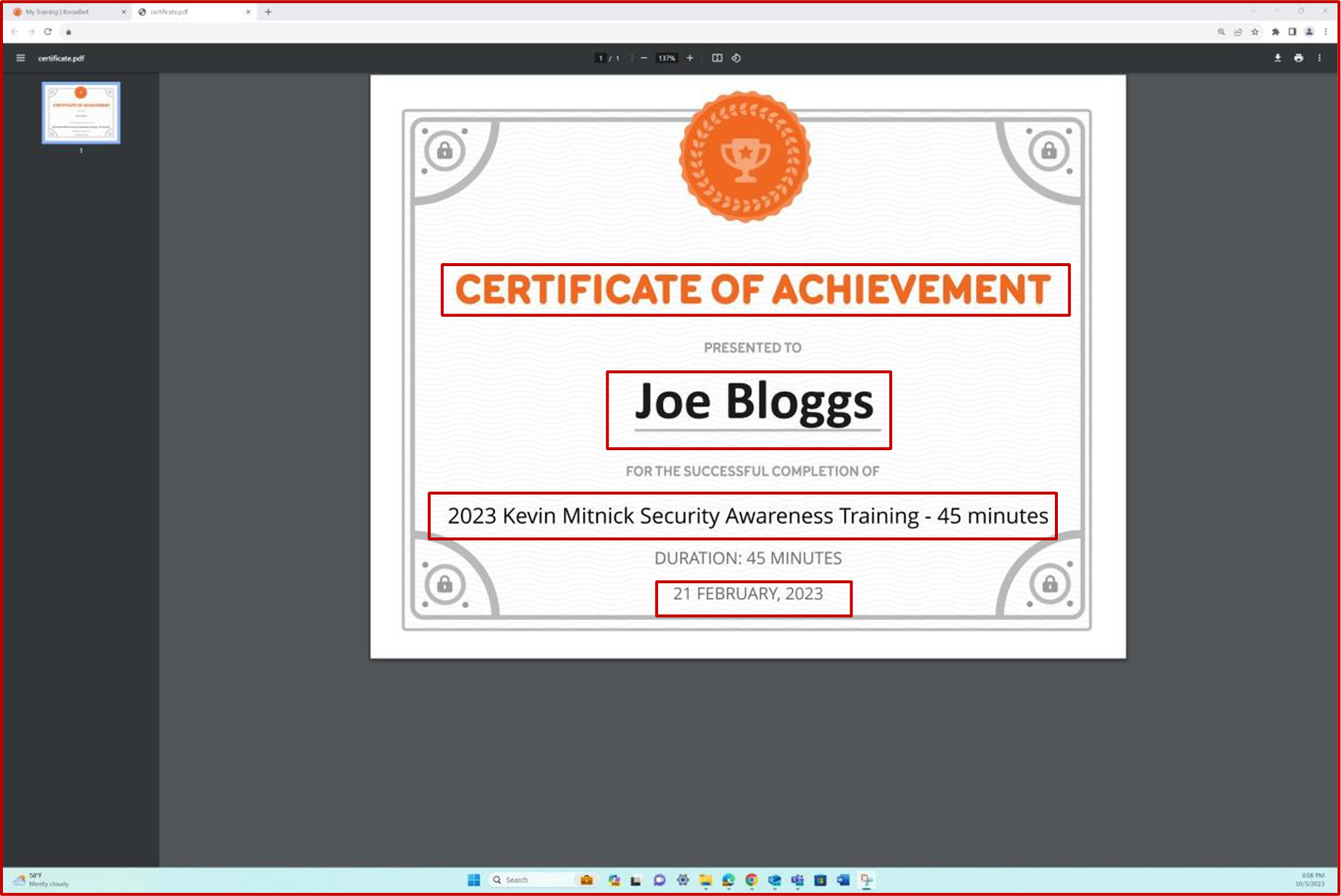
La capture d’écran montre le certificat d’achèvement généré par Knowb4 lors de la réussite de la formation de sensibilisation à la sécurité par l’employé. La date d’achèvementest le 21 février 2023, ce qui correspond à la période attribuée.
Intention : modifications du système d’information.
L’objectif de ce sous-point est de s’assurer que la formation de sensibilisation à la sécurité adaptative est lancée chaque fois qu’il y a des changements importants dans les systèmes d’information de l’organisation. Les modifications peuvent survenir en raison de mises à jour logicielles, de modifications architecturales ou de nouvelles exigences réglementaires. La session de formation mise à jour garantit que tous les employés sont informés des nouvelles modifications et de l’impact qui en résulte sur les mesures de sécurité, ce qui leur permet d’adapter leurs actions et décisions en conséquence. Cette approche proactive est essentielle pour protéger les ressources numériques de l’organisation contre les vulnérabilités qui pourraient résulter des modifications apportées au système.
Recommandations : modifications du système d’information.
La plupart des organisations utilisent une combinaison de formations de sensibilisation à la sécurité basées sur les plateformes et de documentation administrative, comme la documentation de stratégie et les enregistrements, pour suivre la fin de la formation pour tous les employés. Les éléments de preuve fournis doivent démontrer que divers employés ont suivi la formation en fonction de différents changements apportés aux systèmes de l’organisation.
Exemple de preuve : modifications du système d’information.
Les captures d’écran suivantes montrent l’attribution d’une formation de sensibilisation à la sécurité à différents employés et montrent que des simulations d’hameçonnage se produisent.
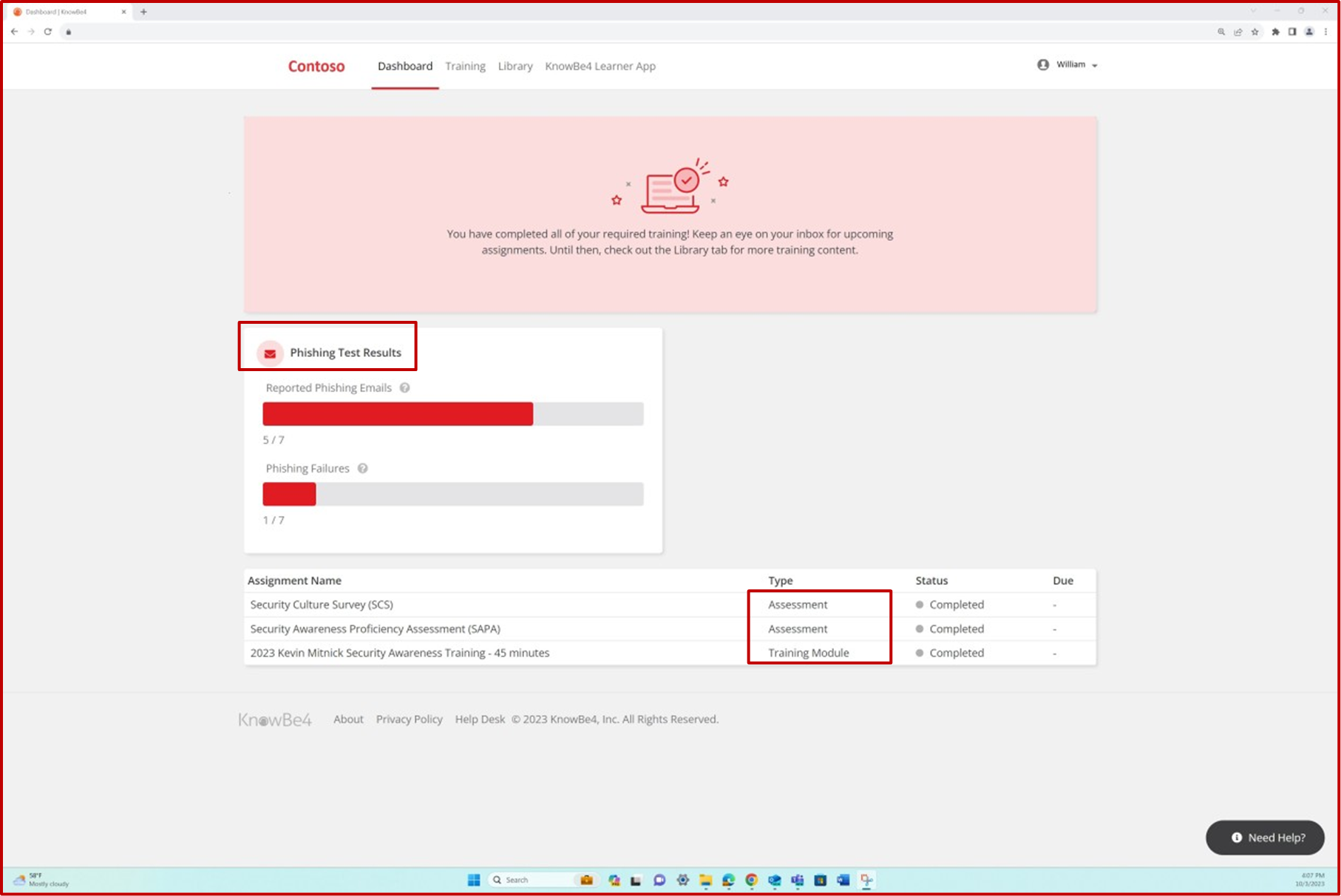
La plateforme est utilisée pour attribuer une nouvelle formation chaque fois qu’une modification du système se produit ou qu’un test échoue.
Intention : fréquence de formation de sensibilisation.
L’objectif de ce sous-point est de définir une fréquence spécifique à l’organisation pour la formation périodique de sensibilisation à la sécurité. Cela peut être planifié annuellement, semi-annuellement ou à un intervalle différent déterminé par l’organisation. En définissant une fréquence, l’organisation garantit que les utilisateurs sont régulièrement mis à jour sur l’évolution du paysage des menaces, ainsi que sur les nouvelles mesures et stratégies de protection. Cette approche peut aider à maintenir un niveau élevé de sensibilisation à la sécurité parmi tous les utilisateurs et à renforcer les composants de formation précédents.
Recommandations : fréquence de formation de sensibilisation.
La plupart des organisations disposent d’une documentation administrative et/ou d’une solution technique pour décrire/implémenter les exigences et la procédure de formation de sensibilisation à la sécurité, ainsi que pour définir la fréquence de la formation. Les preuves fournies doivent démontrer l’achèvement de diverses formations de sensibilisation au cours de la période définie et qu’une période définie par votre organisation existe.
Exemple de preuve : fréquence de formation de sensibilisation.
Les captures d’écran suivantes montrent des captures instantanées de la documentation sur la stratégie de sensibilisation à la sécurité et indiquent qu’elle existe et est conservée. La stratégie exige que tous les employés de l’organisation reçoivent une formation de sensibilisation à la sécurité, comme indiqué dans la section étendue de la stratégie. La formation doit être attribuée et complétée sur une base annuelle par le service concerné.
Selon le document de politique, tous les employés de l’organisation doivent suivre trois cours (une formation et deux évaluations) chaque année et dans les vingt jours suivant l’affectation. Les cours doivent être envoyés par e-mail et attribués via KnowBe4.
L’exemple fourni montre uniquement des instantanés de la stratégie. Notez que l’on s’attend à ce que le document de stratégie complet soit envoyé.

La deuxième capture d’écran est la continuation de la politique, et elle montre la section du document qui impose l’exigence annuelle de formation, et elle montre que la fréquence définie par l’organisation de la formation de sensibilisation est définie sur annuellement.

Les deux captures d’écran suivantes illustrent la réussite des évaluations de formation mentionnées précédemment. Les captures d’écran ont été prises à partir de deux employés différents.
Intention : documentation et surveillance.
L’objectif de ce sous-point est de créer, de gérer et de surveiller des enregistrements méticuleux de la participation de chaque utilisateur à la formation de sensibilisation à la sécurité. Ces enregistrements doivent être conservés sur une période définie par l’organisation. Cette documentation sert de piste auditable pour la conformité avec les réglementations et les stratégies internes. Le composant de surveillance permet à l’organisation d’évaluer l’efficacité du
la formation, l’identification des domaines à améliorer et la compréhension des niveaux d’engagement des utilisateurs. En conservant ces enregistrements sur une période définie, l’organisation peut suivre l’efficacité et la conformité à long terme.
Recommandations : documentation et surveillance.
Les preuves qui peuvent être fournies pour la formation de sensibilisation à la sécurité dépendent de la façon dont la formation est implémentée au niveau de l’organisation. Cela peut indiquer si la formation est effectuée via une plateforme ou effectuée en interne sur la base d’un processus interne. Les éléments de preuve fournis doivent montrer que des enregistrements historiques de formation effectuées pour tous les utilisateurs sur une période existent et comment cela est suivi.
Exemple de preuve : documentation et surveillance.
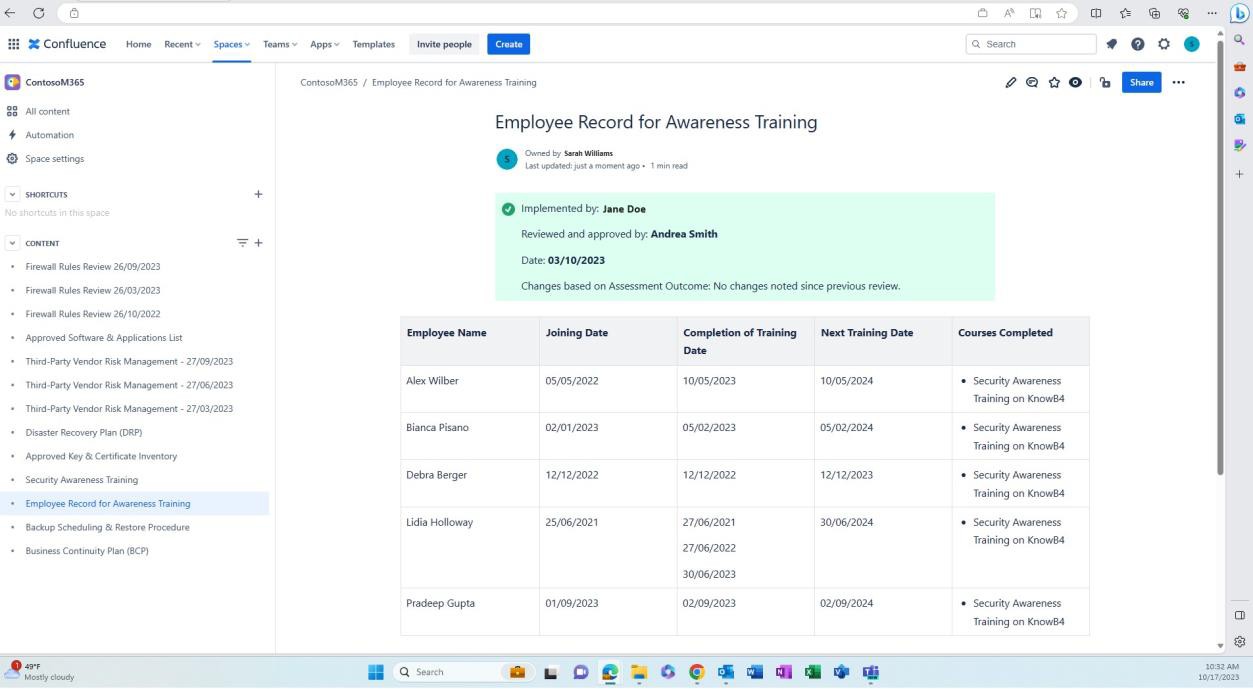
La capture d’écran suivante montre l’historique de l’enregistrement d’entraînement pour chaque utilisateur, y compris sa date de participation, la fin de la formation et le moment où la prochaine formation est planifiée. L’évaluation de ce document est effectuée régulièrement et au moins une fois par an pour s’assurer que les dossiers de formation sur la sensibilisation à la sécurité de chaque employé sont tenus à jour.
Protection contre les programmes malveillants/anti-programmes malveillants
Les programmes malveillants présentent un risque important pour les organisations, ce qui peut varier l’impact sur la sécurité causé à l’environnement opérationnel, en fonction des caractéristiques des programmes malveillants. Les acteurs des menaces ont réalisé que les programmes malveillants peuvent être monétisés avec succès, ce qui a été réalisé grâce à la croissance des attaques de logiciels malveillants de type ransomware. Les programmes malveillants peuvent également être utilisés pour fournir un point d’entrée à un acteur de menace afin de compromettre un environnement afin de voler des données sensibles, c’est-à-dire des chevaux de Troie/Rootkits d’accès à distance. Les organisations doivent donc implémenter des mécanismes appropriés pour se protéger contre ces menaces. Les défenses qui peuvent être utilisées sont l’antivirus (AV)/La détection et la réponse de point de terminaison (EDR)/La détection et la protection des points de terminaison (EDPR)/analyse heuristique à l’aide de l’intelligence artificielle (IA). Si vous avez déployé une autre technique pour atténuer le risque de programmes malveillants, indiquez à l’analyste de certification qui sera heureux d’explorer si cela répond ou non à l’intention.
Contrôle n° 2
Indiquez que votre solution anti-programme malveillant est active et activée sur tous les composants système échantillonnées et configurée pour répondre aux critères suivants :
si l’antivirus que l’analyse sur l’accès est activée et que les signatures sont à jour dans un délai d’un jour.
pour l’antivirus qui bloque automatiquement les programmes malveillants ou les alertes et les mises en quarantaine lorsque des programmes malveillants sont détectés
OU si EDR/EDPR/NGAV :
que l’analyse périodique est effectuée.
génère des journaux d’audit.
est tenu à jour en permanence et dispose de fonctionnalités d’auto-apprentissage.
il bloque les programmes malveillants connus et identifie et bloque les nouvelles variantes de programmes malveillants en fonction des comportements de macro, ainsi que des fonctionnalités d’allocation complète.
Intention : analyse à l’accès
Ce sous-point est conçu pour vérifier que le logiciel anti-programme malveillant est installé sur tous les composants système échantillonné et qu’il effectue activement une analyse à l’accès. Le contrôle exige également que la base de données de signature de la solution anti-programme malveillant soit à jour dans un délai d’un jour. Une base de données de signatures à jour est essentielle pour identifier et atténuer les menaces les plus récentes des programmes malveillants, garantissant ainsi la protection adéquate des composants système.
Recommandations : analyse à l’accès**.**
Pour montrer qu’une instance active d’AV est en cours d’exécution dans l’environnement évalué, fournissez une capture d’écran pour chaque appareil de l’ensemble d’exemples d’appareils convenu avec votre analyste qui prend en charge l’utilisation de logiciels anti-programmes malveillants. La capture d’écran doit montrer que le logiciel anti-programme malveillant est en cours d’exécution et que le logiciel anti-programme malveillant est actif. S’il existe une console de gestion centralisée pour les logiciels anti-programmes malveillants, des preuves de la console de gestion peuvent être fournies. Veillez également à fournir une capture d’écran montrant que les appareils échantillonné sont connectés et fonctionnent.
Exemple de preuve : analyse à l’accès**.**
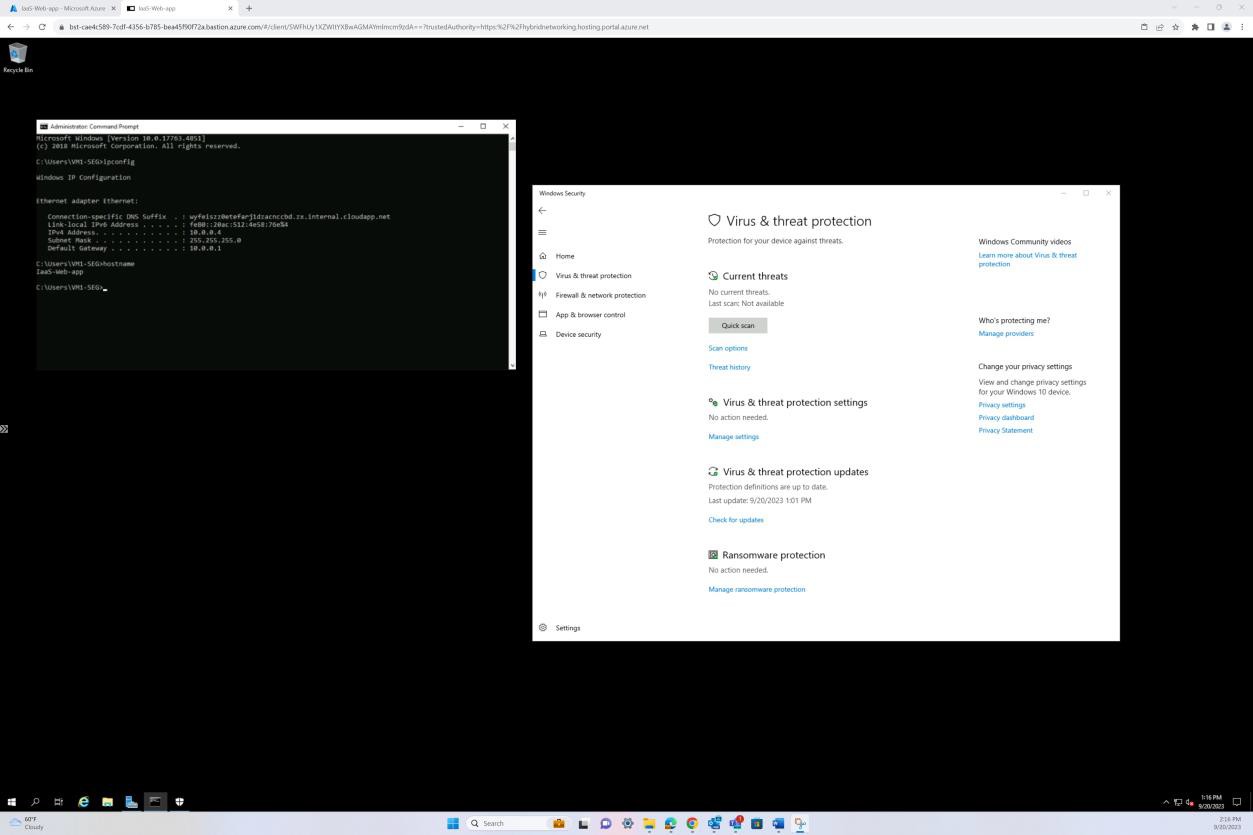
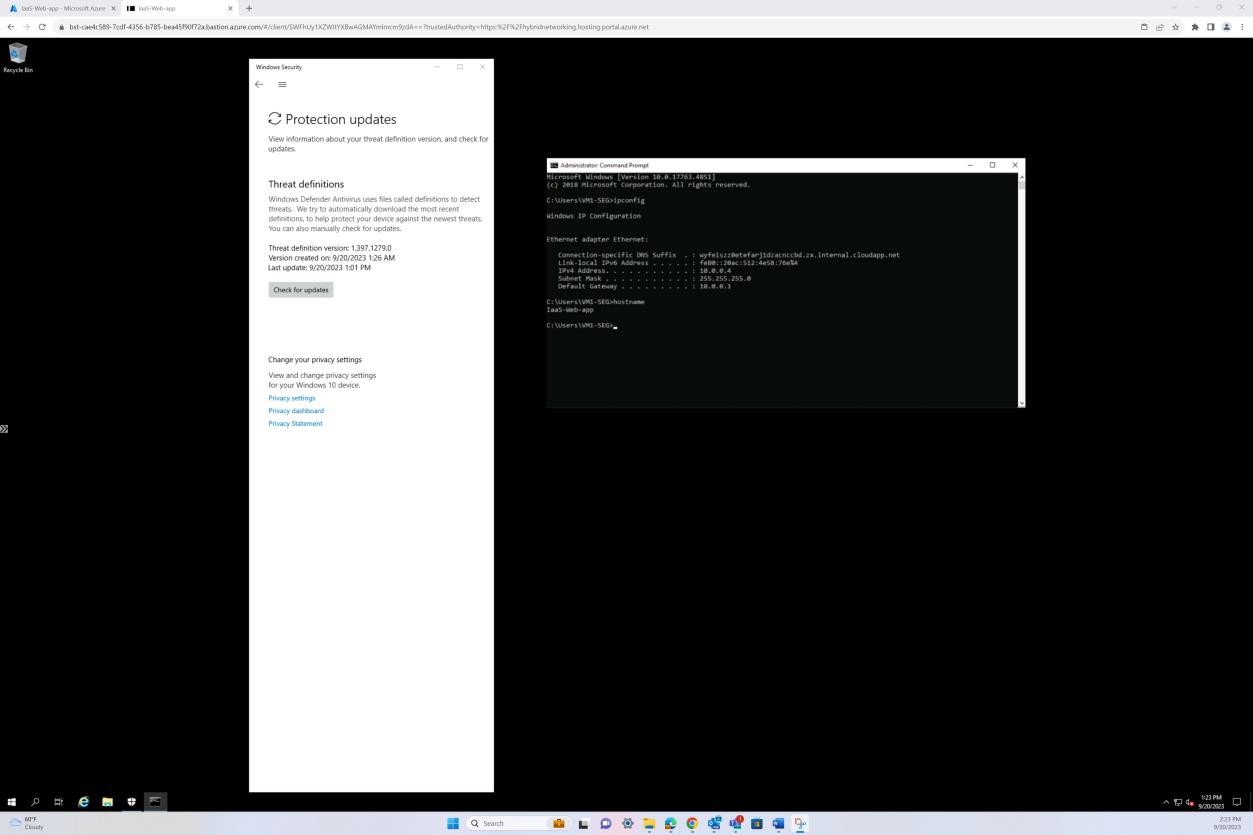
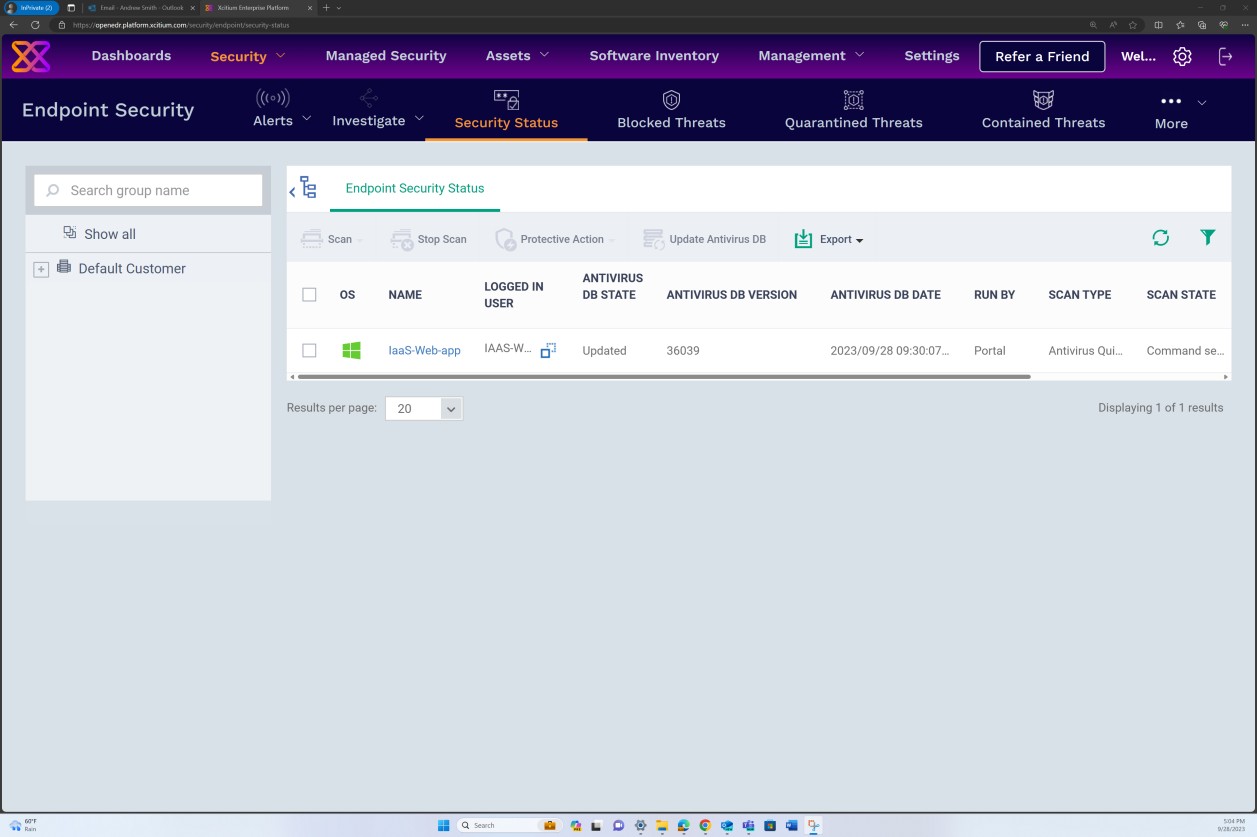
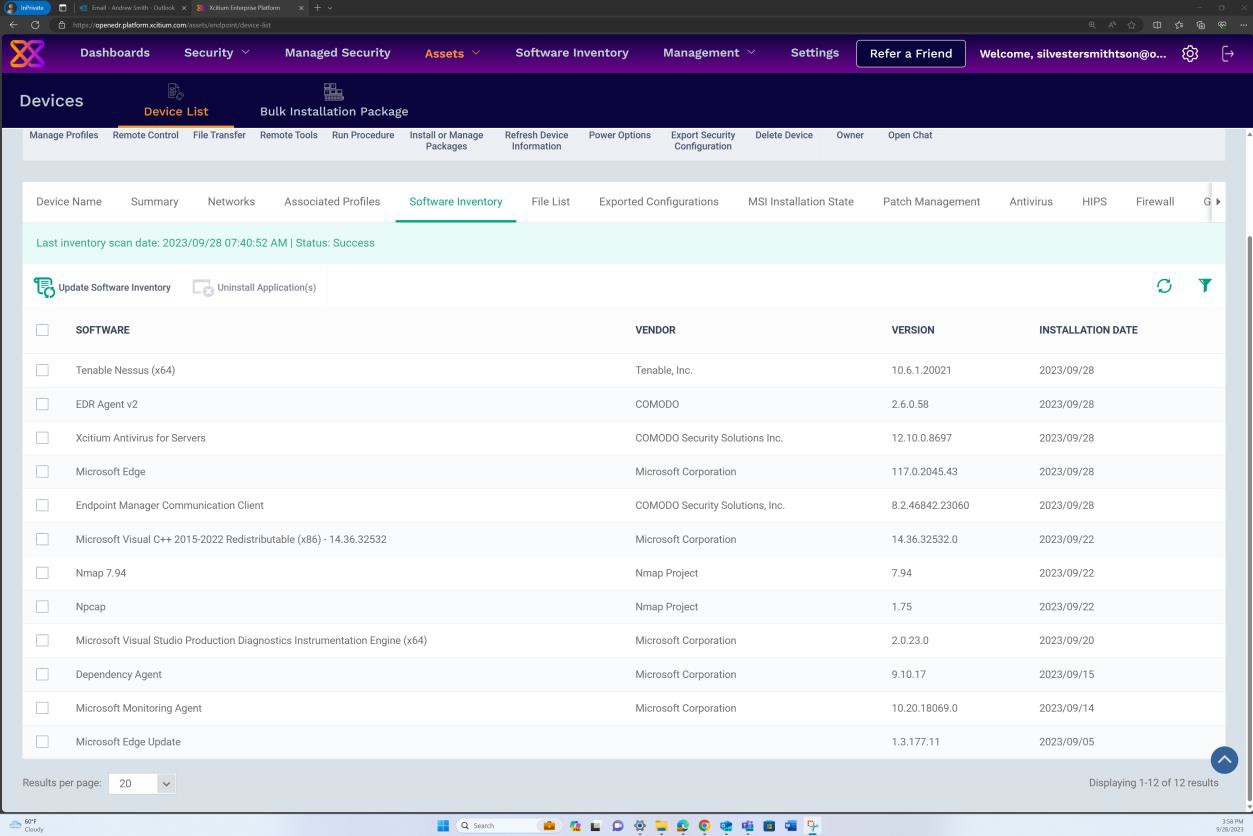
La capture d’écran suivante a été prise à partir d’un appareil Windows Server, montrant que « Microsoft Defender » est activé pour le nom d’hôte « IaaS-Web-app ».
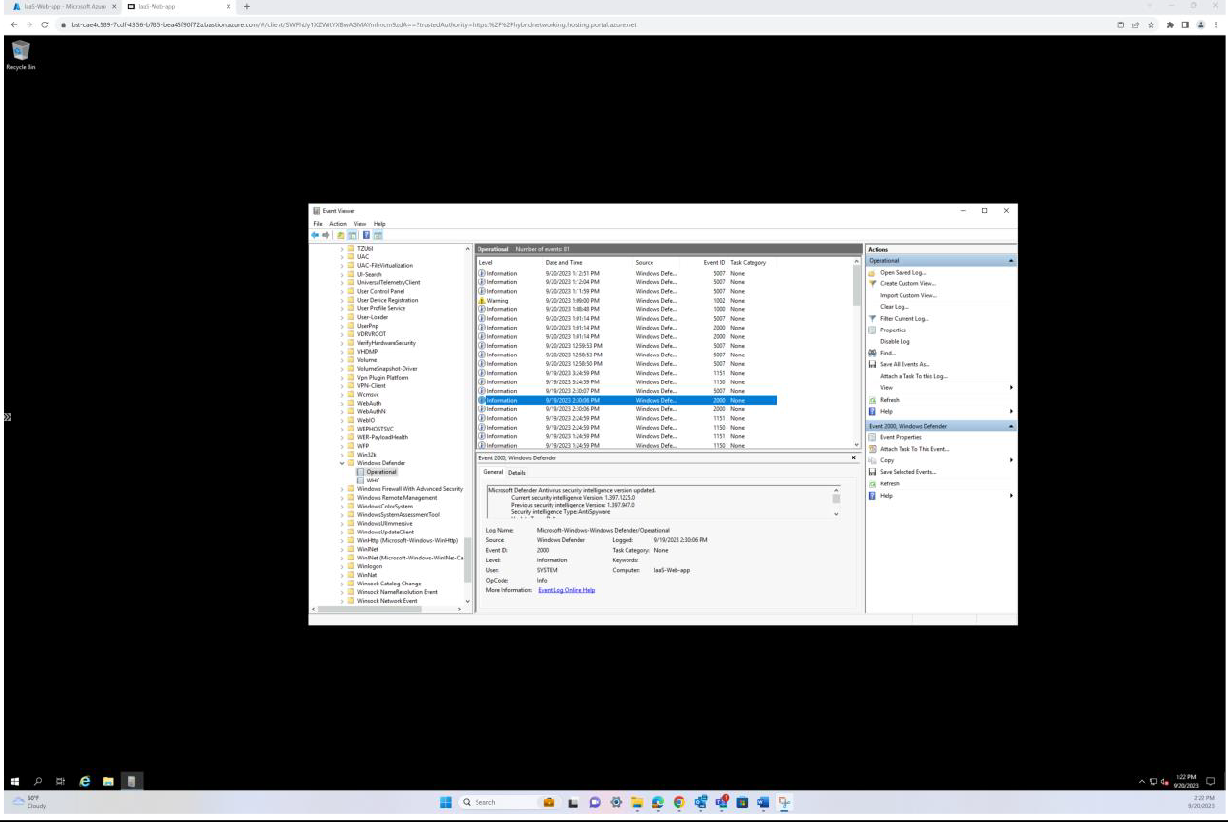
La capture d’écran suivante a été prise à partir d’un appareil Windows Server, montrant que la version de microsoft Defender Antimalware Security Intelligence a mis à jour le journal à partir de l’observateur d’événements Windows. Ceci illustre les dernières signatures pour le nom d’hôte « IaaS-Web-app ».
Cette capture d’écran a été prise à partir d’un appareil Windows Server, montrant les mises à jour de la protection contre les programmes malveillants Microsoft Defender. Cela montre clairement les versions de définition de menace, la version créée sur et la dernière mise à jour pour démontrer que les définitions de programmes malveillants sont à jour pour le nom d’hôte « IaaS-Web-app ».
Intention : blocages anti-programme malveillant.
L’objectif de ce sous-point est de confirmer que le logiciel anti-programme malveillant est configuré pour bloquer automatiquement les programmes malveillants lors de la détection ou générer des alertes et déplacer les programmes malveillants détectés vers une zone de quarantaine sécurisée. Cela peut garantir une action immédiate lorsqu’une menace est détectée, ce qui réduit la fenêtre de vulnérabilité et maintient une posture de sécurité forte du système.
Recommandations : blocages anti-programme malveillant.
Fournissez une capture d’écran pour chaque appareil de l’exemple qui prend en charge l’utilisation d’un logiciel anti-programme malveillant. La capture d’écran doit montrer que l’anti-programme malveillant est en cours d’exécution et qu’il est configuré pour bloquer automatiquement les programmes malveillants, les alertes ou la mise en quarantaine et l’alerte.
Exemple de preuve : blocages anti-programme malveillant.
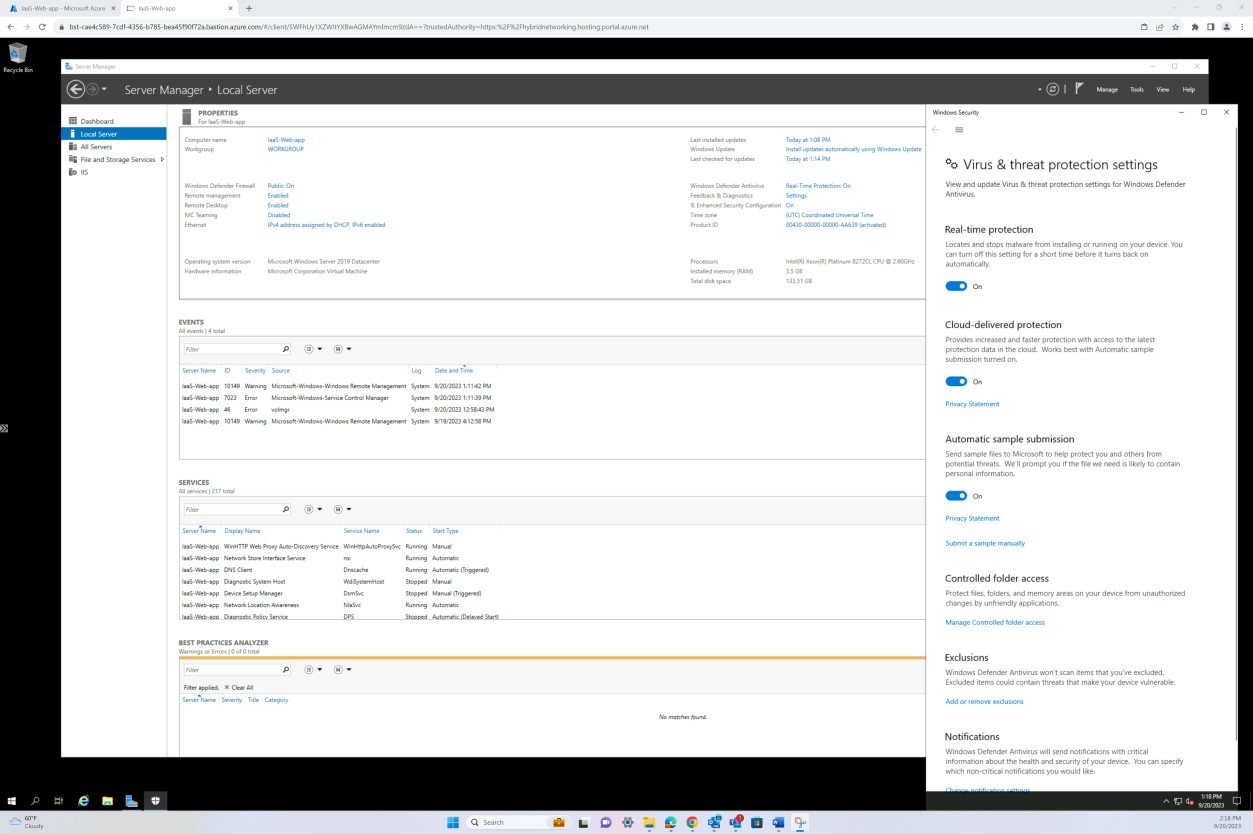
La capture d’écran suivante montre que l’hôte « IaaS-Web-app » est configuré avec une protection en temps réel comme activé pour Microsoft Defender Antimalware. Comme l’indique le paramètre, cela permet de localiser et d’arrêter l’installation ou l’exécution du programme malveillant sur l’appareil.
Intention : EDR/NGAV
Ce sous-point vise à vérifier que la détection et la réponse des points de terminaison (EDR) ou l’antivirus nouvelle génération (NGAV) effectuent activement des analyses périodiques sur tous les composants système échantillonnés. les journaux d’audit sont générés pour le suivi des activités d’analyse et des résultats ; la solution d’analyse est mise à jour en permanence et possède des fonctionnalités d’auto-apprentissage pour s’adapter aux nouveaux paysages des menaces.
Recommandations : EDR/NGAV
Fournissez une capture d’écran de votre solution EDR/NGAV montrant que tous les agents des systèmes échantillonnés sont signalés et montrant que leur état est actif.
Exemple de preuve : EDR/NGAV
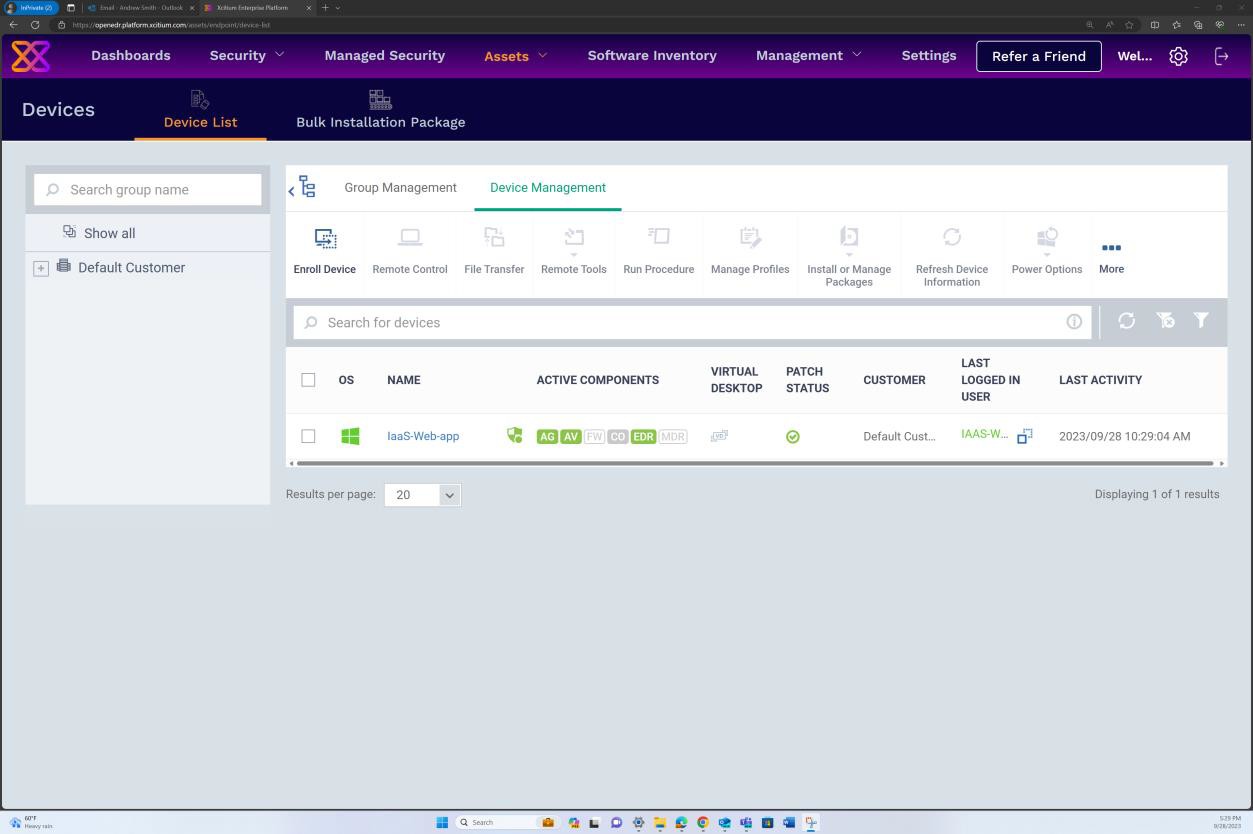
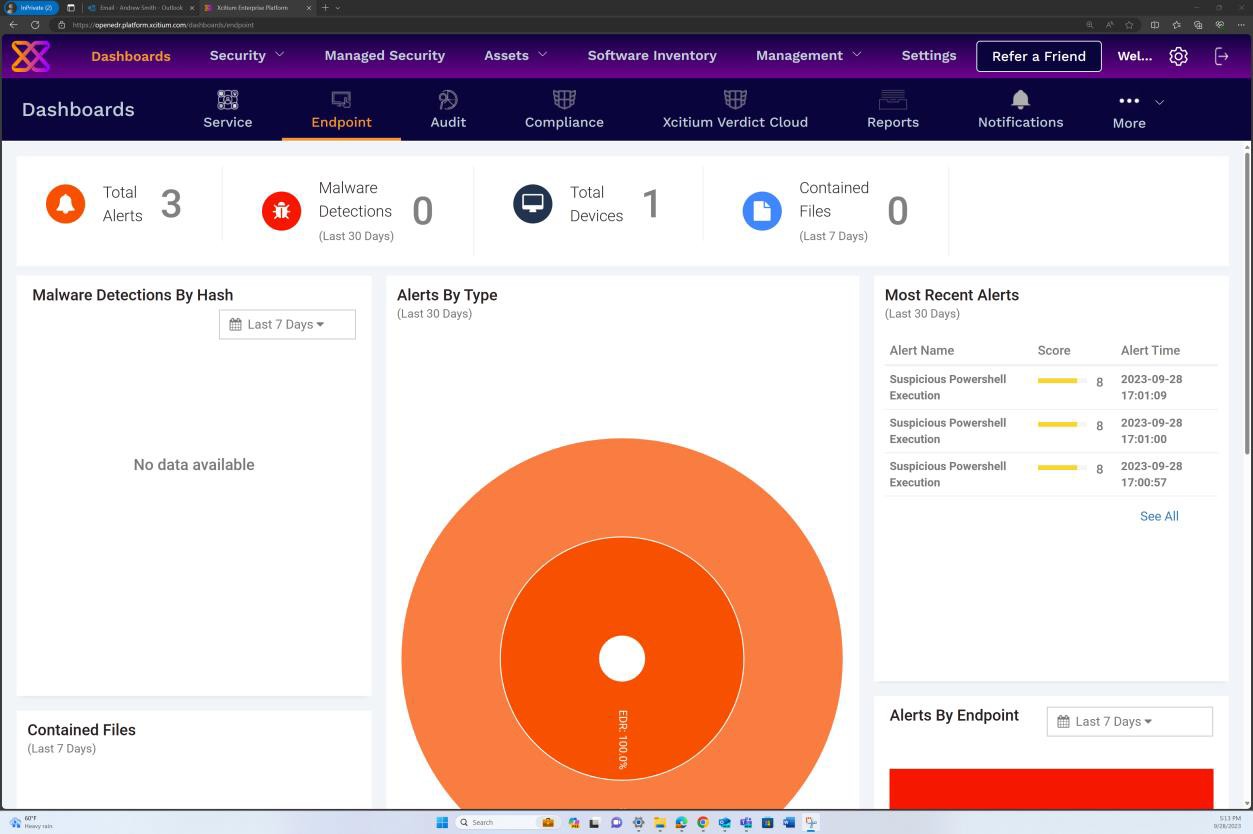
La capture d’écran suivante de la solution OpenEDR montre qu’un agent pour l’hôte « IaaS-Web-app » est actif et qu’il génère des rapports.
La capture d’écran suivante de la solution OpenEDR montre que l’analyse en temps réel est activée.
La capture d’écran suivante montre que les alertes sont générées en fonction des métriques de comportement obtenues en temps réel à partir de l’agent installé au niveau du système.
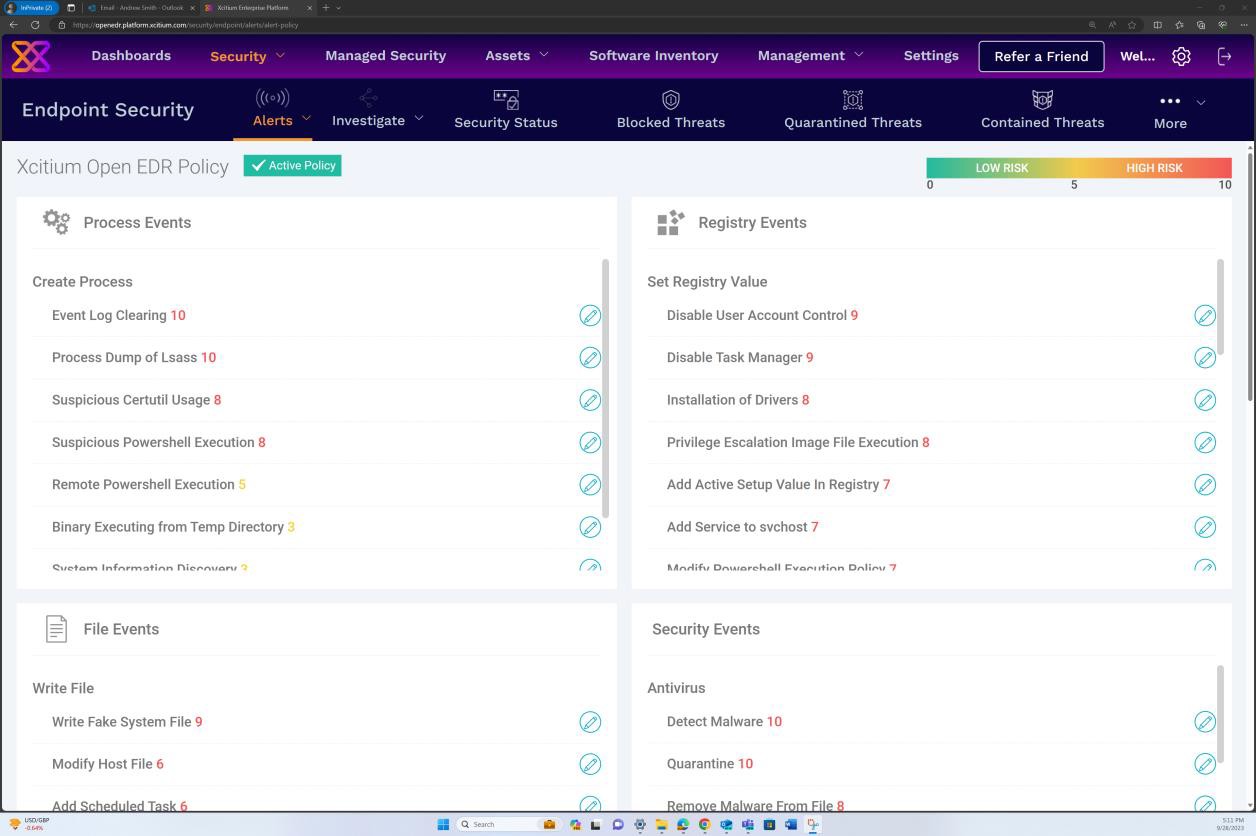
Les captures d’écran suivantes de la solution OpenEDR montrent la configuration et la génération des journaux d’audit et des alertes. La deuxième image montre que la stratégie est activée et que les événements sont configurés.
La capture d’écran suivante de la solution OpenEDR montre que la solution est continuellement à jour.
Intention : EDR/NGAV
L’objectif de ce sous-point est de s’assurer que EDR/NGAV ont la capacité de bloquer automatiquement les programmes malveillants connus et d’identifier et de bloquer les nouvelles variantes de programmes malveillants en fonction des comportements de macro. Il garantit également que la solution dispose de toutes les fonctionnalités d’approbation, ce qui permet à l’organisation d’autoriser les logiciels approuvés tout en bloquant tout le reste, ajoutant ainsi une couche supplémentaire de sécurité.
Recommandations : EDR/NGAV
Selon le type de solution utilisé, vous pouvez fournir des preuves montrant les paramètres de configuration de la solution et que la solution dispose de fonctionnalités Machine Learning/heuristique, ainsi que d’être configurée pour bloquer les programmes malveillants lors de la détection. Si la configuration est implémentée par défaut sur la solution, elle doit être validée par la documentation du fournisseur.
Exemple de preuve : EDR/NGAV
Les captures d’écran suivantes de la solution OpenEDR montrent qu’un profil sécurisé v7.4 est configuré pour appliquer l’analyse en temps réel, bloquer les programmes malveillants et la mise en quarantaine.
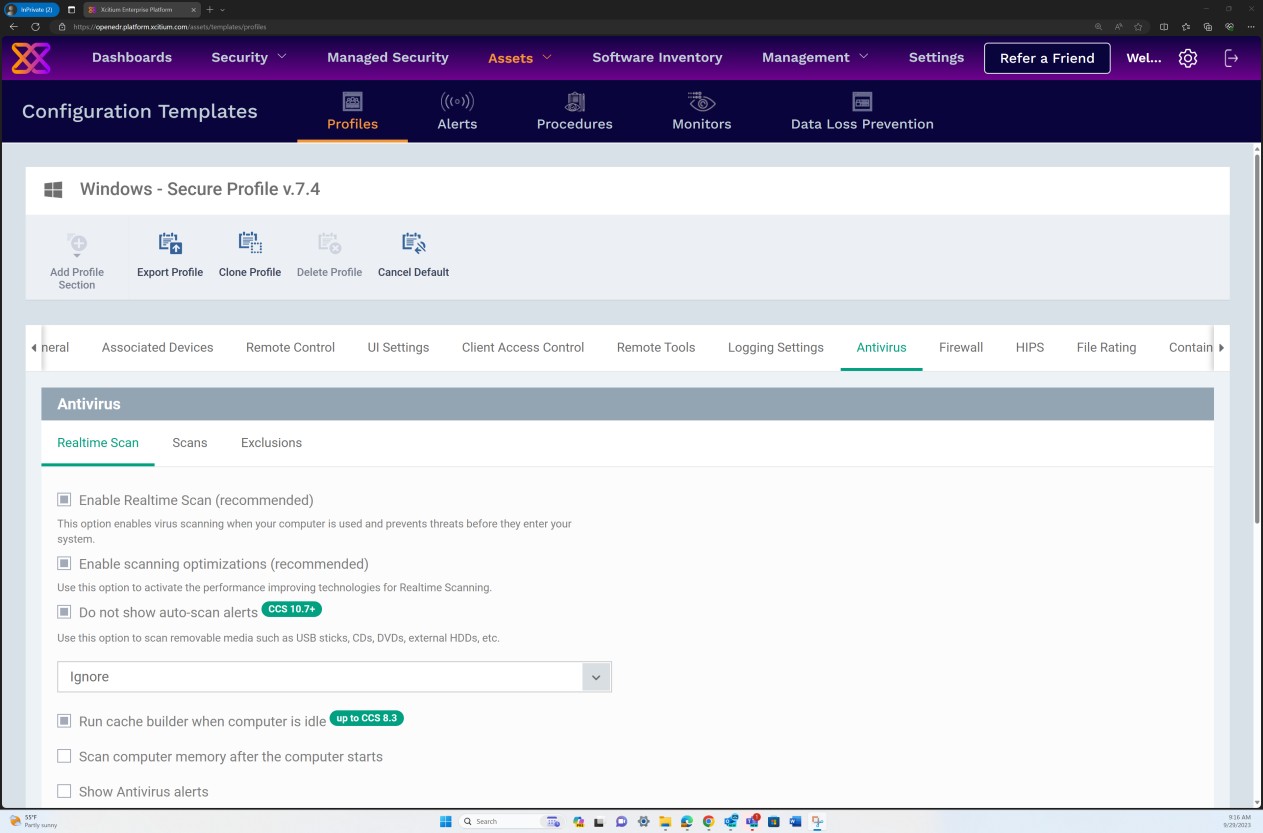
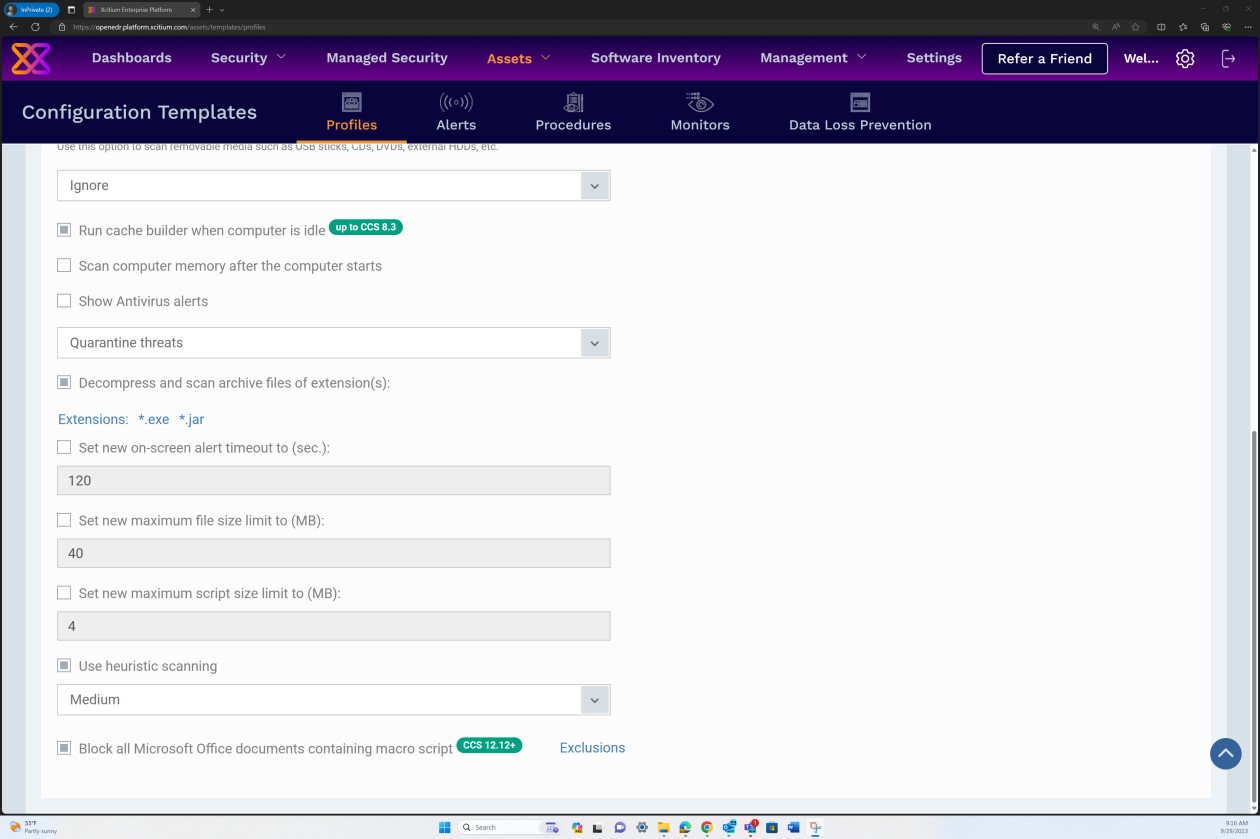
Les captures d’écran suivantes de la configuration Secure Profile v7.4 montrent que la solution implémente à la fois l’analyse « Realtime » basée sur une approche anti-programme malveillant plus traditionnelle, qui recherche les signatures de programmes malveillants connues, et l’analyse « Heuristics » définie sur un niveau moyen. La solution détecte et supprime les logiciels malveillants en vérifiant les fichiers et le code qui se comportent de manière suspecte/inattendue ou malveillante.
Le scanneur est configuré pour décompresser les archives et analyser les fichiers à l’intérieur afin de détecter les programmes malveillants potentiels qui peuvent se masquer sous l’archive. En outre, le scanneur est configuré pour bloquer les micro-scripts dans les fichiers Microsoft Office.
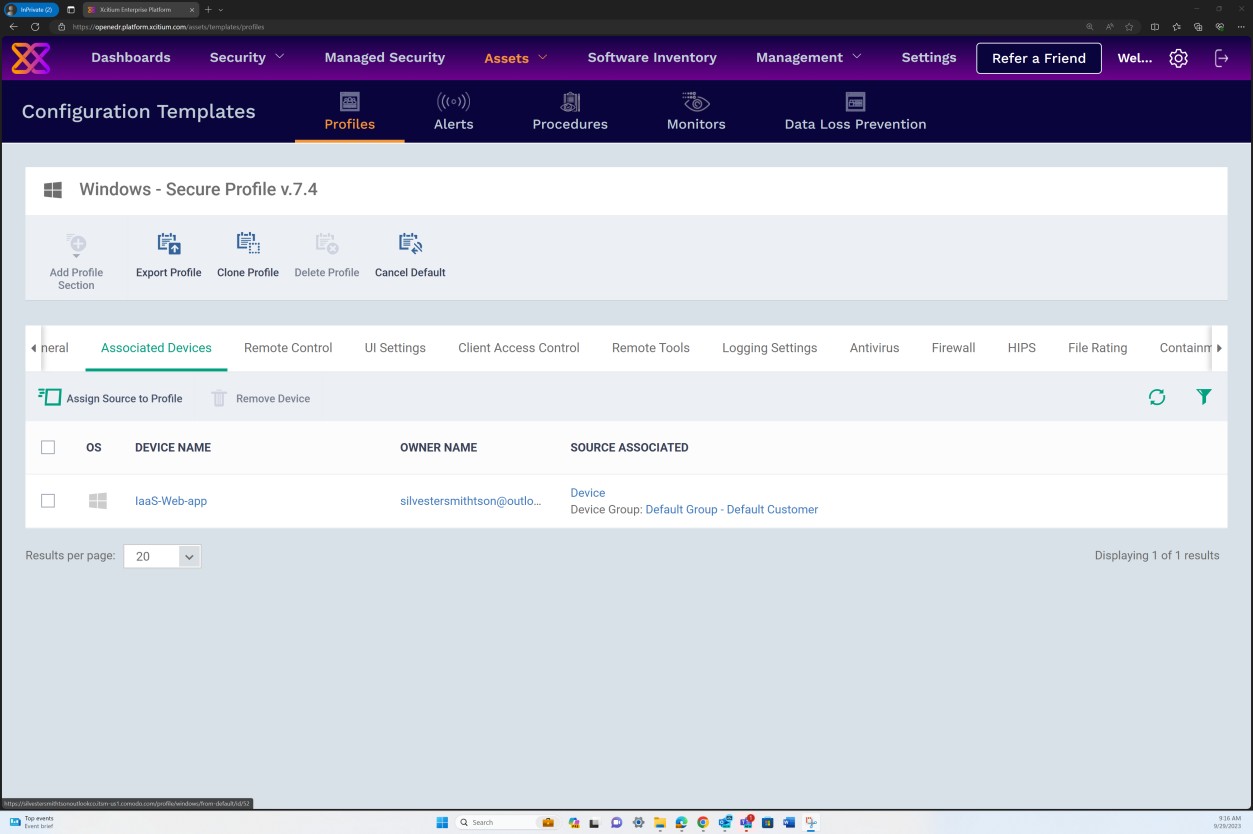
Les captures d’écran suivantes montrent que Secure Profile v.7.4 a été affecté à notre hôte d’appareil Windows Server « IaaS-Web-app ».
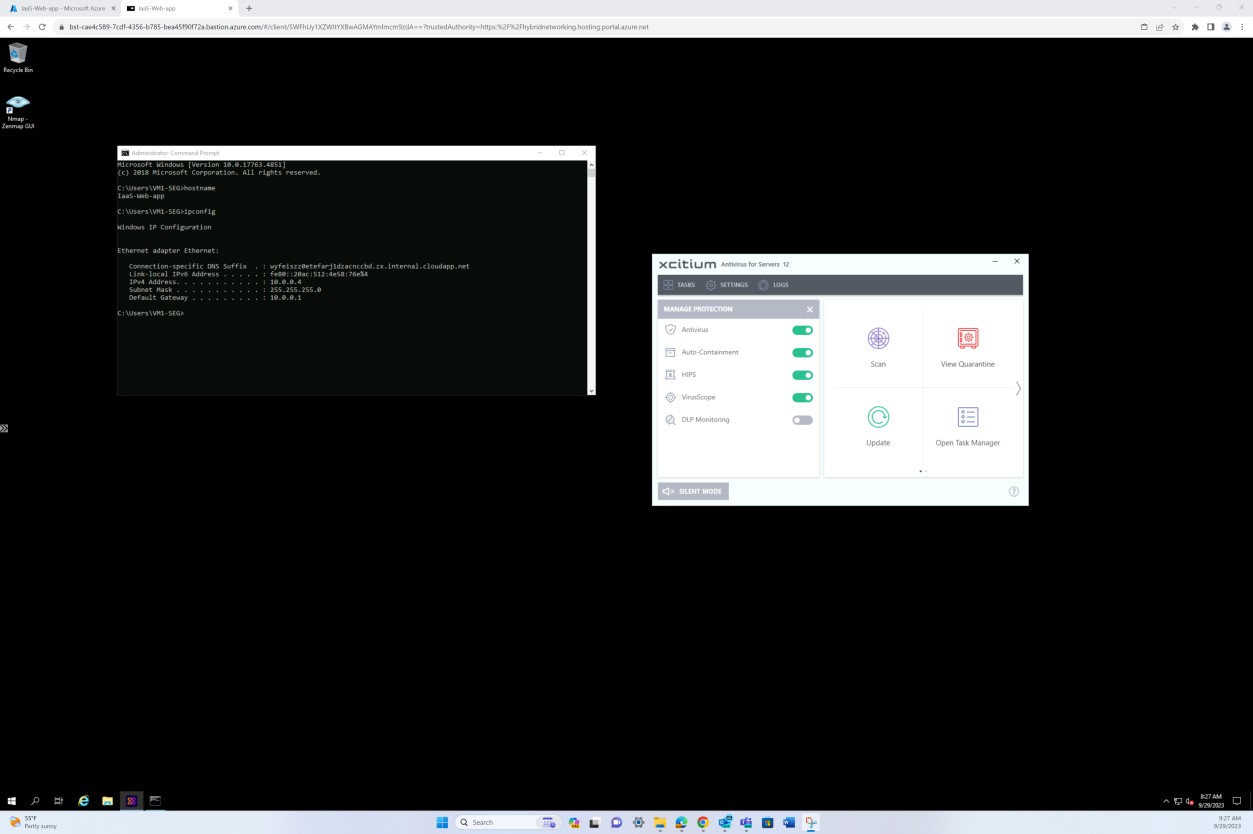
La capture d’écran suivante a été prise à partir de l’appareil Windows Server « IaaS-Web-app », qui a montré que l’agent OpenEDR est activé et en cours d’exécution sur l’hôte.
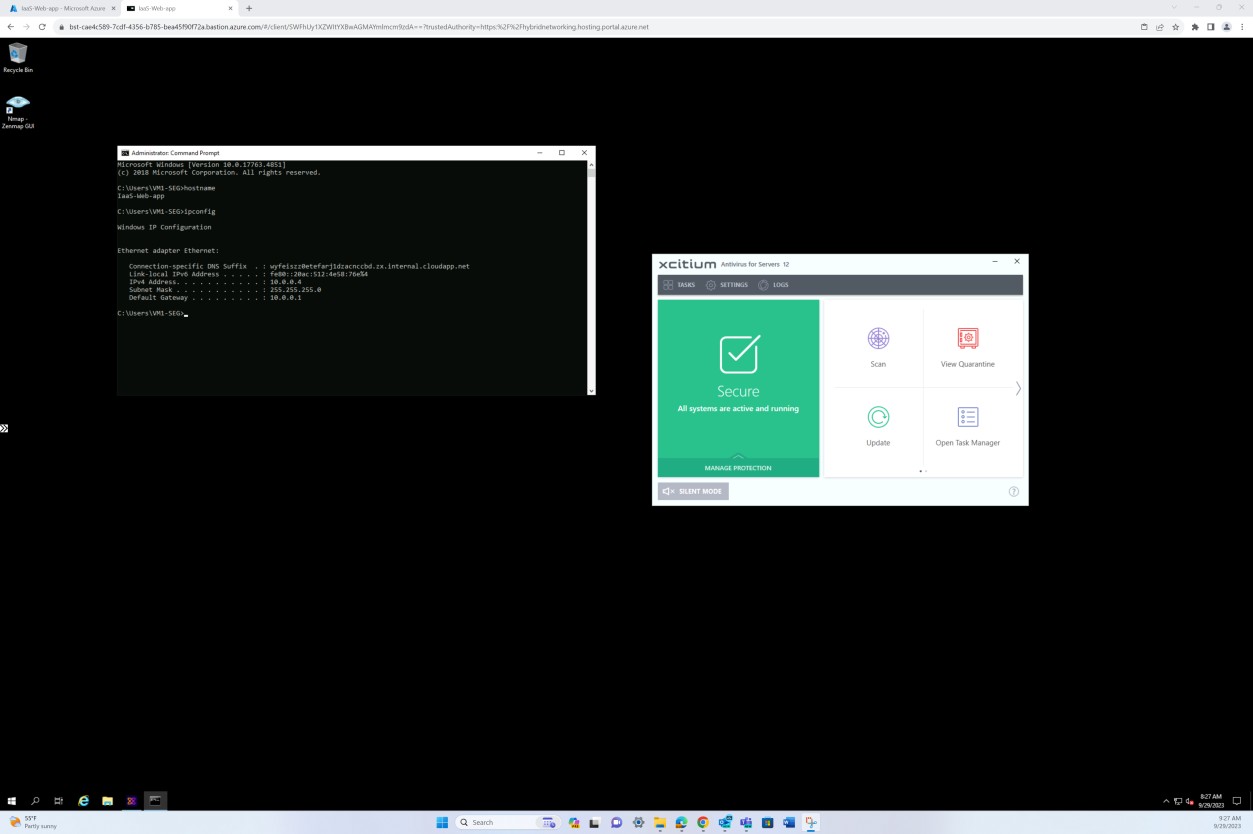
Protection contre les programmes malveillants/contrôle des applications
Le contrôle d’application est une pratique de sécurité qui bloque ou restreint l’exécution des applications non autorisées de manière à mettre les données en danger. Les contrôles d’application sont une partie importante d’un programme de sécurité d’entreprise et peuvent aider à empêcher les acteurs malveillants d’exploiter les vulnérabilités des applications et à réduire le risque de violation. En implémentant le contrôle des applications, les entreprises et les organisations peuvent réduire considérablement les risques et les menaces associés à l’utilisation des applications, car les applications ne peuvent pas s’exécuter si elles mettent le réseau ou les données sensibles en danger. Les contrôles d’application fournissent aux équipes chargées des opérations et de la sécurité une approche fiable, standardisée et systématique pour atténuer les cyber-risques. Ils fournissent également aux organisations une image plus complète des applications dans leur environnement, ce qui peut aider les organisations informatiques et de sécurité à gérer efficacement les cyber-risques.
Contrôle n° 3
Fournissez des preuves démontrant que :
Vous disposez d’une liste approuvée de logiciels/applications avec justification métier :
existe et est maintenu à jour, et
que chaque application subit un processus d’approbation et d’approbation avant son déploiement.
Cette technologie de contrôle d’application est active, activée et configurée sur tous les composants système échantillonnés, comme indiqué.
Intention : liste des logiciels
Ce sous-point vise à s’assurer qu’une liste approuvée de logiciels et d’applications existe au sein de l’organisation et qu’elle est continuellement mise à jour. Vérifiez que chaque logiciel ou application de la liste dispose d’une justification métier documentée pour valider sa nécessité. Cette liste sert de référence faisant autorité pour réglementer le déploiement de logiciels et d’applications, ce qui permet d’éliminer les logiciels non autorisés ou redondants susceptibles de poser un risque pour la sécurité.
Recommandations : liste des logiciels
Document contenant la liste approuvée des logiciels et des applications s’il est conservé en tant que document numérique (Word, PDF, etc.). Si la liste approuvée des logiciels et des applications est conservée via une plateforme, des captures d’écran de la liste de la plateforme doivent être fournies.
Exemple de preuve : liste de logiciels
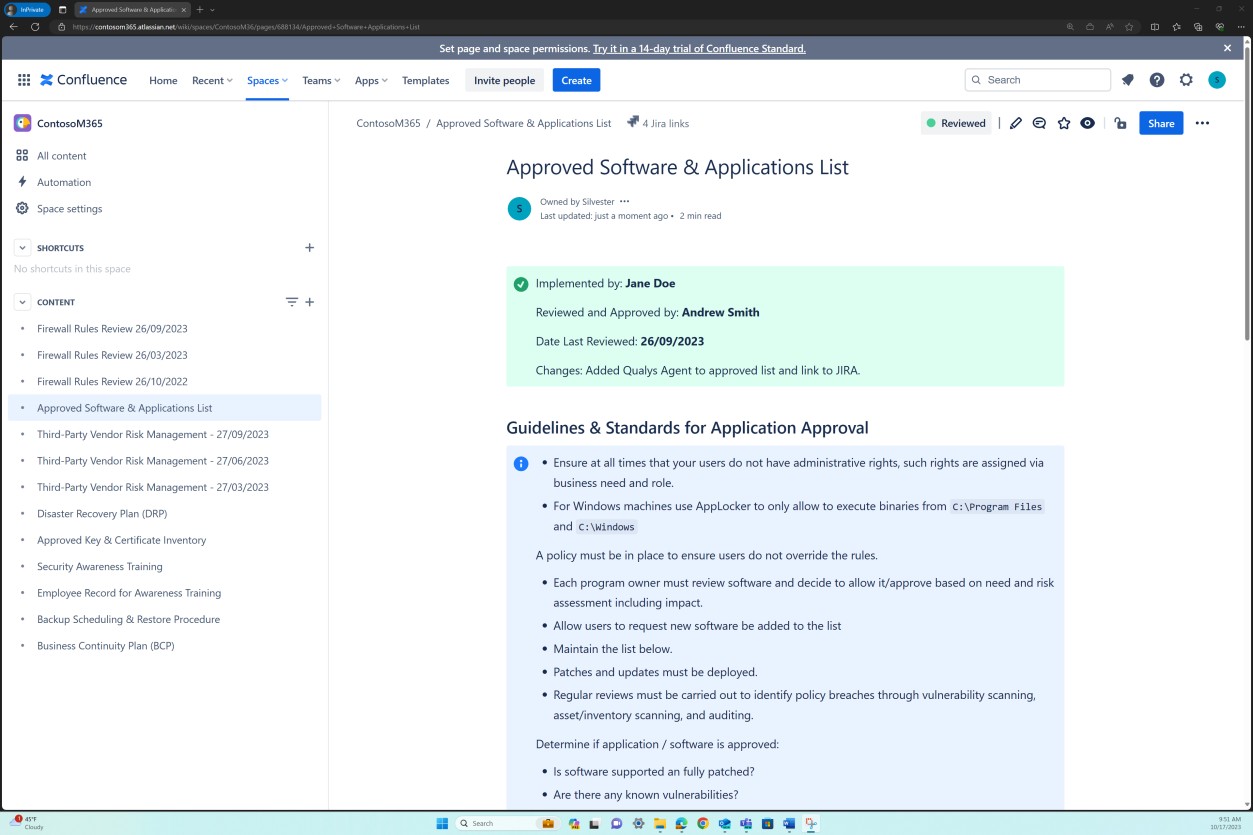
Les captures d’écran suivantes montrent qu’une liste de logiciels et d’applications approuvés est conservée dans la plateforme Confluence Cloud.
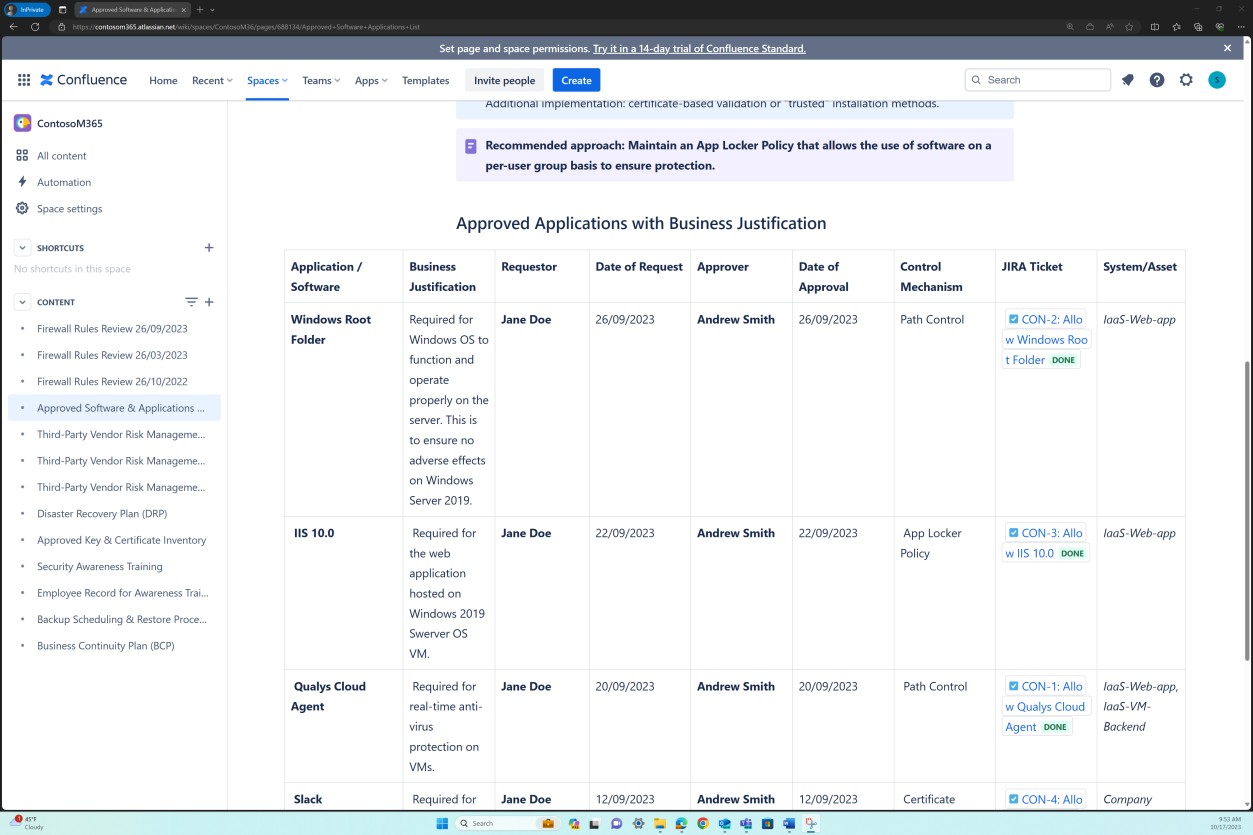
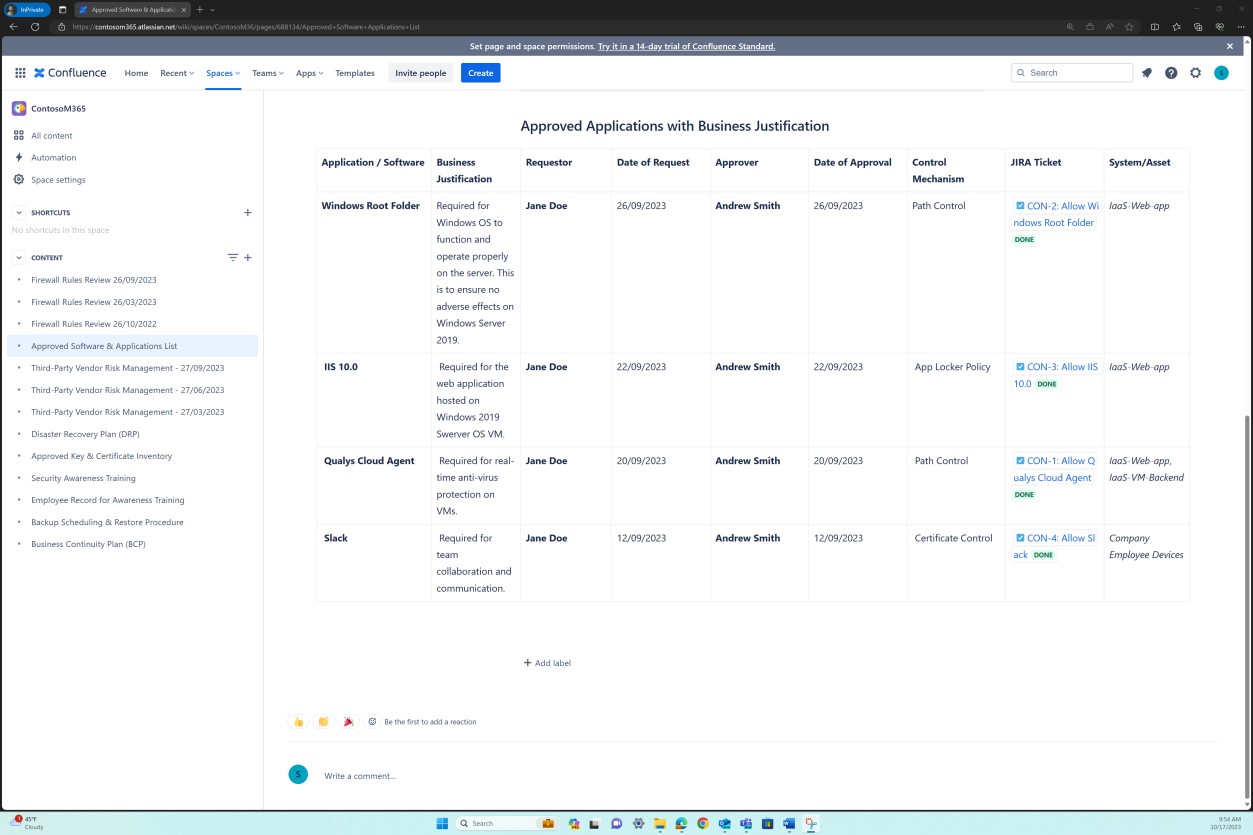
Les captures d’écran suivantes montrent que la liste des logiciels et applications approuvés, y compris le demandeur, la date de la demande, l’approbateur, la date d’approbation, le mécanisme de contrôle, le ticket JIRA, le système/la ressource, est conservée.
Intention : approbation du logiciel
L’objectif de ce sous-point est de confirmer que chaque logiciel/application fait l’objet d’un processus d’approbation formel avant son déploiement au sein de l’organisation. Le processus d’approbation doit inclure une évaluation technique et une approbation de la direction, afin de s’assurer que les perspectives opérationnelles et stratégiques ont été prises en compte. En mettant en place ce processus rigoureux, l’organisation s’assure que seuls les logiciels vérifiés et nécessaires sont déployés, ce qui réduit les vulnérabilités de sécurité et garantit l’alignement sur les objectifs de l’entreprise.
Conseils
Vous pouvez fournir des preuves indiquant que le processus d’approbation est suivi. Cela peut être fourni au moyen de documents signés, d’un suivi dans les systèmes de contrôle des modifications ou à l’aide de quelque chose comme Azure DevOps/JIRA pour suivre les demandes de modification et l’autorisation.
Exemple de preuve
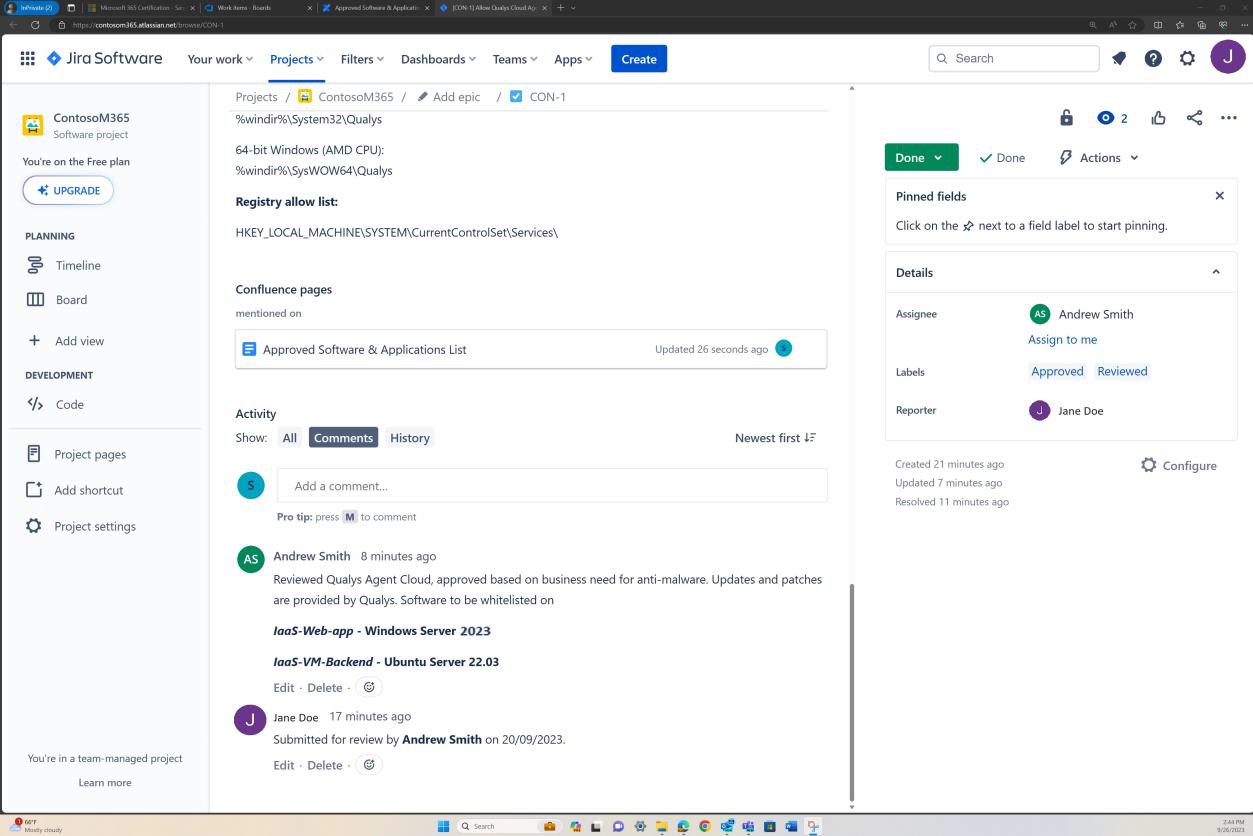
Les captures d’écran suivantes illustrent un processus d’approbation complet dans JIRA Software. Un utilisateur « Jane Doe » a déclenché une demande d’installation de l’agent cloud Qualys sur les serveurs « IaaS-Web-app » et « IaaS-VM- Backend ». « Andrew Smith » a examiné la demande et l’a approuvée avec le commentaire « approuvé en fonction des besoins de l’entreprise pour anti-programme malveillant. Mises à jour et correctifs fournis par Qualys. Logiciel à approuver.
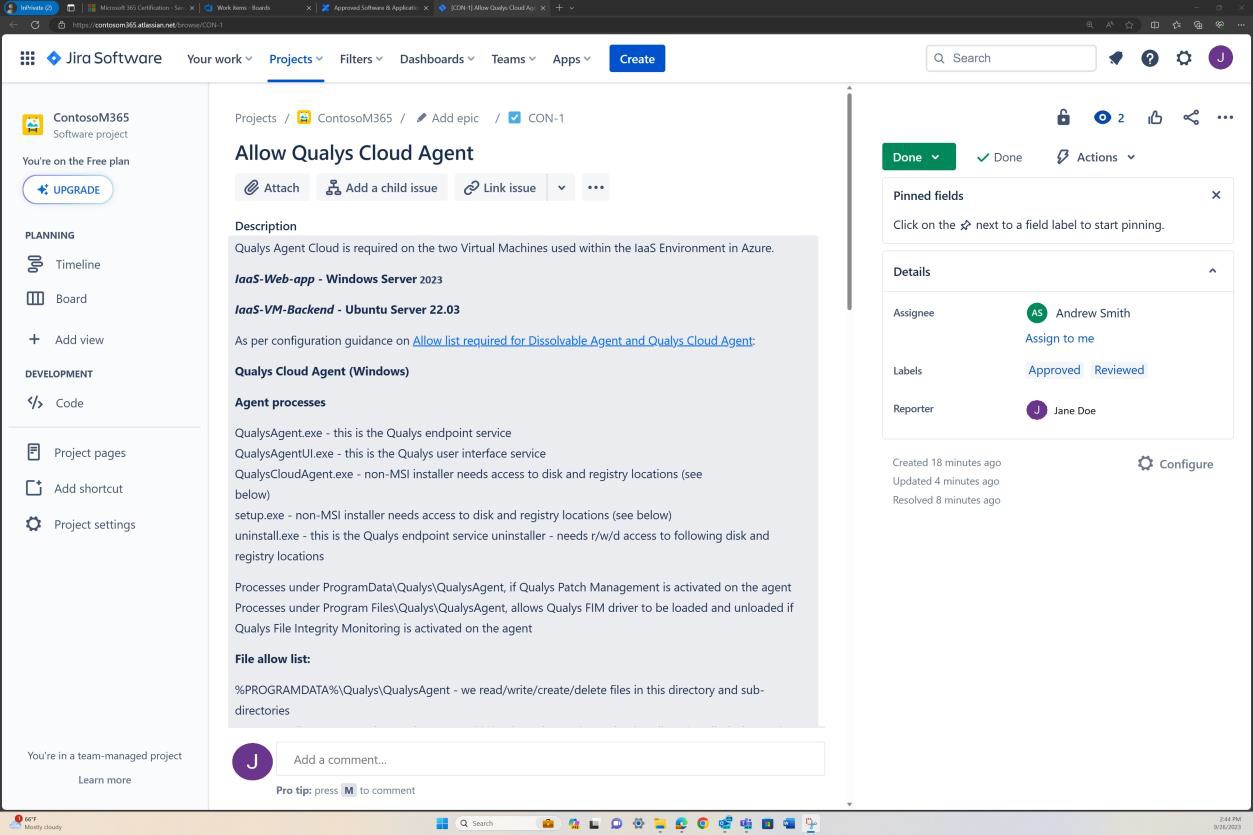
La capture d’écran suivante montre l’approbation accordée via le ticket déclenché sur la plateforme Confluence avant d’autoriser l’application à s’exécuter sur le serveur de production.
Intention : technologie de contrôle d’application
Ce sous-point se concentre sur la vérification que la technologie de contrôle d’application est active, activée et correctement configurée sur tous les composants système échantillonnées. S’assurer que la technologie fonctionne conformément aux politiques et procédures documentées, qui servent de lignes directrices pour sa mise en œuvre et sa maintenance. En disposant d’une technologie de contrôle d’application active, activée et bien configurée, l’organisation peut empêcher l’exécution de logiciels non autorisés ou malveillants et améliorer la posture de sécurité globale du système.
Recommandations : technologie de contrôle d’application
Fournissez une documentation détaillant comment le contrôle d’application a été configuré et des preuves de la technologie applicable montrant comment chaque application/processus a été configuré.
Exemple de preuve : technologie de contrôle d’application
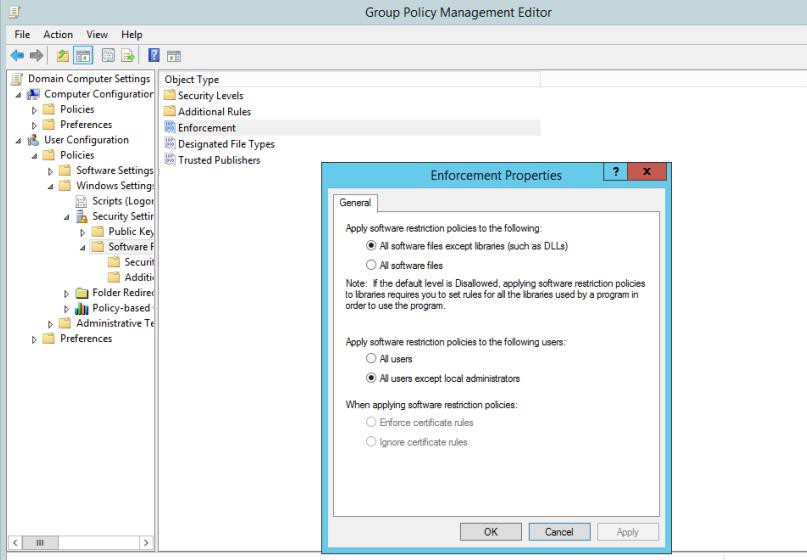
Les captures d’écran suivantes montrent que les stratégies de groupe Windows (GPO) sont configurées pour appliquer uniquement les logiciels et applications approuvés.
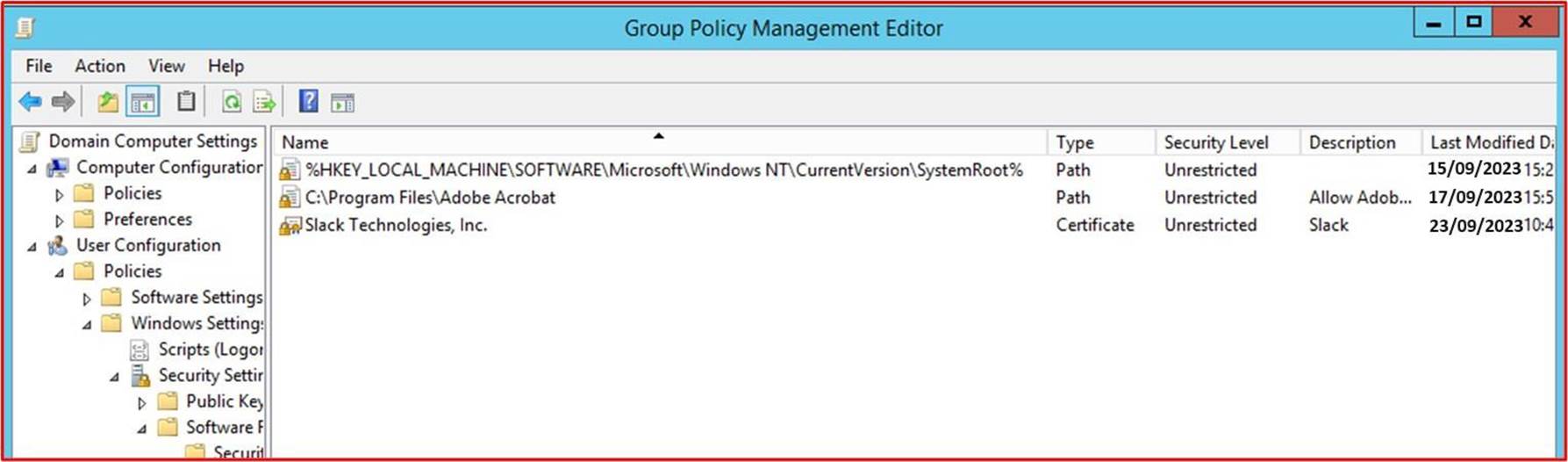
La capture d’écran suivante montre les logiciels/applications autorisés à s’exécuter via le contrôle de chemin d’accès.
Remarque : Dans ces exemples, les captures d’écran complètes n’ont pas été utilisées, mais toutes les captures d’écran de preuve envoyées par l’éditeur de logiciels indépendant doivent être des captures d’écran en plein écran montrant n’importe quelle URL, l’utilisateur connecté, ainsi que l’heure et la date système.
Gestion/mise à jour corrective et classement des risques
La gestion des correctifs, souvent appelée mise à jour corrective, est un composant essentiel de toute stratégie de cybersécurité robuste. Cela implique le processus systématique d’identification, de test et d’application de correctifs ou de mises à jour aux logiciels, systèmes d’exploitation et applications. L’objectif principal de la gestion des correctifs est d’atténuer les vulnérabilités de sécurité, en veillant à ce que les systèmes et les logiciels restent résilients contre les menaces potentielles. En outre, la gestion des correctifs englobe le classement des risques un élément essentiel dans la hiérarchisation des correctifs. Cela implique d’évaluer les vulnérabilités en fonction de leur gravité et de leur impact potentiel sur la posture de sécurité d’une organisation. En affectant des scores de risque aux vulnérabilités, les organisations peuvent allouer des ressources efficacement, en concentrant leurs efforts sur la résolution rapide des vulnérabilités critiques et à haut risque tout en conservant une position proactive face aux menaces émergentes. Une stratégie efficace de gestion des correctifs et de classement des risques non seulement améliore la sécurité, mais contribue également à la stabilité et aux performances globales de l’infrastructure informatique, aidant les organisations à rester résilientes dans le paysage en constante évolution des menaces de cybersécurité.
Pour maintenir un environnement d’exploitation sécurisé, les applications/modules complémentaires et les systèmes de prise en charge doivent être correctement corrigés. Un délai approprié entre l’identification (ou la mise en production publique) et la mise à jour corrective doit être géré pour réduire la fenêtre d’opportunité pour qu’une vulnérabilité soit exploitée par un acteur de menace. La certification Microsoft 365 ne prévoit pas de « fenêtre de mise à jour corrective » ; Toutefois, les analystes de certification rejetteront les délais qui ne sont pas raisonnables ou conformes aux meilleures pratiques du secteur. Ce groupe de contrôle de sécurité est également dans l’étendue des environnements d’hébergement PaaS (Platform-as-a-Service), car les bibliothèques de logiciels tiers d’application/complément et la base de code doivent être corrigées en fonction du classement des risques.
Contrôle n° 4
Indiquez que la documentation sur la stratégie et la procédure de gestion des correctifs définissent toutes les opérations suivantes :
Fenêtre de mise à jour corrective minimale appropriée pour les vulnérabilités à risque critique/élevé et moyen.
Désaffectation des systèmes d’exploitation et logiciels non pris en charge.
Comment les nouvelles vulnérabilités de sécurité sont identifiées et affectées à un score de risque.
Intention : gestion des correctifs
La gestion des correctifs est requise par de nombreuses infrastructures de conformité de sécurité, par exemple PCI-DSS, ISO 27001, NIST (SP) 800-53, FedRAMP et SOC 2. L’importance d’une bonne gestion des correctifs ne peut pas être trop soulignée
car il peut corriger les problèmes de sécurité et de fonctionnalité dans les logiciels, les microprogrammes et atténuer les vulnérabilités, ce qui contribue à réduire les opportunités d’exploitation. L’objectif de ce contrôle est de réduire la fenêtre d’opportunité d’un acteur de menace, afin d’exploiter les vulnérabilités qui peuvent exister dans l’environnement dans l’étendue.
Fournissez une documentation sur la stratégie et les procédures de gestion des correctifs qui couvrent de manière complète les aspects suivants :
Fenêtre de mise à jour corrective minimale appropriée pour les vulnérabilités à risque critique/élevé et moyen.
La stratégie et la procédure de gestion des correctifs de l’organisation doivent clairement définir une fenêtre de mise à jour corrective minimale appropriée pour les vulnérabilités classées comme des risques critiques/élevés et moyens. Une telle disposition établit la durée maximale autorisée pendant laquelle les correctifs doivent être appliqués après l’identification d’une vulnérabilité, en fonction de son niveau de risque. En spécifiant explicitement ces délais, l’organisation a normalisé son approche de gestion des correctifs, réduisant ainsi le risque associé aux vulnérabilités non corrigées.
Désaffectation des systèmes d’exploitation et logiciels non pris en charge.
La stratégie de gestion des correctifs comprend des dispositions pour la désaffectation des systèmes d’exploitation et des logiciels non pris en charge. Les systèmes d’exploitation et les logiciels qui ne reçoivent plus de mises à jour de sécurité posent un risque significatif pour la posture de sécurité d’une organisation. Par conséquent, ce contrôle garantit que ces systèmes sont identifiés et supprimés ou remplacés en temps voulu, comme défini dans la documentation de la stratégie.
- Procédure documentée décrivant la façon dont les nouvelles vulnérabilités de sécurité sont identifiées et affectées à un score de risque.
La mise à jour corrective doit être basée sur le risque, plus la vulnérabilité est risquée, plus rapidement elle doit être corrigée. Le classement des risques des vulnérabilités identifiées fait partie intégrante de ce processus. L’objectif de ce contrôle est de s’assurer qu’il existe un processus de classement des risques documenté qui est suivi pour s’assurer que toutes les vulnérabilités identifiées sont correctement classées en fonction du risque. Les organisations utilisent généralement la classification CVSS (Common Vulnerability Scoring System) fournie par les fournisseurs ou les chercheurs en sécurité. Il est recommandé que si les organisations s’appuient sur CVSS, un mécanisme de re-classement soit inclus dans le processus pour permettre à l’organisation de modifier le classement en fonction d’une évaluation des risques interne. Parfois, la vulnérabilité peut ne pas être applicable en raison de la façon dont l’application a été déployée dans l’environnement. Par exemple, une vulnérabilité Java peut être libérée et avoir un impact sur une bibliothèque spécifique qui n’est pas utilisée par l’organisation.
Remarque : Même si vous exécutez dans un environnement « PaaS/Serverless » purement platform as a service, vous avez toujours la responsabilité d’identifier les vulnérabilités au sein de votre base de code : c’est-à-dire les bibliothèques tierces.
Recommandations : gestion des correctifs
Fournissez le document de stratégie. Des preuves administratives telles que la documentation de stratégie et de procédure détaillant les processus définis de l’organisation qui couvrent tous les éléments du contrôle donné doivent être fournies.
Remarque : cette preuve logique peut être fournie comme preuve à l’appui, ce qui fournira des informations supplémentaires sur le programme de gestion des vulnérabilités (VMP) de votre organisation, mais il ne remplira pas ce contrôle en soi.
Exemple de preuve : gestion des correctifs
La capture d’écran suivante montre un extrait de code d’une stratégie de gestion des correctifs/classement des risques, ainsi que les différents niveaux de catégories de risque. Ceci est suivi par les délais de classification et de correction. Remarque : Les éditeurs de logiciels indépendants doivent partager la documentation réelle sur la stratégie/procédure de prise en charge et ne pas simplement fournir une capture d’écran.


