Tutoriel : Utiliser des fonctions d’agrégation
S’applique à : ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
Les fonctions d’agrégation vous permettent de regrouper et de combiner des données de plusieurs lignes dans une valeur récapitulative. La valeur récapitulative dépend de la fonction choisie, par exemple un nombre, un maximum ou une valeur moyenne.
Ce didacticiel vous montre comment effectuer les opérations suivantes :
- Utiliser l’opérateur de synthèse
- Visualiser les résultats de la requête
- Compter des lignes de manière conditionnelle
- Regrouper des données dans des compartiments
- Calculer les valeurs min, max, avg et sum
- Calculer des pourcentages
- Extraire des valeurs uniques
- Données de compartiment par condition
- Effectuer une agrégation sur une fenêtre glissante
Les exemples de ce didacticiel utilisent la StormEvents table, qui est publiquement disponible dans le cluster d’aide. Pour explorer vos propres données, créez votre propre cluster gratuit.
Les exemples de ce didacticiel utilisent la StormEvents table, qui est publiquement disponible dans les exemples de données d’analyse météorologique.
Ce didacticiel s’appuie sur la base du premier didacticiel, learn common operators.
Prérequis
Pour exécuter les requêtes suivantes, vous avez besoin d’un environnement de requête avec accès aux exemples de données. Vous pouvez utiliser l'un des éléments suivants :
- Un compte Microsoft ou une identité d’utilisateur Microsoft Entra
- Un espace de travail Fabric avec une capacité avec Microsoft Fabric
Utiliser l’opérateur de synthèse
L’opérateur de synthèse est essentiel pour effectuer des agrégations sur vos données. L’opérateur summarize regroupe des lignes en fonction de la by clause, puis utilise la fonction d’agrégation fournie pour combiner chaque groupe dans une seule ligne.
Recherchez le nombre d’événements par état à l’aide summarize de la fonction d’agrégation de nombre .
