Détection d’anomalies dans l’analytique des points de terminaison
Remarque
Cette fonctionnalité est disponible en tant que module complémentaire Intune. Pour plus d’informations, consultez Intune modules complémentaires.
Cet article explique comment la détection d’anomalies dans Endpoint Analytics fonctionne comme un système d’avertissement précoce.
La détection d’anomalies surveille l’intégrité des appareils de votre organization pour l’expérience utilisateur et les régressions de productivité suite à des modifications de configuration. En cas de défaillance, Anomalies met en corrélation les objets de déploiement pertinents pour permettre une résolution rapide des problèmes, suggérer des causes racines et une correction.
Les administrateurs peuvent s’appuyer sur la détection des anomalies pour en savoir plus sur l’expérience utilisateur impactant les problèmes avant qu’elles ne les atteignent via d’autres canaux. La détection d’anomalies se concentre initialement sur les blocages/blocages d’application et les redémarrages d’erreur d’arrêt.
Vue d’ensemble
Avec la détection d’anomalie, vous pouvez détecter les problèmes potentiels dans un système avant qu’ils ne deviennent un problème grave. Traditionnellement, les équipes de support technique ont une visibilité limitée sur les problèmes potentiels.
souvent, ils obtiennent seulement un sous-ensemble des problèmes signalés/réaffectés via le canal de support, ce qui n’est pas vraiment représentatif de tout ce qui se passe dans votre organization.
Ils doivent passer d’innombrables heures à examiner les tableaux de bord personnalisés pour essayer d’identifier la cause racine, de résoudre les problèmes, de créer des alertes personnalisées, de modifier les seuils et de modifier les paramètres.
La détection d’anomalies vise à résoudre ces problèmes en permettant aux administrateurs informatiques d’obtenir des informations critiques.
En plus de détecter les anomalies, vous pouvez afficher les groupes de corrélation d’appareils pour explorer les causes racines potentielles des anomalies de gravité moyenne et élevée. Ces cohortes d’appareils vous permettent d’afficher les modèles identifiés parmi les appareils. Nous avons adopté une approche proactive de la gestion des appareils en identifiant également les appareils « à risque » dans ces cohortes. Il s’agit des appareils qui relèvent des modèles identifiés avec un niveau de confiance élevé, mais qui n’ont pas encore vu ces anomalies.
Remarque
Les cohortes d’appareils sont identifiées uniquement pour les anomalies de gravité moyenne et élevée.
Configuration requise
Licences/abonnements : les fonctionnalités avancées de Endpoint Analytics sont incluses en tant que Intune-add on sous Microsoft Intune Suite et nécessitent un coût supplémentaire pour les options de licence qui incluent Microsoft Intune.
Autorisations : la détection d’anomalie utilise des autorisations de rôle intégrées
Onglet Anomalies
Connectez-vous au Centre d’administration Microsoft Intune.
SélectionnezVue d’ensemble del’analytique de point de> terminaison de rapport>.
Sélectionnez l’onglet Anomalies. L’onglet Anomalies fournit une vue d’ensemble rapide des anomalies détectées dans votre organization.
Dans cet exemple, l’onglet Anomalies affiche une anomalie avec un impact de gravité moyenne . Vous pouvez ajouter des filtres pour affiner la liste.