Exemple de preuve technique supplémentaire (facultatif) à l’appui du document de stratégie
Des preuves logiques telles que des feuilles de calcul de suivi des vulnérabilités, des rapports d’évaluation technique des vulnérabilités ou des captures d’écran de tickets générés via des plateformes de gestion en ligne pour suivre l’état et la progression des vulnérabilités utilisées pour prendre en charge l’implémentation du processus décrit dans la documentation de stratégie à fournir. La capture d’écran suivante montre que Snyk, qui est un outil d’analyse de composition logicielle (SCA), est utilisé pour analyser la base de code à la recherche de vulnérabilités. Cette opération est suivie d’une notification par e-mail.
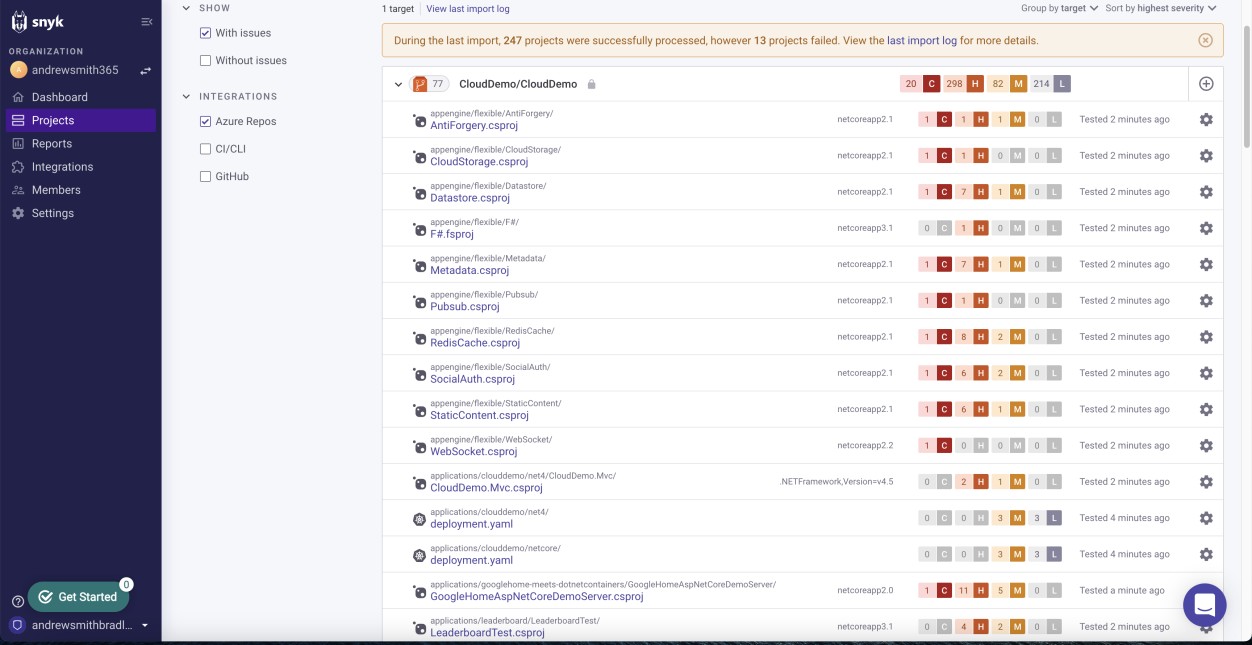
Remarque : Dans cet exemple, une capture d’écran complète n’a pas été utilisée, mais toutes les captures d’écran de preuve envoyées par l’éditeur de logiciels indépendant doivent être des captures d’écran complètes montrant n’importe quelle URL, l’utilisateur connecté, ainsi que l’heure et la date système.
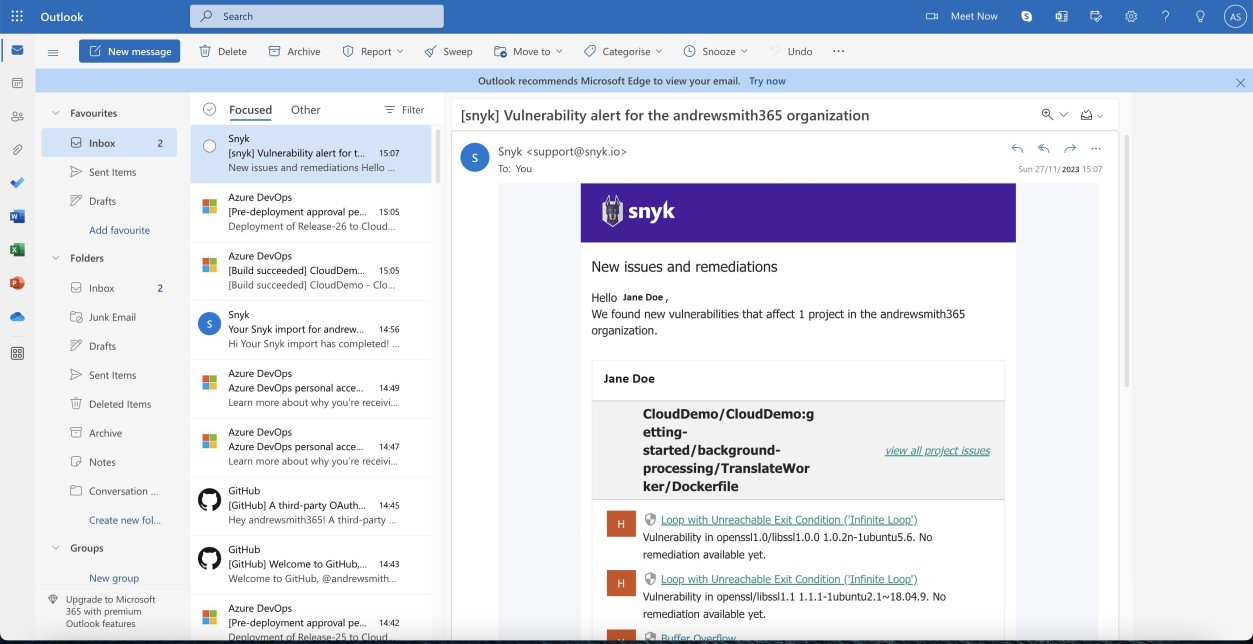
Les deux captures d’écran suivantes montrent un exemple de notification par e-mail reçue lorsque de nouvelles vulnérabilités sont signalées par Snyk. Nous pouvons voir que l’e-mail contient le projet affecté et l’utilisateur affecté pour recevoir les alertes.
La capture d’écran suivante montre les vulnérabilités identifiées.
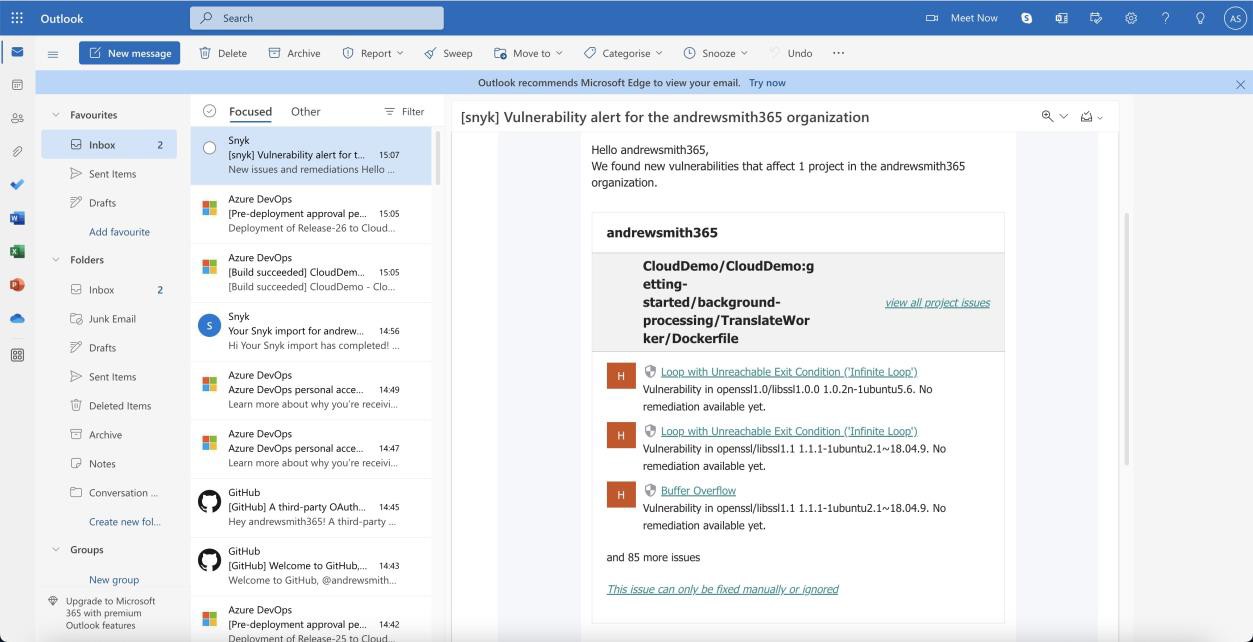
Remarque : Dans les exemples précédents, les captures d’écran complètes n’ont pas été utilisées, mais toutes les captures d’écran de preuve envoyées par l’éditeur de logiciels indépendant doivent être des captures d’écran complètes montrant l’URL, l’heure et la date de connexion de l’utilisateur et du système.
Exemple de preuve
Les captures d’écran suivantes montrent les outils de sécurité GitHub configurés et activés pour rechercher les vulnérabilités au sein de la base de code et les alertes sont envoyées par e-mail.
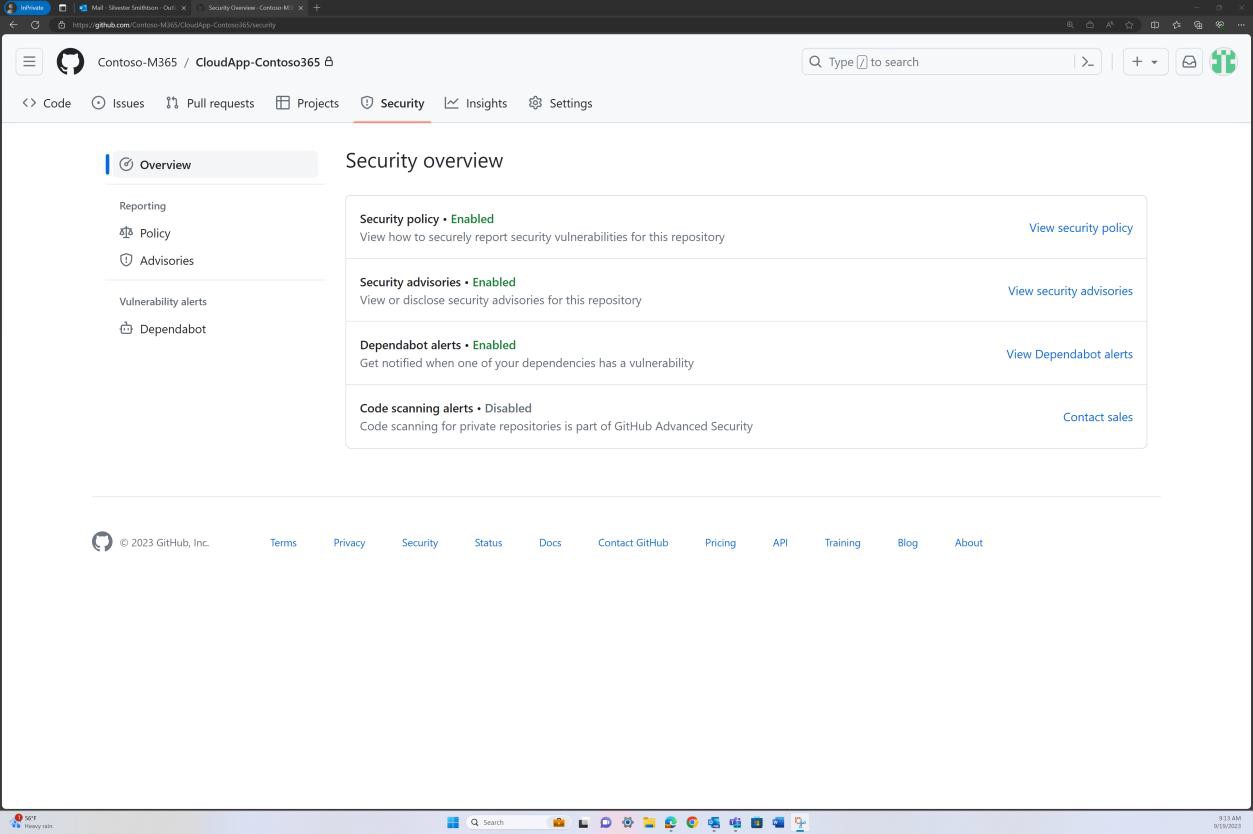
La notification par e-mail suivante est une confirmation que les problèmes avec indicateur seront résolus automatiquement par le biais d’une demande de tirage.
Exemple de preuve
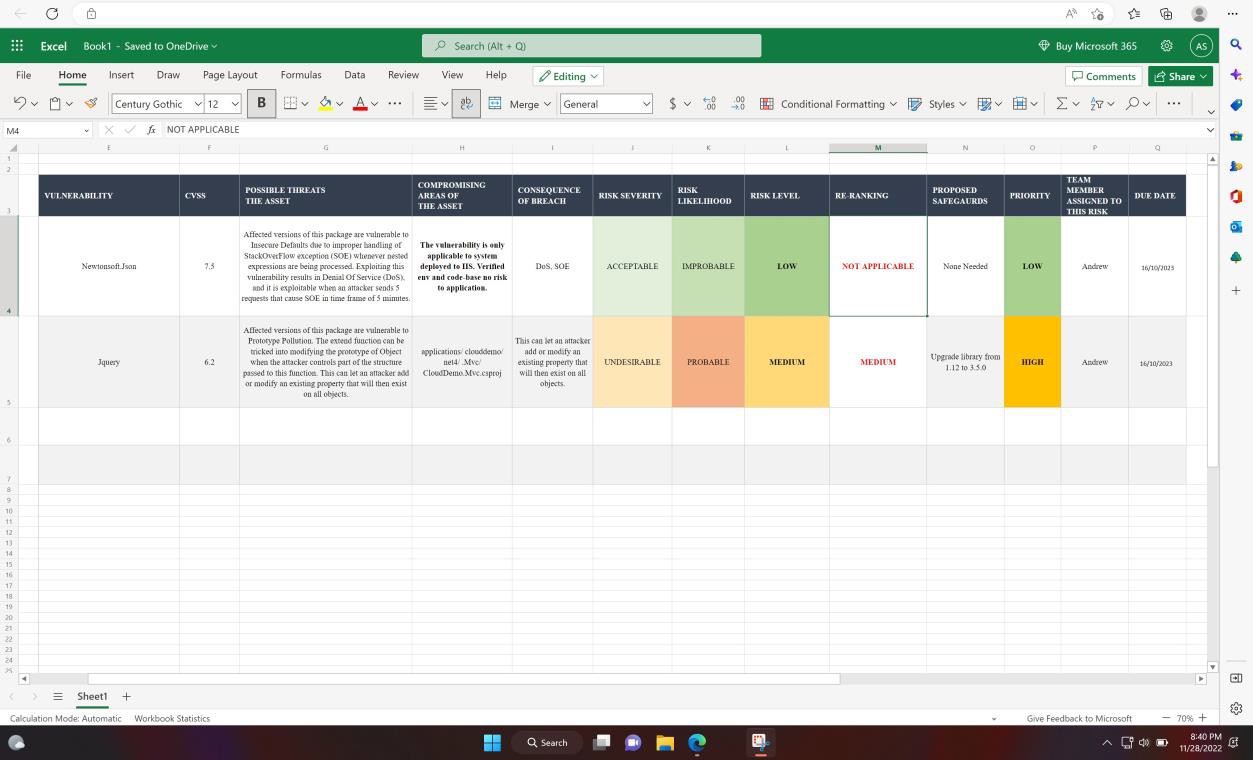
La capture d’écran suivante montre l’évaluation technique interne et le classement des vulnérabilités via une feuille de calcul.
Exemple de preuve
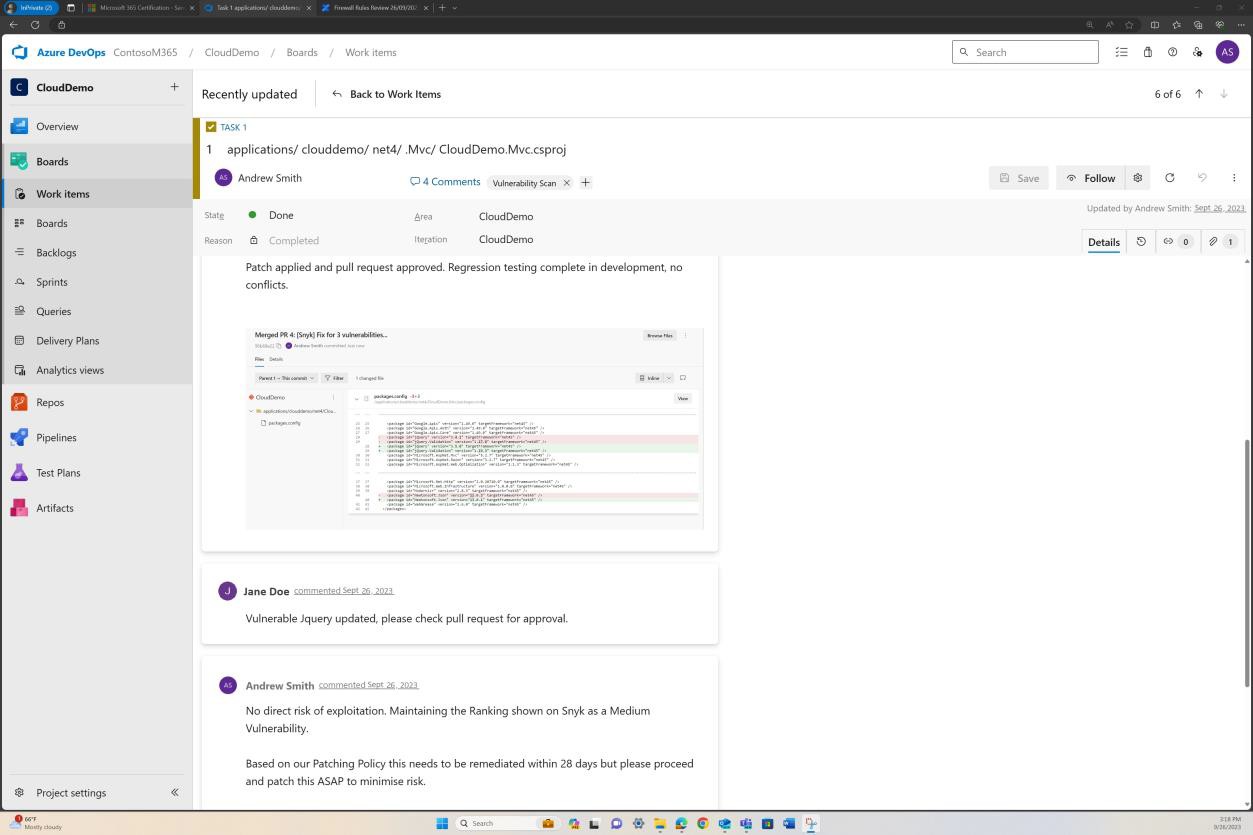
Les captures d’écran suivantes montrent les tickets déclenchés dans DevOps pour chaque vulnérabilité qui a été découverte.
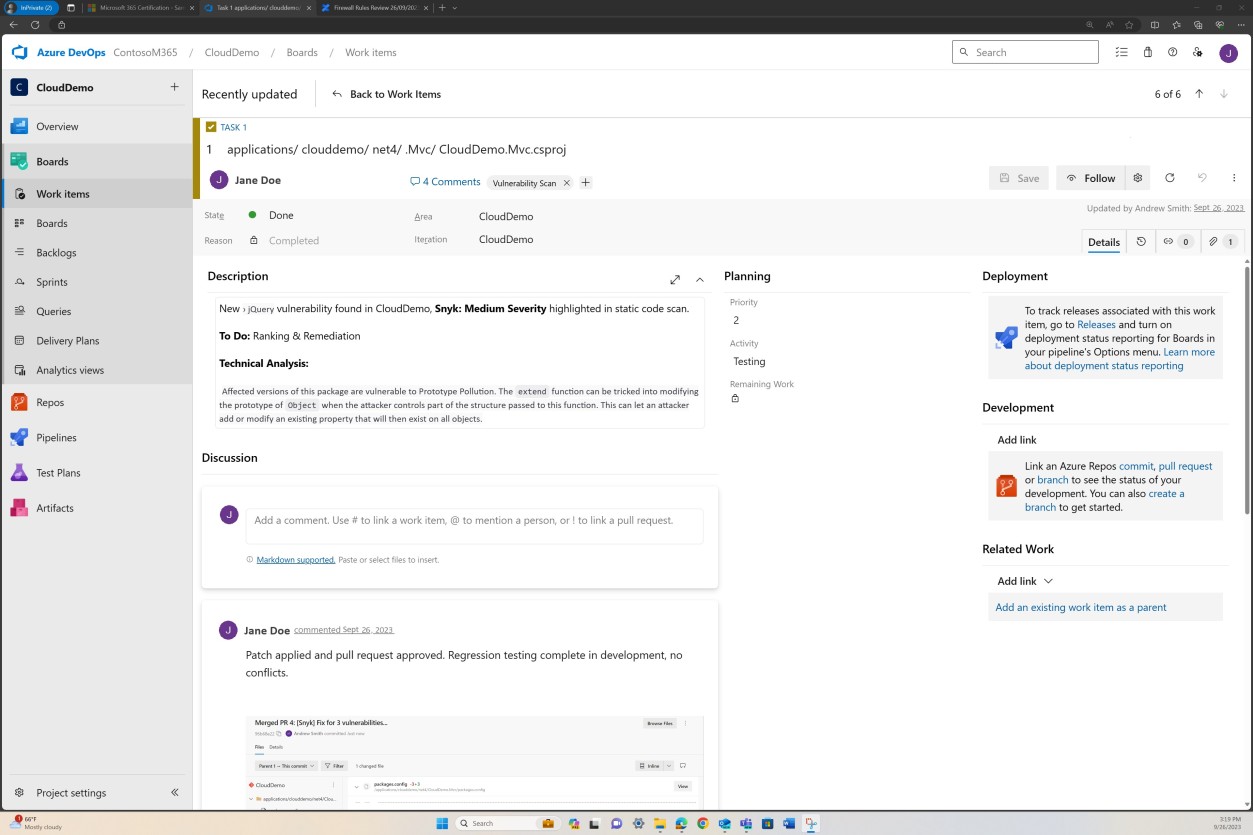
L’évaluation, le classement et l’examen par un employé distinct se produisent avant l’implémentation des modifications.
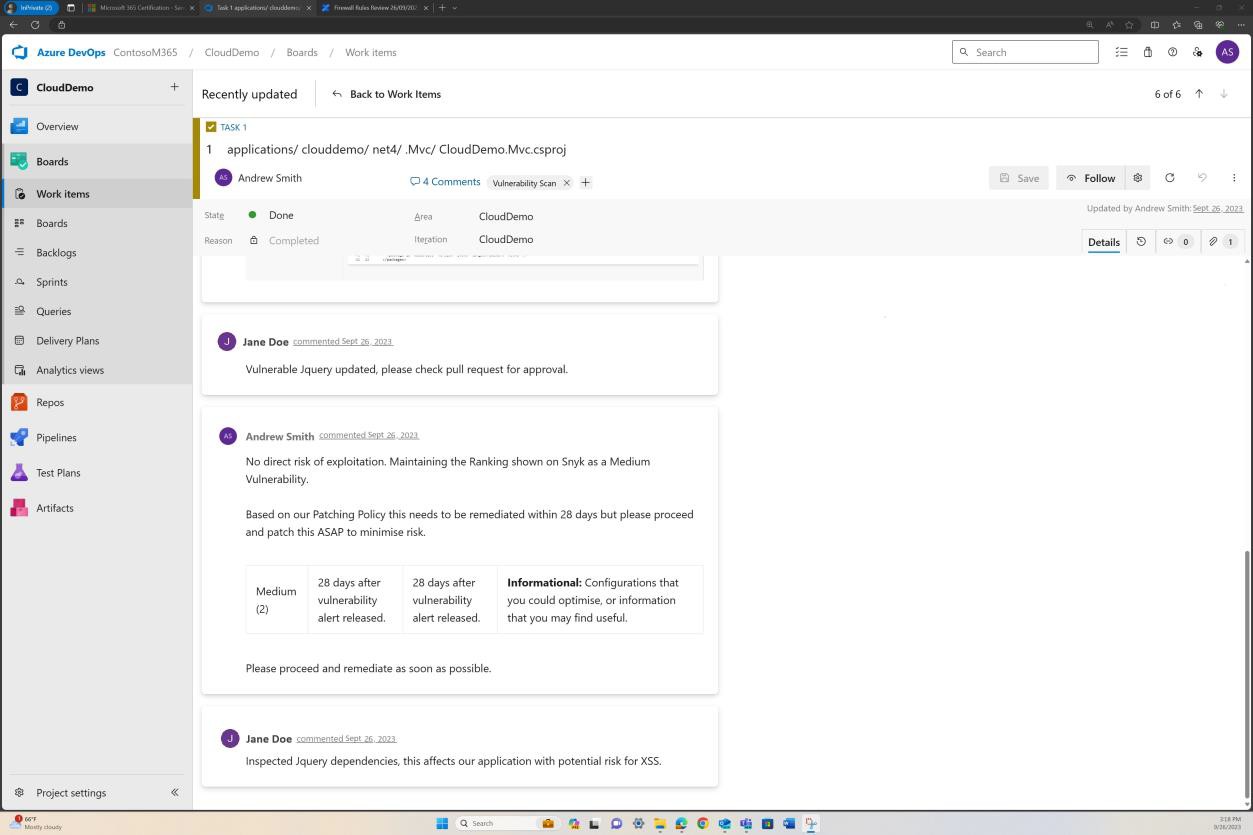
Contrôle n° 5
Fournissez des preuves démontrables que :
Tous les composants système échantillonnés sont corrigés.
Fournir des preuves démontrables que les systèmes d’exploitation et les composants logiciels non pris en charge ne sont pas en cours d’utilisation.
Intention : composants système échantillonné
Ce sous-point vise à s’assurer que des preuves vérifiables sont fournies pour confirmer que tous les composants du système échantillonnés au sein de l’organisation sont activement corrigés. Les preuves peuvent inclure, sans s’y limiter, des journaux de gestion des correctifs, des rapports d’audit système ou des procédures documentées montrant que des correctifs ont été appliqués. Lorsque la technologie serverless ou PaaS (Platform as a Service) est utilisée, cela doit s’étendre pour inclure la base de code pour confirmer que les versions les plus récentes et les plus sécurisées des bibliothèques et des dépendances sont en cours d’utilisation.
Recommandations : composants système échantillonnées
Fournissez une capture d’écran pour chaque appareil dans l’exemple et les composants logiciels de prise en charge montrant que les correctifs sont installés conformément au processus de mise à jour corrective documenté. En outre, fournissez des captures d’écran montrant la mise à jour corrective de la base de code.
Exemple de preuve : composants système échantillonnées
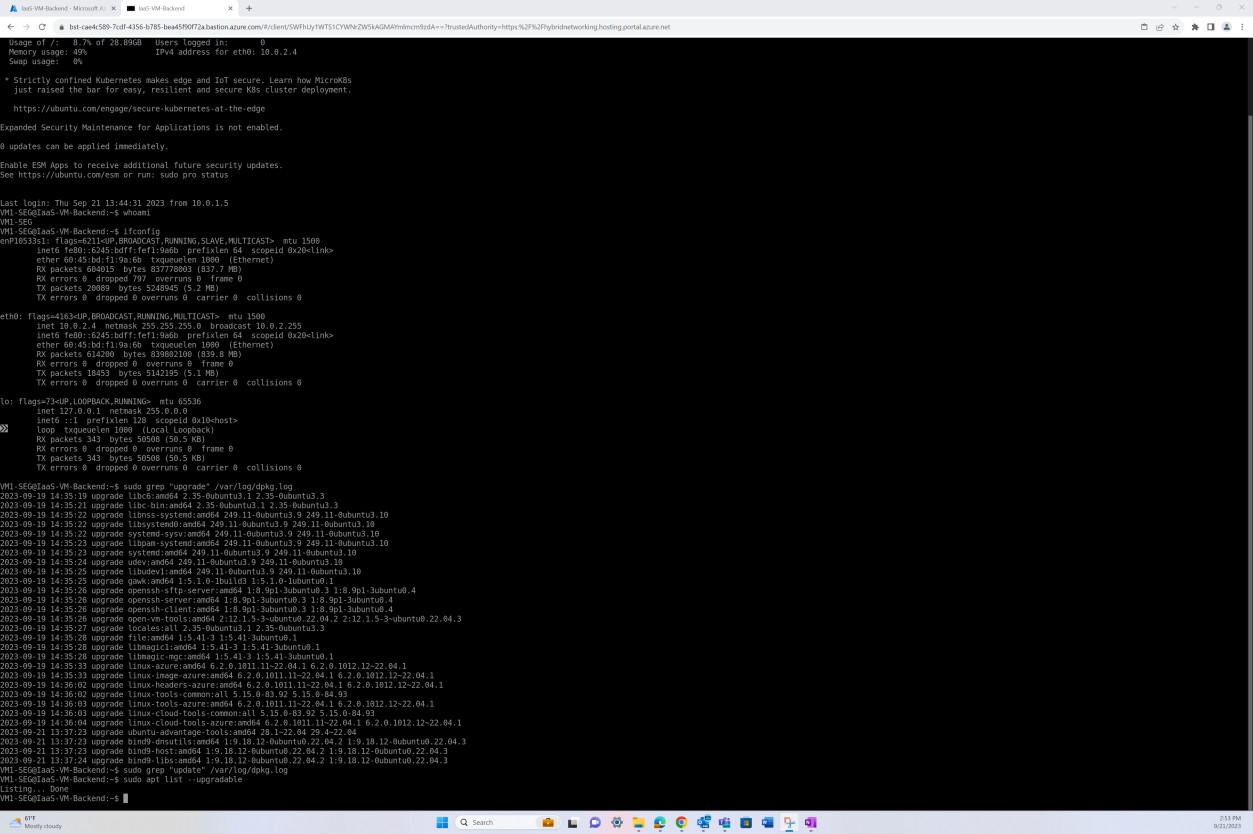
La capture d’écran suivante montre la mise à jour corrective d’une machine virtuelle de système d’exploitation Linux « IaaS- VM-Backend ».
Exemple de preuve
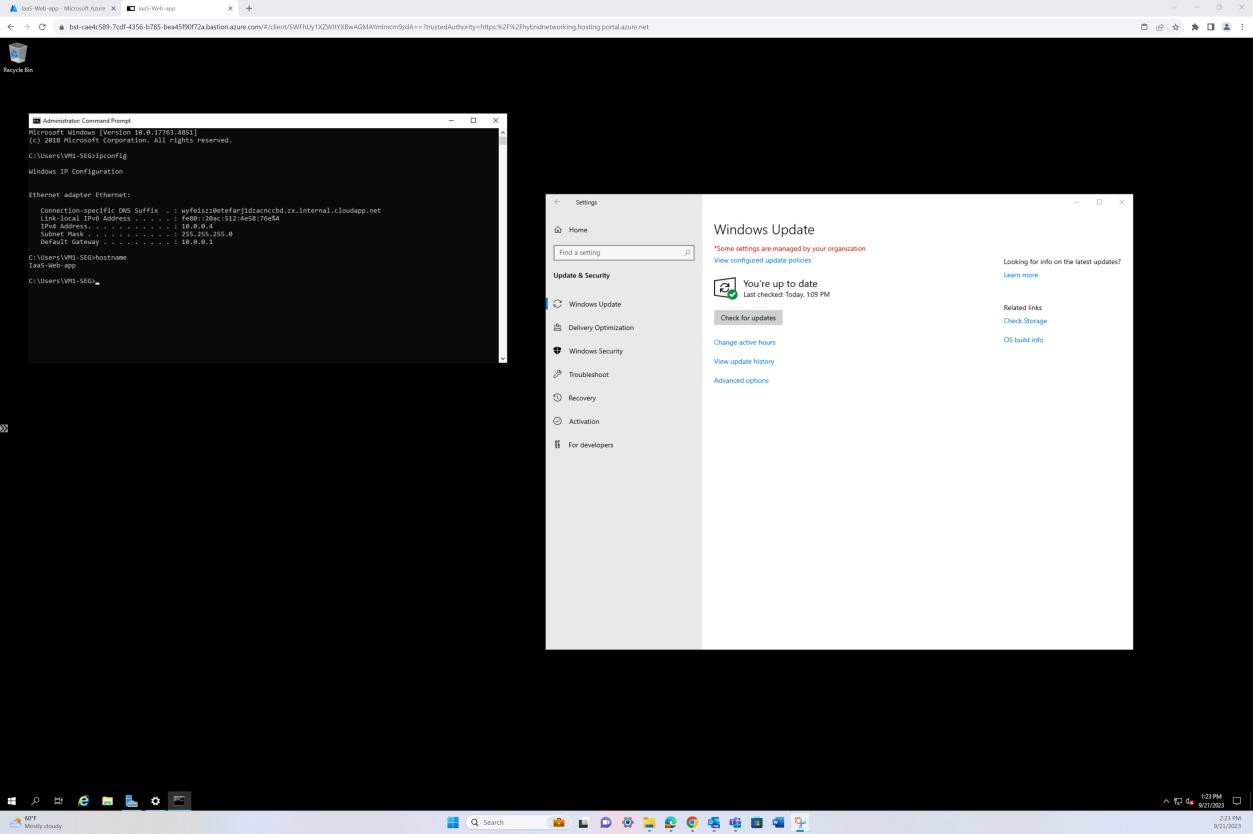
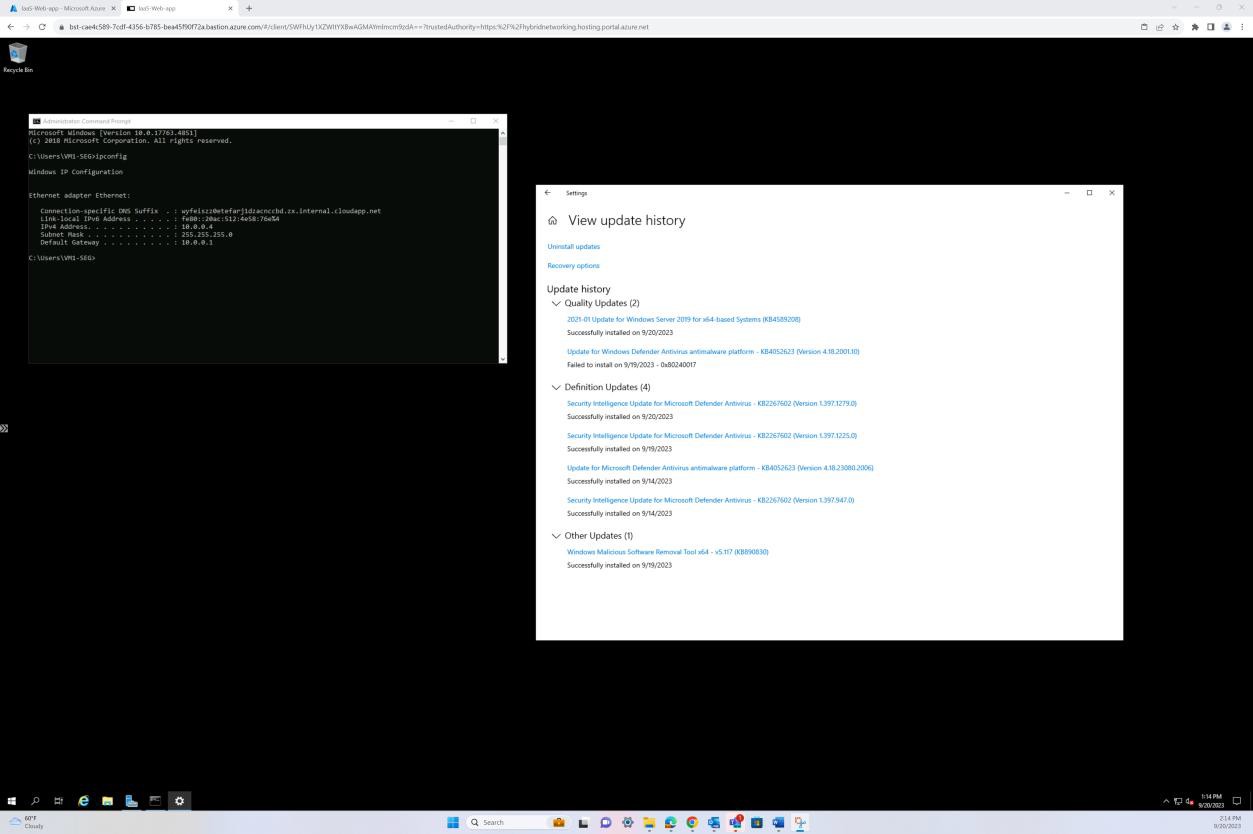
La capture d’écran suivante montre la mise à jour corrective d’une machine virtuelle du système d’exploitation Windows « IaaS-Web-app ».
Exemple de preuve
Si vous conservez la mise à jour corrective à partir d’autres outils tels que Microsoft Intune, Defender pour le cloud, etc., des captures d’écran peuvent être fournies à partir de ces outils. Les captures d’écran suivantes de la solution OpenEDR montrent que la gestion des correctifs est effectuée via le portail OpenEDR.
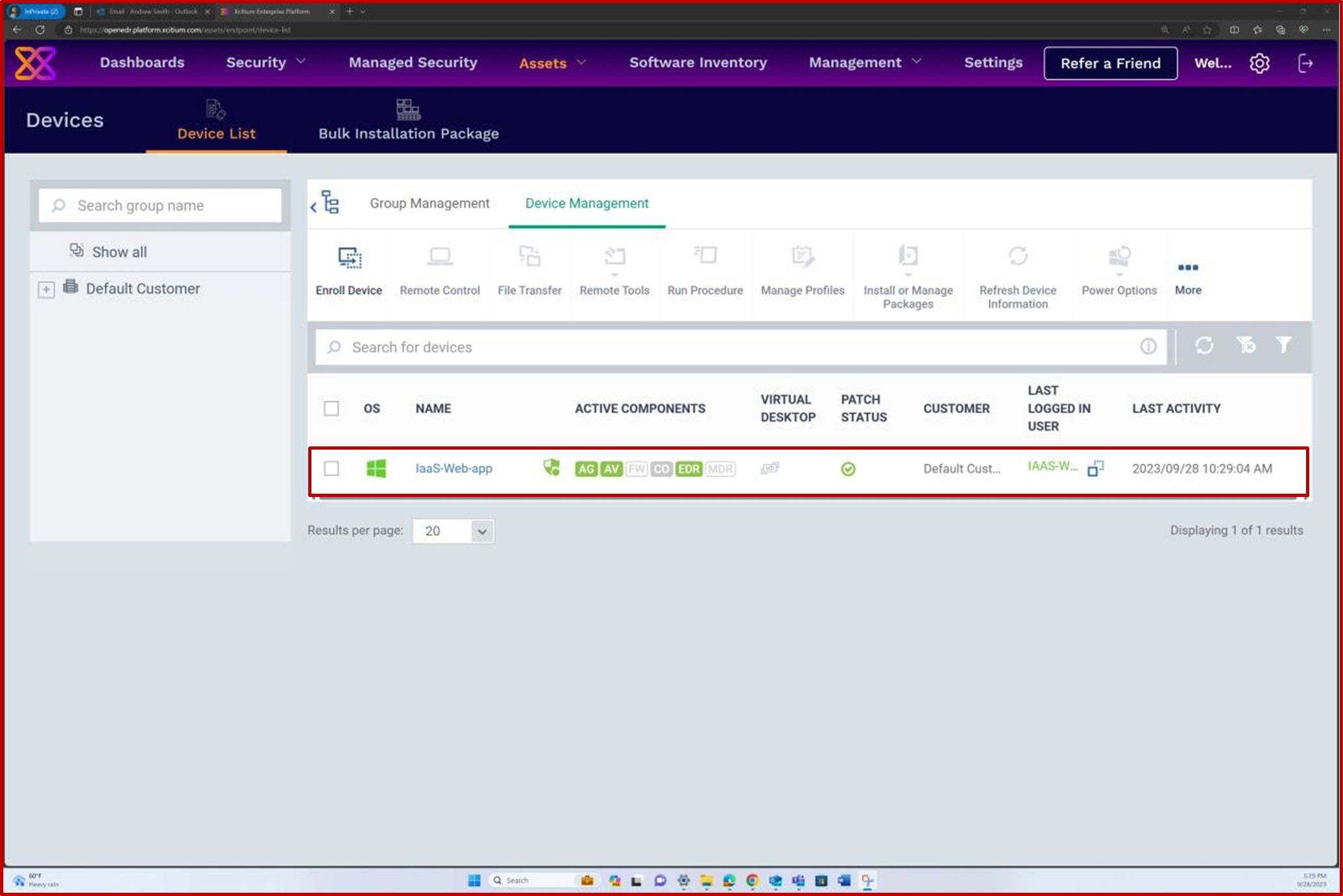
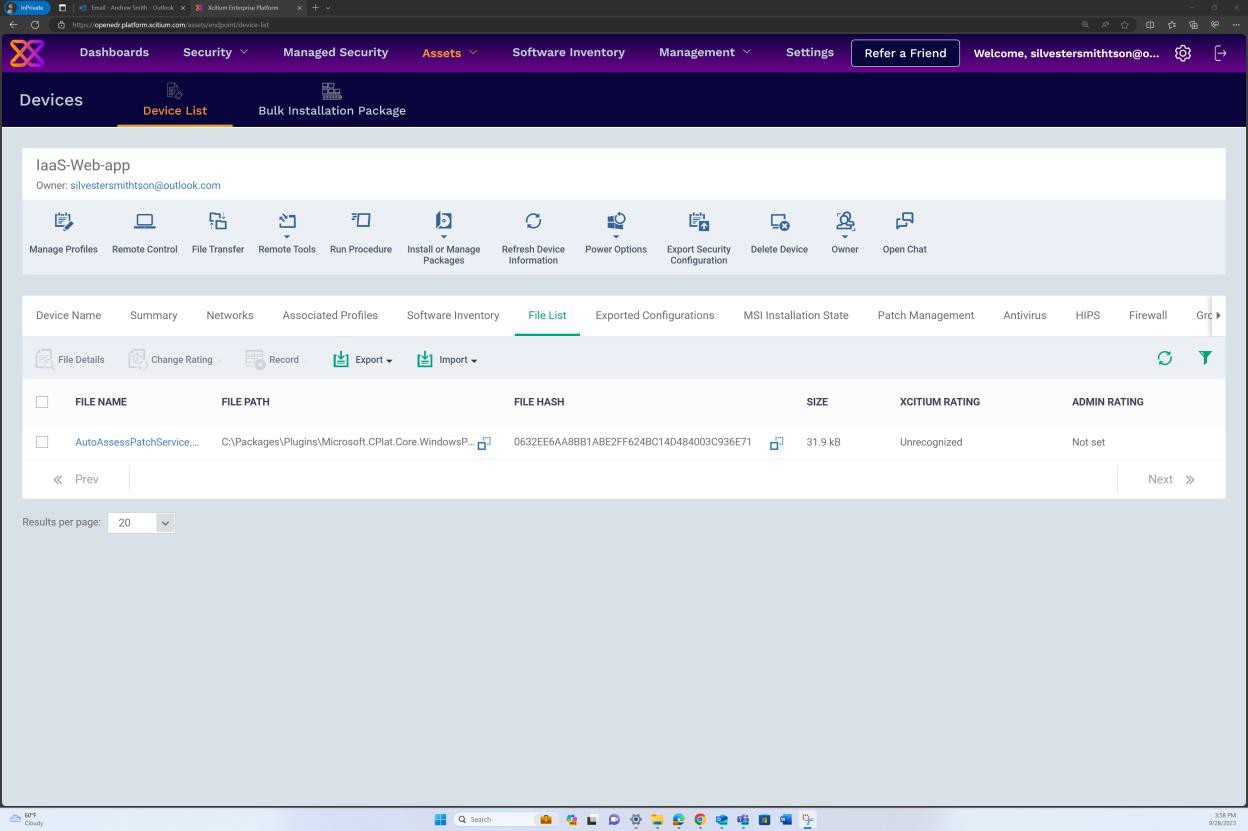
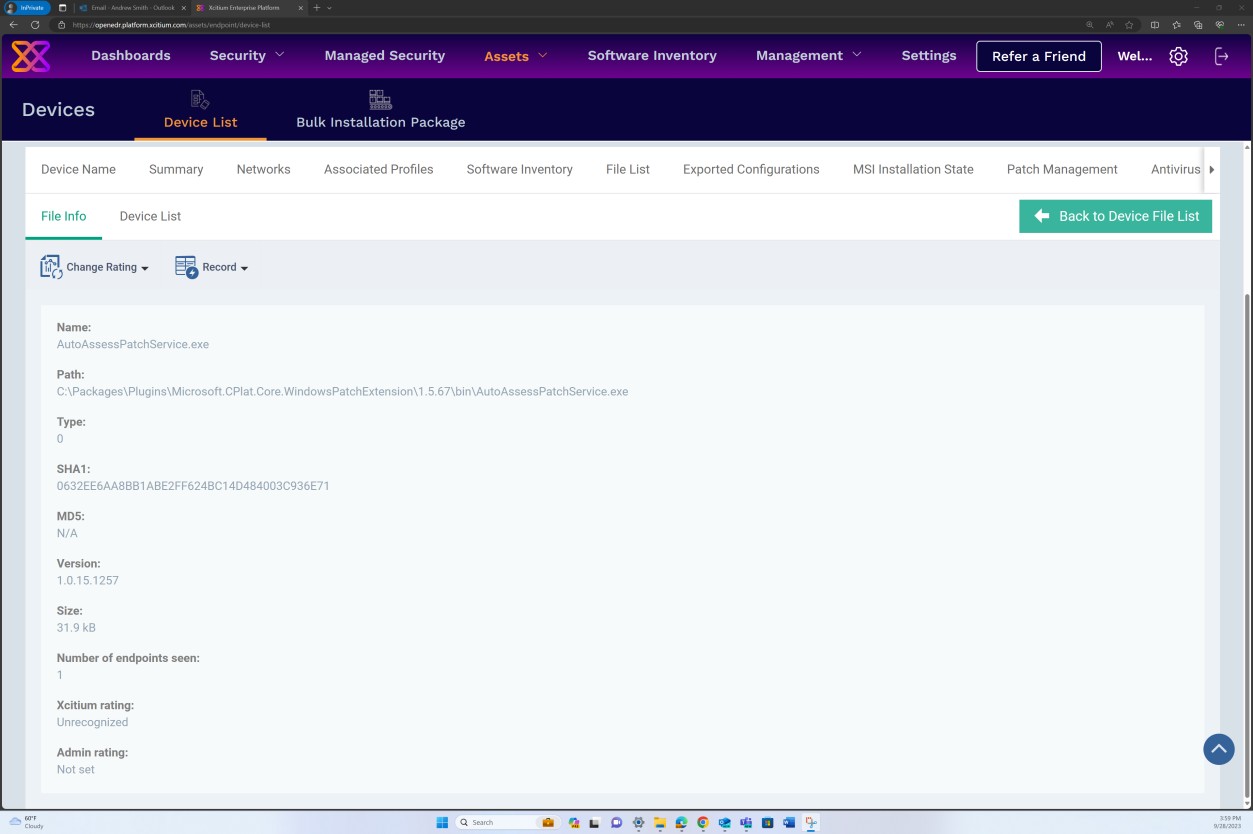
La capture d’écran suivante montre que la gestion des correctifs du serveur dans l’étendue s’effectue via la plateforme OpenEDR. La classification et l’état sont visibles ci-dessous, ce qui montre que la mise à jour corrective se produit.
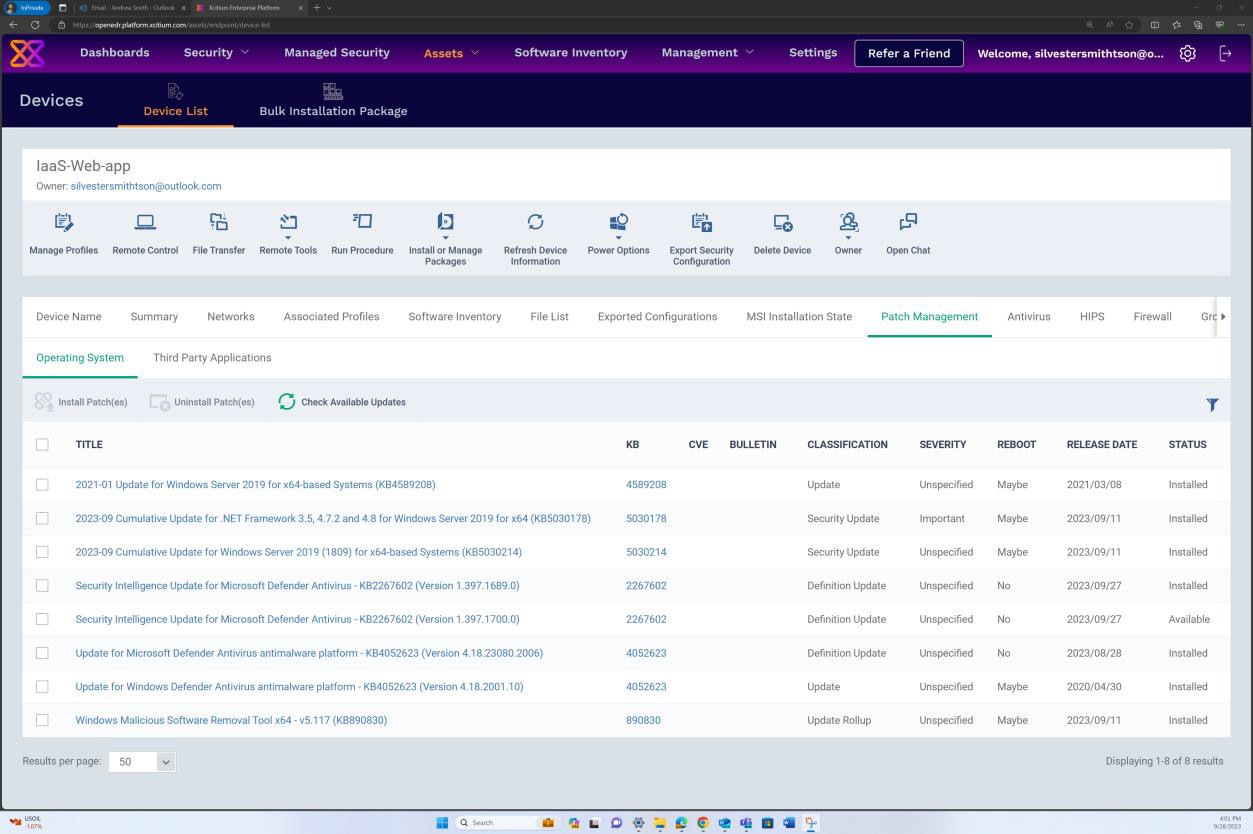
La capture d’écran suivante montre que les journaux sont générés pour les correctifs correctement installés sur le serveur.
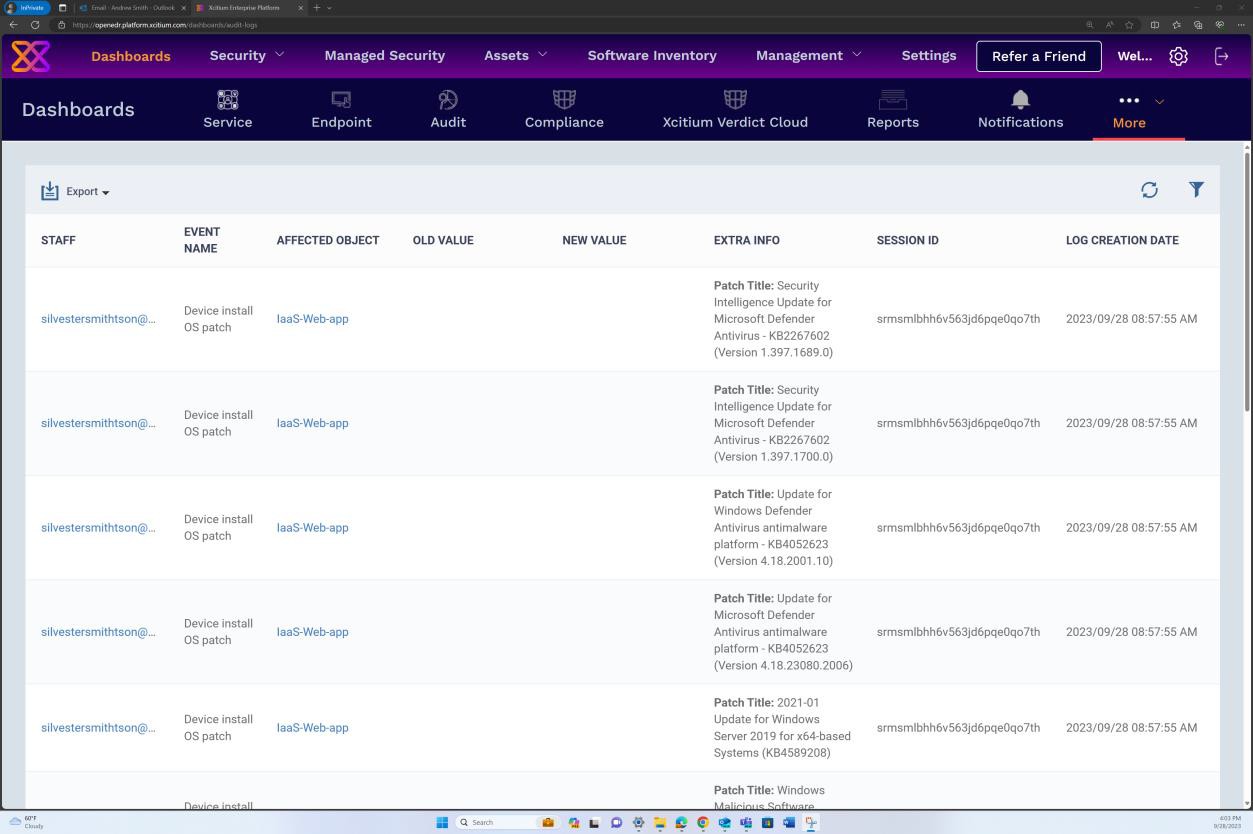
Exemple de preuve
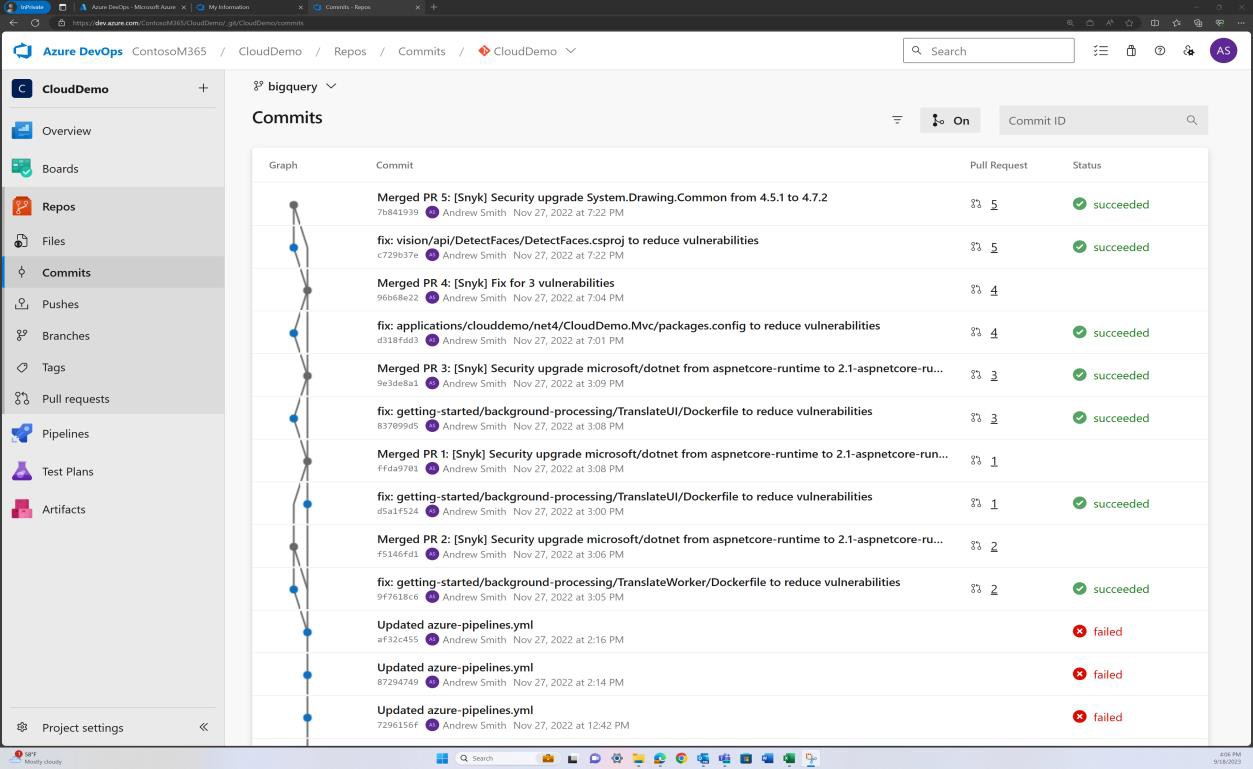
La capture d’écran suivante montre que les dépendances de la base de code/bibliothèque tierce sont corrigées via Azure DevOps.
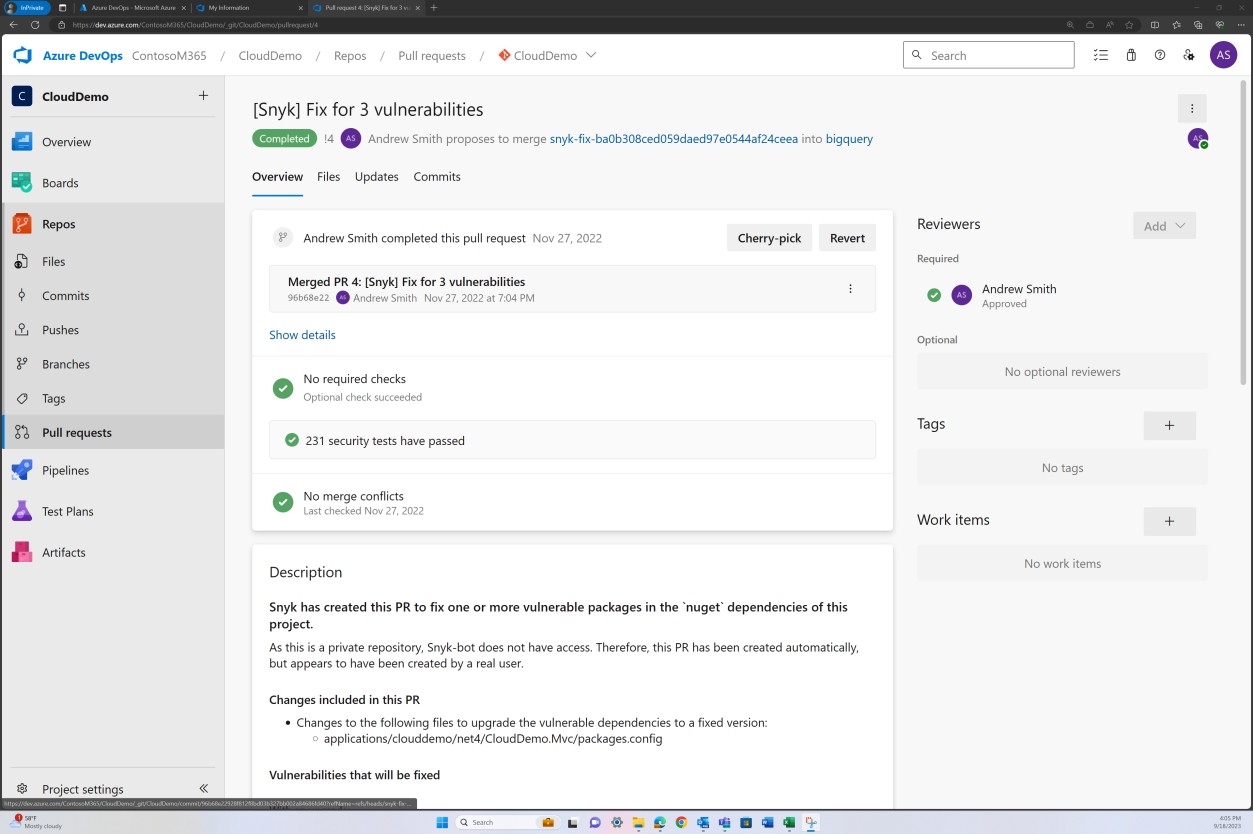
La capture d’écran suivante montre qu’un correctif pour les vulnérabilités découvertes par Snyk est en cours de validation dans la branche pour résoudre les bibliothèques obsolètes.
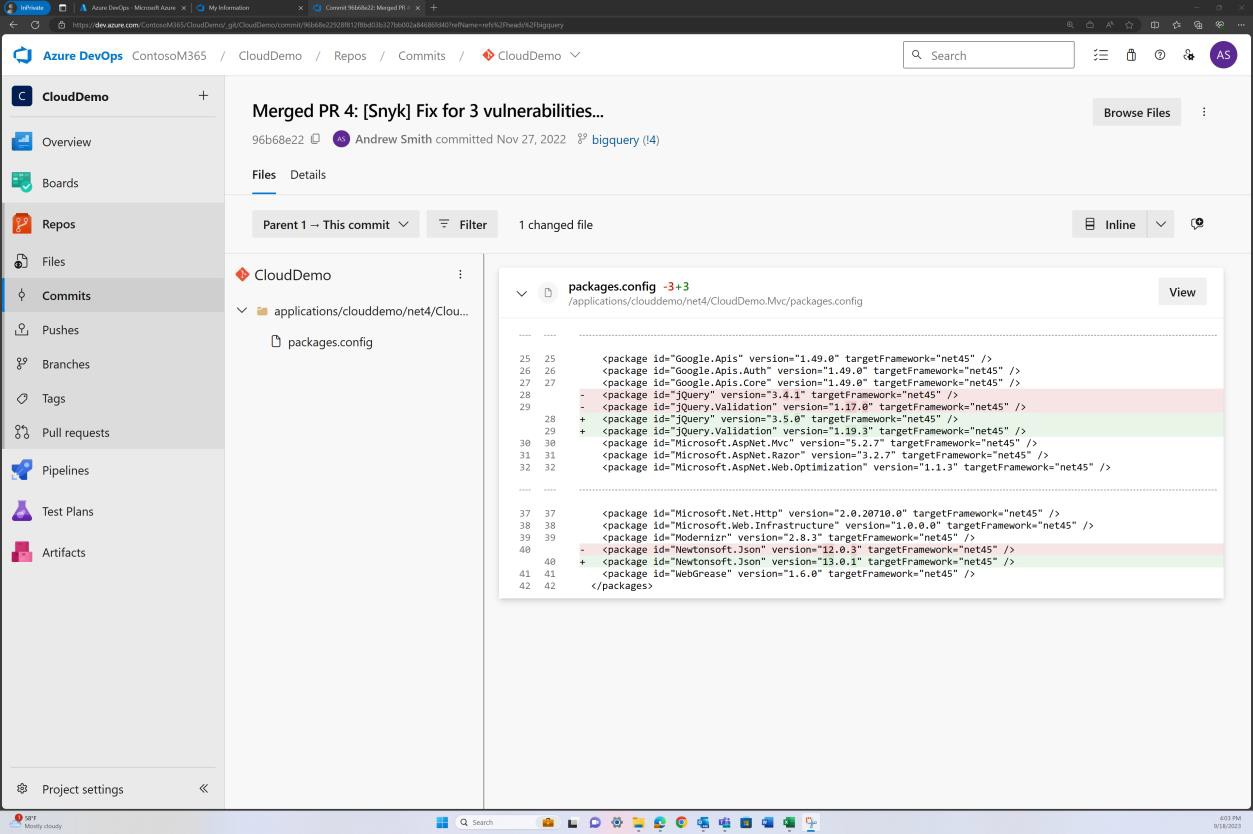
La capture d’écran suivante montre que les bibliothèques ont été mises à niveau vers des versions prises en charge.
Exemple de preuve
Les captures d’écran suivantes montrent que la mise à jour corrective de base du code est conservée via GitHub Dependabot. Les éléments fermés montrent que la mise à jour corrective se produit et que les vulnérabilités ont été résolues.
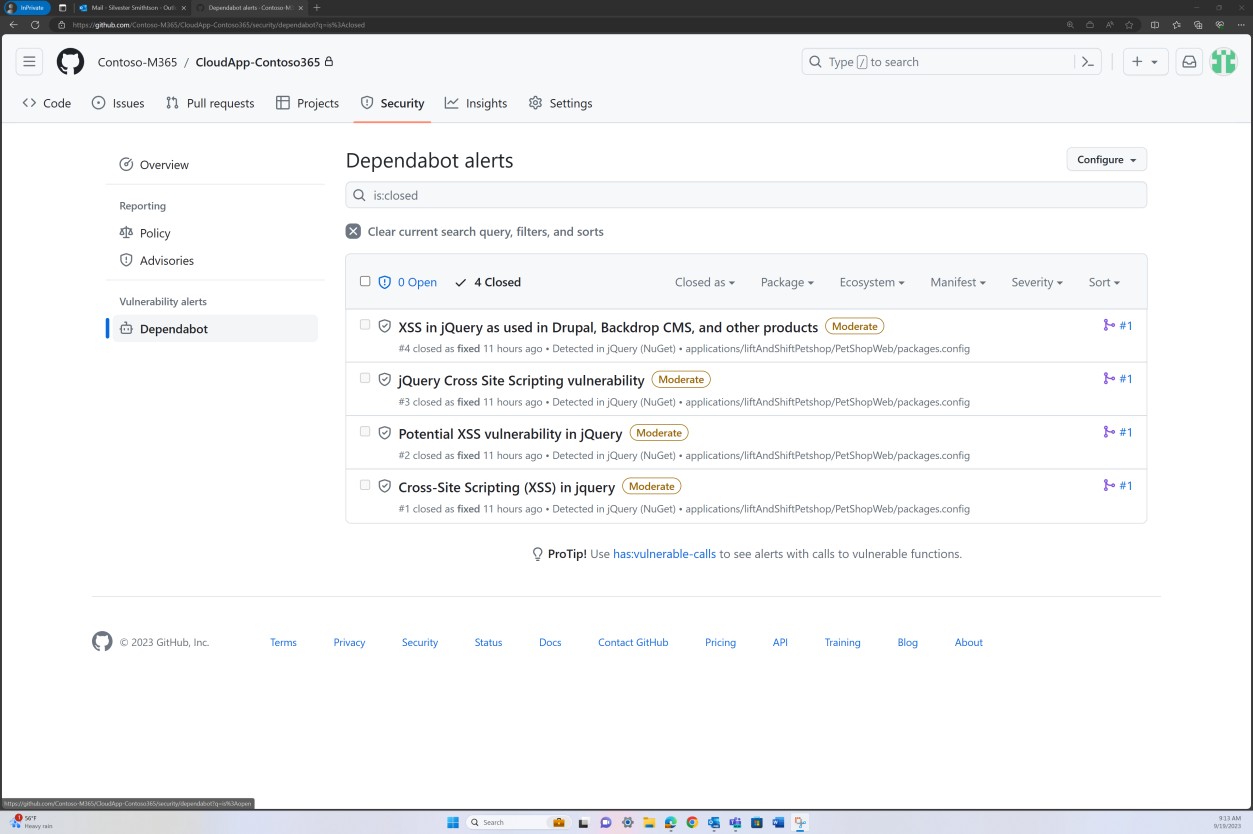
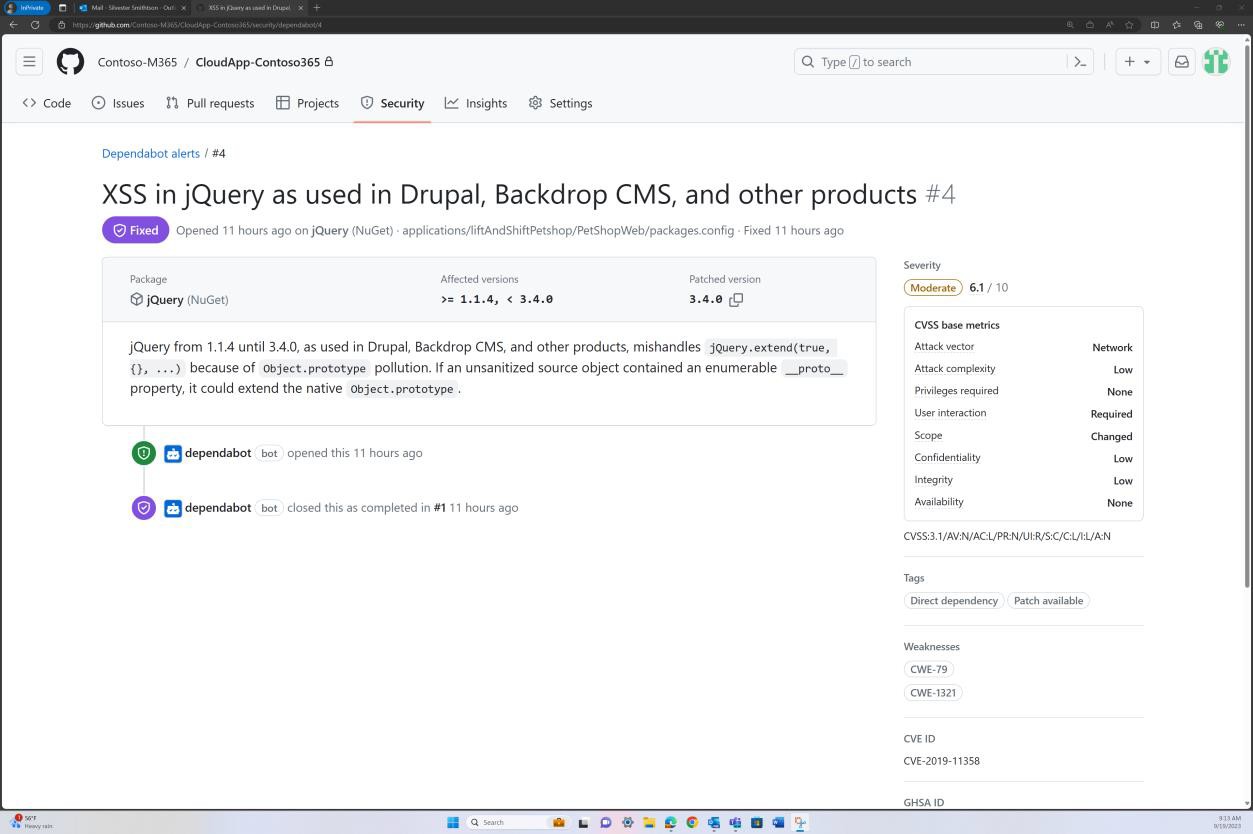
Intention : système d’exploitation non pris en charge
Les logiciels qui ne sont pas gérés par les fournisseurs souffrent, au fil du temps, de vulnérabilités connues qui ne sont pas corrigées. Par conséquent, l’utilisation de systèmes d’exploitation et de composants logiciels non pris en charge ne doit pas être utilisée dans des environnements de production. Lorsque l’infrastructure en tant que service (IaaS) est déployée, la configuration requise pour ce sous-point s’étend pour inclure à la fois l’infrastructure et la base de code afin de garantir que chaque couche de la pile technologique est conforme à la stratégie de l’organisation sur l’utilisation des logiciels pris en charge.
Recommandations : système d’exploitation non pris en charge
Fournissez une capture d’écran pour chaque appareil dans l’exemple d’ensemble choisi par votre analyste afin de collecter des preuves contre l’affichage de la version du système d’exploitation en cours d’exécution (incluez le nom de l’appareil/du serveur dans la capture d’écran). En outre, fournissez la preuve que les composants logiciels s’exécutant dans l’environnement exécutent des versions prises en charge du logiciel. Pour ce faire, vous pouvez fournir la sortie des rapports d’analyse des vulnérabilités internes (à condition que l’analyse authentifiée soit incluse) et/ou la sortie d’outils qui vérifient les bibliothèques tierces, telles que Snyk, Trivy ou NPM Audit. En cas d’exécution dans PaaS, seule la mise à jour corrective de bibliothèque tierce doit être couverte.
Exemple de preuve : système d’exploitation non pris en charge
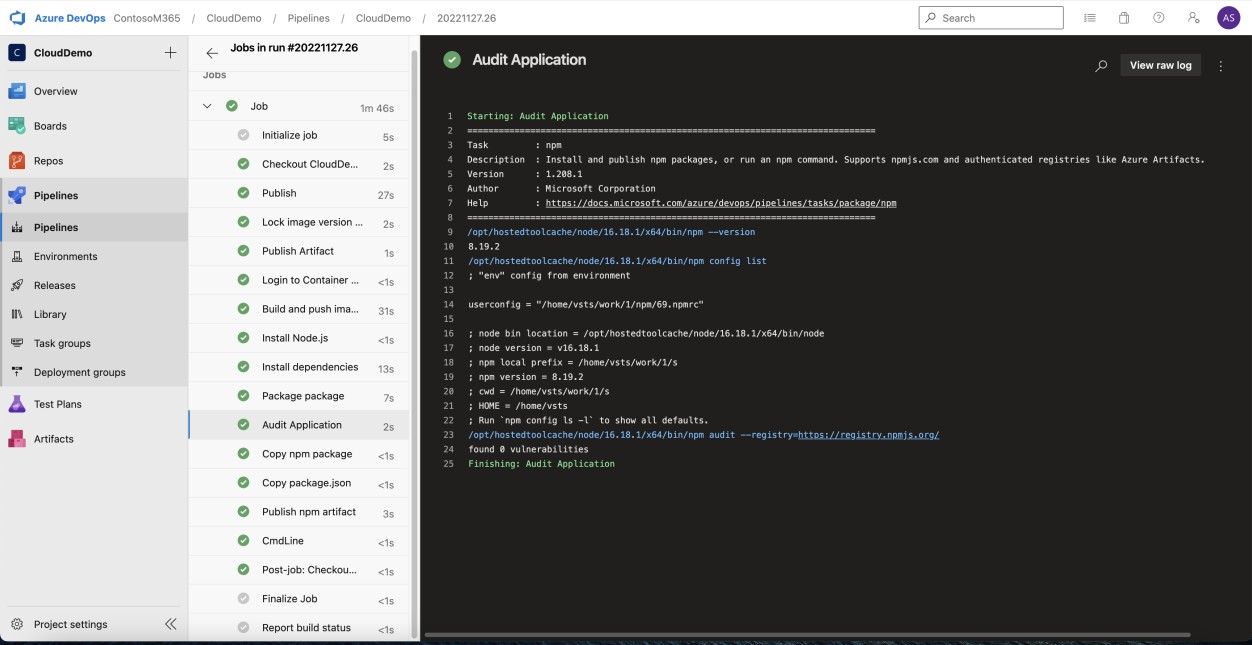
La capture d’écran suivante de l’audit NPM Azure DevOps montre qu’aucune bibliothèque/dépendance non prise en charge n’est utilisée dans l’application web.
Remarque : Dans l’exemple suivant, aucune capture d’écran complète n’a été utilisée, mais toutes les captures d’écran de preuve envoyées par l’éditeur de logiciels indépendant doivent être des captures d’écran complètes montrant l’URL, l’heure et la date de connexion de l’utilisateur et du système.
Exemple de preuve
La capture d’écran suivante de GitHub Dependabot montre qu’aucune bibliothèque/dépendance n’est utilisée dans l’application web.
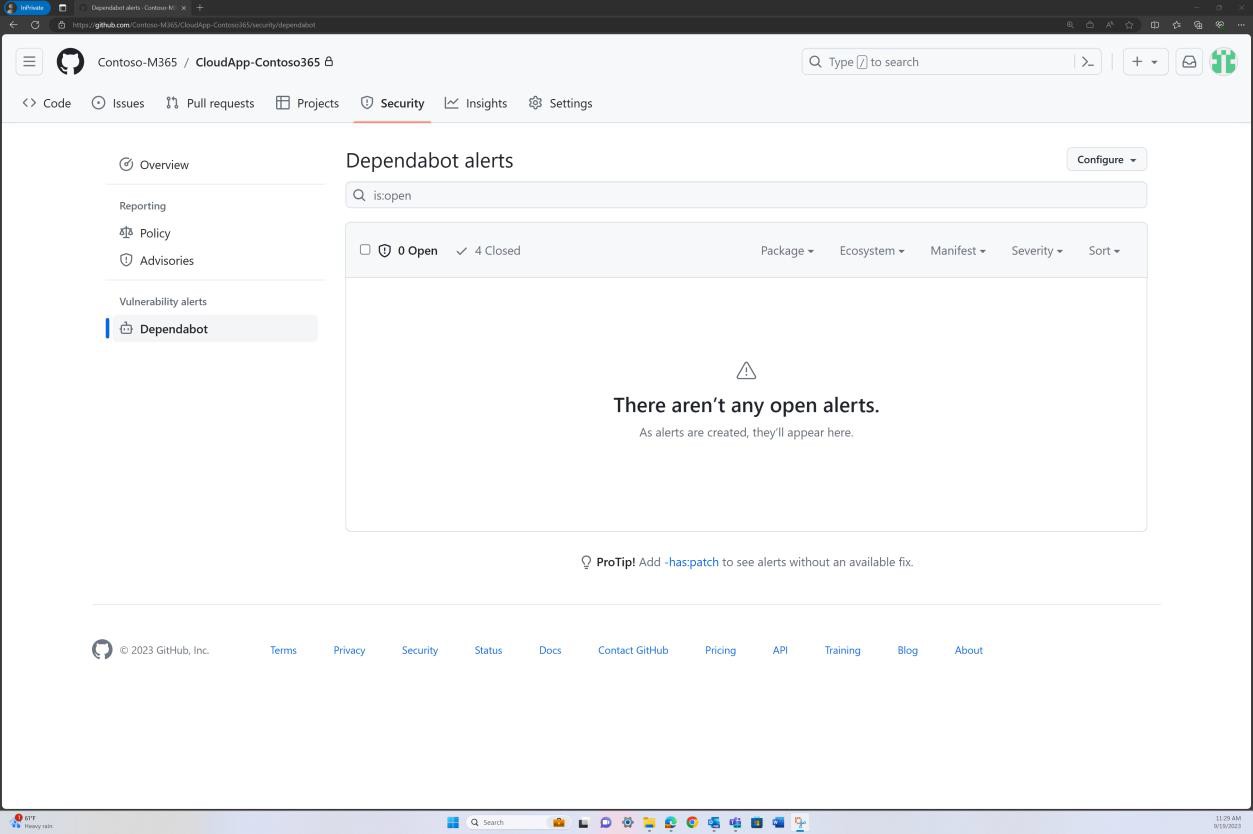
Exemple de preuve
La capture d’écran suivante de l’inventaire logiciel pour le système d’exploitation Windows via OpenEDR montre qu’aucune version de logiciel et de système d’exploitation non pris en charge ou obsolète n’a été trouvée.
Exemple de preuve
La capture d’écran suivante provient d’OpenEDR sous le Résumé du système d’exploitation montrant Windows Server 2019 Datacenter (x64) et l’historique complet des versions du système d’exploitation, y compris le Service Pack, la version de build, etc. validation qu’aucun système d’exploitation non pris en charge n’a été trouvé.
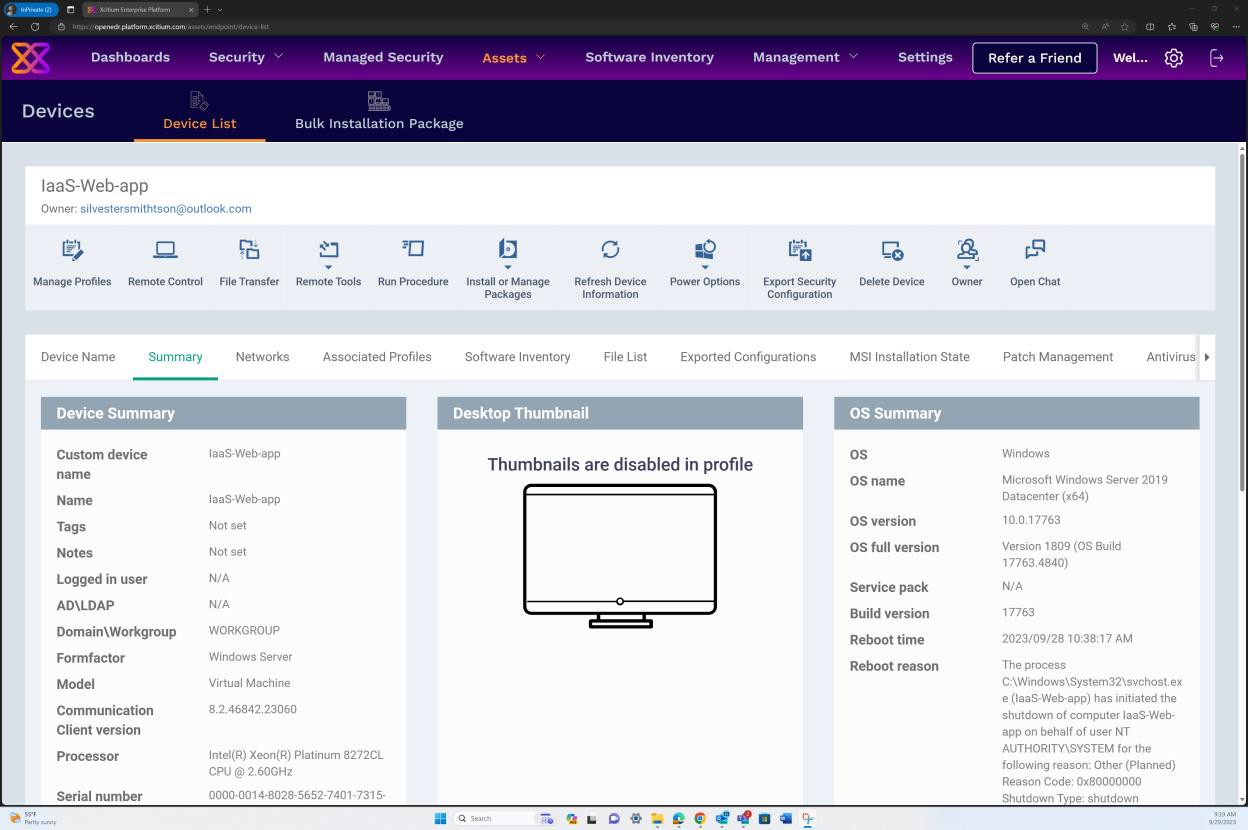
Exemple de preuve
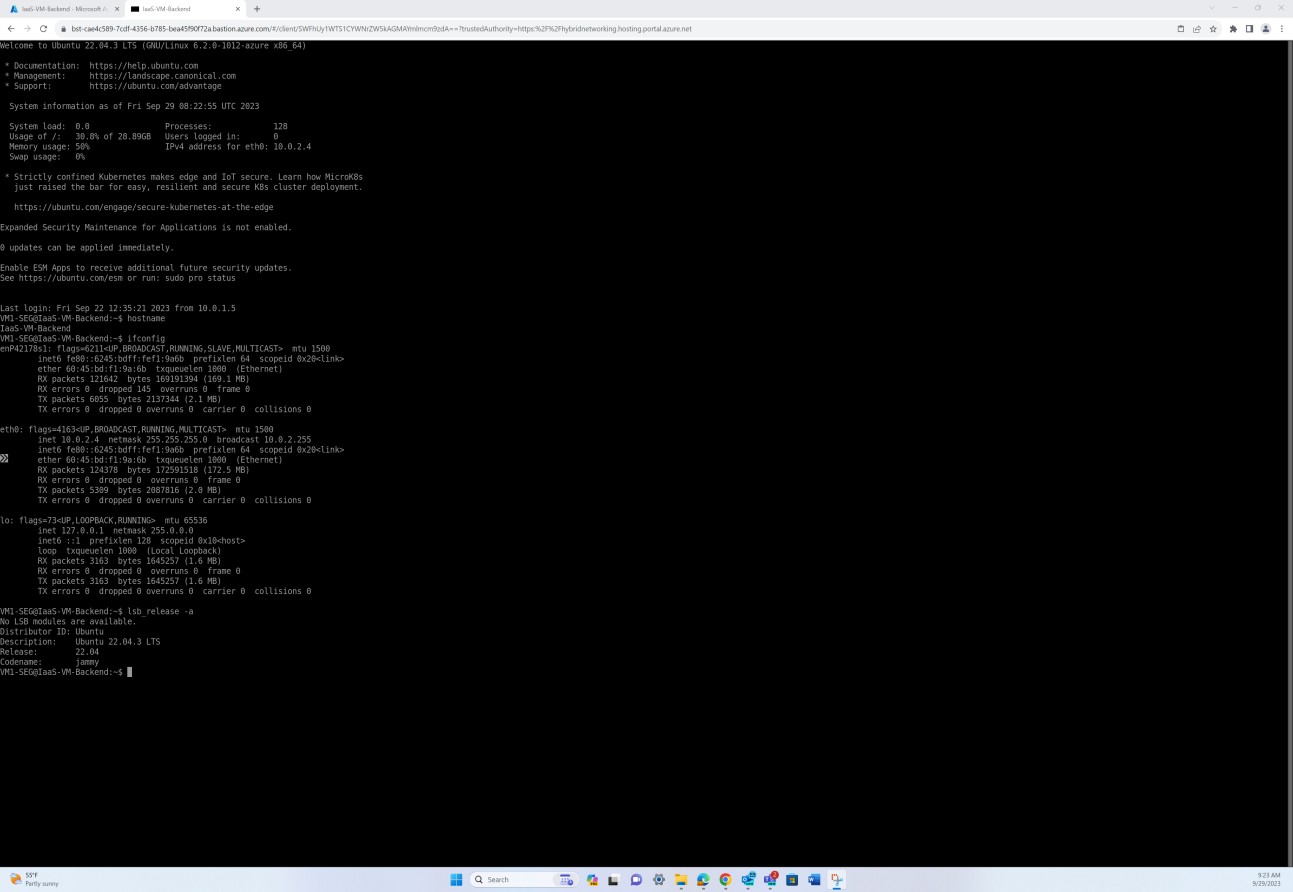
La capture d’écran suivante d’un serveur de système d’exploitation Linux montre tous les détails de la version, notamment l’ID du serveur de distribution, la description, la version et le nom du code, confirmant qu’aucun système d’exploitation Linux non pris en charge n’a été trouvé.
Exemple de preuve :
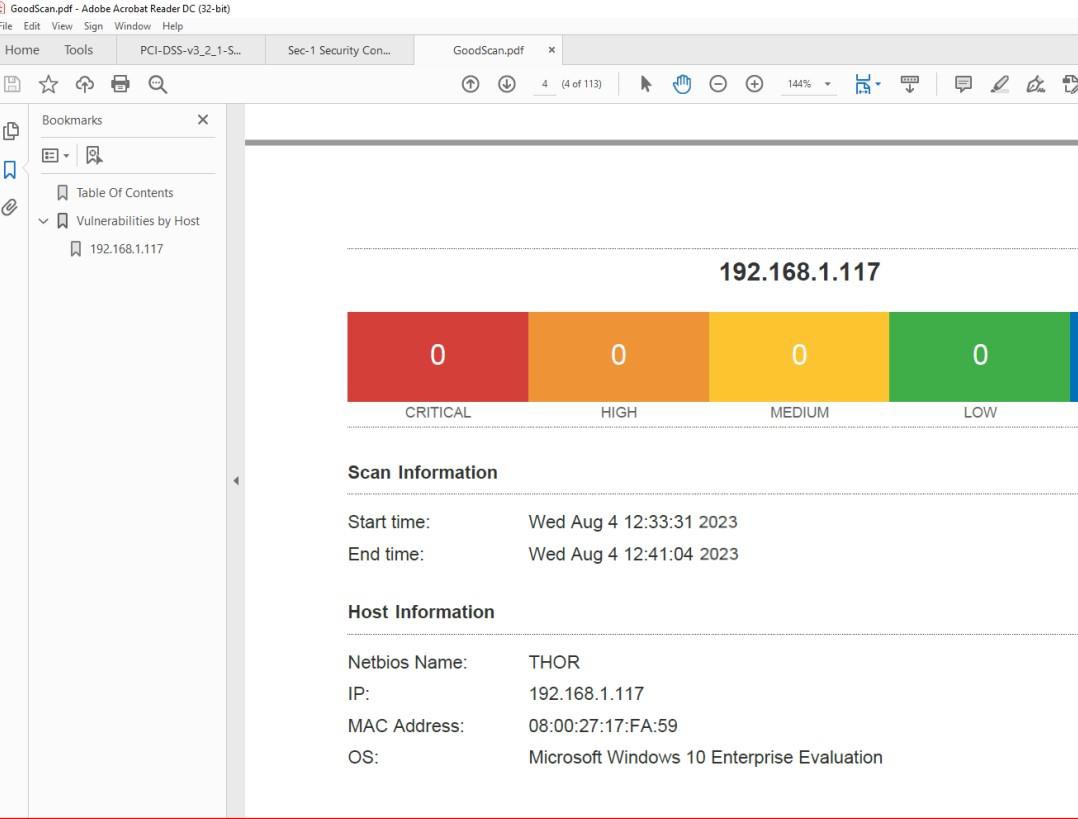
La capture d’écran suivante du rapport d’analyse des vulnérabilités Nessus montre qu’aucun système d’exploitation et logiciel non pris en charge n’a été trouvé sur l’ordinateur cible.
Remarque : Dans les exemples précédents, aucune capture d’écran complète n’a été utilisée, mais toutes les captures d’écran de preuve envoyées par l’éditeur de logiciels indépendant doivent être des captures d’écran complètes montrant l’URL, l’heure et la date de connexion de l’utilisateur et du système.
Analyse des vulnérabilités
L’analyse des vulnérabilités recherche les faiblesses possibles dans le système informatique, les réseaux et les applications web d’une organisation afin d’identifier les trous susceptibles d’entraîner des violations de la sécurité et l’exposition de données sensibles. L’analyse des vulnérabilités est souvent requise par les normes du secteur et les réglementations gouvernementales, par exemple la norme PCI DSS (Payment Card Industry Data Security Standard).
Un rapport de Security Metric intitulé « 2020 Security Metrics Guide to PCI DSS Compliance » indique qu'« en moyenne, il a fallu 166 jours à partir du moment où une organisation a été considérée comme ayant des vulnérabilités pour qu’une personne malveillante compromette le système. Une fois compromis, les attaquants ont eu accès aux données sensibles pendant une moyenne de 127 jours. Par conséquent, ce contrôle vise à identifier les failles de sécurité potentielles dans l’environnement dans l’étendue.
En introduisant des évaluations régulières des vulnérabilités, les organisations peuvent détecter les faiblesses et les insécurités au sein de leurs environnements, ce qui peut fournir un point d’entrée pour qu’un acteur malveillant puisse compromettre l’environnement. L’analyse des vulnérabilités peut aider à identifier les correctifs manquants ou les configurations incorrectes dans l’environnement. En effectuant régulièrement ces analyses, une organisation peut fournir une correction appropriée pour réduire le risque d’une compromission en raison de problèmes couramment détectés par ces outils d’analyse des vulnérabilités.
Contrôle n° 6
Fournissez des preuves démontrant que :
Une analyse trimestrielle des vulnérabilités de l’infrastructure et des applications web est effectuée.
L’analyse doit être effectuée sur l’ensemble de l’empreinte publique (adresses IP/URL) et des plages d’adresses IP internes si l’environnement est IaaS, hybride ou local.
Remarque : cela doit inclure l’étendue complète de l’environnement.
Intention : analyse des vulnérabilités
Ce contrôle vise à garantir que l’organisation effectue une analyse des vulnérabilités sur une base trimestrielle, en ciblant à la fois son infrastructure et ses applications web. L’analyse doit être complète, couvrant à la fois les empreintes publiques telles que les adresses IP publiques et les URL, ainsi que les plages d’adresses IP internes. L’étendue de l’analyse varie en fonction de la nature de l’infrastructure de l’organisation :
Si une organisation implémente des modèles IaaS (Infrastructure as a Service) hybrides, locaux ou locaux, l’analyse doit englober à la fois les adresses IP/URL publiques externes et les plages d’adresses IP internes.
Si une organisation implémente PaaS (Platform-as-a-Service), l’analyse doit englober uniquement les ADRESSES IP/URL publiques externes.
Ce contrôle impose également que l’analyse inclue toute l’étendue de l’environnement, ce qui ne laisse aucun composant désactivé. L’objectif est d’identifier et d’évaluer les vulnérabilités dans toutes les parties de la pile technologique de l’organisation pour garantir une sécurité complète.
Recommandations : analyse des vulnérabilités
Fournissez le ou les rapports d’analyse complets pour les analyses de vulnérabilité de chaque trimestre qui ont été effectuées au cours des 12 derniers mois. Les rapports doivent indiquer clairement les cibles pour valider que l’empreinte publique complète est incluse et, le cas échéant, chaque sous-réseau interne. Fournissez TOUS les rapports d’analyse pour CHAQUE trimestre.
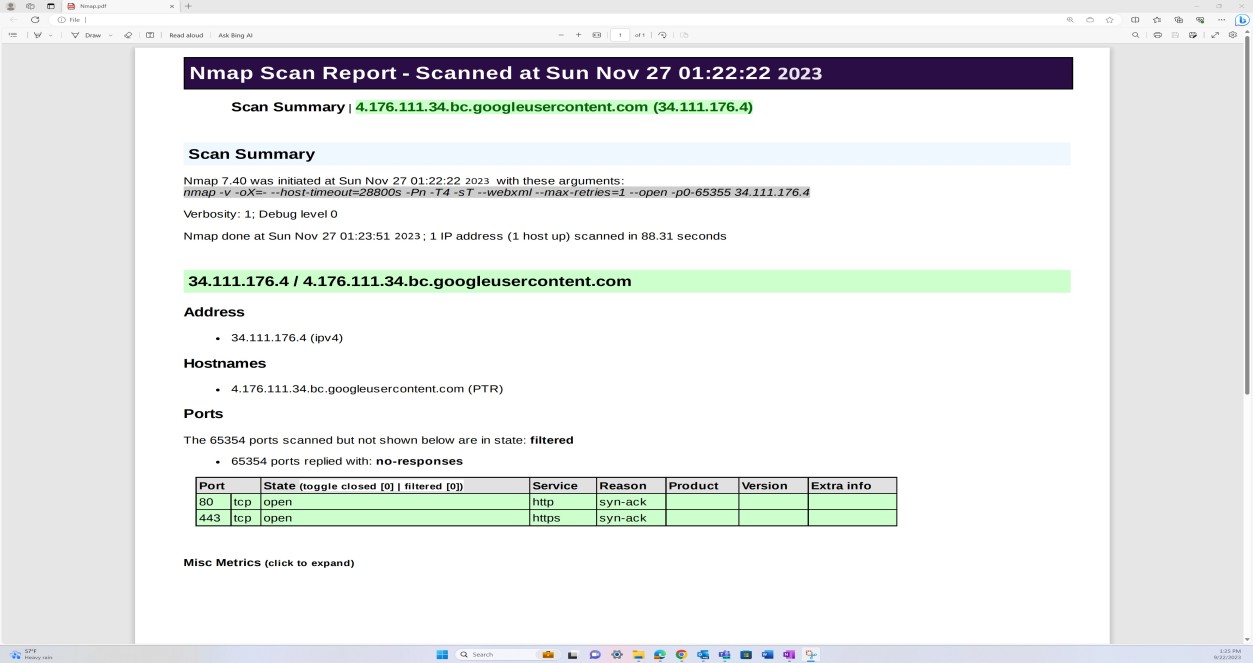
Exemple de preuve : analyse des vulnérabilités
La capture d’écran suivante montre une découverte de réseau et une analyse de port effectuée via Nmap sur l’infrastructure externe pour identifier les ports ouverts non sécurisés.
Remarque : Nmap en soi ne peut pas être utilisé pour répondre à ce contrôle, car on s’attend à ce qu’une analyse complète des vulnérabilités soit fournie. La découverte de ports Nmap fait partie du processus de gestion des vulnérabilités illustré ci-dessous et est complétée par des analyses OpenVAS et OWASP ZAP sur l’infrastructure externe.
La capture d’écran montre l’analyse des vulnérabilités via OpenVAS sur l’infrastructure externe pour identifier les erreurs de configuration et les vulnérabilités en suspens.
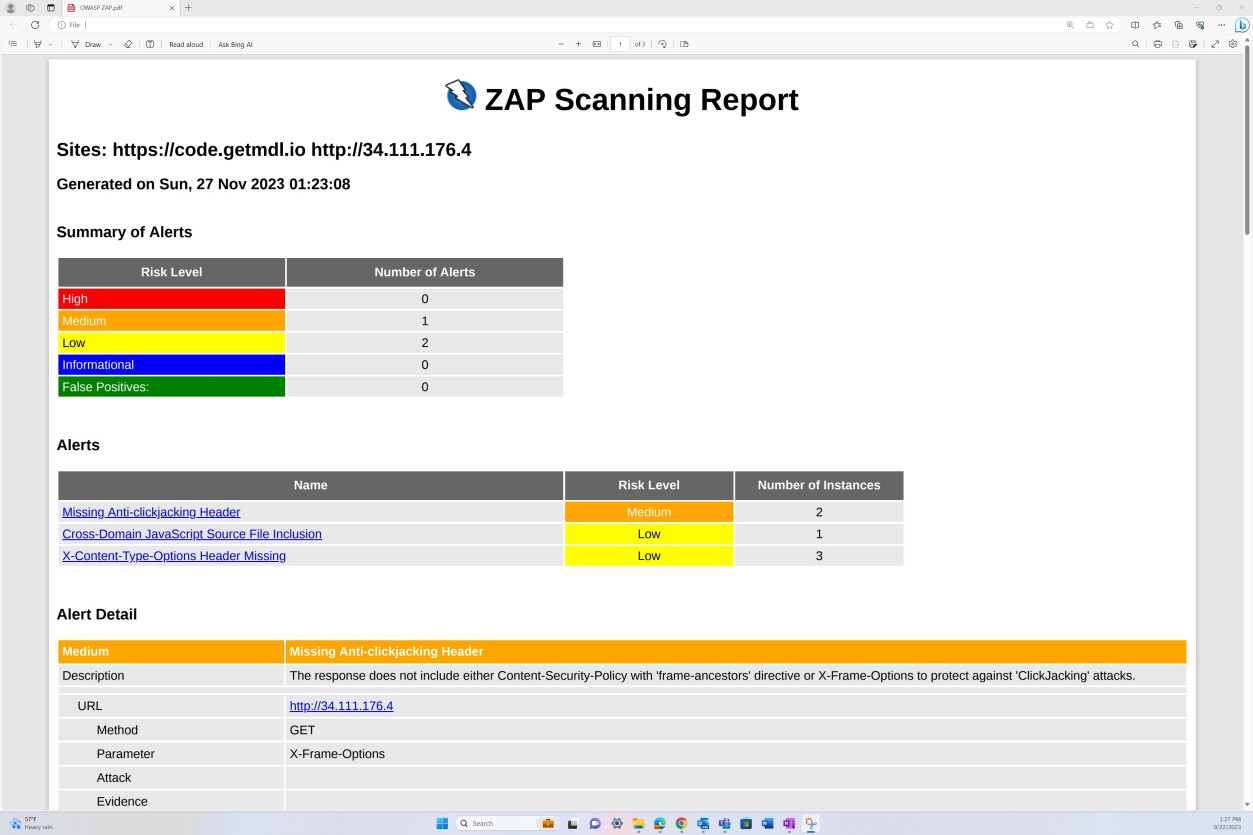
La capture d’écran suivante montre le rapport d’analyse des vulnérabilités d’OWASP ZAP illustrant les tests dynamiques de sécurité des applications.
Exemple de preuve : analyse des vulnérabilités
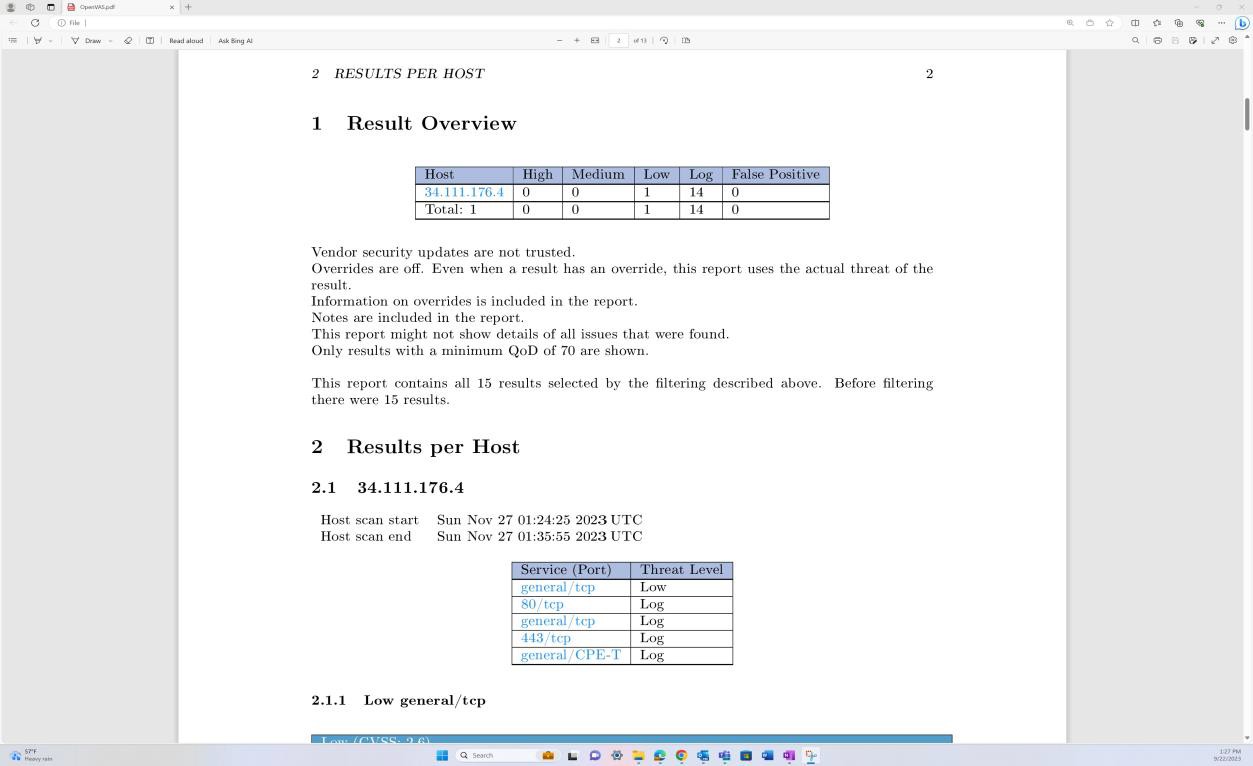
Les captures d’écran suivantes du rapport d’analyse des vulnérabilités tenable Nessus Essentials montrent que l’analyse de l’infrastructure interne est effectuée.
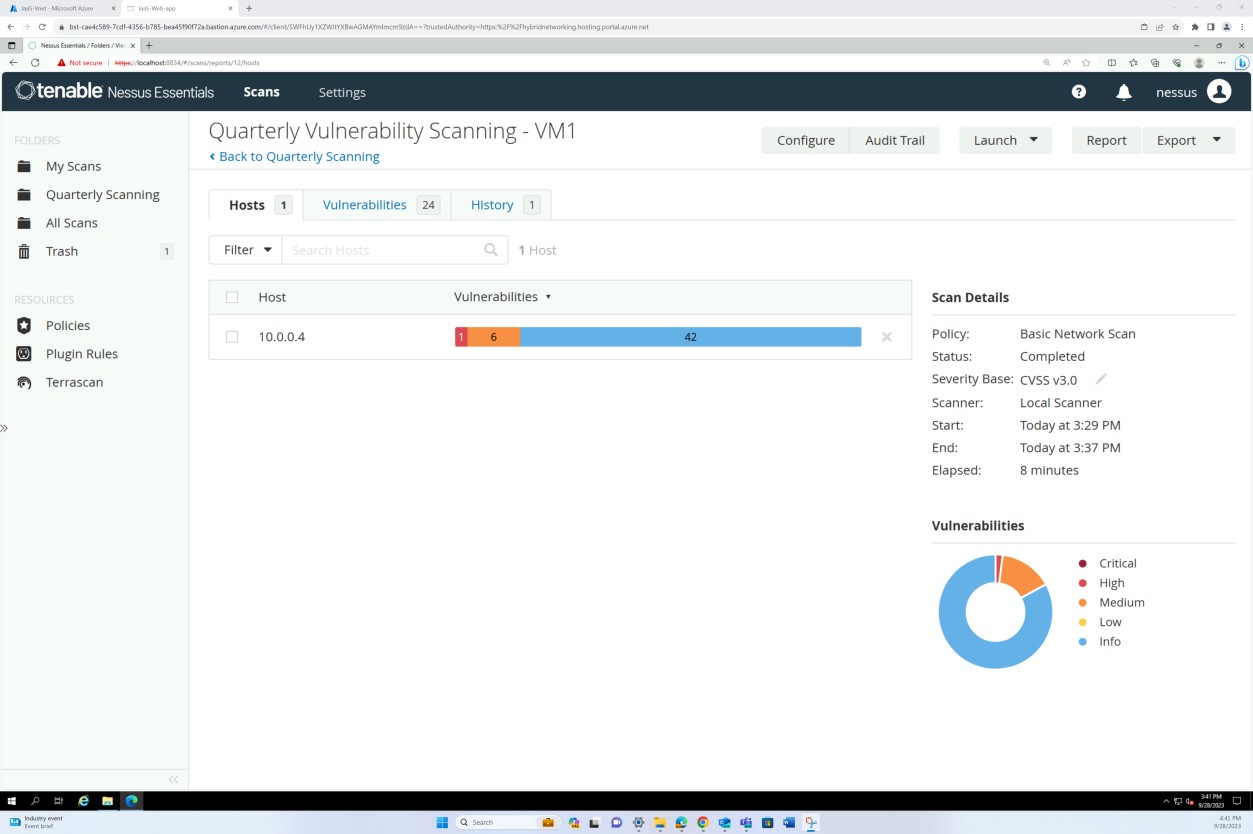
Les captures d’écran précédentes illustrent la configuration des dossiers pour les analyses trimestrielles sur les machines virtuelles hôtes.
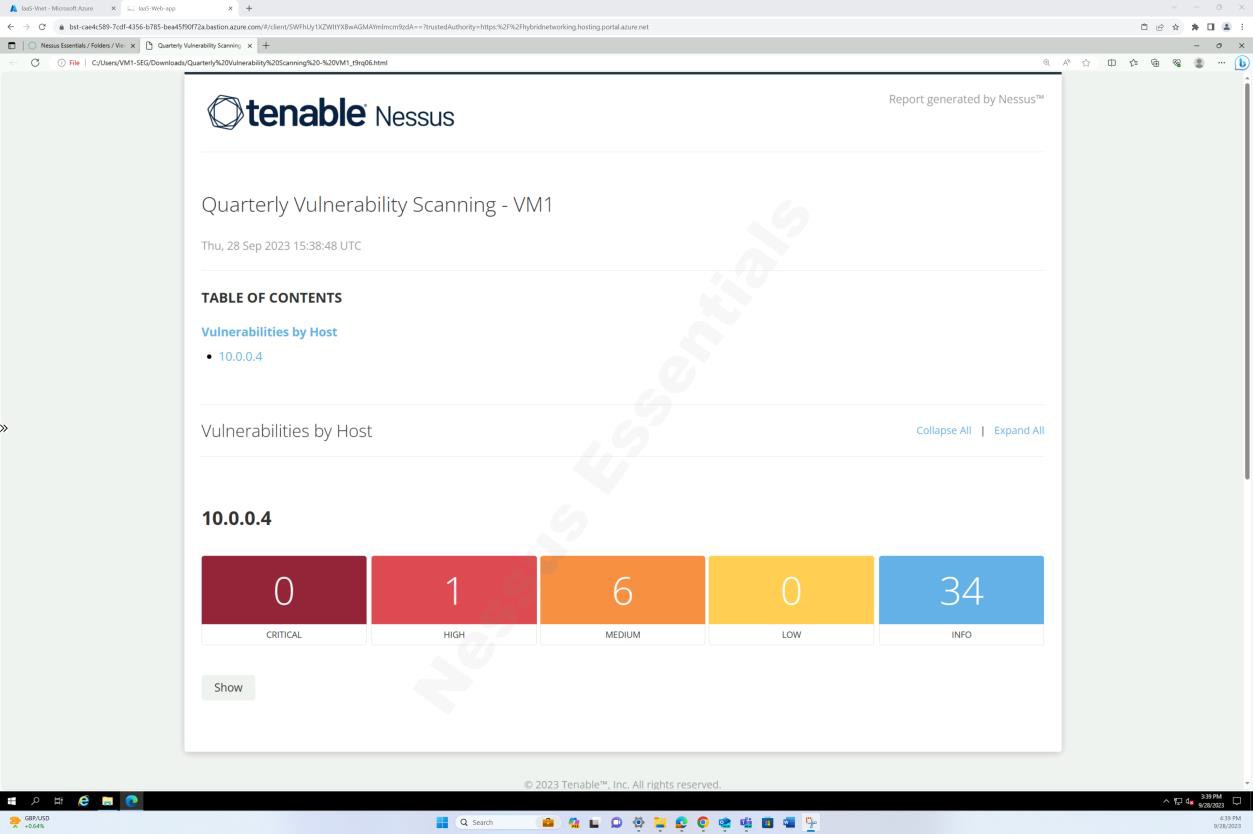
Les captures d’écran ci-dessus et ci-dessous montrent la sortie du rapport d’analyse des vulnérabilités.
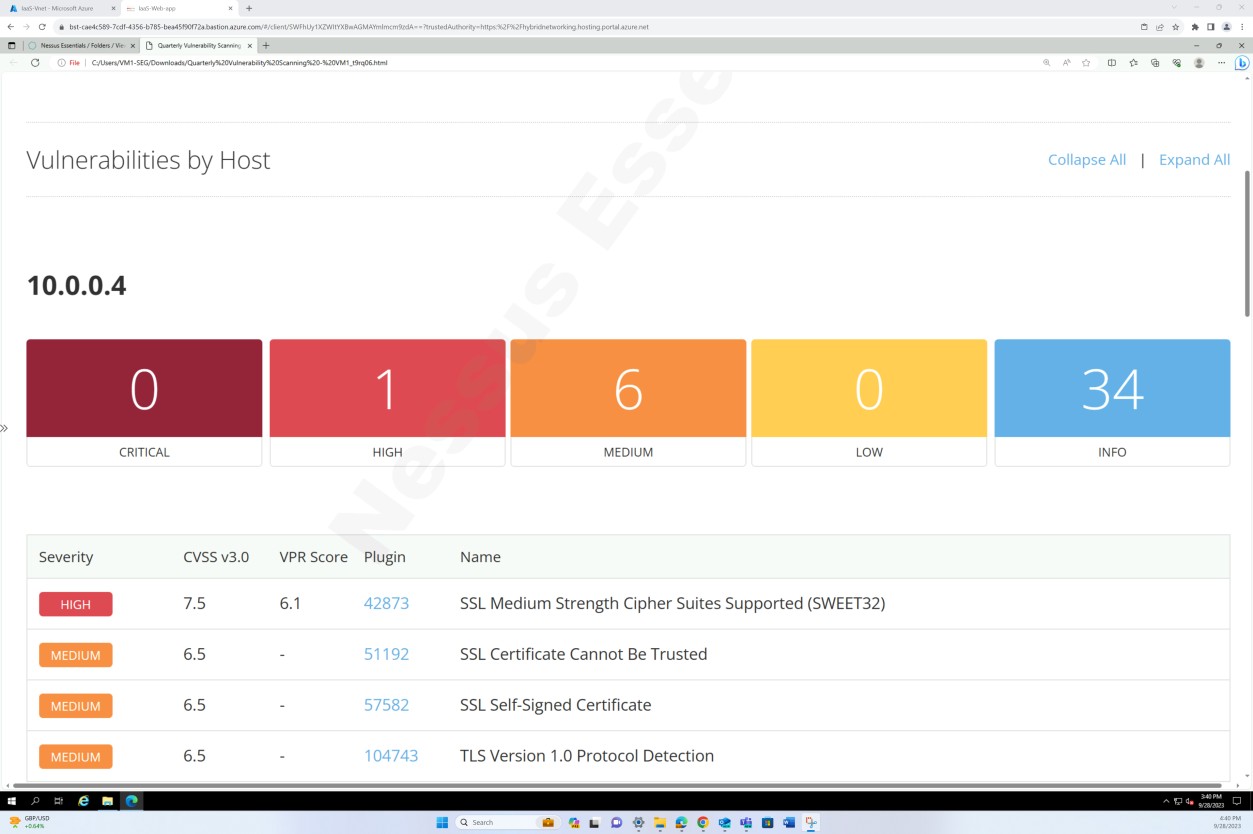
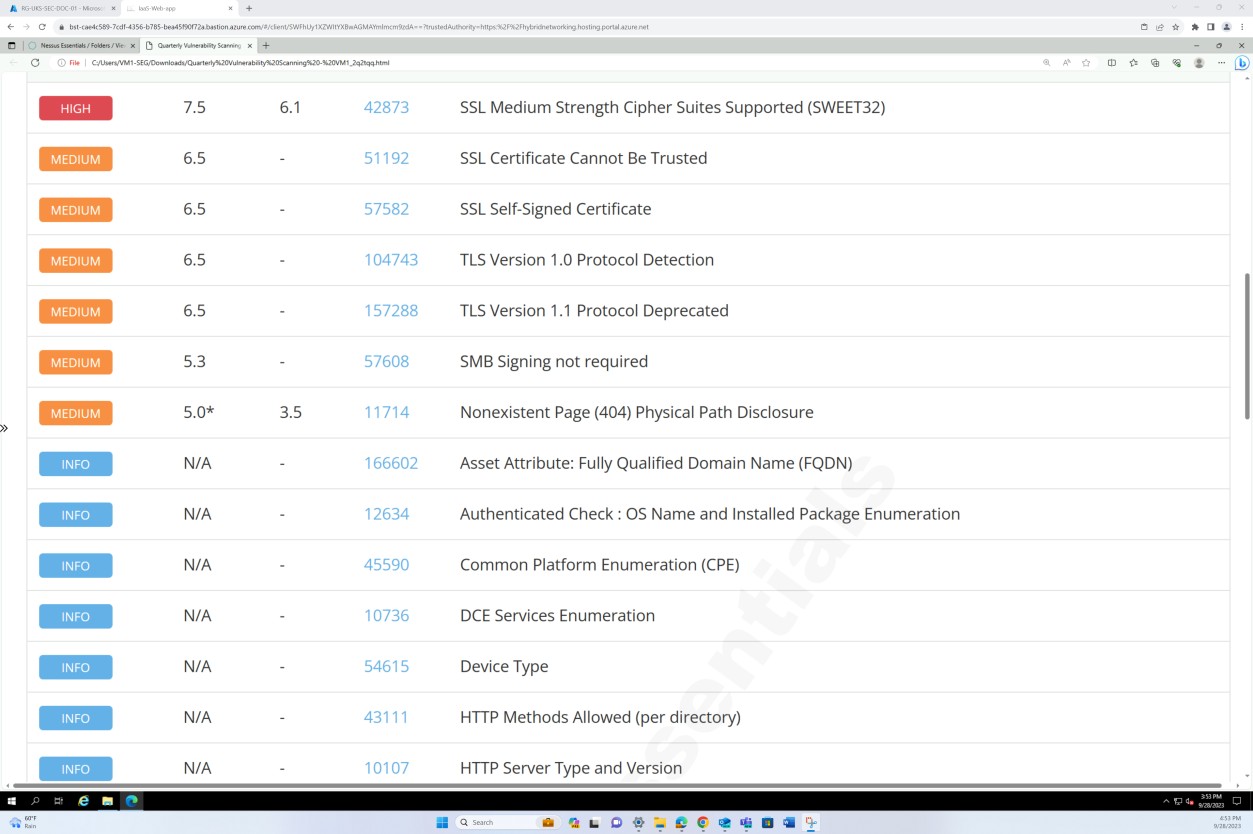
La capture d’écran suivante montre la continuation du rapport couvrant tous les problèmes détectés.
Contrôle n° 7
Fournissez une nouvelle preuve d’analyse montrant que :
- La correction de toutes les vulnérabilités identifiées dans le contrôle 6 est corrigée conformément à la fenêtre de mise à jour corrective minimale définie dans votre stratégie.
Intention : mise à jour corrective
Le fait de ne pas identifier, gérer et corriger rapidement les vulnérabilités et les erreurs de configuration peut augmenter le risque d’une compromission entraînant des violations de données potentielles. L’identification et la correction correctes des problèmes sont considérées comme importantes pour la posture de sécurité globale et l’environnement d’une organisation, ce qui est conforme aux meilleures pratiques de divers frameworks de sécurité, par exemple, ISO 27001 et PCI DSS.
L’objectif de ce contrôle est de s’assurer que l’organisation fournit des preuves crédibles des nouvelles analyses, ce qui démontre que toutes les vulnérabilités identifiées dans un contrôle 6 ont été corrigées. La correction doit s’aligner sur la fenêtre de mise à jour corrective minimale définie dans la stratégie de gestion des correctifs de l’organisation.
Recommandations : mise à jour corrective
Fournissez des rapports d’analyse de nouveau confirmant que toutes les vulnérabilités identifiées dans le contrôle 6 ont été corrigées conformément aux fenêtres de mise à jour corrective définies dans le contrôle 4 .
Exemple de preuve : mise à jour corrective
La capture d’écran suivante montre une analyse Nessus de l’environnement dans l’étendue (une seule machine dans cet exemple nommée Thor) montrant les vulnérabilités du 2août 2023.
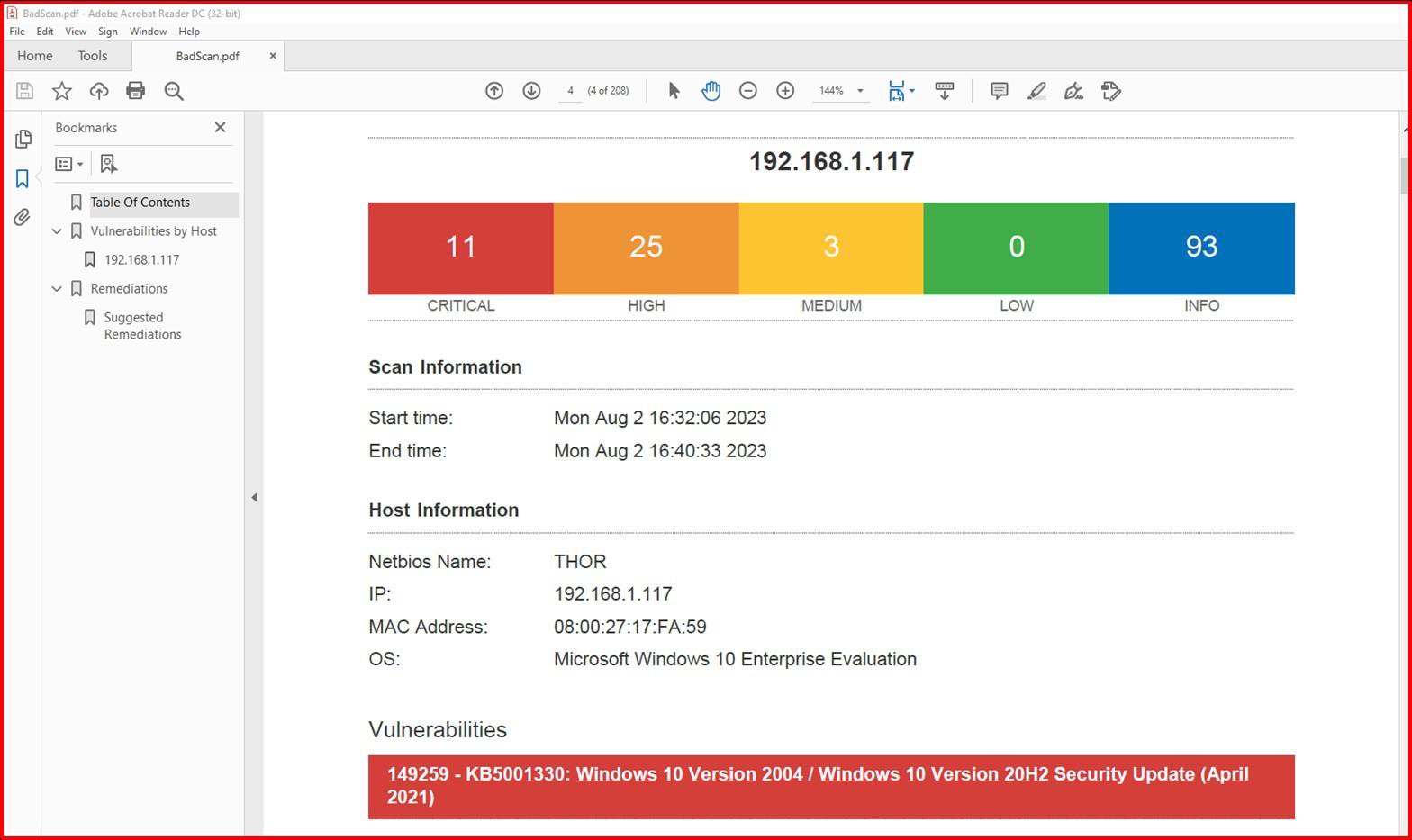
La capture d’écran suivante montre que les problèmes ont été résolus, 2 jours plus tard, ce qui se trouve dans la fenêtre de mise à jour corrective définie dans la stratégie de mise à jour corrective.
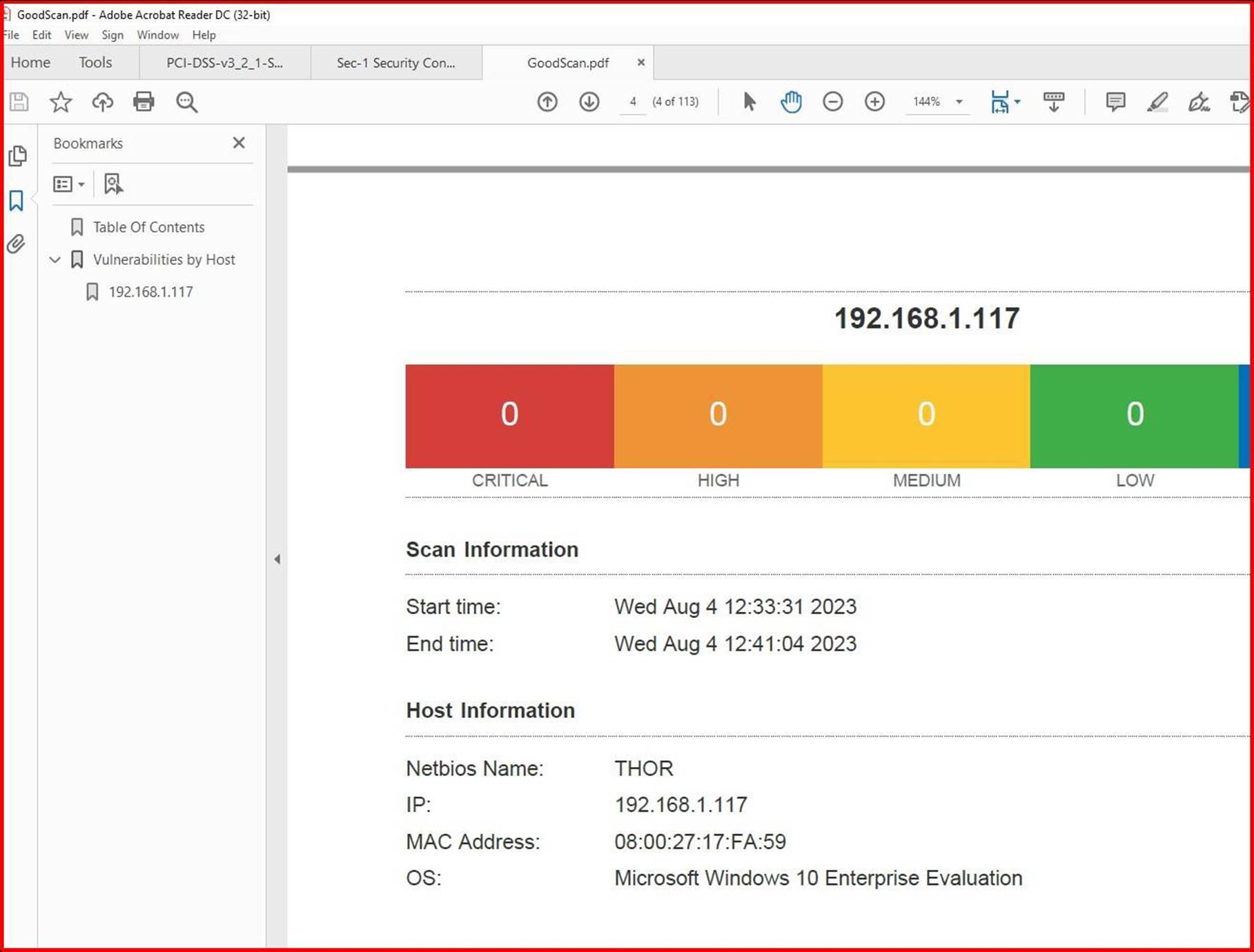
Remarque : Dans les exemples précédents, une capture d’écran complète n’a pas été utilisée, mais tous les éditeurs de logiciels indépendants envoyés
Les captures d’écran des preuves doivent être des captures d’écran complètes montrant n’importe quelle URL, l’utilisateur connecté, ainsi que l’heure et la date du système.
Contrôles de sécurité réseau (NSC)
Les contrôles de sécurité réseau sont un composant essentiel des infrastructures de cybersécurité telles que iso 27001, les contrôles CIS et le framework de cybersécurité NIST. Ils aident les organisations à gérer les risques associés aux cybermenaces, à protéger les données sensibles contre les accès non autorisés, à se conformer aux exigences réglementaires, à détecter et à répondre aux cybermenaces en temps voulu, et à garantir la continuité de l’activité. Une sécurité réseau efficace protège les ressources de l’organisation contre un large éventail de menaces internes ou externes à l’organisation.
Contrôle n° 8
Fournissez des preuves démontrables que :
- Les contrôles de sécurité réseau (NSC) sont installés à la limite de l’environnement dans l’étendue et installés entre le réseau de périmètre et les réseaux internes.
ET si l’iaaS est hybride, local, fournit également la preuve que :
- Tout accès public se termine au niveau du réseau de périmètre.
Intention : NSC
Ce contrôle vise à vérifier que les contrôles de sécurité réseau (NSC) sont installés à des emplacements clés au sein de la topologie réseau de l’organisation. Plus précisément, les NSC doivent être placés à la limite de l’environnement dans l’étendue et entre le réseau de périmètre et les réseaux internes. L’objectif de ce contrôle est de vérifier que ces mécanismes de sécurité sont correctement placés pour optimiser leur efficacité dans la protection des ressources numériques de l’organisation.
Lignes directrices : NSC
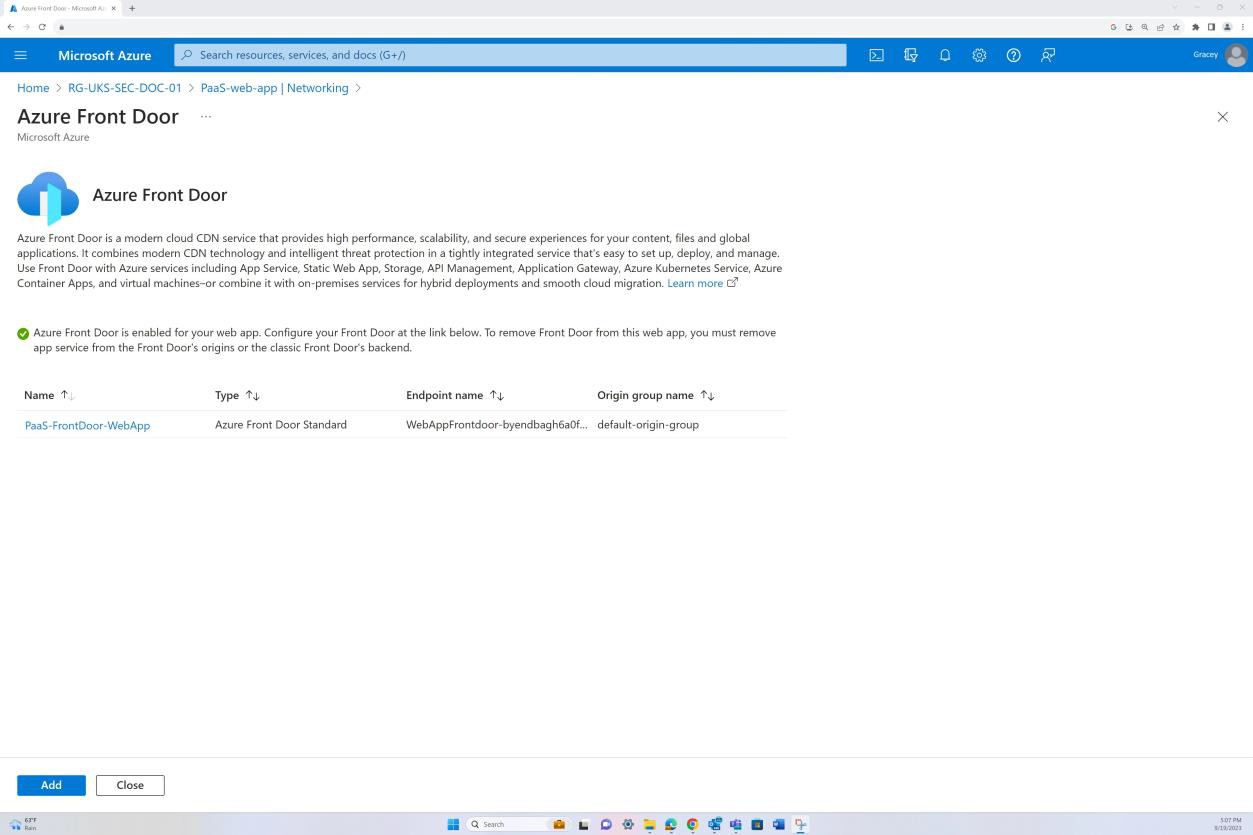
Des preuves doivent être fournies pour démontrer que les contrôles de sécurité réseau (NSC) sont installés à la limite et configurés entre le périmètre et les réseaux internes. Pour ce faire, vous pouvez fournir les captures d’écran des paramètres de configuration des contrôles de sécurité réseau (NSC) et l’étendue à laquelle il est appliqué, par exemple, un pare-feu ou une technologie équivalente comme les groupes de sécurité réseau (NSG), Azure Front Door, etc.
Exemple de preuve : NSC
La capture d’écran suivante provient de l’application web « PaaS-web-app » ; Le panneau réseau montre que tout le trafic entrant transite par Azure Front Door, tandis que tout le trafic de l’application vers d’autres ressources Azure est routé et filtré via le groupe de sécurité réseau Azure via l’intégration au réseau virtuel.
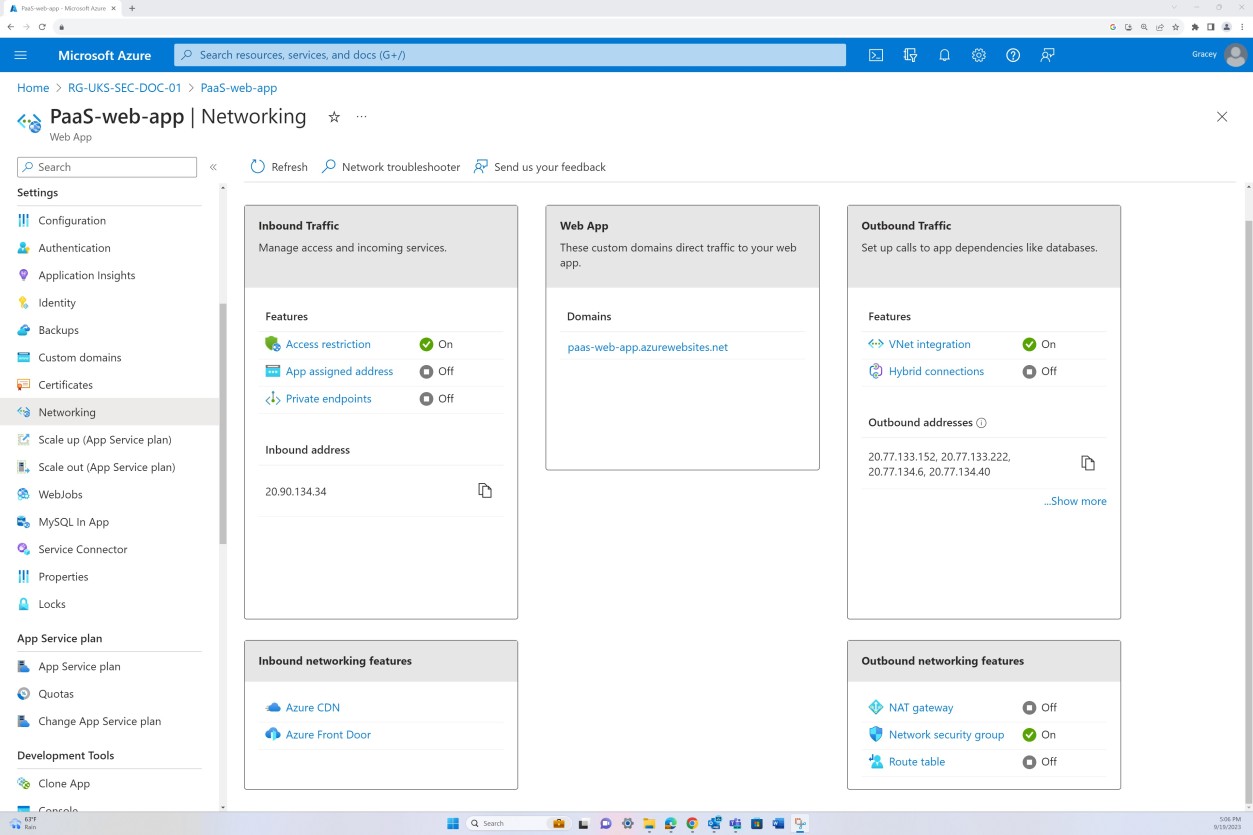
Les règles de refus dans les « restrictions d’accès » empêchent tout trafic entrant, à l’exception de Front Door (FD), le trafic est routé via FD avant d’atteindre l’application.