StormEvents
| summarize TotalStorms = count() by State
Sortie
| State | TotalStorms |
|---|---|
| TEXAS | 4701 |
| KANSAS | 3166 |
| IOWA | 2337 |
| ILLINOIS | 2022 |
| MISSOURI | 2016 |
| ... | ... |
Visualiser les résultats de requête
La visualisation des résultats de requête dans un graphique ou un graphique peut vous aider à identifier des modèles, des tendances et des valeurs hors norme dans vos données. Vous pouvez le faire avec l’opérateur de rendu .
Tout au long du tutoriel, vous verrez des exemples d’utilisation render pour afficher vos résultats. Pour l’instant, nous allons utiliser render pour afficher les résultats de la requête précédente dans un graphique à barres.
StormEvents
| summarize TotalStorms = count() by State
| render barchart
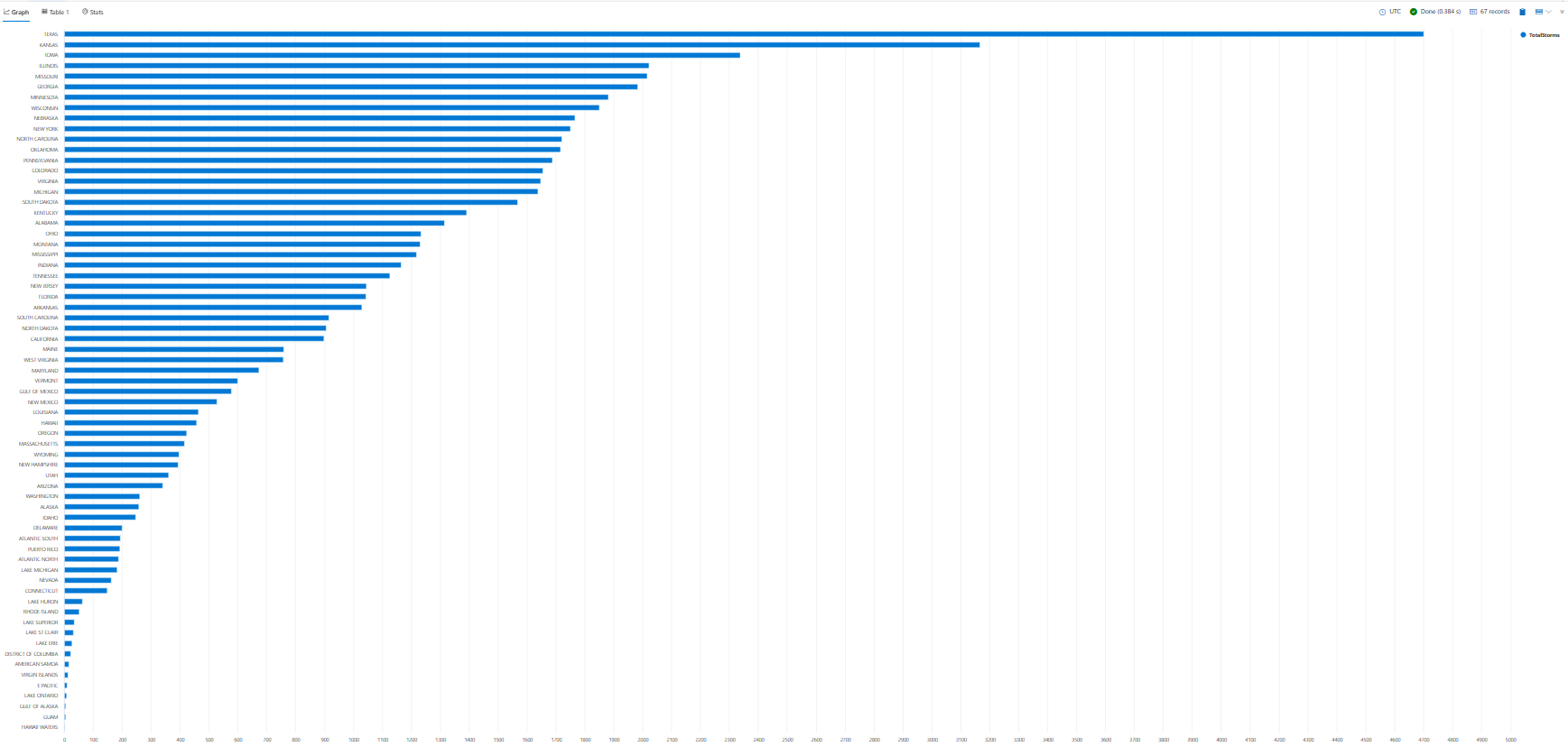
Compter des lignes de manière conditionnelle
Lors de l’analyse de vos données, utilisez countif() pour compter les lignes en fonction d’une condition spécifique pour comprendre le nombre de lignes répondant aux critères donnés.
La requête suivante utilise countif() pour compter les tempêtes qui ont causé des dommages. La requête utilise ensuite l’opérateur top pour filtrer les résultats et afficher les états avec la quantité la plus élevée de dommages causés par les tempêtes.
StormEvents
| summarize StormsWithCropDamage = countif(DamageCrops > 0) by State
| top 5 by StormsWithCropDamage
Sortie
| State | StormsWithCropDamage |
|---|---|
| IOWA | 359 |
| NEBRASKA | 201 |
| MISSISSIPPI | 105 |
| CAROLINE DU NORD | 82 |
| MISSOURI | 78 |
Regrouper des données dans des compartiments
Pour agréger par valeurs numériques ou temporelles, vous devez d’abord regrouper les données dans des bacs à l’aide de la fonction bin(). L’utilisation bin() peut vous aider à comprendre comment les valeurs sont distribuées dans une certaine plage et effectuer des comparaisons entre différentes périodes.