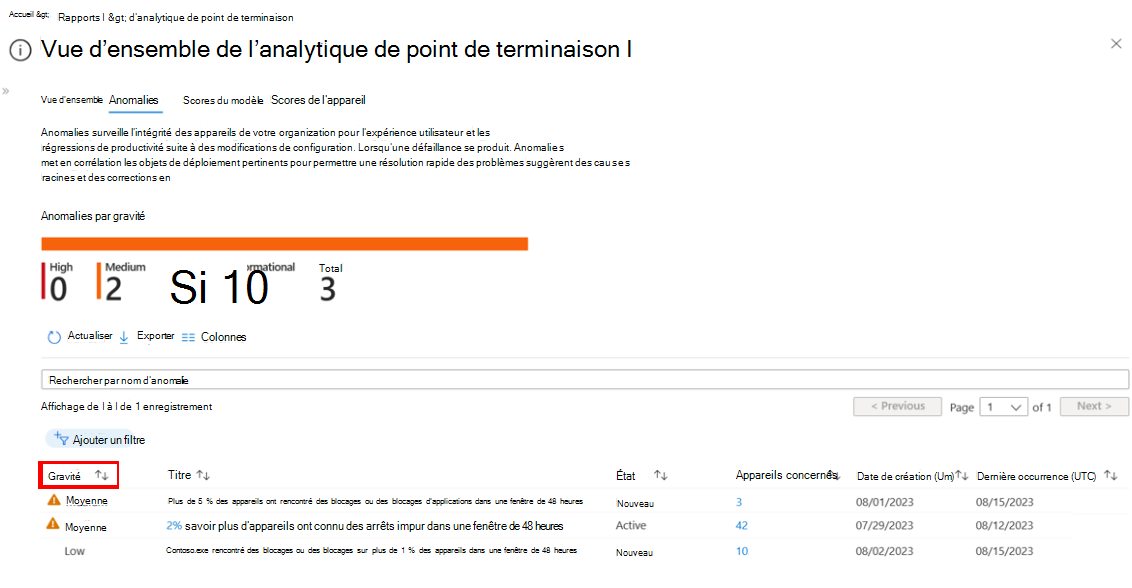
Pour afficher plus d’informations sur un élément spécifique, choisissez-le dans la liste. Vous pouvez voir des détails tels que le nom de l’application, les appareils affectés, le moment où le problème a été détecté pour la première fois et la dernière fois qu’il s’est produit, ainsi que tous les groupes d’appareils susceptibles de contribuer au problème.
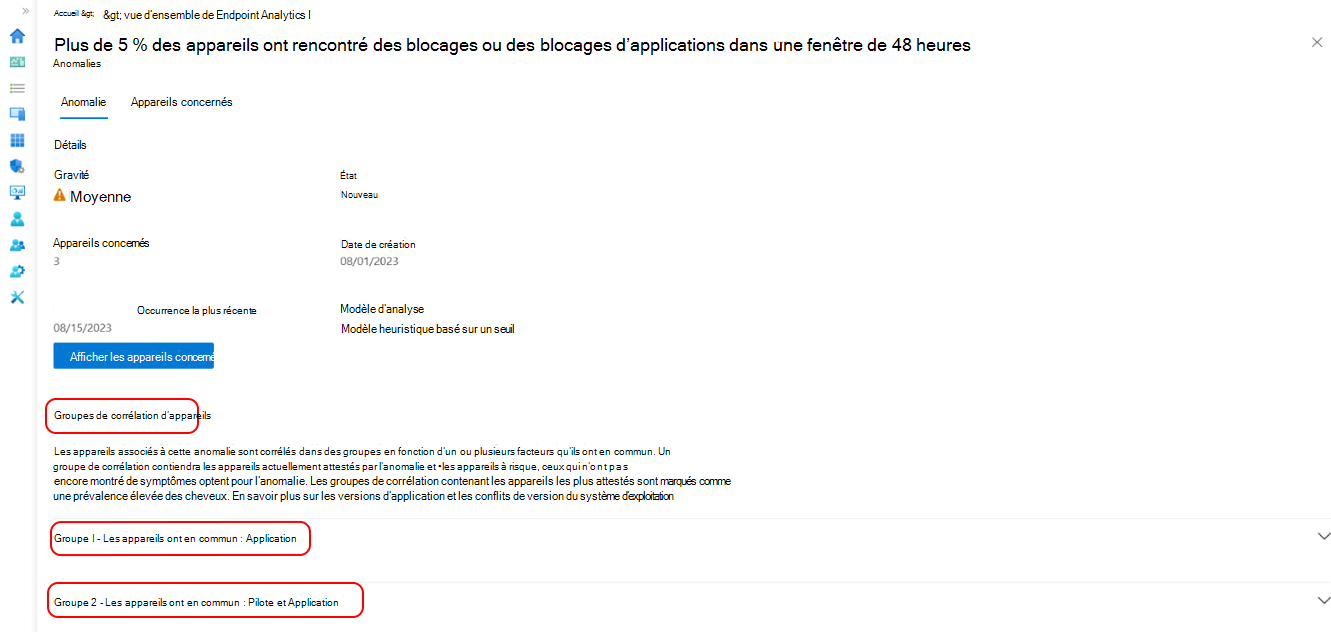
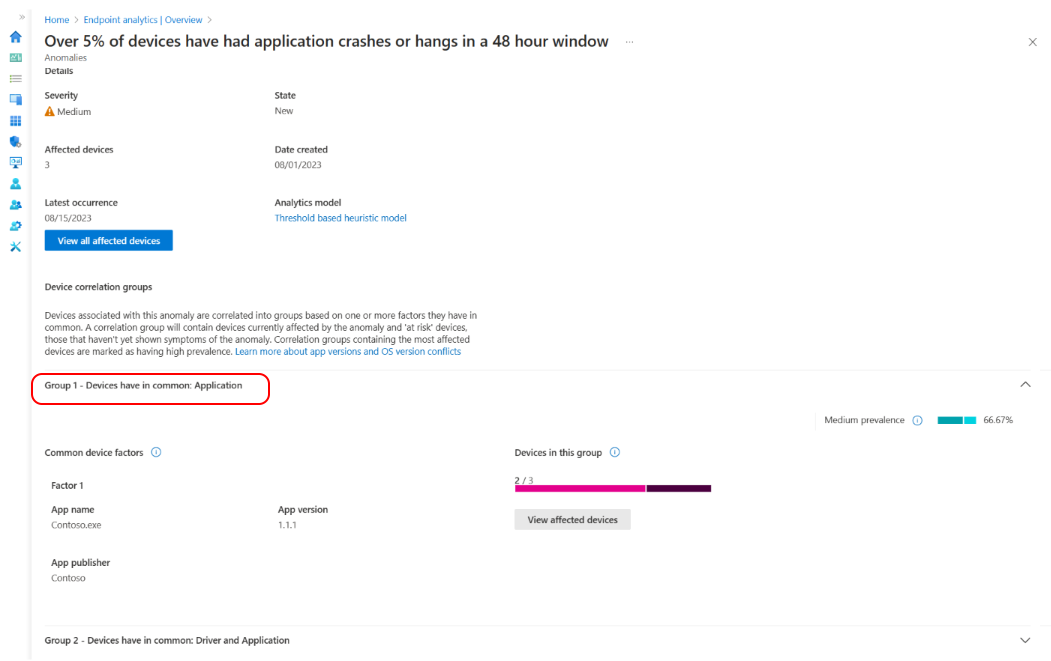
Sélectionnez un groupe de corrélation d’appareils dans la liste pour obtenir une vue détaillée des facteurs communs des appareils. Les appareils sont corrélés en fonction d’un ou plusieurs attributs partagés tels que la version de l’application, la mise à jour du pilote, la version du système d’exploitation et le modèle d’appareil. Vous pouvez voir le nombre d’appareils actuellement affectés par l’anomalie et les appareils à risque de rencontrer l’anomalie. Le taux de prévalence indique également le pourcentage d’appareils affectés d’une anomalie qui sont membres d’un groupe de corrélation.