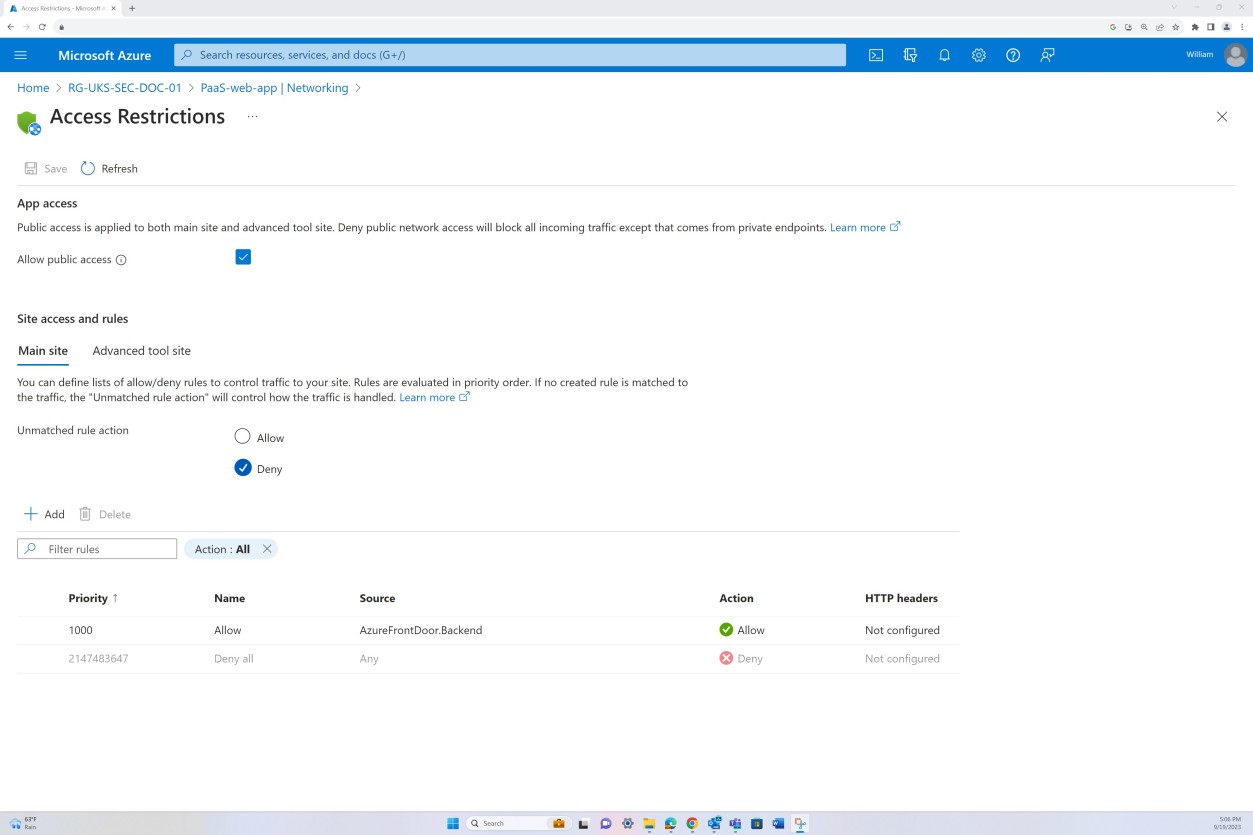
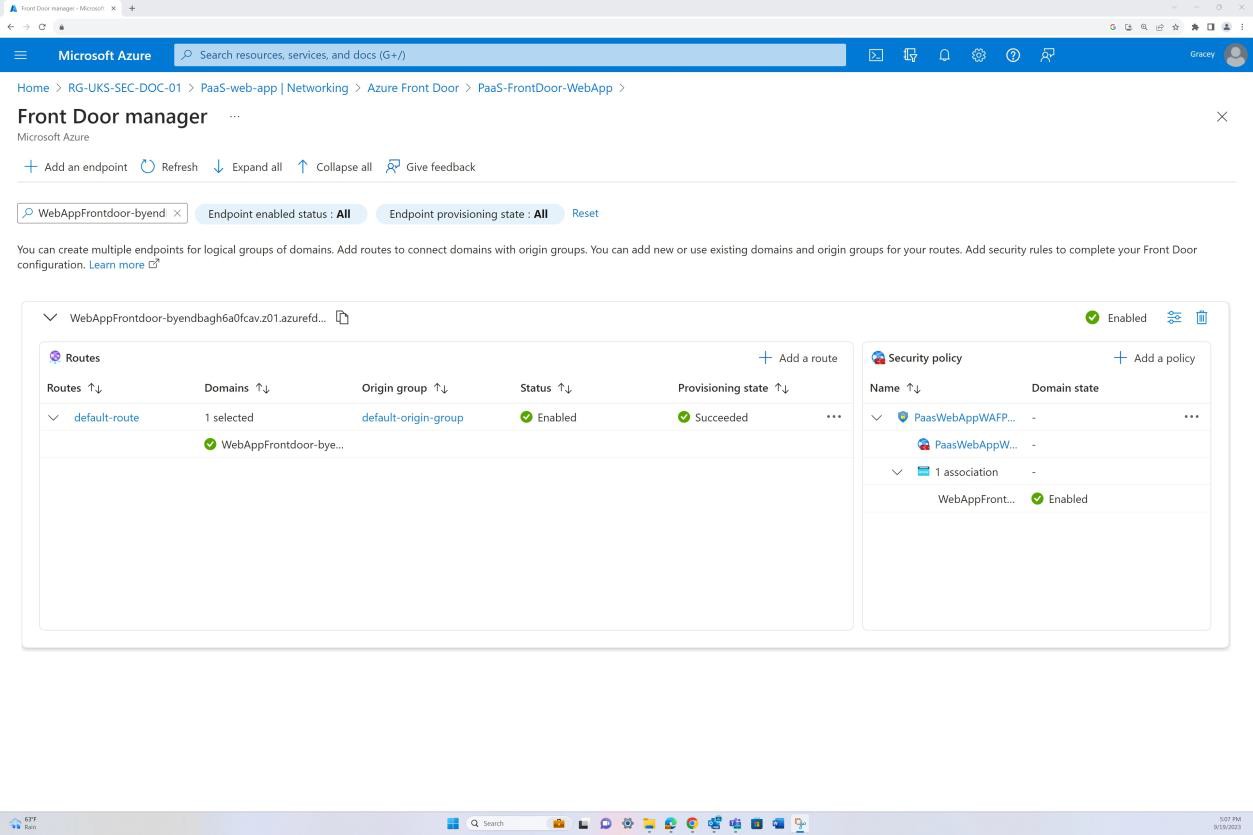
Exemple de preuve : NSC
La capture d’écran suivante montre l’itinéraire par défaut d’Azure Front Door et le trafic est routé via Front Door avant d’atteindre l’application. La stratégie WAF a également été appliquée.
Exemple de preuve : NSC
La première capture d’écran montre un groupe de sécurité réseau Azure appliqué au niveau du réseau virtuel pour filtrer le trafic entrant et sortant. La deuxième capture d’écran montre que SQL Server n’est pas routable sur Internet et qu’il est intégré via le réseau virtuel et via une liaison privée.
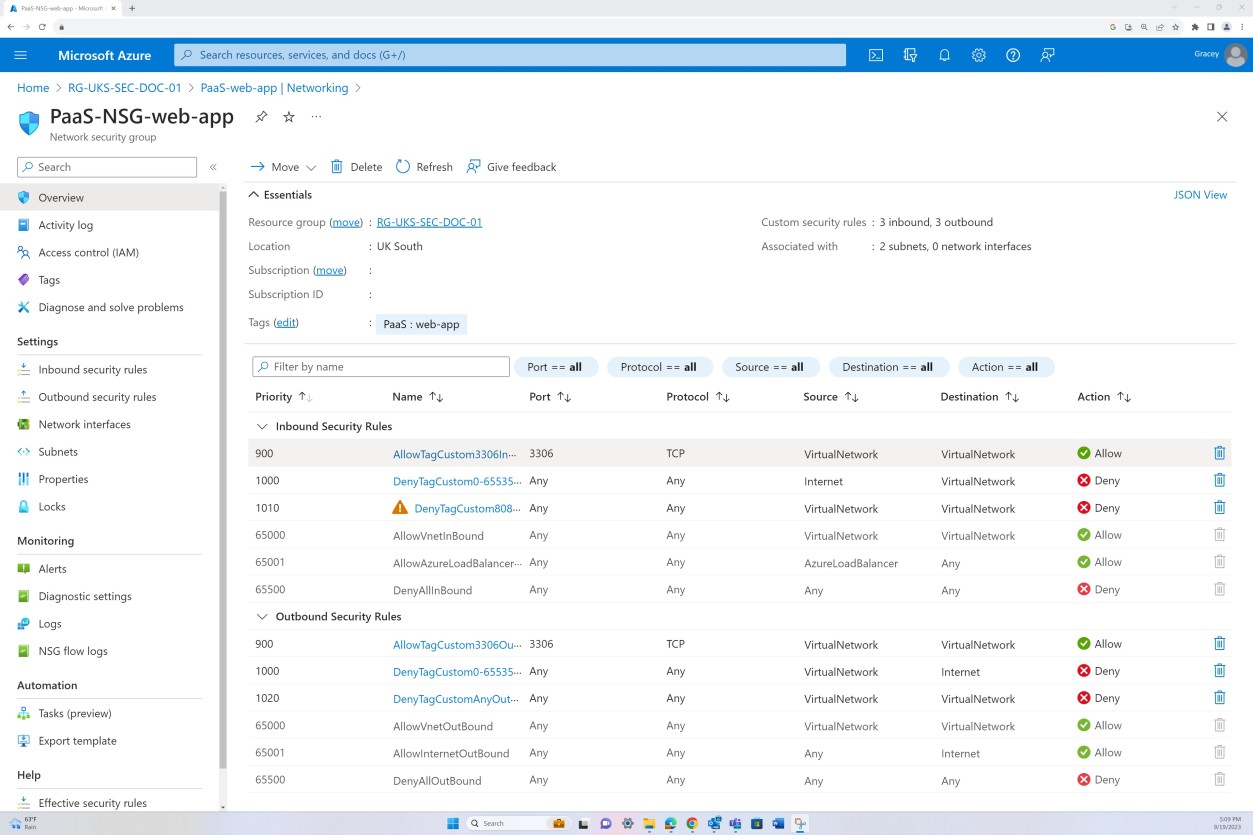
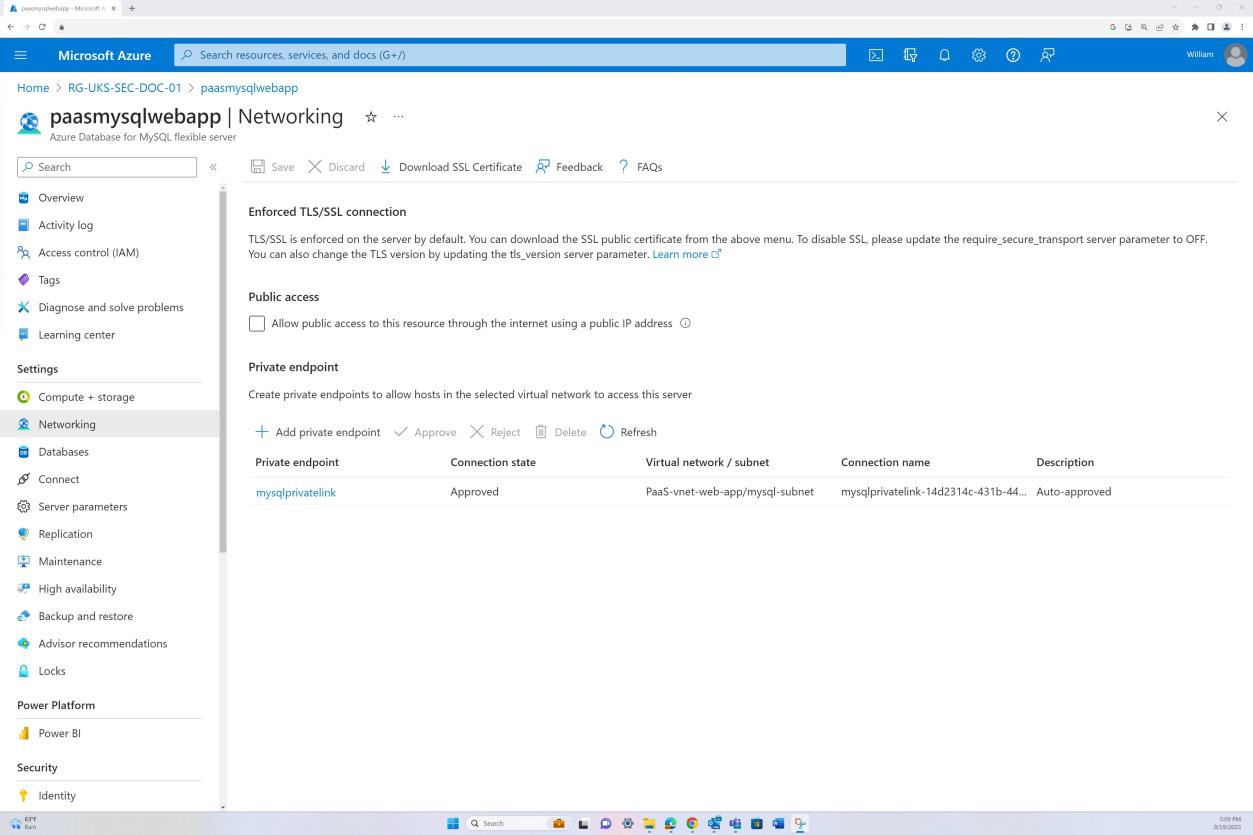
Cela garantit que le trafic interne et la communication sont filtrés par le groupe de sécurité réseau avant d’atteindre le serveur SQL.
Intent**:** hybride, local, IaaS
Ce sous-point est essentiel pour les organisations qui exploitent des modèles IaaS (Infrastructure as a Service) hybrides, locaux ou locaux. Il vise à s’assurer que tous les accès publics se terminent au niveau du réseau de périmètre, ce qui est essentiel pour contrôler les points d’entrée dans le réseau interne et réduire l’exposition potentielle aux menaces externes. La preuve de conformité peut inclure des configurations de pare-feu, des listes de contrôle d’accès réseau ou d’autres documents similaires qui peuvent justifier l’affirmation selon laquelle l’accès public ne s’étend pas au-delà du réseau de périmètre.
Exemple de preuve : hybride, local, IaaS
La capture d’écran montre que SQL Server n’est pas routable sur Internet et qu’il est intégré via le réseau virtuel et via une liaison privée. Cela garantit que seul le trafic interne est autorisé.
Exemple de preuve : hybride, local, IaaS
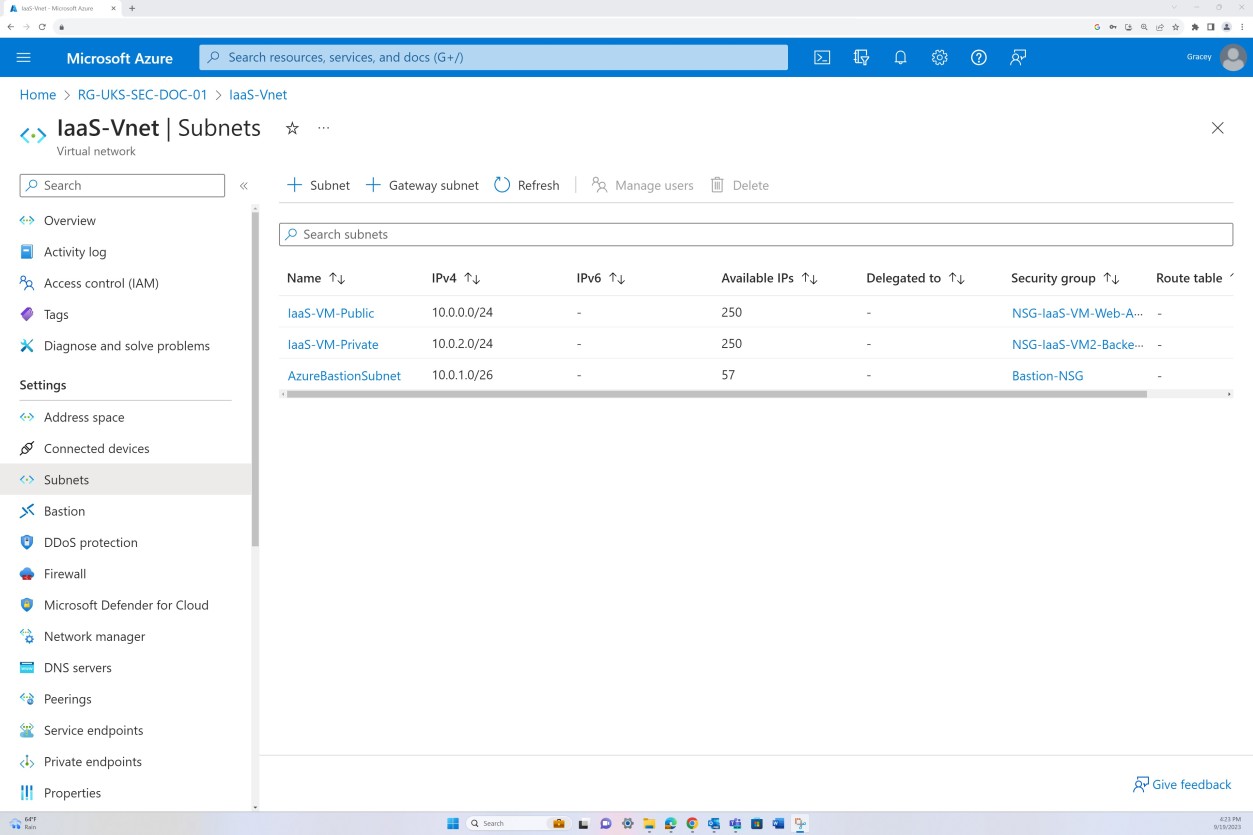
Les captures d’écran suivantes montrent que la segmentation du réseau est en place dans le réseau virtuel dans l’étendue. Le réseau virtuel comme indiqué ci-dessous est divisé en trois sous-réseaux, chacun avec un groupe de sécurité réseau appliqué.
Le sous-réseau public fait office de réseau de périmètre. Tout le trafic public est routé via ce sous-réseau et filtré via le groupe de sécurité réseau avec des règles spécifiques, et seul le trafic explicitement défini est autorisé. Le back-end se compose du sous-réseau privé sans accès public. Tout accès aux machines virtuelles est autorisé uniquement via l’hôte Bastion qui a son propre groupe de sécurité réseau appliqué au niveau du sous-réseau.
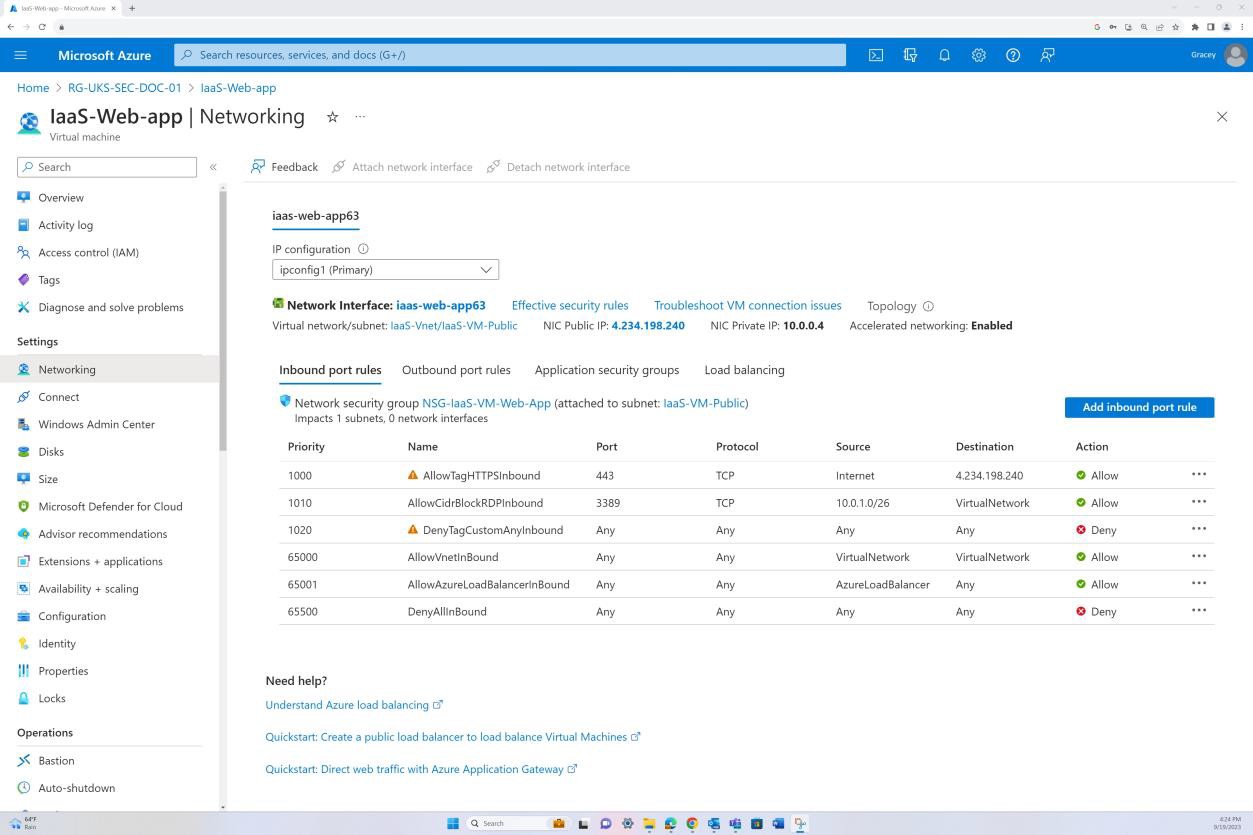
La capture d’écran suivante montre que le trafic à partir d’Internet vers une adresse IP spécifique est autorisé uniquement sur le port 443. En outre, le protocole RDP est autorisé uniquement à partir de la plage d’adresses IP Bastion vers le réseau virtuel.
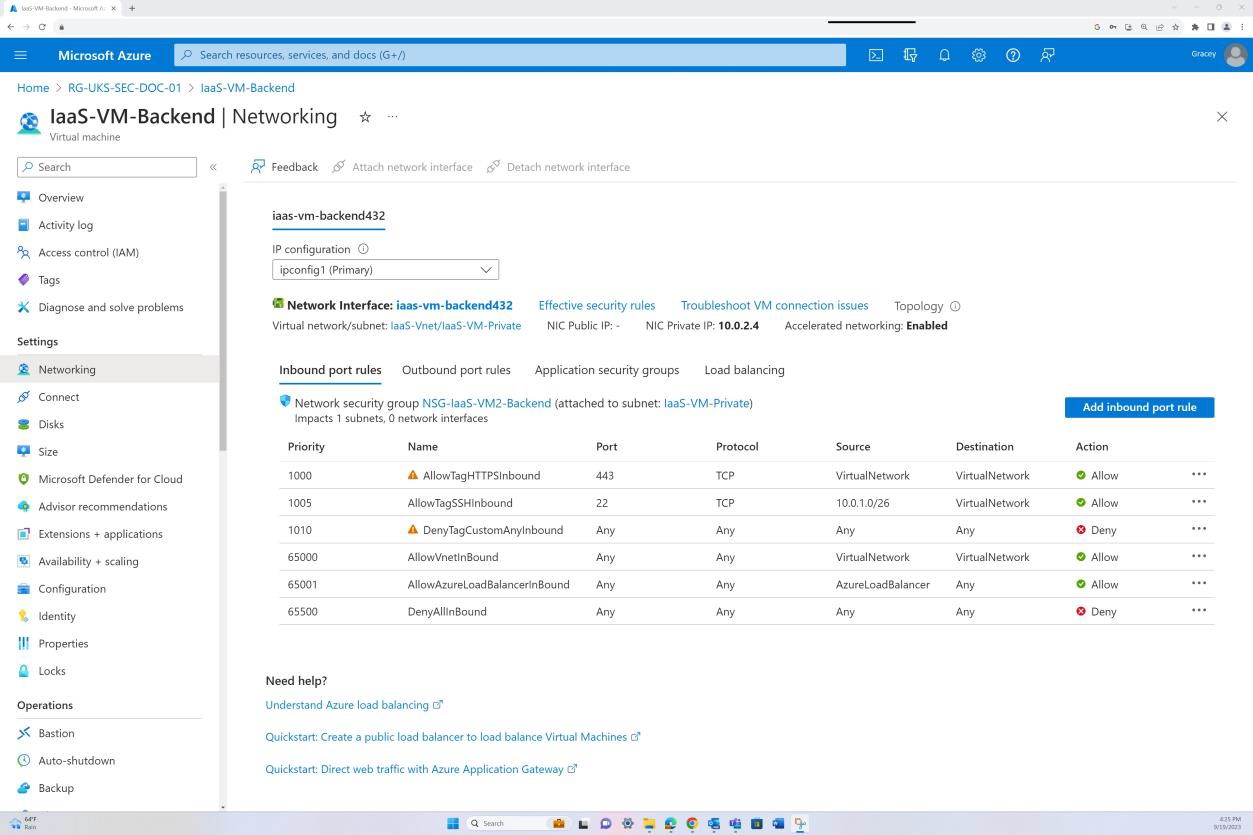
La capture d’écran suivante montre que le back-end n’est pas routable sur Internet (cela est dû à l’absence d’adresse IP publique pour la carte réseau) et que le trafic est autorisé uniquement à provenir du réseau virtuel et bastion.
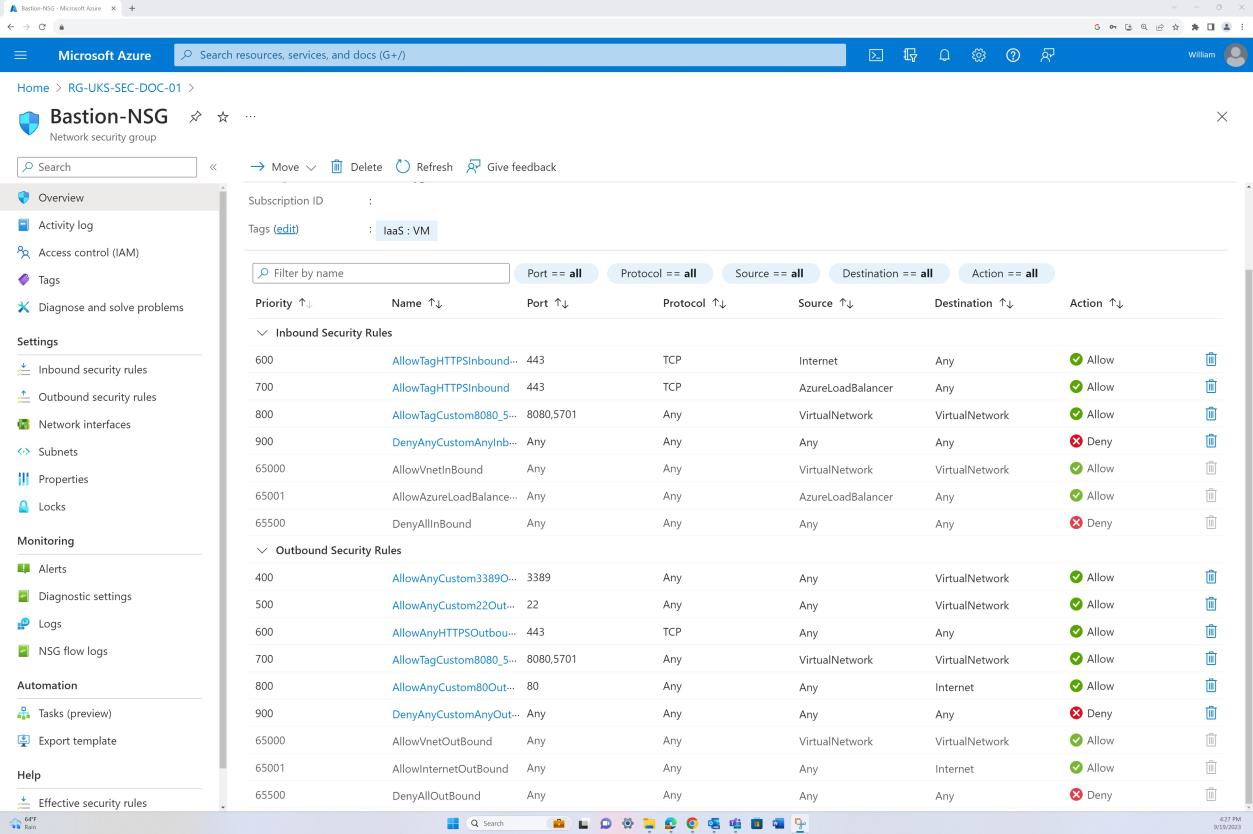
La capture d’écran montre que l’hôte Azure Bastion est utilisé pour accéder aux machines virtuelles uniquement à des fins de maintenance.
Contrôle n° 9
Tous les contrôles de sécurité réseau (NSC) sont configurés pour supprimer le trafic qui n’est pas explicitement défini dans la base de règles.
Les révisions des règles de contrôle de sécurité réseau (NSC) sont effectuées au moins tous les six mois.
Intention : NSC
Ce sous-point garantit que tous les contrôles de sécurité réseau (NSC) d’une organisation sont configurés pour supprimer tout trafic réseau qui n’est pas explicitement défini dans leur base de règles. L’objectif est d’appliquer le principe du privilège minimum au niveau de la couche réseau en autorisant uniquement le trafic autorisé tout en bloquant tout le trafic non spécifié ou potentiellement malveillant.
Lignes directrices : NSC
Les preuves fournies à cet effet peuvent être des configurations de règles qui affichent les règles de trafic entrant et l’endroit où ces règles sont arrêtées ; soit en acheminant les adresses IP publiques vers les ressources, soit en fournissant la traduction d’adresses réseau (NAT) du trafic entrant.
Exemple de preuve : NSC
La capture d’écran montre la configuration du groupe de sécurité réseau, y compris l’ensemble de règles par défaut et une règle Deny :All personnalisée pour réinitialiser toutes les règles par défaut du groupe de sécurité réseau et garantir que tout le trafic est interdit. Dans les règles personnalisées supplémentaires, la règle Deny :All définit explicitement le trafic autorisé.
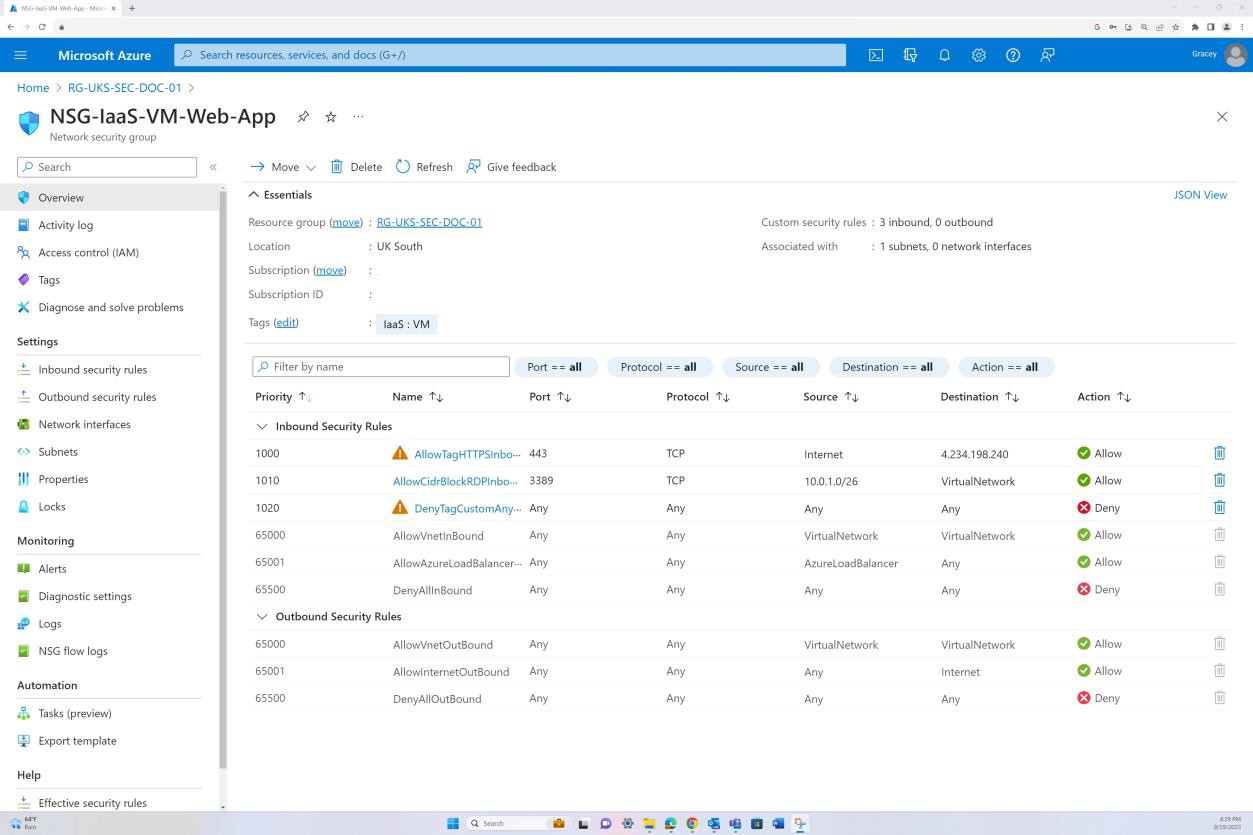
Exemple de preuve : NSC
Les captures d’écran suivantes montrent qu’Azure Front Door est déployé et que tout le trafic est routé via Front Door. Une stratégie WAF en « mode prévention » est appliquée, qui filtre le trafic entrant pour les charges utiles potentielles malveillantes et le bloque.
Intention : NSC
Sans révisions régulières, les contrôles de sécurité réseau (NSC) peuvent devenir obsolètes et inefficaces, laissant une organisation vulnérable aux cyberattaques. Cela peut entraîner des violations de données, le vol d’informations sensibles et d’autres incidents de cybersécurité. Les examens réguliers du NSC sont essentiels pour gérer les risques, protéger les données sensibles, se conformer aux exigences réglementaires, détecter les cybermenaces et y répondre en temps opportun, et assurer la continuité de l’activité. Ce sous-point exige que les contrôles de sécurité réseau (NSC) soient soumis à un examen de la base de règles au moins tous les six mois. Des examens réguliers sont essentiels pour maintenir l’efficacité et la pertinence des configurations NSC, en particulier dans les environnements réseau en évolution dynamique.
Lignes directrices : NSC
Toute preuve fournie doit être en mesure de démontrer que des réunions d’examen des règles ont eu lieu. Pour ce faire, vous pouvez partager les procès-verbaux de réunion de l’examen du CSN et toute preuve supplémentaire de contrôle des modifications montrant les mesures prises à partir de l’examen. Assurez-vous que les dates sont présentes, car l’analyste de certification qui examine votre soumission doit voir au moins deux de ces documents d’examen de réunion (c’est-à-dire tous les six mois).
Exemple de preuve : NSC
Ces captures d’écran montrent qu’il existe des révisions de pare-feu six mois et que les détails sont conservés dans la plateforme Confluence Cloud.
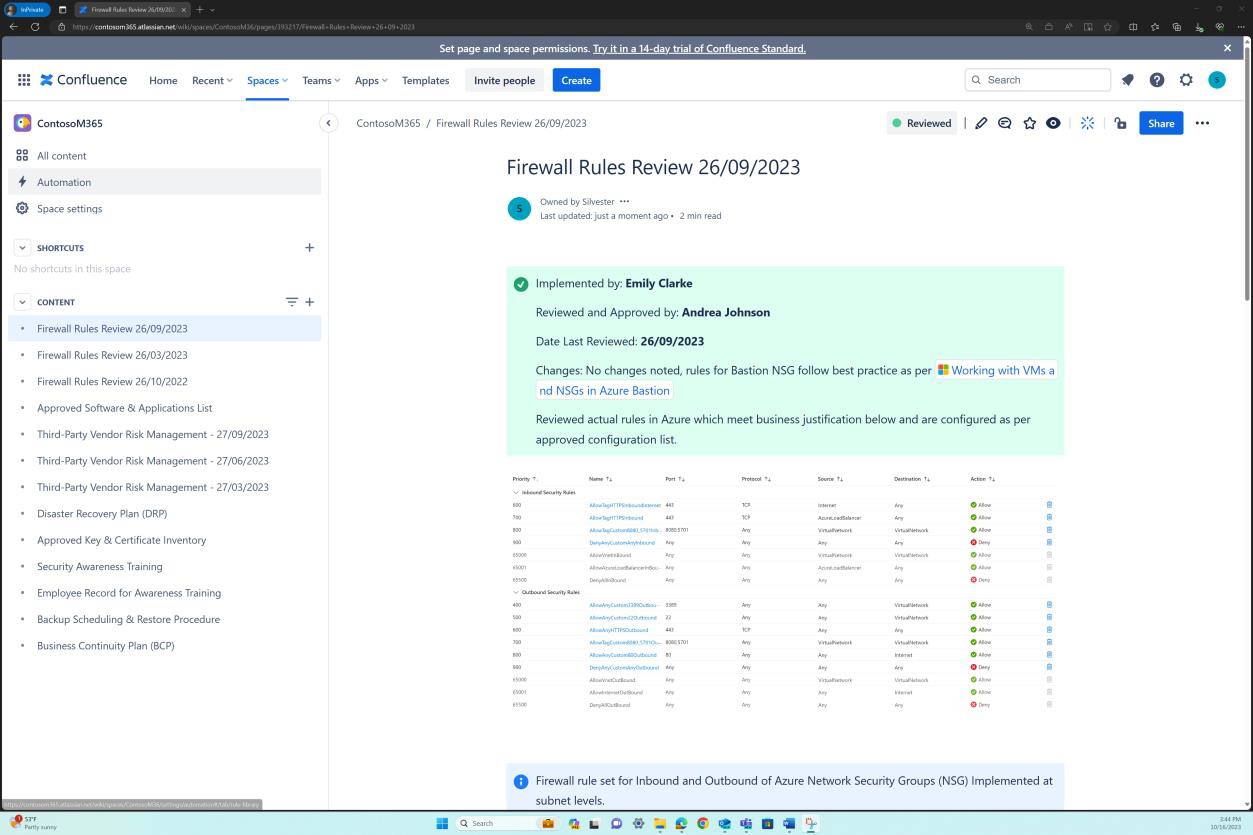
La capture d’écran suivante montre que chaque révision de règle a une page créée dans Confluence. La révision des règles contient une liste d’ensembles de règles approuvées décrivant le trafic autorisé, le numéro de port, le protocole, etc. ainsi que la justification métier.
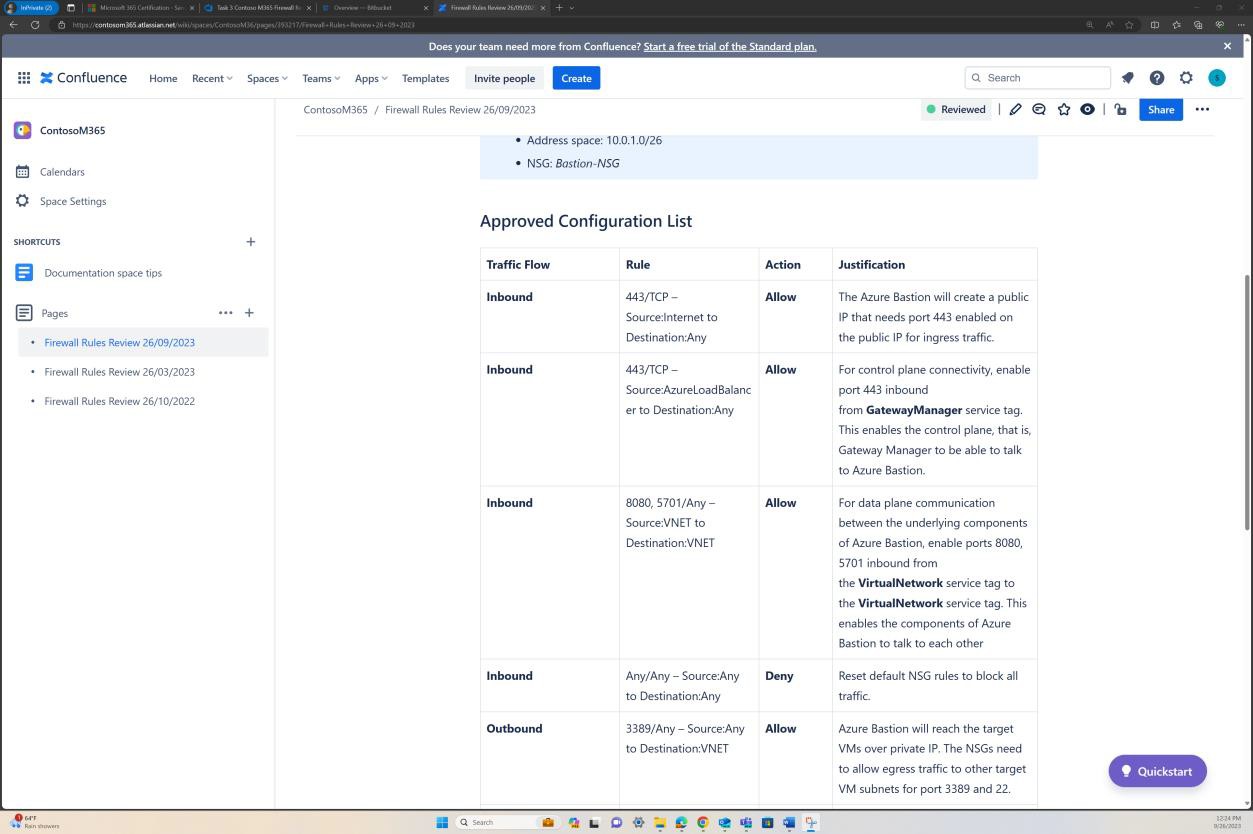
Exemple de preuve : NSC
La capture d’écran suivante montre un autre exemple d’examen des règles de six mois en cours de maintenance dans DevOps.
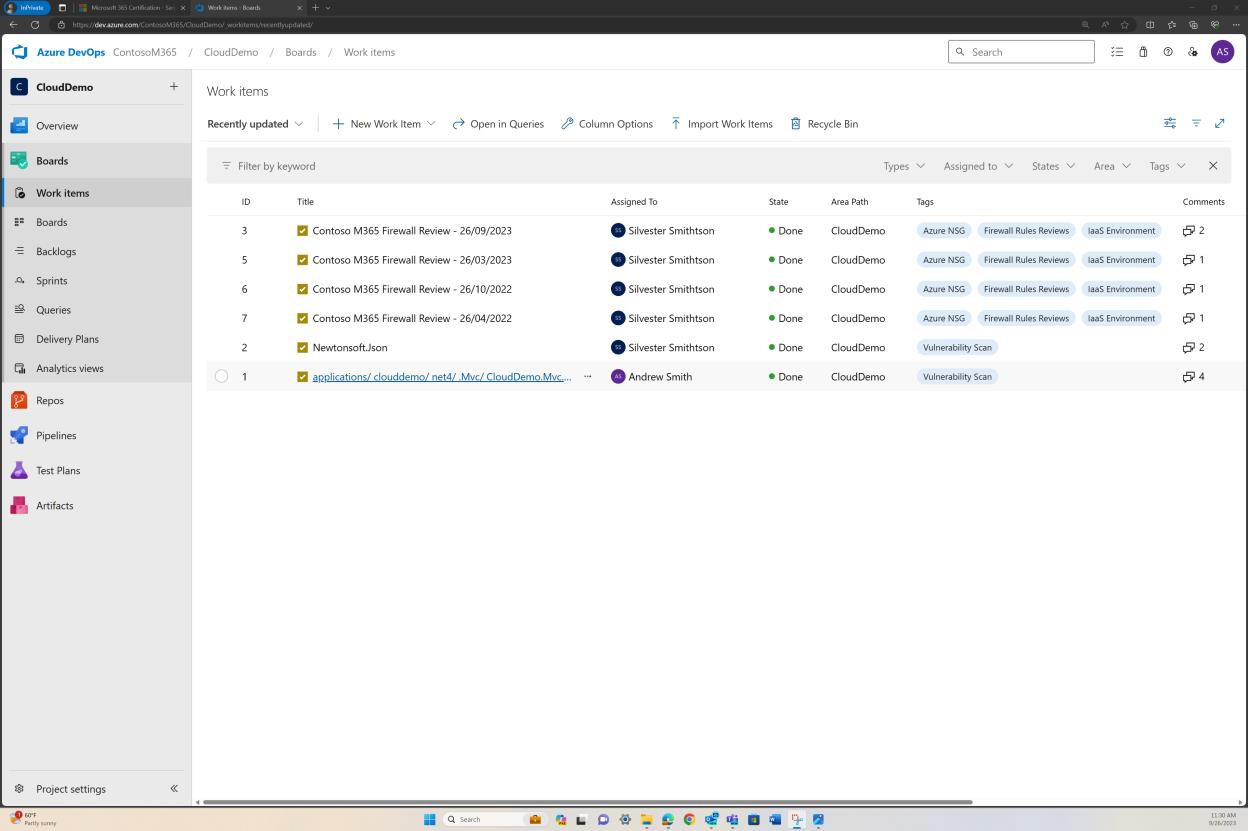
Exemple de preuve : NSC
Cette capture d’écran montre un exemple de révision de règle en cours d’exécution et d’enregistrement en tant que ticket dans DevOps.
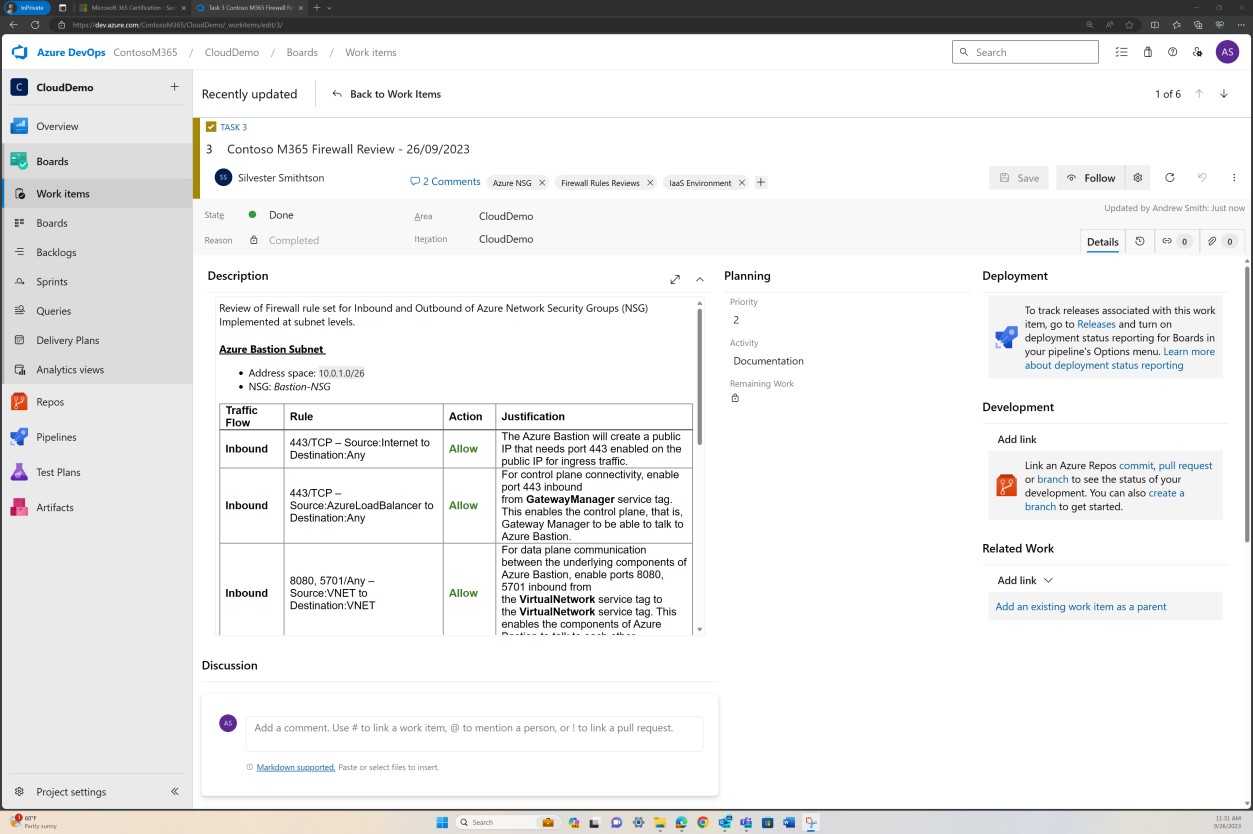
La capture d’écran précédente montre la liste des règles documentées établie avec la justification métier, tandis que l’image suivante montre un instantané des règles dans le ticket à partir du système réel.
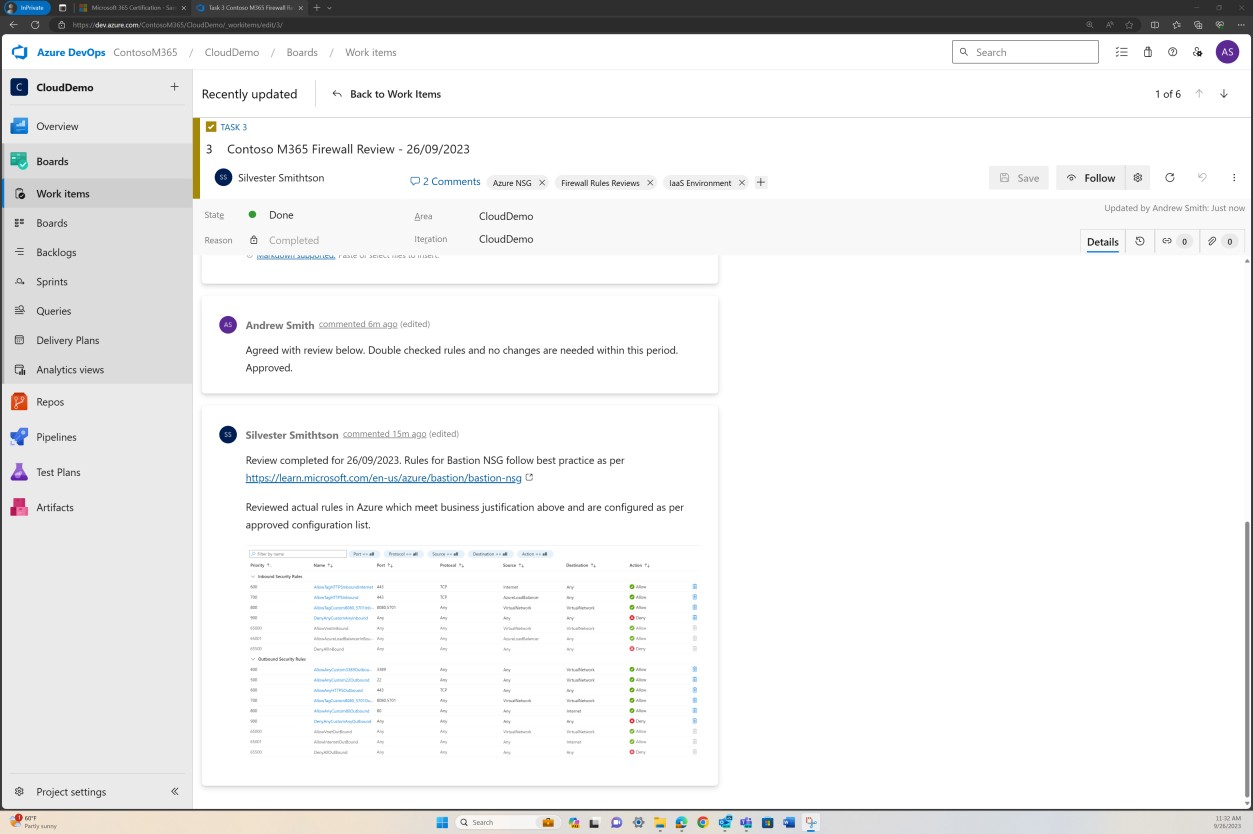
Contrôle des modifications
Un processus de contrôle des modifications établi et compris est essentiel pour garantir que toutes les modifications passent par un processus structuré et reproductible. En veillant à ce que toutes les modifications passent par un processus structuré, les organisations peuvent s’assurer que les modifications sont gérées efficacement, examinées par les pairs et testées de manière adéquate avant d’être signées. Cela permet non seulement de réduire le risque de pannes du système, mais aussi de réduire le risque d’incidents de sécurité potentiels grâce à l’introduction de modifications incorrectes.
Contrôle n° 10
Fournissez des preuves démontrant que :
Toutes les modifications introduites dans les environnements de production sont implémentées par le biais de demandes de modification documentées qui contiennent :
impact de la modification.
détails des procédures de back-out.
tests à effectuer.
examen et approbation par le personnel autorisé.
Intention : contrôle de modification
L’objectif de ce contrôle est de s’assurer que toutes les modifications demandées ont été soigneusement prises en compte et documentées. Cela inclut l’évaluation de l’impact de la modification sur la sécurité du système/de l’environnement, la documentation des procédures d’arrière-plan pour faciliter la récupération en cas de problème et le détail des tests nécessaires pour valider la réussite de la modification.
Des processus doivent être implémentés qui interdisent les modifications d’être effectuées sans autorisation et approbation appropriées. La modification doit être autorisée avant d’être implémentée et la modification doit être signée une fois terminée. Cela garantit que les demandes de modification ont été correctement examinées et qu’une personne autorisée a approuvé la modification.
Recommandations : contrôle des modifications
Vous pouvez fournir des preuves en partageant des captures d’écran d’un échantillon de demandes de modification montrant que les détails de l’impact de la modification, les procédures de recul et les tests sont conservés dans la demande de modification.
Exemple de preuve : contrôle des modifications
La capture d’écran suivante montre une nouvelle vulnérabilité XSS (Cross Site Scripting Vulnerability) affectée et documente la demande de modification. Les tickets ci-dessous illustrent les informations qui ont été définies ou ajoutées au ticket sur son trajet en cours de résolution.
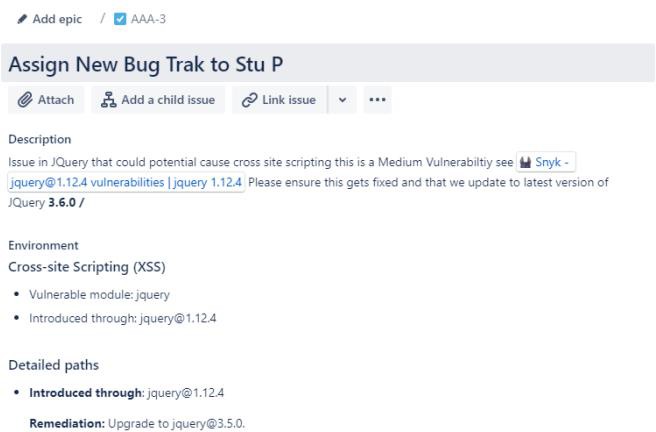
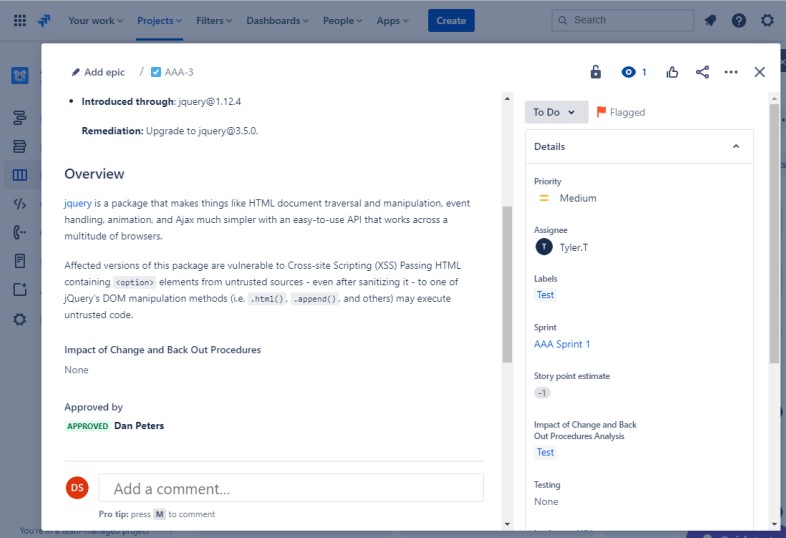
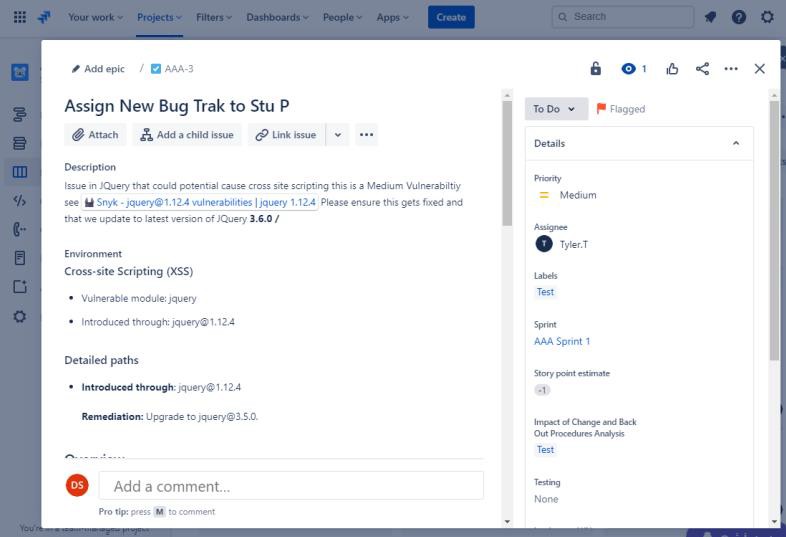
Les deux tickets suivants montrent l’impact de la modification du système et des procédures de retour en arrière qui peuvent être nécessaires en cas de problème. L’impact des modifications et des procédures de recul a fait l’objet d’un processus d’approbation et a été approuvé pour les tests.
Sur la capture d’écran suivante, le test des modifications a été approuvé et, à droite, vous voyez que les modifications ont maintenant été approuvées et testées.
Tout au long du processus, notez que la personne qui effectue le travail, la personne qui en fait rapport et la personne qui approuve le travail à accomplir sont des personnes différentes.
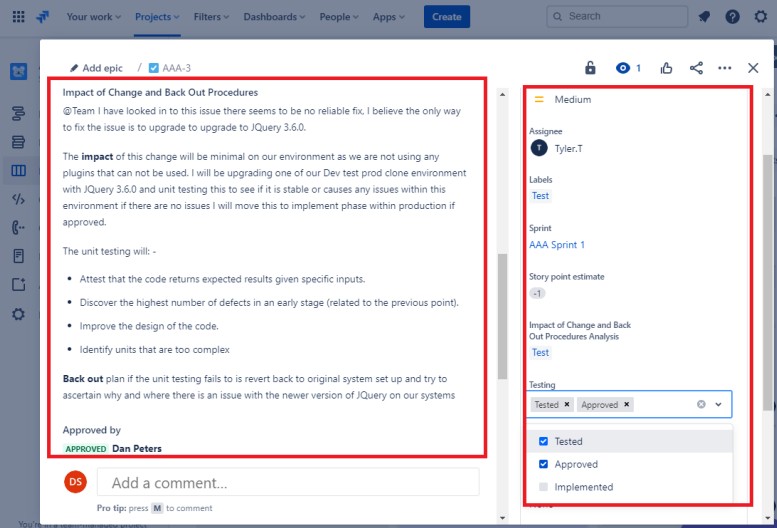
Le ticket suivant montre que les modifications ont maintenant été approuvées pour l’implémentation dans l’environnement de production. La zone de droite indique que le test a fonctionné et a réussi et que les modifications sont désormais implémentées dans l’environnement Prod.
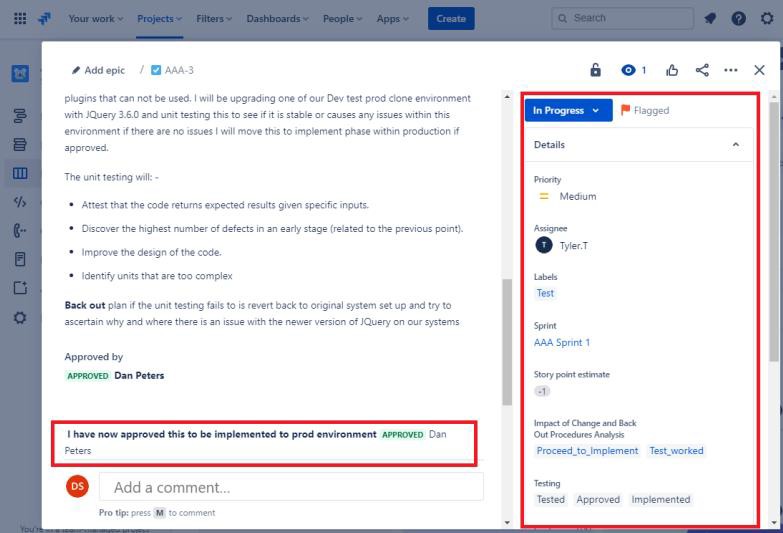
Exemple de preuve
Les captures d’écran suivantes montrent un exemple de ticket Jira montrant que la modification doit être autorisée avant d’être implémentée et approuvée par une personne autre que le développeur/demandeur. Les modifications sont approuvées par une personne autorisée. La droite de la capture d’écran montre que la modification a été signée par DP une fois l’opération terminée.
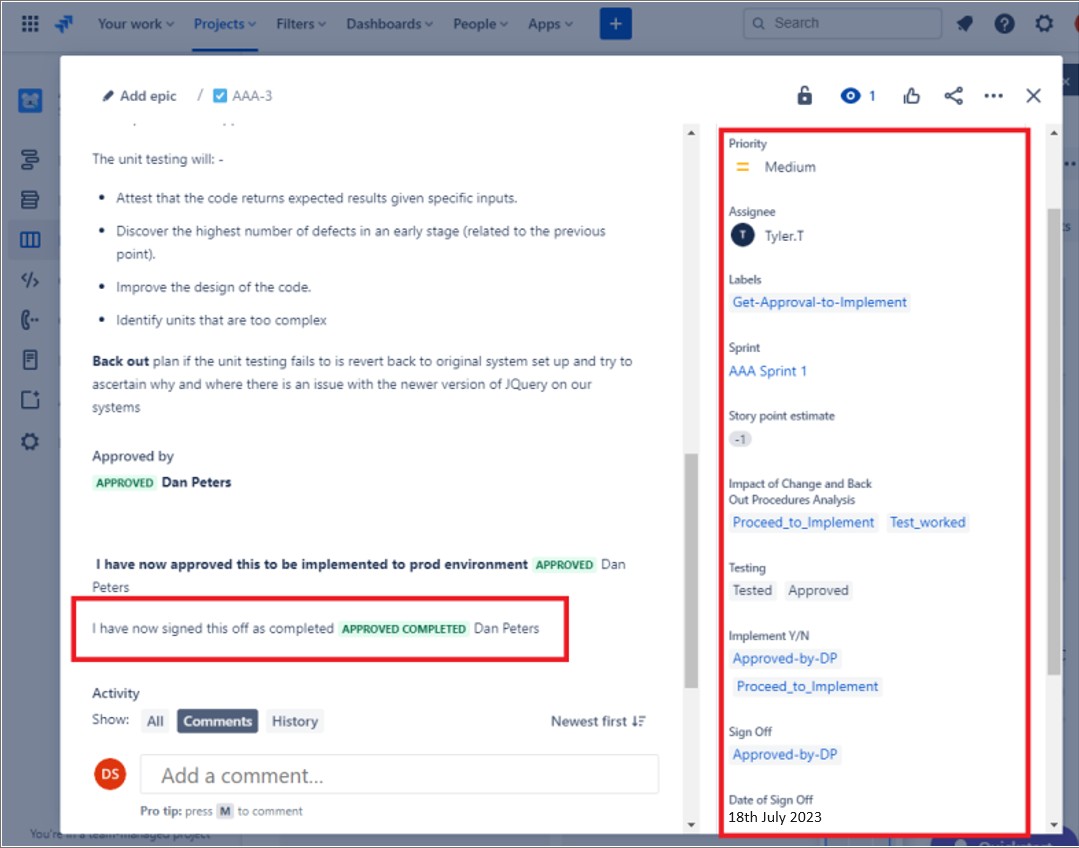
Dans le ticket suivant, la modification a été signée une fois terminée et affiche le travail terminé et fermé.
Remarque : Dans ces exemples, une capture d’écran complète n’a pas été utilisée, mais toutes les captures d’écran de preuve envoyées par un éditeur de logiciels indépendant doivent être des captures d’écran complètes montrant n’importe quelle URL, l’utilisateur connecté et l’heure et la date du système.
Contrôle n° 11
Fournissez la preuve que :
Des environnements distincts existent afin que :
Les environnements de développement et de test/intermédiaire appliquent la séparation des tâches de l’environnement de production.
La séparation des tâches est appliquée via des contrôles d’accès.
Les données de production sensibles ne sont pas utilisées dans les environnements de développement ou de test/intermédiaire.
Intention : environnements distincts
Les environnements de développement/test de la plupart des organisations ne sont pas configurés avec la même vigueur que les environnements de production et sont donc moins sécurisés. En outre, les tests ne doivent pas être effectués dans l’environnement de production, car cela peut introduire des problèmes de sécurité ou peut nuire à la prestation des services pour les clients. En conservant des environnements distincts qui appliquent une séparation des tâches, les organisations peuvent s’assurer que les modifications sont appliquées aux environnements appropriés, réduisant ainsi le risque d’erreurs en implémentant les modifications apportées aux environnements de production lorsqu’elles étaient destinées à l’environnement de développement/test.
Les contrôles d’accès doivent être configurés de sorte que le personnel responsable du développement et des tests ne dispose pas d’un accès inutile à l’environnement de production, et vice versa. Cela réduit le risque de modifications non autorisées ou d’exposition des données.
L’utilisation de données de production dans des environnements de développement/test peut augmenter le risque de compromission et exposer l’organisation à des violations de données ou à un accès non autorisé. L’intention exige que toutes les données utilisées à des fins de développement ou de test soient nettoyées, rendues anonymes ou générées spécifiquement à cet effet.
Recommandations : environnements distincts
Vous pouvez fournir des captures d’écran montrant les différents environnements utilisés pour les environnements de développement/test et les environnements de production. En règle générale, vous avez des personnes/équipes différentes ayant accès à chaque environnement, ou, lorsque cela n’est pas possible, les environnements utilisent différents services d’autorisation pour garantir que les utilisateurs ne peuvent pas se connecter par erreur dans le mauvais environnement pour appliquer les modifications.
Exemple de preuve : environnements distincts
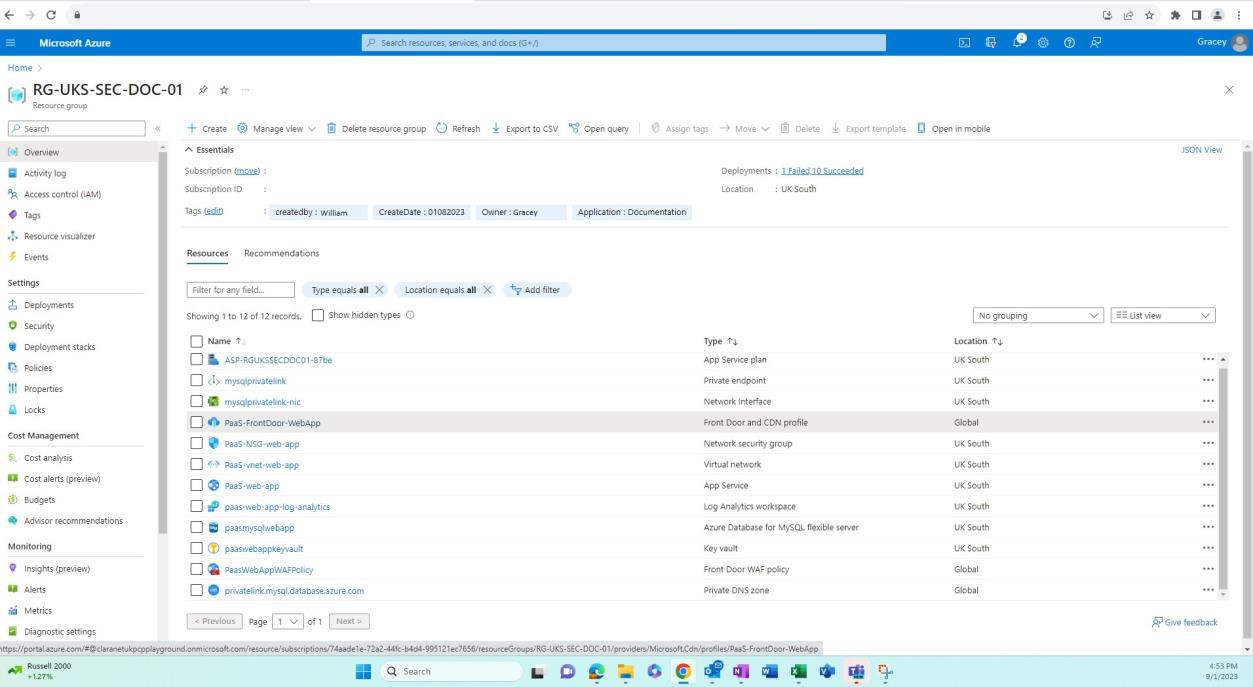
Les captures d’écran suivantes montrent que les environnements de développement/test sont séparés de la production. Cela s’effectue via des groupes de ressources dans Azure, ce qui permet de regrouper logiquement des ressources dans un conteneur. D’autres façons d’obtenir la séparation peuvent être différents abonnements Azure, mise en réseau et sous-réseau, etc.
La capture d’écran suivante montre l’environnement de développement et les ressources au sein de ce groupe de ressources.
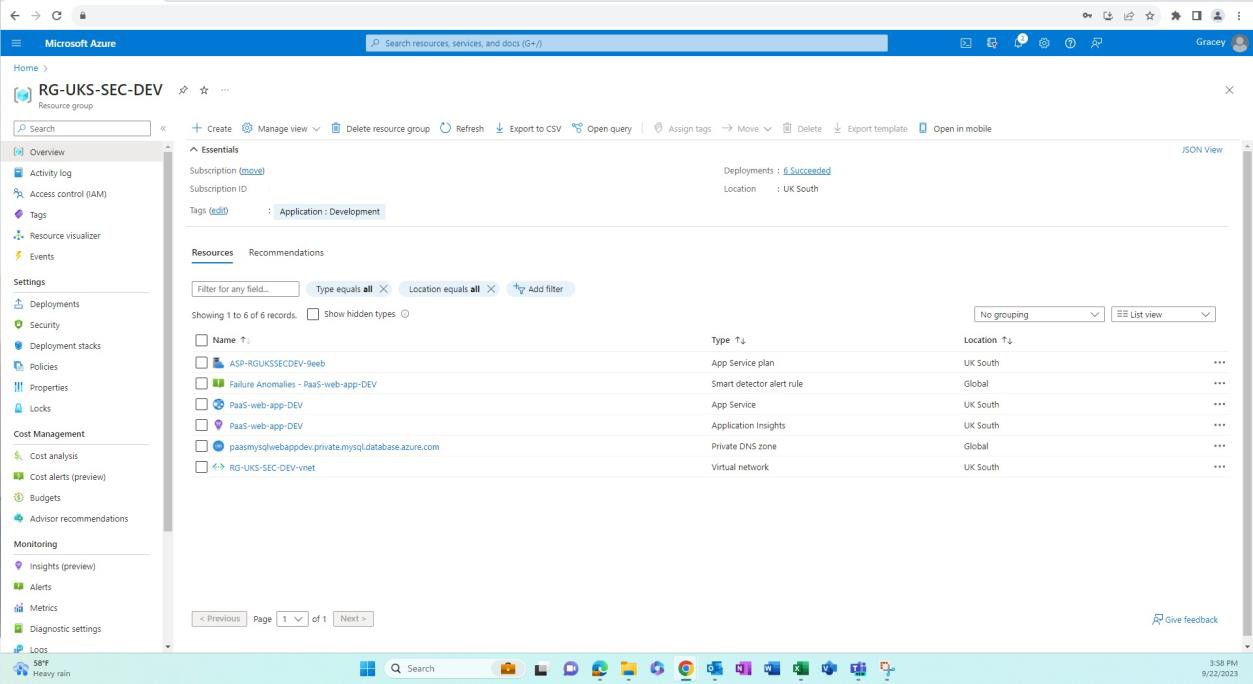
La capture d’écran suivante montre l’environnement de production et les ressources au sein de ce groupe de ressources.
Exemple de preuve :
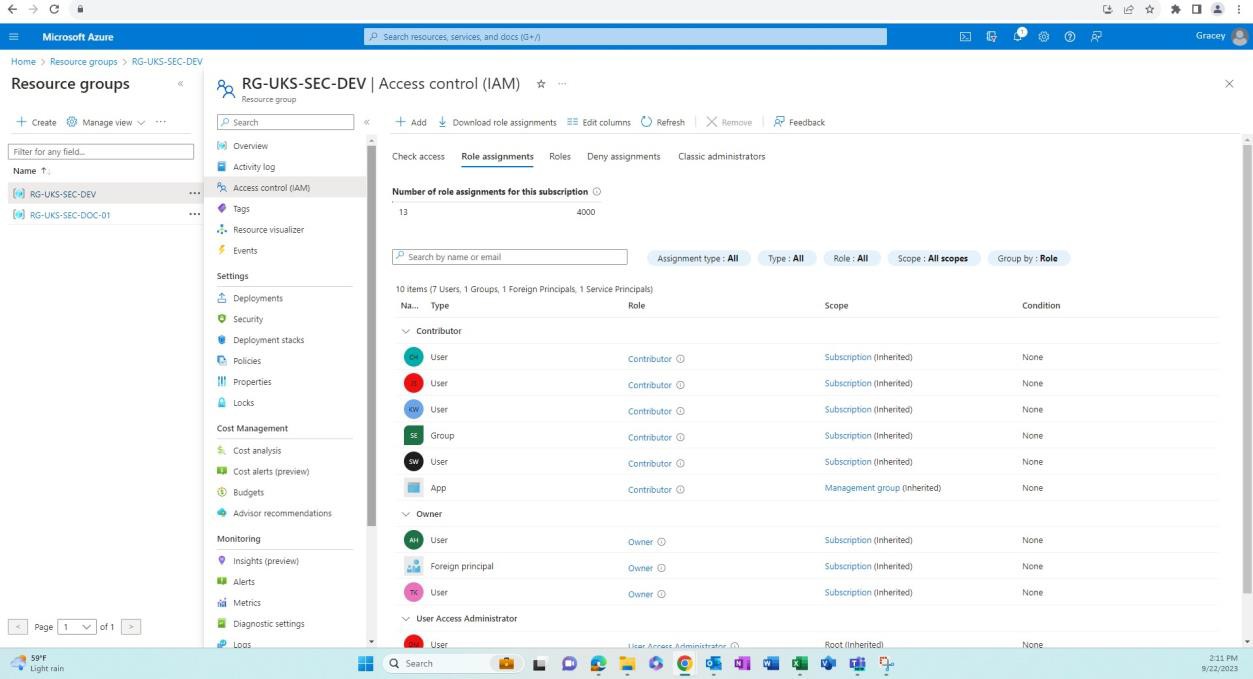
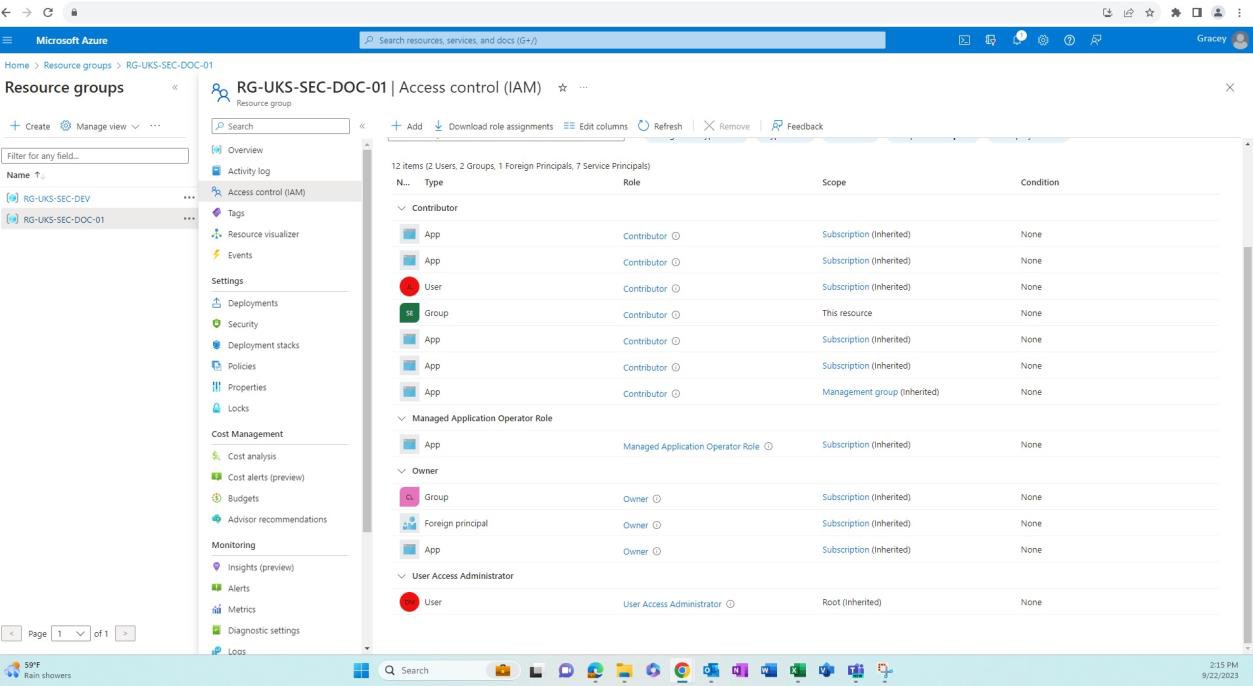
Les captures d’écran suivantes montrent que les environnements de développement/test sont distincts de l’environnement de production. Une séparation adéquate des environnements est obtenue via différents utilisateurs/groupes avec des autorisations différentes associées à chaque environnement.
La capture d’écran suivante montre l’environnement de développement et les utilisateurs ayant accès à ce groupe de ressources.
La capture d’écran suivante montre l’environnement de production et les utilisateurs (différents de l’environnement de développement) qui ont accès à ce groupe de ressources.
Recommandations :
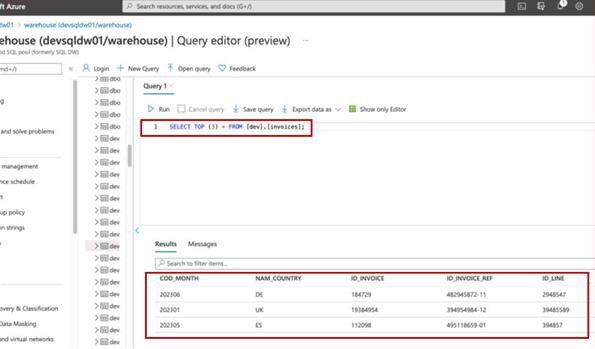
Vous pouvez fournir des preuves en partageant des captures d’écran de la sortie de la même requête SQL sur une base de données de production (rédaction de toutes les informations sensibles) et la base de données de développement/test. La sortie des mêmes commandes doit produire des jeux de données différents. Lorsque les fichiers sont stockés, l’affichage du contenu des dossiers dans les deux environnements doit également présenter différents jeux de données.
Exemple de preuve
La capture d’écran montre les 3 premiers enregistrements (pour la soumission des preuves, indiquez les 20 premiers) de la base de données de production.
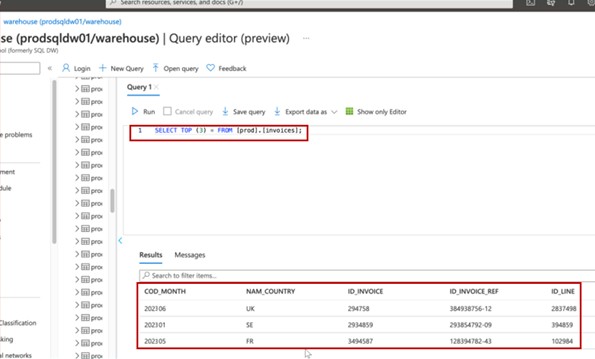
La capture d’écran suivante montre la même requête à partir de la base de données de développement, montrant différents enregistrements.
Remarque : Dans cet exemple, aucune capture d’écran complète n’a été utilisée. Toutefois, toutes les captures d’écran de preuve envoyées par l’éditeur de logiciels indépendant doivent être des captures d’écran complètes montrant l’URL, l’heure et la date de connexion de l’utilisateur et du système.
Développement/déploiement de logiciels sécurisés
Les organisations impliquées dans les activités de développement de logiciels sont souvent confrontées à des priorités concurrentes entre la sécurité et les pressions TTM (Time to Market), mais l’implémentation d’activités liées à la sécurité tout au long du cycle de vie du développement logiciel (SDLC) peut non seulement économiser de l’argent, mais également gagner du temps. Lorsque la sécurité est laissée après coup, les problèmes sont généralement identifiés uniquement pendant la phase de test du (DSLC), ce qui peut souvent prendre plus de temps et de coût à résoudre. L’objectif de cette section de sécurité est de s’assurer que les pratiques de développement de logiciels sécurisés sont suivies afin de réduire le risque d’introduction de défauts de codage dans le logiciel qui est développé. En outre, cette section cherche à inclure certains contrôles pour faciliter le déploiement sécurisé des logiciels.
Contrôle n° 12
Fournissez des preuves démontrant que la documentation existe et est conservée que :
prend en charge le développement de logiciels sécurisés et inclut les normes du secteur et/ou les meilleures pratiques pour le codage sécurisé, telles que OWASP Top 10 ou SANS Top 25 CWE.
les développeurs suivent chaque année une formation pertinente en matière de codage sécurisé et de développement de logiciels sécurisés.
Intention : développement sécurisé
Les organisations doivent faire tout ce qui est en leur pouvoir pour s’assurer que les logiciels sont développés en toute sécurité et exempts de vulnérabilités. Pour ce faire, il convient d’établir un cycle de vie de développement logiciel sécurisé (SDLC) et des meilleures pratiques de codage sécurisés pour promouvoir des techniques de codage sécurisées et un développement sécurisé tout au long du processus de développement logiciel. L’objectif est de réduire le nombre et la gravité des vulnérabilités dans le logiciel.
Les meilleures pratiques et techniques de codage existent pour tous les langages de programmation afin de garantir que le code est développé en toute sécurité. Il existe des cours de formation externes conçus pour enseigner aux développeurs les différents types de classes de vulnérabilités logicielles et les techniques de codage qui peuvent être utilisées pour arrêter l’introduction de ces vulnérabilités dans le logiciel. L’objectif de ce contrôle est également d’enseigner ces techniques à tous les développeurs et de s’assurer que ces techniques ne sont pas oubliées, ou que des techniques plus récentes sont apprises en effectuant cela chaque année.
Recommandations : développement sécurisé
Fournissez la documentation SDLC documentée et/ou de support qui montre qu’un cycle de vie de développement sécurisé est en cours d’utilisation et que des conseils sont fournis à tous les développeurs pour promouvoir les meilleures pratiques de codage sécurisé. Jetez un coup d’œil à OWASP dans SDLC et au modèle SAMM ( Software Assurance MaturityModel ) OWASP.
Exemple de preuve : développement sécurisé
Un exemple de document de stratégie de développement logiciel sécurisé est présenté ci-dessous. Voici un extrait de la procédure de développement logiciel sécurisé de Contoso, qui illustre les pratiques de développement et de codage sécurisés.
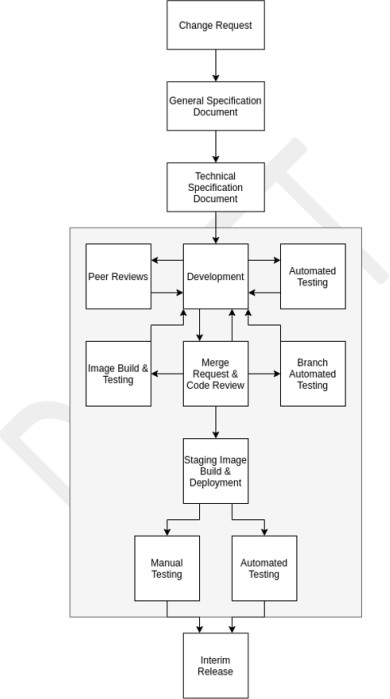