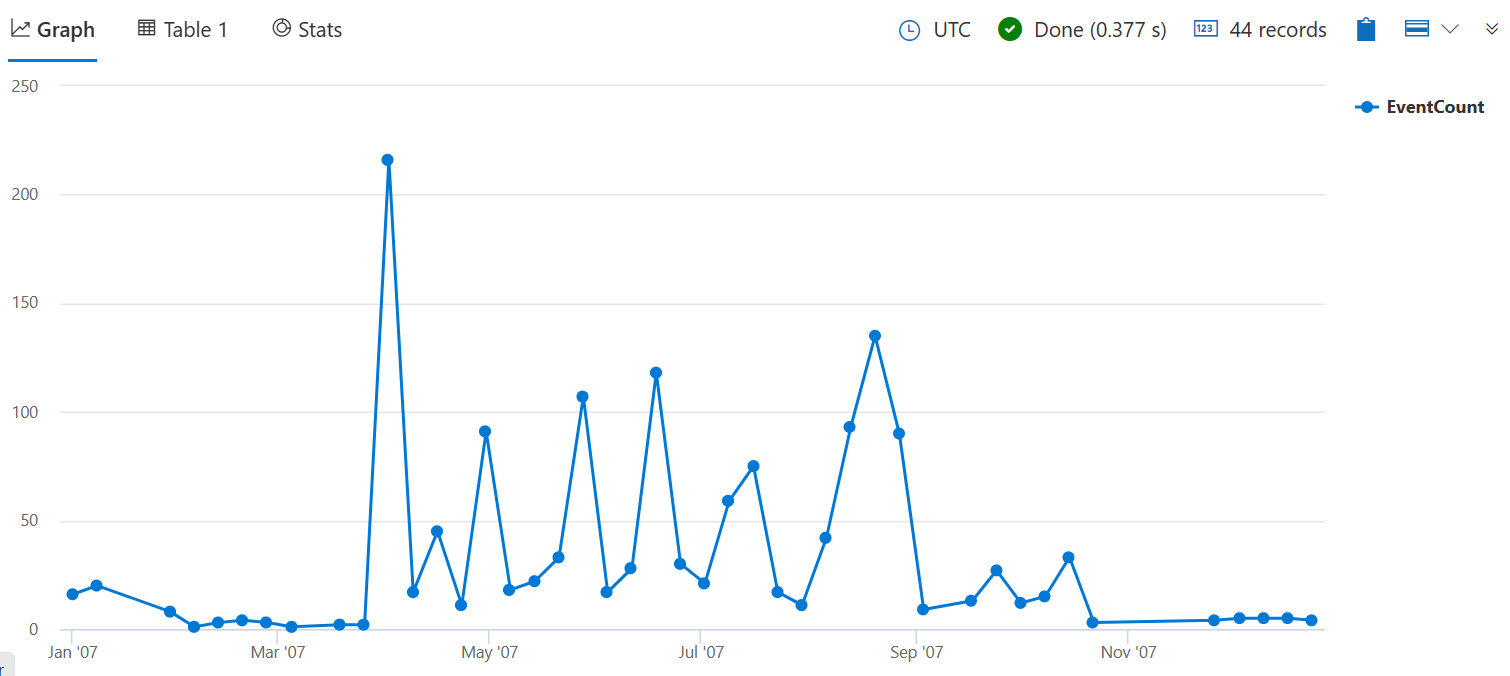
La requête suivante compte le nombre de tempêtes qui ont causé des dommages aux cultures pour chaque semaine en 2007. L’argument 7d représente une semaine, car la fonction requiert une valeur d’intervalle de temps valide.
StormEvents
| where StartTime between (datetime(2007-01-01) .. datetime(2007-12-31))
and DamageCrops > 0
| summarize EventCount = count() by bin(StartTime, 7d)
Sortie
| StartTime | EventCount |
|---|---|
| 2007-01-01T00:00:00Z | 16 |
| 2007-01-08T00:00:00Z | 20 |
| 2007-01-29T00:00:00Z | 8 |
| 2007-02-05T00:00:00Z | 1 |
| 2007-02-12T00:00:00Z | 3 |
| ... | ... |
Ajoutez | render timechart à la fin de la requête pour visualiser les résultats.
Remarque
bin() est similaire à la floor() fonction dans d’autres langages de programmation. Elle réduit chaque valeur au multiple le plus proche du module que vous fournissez et permet summarize d’affecter les lignes aux groupes.
Calculer les valeurs min, max, avg et sum
Pour en savoir plus sur les types de tempêtes qui provoquent des dommages aux cultures, calculez les dommages de culture min(),max()et avg() pour chaque type d’événement, puis triez le résultat par les dommages moyens.
Notez que vous pouvez utiliser plusieurs fonctions d’agrégation dans un seul summarize opérateur pour produire plusieurs colonnes calculées.