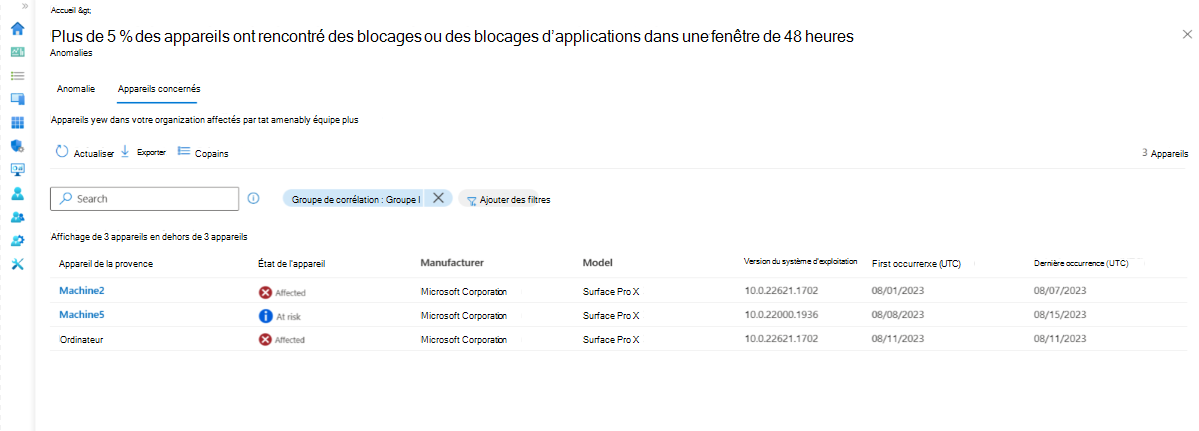
Sélectionnez Afficher les appareils affectés pour afficher la liste des appareils avec des attributs clés pertinents pour chaque appareil. Vous pouvez filtrer pour afficher les appareils dans des groupes de corrélation spécifiques ou afficher tous les appareils affectés par cette anomalie dans votre organization. En outre, l’appareil chronologie affiche des événements plus anormaux.




Modèles statistiques pour déterminer les anomalies
Le modèle analytique généré détecte les cohortes d’appareils confrontées à un ensemble anormal de redémarrages d’erreurs d’arrêt et de blocages/incidents d’application qui nécessitent l’attention de l’administrateur pour les atténuer et les résoudre. Les modèles identifiés à partir de nos journaux de télémétrie et de diagnostics de capteur déterminent ces cohortes d’appareils
Modèle heuristique basé sur des seuils : le modèle heuristique implique la définition d’une ou plusieurs valeurs de seuil pour les blocages/incidents d’application ou les redémarrages d’erreur d’arrêt. Les appareils sont signalés comme anormaux en cas de violation du seuil défini ci-dessus. Le modèle est simple mais efficace ; il est adapté à la présentation de problèmes importants ou statiques avec les appareils ou leurs applications. Actuellement, les seuils sont prédéterminés sans option de personnalisation.
Modèle de tests t appairés : les tests T couplés sont une méthode mathématique qui compare des paires d’observations dans un jeu de données, en recherchant une distance statistiquement significative entre leurs moyens. Les tests sont utilisés sur des jeux de données qui se composent d’observations liées les unes aux autres d’une manière ou d’une autre. Par exemple, le nombre de redémarrages d’erreur d’arrêt à partir du même appareil avant et après une modification de stratégie, ou l’application se bloque sur un appareil après une mise à jour du système d’exploitation (systèmes d’exploitation).
Modèle de score Z de population : les modèles statistiques basés sur le score Z de la population impliquent le calcul de l’écart type et la moyenne d’un jeu de données, puis l’utilisation de ces valeurs pour déterminer quels points de données sont anormaux. Standard écart et la moyenne sont utilisés pour calculer le score Z pour chaque point de données, qui représente le nombre d’écarts types par rapport à la moyenne. Les points de données qui se trouvent en dehors d’une certaine plage sont anormaux. Ce modèle est bien adapté pour mettre en évidence les appareils ou applications hors norme à partir de la base de référence plus large, mais nécessite des jeux de données suffisamment volumineux pour être précis.
Modèle de score Z de série chronologique : les modèles de score Z de série chronologique sont une variante du modèle de score Z standard conçu pour détecter les anomalies dans les données de série chronologique. Les données de série chronologique sont une séquence de points de données collectés à intervalles réguliers au fil du temps, comme l’agrégat des redémarrages d’erreur d’arrêt. Standard écart et moyenne sont calculés pour une fenêtre de temps glissante, à l’aide de métriques agrégées. Cette méthode permet au modèle d’être sensible aux modèles temporels dans les données et de s’adapter aux modifications de sa distribution au fil du temps.
Étapes suivantes
Pour plus d’informations, voir :