Remarque : Dans les exemples précédents, les captures d’écran complètes n’ont pas été utilisées, mais toutes les captures d’écran des preuves envoyées par un éditeur de logiciels indépendant doivent être des captures d’écran complètes montrant n’importe quelle URL, l’utilisateur connecté, ainsi que l’heure et la date du système.
Recommandations : formation au développement sécurisé
Fournissez des preuves au moyen de certificats si la formation est effectuée par une société de formation externe, ou en fournissant des captures d’écran des journaux de formation ou d’autres artefacts qui montrent que les développeurs ont participé à la formation. Si cette formation est effectuée par le biais de ressources internes, fournissez également des preuves du matériel de formation.
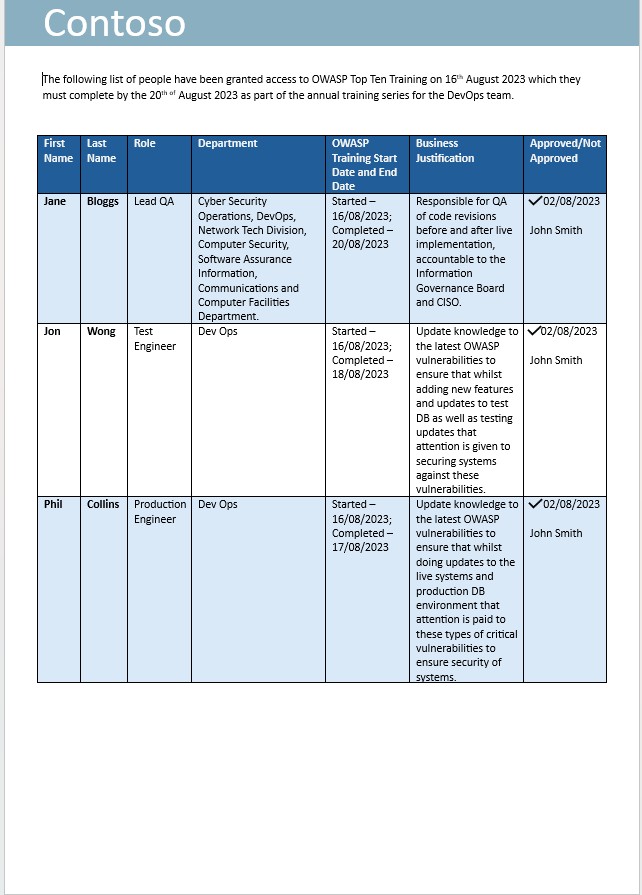
Exemple de preuve : formation au développement sécurisé
La capture d’écran suivante est un e-mail demandant au personnel de l’équipe DevOps d’être inscrit à la formation annuelle des dix meilleures formations OWASP.