StormEvents
| where DamageCrops > 0
| summarize
MaxCropDamage=max(DamageCrops),
MinCropDamage=min(DamageCrops),
AvgCropDamage=avg(DamageCrops)
by EventType
| sort by AvgCropDamage
Sortie
| Type d’événement | MaxCropDamage | MinCropDamage | AvgCropDamage |
|---|---|---|---|
| Gel | 568600000 | 3000 | 9106087.5954198465 |
| Feu de forêt | 21000000 | 10000 | 7268333.333333333 |
| Sécheresse | 700 000 000 | 2000 | 6763977.8761061952 |
| Crue | 500000000 | 1 000 | 4844925.23364486 |
| Vent d’orage | 22000000 | 100 | 920328.36538461538 |
| ... | ... | ... | ... |
Les résultats de la requête précédente indiquent que les événements Frost/Freeze ont entraîné en moyenne le plus de dégâts sur les cultures. Toutefois, la requête bin() a montré que les événements avec des dommages aux cultures ont eu lieu principalement dans les mois d’été.
Utilisez sum() pour vérifier le nombre total de cultures endommagées au lieu de la quantité d’événements qui ont causé des dommages, comme dans count() la requête bin() précédente.
StormEvents
| where StartTime between (datetime(2007-01-01) .. datetime(2007-12-31))
and DamageCrops > 0
| summarize CropDamage = sum(DamageCrops) by bin(StartTime, 7d)
| render timechart
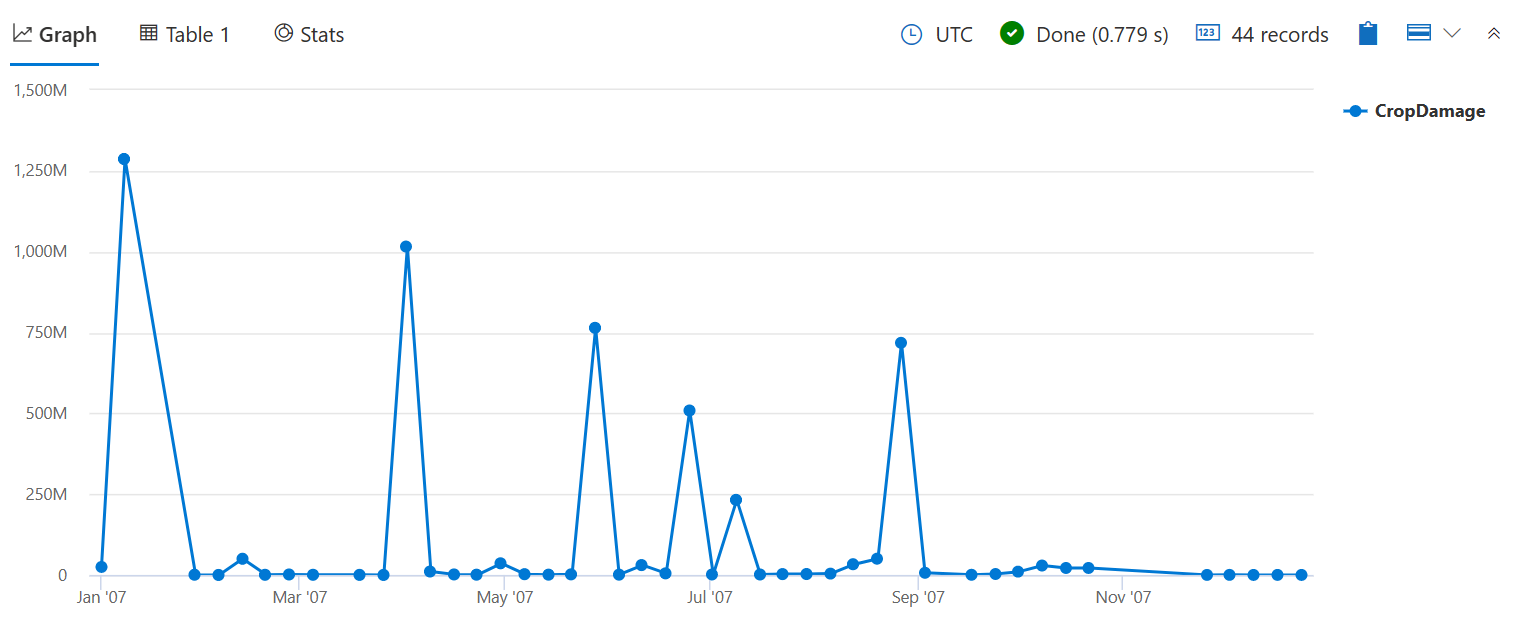
Maintenant, vous pouvez voir un pic de dommages aux cultures en janvier, ce qui a probablement été dû au gel/gel.