La capture d’écran suivante montre que la formation a été demandée avec justification métier et approbation. Cette opération est suivie de captures d’écran tirées de la formation et d’un enregistrement d’achèvement montrant que la personne a terminé la formation annuelle.
Remarque : Dans cet exemple, aucune capture d’écran complète n’a été utilisée. Toutefois, toutes les captures d’écran de preuve envoyées par l’éditeur de logiciels indépendant doivent être des captures d’écran complètes montrant l’URL, l’heure et la date de connexion de l’utilisateur et du système.
Contrôle n° 13
Indiquez que les dépôts de code sont sécurisés afin que :
toutes les modifications de code font l’objet d’un processus de révision et d’approbation par un deuxième réviseur avant d’être fusionnées avec la branche principale.
des contrôles d’accès appropriés sont en place.
tous les accès sont appliqués via l’authentification multifacteur (MFA).
toutes les mises en production effectuées dans les environnements de production sont examinées et approuvées avant leur déploiement.
Intention : révision du code
L’objectif de ce sous-point est d’effectuer une révision du code par un autre développeur afin d’identifier les erreurs de codage susceptibles d’introduire une vulnérabilité dans le logiciel. L’autorisation doit être établie pour s’assurer que les révisions de code sont effectuées, que les tests sont effectués, etc. avant le déploiement. L’étape d’autorisation vérifie que les processus appropriés ont été suivis, ce qui sous-tend le SDLC défini dans le contrôle 12.
L’objectif est de s’assurer que toutes les modifications du code font l’objet d’un processus rigoureux d’examen et d’approbation par un deuxième réviseur avant qu’elles ne soient fusionnées dans la branche principale. Ce processus de double approbation sert de mesure de contrôle qualité, visant à intercepter les erreurs de codage, les failles de sécurité ou d’autres problèmes susceptibles de compromettre l’intégrité de l’application.
Recommandations : révision du code
Fournissez la preuve que le code fait l’objet d’une révision par les pairs et doit être autorisé avant de pouvoir être appliqué à l’environnement de production. Cette preuve peut se faire via une exportation de tickets de modification, montrant que des révisions de code ont été effectuées et les modifications autorisées, ou cela peut être par le biais d’un logiciel de révision de code tel que Crucible
Exemple de preuve : révision du code
Voici un ticket qui montre que les modifications du code font l’objet d’un processus de révision et d’autorisation par une personne autre que le développeur d’origine. Il montre qu’une révision du code a été demandée par le destinataire et sera affectée à une autre personne pour la révision du code.
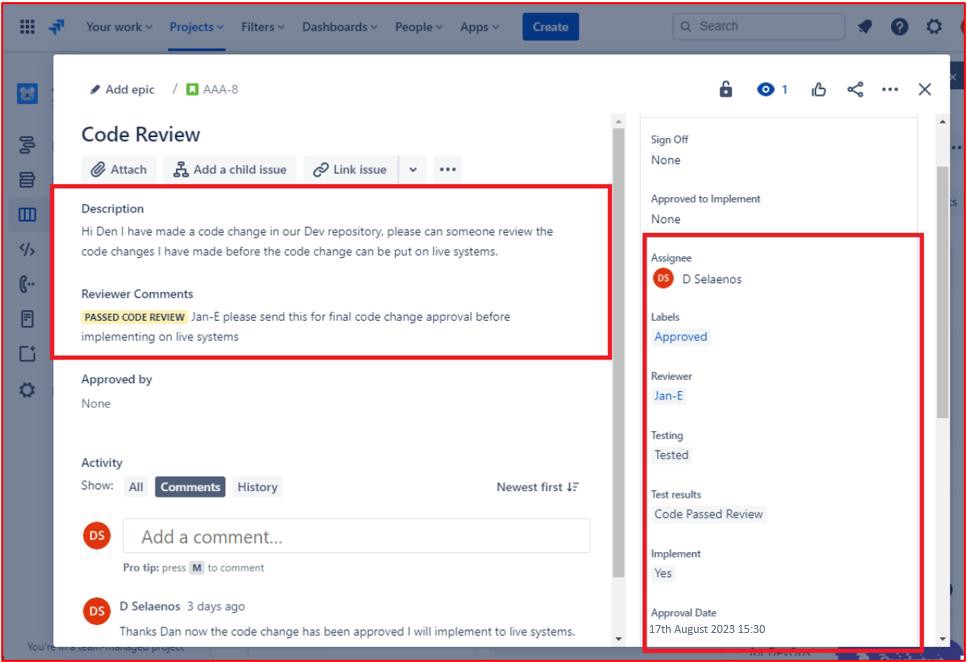
L’image suivante montre que la révision de code a été attribuée à une personne autre que le développeur d’origine, comme indiqué dans la section mise en surbrillance sur le côté droit de l’image. Sur le côté gauche, le code a été examiné et a reçu l’état « RÉVISION DU CODE RÉUSSIE » par le réviseur de code. Le ticket doit maintenant obtenir l’approbation d’un responsable avant que les modifications puissent être apportées aux systèmes de production en direct.
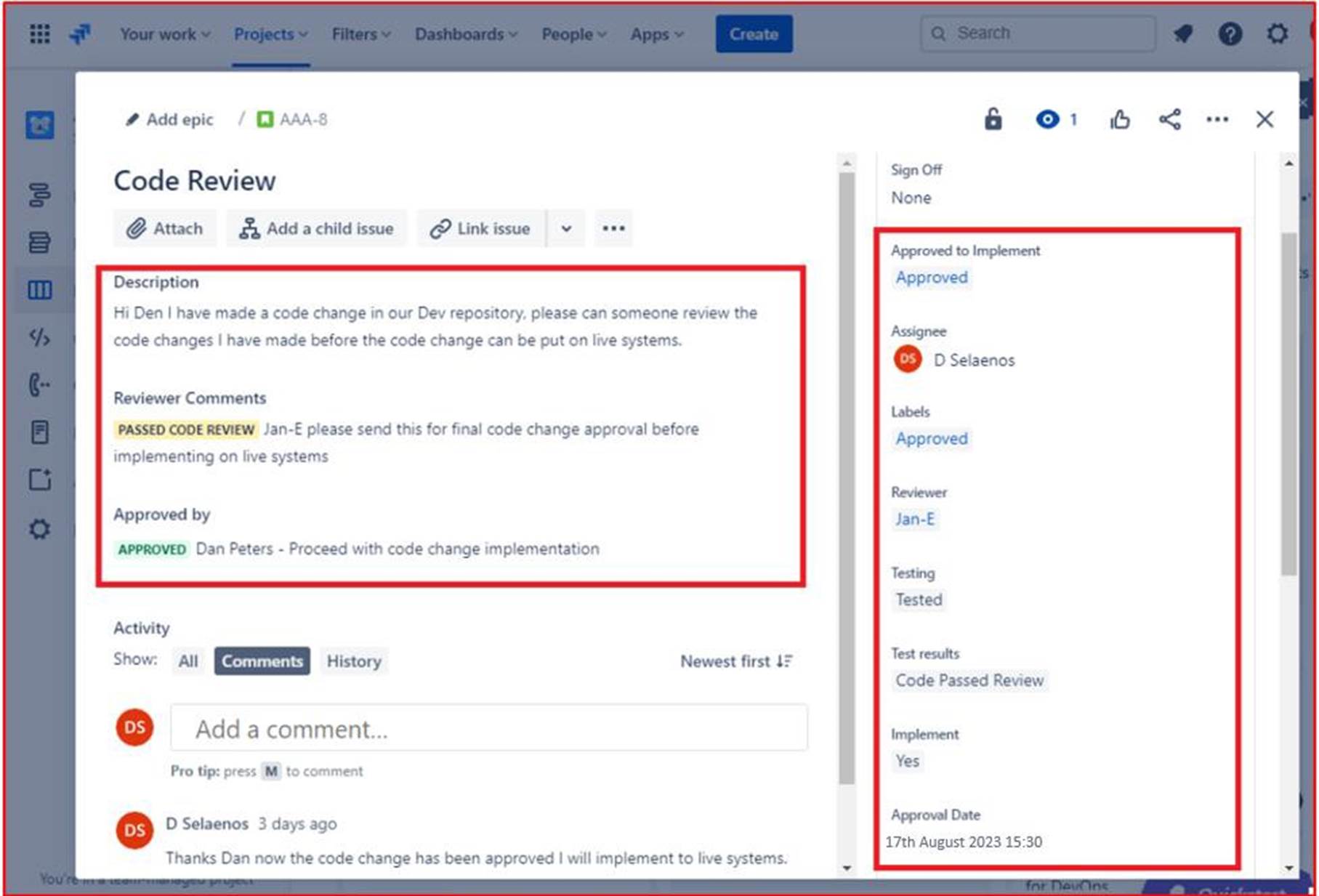
L’image suivante montre que le code révisé a reçu une approbation pour être implémenté sur les systèmes de production en direct. Une fois que les modifications du code ont été effectuées, le travail final est signé. Notez que tout au long du processus, trois personnes sont impliquées : le développeur d’origine du code, le réviseur de code et un responsable pour donner l’approbation et l’approbation. Pour répondre aux critères de ce contrôle, on s’attend à ce que vos billets suivent ce processus.
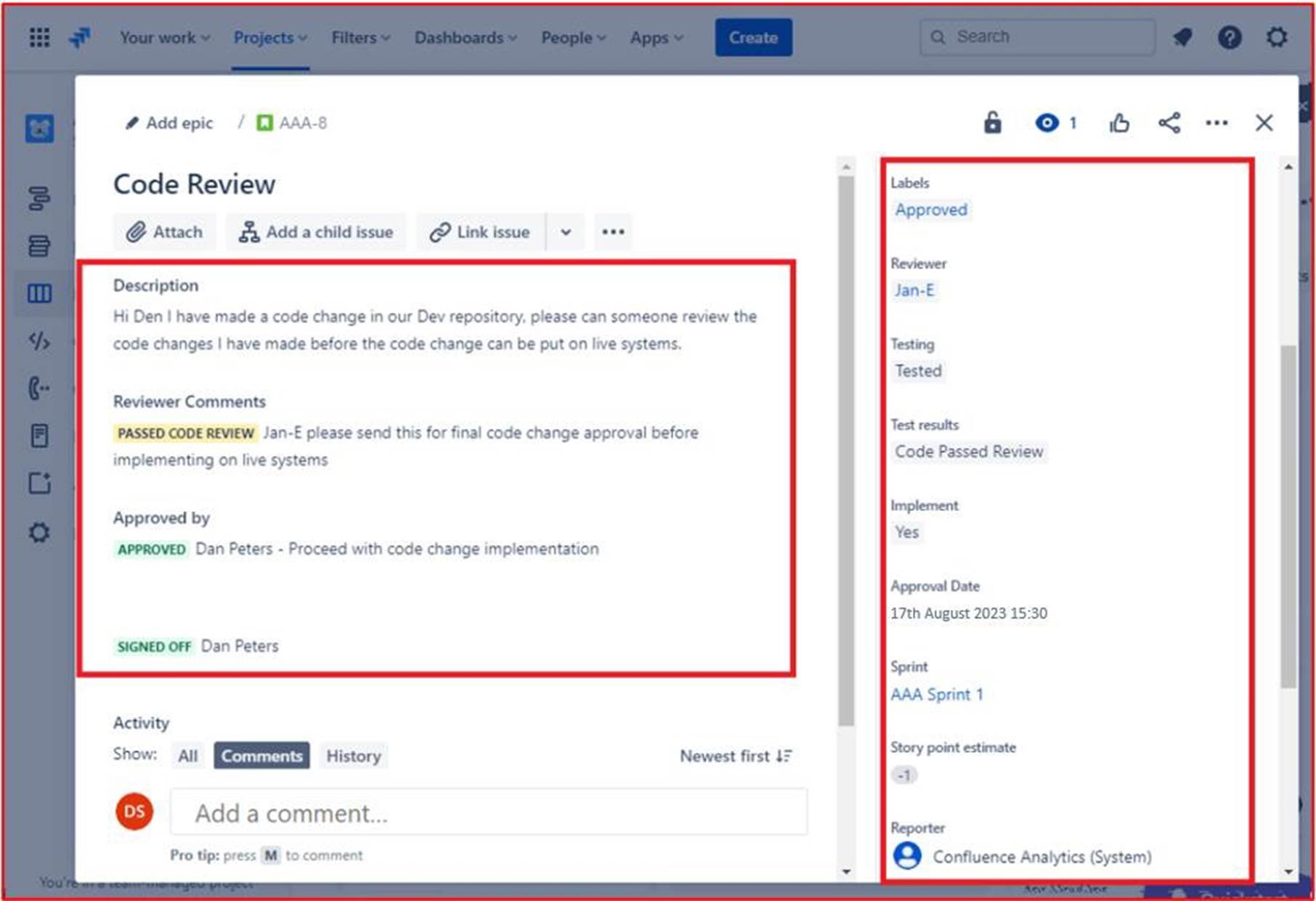
Remarque : Dans cet exemple, aucune capture d’écran complète n’a été utilisée. Toutefois, toutes les captures d’écran de preuve envoyées par l’éditeur de logiciels indépendant doivent être des captures d’écran complètes montrant l’URL, l’heure et la date de connexion de l’utilisateur et du système.
Exemple de preuve : révision du code
Outre la partie administrative du processus indiqué ci-dessus, avec les plateformes et référentiels de code modernes, des contrôles supplémentaires tels que la stratégie de branche appliquant la révision peuvent être implémentés pour garantir que les fusions ne peuvent pas se produire tant qu’une telle révision n’est pas terminée. L’exemple suivant illustre cette opération dans DevOps.
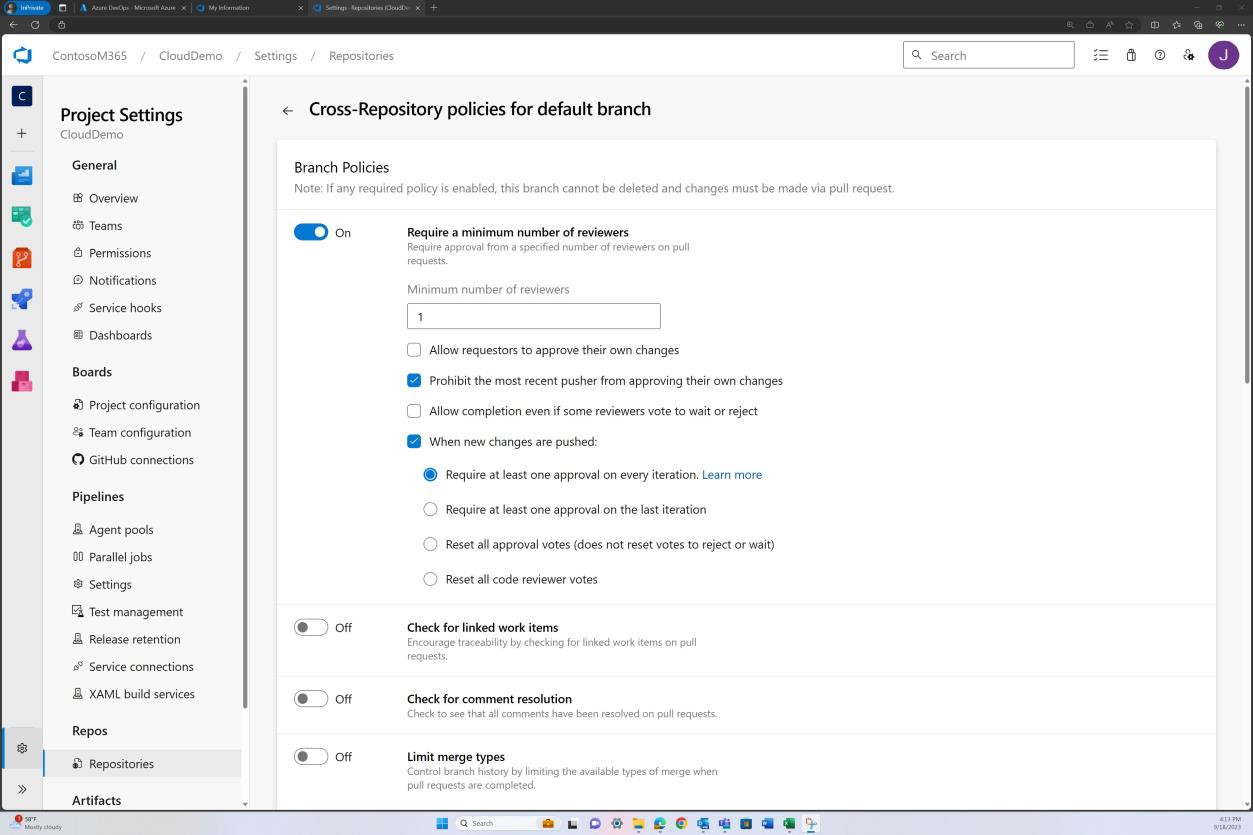
La capture d’écran suivante montre que les réviseurs par défaut sont affectés et que la révision est automatiquement requise.
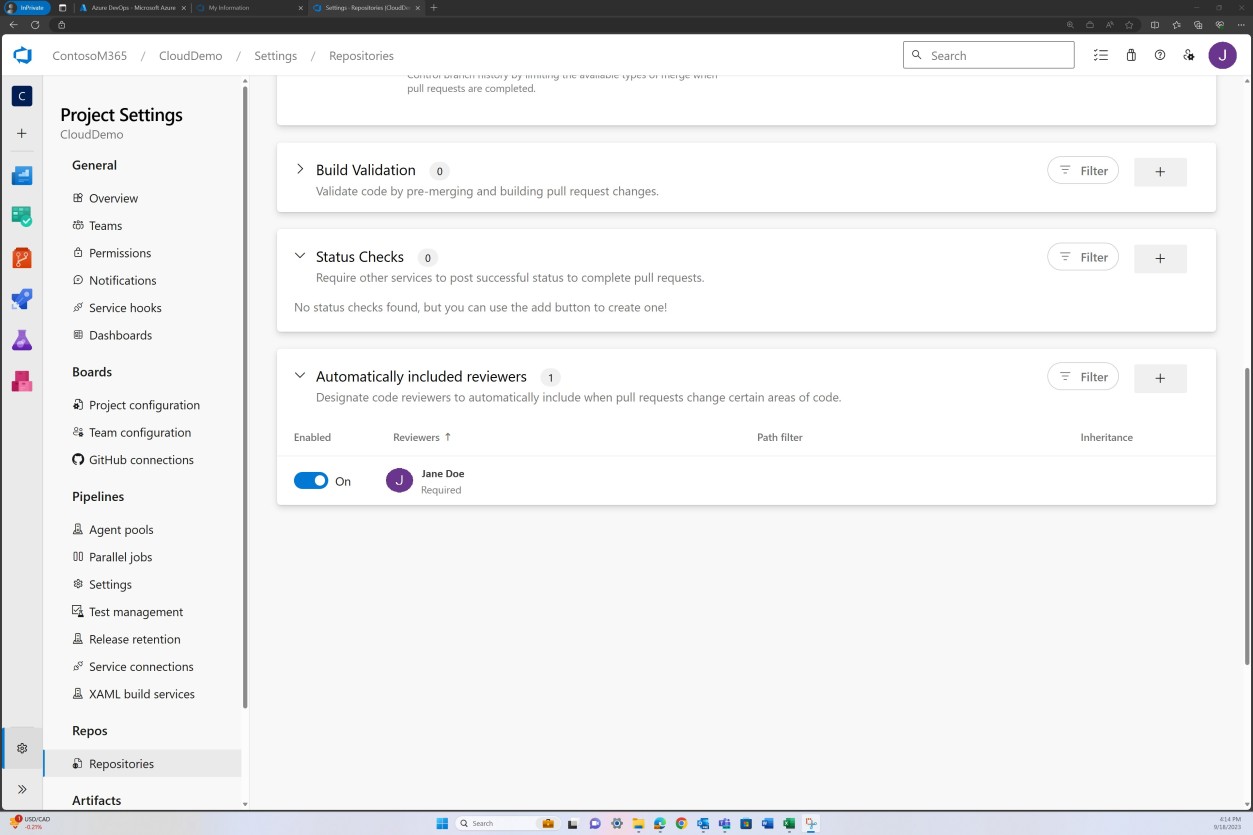
Exemple de preuve : révision du code
La révision de la stratégie de branche peut également être effectuée dans Bitbucket.
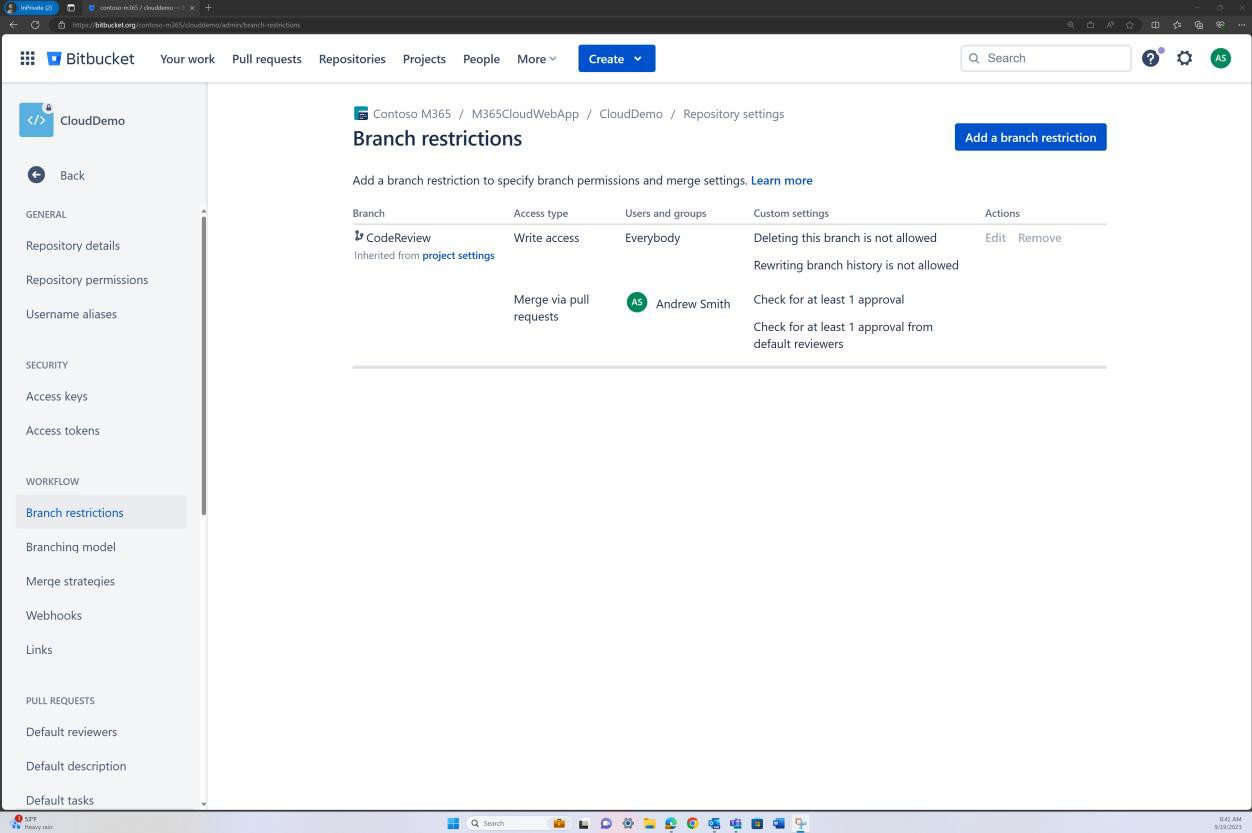
Dans la capture d’écran suivante, un réviseur par défaut est défini. Cela garantit que toutes les fusions nécessitent une révision de la part de l’individu affecté avant que la modification ne soit propagée à la branche principale.
Les deux captures d’écran suivantes illustrent un exemple des paramètres de configuration appliqués. En plus d’une demande de tirage terminée, qui a été lancée par l’utilisateur Silvester et qui a nécessité l’approbation du réviseur par défaut Andrew avant d’être fusionnée avec la branche principale.
Veuillez noter que lorsque la preuve est fournie, on s’attend à ce que le processus de bout en bout soit démontré. Remarque : des captures d’écran doivent être fournies montrant les paramètres de configuration si une stratégie de branche est en place (ou une autre méthode/contrôle programmatique), et des tickets/enregistrements d’approbation sont accordés.
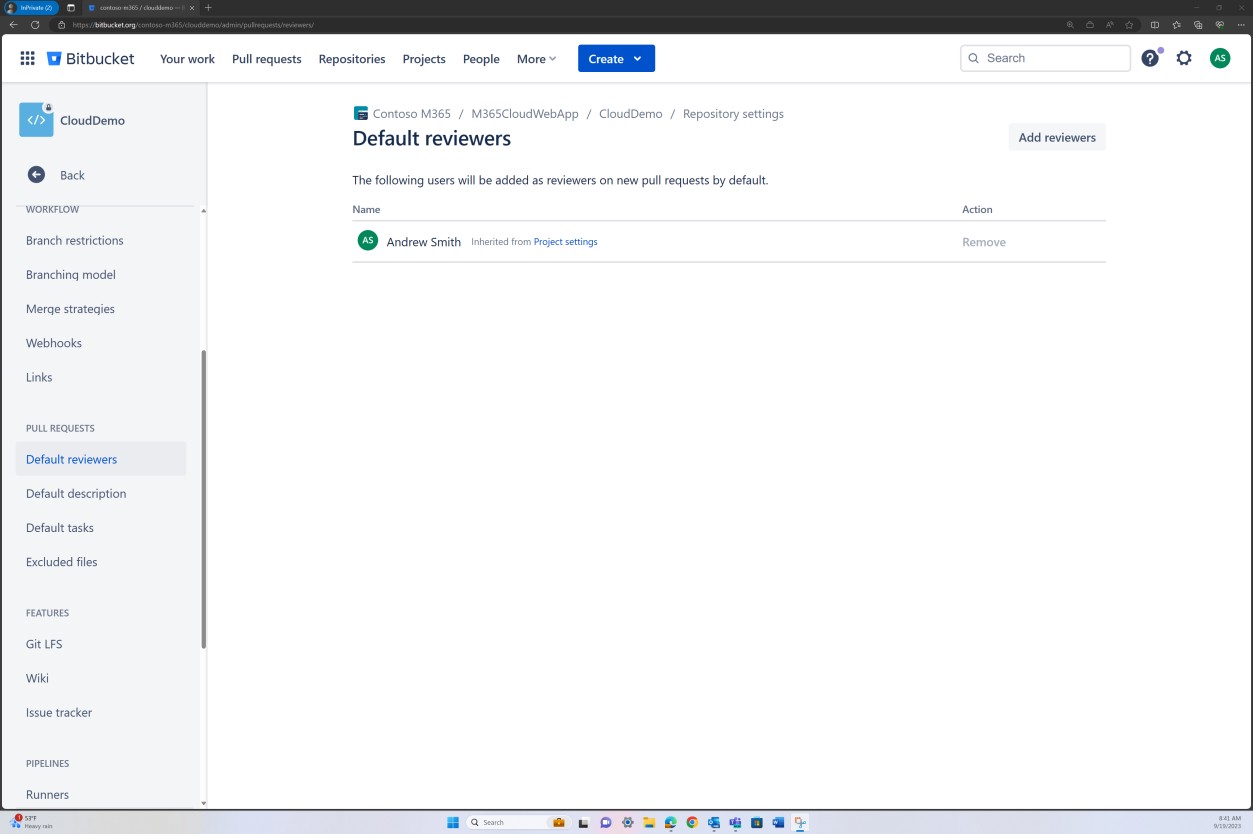
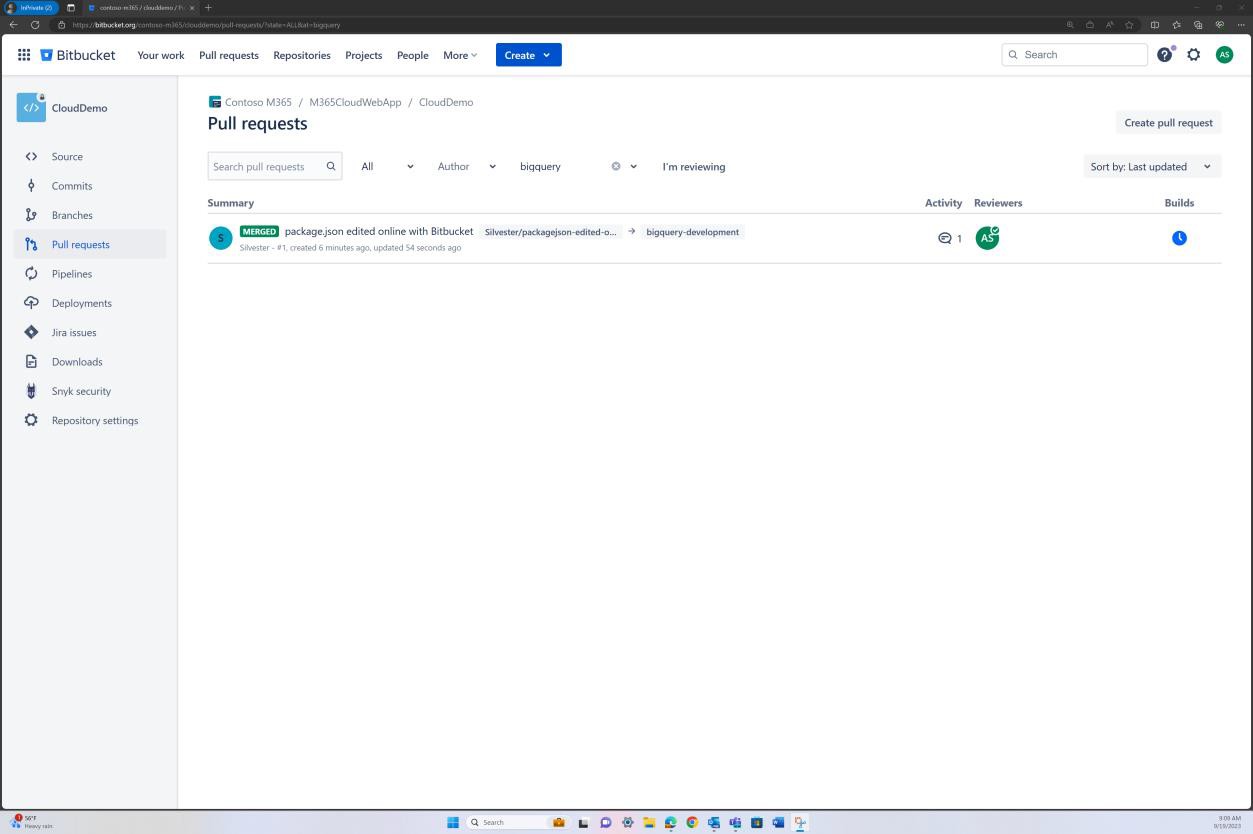
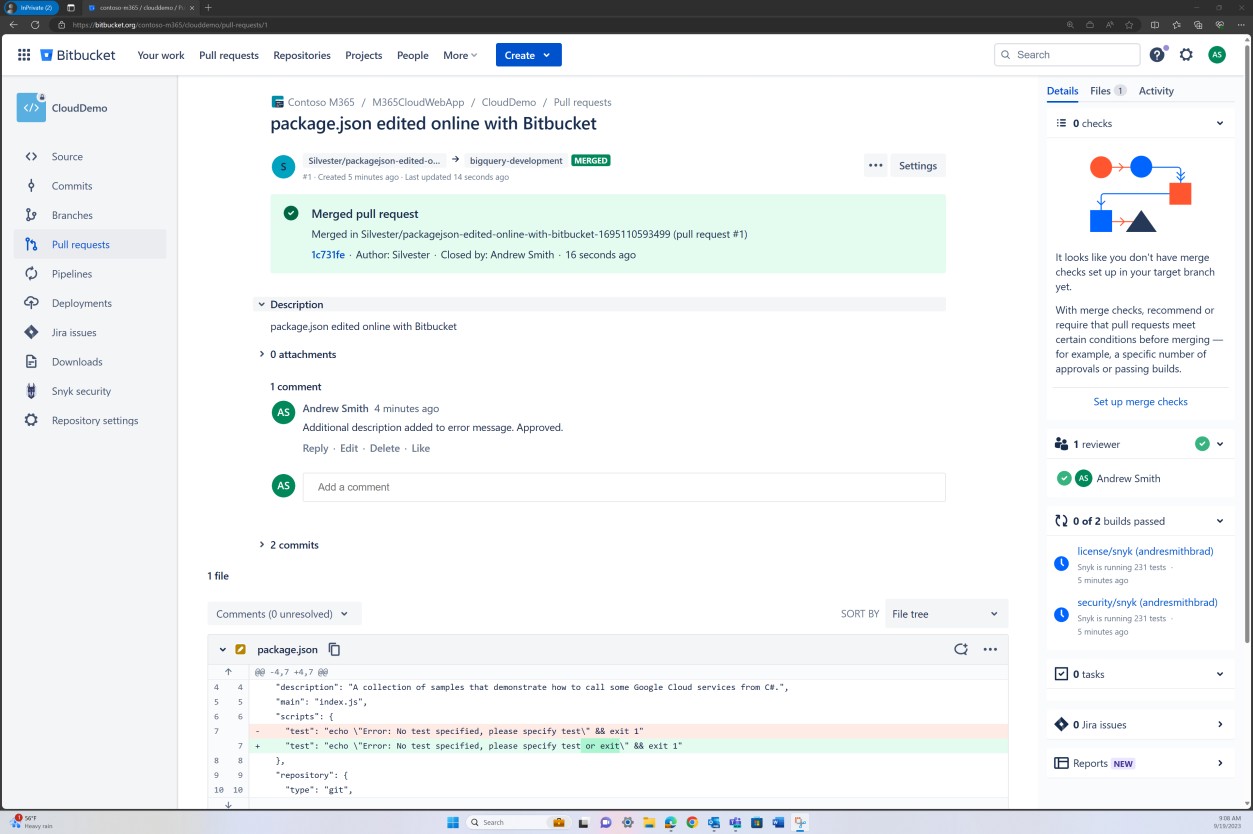
Intention : accès restreint
À partir du contrôle précédent, les contrôles d’accès doivent être implémentés pour limiter l’accès aux seuls utilisateurs individuels qui travaillent sur des projets spécifiques. En limitant l’accès, vous pouvez limiter le risque de modifications non autorisées et ainsi introduire des modifications de code non sécurisées. Une approche des privilèges minimum doit être adoptée pour protéger le dépôt de code.
Recommandations : accès restreint
Fournissez des preuves par le biais de captures d’écran du référentiel de code que l’accès est limité aux personnes nécessaires, y compris les différents privilèges.
Exemple de preuve : accès restreint
Les captures d’écran suivantes montrent les contrôles d’accès qui ont été implémentés dans Azure DevOps. L'« équipe CloudDemo » a deux membres, et chaque membre a des autorisations différentes.
Remarque : les captures d’écran suivantes montrent un exemple du type de preuve et du format attendus pour répondre à ce contrôle. Ce n’est en aucun cas très étendu et les cas réels peuvent différer sur la façon dont les contrôles d’accès sont implémentés.
Si les autorisations sont définies au niveau du groupe, la preuve de chaque groupe et des utilisateurs de ce groupe doit être fournie comme indiqué dans le deuxième exemple pour Bitbucket.
Capture d’écran suivante montrant les membres de « l’équipe CloudDemo ».
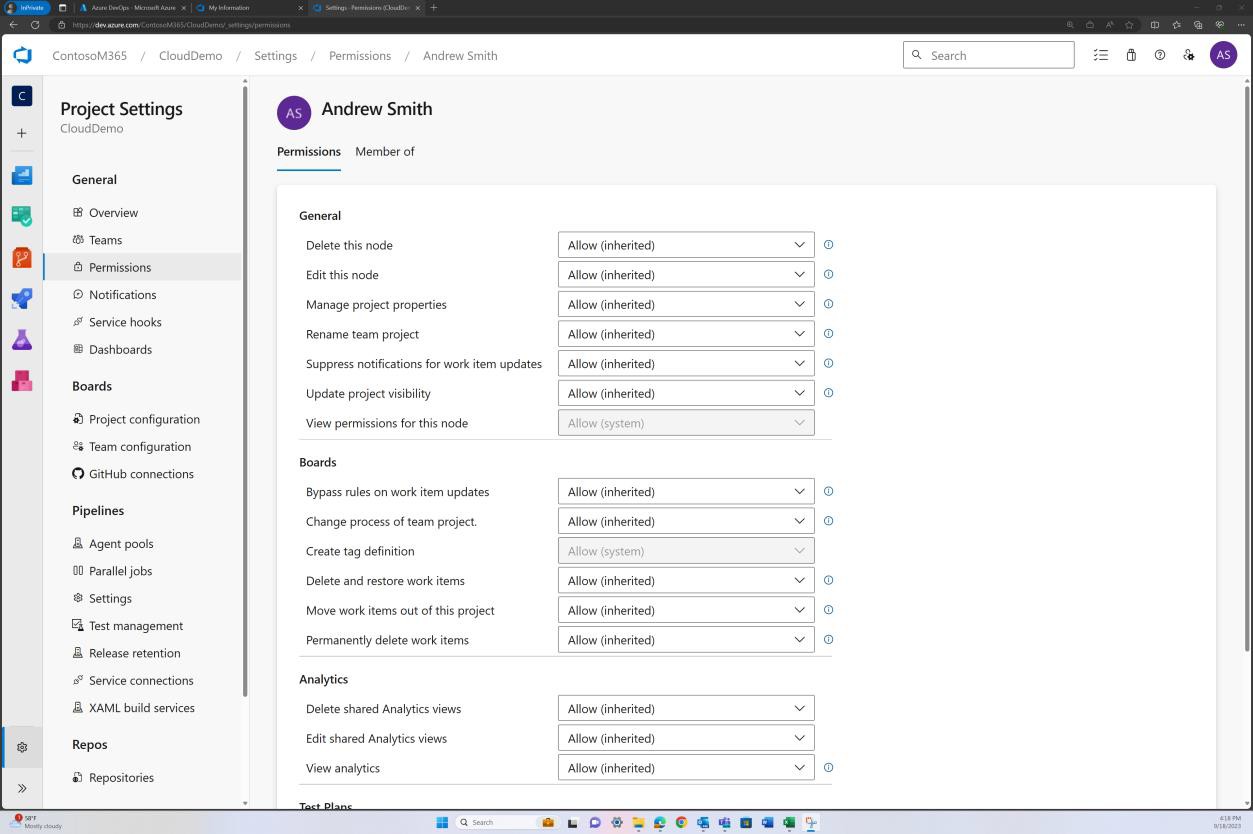
L’image précédente montre qu’Andrew Smith a des privilèges beaucoup plus élevés en tant que propriétaire du projet que Silvester ci-dessous.
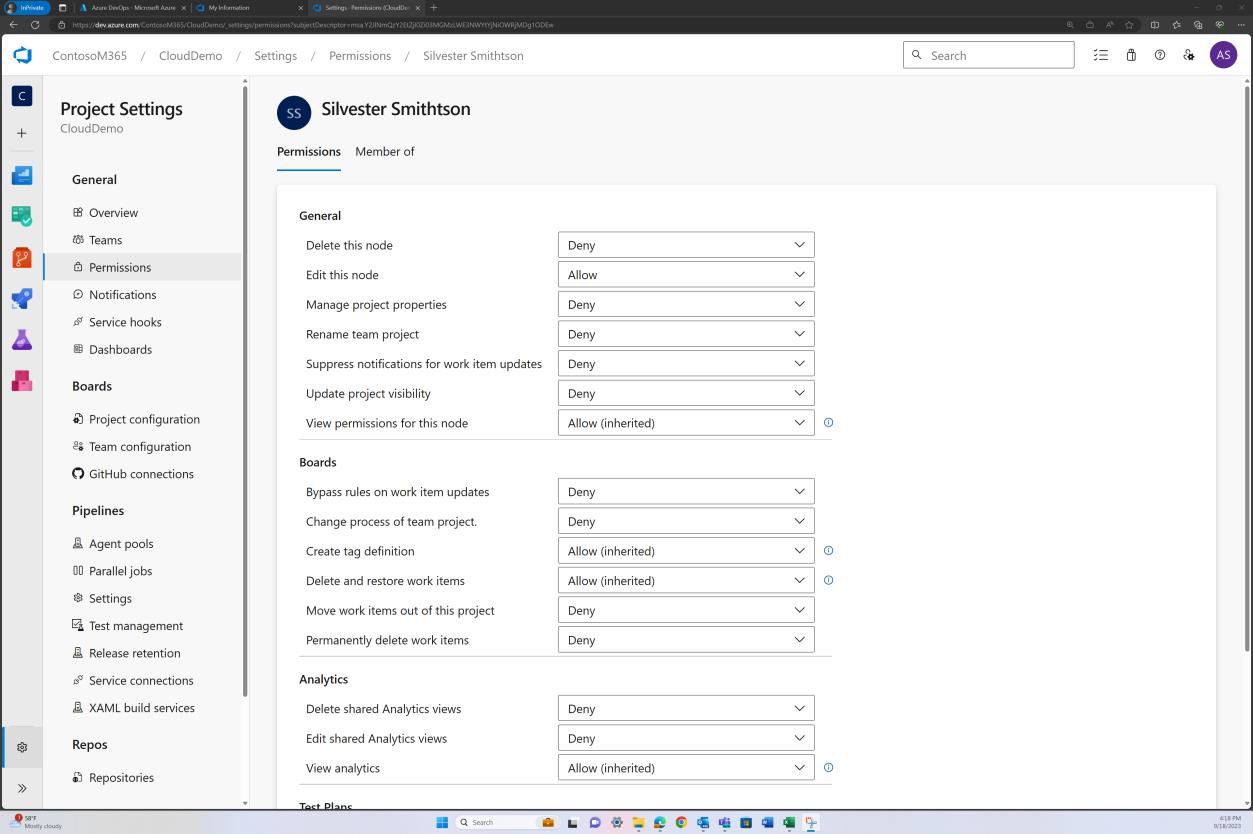
Exemple de preuve
Dans la capture d’écran suivante, les contrôles d’accès implémentés dans Bitbucket sont obtenus via des autorisations définies au niveau du groupe. Pour le niveau d’accès au référentiel, il existe un groupe « Administrateur » avec un utilisateur et un groupe « Développeur » avec un autre utilisateur.
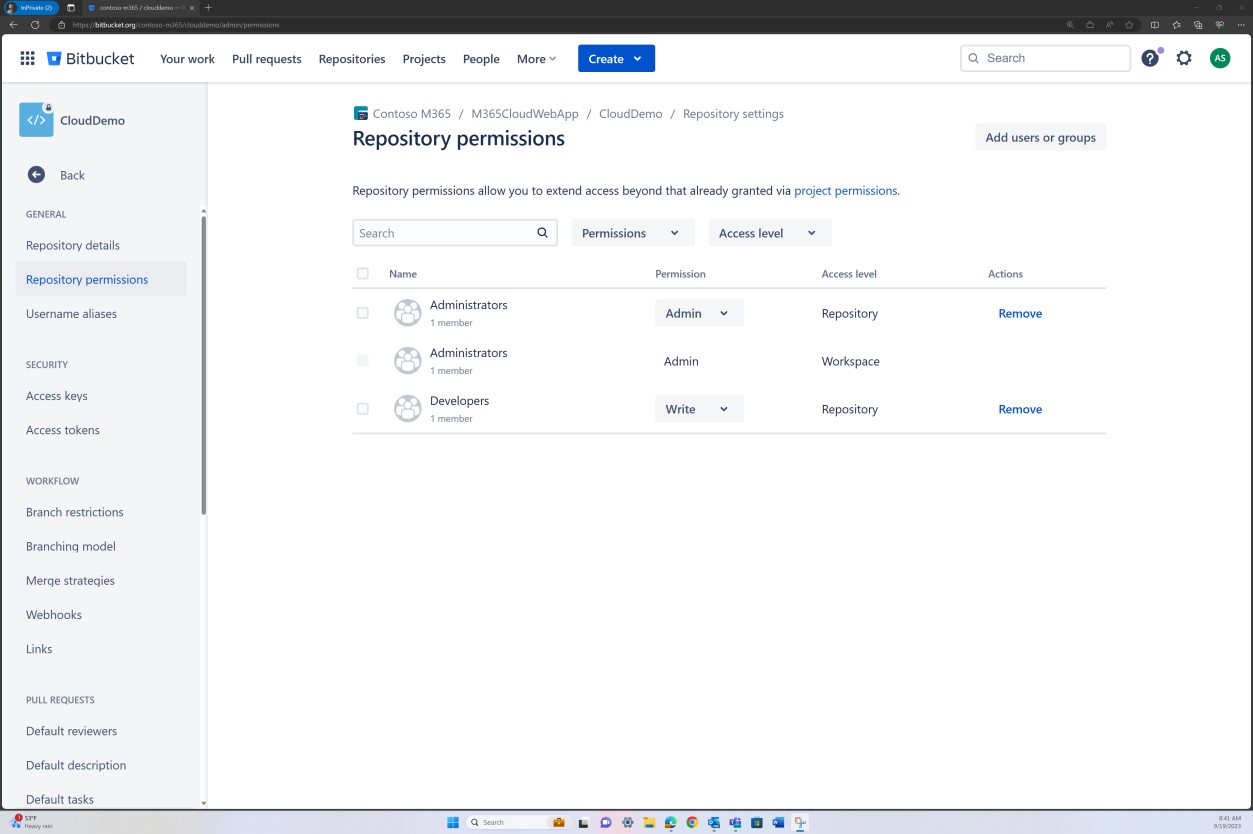
Les captures d’écran suivantes montrent que chacun des utilisateurs appartient à un groupe différent et a par nature un niveau d’autorisations différent. Andrew Smith est l’administrateur, et Silvester fait partie du groupe développeur, qui lui accorde uniquement des privilèges de développeur.
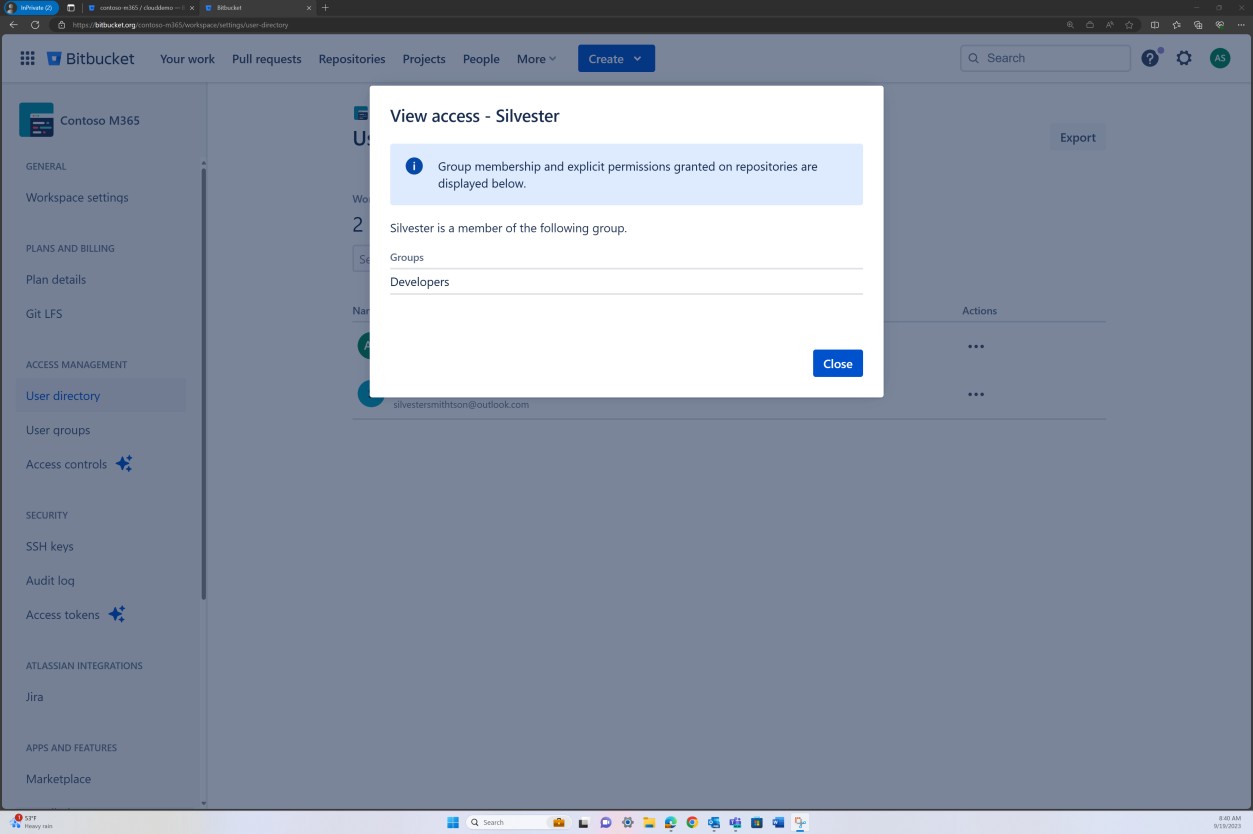
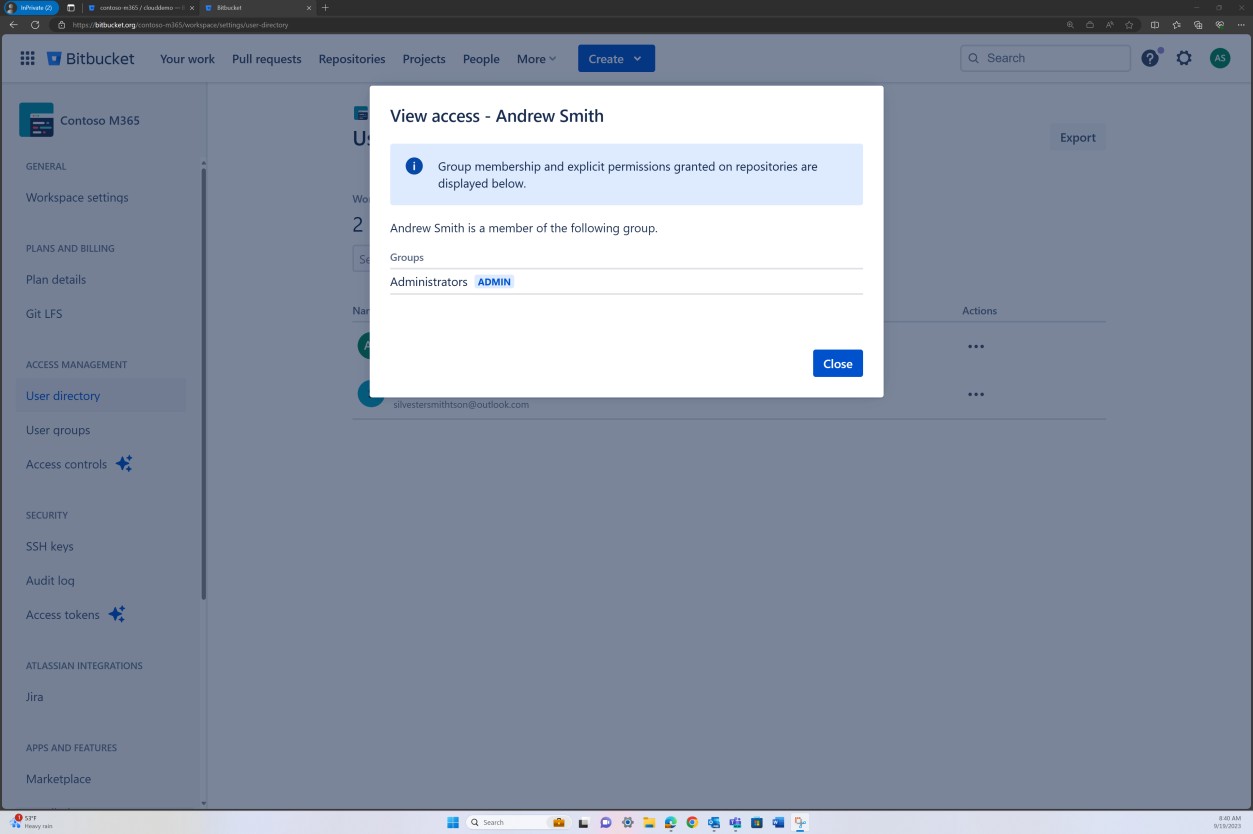
Intention : MFA
Si un acteur de menace peut accéder à la base de code d’un logiciel et le modifier, il peut introduire des vulnérabilités, des portes dérobées ou du code malveillant dans la base de code et donc dans l’application. Il y a déjà eu plusieurs cas de cela, le plus médiatisé étant probablement l’attaque SolarWinds de 2020, où les attaquants ont injecté du code malveillant dans un fichier qui a été plus tard inclus dans les mises à jour logicielles Orion de SolarWinds. Plus de 18 000 clients SolarWinds ont installé les mises à jour malveillantes, les programmes malveillants se propageant sans détection.
L’objectif de ce sous-point est de vérifier que tous les accès aux dépôts de code sont appliqués via l’authentification multifacteur (MFA).
Recommandations : MFA
Fournissez des preuves par le biais de captures d’écran du référentiel de code indiquant que l’authentification MFA est activée pour TOUS les utilisateurs.
Exemple de preuve : MFA
Si les dépôts de code sont stockés et gérés dans Azure DevOps, en fonction de la configuration de l’authentification multifacteur au niveau du locataire, des preuves peuvent être fournies à partir d’AAD, par exemple, « MFA par utilisateur ». La capture d’écran suivante montre que l’authentification multifacteur est appliquée à tous les utilisateurs dans AAD, et cela s’applique également à Azure DevOps.
Exemple de preuve : MFA
Si l’organisation utilise une plateforme telle que GitHub, vous pouvez démontrer que la 2FA est activée en partageant la preuve à partir du compte « Organisation », comme illustré dans les captures d’écran suivantes.
Pour voir si la 2FA est appliquée à tous les membres de votre organisation sur GitHub, vous pouvez accéder à l’onglet paramètres de l’organisation, comme dans la capture d’écran suivante.
En accédant à l’onglet « Contacts » dans GitHub, vous pouvez établir que « 2FA » est activé pour tous les utilisateurs de l’organisation, comme illustré dans la capture d’écran suivante.
Intention : avis
L’objectif de ce contrôle est d’effectuer une révision de la version dans un environnement de développement par un autre développeur pour aider à identifier les erreurs de codage, ainsi que les erreurs de configuration susceptibles d’introduire une vulnérabilité. L’autorisation doit être établie pour s’assurer que les révisions de mise en production sont effectuées, que les tests sont effectués, etc. avant le déploiement en production. Autorisation. l’étape peut vérifier que les processus appropriés ont été suivis, ce qui sous-tend les principes SDLC.
Conseils
Fournissez la preuve que toutes les versions de l’environnement de test/développement dans l’environnement de production sont examinées par une personne ou un développeur différent de celui de l’initiateur. Si cette opération est effectuée via un pipeline d’intégration continue/déploiement continu, la preuve fournie doit indiquer (comme pour les révisions de code ) que les révisions sont appliquées.
Exemple de preuve
Dans la capture d’écran suivante, nous pouvons voir qu’un pipeline CI/CD est en cours d’utilisation dans Azure DevOps, le pipeline contient deux étapes : Développement et Production. Une mise en production a été déclenchée et déployée avec succès dans l’environnement de développement, mais elle n’a pas encore été propagée dans la deuxième étape (production) et qui est en attente d’approbation par Andrew Smith.
L’objectif est qu’une fois déployé pour le développement, les tests de sécurité soient effectués par l’équipe concernée et que seulement lorsque la personne affectée disposant de l’autorité appropriée pour examiner le déploiement a effectué une révision secondaire et est satisfaite que toutes les conditions sont remplies, accordera ensuite l’approbation qui permettra à la mise en production de la mise en production.
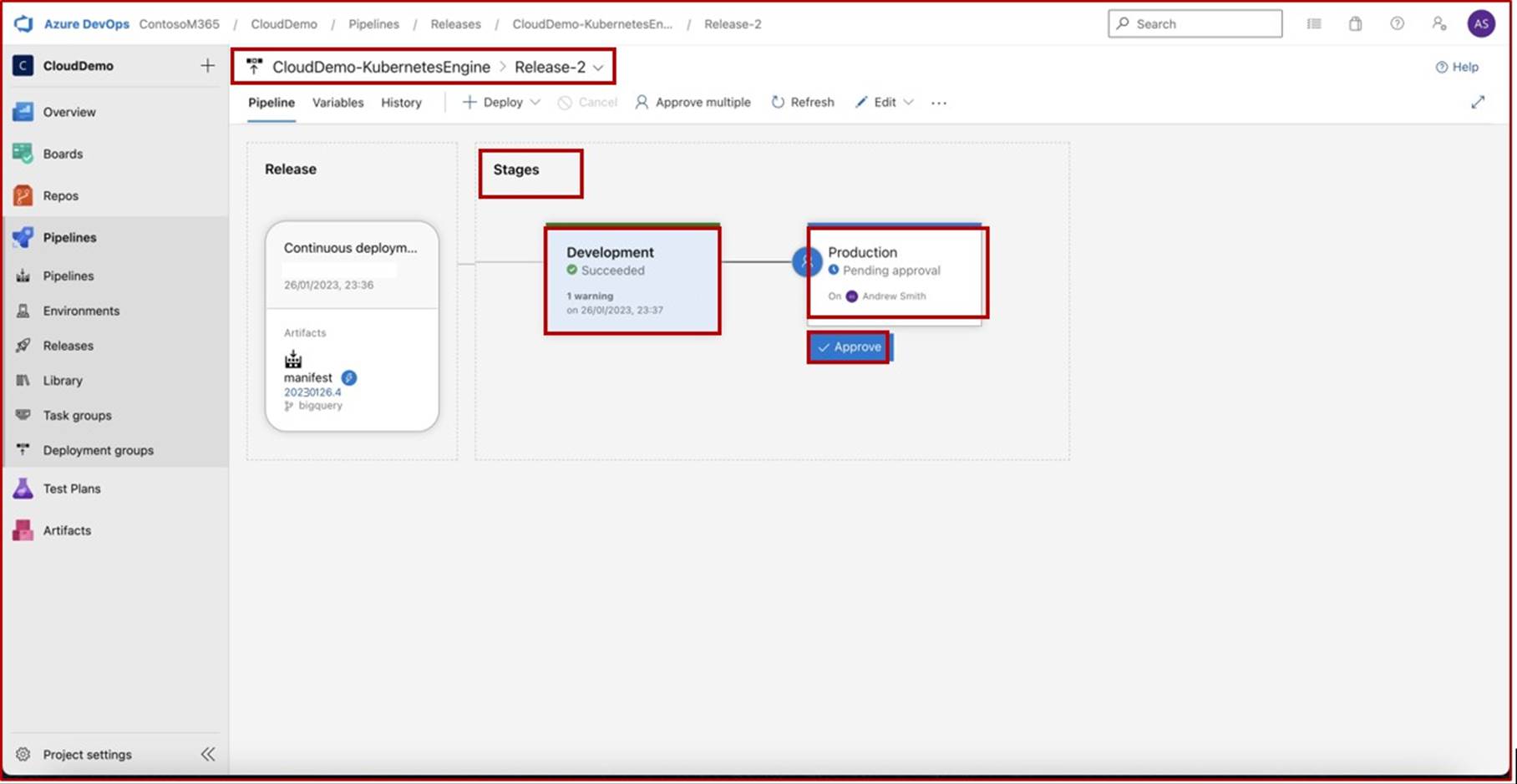
Alerte par e-mail qui serait normalement reçue par le réviseur affecté, l’informant qu’une condition de prédéploiement a été déclenchée et qu’une révision et une approbation sont en attente.
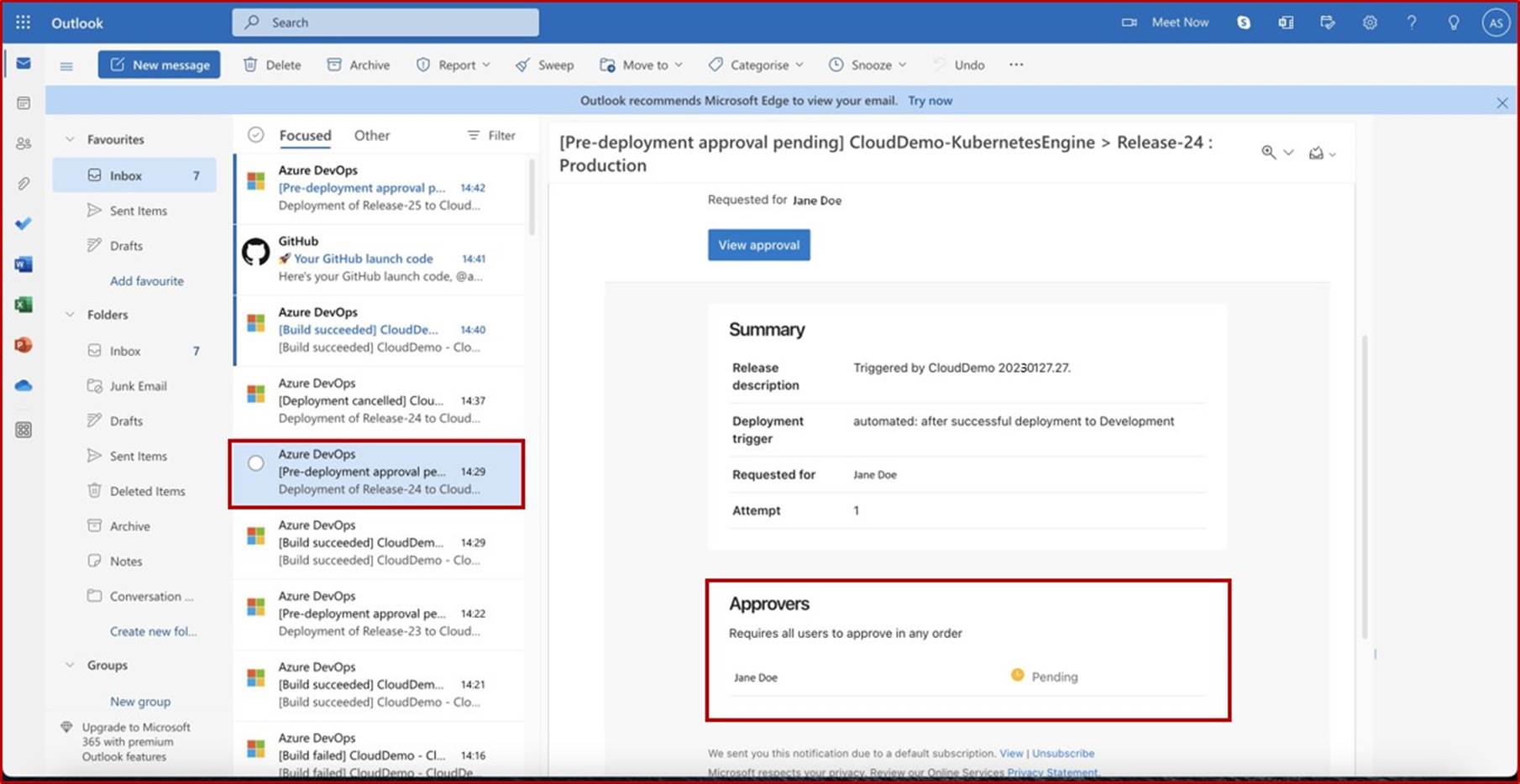
À l’aide de la notification par e-mail, le réviseur peut accéder au pipeline de mise en production dans DevOps et accorder l’approbation. Nous pouvons voir ci-dessous que des commentaires sont ajoutés pour justifier l’approbation.
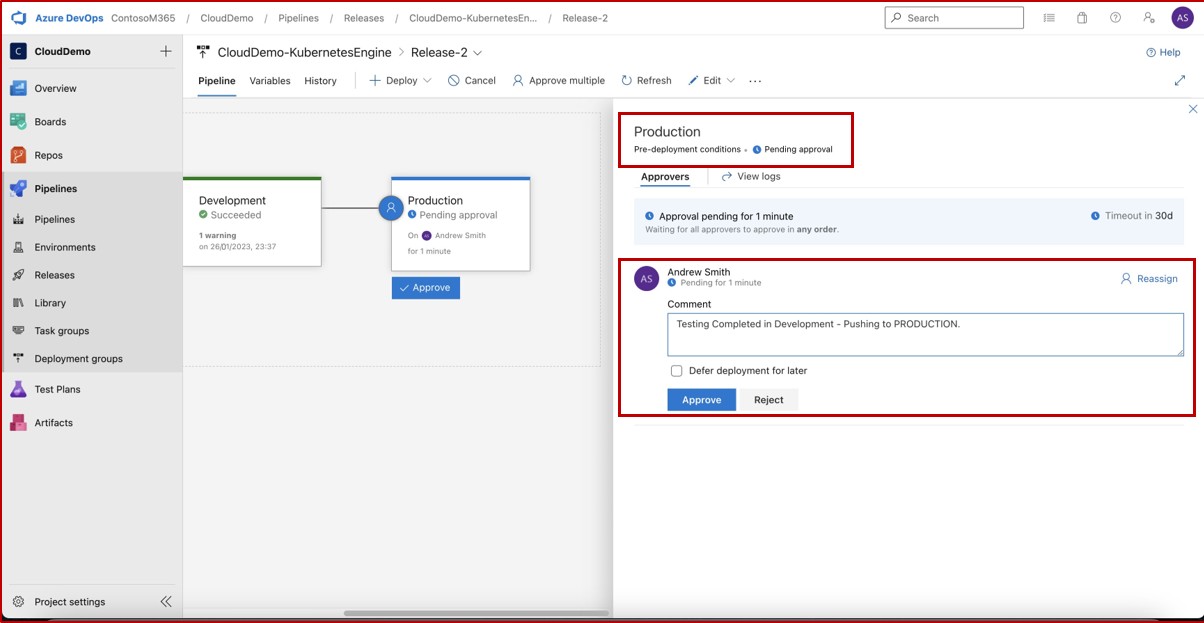
Dans la deuxième capture d’écran, il est montré que l’approbation a été accordée et que la mise en production a réussi.
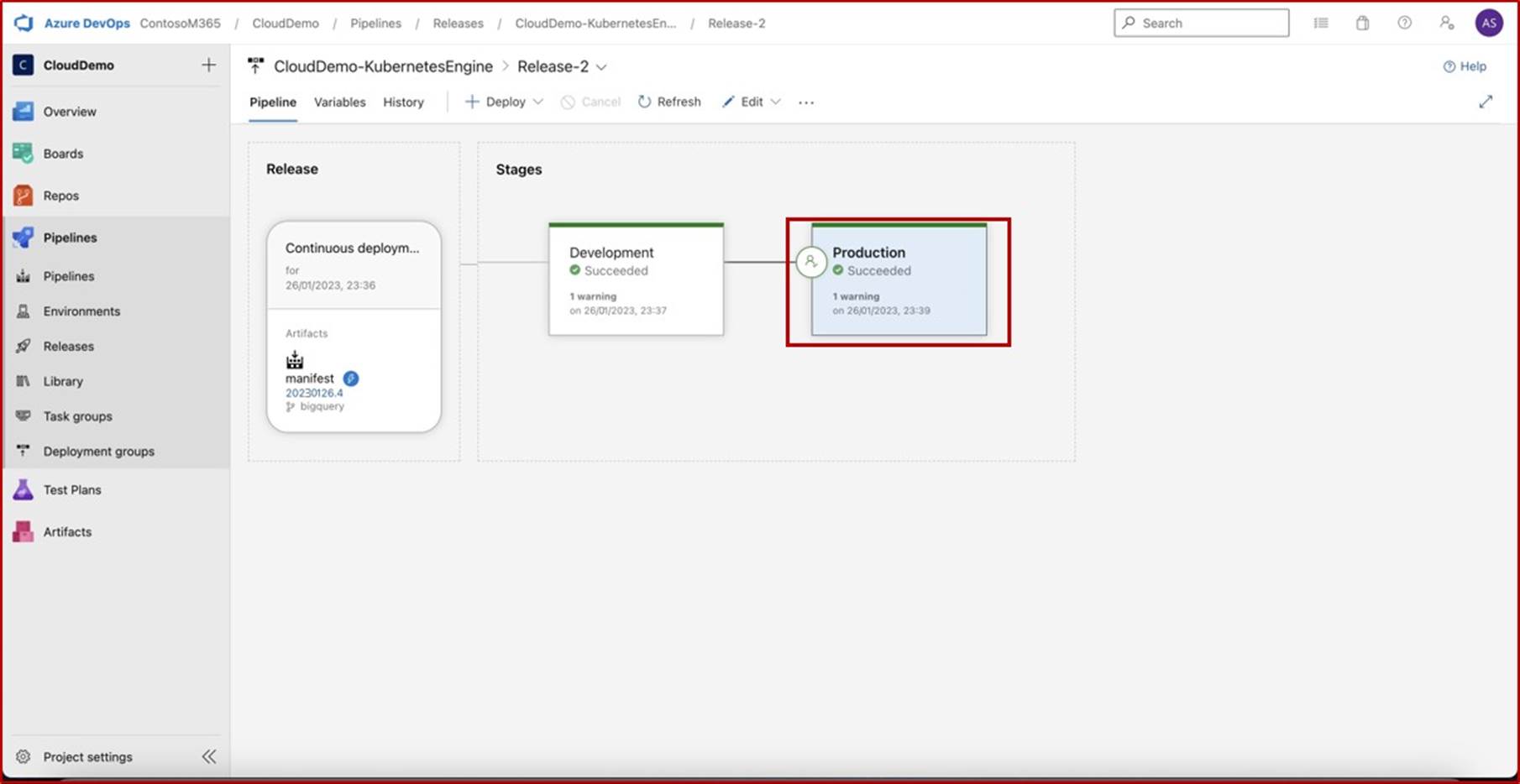
Les deux captures d’écran suivantes montrent un exemple des preuves attendues.
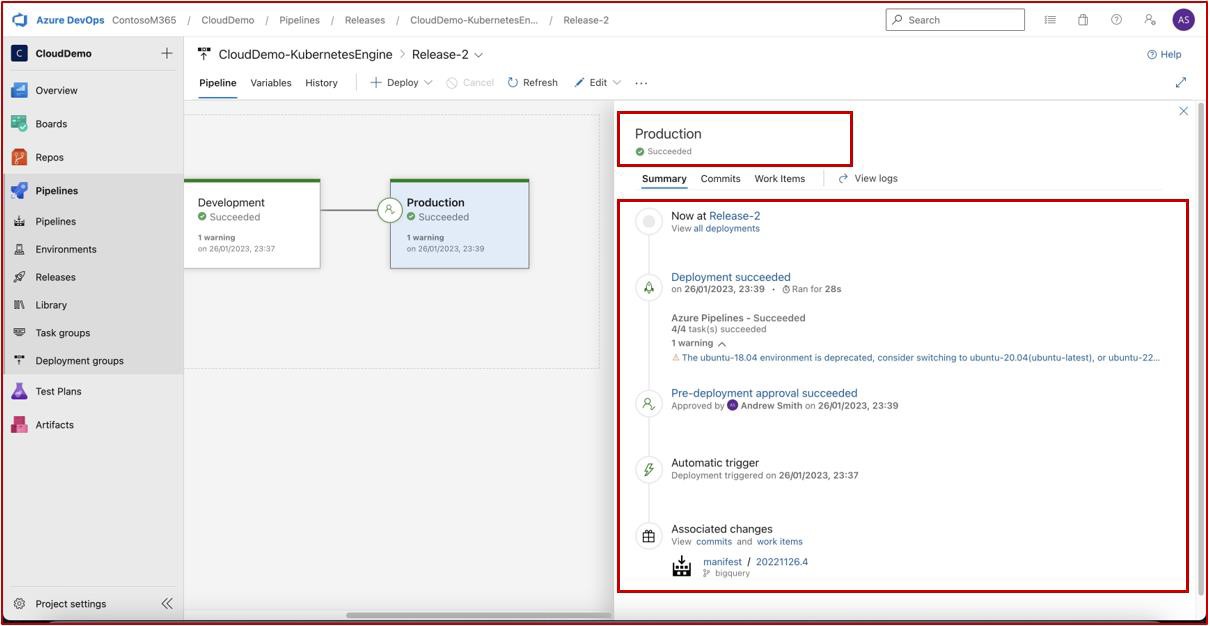
La preuve montre les versions historiques et que les conditions de prédéploiement sont appliquées, et une révision et une approbation sont nécessaires avant que le déploiement puisse être effectué dans l’environnement de production.
Capture d’écran suivante montrant l’historique des versions, y compris la version récente qui a été déployée avec succès sur le développement et la production.
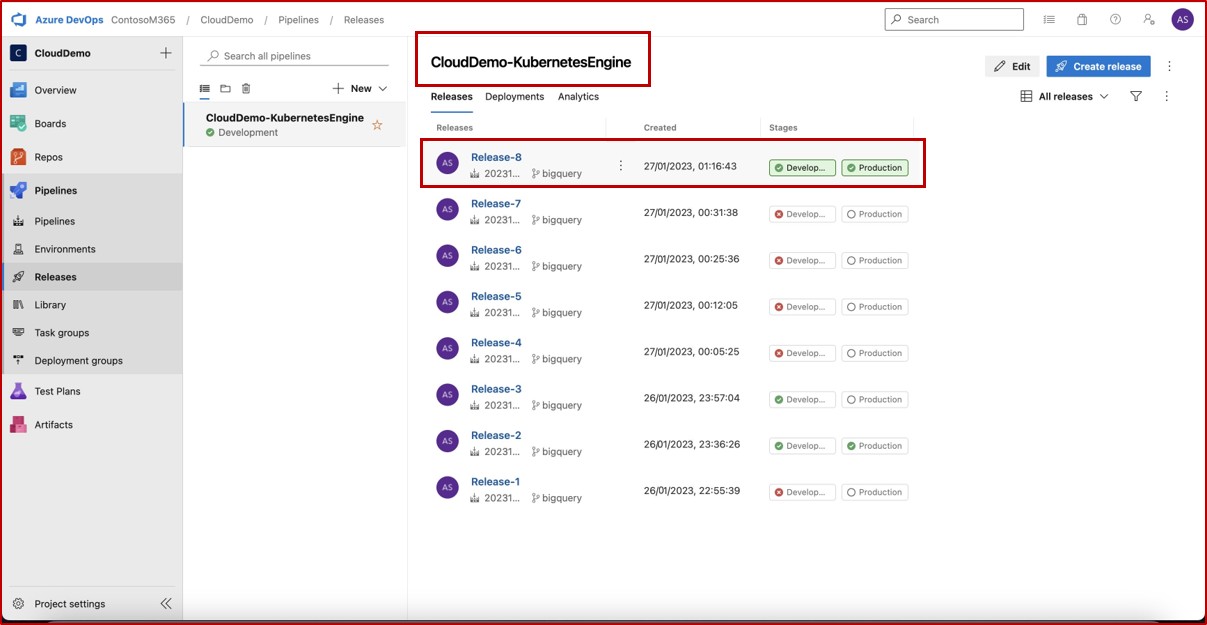
Remarque : Dans les exemples précédents, une capture d’écran complète n’a pas été utilisée, mais toutes les captures d’écran de preuve envoyées par l’éditeur de logiciels indépendant doivent être des captures d’écran complètes montrant l’URL, l’heure et la date de connexion de l’utilisateur et du système.
Gestion des comptes
Les pratiques de gestion des comptes sécurisées sont importantes, car les comptes d’utilisateur constituent la base de l’autorisation de l’accès aux systèmes d’information, aux environnements système et aux données. Les comptes d’utilisateur doivent être correctement sécurisés, car une compromission des informations d’identification de l’utilisateur peut non seulement fournir un accès à l’environnement et l’accès aux données sensibles, mais peut également fournir un contrôle administratif sur l’ensemble de l’environnement ou des systèmes clés si les informations d’identification de l’utilisateur disposent de privilèges administratifs.
Contrôle n° 14
Fournissez la preuve que :
Les informations d’identification par défaut sont désactivées, supprimées ou modifiées sur les composants système échantillonnées.
Un processus est en place pour sécuriser (renforcer) les comptes de service et que ce processus a été suivi.
Intention : informations d’identification par défaut
Bien que cela devienne moins populaire, il existe encore des cas où les acteurs des menaces peuvent tirer parti des informations d’identification utilisateur par défaut et bien documentées pour compromettre les composants du système de production. L’exemple le plus courant est le contrôleur d’accès à distance Dell iDRAC (Integrated Dell Remote Access Controller). Ce système peut être utilisé pour gérer à distance un serveur Dell, qui peut être utilisé par un acteur de menace pour prendre le contrôle du système d’exploitation du serveur. Les informations d’identification par défaut de root ::calvin sont documentées et peuvent souvent être utilisées par les acteurs des menaces pour accéder aux systèmes utilisés par les organisations. L’objectif de ce contrôle est de s’assurer que les informations d’identification par défaut sont désactivées ou supprimées pour améliorer la sécurité.
Recommandations : informations d’identification par défaut
Il existe différentes façons de recueillir des preuves à l’appui de ce contrôle. Les captures d’écran des utilisateurs configurés sur tous les composants système peuvent être utiles, c’est-à-dire que les captures d’écran des comptes Windows par défaut via l’invite de commandes (CMD) et pour les fichiers /etc/shadow et /etc/passwd Linux vous aideront à montrer si les comptes ont été désactivés.
Exemple de preuve : informations d’identification par défaut
La capture d’écran suivante montre le fichier /etc/shadow pour montrer que les comptes par défaut ont un mot de passe verrouillé et que les nouveaux comptes créés/actifs ont un mot de passe utilisable.
Notez que le fichier /etc/shadow est nécessaire pour montrer que les comptes sont réellement désactivés en observant que le hachage de mot de passe commence par un caractère non valide tel que « ! » indiquant que le mot de passe est inutilisable. Dans les captures d’écran suivantes, « L » signifie verrouiller le mot de passe du compte nommé. Cette option désactive un mot de passe en le remplaçant par une valeur qui ne correspond à aucune valeur chiffrée possible (elle ajoute un ! au début du mot de passe). « P » signifie qu’il s’agit d’un mot de passe utilisable.
La deuxième capture d’écran montre que sur le serveur Windows, tous les comptes par défaut ont été désactivés. En utilisant la commande « net user » sur un terminal (CMD), vous pouvez répertorier les détails de chacun des comptes existants, en observant que tous ces comptes ne sont pas actifs.
En utilisant la commande net user dans CMD, vous pouvez afficher tous les comptes et observer que tous les comptes par défaut ne sont pas actifs.
Intention : informations d’identification par défaut
Les comptes de service sont souvent ciblés par des acteurs de menace, car ils sont souvent configurés avec des privilèges élevés. Ces comptes peuvent ne pas suivre les stratégies de mot de passe standard, car l’expiration des mots de passe de compte de service interrompt souvent les fonctionnalités. Par conséquent, ils peuvent être configurés avec des mots de passe faibles ou des mots de passe réutilisés au sein de l’organisation. Un autre problème potentiel, en particulier au sein d’un environnement Windows, peut être que le système d’exploitation met en cache le hachage de mot de passe. Cela peut être un gros problème dans les cas suivants :
le compte de service est configuré dans un service d’annuaire, car ce compte peut être utilisé sur plusieurs systèmes avec le niveau de privilèges configuré, ou
le compte de service est local, il est probable que le même compte/mot de passe soit utilisé sur plusieurs systèmes au sein de l’environnement.
Les problèmes précédents peuvent conduire à un acteur de menace à accéder à davantage de systèmes dans l’environnement et peuvent entraîner une élévation supplémentaire des privilèges et/ou un mouvement latéral. L’objectif est donc de s’assurer que les comptes de service sont correctement renforcés et sécurisés pour les protéger contre toute prise en charge par un acteur de menace, ou en limitant le risque en cas de compromission de l’un de ces comptes de service. Le contrôle nécessite la mise en place d’un processus formel pour le renforcement de ces comptes, qui peut inclure la restriction des autorisations, l’utilisation de mots de passe complexes et une rotation régulière des informations d’identification.
Conseils
Il existe de nombreux guides sur Internet pour renforcer les comptes de service. Les preuves peuvent se présenter sous la forme de captures d’écran montrant comment l’organisation a implémenté un renforcement sécurisé du compte. Voici quelques exemples (on s’attend à ce que plusieurs techniques soient utilisées) :
Restreindre les comptes à un ensemble d’ordinateurs dans Active Directory,
La définition du compte de sorte que la connexion interactive n’est pas autorisée,
Définition d’un mot de passe extrêmement complexe,
Pour Active Directory, activez l’indicateur « Le compte est sensible et ne peut pas être délégué ».
Exemple de preuve
Il existe plusieurs façons de renforcer un compte de service qui dépend de chaque environnement individuel. Voici quelques-uns des mécanismes qui peuvent être utilisés :
La capture d’écran suivante montre que l’option « Le compte est sensible et se connecter à délégué » est sélectionnée sur le compte de service « _Prod compte de service SQL ».
Cette deuxième capture d’écran montre que le compte de service « _Prod compte de service SQL » est verrouillé sur SQL Server et peut uniquement se connecter à ce serveur.
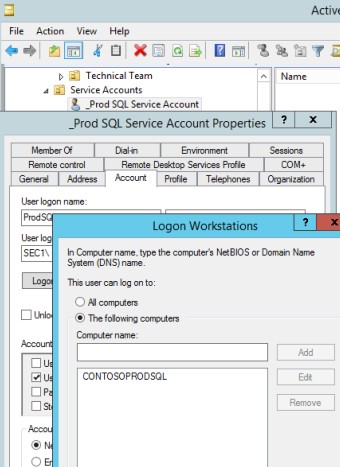
Cette capture d’écran suivante montre que le compte de service « _Prod compte de service SQL » est uniquement autorisé à se connecter en tant que service.
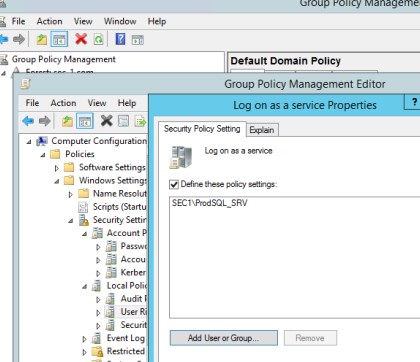
Remarque : Dans les exemples précédents, une capture d’écran complète n’a pas été utilisée, mais toutes les captures d’écran de preuve envoyées par l’éditeur de logiciels indépendant doivent être des captures d’écran complètes montrant l’URL, l’heure et la date de connexion de l’utilisateur et du système.
Contrôle n° 15
Fournissez la preuve que :
Des comptes d’utilisateur uniques sont émis pour tous les utilisateurs.
Les principes des privilèges minimum de l’utilisateur sont respectés dans l’environnement.
Une stratégie de mot de passe/phrase secrète forte ou d’autres mesures d’atténuation appropriées sont en place.
Un processus est en place et suivi au moins tous les trois mois pour désactiver ou supprimer les comptes non utilisés dans les 3 mois.
Intention : sécuriser les comptes de service
L’objectif de ce contrôle est la responsabilité. En émettant des utilisateurs avec leur propre compte d’utilisateur unique, les utilisateurs seront responsables de leurs actions, car l’activité de l’utilisateur peut être suivie auprès d’un utilisateur individuel.
Recommandations : sécuriser les comptes de service
Des captures d’écran montrant des comptes d’utilisateur configurés dans les composants système dans l’étendue peuvent inclure des serveurs, des référentiels de code, des plateformes de gestion cloud, Active Directory, des pare-feu, etc.
Exemple de preuve : comptes de service sécurisés
La capture d’écran suivante montre les comptes d’utilisateur configurés pour l’environnement Azure dans l’étendue et que tous les comptes sont uniques.
Intention : privilèges
Les utilisateurs doivent uniquement obtenir les privilèges nécessaires pour remplir leur fonction de travail. Il s’agit de limiter le risque qu’un utilisateur accède intentionnellement ou involontairement à des données qu’il ne doit pas ou effectue
acte malveillant. En suivant ce principe, il réduit également la surface d’attaque potentielle (c’est-à-dire, les comptes privilégiés) qui peut être ciblée par un acteur de menace malveillant.
Recommandations : privilèges
La plupart des organisations utilisent des groupes pour attribuer des privilèges en fonction des équipes au sein de l’organisation. Les preuves peuvent être des captures d’écran montrant les différents groupes privilégiés et uniquement les comptes d’utilisateur des équipes qui ont besoin de ces privilèges. En règle générale, cela est sauvegardé avec des stratégies/processus de prise en charge définissant chaque groupe défini avec les privilèges requis et la justification métier et une hiérarchie de membres de l’équipe pour valider l’appartenance au groupe est configurée correctement.
Par exemple : dans Azure, le groupe Propriétaires doit être très limité. Il doit donc être documenté et doit avoir un nombre limité de personnes affectées à ce groupe. Un autre exemple peut être un nombre limité de membres du personnel ayant la capacité d’apporter des modifications au code. Un groupe peut être configuré avec ce privilège avec les membres du personnel considérés comme ayant besoin de cette autorisation configurée. Cela doit être documenté afin que l’analyste de certification puisse croiser le document avec les groupes configurés, etc.
Exemple de preuve : privilèges
Les captures d’écran suivantes illustrent le principe du privilège minimum dans un environnement Azure.
La capture d’écran suivante met en évidence l’utilisation de différents groupes dans Azure Active Directory (AAD)/Microsoft Entra. Notez qu’il existe trois groupes de sécurité : Développeurs, Ingénieurs principaux et Opérations de sécurité.
En accédant au groupe « Développeurs », au niveau du groupe, les seuls rôles attribués sont « Développeur d’applications » et « Lecteurs d’annuaire ».
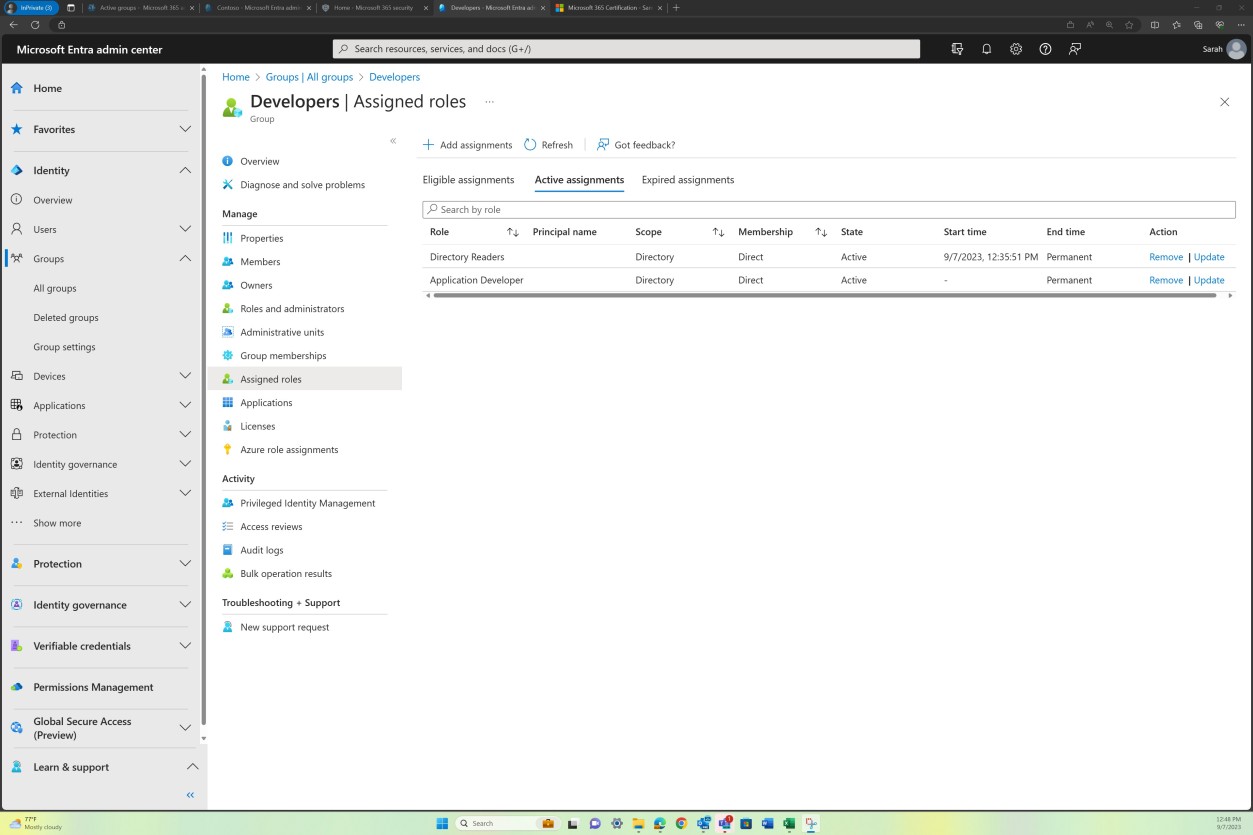
La capture d’écran suivante montre les membres du groupe « Développeurs ».
Enfin, la capture d’écran suivante montre le propriétaire du groupe.
Contrairement au groupe « Développeurs », le groupe « Opérations de sécurité » a des rôles différents attribués, c’est-à-dire « Opérateur de sécurité », qui est conforme à l’exigence du travail.
La capture d’écran suivante montre que différents membres font partie du groupe « Opérations de sécurité ».
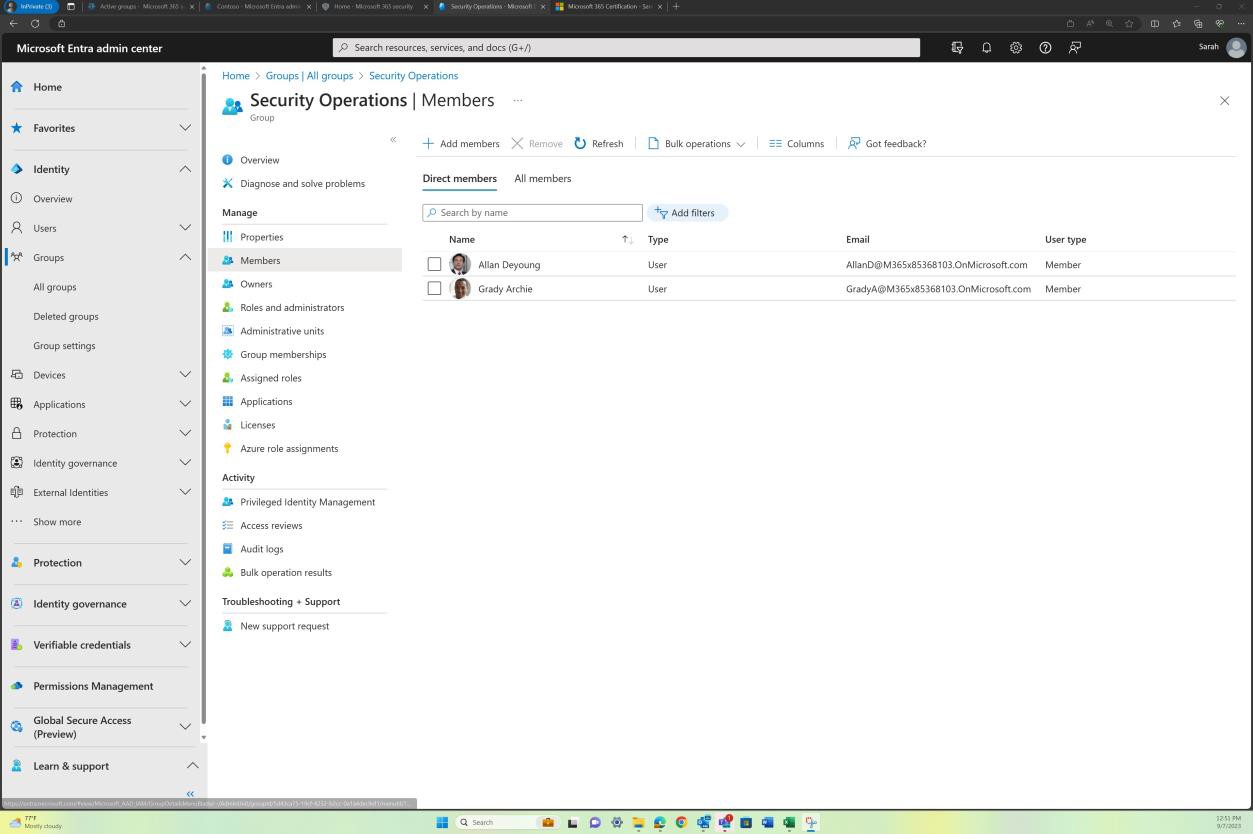
Enfin, le groupe a un propriétaire différent.
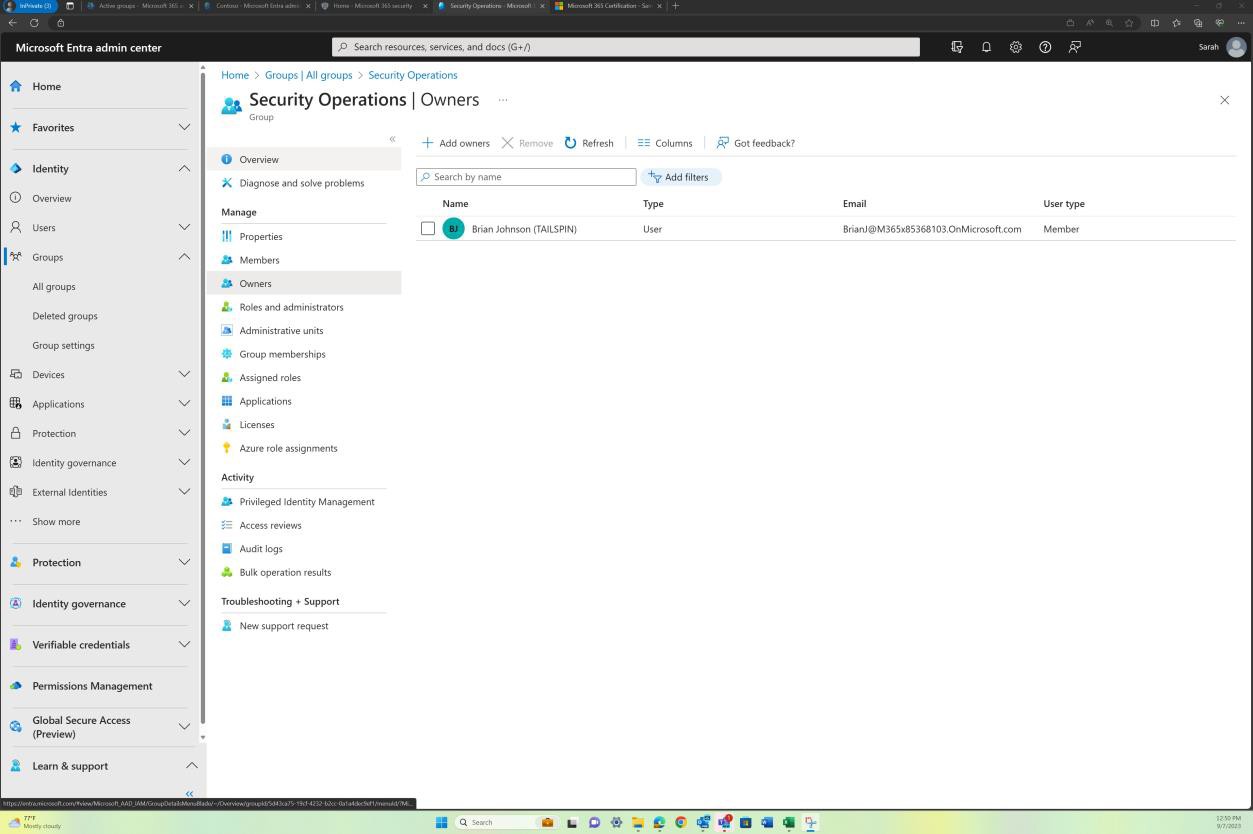
Les administrateurs généraux sont un rôle hautement privilégié et les organisations doivent décider du niveau de risque qu’elles souhaitent accepter lorsqu’elles fournissent ce type d’accès. Dans l’exemple fourni, seuls deux utilisateurs ont ce rôle. Cela permet de s’assurer que la surface d’attaque et l’impact sont réduits.
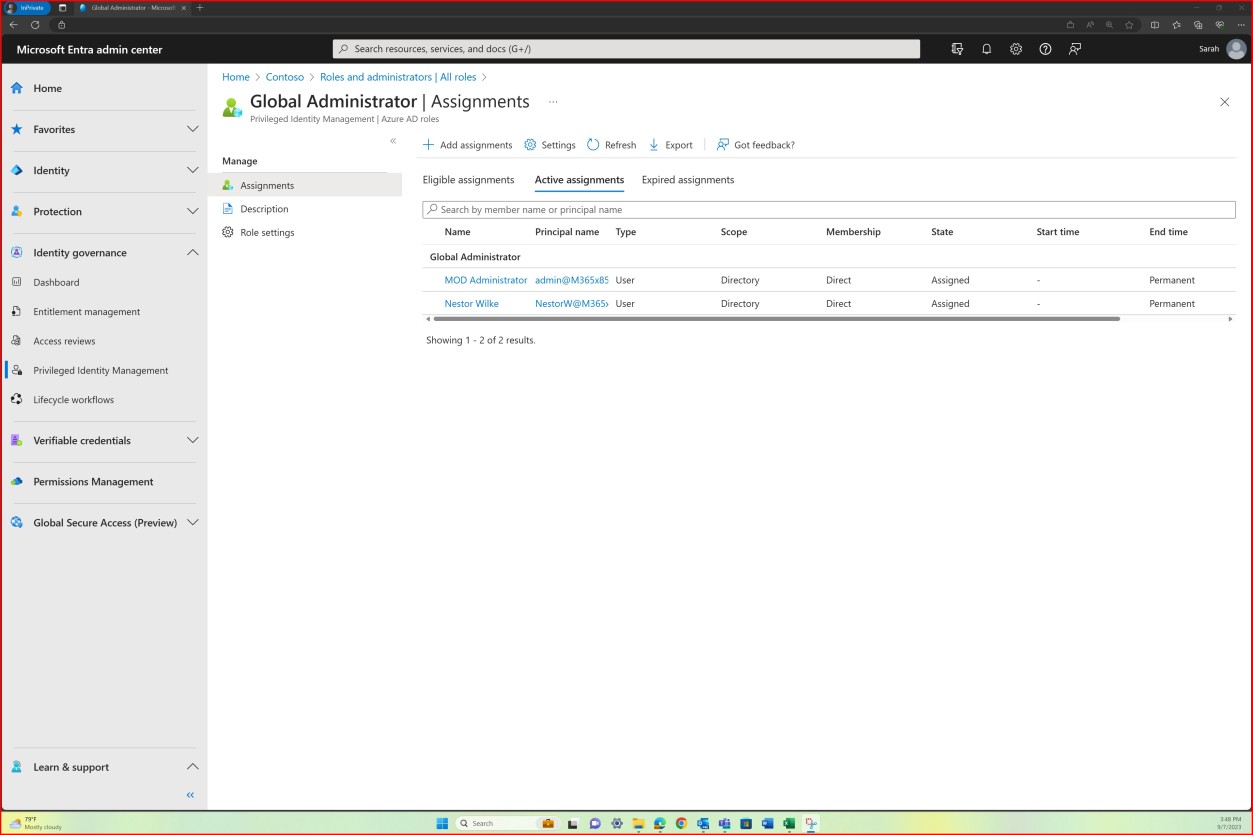
Intention : stratégie de mot de passe
Les informations d’identification de l’utilisateur sont souvent la cible d’attaques par des acteurs de menace qui tentent d’accéder à l’environnement d’une organisation. L’objectif d’une stratégie de mot de passe fort est d’essayer de forcer les utilisateurs à choisir des mots de passe forts afin d’atténuer les risques que les acteurs de menace puissent les forcer par force brute. L’intention de l’ajout de « ou d’autres atténuations appropriées » est de reconnaître que les organisations peuvent implémenter d’autres mesures de sécurité pour aider à protéger les informations d’identification des utilisateurs en fonction des développements du secteur tels que la publication spéciale NIST 800-63B.
Recommandations : stratégie de mot de passe
La preuve d’une stratégie de mot de passe fort peut se présenter sous la forme d’une capture d’écran d’un objet de stratégie de groupe ou d’une stratégie de sécurité locale « Stratégies de compte → stratégie de mot de passe » et « Stratégies de compte → stratégie de verrouillage de compte ». La preuve dépend des technologies utilisées, c’est-à-dire que pour Linux, il peut s’agir du fichier de configuration /etc/pam.d/common-password, pour Bitbucket la section « Stratégies d’authentification » dans le portail d’administration [Gérer votre stratégie de mot de passe | Support Atlassian, etc.