Conseil
Utilisez minif(), maxif(), avgif()et sumif() pour effectuer des agrégations conditionnelles, comme nous l’avons fait dans la section nombre conditionnel de lignes.
Calculer des pourcentages
Le calcul des pourcentages peut vous aider à comprendre la distribution et la proportion de différentes valeurs au sein de vos données. Cette section décrit deux méthodes courantes pour calculer des pourcentages avec le Langage de requête Kusto (KQL).
Calculer le pourcentage en fonction de deux colonnes
Utilisez count() et countif pour trouver le pourcentage d’événements de tempête qui ont provoqué des dommages de culture dans chaque état. Tout d’abord, comptez le nombre total de tempêtes dans chaque état. Ensuite, comptez le nombre de tempêtes qui ont causé des dommages aux cultures dans chaque état.
Ensuite, utilisez l’extension pour calculer le pourcentage entre les deux colonnes en divisant le nombre de tempêtes avec des dommages de culture par le nombre total de tempêtes et en multipliant par 100.
Pour vous assurer que vous obtenez un résultat décimal, utilisez la fonction todouble() pour convertir au moins une des valeurs de nombre entier en double avant d’effectuer la division.
StormEvents
| summarize
TotalStormsInState = count(),
StormsWithCropDamage = countif(DamageCrops > 0)
by State
| extend PercentWithCropDamage =
round((todouble(StormsWithCropDamage) / TotalStormsInState * 100), 2)
| sort by StormsWithCropDamage
Sortie
| State | TotalStormsInState | StormsWithCropDamage | PercentWithCropDamage |
|---|---|---|---|
| IOWA | 2337 | 359 | 15.36 |
| NEBRASKA | 1766 | 201 | 11.38 |
| MISSISSIPPI | 1 218 | 105 | 8.62 |
| CAROLINE DU NORD | 1721 | 82 | 4.76 |
| MISSOURI | 2016 | 78 | 3.87 |
| ... | ... | ... | ... |
Remarque
Lors du calcul des pourcentages, convertissez au moins une des valeurs entières de la division avec todouble() ou toreal(). Cela garantit que vous n’obtenez pas de résultats tronqués en raison d’une division entière. Pour plus d’informations, consultez Règles de type pour les opérations arithmétiques.
Calculer le pourcentage en fonction de la taille de la table
Pour comparer le nombre de tempêtes par type d’événement au nombre total de tempêtes dans la base de données, commencez par enregistrer le nombre total de tempêtes dans la base de données sous forme de variable. Laissez les instructions utilisées pour définir des variables dans une requête.
Étant donné que les instructions d’expression tabulaire retournent des résultats tabulaires, utilisez la fonction toscalar() pour convertir le résultat tabulaire de la count() fonction en valeur scalaire. Ensuite, la valeur numérique peut être utilisée dans le calcul du pourcentage.
let TotalStorms = toscalar(StormEvents | summarize count());
StormEvents
| summarize EventCount = count() by EventType
| project EventType, EventCount, Percentage = todouble(EventCount) / TotalStorms * 100.0
Sortie
| Type d’événement | EventCount | Percentage |
|---|---|---|
| Vent d’orage | 13015 | 22.034673077574237 |
| Grêle | 12711 | 21.519994582331627 |
| Crue soudaine | 3688 | 6.2438627975485055 |
| Sécheresse | 3616 | 6.1219652592015716 |
| Météo hivernale | 3349 | 5.669928554498358 |
| ... | ... | ... |
Extraire des valeurs uniques
Utilisez make_set() pour transformer une sélection de lignes dans une table en tableau de valeurs uniques.
La requête suivante utilise make_set() pour créer un tableau des types d’événements qui provoquent des décès dans chaque état. La table résultante est ensuite triée par le nombre de types storm dans chaque tableau.
StormEvents
| where DeathsDirect > 0 or DeathsIndirect > 0
| summarize StormTypesWithDeaths = make_set(EventType) by State
| project State, StormTypesWithDeaths
| sort by array_length(StormTypesWithDeaths)
Sortie
| State | StormTypesWithDeaths |
|---|---|
| CALIFORNIE | ["Vent d’orage »,"High Surf »,"Froid/Refroidissement du vent »,"Vent fort »,"Rip Current »,"Heat »,"Excessive Heat »,"Feu excessif »,"Feu excessif »,"Tempête de poussière »,"Marée basse astronomique »,"Brouillard dense »,"Météo d’hiver"] |
| TEXAS | ["Flash Flood »,"Thunderstorm Wind »,"Tornado »,"Lightning »,"Flood »,"Ice Storm »,"Winter Weather »,"Rip Current »,"Excessive Heat »,"Dense Fog »,"Hurricane (Typhon) »,"Cold/Wind Chill"] |
| OKLAHOMA | ["Flash Flood »,"Tornado »,"Cold/Wind Chill »,"Winter Storm »,"Heavy Snow »,"Excessive Heat »,"Heat »,"Ice Storm »,"Winter Weather »,"Dense Fog"] |
| NEW YORK | ["Flood »,"Lightning »,"Thunderstorm Wind »,"Flash Flood »,"Winter Weather »,"Ice Storm »,"Extreme Cold/Wind Chill »,"Winter Storm »,"Heavy Snow"] |
| KANSAS | ["Vent d’orage »,"Pluie lourde »,"Tornado »,"Inondation »,"Inondation flash »,"Éclair »,"Neige lourde »,"Météo d’hiver »,"Blizzard"] |
| ... | ... |
Données de compartiment par condition
La fonction case() regroupe les données dans des compartiments en fonction des conditions spécifiées. La fonction retourne l’expression de résultat correspondante pour le premier prédicat satisfait ou l’expression finale si aucun des prédicats n’est satisfait.
Cet exemple regroupe les états basés sur le nombre de blessures liées à la tempête que leurs citoyens ont subis.
StormEvents
| summarize InjuriesCount = sum(InjuriesDirect) by State
| extend InjuriesBucket = case (
InjuriesCount > 50,
"Large",
InjuriesCount > 10,
"Medium",
InjuriesCount > 0,
"Small",
"No injuries"
)
| sort by State asc
Sortie
| State | InjuriesCount | BlessuresBucket |
|---|---|---|
| ALABAMA | 494 | Grande |
| ALASKA | 0 | Aucune blessure |
| SAMOA AMÉRICAINES | 0 | Aucune blessure |
| ARIZONA | 6 | Petite |
| ARKANSAS | 54 | Grande |
| ATLANTIQUE NORD | 15 | Moyenne |
| ... | ... | ... |
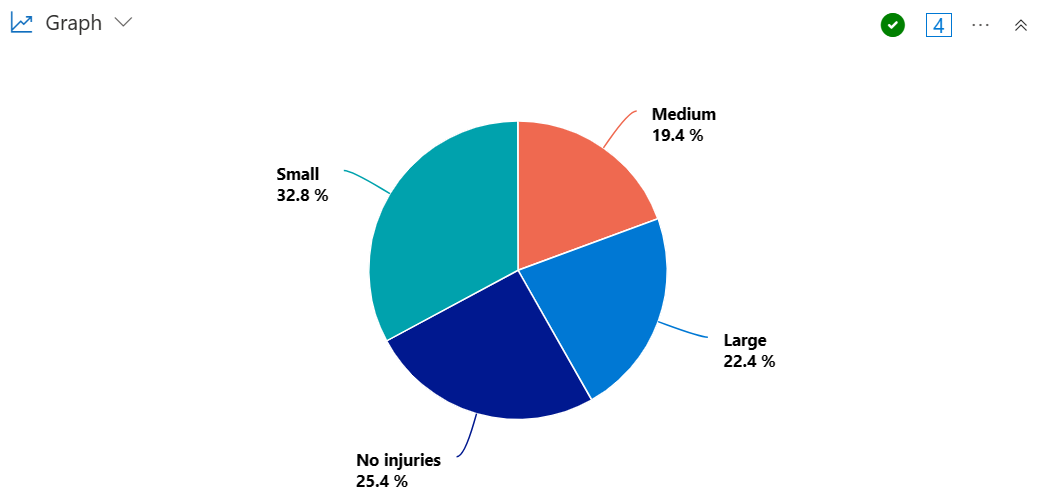
Créez un graphique en secteurs pour visualiser la proportion d’états qui ont connu des tempêtes entraînant un grand, moyen ou petit nombre de blessures.