Exemple de preuve : stratégie de mot de passe
La preuve suivante montre la stratégie de mot de passe configurée dans la « Stratégie de sécurité locale » du composant système dans l’étendue « CONTOSO-SRV1 ».
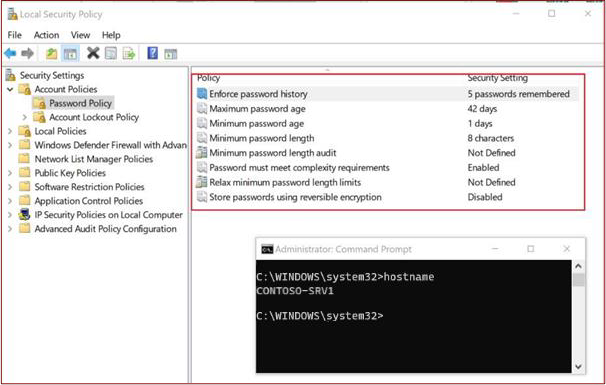
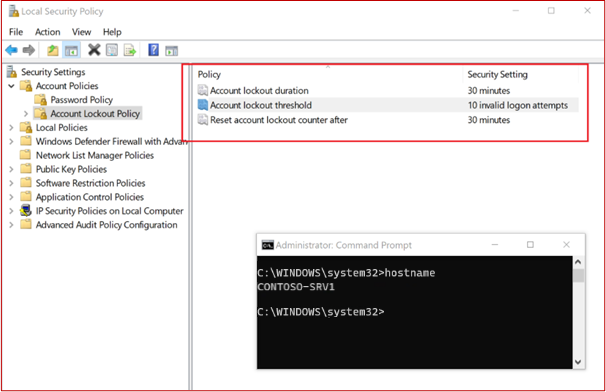
La capture d’écran suivante montre les paramètres de verrouillage de compte pour un pare-feu WatchGuard.
Voici un exemple de longueur minimale de phrase secrète pour le pare-feu WatchGuard.
Remarque : Dans les exemples précédents, aucune capture d’écran complète n’a été utilisée, mais toutes les captures d’écran de preuve envoyées par l’éditeur de logiciels indépendant doivent être des captures d’écran complètes montrant l’URL, l’heure et la date de connexion de l’utilisateur et du système.
Intention : comptes inactifs
Les comptes inactifs peuvent parfois être compromis, soit parce qu’ils sont ciblés par des attaques par force brute qui peuvent ne pas être marquées car l’utilisateur ne tentera pas de se connecter aux comptes, ou par le biais d’une violation de la base de données de mot de passe où le mot de passe d’un utilisateur a été réutilisé et est disponible dans un vidage de nom d’utilisateur/mot de passe sur Internet. Les comptes inutilisés doivent être désactivés/supprimés pour réduire la surface d’attaque d’un acteur de menace pour effectuer des activités de compromission de compte. Ces comptes peuvent être dus à un processus de départ qui n’est pas effectué correctement, à un membre du personnel en cas de maladie de longue durée ou à un membre du personnel en congé de maternité/paternité. En implémentant un processus trimestriel pour identifier ces comptes, les organisations peuvent réduire la surface d’attaque.
Ce contrôle impose qu’un processus soit en place et suivi au moins tous les trois mois pour désactiver ou supprimer les comptes qui n’ont pas été utilisés au cours des trois derniers mois afin de réduire le risque en garantissant des révisions régulières des comptes et la désactivation en temps voulu des comptes inutilisés.
Recommandations : comptes inactifs
La preuve doit être double :
Tout d’abord, une capture d’écran ou une exportation de fichier montrant la « dernière ouverture de session » de tous les comptes d’utilisateur dans l’environnement dans l’étendue. Il peut s’agir de comptes locaux ou de comptes au sein d’un service d’annuaire centralisé, comme AAD (Azure Active Directory). Cela montre qu’aucun compte de plus de 3 mois n’est activé.
Deuxièmement, la preuve du processus de révision trimestrielle qui peut être une preuve documentaire de l’achèvement de la tâche dans ado (Azure DevOps) ou des tickets JIRA, ou via des enregistrements papier qui doivent être signés.
Exemple de preuve : comptes inactifs
La capture d’écran suivante montre qu’une plateforme cloud a été utilisée pour effectuer des révisions d’accès. Pour ce faire, utilisez la fonctionnalité De gouvernance des identités dans Azure.
La capture d’écran suivante montre l’historique des révisions, la période de révision et l’état.
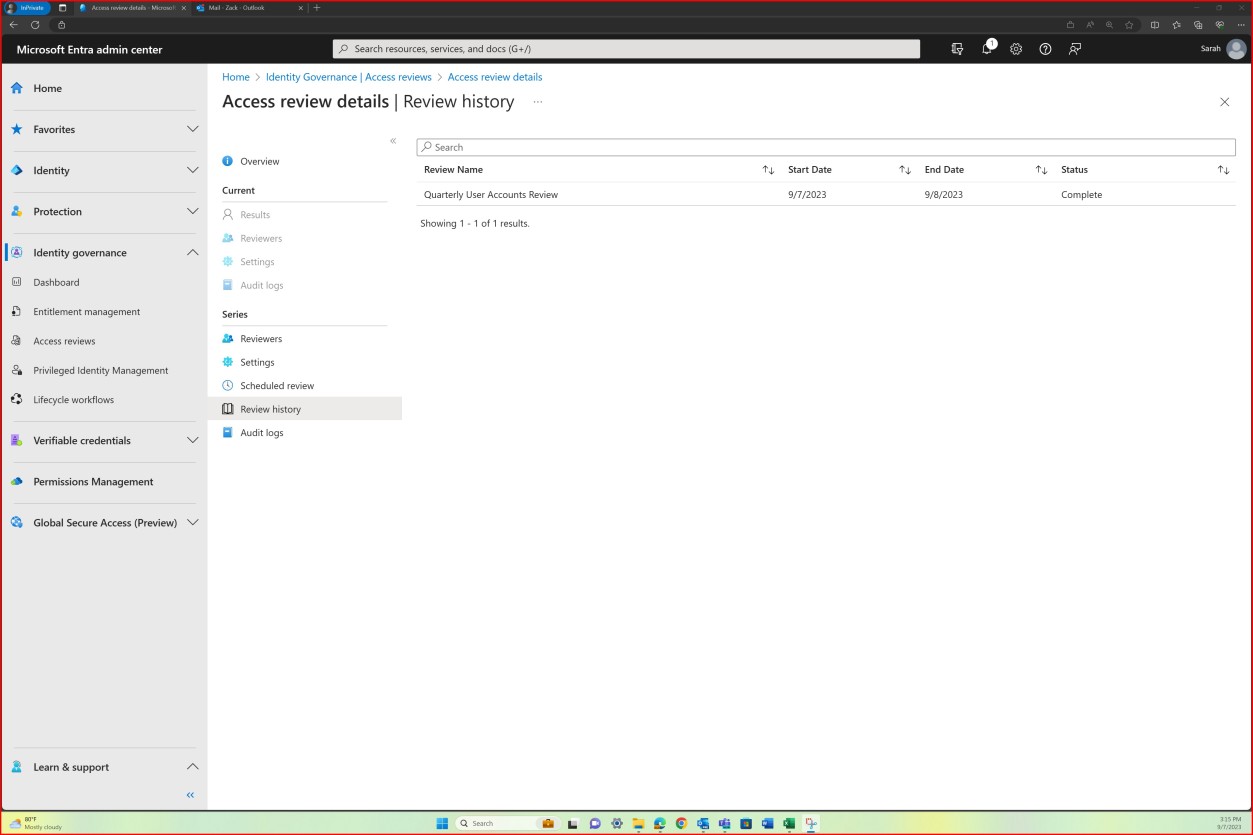
Le tableau de bord et les métriques de la révision fournissent des détails supplémentaires tels que l’étendue de tous les utilisateurs de l’organisation et le résultat de la révision, ainsi que la fréquence qui est trimestrielle.
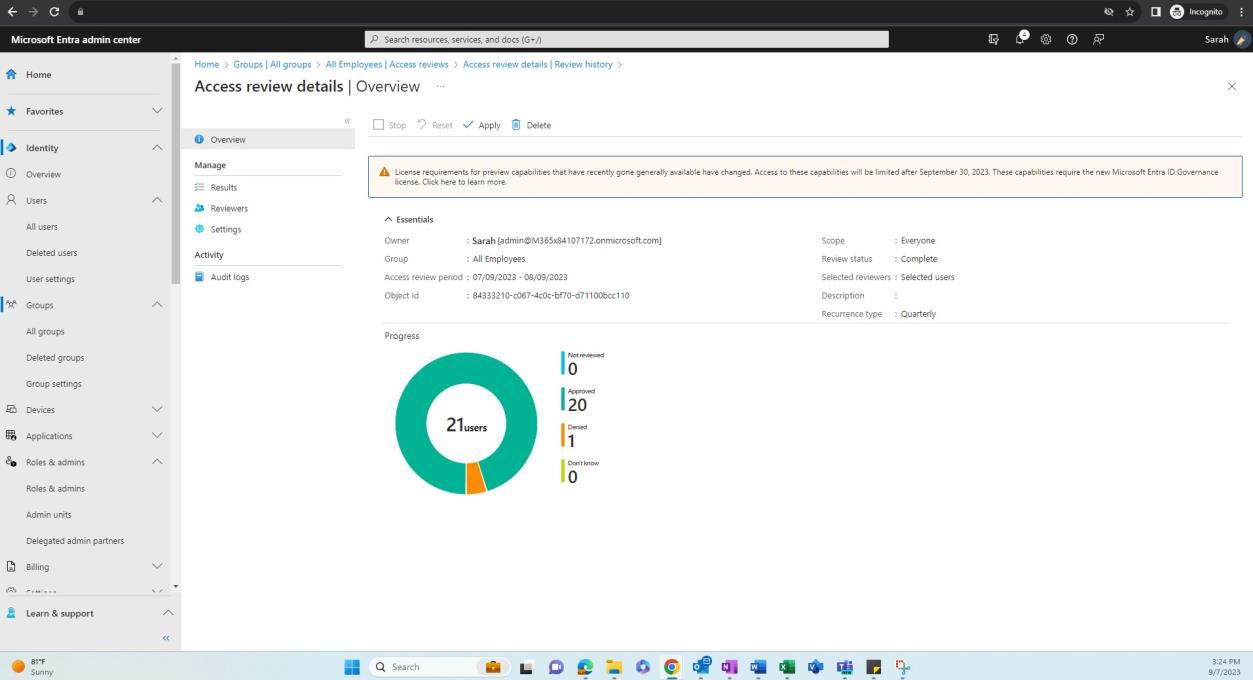
Lors de l’évaluation des résultats de la révision, l’image indique qu’une action recommandée a été fournie, qui est basée sur des conditions préconfigurées. En outre, elle exige qu’une personne affectée applique manuellement les décisions de l’examen.
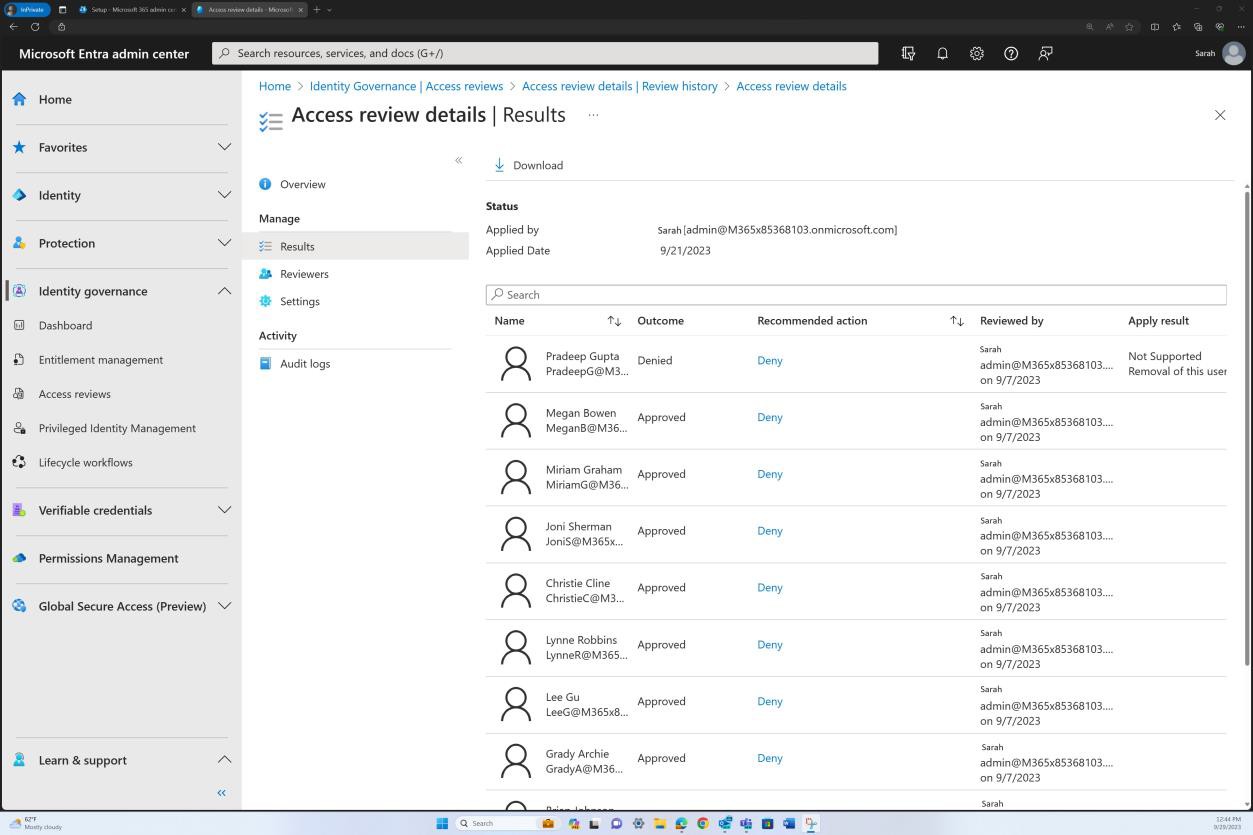
Vous pouvez observer dans ce qui suit que pour chaque employé, une recommandation et une justification sont fournies. Comme mentionné, une décision d’accepter la recommandation ou de l’ignorer avant d’appliquer la révision est requise par une personne affectée. Si la décision finale est contraire à la recommandation, on s’attend à ce que des éléments de preuve soient fournis pour expliquer pourquoi.
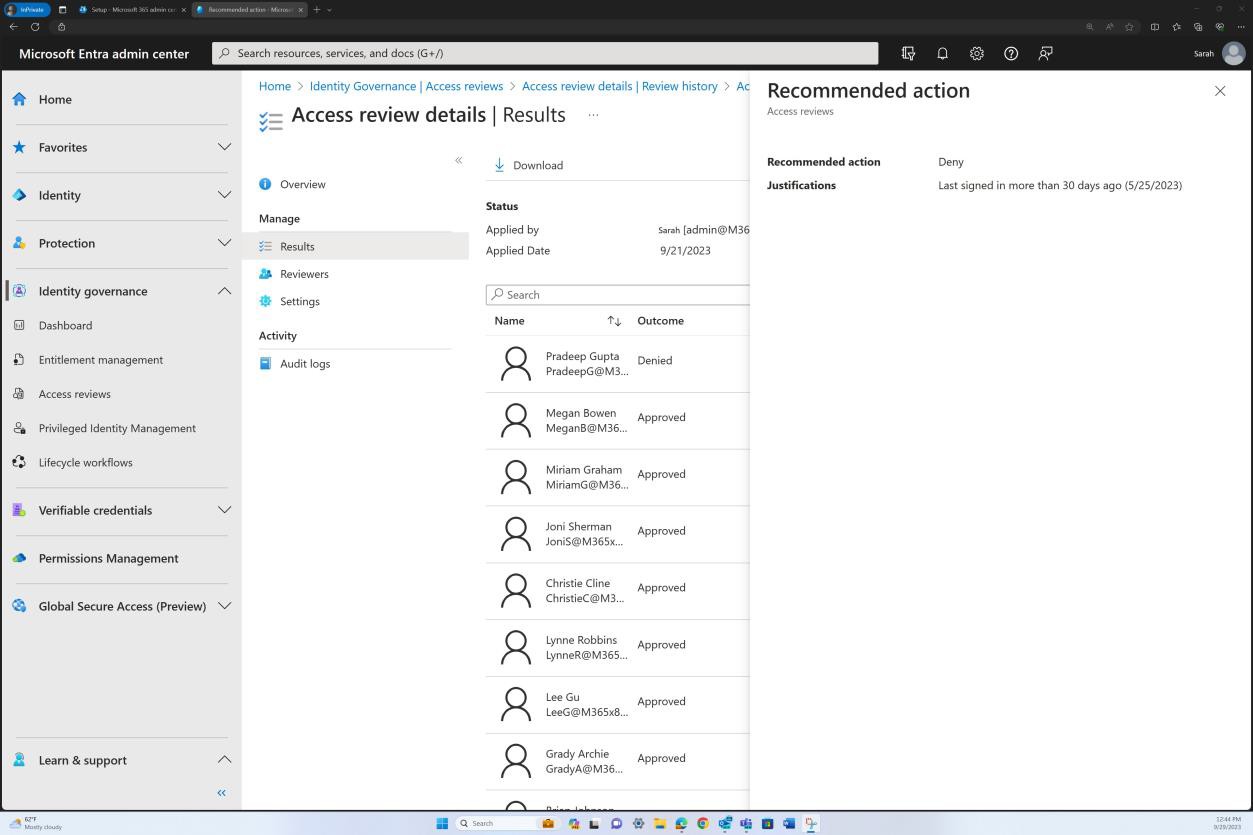
Contrôle n° 16
Vérifiez que l’authentification multifacteur (MFA) est configurée pour toutes les connexions d’accès à distance et toutes les interfaces d’administration non-console, y compris l’accès aux dépôts de code et aux interfaces de gestion cloud.
Signification de ces termes
Accès à distance : il s’agit des technologies utilisées pour accéder à l’environnement de prise en charge. Par exemple, VPN IPSec d’accès à distance, VPN SSL ou Hôte Jumpbox/Bastian.
Interfaces d’administration non-console : il s’agit des connexions d’administration réseau aux composants système. Cela peut être via le Bureau à distance, SSH ou une interface web.
Référentiels de code : la base de code de l’application doit être protégée contre les modifications malveillantes susceptibles d’introduire des programmes malveillants dans l’application. L’authentification multifacteur doit être configurée sur les référentiels de code.
Interfaces de gestion cloud : où tout ou partie de l’environnement est hébergé dans le fournisseur de services cloud (CSP). L’interface d’administration pour la gestion cloud est incluse ici.
Intention : MFA
L’objectif de ce contrôle est de fournir des atténuations contre les attaques par force brute sur les comptes privilégiés avec un accès sécurisé à l’environnement en implémentant l’authentification multifacteur (MFA). Même si un mot de passe est compromis, le mécanisme d’authentification multifacteur doit toujours être sécurisé, garantissant que toutes les actions d’accès et d’administration sont effectuées uniquement par des membres du personnel autorisés et approuvés.
Pour renforcer la sécurité, il est important d’ajouter une couche de sécurité supplémentaire pour les connexions d’accès à distance et les interfaces d’administration non-console à l’aide de l’authentification multifacteur. Les connexions d’accès à distance sont particulièrement vulnérables aux entrées non autorisées, et les interfaces administratives contrôlent les fonctions à privilèges élevés, ce qui rend les deux zones critiques qui nécessitent des mesures de sécurité renforcées. En outre, les dépôts de code contiennent un travail de développement sensible, et les interfaces de gestion cloud fournissent un accès étendu aux ressources cloud d’une organisation, ce qui en fait des points critiques supplémentaires qui doivent être sécurisés avec l’authentification multifacteur.
Recommandations : MFA
Les preuves doivent montrer que l’authentification multifacteur est activée sur toutes les technologies qui correspondent aux catégories précédentes. Il peut s’agir d’une capture d’écran montrant que l’authentification multifacteur est activée au niveau du système. Au niveau du système, nous avons besoin d’une preuve indiquant qu’elle est activée pour tous les utilisateurs, et pas seulement un exemple de compte avec l’authentification multifacteur activée. Lorsque la technologie est renvoyée à une solution d’authentification multifacteur, nous avons besoin des preuves pour démontrer qu’elle est activée et en cours d’utilisation. Ce que cela veut dire, c’est : lorsque la technologie est configurée pour l’authentification Radius, qui pointe vers un fournisseur MFA, vous devez également prouver que le serveur Radius vers lequel il pointe est une solution MFA et que les comptes sont configurés pour l’utiliser.
Exemple de preuve : MFA
Les captures d’écran suivantes montrent comment une stratégie conditionnelle MFA peut être implémentée dans AAD/Entra pour appliquer l’exigence d’authentification à deux facteurs au sein de l’organisation. Nous pouvons voir dans l’exemple suivant que la stratégie est « activée ».
La capture d’écran suivante montre que la stratégie MFA doit être appliquée à tous les utilisateurs au sein de l’organisation et que cette option est activée.
La capture d’écran suivante montre que l’accès est accordé en cas de respect de la condition MFA. Sur le côté droit de la capture d’écran, nous pouvons voir que l’accès n’est accordé à un utilisateur qu’une fois l’authentification MFA implémentée.
Exemple de preuve : MFA
Des contrôles supplémentaires peuvent être implémentés, tels qu’une exigence d’inscription MFA, qui garantit que lors de l’inscription, les utilisateurs devront configurer l’authentification multifacteur avant que l’accès soit accordé à leur nouveau compte. Vous pouvez observer ci-dessous la configuration d’une stratégie d’inscription MFA qui est appliquée à tous les utilisateurs.
Dans la suite de la capture d’écran précédente qui montre la stratégie à appliquer sans exclusions, la capture d’écran suivante montre que tous les utilisateurs sont inclus dans la stratégie.
Exemple de preuve : MFA
La capture d’écran suivante montre que la page « MFA par utilisateur » montre que l’authentification multifacteur est appliquée à tous les utilisateurs.
Exemple de preuve : MFA
Les captures d’écran suivantes montrent les domaines d’authentification configurés sur Pulse Secure, qui est utilisé pour l’accès à distance dans l’environnement. L’authentification est annulée par le service SaaS Duo pour la prise en charge de l’authentification multifacteur.
Cette capture d’écran montre qu’un serveur d’authentification supplémentaire est activé et pointe vers « Duo-LDAP » pour le domaine d’authentification « Duo - Route par défaut ».
Cette capture d’écran finale montre la configuration du serveur d’authentification Duo-LDAP, qui montre que cela pointe vers le service SaaS Duo pour l’authentification multifacteur.
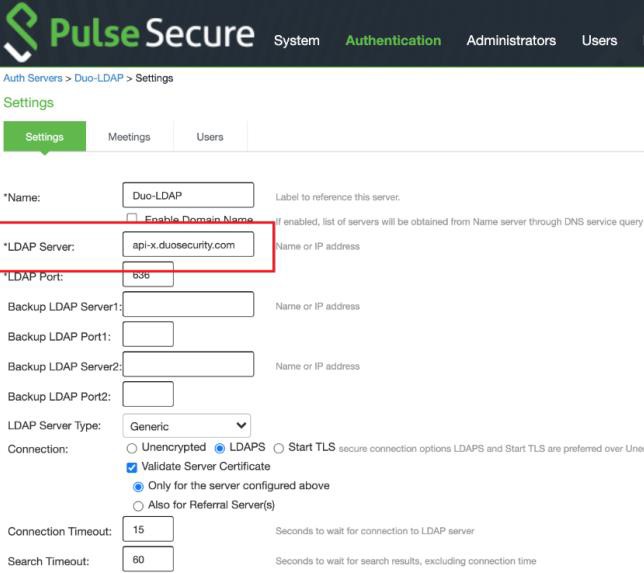
Remarque : Dans les exemples précédents, une capture d’écran complète n’a pas été utilisée, mais toutes les captures d’écran de preuve envoyées par l’éditeur de logiciels indépendant doivent être des captures d’écran complètes montrant l’URL, l’heure et la date de connexion de l’utilisateur et du système.
Journalisation, révision et génération d’alertes des événements de sécurité
La journalisation des événements de sécurité fait partie intégrante du programme de sécurité d’une organisation. Une journalisation adéquate des événements de sécurité associée à des processus d’alerte et de révision paramétrés aide les organisations à identifier les violations ou les tentatives de violation qui peuvent être utilisées par l’organisation pour améliorer la sécurité et les stratégies de sécurité défensives. En outre, une journalisation adéquate sera essentielle à une capacité de réponse aux incidents des organisations qui peut alimenter d’autres activités telles que la possibilité d’identifier avec précision les données et les personnes qui ont été compromises, la période de compromission, de fournir des rapports d’analyse détaillés aux organismes gouvernementaux, etc.
L’examen des journaux de sécurité est une fonction importante pour aider les organisations à identifier les événements de sécurité qui peuvent indiquer une violation de la sécurité ou des activités de reconnaissance qui peuvent indiquer quelque chose à venir. Cela peut être effectué quotidiennement par le biais d’un processus manuel ou à l’aide d’une solution SIEM (Security Information and Event Management) qui permet d’analyser les journaux d’audit, de rechercher des corrélations et des anomalies qui peuvent être signalées pour une inspection manuelle.
Les événements de sécurité critiques doivent être immédiatement examinés pour réduire l’impact sur les données et l’environnement opérationnel. Les alertes permettent de mettre immédiatement en évidence les violations de sécurité potentielles pour le personnel afin de garantir une réponse en temps voulu afin que l’organisation puisse contenir l’événement de sécurité le plus rapidement possible. En veillant à ce que les alertes fonctionnent efficacement, les organisations peuvent minimiser l’impact d’une violation de la sécurité, réduisant ainsi le risque d’une violation grave qui pourrait nuire à la marque de l’organisation et imposer des pertes financières par le biais d’amendes et de dommages à la réputation.
Contrôle n° 17
Indiquez que la journalisation des événements de sécurité est configurée dans l’environnement dans l’étendue pour journaliser les événements, le cas échéant, par exemple :
Accès utilisateur/s aux composants système et à l’application.
Toutes les actions effectuées par un utilisateur disposant de privilèges élevés.
Tentatives d’accès logique non valides.
Création/modification d’un compte privilégié.
Falsification du journal des événements.
Désactivation des outils de sécurité ; par exemple, journalisation des événements.
Journalisation anti-programme malveillant ; par exemple, mises à jour, détection de programmes malveillants, échecs d’analyse.
Intention : journalisation des événements
Pour identifier les tentatives et les violations réelles, il est important que des journaux d’événements de sécurité adéquats soient collectés par tous les systèmes qui composent l’environnement. L’objectif de ce contrôle est de s’assurer que les types corrects d’événements de sécurité sont capturés, ce qui peut ensuite alimenter les processus de révision et d’alerte pour aider à identifier ces événements et à y répondre.
Ce sous-point nécessite qu’un éditeur de logiciels indépendant ait configuré la journalisation des événements de sécurité pour capturer toutes les instances d’accès utilisateur aux composants système et aux applications. Cela est essentiel pour surveiller qui accède aux composants système et aux applications au sein de l’organisation et est essentiel à des fins de sécurité et d’audit.
Ce sous-point nécessite que toutes les actions effectuées par les utilisateurs disposant de privilèges généraux soient journalisées. Les utilisateurs disposant de privilèges élevés peuvent apporter des modifications significatives susceptibles d’avoir un impact sur la posture de sécurité de l’organisation. Par conséquent, il est essentiel de conserver un enregistrement de leurs actions.
Ce sous-point nécessite la journalisation de toutes les tentatives non valides d’accès logique aux composants système ou aux applications. Cette journalisation est un moyen principal de détecter les tentatives d’accès non autorisées et les menaces de sécurité potentielles.
Ce sous-point nécessite la journalisation de toute création ou modification de comptes avec accès privilégié. Ce type de journalisation est essentiel pour le suivi des modifications apportées aux comptes qui ont un niveau élevé d’accès au système et qui peuvent être ciblés par des attaquants.
Ce sous-point nécessite la journalisation de toutes les tentatives de falsification des journaux des événements. La falsification des journaux peut être un moyen de masquer les activités non autorisées. Par conséquent, il est essentiel que ces actions soient journalisées et appliquées.
Ce sous-point nécessite la journalisation de toutes les actions qui désactivent les outils de sécurité, y compris la journalisation des événements elle-même. La désactivation des outils de sécurité peut être un indicateur rouge indiquant une attaque ou une menace interne.
Ce sous-point nécessite la journalisation des activités liées aux outils anti-programme malveillant, notamment les mises à jour, la détection des programmes malveillants et les échecs d’analyse. Le bon fonctionnement et la mise à jour des outils anti-programme malveillant sont essentiels pour la sécurité d’une organisation et les journaux liés à ces activités aident à la surveillance.
Recommandations : journalisation des événements
Des preuves par le biais de captures d’écran ou de paramètres de configuration doivent être fournies sur tous les appareils échantillonné et tous les composants système pertinents pour montrer comment la journalisation est configurée pour fournir l’assurance que ces types d’événements de sécurité sont capturés.
Exemple de preuve
Les captures d’écran suivantes montrent les configurations des journaux et des métriques générés par différentes ressources dans Azure, qui sont ensuite ingérées dans l’espace de travail Log Analytics centralisé.
Nous pouvons voir dans la première capture d’écran que l’emplacement de stockage des journaux est « PaaS-web-app-log-analytics ».
Dans Azure, les paramètres de diagnostic peuvent être activés sur les ressources Azure pour accéder aux journaux d’audit, de sécurité et de diagnostic, comme illustré ci-dessous. Les journaux d’activité, qui sont automatiquement disponibles, incluent la source de l’événement, la date, l’utilisateur, l’horodatage, les adresses sources, les adresses de destination et d’autres éléments utiles.
Remarque : Les exemples suivants montrent un type de preuve qui peut être fourni pour répondre à ce contrôle. Cela dépend de la façon dont votre organisation a configuré la journalisation des événements de sécurité dans l’environnement dans l’étendue. D’autres exemples peuvent inclure Azure Sentinel, Datadog, etc.
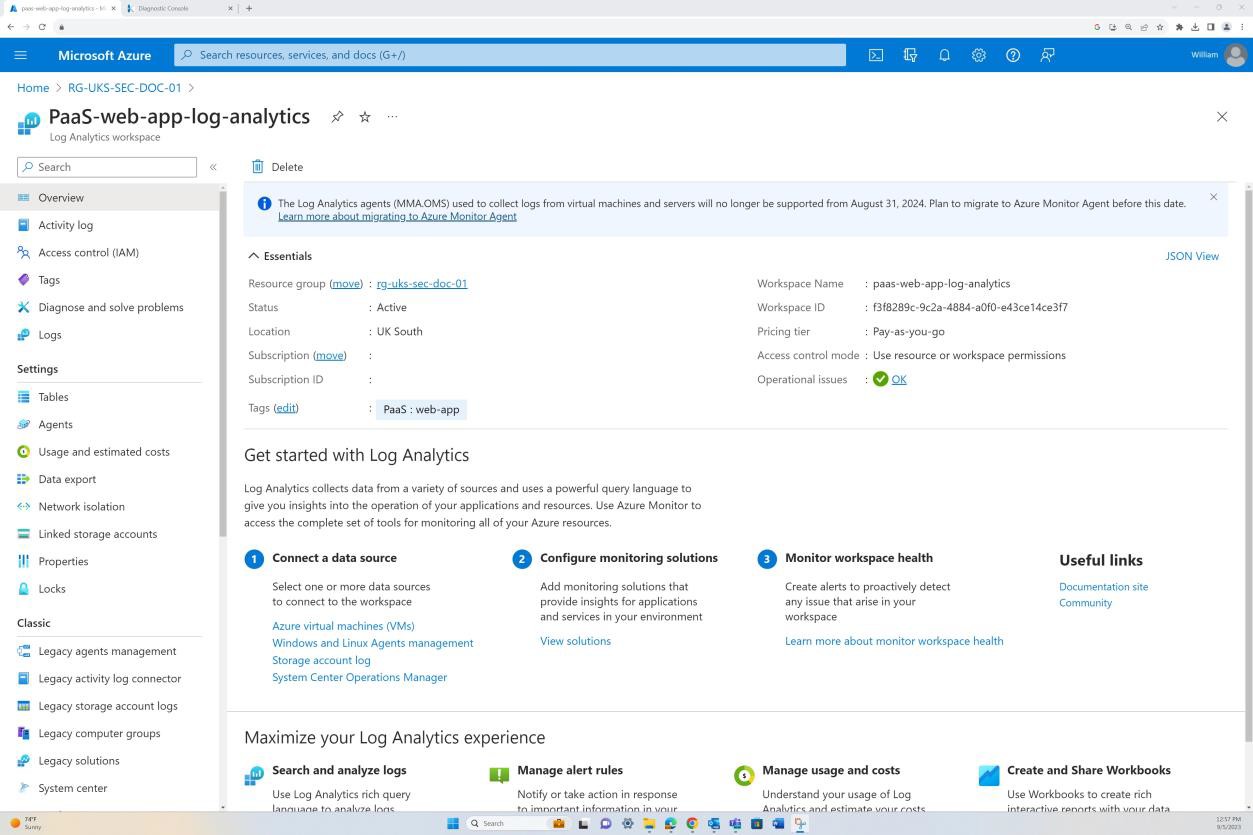
À l’aide de l’option « Paramètres de diagnostic » pour l’application web hébergée sur Azure App Services, vous pouvez configurer les journaux générés et l’emplacement où ils sont envoyés pour le stockage et l’analyse.
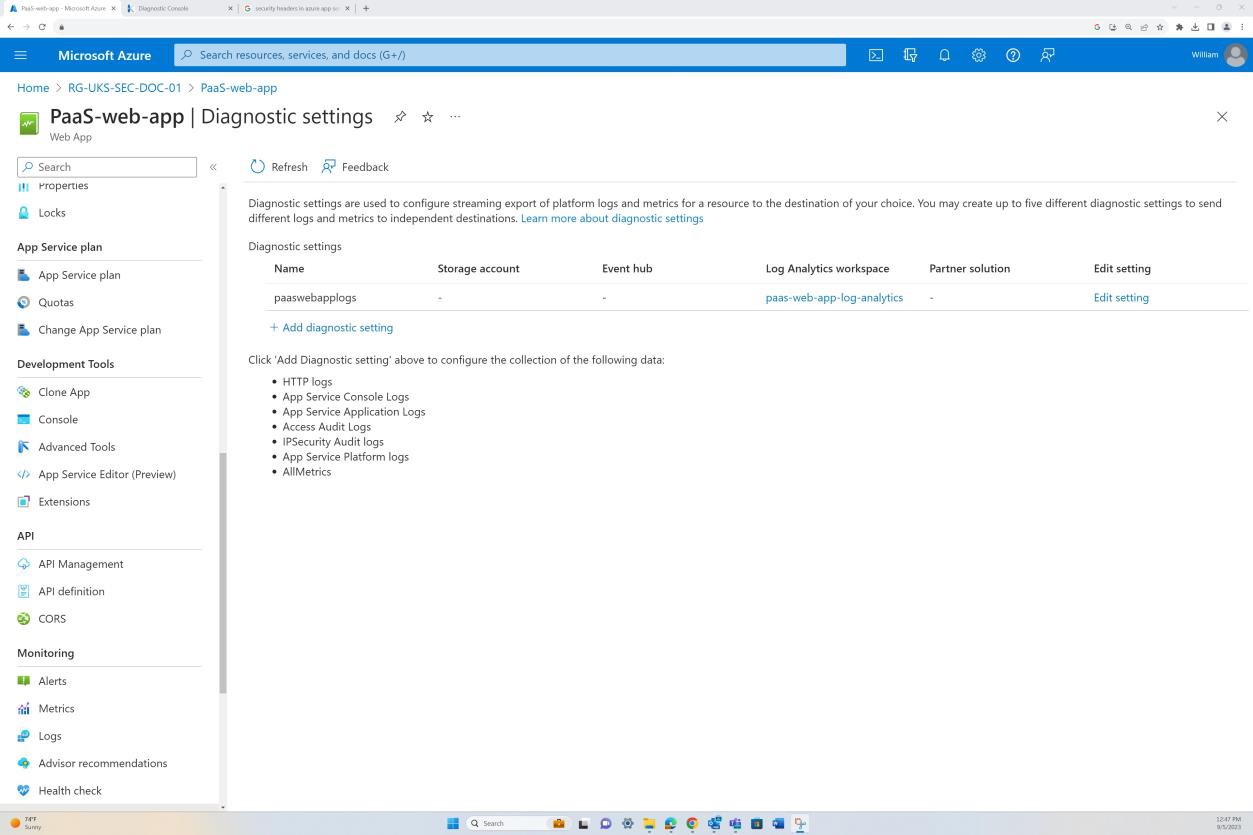
Dans la capture d’écran suivante, les journaux d’audit d’accès et les journaux d’audit IPSecurity sont configurés pour être générés et capturés dans l’espace de travail Log Analytics.
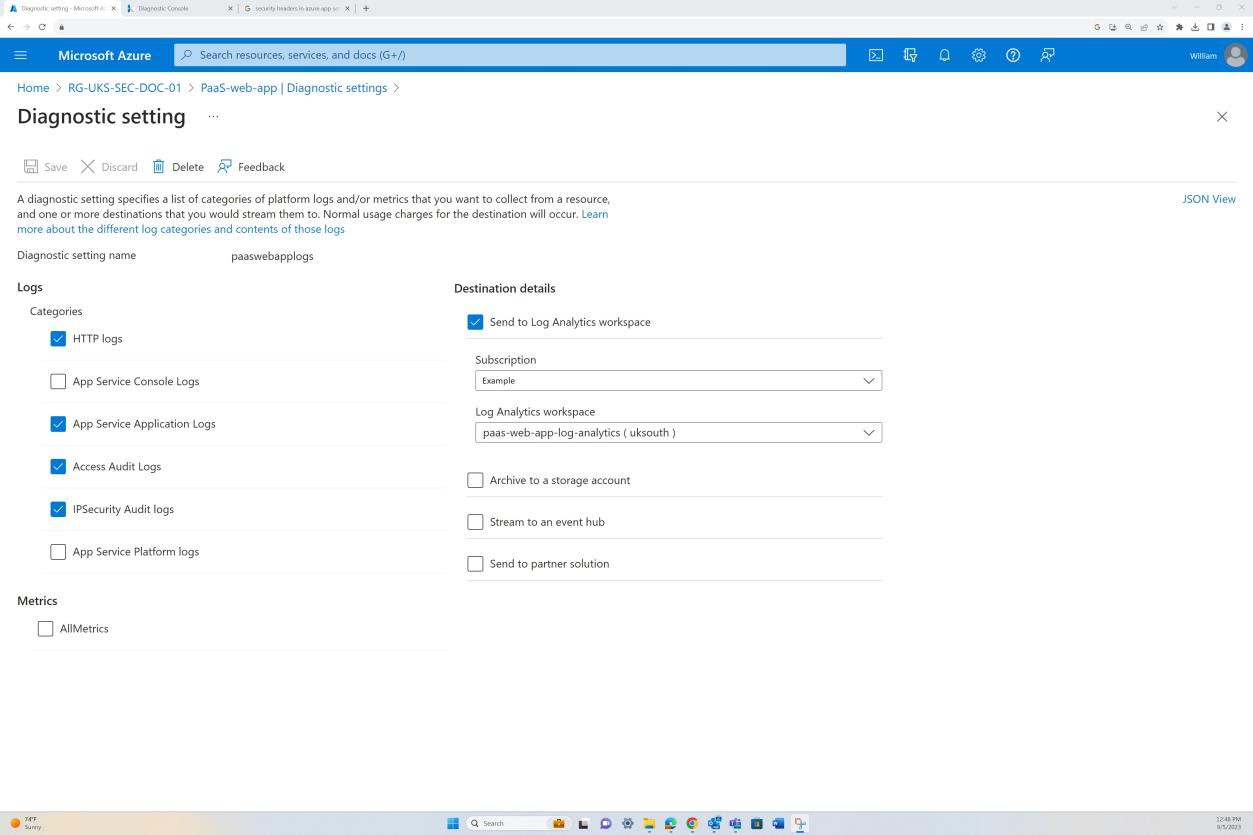
Un autre exemple est pour Azure Front Door, qui est configuré pour envoyer des journaux générés vers le même espace de travail Log Analytics centralisé.
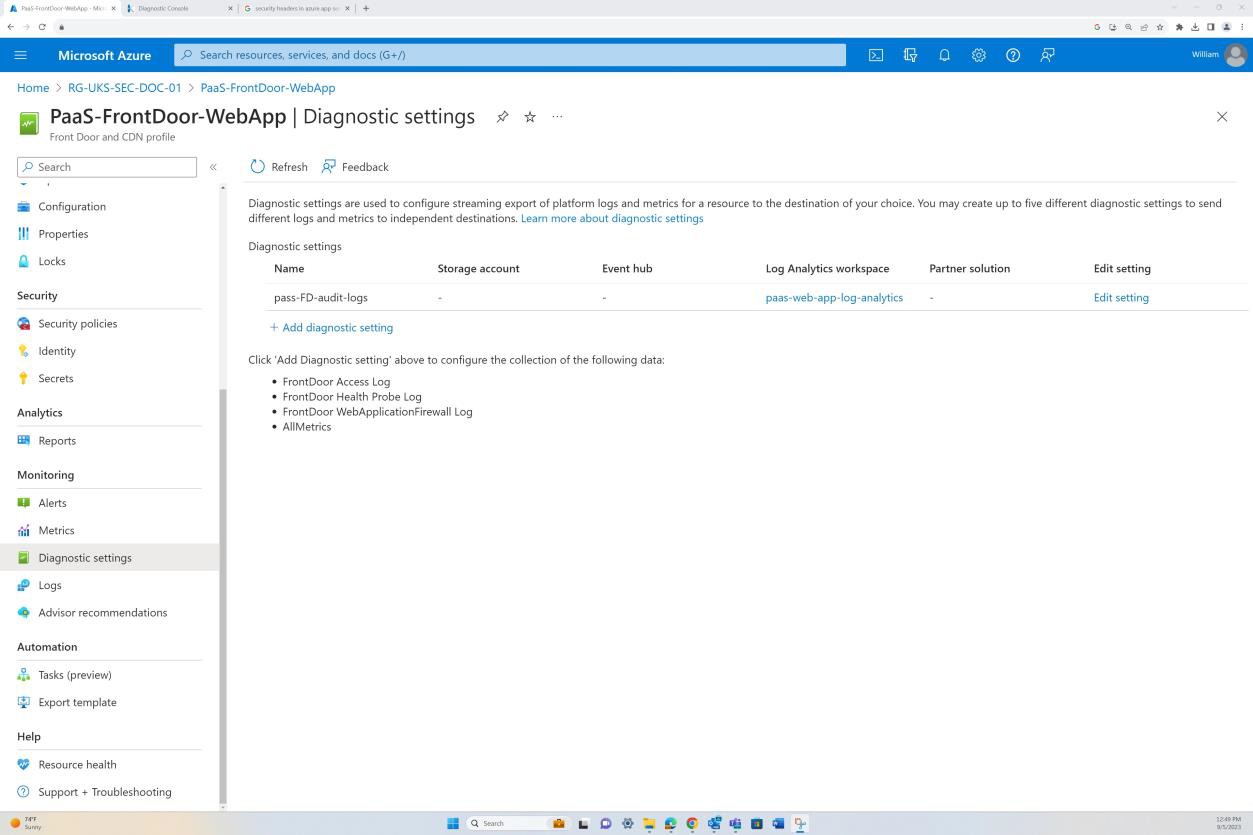
Comme avant d’utiliser l’option « Paramètres de diagnostic », configurez les journaux générés et l’emplacement où ils sont envoyés pour le stockage et l’analyse. La capture d’écran suivante montre que « Journaux d’accès » et « Journaux WAF » ont été configurés.
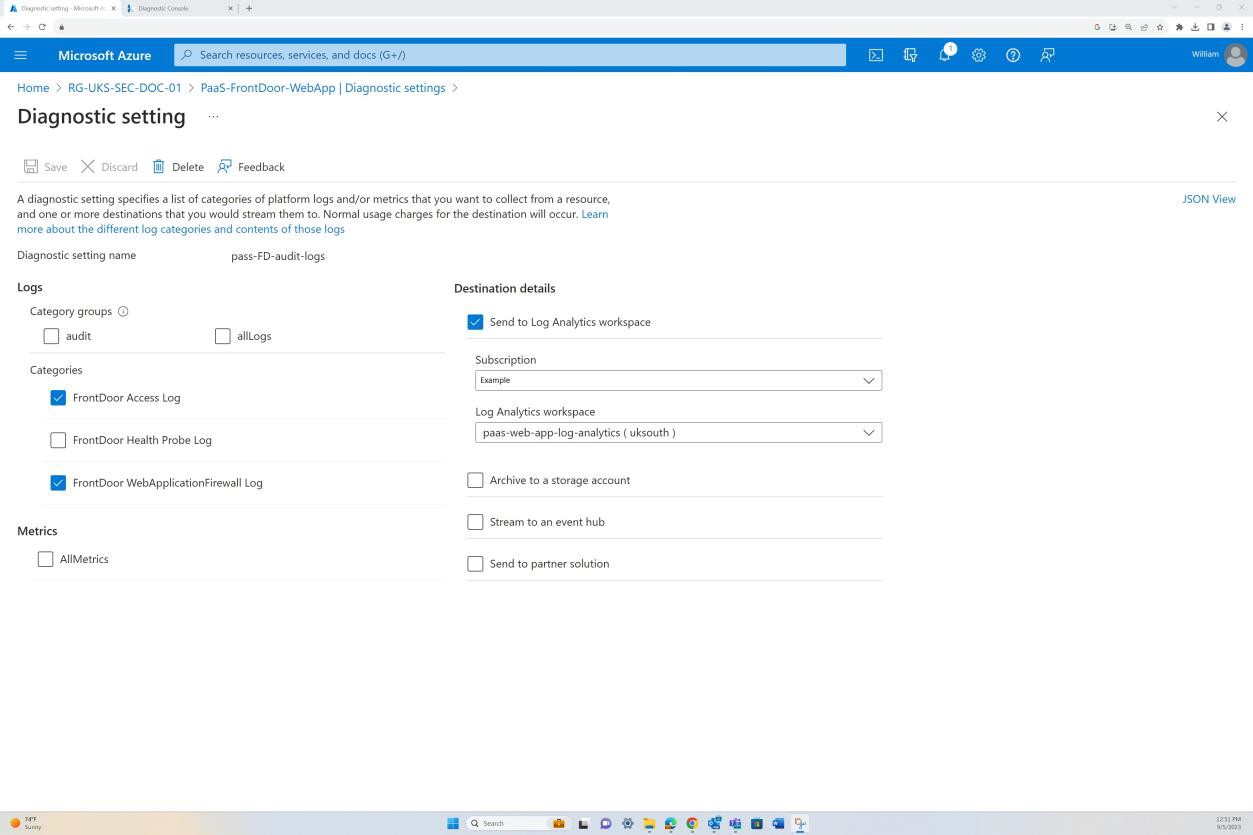
De même, pour Azure SQL Server, les « paramètres de diagnostic » peuvent configurer les journaux générés et l’emplacement où ils sont envoyés pour le stockage et l’analyse.
La capture d’écran suivante montre que les journaux d’audit pour le serveur SQL sont générés et envoyés à l’espace de travail Log Analytics.
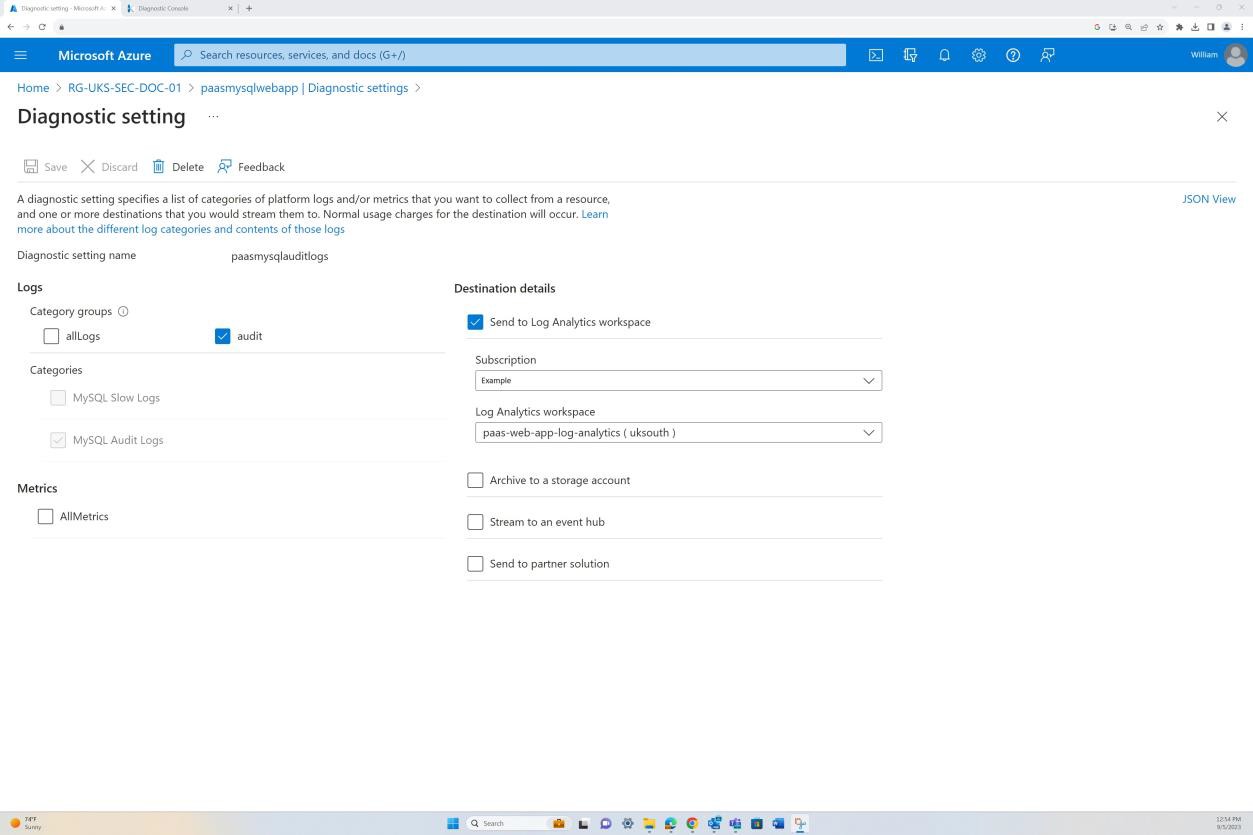
Exemple de preuve
La capture d’écran suivante d’AAD/Entra montre que les journaux d’audit sont générés pour les rôles privilégiés et les administrateurs. Les informations incluent l’état, l’activité, le service, la cible et l’initiateur.
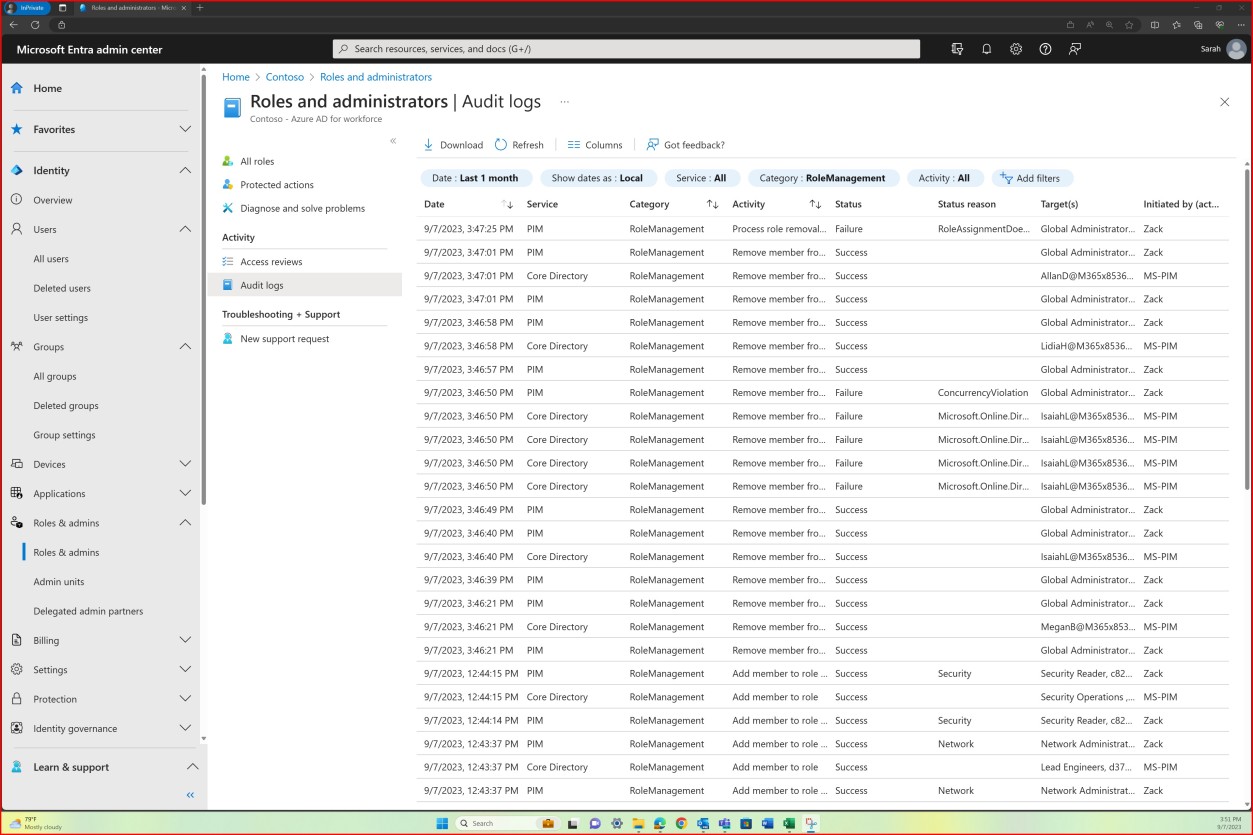
La capture d’écran suivante montre les journaux de connexion. Les informations de journal incluent l’adresse IP, l’état, l’emplacement et la date.
Exemple de preuve
L’exemple suivant se concentre sur les journaux générés pour les instances de calcul telles que les machines virtuelles. Une règle de collecte de données a été implémentée et les journaux des événements Windows, y compris les journaux d’audit de sécurité, sont capturés.
La capture d’écran suivante montre un autre exemple de paramètres de configuration à partir d’un appareil échantillonné appelé « Galaxy-Compliance ». Les paramètres illustrent les différents paramètres d’audit activés dans la « Stratégie de sécurité locale ».
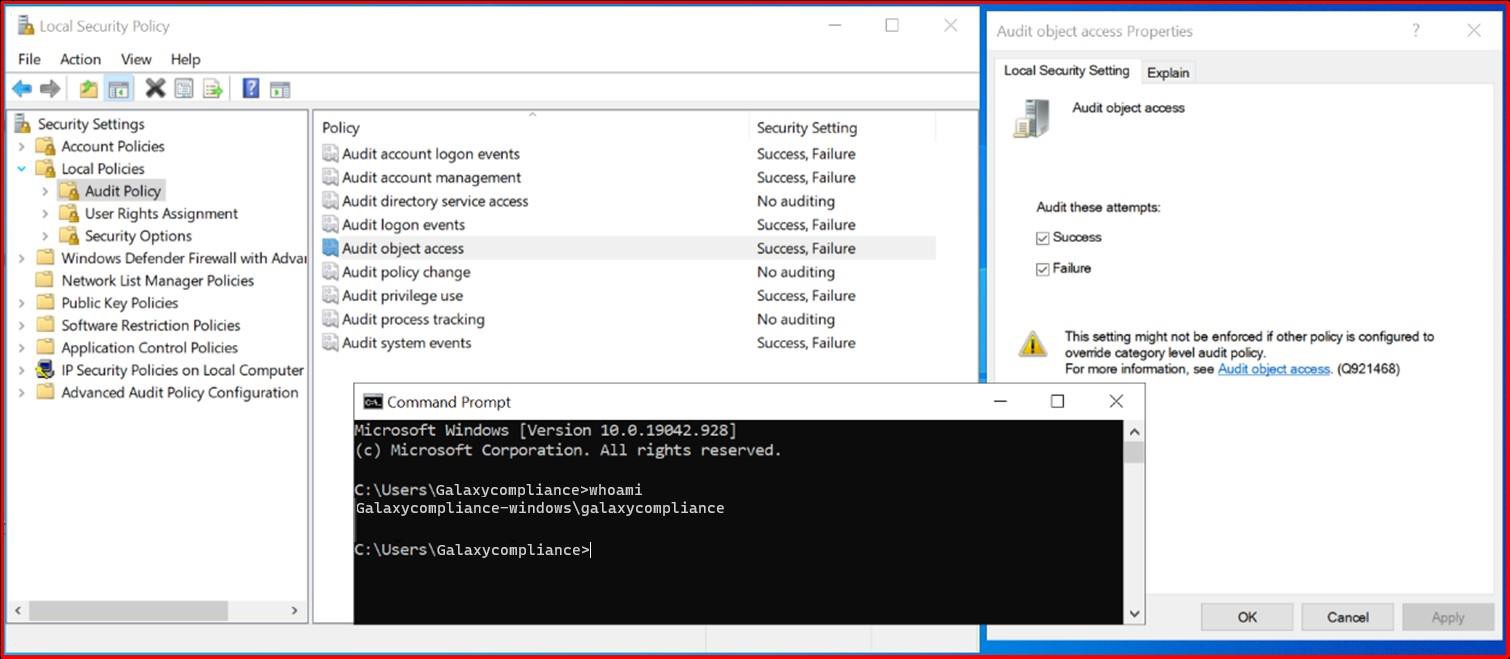
Cette capture d’écran suivante montre un événement où un utilisateur a effacé le journal des événements de l’appareil échantillonné « Galaxy-Compliance ».
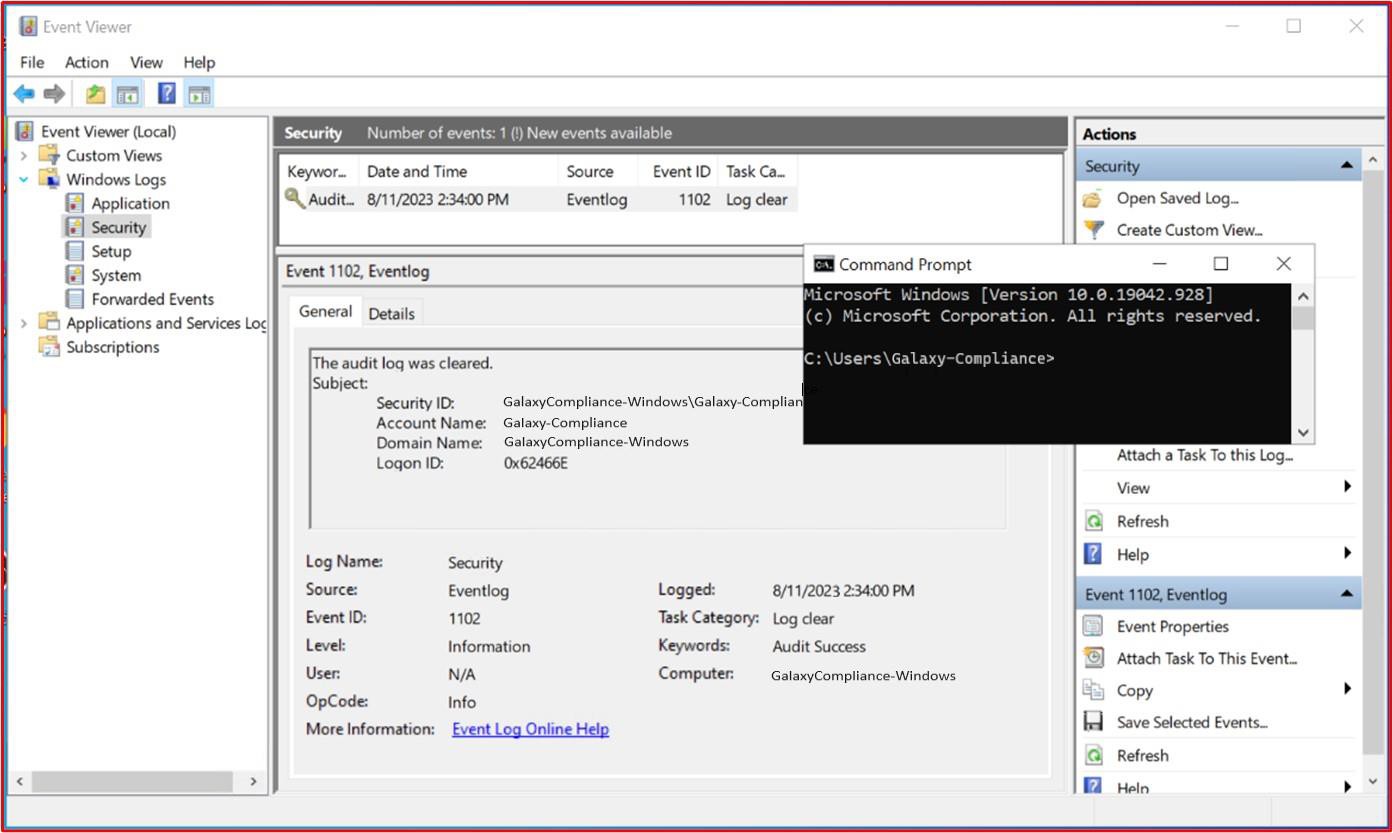
Notez que les exemples précédents ne sont pas des captures d’écran en plein écran. Vous devrez envoyer des captures d’écran en plein écran avec n’importe quelle URL, l’utilisateur connecté et l’horodatage et la date pour l’examen des preuves. Si vous êtes un utilisateur Linux, vous pouvez le faire via l’invite de commandes.
Contrôle n° 18
Fournissez la preuve qu’un minimum de 30 jours de données de journalisation des événements de sécurité est disponible immédiatement, avec 90 jours de journaux d’événements de sécurité conservés.
Intention : journalisation des événements
Parfois, il y a un intervalle de temps entre un événement de compromission ou de sécurité et une organisation qui l’identifie. L’objectif de ce contrôle est de s’assurer que l’organisation a accès aux données d’événements historiques pour faciliter la réponse aux incidents et tout travail d’investigation judiciaire qui peut être nécessaire. S’assurer que l’organisation conserve au moins 30 jours de données de journalisation des événements de sécurité qui sont immédiatement disponibles pour analyse afin de faciliter l’investigation et la réponse rapides aux incidents de sécurité. En outre, un total de 90 jours de journaux des événements de sécurité est conservé pour permettre une analyse approfondie.
Recommandations : journalisation des événements
La preuve consiste généralement à afficher les paramètres de configuration de la solution de journalisation centralisée, montrant la durée de conservation des données. Les données de journalisation des événements de sécurité d’une durée de 30 jours doivent être immédiatement disponibles dans la solution. Toutefois, lorsque les données sont archivées, vous devez démontrer que 90 jours sont disponibles. Cela peut être en affichant les dossiers d’archivage avec les dates des données exportées.
Exemple de preuve : journalisation des événements
Suite à l’exemple précédent dans le contrôle 17 où un espace de travail Log Analytics centralisé est utilisé pour stocker tous les journaux générés par les ressources cloud, vous pouvez observer ci-dessous que les journaux sont stockés dans des tables individuelles pour chaque catégorie de journal. En outre, la rétention interactive pour toutes les tables est de 90 jours.
La capture d’écran suivante fournit des preuves supplémentaires illustrant les paramètres de configuration pour la période de rétention de l’espace de travail Log Analytics.
Exemple de preuve
Les captures d’écran suivantes montrent que 30 jours de journaux sont disponibles dans AlienVault.
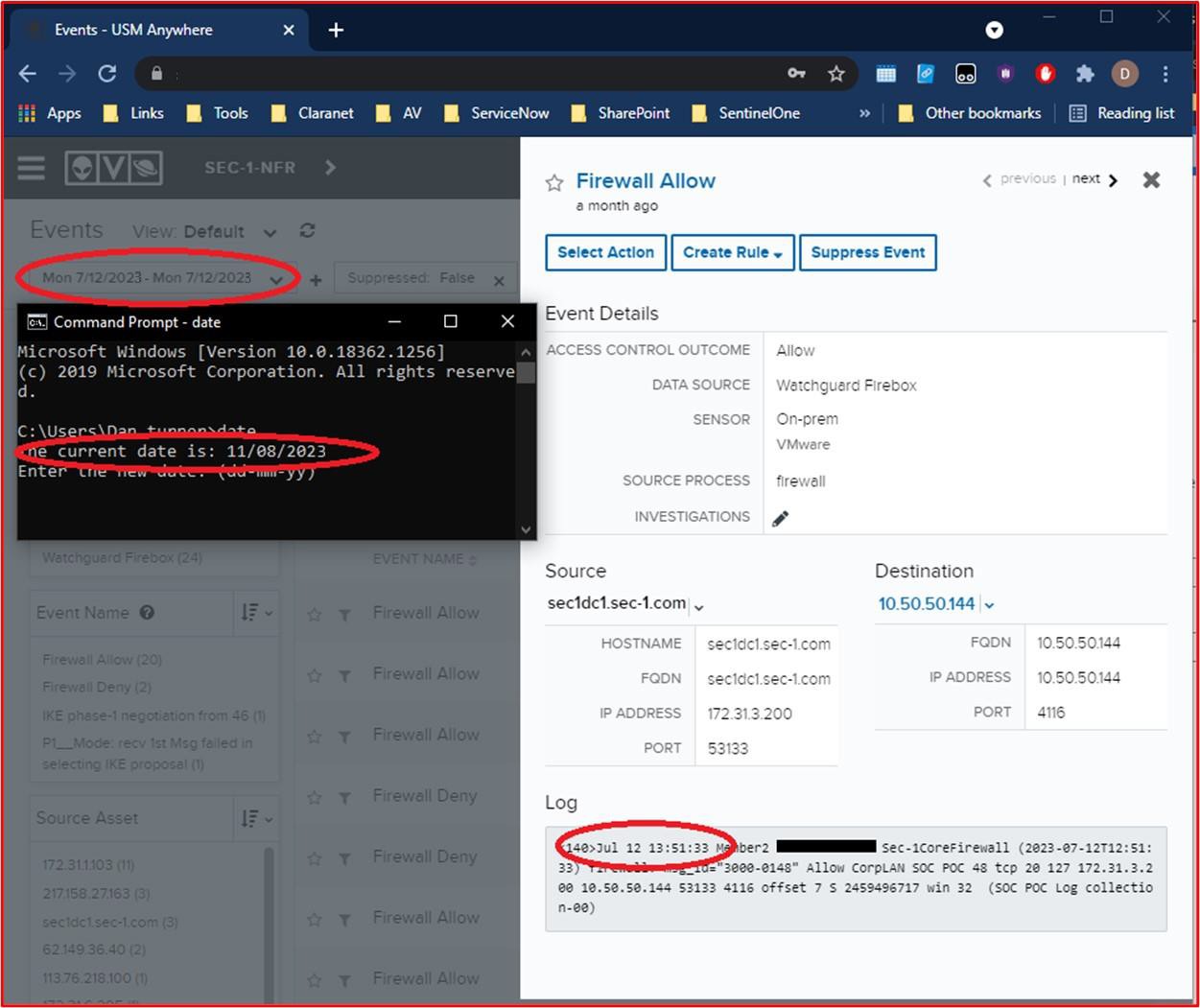
Remarque : Étant donné qu’il s’agit d’un document public, le numéro de série du pare-feu a été rédigé. Toutefois, les éditeurs de logiciels indépendants devront soumettre ces informations sans rédaction, sauf s’ils contiennent des informations d’identification personnelle (PII) qui doivent être divulguées à leur analyste.
Cette capture d’écran suivante montre que les journaux sont disponibles en montrant un extrait de journal remontant à cinq mois.
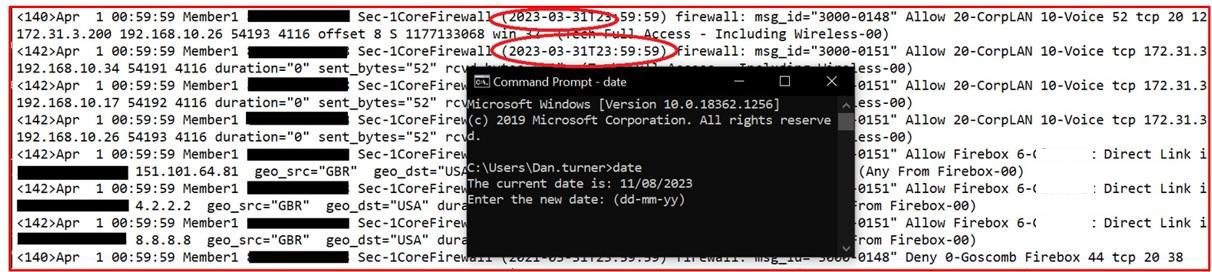
Remarque : Étant donné qu’il s’agit d’un document public, les adresses IP publiques ont été rédigées. Toutefois, les éditeurs de logiciels indépendants devront soumettre ces informations sans rédaction, sauf si elles contiennent des informations d’identification personnelle (PII) qu’ils doivent d’abord discuter avec leur analyste.
Remarque : Les exemples précédents ne sont pas des captures d’écran en plein écran. Vous devez envoyer des captures d’écran en plein écran avec n’importe quelle URL, l’utilisateur connecté et l’horodatage pour l’examen des preuves. Si vous êtes un utilisateur Linux, vous pouvez le faire via l’invite de commandes.
Exemple de preuve
La capture d’écran suivante montre que les événements de journal sont conservés pendant 30 jours en direct et 90 jours dans le stockage à froid dans Azure.
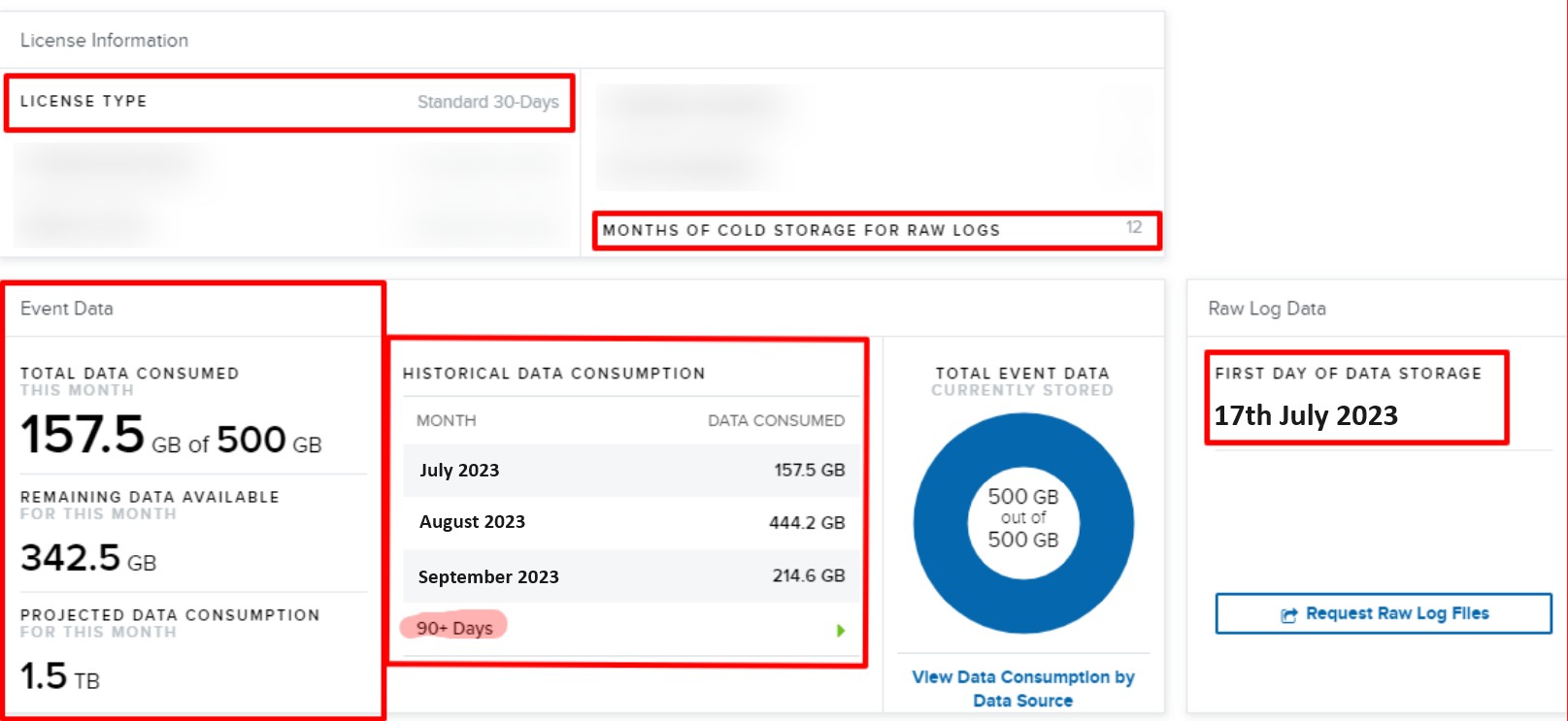
Remarque : en plus des paramètres de configuration illustrant la conservation configurée, un exemple de journaux de la période de 90 jours est fourni pour valider que les journaux d’activité sont conservés pendant 90 jours.
Remarque : ces exemples ne sont pas des captures d’écran en plein écran. Vous devrez envoyer des captures d’écran en plein écran avec n’importe quelle URL, l’utilisateur connecté et l’horodatage pour l’examen des preuves. Si vous êtes un utilisateur Linux, vous pouvez le faire via l’invite de commandes.
Contrôle n° 19
Fournissez des preuves démontrant que :
Les journaux sont examinés régulièrement et tous les événements/anomalies de sécurité potentiels identifiés pendant le processus de révision sont examinés et traités.
Intention : journalisation des événements
L’objectif de ce contrôle est de s’assurer que des révisions périodiques des journaux sont effectuées. Cela est important pour identifier les anomalies qui peuvent ne pas être détectées par les scripts/requêtes d’alerte configurés pour fournir des alertes d’événement de sécurité. En outre, toutes les anomalies identifiées lors des révisions de journal sont examinées, et une correction ou une action appropriée est effectuée. Cela implique généralement un processus de triage pour déterminer si les anomalies nécessitent une action, puis il peut être nécessaire d’appeler le processus de réponse aux incidents.
Recommandations : journalisation des événements
La preuve serait fournie par des captures d’écran, montrant que des révisions de journal sont effectuées. Il peut s’agir de formulaires remplis chaque jour ou d’un ticket JIRA ou DevOps avec
commentaires pertinents affichés pour montrer que cette opération est effectuée. Si des anomalies sont signalées, cela peut être documenté dans ce même ticket pour démontrer que les anomalies identifiées dans le cadre de la révision du journal font l’objet d’un suivi, puis détaillent les activités qui ont été effectuées par la suite. Cela peut inviter un ticket JIRA spécifique à être généré pour suivre toutes les activités en cours, ou il peut simplement être documenté dans le ticket de révision du journal. Si une action de réponse aux incidents est nécessaire, celle-ci doit être documentée dans le cadre du processus de réponse aux incidents et des preuves doivent être fournies pour le démontrer.
Exemple de preuve : journalisation des événements
Cette première capture d’écran identifie où un utilisateur a été ajouté au groupe « Administrateurs du domaine ».

Cette capture d’écran suivante identifie où plusieurs tentatives d’ouverture de session ayant échoué sont suivies d’une connexion réussie qui peut mettre en évidence une attaque par force brute réussie.

Cette capture d’écran finale identifie où une modification de stratégie de mot de passe s’est produite pour définir la stratégie, de sorte que les mots de passe de compte n’expirent pas.

Cette capture d’écran suivante montre qu’un ticket est automatiquement déclenché dans l’outil ServiceNow du SOC, ce qui déclenche la règle précédente ci-dessus.
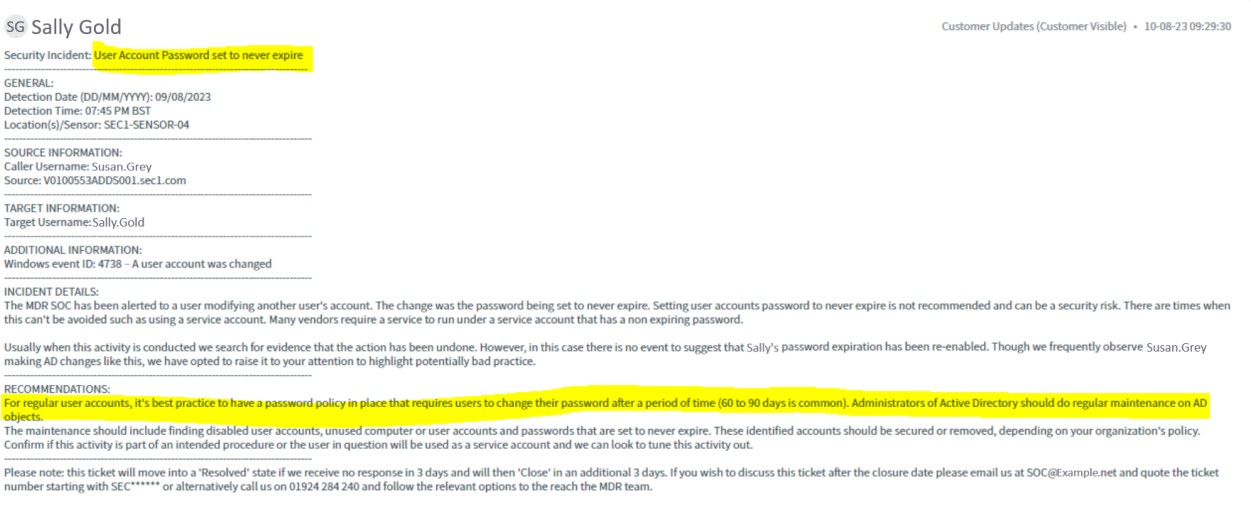
Remarque : ces exemples ne sont pas des captures d’écran en plein écran. Vous devrez envoyer des captures d’écran en plein écran avec n’importe quelle URL, l’utilisateur connecté et l’horodatage pour l’examen des preuves. Si vous êtes un utilisateur Linux, vous pouvez le faire via l’invite de commandes.
Contrôle n° 20
Fournissez des preuves démontrant que :
Les règles d’alerte sont configurées de sorte que les alertes soient déclenchées à des fins d’investigation pour les événements de sécurité suivants, le cas échéant :
Création/modifications de compte privilégié.
Activités ou opérations privilégiées/à haut risque.
Événements de programmes malveillants.
Falsification du journal des événements.
Événements IDPS/WAF (si configurés).
Intention : alertes
Il s’agit de certains types d’événements de sécurité qui peuvent mettre en évidence un événement de sécurité qui peut indiquer une violation de l’environnement et/ou une violation de données.
Ce sous-point permet de s’assurer que les règles d’alerte sont spécifiquement configurées pour déclencher des investigations lors de la création ou de la modification de comptes privilégiés. En cas de création ou de modification de compte privilégié, les journaux doivent être générés et des alertes doivent être déclenchées chaque fois qu’un nouveau compte privilégié est créé ou que les autorisations de compte privilégié existantes sont modifiées. Cela permet de suivre les activités non autorisées ou suspectes.
Ce sous-point vise à définir des règles d’alerte pour informer le personnel approprié en cas d’activités ou d’opérations privilégiées ou à haut risque. Pour les activités ou opérations privilégiées ou à haut risque, les alertes doivent être configurées pour avertir le personnel approprié lorsque de telles activités sont lancées. Cela peut inclure des modifications apportées aux règles de pare-feu, aux transferts de données ou à l’accès aux fichiers sensibles.
L’objectif de ce sous-point est d’imposer la configuration des règles d’alerte déclenchées par des événements liés aux programmes malveillants. Les événements de programmes malveillants doivent non seulement être enregistrés, mais doivent également déclencher une alerte immédiate à des fins d’investigation. Ces alertes doivent être conçues pour inclure des détails tels que l’origine, la nature des programmes malveillants et les composants système affectés afin d’accélérer le temps de réponse.
Ce sous-point est conçu pour garantir que toute falsification des journaux d’événements déclenche une alerte immédiate pour investigation. En ce qui concerne la falsification du journal des événements, le système doit être configuré pour déclencher des alertes en cas de détection d’un accès non autorisé aux journaux ou de modifications de journaux. Cela garantit l’intégrité des journaux des événements, qui sont essentiels pour l’analyse d’investigation et les audits de conformité.
Ce sous-point vise à garantir que, si les systèmes de détection et de prévention des intrusions (IDPS) ou les pare-feu d’applications web (WAF) sont configurés, ils sont configurés pour déclencher des alertes à des fins d’investigation. Si les systèmes de détection et de prévention des intrusions (IDPS) ou les pare-feu d’applications web (WAF) sont configurés, ils doivent également être configurés pour déclencher des alertes en cas d’activités suspectes telles que des échecs de connexion répétés, des tentatives d’injection de code SQL ou des modèles suggérant une attaque par déni de service.
Recommandations : alertes
Les preuves doivent être fournies au moyen de captures d’écran de la configuration des alertes ET de la preuve des alertes reçues. Les captures d’écran de configuration doivent montrer la logique qui déclenche les alertes et la façon dont les alertes sont envoyées. Les alertes peuvent être envoyées par SMS, e-mail, canaux Teams, canaux Slack, etc.
Exemple de preuve : alertes
La capture d’écran suivante montre un exemple d’alertes configurées dans Azure. Nous pouvons observer sur la première capture d’écran qu’une alerte a été déclenchée lorsque la machine virtuelle a été arrêtée et libérée. Notez qu’il s’agit d’un exemple d’alertes configurées dans Azure et que la preuve est fournie pour démontrer que des alertes sont générées pour tous les événements spécifiés dans la description du contrôle.
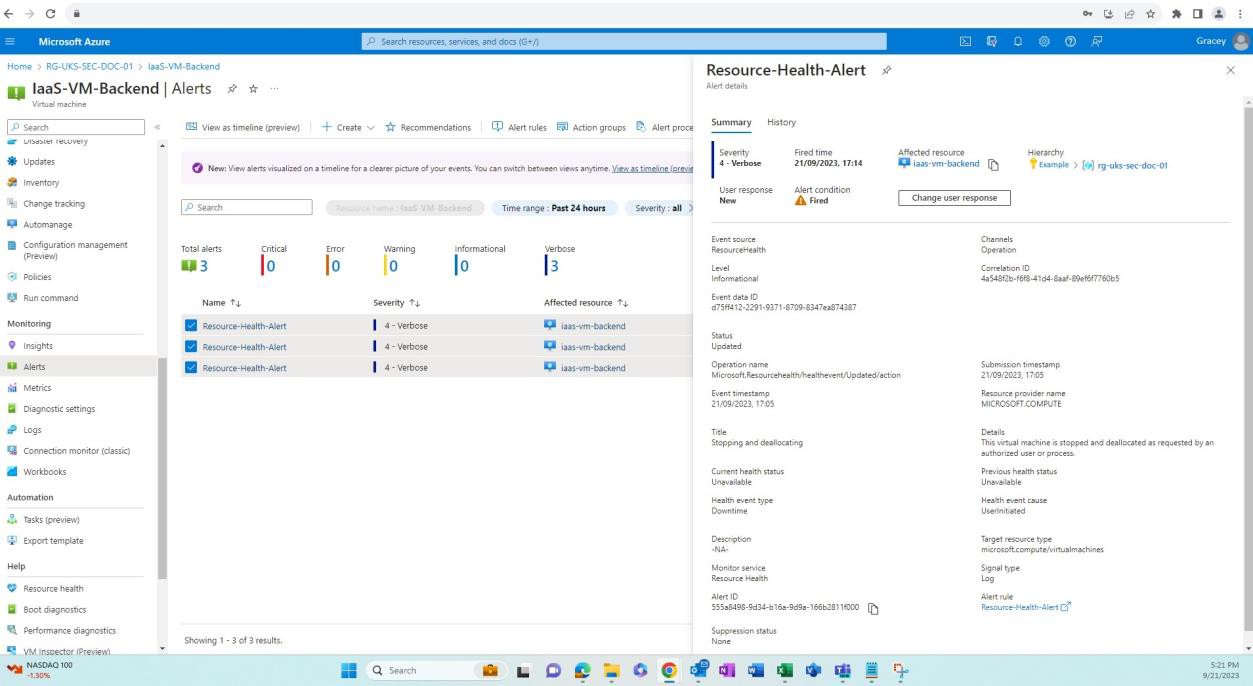
La capture d’écran suivante montre les alertes configurées pour toutes les actions administratives effectuées au niveau d’Azure App Service et au niveau du groupe de ressources Azure.
Exemple de preuve
Contoso utilise un centre d’opérations de sécurité (SOC) tiers fourni par Contoso Security. L’exemple montre que les alertes dans AlienVault, utilisées par le SOC, sont configurées pour envoyer une alerte à un membre de l’équipe SOC, Sally Gold chez Contoso Security.
Cette capture d’écran suivante montre une alerte reçue par Sally.
Remarque : ces exemples ne sont pas des captures d’écran en plein écran. Vous devrez envoyer des captures d’écran en plein écran avec n’importe quelle URL, l’utilisateur connecté et l’horodatage pour l’examen des preuves. Si vous êtes un utilisateur Linux, vous pouvez le faire via l’invite de commandes.
Gestion des risques liés à la sécurité des informations
La gestion des risques liés à la sécurité des informations est une activité importante que toutes les organisations doivent effectuer au moins une fois par an. Les organisations doivent comprendre leurs risques pour atténuer efficacement les menaces. Sans une gestion efficace des risques, les organisations peuvent implémenter des ressources de sécurité dans des domaines qu’elles jugent importants, lorsque d’autres menaces peuvent être plus probables. Une gestion efficace des risques aidera les organisations à se concentrer sur les risques qui représentent le plus de menaces pour l’entreprise. Cela devrait être effectué chaque année, car le paysage de la sécurité est en constante évolution et, par conséquent, les menaces et les risques peuvent changer au fil du temps. Par exemple, pendant le récent verrouillage covid-19, il y a eu une forte augmentation des attaques par hameçonnage avec le passage au travail à distance.
Contrôle No. 21
Fournir la preuve qu’une politique ou un processus officiel de gestion des risques liés à la sécurité de l’information ratifié est documenté et établi.
Intention : gestion des risques
Un processus robuste de gestion des risques liés à la sécurité des informations est important pour aider les organisations à gérer efficacement les risques. Cela aidera les organisations à planifier des atténuations efficaces contre les menaces pour l’environnement. L’objectif de ce contrôle est de confirmer que l’organisation a officiellement ratifié une politique ou un processus de gestion des risques liés à la sécurité de l’information qui est documenté de manière complète. La stratégie doit décrire la façon dont l’organisation identifie, évalue et gère les risques de sécurité des informations. Il doit inclure les rôles et responsabilités, les méthodologies d’évaluation des risques, les critères d’acceptation des risques et les procédures d’atténuation des risques.
Remarque : L’évaluation des risques doit se concentrer sur les risques liés à la sécurité de l’information, et pas seulement sur les risques généraux de l’entreprise.
Recommandations : gestion des risques
Le processus de gestion de l’évaluation des risques officiellement documenté doit être fourni.
Exemple de preuve : gestion des risques
La preuve suivante est une capture d’écran d’une partie du processus d’évaluation des risques de Contoso.
Remarque : Les éditeurs de logiciels indépendants doivent partager la documentation réelle sur la stratégie/procédure de prise en charge et pas simplement fournir une capture d’écran.
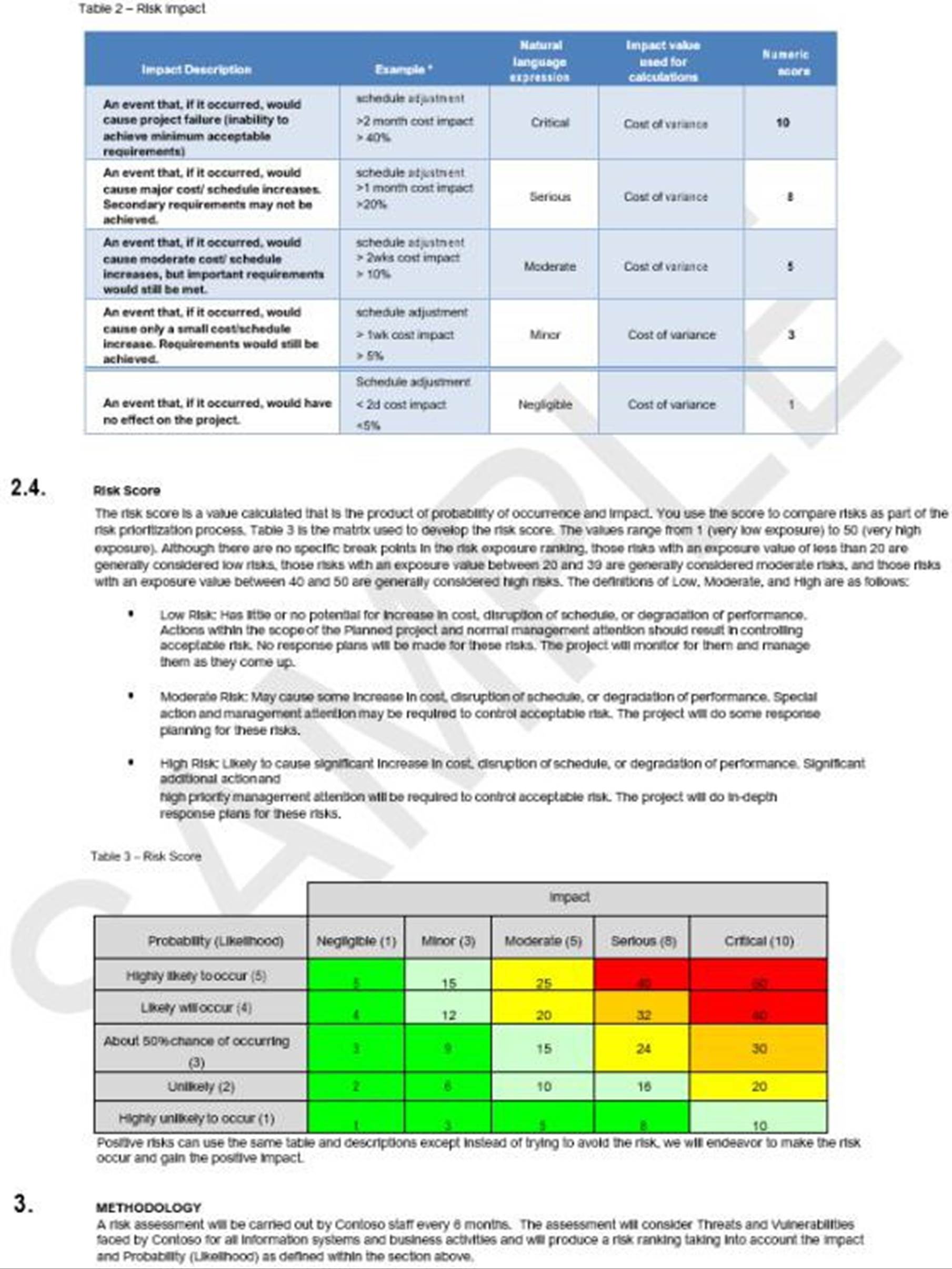
Remarque : Les éditeurs de logiciels indépendants doivent partager la documentation réelle sur la stratégie/procédure de prise en charge et pas simplement fournir une capture d’écran.
Contrôle n° 22
Fournissez des preuves démontrant que :
- Une évaluation formelle des risques liés à la sécurité des informations à l’échelle de l’entreprise est effectuée au moins une fois par an.
OU Pour l’analyse des risques ciblés :
Une analyse des risques ciblées est documentée et effectuée :
Au moins tous les 12 mois pour chaque instance où un contrôle traditionnel ou une meilleure pratique de l’industrie n’est pas en place.
Lorsqu’une limitation technologique ou de conception crée un risque d’introduire une vulnérabilité dans l’environnement ou met les utilisateurs et les données en danger.
En cas de suspicion ou de confirmation de compromis.
Intention : évaluation annuelle
Les menaces de sécurité changent constamment en fonction de l’évolution de l’environnement, des modifications apportées aux services proposés, des influences externes, de l’évolution du paysage des menaces de sécurité, etc. Les organisations doivent suivre le processus d’évaluation des risques au moins une fois par an. Il est recommandé que ce processus soit également effectué en cas de changements importants, car les menaces peuvent changer.
L’objectif de ce contrôle est de s’assurer que l’organisation effectue une évaluation formelle des risques liés à la sécurité des informations à l’échelle de l’entreprise au moins une fois par an et/ou une analyse ciblée des risques pendant les modifications du système ou en cas d’incidents, de découverte de vulnérabilités, de changements d’infrastructure, etc. Cette évaluation doit englober l’ensemble des ressources, processus et données de l’organisation, afin d’identifier et d’évaluer les vulnérabilités et les menaces potentielles.
Pour l’analyse de risque ciblée, ce contrôle met l’accent sur la nécessité d’effectuer une analyse des risques sur des scénarios spécifiques, ce qui est axé sur une étendue plus étroite, comme une ressource, une menace, un système ou un contrôle. L’objectif est de s’assurer que les organisations évaluent et identifient en permanence les risques introduits par les écarts par rapport aux meilleures pratiques de sécurité ou aux limitations de conception du système. En effectuant des analyses de risques ciblées au moins une fois par an en cas de manque de contrôles, lorsque les contraintes technologiques créent des vulnérabilités et en réponse à des incidents de sécurité suspects ou confirmés, l’organisation peut identifier les faiblesses et les expositions. Cela permet de prendre des décisions éclairées basées sur les risques sur la hiérarchisation des efforts de correction et la mise en œuvre de contrôles de compensation pour minimiser la probabilité et l’impact de l’exploitation. L’objectif est de fournir une diligence raisonnable, des conseils et des preuves que les lacunes connues sont traitées de manière consciente des risques plutôt que d’être ignorées indéfiniment. L’exécution de ces évaluations des risques ciblées démontre l’engagement de l’organisation à améliorer de manière proactive la posture de sécurité au fil du temps.
Recommandations : évaluation annuelle
La preuve peut être par le biais d’un suivi de version ou d’une preuve datée. Il convient de fournir des éléments de preuve indiquant la sortie de l’évaluation des risques liés à la sécurité de l’information et NON les dates du processus d’évaluation des risques liés à la sécurité de l’information proprement dit.
Exemple de preuve : évaluation annuelle
La capture d’écran suivante montre une réunion d’évaluation des risques planifiée tous les six mois.
Ces deux captures d’écran suivantes montrent un exemple de minutes de réunion à partir de deux évaluations des risques. On s’attend à ce qu’un rapport/procès-verbal de réunion, ou un rapport de l’évaluation des risques soit fourni.