StormEvents
| summarize InjuriesCount = sum(InjuriesDirect) by State
| extend InjuriesBucket = case (
InjuriesCount > 50,
"Large",
InjuriesCount > 10,
"Medium",
InjuriesCount > 0,
"Small",
"No injuries"
)
| summarize InjuryBucketByState=count() by InjuriesBucket
| render piechart
Effectuer des agrégations sur une fenêtre glissante
L’exemple suivant montre comment synthétiser des colonnes à l’aide d’une fenêtre glissante.
La requête calcule les dommages minimum, maximal et moyen des biens des tornades, des inondations et des feux de forêt à l’aide d’une fenêtre glissante de sept jours. Chaque enregistrement du jeu de résultats regroupe les sept jours précédents et les résultats contiennent un enregistrement par jour dans la période d’analyse.
Voici une explication pas à pas de la requête :
- Binez chaque enregistrement à un seul jour par rapport à
windowStart. - Ajoutez sept jours à la valeur bin pour définir la fin de la plage pour chaque enregistrement. Si la valeur est hors de la plage et
windowStartwindowEndque la valeur est ajustée en conséquence. - Créez un tableau de sept jours pour chaque enregistrement, à partir du jour actuel de l’enregistrement.
- Développez le tableau de l’étape 3 avec mv-expand afin de dupliquer chaque enregistrement à sept enregistrements avec des intervalles d’un jour entre eux.
- Effectuez les agrégations pour chaque jour. En raison de l’étape 4, cette étape résume réellement les sept jours précédents.
- Excluez les sept premiers jours du résultat final, car il n’y a pas de période de recherche de sept jours pour eux.
let windowStart = datetime(2007-07-01);
let windowEnd = windowStart + 13d;
StormEvents
| where EventType in ("Tornado", "Flood", "Wildfire")
| extend bin = bin_at(startofday(StartTime), 1d, windowStart) // 1
| extend endRange = iff(bin + 7d > windowEnd, windowEnd,
iff(bin + 7d - 1d < windowStart, windowStart,
iff(bin + 7d - 1d < bin, bin, bin + 7d - 1d))) // 2
| extend range = range(bin, endRange, 1d) // 3
| mv-expand range to typeof(datetime) // 4
| summarize min(DamageProperty), max(DamageProperty), round(avg(DamageProperty)) by Timestamp=bin_at(range, 1d, windowStart), EventType // 5
| where Timestamp >= windowStart + 7d; // 6
Sortie
Le tableau de résultats suivant est tronqué. Pour voir la sortie complète, exécutez la requête.
| Timestamp | Type d’événement | min_DamageProperty | max_DamageProperty | avg_DamageProperty |
|---|---|---|---|---|
| 2007-07-08T00:00:00Z | Tornade | 0 | 30000 | 6905 |
| 2007-07-08T00:00:00Z | Crue | 0 | 200000 | 9261 |
| 2007-07-08T00:00:00Z | Feu de forêt | 0 | 200000 | 14033 |
| 2007-07-09T00:00:00Z | Tornade | 0 | 100000 | 14783 |
| 2007-07-09T00:00:00Z | Crue | 0 | 200000 | 12529 |
| 2007-07-09T00:00:00Z | Feu de forêt | 0 | 200000 | 14033 |
| 2007-07-10T00:00:00Z | Tornade | 0 | 100000 | 31400 |
| 2007-07-10T00:00:00Z | Crue | 0 | 200000 | 12,263 |
| 2007-07-10T00:00:00Z | Feu de forêt | 0 | 200000 | 11694 |
| ... | ... | ... |
Étape suivante
Maintenant que vous êtes familiarisé avec les opérateurs de requête courants et les fonctions d’agrégation, passez au tutoriel suivant pour découvrir comment joindre des données à partir de plusieurs tables.