Remarque : cette capture d’écran montre un document de stratégie/processus. Il est prévu que les éditeurs de logiciels indépendants partagent la documentation réelle sur la stratégie/procédure de prise en charge et ne fournissent pas seulement une capture d’écran.
Remarque : cette capture d’écran montre un document de stratégie/processus. Les éditeurs de logiciels indépendants doivent partager la documentation réelle sur la stratégie/procédure de prise en charge et pas simplement fournir une capture d’écran.
Contrôle No. 23
Vérifiez que l’évaluation des risques liés à la sécurité des informations inclut :
Composant système ou ressource affecté.
Menaces et vulnérabilités, ou équivalent.
Matrices d’impact et de probabilité ou équivalent.
La création d’un registre des risques/plan de traitement des risques.
Intention : évaluation des risques
L’objectif est que l’évaluation des risques inclut des composants système et des ressources, car elle permet d’identifier les ressources informatiques les plus critiques et leur valeur. En identifiant et en analysant les menaces potentielles pour l’entreprise, l’organisation peut d’abord se concentrer sur les risques qui ont l’impact potentiel le plus élevé et la probabilité la plus élevée. En comprenant l’impact potentiel sur l’infrastructure informatique et les coûts associés, vous pouvez aider la direction à prendre des décisions éclairées sur le budget, les stratégies, les procédures et bien plus encore. Voici la liste des composants système ou des ressources qui peuvent être inclus dans l’évaluation des risques de sécurité :
Serveurs
Bases de données
Applications
Réseaux
Appareils de stockage de données
Personnes
Pour gérer efficacement les risques liés à la sécurité des informations, les organisations doivent effectuer des évaluations des risques par rapport aux menaces pour l’environnement et les données, ainsi qu’aux vulnérabilités potentielles qui peuvent être présentes. Cela aidera les organisations à identifier la myriade de menaces et de vulnérabilités qui peuvent présenter un risque important. Les évaluations des risques doivent documenter les évaluations d’impact et de probabilité, qui peuvent être utilisées pour identifier la valeur du risque. Cela peut être utilisé pour hiérarchiser le traitement à risque et aider à réduire la valeur globale du risque. Les évaluations des risques doivent faire l’objet d’un suivi approprié pour fournir un enregistrement de l’un des quatre traitements à risque appliqués. Ces traitements à risque sont les suivants :
Éviter/Arrêter : l’entreprise peut déterminer que le coût de la gestion du risque est supérieur au chiffre d’affaires généré par le service. L’entreprise peut donc choisir d’arrêter d’effectuer le service.
Transfert/Partage : l’entreprise peut choisir de transférer le risque à un tiers en déplaçant le traitement vers un tiers.
Accepter/Tolérer/Conserver : l’entreprise peut décider que le risque est acceptable. Cela dépend beaucoup de l’appétit des entreprises au risque et peut varier selon l’organisation.
Traiter/Atténuer/Modifier : l’entreprise décide d’implémenter des contrôles d’atténuation pour réduire le risque à un niveau acceptable.
Recommandations : évaluation des risques
Les éléments de preuve doivent être fournis non seulement au moyen du processus d’évaluation des risques en matière de sécurité de l’information déjà fourni, mais également de la sortie de l’évaluation des risques (au moyen d’un registre des risques/plan de traitement des risques) pour démontrer que le processus d’évaluation des risques est effectué correctement. Le registre des risques doit inclure les risques, les vulnérabilités, l’impact et les évaluations de probabilité.
Exemple de preuve : évaluation des risques
La capture d’écran suivante montre le registre des risques qui montre que les menaces et les vulnérabilités sont incluses. Il démontre également que l’impact et les probabilités sont inclus.
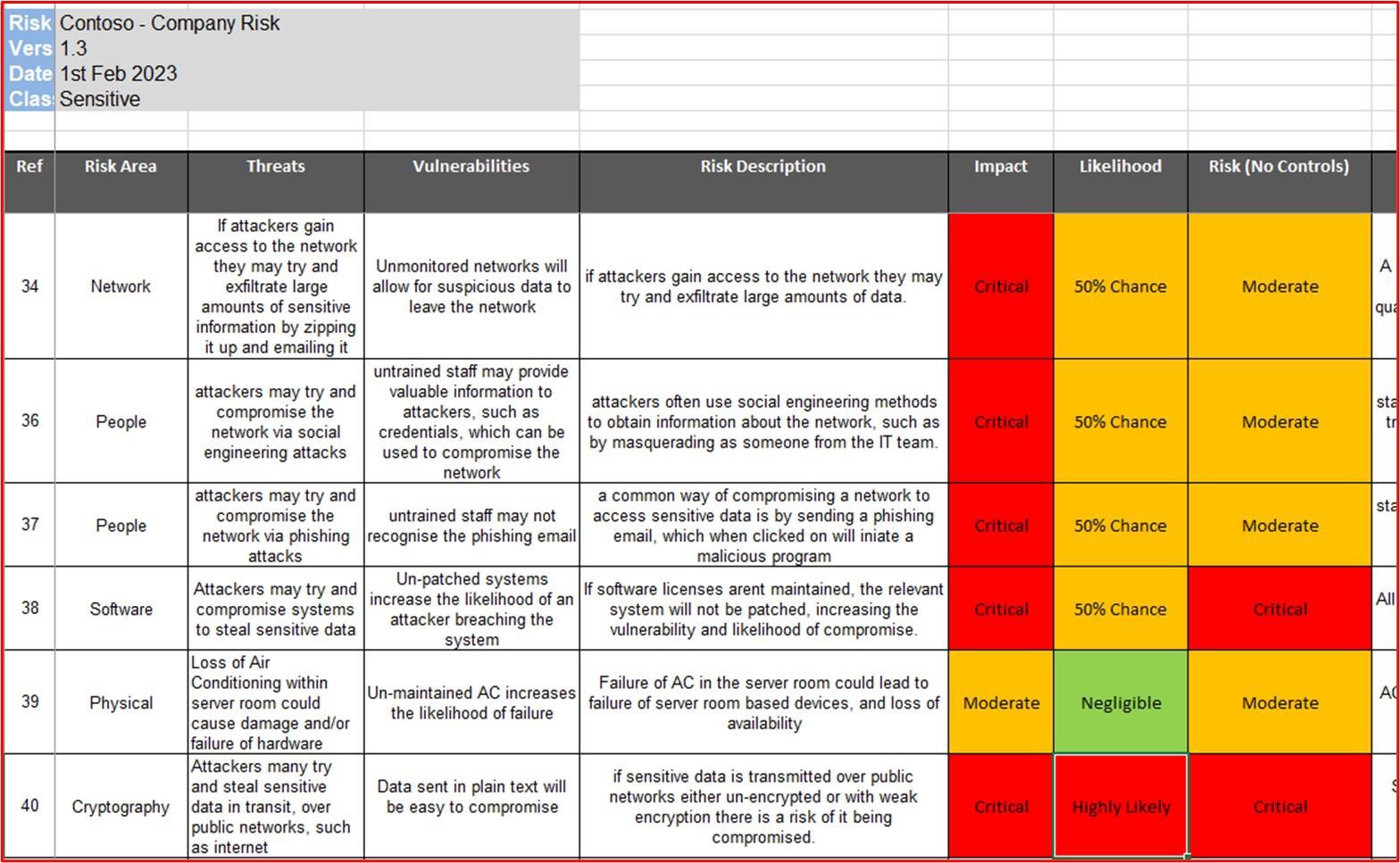
Remarque : la documentation complète sur l’évaluation des risques doit être fournie au lieu d’une capture d’écran. La capture d’écran suivante illustre un plan de traitement des risques.
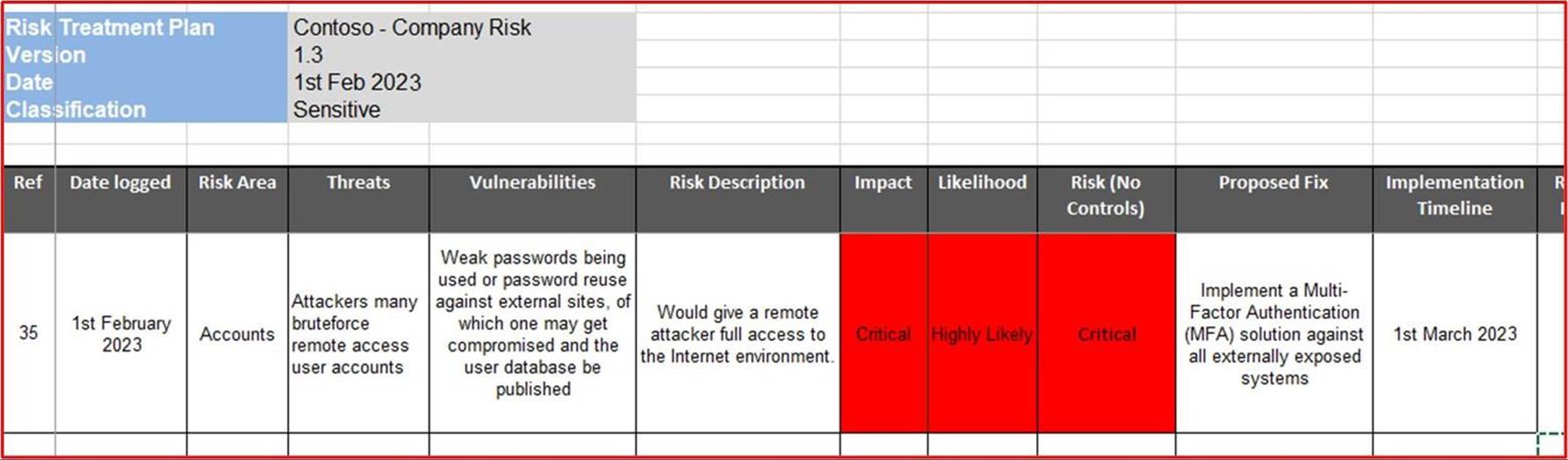
Contrôle n° 24
Fournissez la preuve que :
Vous (ISV) avez mis en place des processus de gestion des risques qui évaluent et gèrent les risques associés aux fournisseurs et aux partenaires commerciaux.
Vous (ISV) pouvez identifier et évaluer les modifications et les risques susceptibles d’avoir un impact sur votre système de contrôles internes.
Intention : fournisseurs et partenaires
La gestion des risques des fournisseurs est la pratique qui consiste à évaluer les postures de risque des partenaires commerciaux, des fournisseurs ou des fournisseurs tiers avant l’établissement d’une relation commerciale et pendant toute la durée de la relation. En gérant les risques des fournisseurs, les organisations peuvent éviter les interruptions de la continuité de l’activité, prévenir les impacts financiers, protéger leur réputation, se conformer aux réglementations et identifier et réduire les risques associés à la collaboration avec un fournisseur. Pour gérer efficacement les risques liés aux fournisseurs, il est important de mettre en place des processus qui incluent des évaluations de diligence raisonnable, des obligations contractuelles liées à la sécurité et une surveillance continue de la conformité des fournisseurs.
Recommandations : fournisseurs et partenaires
Des preuves peuvent être fournies pour démontrer le processus d’évaluation des risques des fournisseurs, comme la documentation établie d’approvisionnement et de vérification, des listes de contrôle et des questionnaires pour l’intégration de nouveaux fournisseurs et sous-traitants, des évaluations effectuées, des vérifications de conformité, etc.
Exemple de preuve : fournisseurs et partenaires
La capture d’écran suivante montre que le processus d’intégration et de vérification du fournisseur est conservé dans Confluence en tant que tâche JIRA. Pour chaque nouveau fournisseur, une évaluation initiale des risques est effectuée afin d’examiner la posture de conformité. Pendant le processus d’approvisionnement, un questionnaire d’évaluation des risques est rempli et le risque global est déterminé en fonction du niveau d’accès aux systèmes et aux données fournis au fournisseur.
La capture d’écran suivante montre le résultat de l’évaluation et le risque global identifié sur la base de l’examen initial.
Intention : contrôles internes
L’objectif de ce sous-point est de reconnaître et d’évaluer les changements et les risques susceptibles d’avoir un impact sur les systèmes de contrôle interne d’une organisation afin de s’assurer que les contrôles internes restent efficaces au fil du temps. À mesure que les opérations de l’entreprise changent, vos contrôles internes risquent de ne plus être efficaces. Les risques évoluent au fil du temps, et de nouveaux risques peuvent apparaître qui n’ont pas été pris en compte auparavant. En identifiant et en évaluant ces risques, vous pouvez vous assurer que vos contrôles internes sont conçus pour y remédier. Cela permet d’éviter les fraudes et les erreurs, de maintenir la continuité de l’activité et de garantir la conformité réglementaire.
Recommandations : contrôles internes
Des preuves peuvent être fournies, telles que les procès-verbaux de réunion d’examen et les rapports qui peuvent démontrer que le processus d’évaluation des risques du fournisseur est actualisé à une période définie pour s’assurer que les changements potentiels des fournisseurs sont pris en compte et évalués.
Exemple de preuve : contrôles internes
Les captures d’écran suivantes montrent qu’un examen de trois mois de la liste du fournisseur et de l’entrepreneur approuvé est effectué pour s’assurer que leurs normes de conformité et leur niveau de conformité sont cohérents avec l’évaluation initiale lors de l’intégration.
La première capture d’écran montre les instructions établies pour l’exécution de l’évaluation et le questionnaire sur les risques.
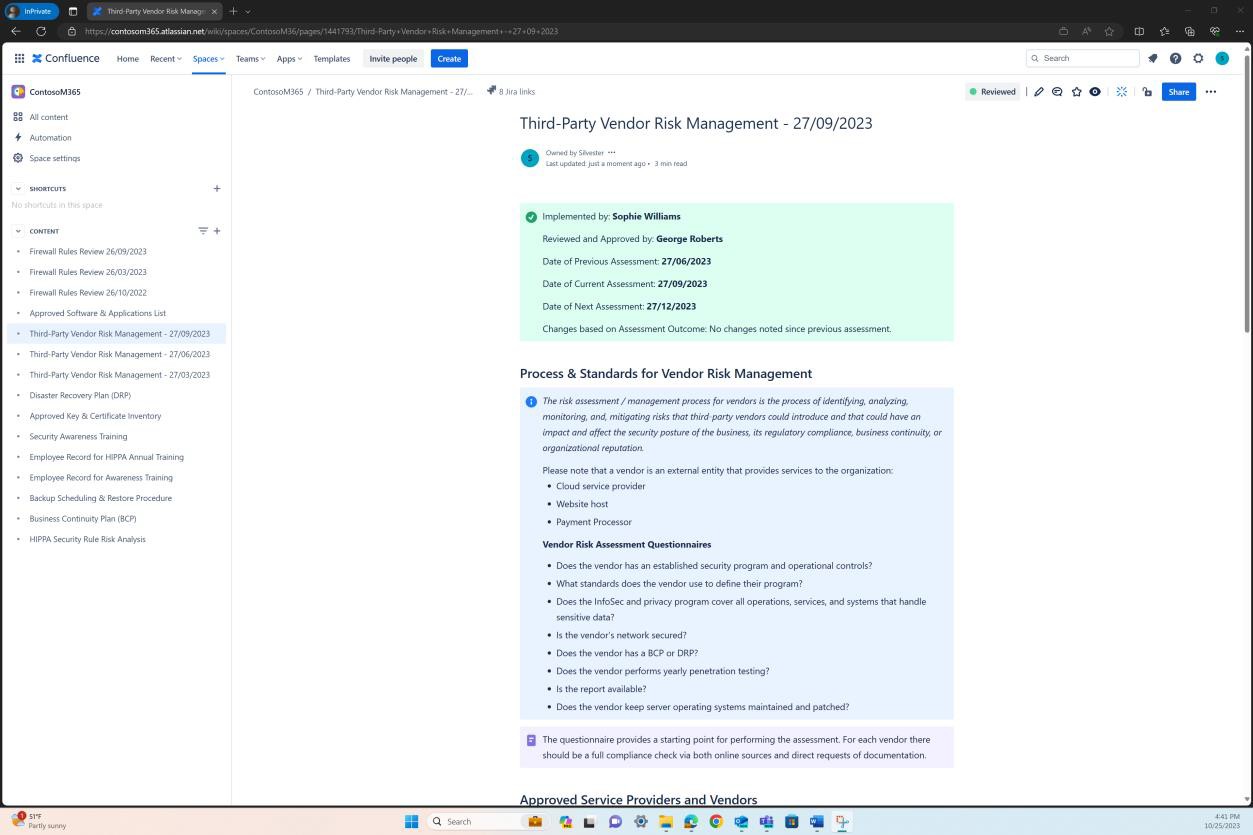
Les captures d’écran suivantes montrent la liste réelle des fournisseurs approuvés et leur niveau de conformité, l’évaluation effectuée, l’évaluateur, l’approbateur, etc. Notez qu’il s’agit simplement d’un exemple d’évaluation rudimentaire des risques des fournisseurs conçue pour fournir un scénario de base pour comprendre l’exigence de contrôle et pour montrer le format de la preuve attendue. En tant qu’éditeur de logiciels indépendant, vous devez fournir votre propre évaluation des risques liés aux fournisseurs, selon les besoins de votre organisation.
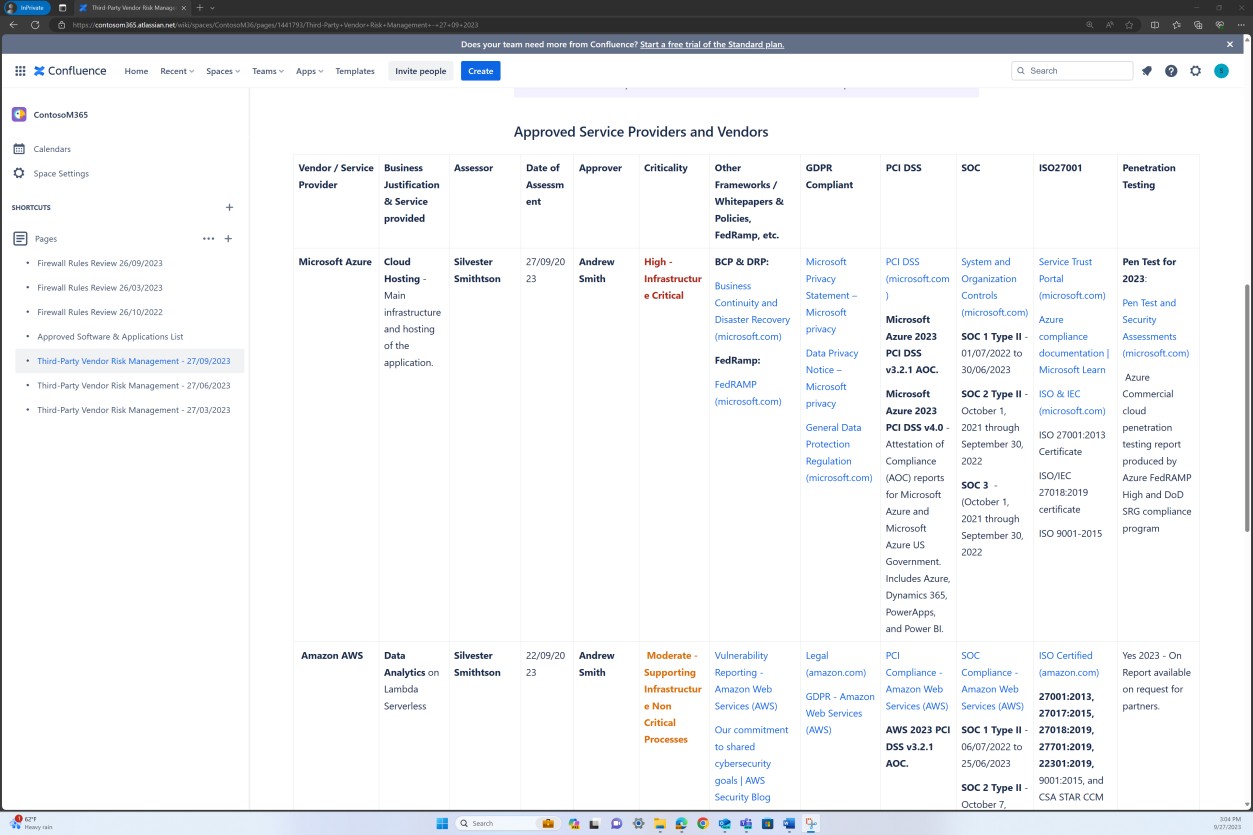
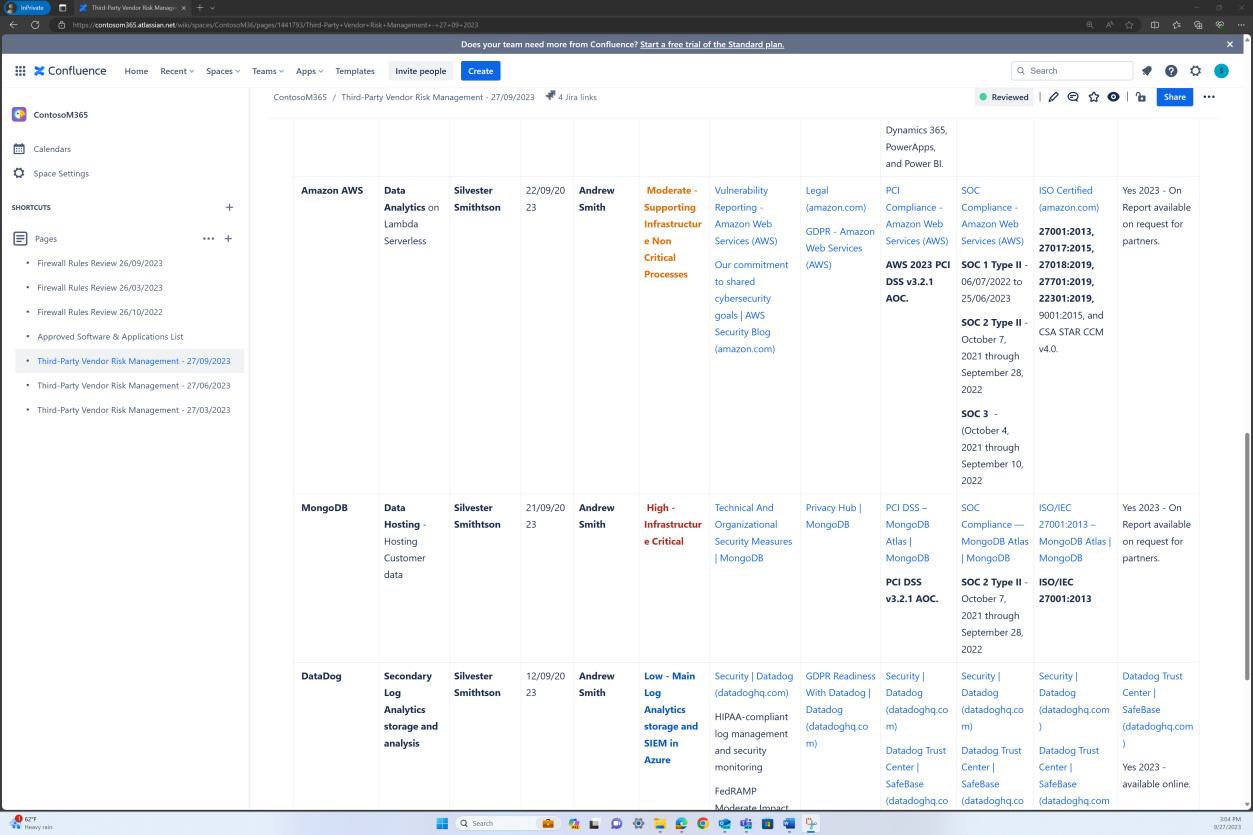
Réponse aux incidents de sécurité
La réponse aux incidents de sécurité est importante pour toutes les organisations, car cela peut réduire le temps passé par une organisation contenant un incident de sécurité et limiter le niveau d’exposition de l’organisation à l’exfiltration de données. En développant un plan complet et détaillé de réponse aux incidents de sécurité, cette exposition peut être réduite du moment de l’identification au moment de l’endiguement.
Un rapport d’IBM intitulé « Rapport sur le coût d’une violation de données 2020 » souligne qu’en moyenne, le temps nécessaire pour contenir une violation était de 73 jours. En outre, le même rapport identifie le plus grand économiseur de coûts pour les organisations qui ont subi une violation, a été la préparation à la réponse aux incidents, fournissant une moyenne de
2 000 000 $ d’économies. Les organisations doivent suivre les meilleures pratiques en matière de conformité de la sécurité à l’aide de frameworks standard du secteur tels que ISO 27001, NIST, SOC 2, PCI DSS, etc.
Contrôle n° 25
Veuillez fournir votre plan/procédure de réponse aux incidents de sécurité (IRP) ratifié décrivant la façon dont votre organisation répond aux incidents, montrant comment il est géré et qu’il inclut :
les détails de l’équipe de réponse aux incidents, y compris les informations de contact,
un plan de communication interne pendant l’incident et une communication externe avec les parties concernées telles que les principales parties prenantes, les marques de paiement et les acquéreurs, les organismes de réglementation (par exemple, 72 heures pour le RGPD), les autorités de surveillance, les administrateurs, les clients,
les étapes pour les activités telles que la classification des incidents, l’endiguement, l’atténuation, la récupération et le retour à des opérations métier normales en fonction du type d’incident.
Intention : Plan de réponse incedent (IRP)
L’objectif de ce contrôle est de s’assurer qu’un plan de réponse aux incidents (IRP) officiellement documenté est en place, qui inclut une équipe de réponse aux incidents désignée avec des rôles, des responsabilités et des informations de contact clairement documentés. L’IRP doit fournir une approche structurée pour la gestion des incidents de sécurité, de la détection à la résolution, y compris la classification de la nature de l’incident, la conservation de l’impact immédiat, l’atténuation des risques, la récupération après l’incident et la restauration des opérations normales de l’entreprise. Chaque étape doit être bien définie, avec des protocoles clairs, pour garantir que les actions entreprises sont alignées sur les stratégies de gestion des risques et les obligations de conformité de l’organisation.
La spécification détaillée de l’équipe de réponse aux incidents dans l’IRP garantit que chaque membre de l’équipe comprend son rôle dans la gestion de l’incident, ce qui permet une réponse coordonnée et efficace. En mettant en place un IRP, une organisation peut gérer plus efficacement une réponse aux incidents de sécurité, ce qui peut finalement limiter l’exposition à la perte de données de l’organisation et réduire les coûts de la compromission.
Les organisations peuvent avoir des obligations de notification de violation en fonction du ou des pays dans lesquels elles opèrent (par exemple, le Règlement général sur la protection des données RGPD) ou en fonction des fonctionnalités proposées (par exemple, PCI DSS si les données de paiement sont traitées). L’absence de notification en temps voulu peut avoir de graves conséquences ; par conséquent, pour s’assurer que les obligations de notification sont respectées, les plans de réponse aux incidents doivent inclure un processus de communication incluant la communication avec toutes les parties prenantes, les processus de communication avec les médias et qui peuvent et ne peuvent pas parler aux médias.
Recommandations : contrôles internes
Fournissez la version complète du plan/procédure de réponse aux incidents. Le plan de réponse aux incidents doit inclure une section couvrant le processus de gestion des incidents, de l’identification à la résolution, ainsi qu’un processus de communication documenté.
Exemple de preuve : contrôles internes
La capture d’écran suivante montre le début du plan de réponse aux incidents de Contoso.
Remarque : Dans le cadre de votre soumission de preuve, vous devez fournir l’ensemble du plan de réponse aux incidents.

Exemple de preuve : contrôles internes
La capture d’écran suivante montre un extrait du plan de réponse aux incidents montrant le processus de communication.
Contrôle n° 26
Fournissez des éléments de preuve qui montrent que :
Tous les membres de l’équipe de réponse aux incidents ont reçu une formation annuelle qui leur permet de répondre aux incidents.
Intention : formation
Plus il faut de temps à une organisation pour contenir une compromission, plus le risque d’exfiltration de données est élevé, ce qui peut entraîner un volume plus important de données exfiltrées et plus le coût global de la compromission est élevé. Il est important que les équipes de réponse aux incidents de l’organisation soient équipées pour répondre aux incidents de sécurité en temps voulu. En effectuant une formation régulière et en effectuant des exercices de table, l’équipe est prête à gérer les incidents de sécurité rapidement et efficacement. Cette formation doit couvrir divers aspects tels que l’identification des menaces potentielles, les actions de réponse initiale, les procédures d’escalade et les stratégies d’atténuation à long terme.
La recommandation est d’effectuer à la fois une formation interne sur la réponse aux incidents pour l’équipe de réponse aux incidents ET d’effectuer des exercices de table réguliers, qui doivent être liés au risque de sécurité des informations
évaluation pour identifier les incidents de sécurité les plus susceptibles de se produire. L’exercice de table doit simuler des scénarios réels pour tester et affiner les capacités de l’équipe à réagir sous pression. Ce faisant, l’organisation peut s’assurer que son personnel sait comment gérer correctement une violation de sécurité ou une cyberattaque. Et l’équipe saura quelles étapes prendre pour contenir et examiner rapidement les incidents de sécurité les plus probables.
Recommandations : formation
Il convient de fournir des preuves qui démontrent que la formation a été effectuée au moyen du partage du contenu de la formation, et des enregistrements montrant qui y a assisté (ce qui doit inclure toute l’équipe de réponse aux incidents). Sinon, ou également, des enregistrements montrant qu’un exercice de table a été effectué. Tout cela doit avoir été effectué dans un délai de 12 mois à compter du moment où la preuve est soumise.
Exemple de preuve : formation
Contoso a effectué un exercice de table de réponse aux incidents à l’aide d’une société de sécurité externe. Voici un exemple du rapport généré dans le cadre de la société de conseil.

Remarque : le rapport complet doit être partagé. Cet exercice peut également être effectué en interne, car il n’existe aucune exigence Microsoft 365 pour que cela soit effectué par une société tierce.
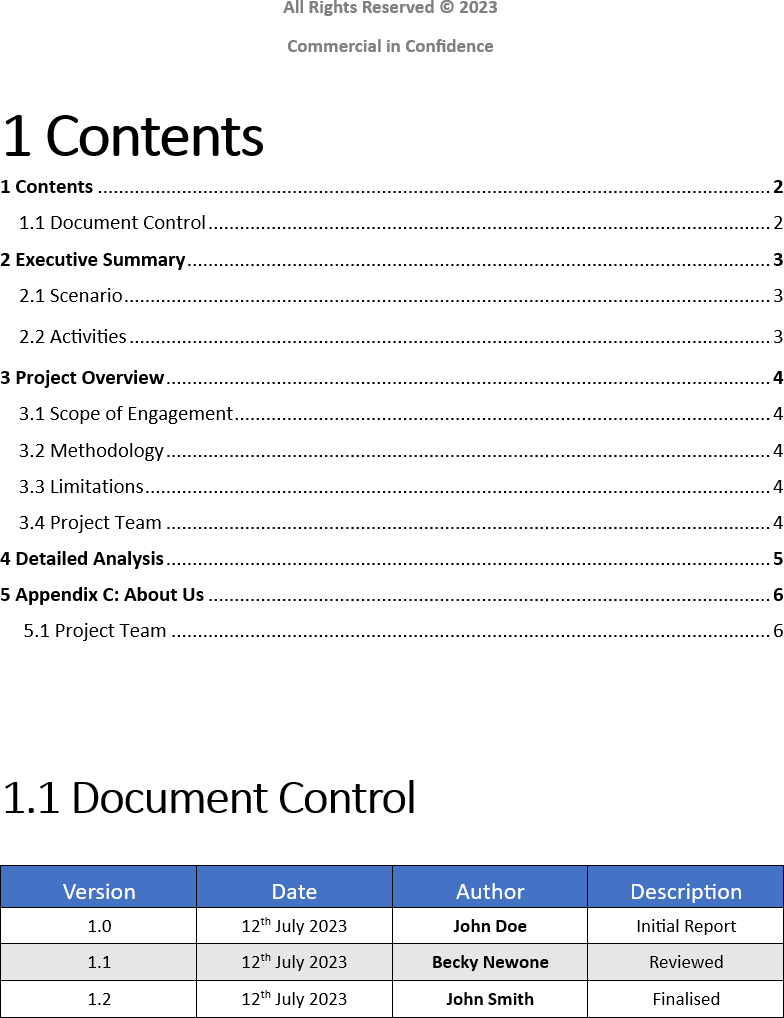
Remarque : le rapport complet doit être partagé. Cet exercice peut également être effectué en interne, car il n’existe aucune exigence Microsoft 365 pour que cela soit effectué par une société tierce.
Contrôle n° 27
Fournissez la preuve que :
La stratégie de réponse aux incidents et la documentation connexe sont examinées et mises à jour en fonction des éléments suivants :
leçons tirées d’un exercice de table
leçons tirées de la réponse à un incident
changements organisationnels
Intention : révisions de plan
Au fil du temps, le plan de réponse aux incidents doit évoluer en fonction des changements organisationnels ou des leçons apprises lors de l’adoption du plan. Les modifications apportées à l’environnement d’exploitation peuvent nécessiter des modifications du plan de réponse aux incidents, car les menaces peuvent changer, ou les exigences réglementaires peuvent changer. En outre, à mesure que des exercices de table et des réponses réelles aux incidents de sécurité sont effectués, cela peut souvent identifier les domaines du plan qui peuvent être améliorés. Cela doit être intégré au plan et l’objectif de ce contrôle est de s’assurer que ce processus est inclus. L’objectif de ce contrôle est d’imposer l’examen et la mise à jour de la stratégie de réponse aux incidents de l’organisation et de la documentation connexe basée sur trois déclencheurs distincts :
Une fois que les exercices simulés pour tester l’efficacité de sa stratégie de réponse aux incidents ont été effectués, les lacunes identifiées ou les domaines à améliorer doivent être immédiatement incorporés dans le plan de réponse aux incidents existant.
Un incident réel fournit des informations précieuses sur les forces et les faiblesses de la stratégie de réponse actuelle. Si un incident se produit, un examen post-incident doit être effectué pour capturer ces leçons, qui doivent ensuite être utilisées pour mettre à jour la stratégie et les procédures de réponse.
Tout changement important au sein de l’organisation, comme des fusions, des acquisitions ou des changements dans le personnel clé, doit déclencher un examen de la stratégie de réponse aux incidents. Ces changements organisationnels peuvent introduire de nouveaux risques ou modifier les risques existants, et le plan de réponse aux incidents doit être mis à jour en conséquence pour rester efficace.
Recommandations : révisions de plan
Cela est souvent démontré par l’examen des résultats des incidents de sécurité ou des exercices de table où les leçons apprises ont été identifiées et ont entraîné une mise à jour du plan de réponse aux incidents. Le plan doit conserver un journal des modifications, qui doit également référencer les modifications qui ont été implémentées en fonction des leçons apprises ou des changements organisationnels.
Exemple de preuve : révisions de plan
Les captures d’écran suivantes proviennent du plan de réponse aux incidents fourni, qui inclut une section sur la mise à jour en fonction des leçons apprises et/ou des modifications apportées à l’organisation.



Remarque : Ces exemples ne sont pas des captures d’écran en plein écran. Vous devez envoyer des captures d’écran en plein écran avec n’importe quelle URL, utilisateur connecté et l’horodatage pour l’examen des preuves. Si vous êtes un utilisateur Linux, vous pouvez le faire via l’invite de commandes.
Plan de continuité d’activité et plan de récupération d’urgence
La planification de la continuité d’activité et la planification de la reprise d’activité sont deux composants essentiels de la stratégie de gestion des risques d’une organisation. La planification de la continuité d’activité est le processus de création d’un plan pour s’assurer que les fonctions métier essentielles peuvent continuer à fonctionner pendant et après un sinistre, tandis que la planification de la reprise d’activité est le processus de création d’un plan de récupération après sinistre et de restauration des opérations normales aussi rapidement que possible. Les deux plans se complètent mutuellement : vous devez avoir les deux pour faire face aux défis opérationnels provoqués par des sinistres ou des interruptions inattendues. Ces plans sont importants, car ils permettent de garantir qu’une organisation peut continuer à fonctionner en cas de sinistre, protéger sa réputation, se conformer aux exigences légales, maintenir la confiance des clients, gérer efficacement les risques et assurer la sécurité des employés.
Contrôle n° 28
Fournissez des preuves démontrant que :
La documentation existe et est conservée, qui décrit le plan de continuité d’activité et comprend :
les détails du personnel concerné, y compris leurs rôles et responsabilités
fonctions métier avec des exigences et des objectifs d’urgence associés
procédures de sauvegarde système et de données, configuration et planification/rétention
priorité de récupération et objectifs de délai
un plan d’urgence détaillant les actions, les étapes et les procédures à suivre pour remettre en service les systèmes d’information, fonctions métier et services critiques en cas d’interruption inattendue et non planifiée
un processus établi qui couvre la restauration complète du système et le retour à l’état d’origine
Intention : plan de continuité d’activité
L’objectif de ce contrôle est de s’assurer qu’une liste clairement définie du personnel avec des rôles et des responsabilités attribués est incluse dans le plan de continuité des activités. Ces rôles sont essentiels pour une activation et une exécution efficaces du plan pendant un incident.
Recommandations : plan de continuité des activités
Fournissez la version complète du plan/procédure de récupération d’urgence, qui doit inclure des sections couvrant le plan traité dans la description du contrôle. Fournissez le document PDF/WORD réel si dans une version numérique, sinon, si le processus est géré via une plateforme en ligne, fournissez une exportation ou des captures d’écran des processus.
Exemple de preuve : plan de continuité d’activité
Les captures d’écran suivantes montrent un extrait d’un plan de continuité d’activité et qu’il existe et est conservé.
Remarque : Cette ou ces captures d’écran montrant des instantanés d’un document de stratégie/processus, l’attente est que les éditeurs de logiciels indépendants partagent la documentation réelle sur la stratégie/procédure de prise en charge et ne fournissent pas simplement une capture d’écran.
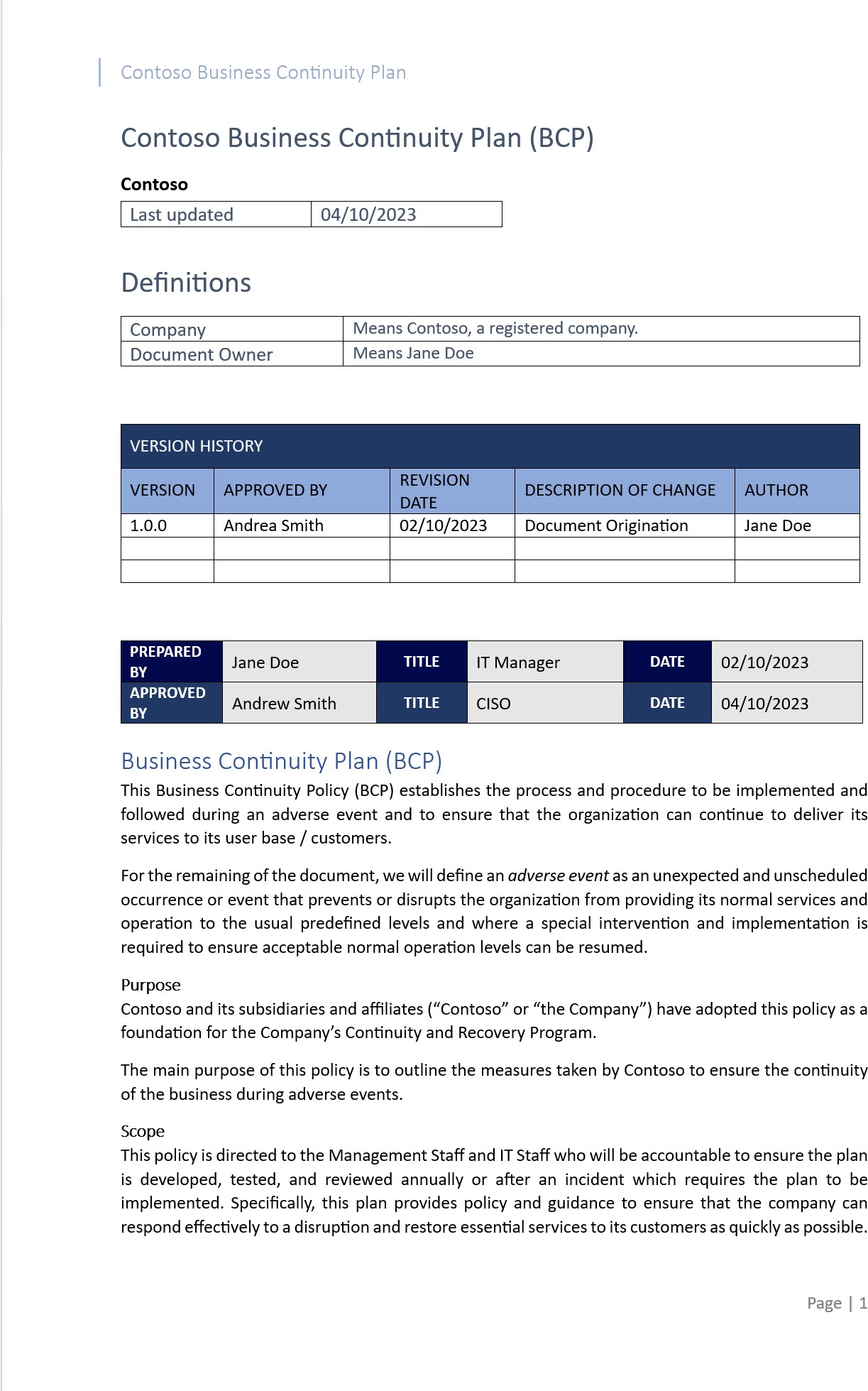
Les captures d’écran suivantes montrent un extrait de la stratégie dans laquelle la section « Personnel clé » est décrite, y compris l’équipe concernée, les coordonnées et les étapes à suivre.
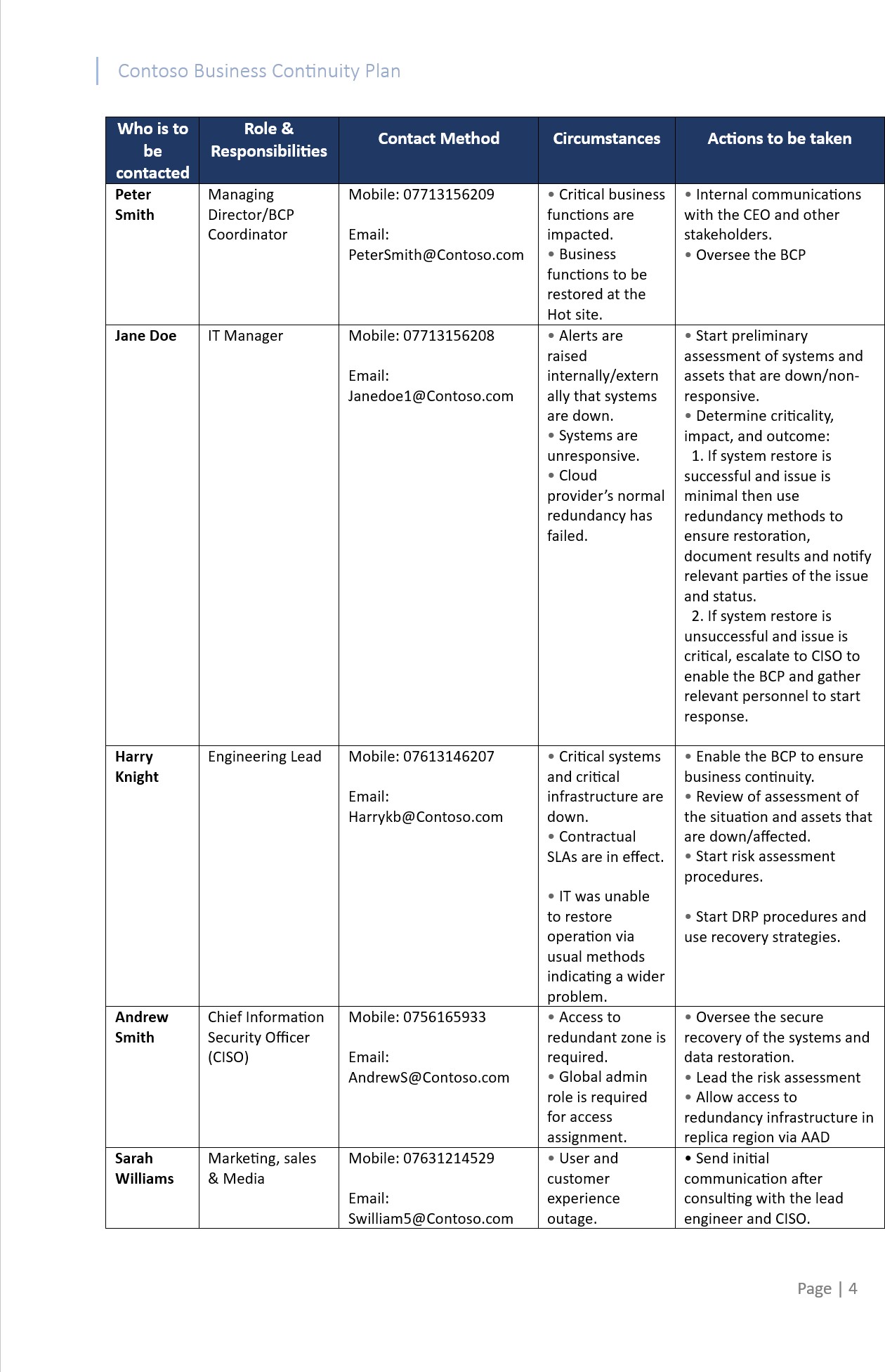
Intention : hiérarchisation
L’objectif de ce contrôle est de documenter et de hiérarchiser les fonctions métier en fonction de leur criticité. Cela doit être accompagné d’un plan des exigences d’urgence correspondantes nécessaires pour maintenir ou restaurer rapidement chaque fonction pendant une interruption non planifiée.
Recommandations : hiérarchisation
Fournissez la version complète du plan/procédure de récupération d’urgence, qui doit inclure des sections couvrant le plan traité dans la description du contrôle. Fournissez le document PDF/WORD réel si dans une version numérique, sinon, si le processus est géré via une plateforme en ligne, fournissez une exportation ou des captures d’écran des processus.
Exemple de preuve : hiérarchisation
Les captures d’écran suivantes montrent un extrait d’un plan de continuité d’activité et un plan des fonctions métier et de leur niveau de criticité, ainsi que si des plans d’urgence existent.
Remarque : cette ou ces captures d’écran montrant un document de stratégie/processus, les éditeurs de logiciels indépendants doivent partager la documentation réelle sur la stratégie/procédure de prise en charge et pas simplement fournir une capture d’écran.

Intention : sauvegardes
L’objectif de ce sous-point est de gérer des procédures documentées pour la sauvegarde des données et des systèmes essentiels. La documentation doit également spécifier les paramètres de configuration, ainsi que les stratégies de planification et de rétention des sauvegardes, pour garantir que les données sont à jour et récupérables.
Recommandations : sauvegardes
Fournissez la version complète du plan/procédure de récupération d’urgence, qui doit inclure des sections couvrant le plan traité dans la description du contrôle. Fournissez le document PDF/WORD réel si dans une version numérique, sinon, si le processus est géré via une plateforme en ligne, fournissez une exportation ou des captures d’écran des processus.
Exemple de preuve : sauvegardes
Les captures d’écran suivantes montrent l’extrait du plan de récupération d’urgence de Contoso et qu’une configuration de sauvegarde documentée existe pour chaque système. Notez que dans la capture d’écran suivante, la planification des sauvegardes est également décrite, notez que pour cet exemple, la configuration de sauvegarde est décrite dans le cadre du plan de récupération d’urgence, car les plans de continuité d’activité et de récupération d’urgence fonctionnent ensemble.
Remarque : Cette ou ces captures d’écran montrant un instantané d’un document de stratégie/procédure, les éditeurs de logiciels indépendants doivent partager la documentation réelle sur la stratégie/procédure de prise en charge et pas simplement fournir une capture d’écran.
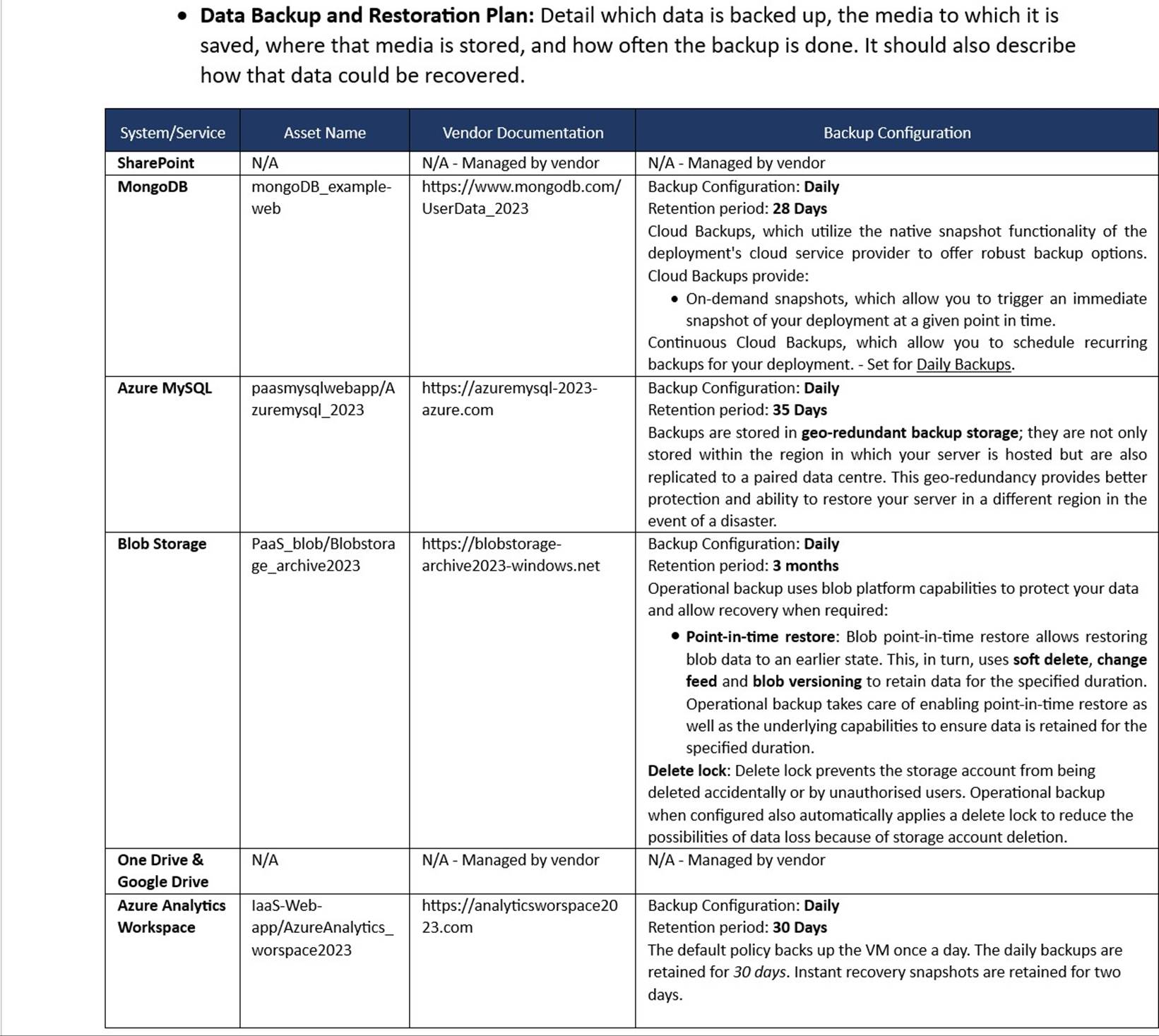
Intention : chronologies
Ce contrôle vise à établir des chronologies hiérarchisées pour les actions de récupération. Ces objectifs de temps de récupération (RTO) doivent être alignés sur l’analyse de l’impact sur l’activité et doivent être clairement définis afin que le personnel comprenne quels systèmes et fonctions doivent être restaurés en premier.
Recommandations : chronologies
Fournissez la version complète du plan/procédure de récupération d’urgence, qui doit inclure des sections couvrant le plan traité dans la description du contrôle. Fournissez le document PDF/WORD réel si dans une version numérique, sinon, si le processus est géré via une plateforme en ligne, fournissez une exportation ou des captures d’écran des processus.
Exemple de preuve : chronologie
Capture d’écran suivante montrant la continuation des fonctions métier et la classification de la criticité, ainsi que l’objectif de temps de récupération (RTO) établi.
Remarque : cette ou ces captures d’écran montrant un document de stratégie/processus, les éditeurs de logiciels indépendants doivent partager la documentation réelle sur la stratégie/procédure de prise en charge et pas simplement fournir une capture d’écran.


Intention : récupération
Ce contrôle a pour but de fournir une procédure pas à pas qui doit être suivie pour rétablir l’état opérationnel des systèmes d’information critiques, des fonctions métier et des services. Cela devrait être suffisamment détaillé pour guider la prise de décision dans les situations de forte pression, où des actions rapides et efficaces sont essentielles.
Recommandations : récupération
Fournissez la version complète du plan/procédure de récupération d’urgence, qui doit inclure des sections couvrant le plan traité dans la description du contrôle. Fournissez le document PDF/WORD réel si dans une version numérique, sinon, si le processus est géré via une plateforme en ligne, fournissez une exportation ou des captures d’écran des processus.
Exemple de preuve : récupération
Les captures d’écran suivantes montrent l’extrait de notre plan de récupération d’urgence et qu’un plan de récupération documenté existe pour chaque système et fonction métier. Notez que pour cet exemple, la procédure de récupération du système fait partie du plan de récupération d’urgence, car les plans de continuité d’activité et de récupération d’urgence fonctionnent ensemble pour obtenir une récupération/restauration complète.
Remarque : cette ou ces captures d’écran montrant un document de stratégie/processus, les éditeurs de logiciels indépendants doivent partager la documentation réelle sur la stratégie/procédure de prise en charge et pas simplement fournir une capture d’écran.
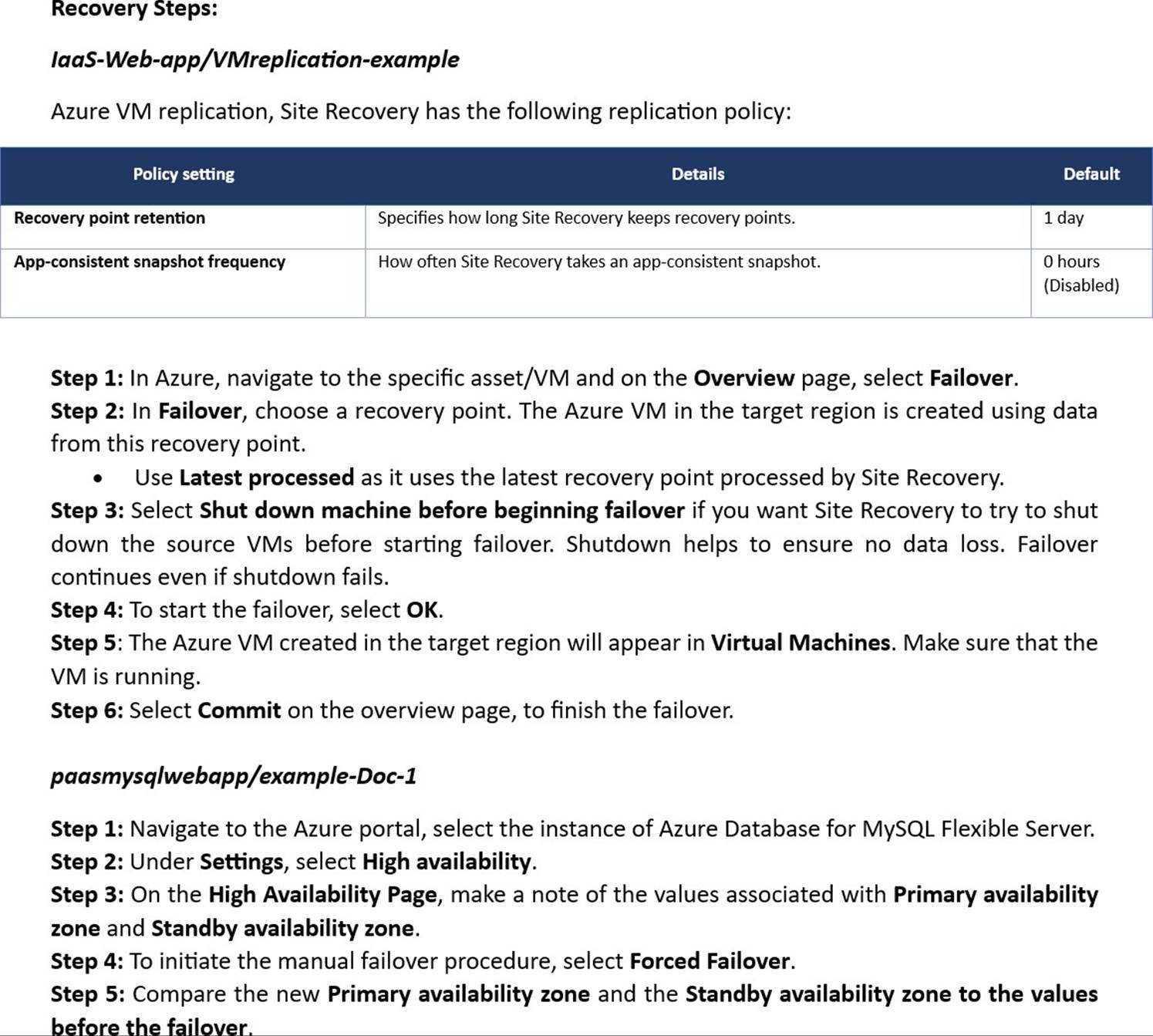
Intention : validation
Ce point de contrôle vise à s’assurer que le plan de continuité d’activité comprend un processus structuré pour guider l’organisation dans la restauration des systèmes à leur état d’origine une fois la crise gérée. Cela inclut des étapes de validation pour s’assurer que les systèmes sont entièrement opérationnels et ont conservé leur intégrité.
Recommandations : validation
Fournissez la version complète du plan/procédure de récupération d’urgence, qui doit inclure des sections couvrant le plan traité dans la description du contrôle. Fournissez le document PDF/WORD réel si dans une version numérique, sinon, si le processus est géré via une plateforme en ligne, fournissez une exportation ou des captures d’écran des processus.
Exemple de preuve : validation
La capture d’écran suivante montre le processus de récupération décrit dans la stratégie du plan de continuité d’activité et les étapes/actions à entreprendre.
Remarque : Cette ou ces captures d’écran montrant un instantané d’un document de stratégie/procédure, les éditeurs de logiciels indépendants doivent partager la documentation réelle sur la stratégie/procédure de prise en charge et pas simplement fournir une capture d’écran.

Contrôle n° 29
Fournissez des preuves démontrant que :
La documentation existe et est conservée, qui décrit le plan de récupération d’urgence et comprend au minimum :
les détails du personnel concerné, y compris leurs rôles et responsabilités
fonctions métier avec des exigences et des objectifs d’urgence associés
procédures de sauvegarde système et de données, configuration et planification/rétention
priorité de récupération et objectifs de délai
un plan d’urgence détaillant les actions, les étapes et les procédures à suivre pour remettre en service les systèmes d’information, fonctions métier et services critiques en cas d’interruption inattendue et non planifiée
un processus établi qui couvre la restauration complète du système et le retour à l’état d’origine
Intention : DRP
L’objectif de ce contrôle est de disposer de rôles et de responsabilités bien documentés pour chaque membre de l’équipe de récupération d’urgence. Un processus d’escalade doit également être décrit pour s’assurer que les problèmes sont rapidement élevés et résolus par le personnel approprié pendant un scénario de sinistre.
Recommandations : DRP
Fournissez la version complète du plan/procédure de récupération d’urgence, qui doit inclure des sections couvrant le plan traité dans la description du contrôle. Fournissez le document PDF/WORD réel si dans une version numérique, sinon, si le processus est géré via une plateforme en ligne, fournissez une exportation ou des captures d’écran des processus.
Exemple de preuve : DRP
Les captures d’écran suivantes montrent l’extrait d’un plan de récupération d’urgence et qu’il existe et est conservé.
Remarque : cette ou ces captures d’écran montrant un document de stratégie/processus, les éditeurs de logiciels indépendants doivent partager la documentation réelle sur la stratégie/procédure de prise en charge et pas simplement fournir une capture d’écran.
La capture d’écran suivante montre un extrait de la stratégie dans laquelle le « plan d’urgence » est décrit, y compris l’équipe concernée, les détails du contact et les étapes d’escalade.
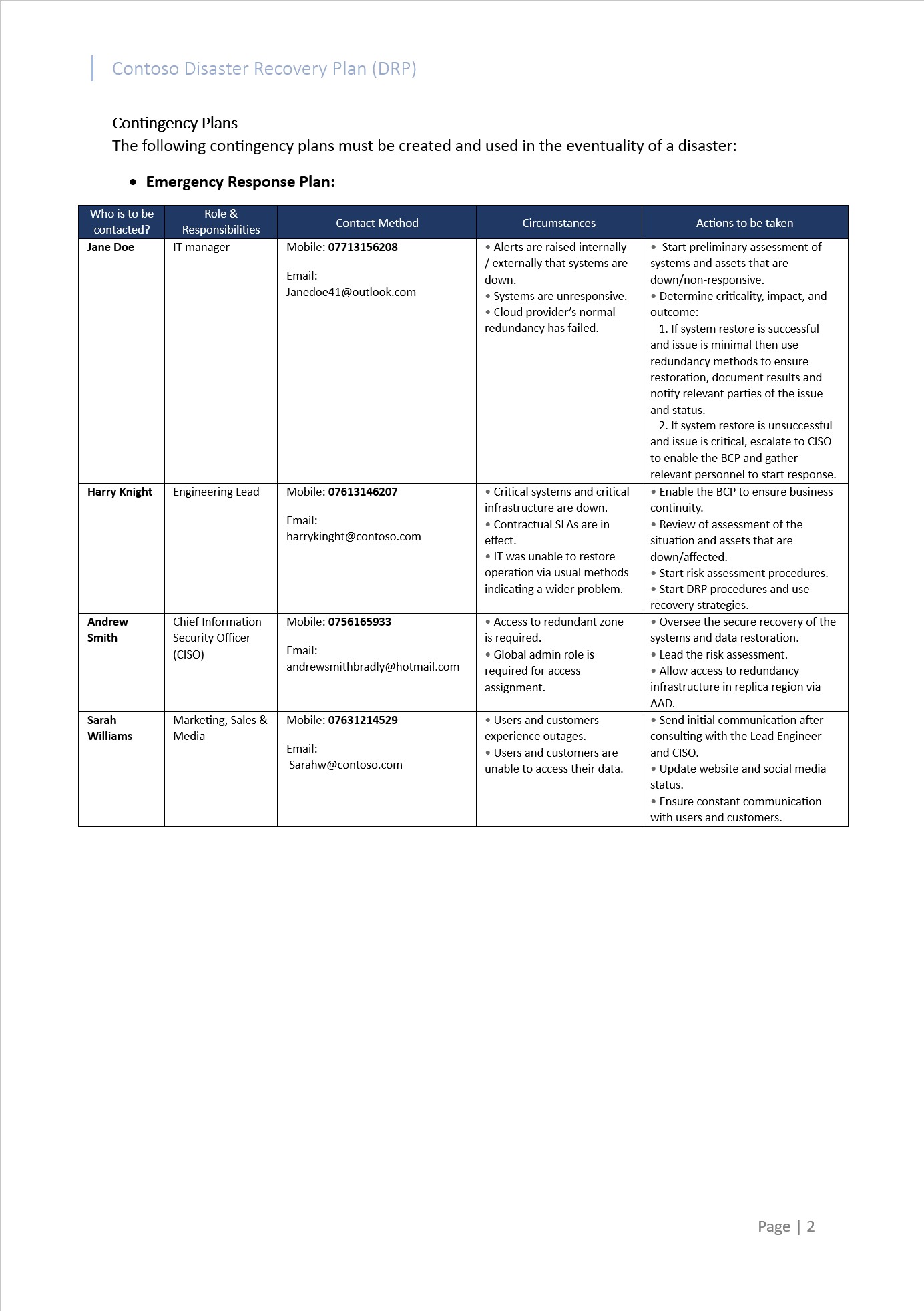
Intention : inventaire
L’objectif de ce contrôle est de maintenir une liste d’inventaire à jour de tous les systèmes d’information qui sont essentiels à la prise en charge des opérations commerciales. Cette liste est fondamentale pour comprendre quels systèmes doivent être hiérarchisés pendant un effort de récupération d’urgence.
Recommandations : inventaire
Fournissez la version complète du plan/procédure de récupération d’urgence, qui doit inclure des sections couvrant le plan traité dans la description du contrôle. Fournissez le document PDF/WORD réel si dans une version numérique, sinon, si le processus est géré via une plateforme en ligne, fournissez une exportation ou des captures d’écran des processus.
Exemple de preuve : inventaire
Les captures d’écran suivantes montrent l’extrait d’un DRP et qu’il existe un inventaire des systèmes critiques et de leur niveau de criticité, ainsi que des fonctions système.
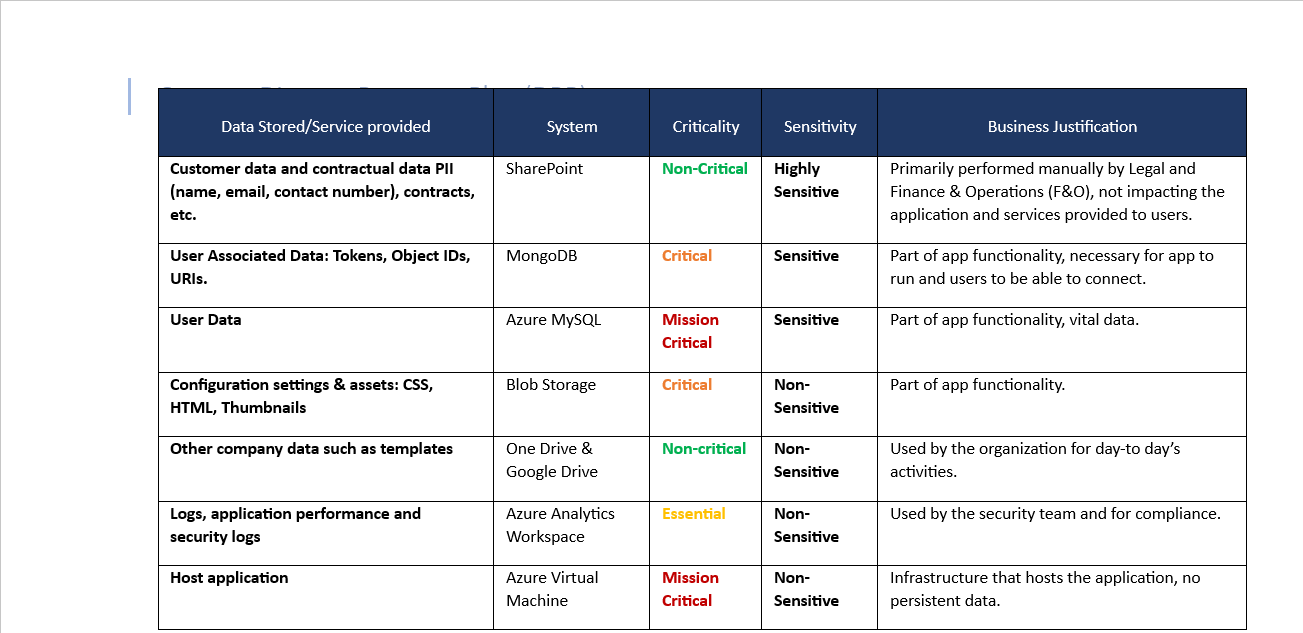
Remarque : cette ou ces captures d’écran montrant un document de stratégie/processus, les éditeurs de logiciels indépendants doivent partager la documentation réelle sur la stratégie/procédure de prise en charge et pas simplement fournir une capture d’écran.
La capture d’écran suivante montre la classification et la définition de criticité du service.
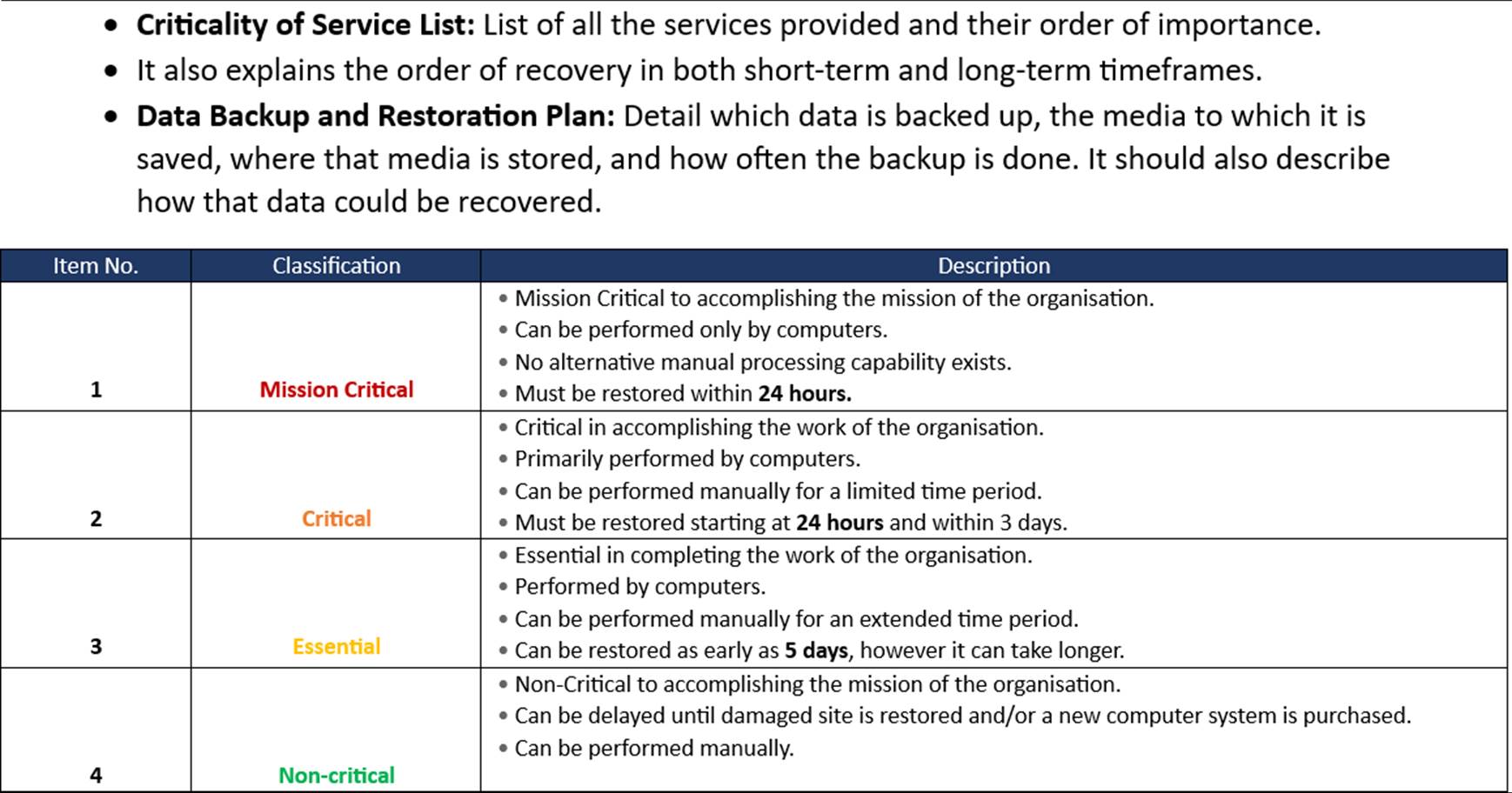
Remarque : cette ou ces captures d’écran montrant un document de stratégie/processus, les éditeurs de logiciels indépendants doivent partager la documentation réelle sur la stratégie/procédure de prise en charge et pas simplement fournir une capture d’écran.
Intention : sauvegardes
Ce contrôle nécessite que des procédures bien définies pour les sauvegardes système et de données soient en place. Ces procédures doivent décrire la fréquence, la configuration et les emplacements des sauvegardes pour garantir que toutes les données critiques peuvent être restaurées en cas de défaillance ou de sinistre.
Recommandations : sauvegardes
Fournissez la version complète du plan/procédure de récupération d’urgence, qui doit inclure des sections couvrant le plan traité dans la description du contrôle. Fournissez le document PDF/WORD réel si dans une version numérique, sinon, si le processus est géré via une plateforme en ligne, fournissez une exportation ou des captures d’écran des processus.
Exemple de preuve : sauvegardes
Les captures d’écran suivantes montrent l’extrait d’un plan de récupération d’urgence et qu’une configuration de sauvegarde documentée existe pour chaque système. Notez ci-dessous que la planification de la sauvegarde est également décrite.
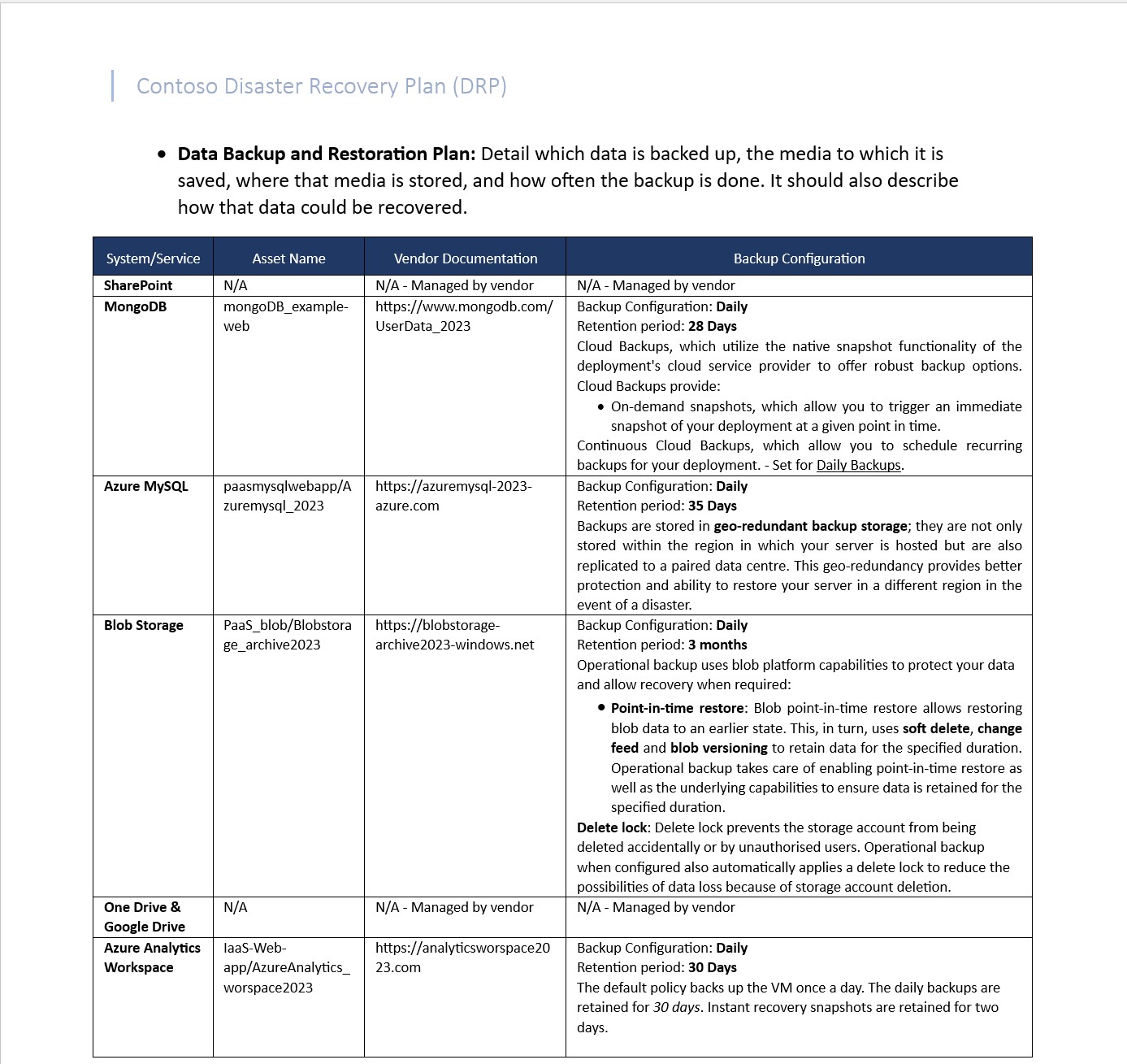
Remarque : cette ou ces captures d’écran montrant un instantané d’un document de stratégie/processus, les éditeurs de logiciels indépendants doivent partager la documentation réelle sur la stratégie/procédure de prise en charge et pas simplement fournir une capture d’écran.
Intention : récupération
Ce contrôle nécessite un plan de récupération complet qui décrit des procédures pas à pas pour restaurer des systèmes et des données vitaux. Cela sert de feuille de route pour l’équipe de récupération d’urgence et garantit que toutes les actions de récupération sont préméditées et efficaces dans la restauration des opérations commerciales.
Recommandations : récupération
Fournissez la version complète du plan/procédure de récupération d’urgence, qui doit inclure des sections couvrant le plan traité dans la description du contrôle. Fournissez le document PDF/WORD réel si dans une version numérique, sinon, si le processus est géré via une plateforme en ligne, fournissez une exportation ou des captures d’écran des processus.
Exemple de preuve : récupération
Les captures d’écran suivantes montrent l’extrait d’un plan de récupération d’urgence et qu’un remplacement d’équipement et des instructions de récupération du système existent et sont documentés, ainsi que la procédure de récupération qui inclut les délais de récupération, les actions à entreprendre pour restaurer l’infrastructure cloud, etc.

Remarque : cette ou ces captures d’écran montrant un instantané d’un document de stratégie/processus, les éditeurs de logiciels indépendants doivent partager la documentation réelle sur la stratégie/procédure de prise en charge et pas simplement fournir une capture d’écran.
Contrôle n° 30
Fournissez des preuves démontrant que :
Le plan de continuité d’activité et le plan de reprise d’activité sont examinés au moins tous les 12 mois pour s’assurer qu’ils restent valides et efficaces dans les situations défavorables, et sont mis à jour en fonction des éléments suivants :
Examen annuel du plan.
Tout le personnel concerné reçoit une formation sur les rôles et responsabilités attribués dans les plans d’urgence.
Le ou les plans sont testés par le biais d’exercices de continuité d’activité ou de récupération d’urgence.
Les résultats des tests sont documentés, y compris les leçons tirées des exercices ou des changements organisationnels.
Intention : révision annuelle
L’objectif de ce contrôle est de s’assurer que les plans de continuité d’activité et de reprise d’activité sont examinés chaque année. L’examen doit confirmer que les plans sont toujours efficaces, exacts et alignés sur les objectifs commerciaux actuels et les architectures technologiques.
Intention : formation annuelle
Ce contrôle exige que toutes les personnes ayant des rôles désignés dans les plans de continuité d’activité et de reprise d’activité reçoivent une formation appropriée chaque année. L’objectif est de s’assurer qu’ils sont conscients de leurs responsabilités et capables de les exécuter efficacement en cas de sinistre ou d’interruption de l’activité.
Intention : exercices
L’objectif ici est de valider l’efficacité des plans de continuité d’activité et de reprise d’activité par le biais d’exercices réels. Ces exercices doivent être conçus pour simuler diverses conditions défavorables afin de tester dans quelle mesure l’organisation peut soutenir ou restaurer des opérations commerciales.
Intention : analyse
Le dernier point de contrôle vise à obtenir une documentation complète de tous les résultats des tests, y compris une analyse de ce qui a bien fonctionné et de ce qui n’a pas fonctionné. Les leçons apprises doivent être intégrées à nouveau dans les plans, et toutes les lacunes doivent être traitées immédiatement pour améliorer la résilience de l’organisation.
Recommandations : révisions
Des éléments de preuve tels que des rapports, des notes de réunion et des résultats des exercices annuels de plans de continuité d’activité et de reprise d’activité doivent être fournis pour examen.
Exemple de preuve : révisions
Les captures d’écran suivantes montrent une sortie de rapport d’un exercice de plan de continuité d’activité et de récupération d’urgence dans lequel un scénario a été établi pour permettre à l’équipe de mettre en œuvre le plan de continuité d’activité et de récupération d’urgence et de passer en revue la situation jusqu’à la restauration réussie des fonctions métier et du fonctionnement du système.
Remarque : ces captures d’écran montrent une ou plusieurs captures instantanées d’un document de stratégie/processus. L’objectif est que les éditeurs de logiciels indépendants partagent la documentation réelle sur la stratégie/procédure de prise en charge et ne fournissent pas simplement une capture d’écran.





Remarque : ces captures d’écran montrent une ou plusieurs captures instantanées d’un document de stratégie/processus. L’objectif est que les éditeurs de logiciels indépendants partagent la documentation réelle sur la stratégie/procédure de prise en charge et ne fournissent pas simplement une capture d’écran.