Overview of data estate strategy
Integrating healthcare and life sciences data from various systems and applications is a costly and time-intensive undertaking. To address this problem, implementing a data estate strategy becomes crucial as it establishes uniform standards for organizations to efficiently manage all their data, regardless of its storage location or format.
Data estate strategy refers to a comprehensive and structured approach adopted by organizations to manage their entire data ecosystem effectively. It involves developing a well-defined plan and guidelines for acquiring, storing, processing, securing, and utilizing data across various sources, systems, and applications within and across an organization. As healthcare and life sciences institutions handle diverse data, effective data management becomes crucial for maintaining confidentiality, regulatory compliance, and gaining a competitive edge to provide effective care to patients.
Data management in healthcare and life sciences
As the healthcare industry transitions to a value-based care model with an emphasis on patient-centered care, the volume of patient data generated through immersive experiences grows significantly. The exponential growth of healthcare data at various touchpoints necessitates a robust data management strategy to effectively manage and utilize this data to generate actionable insights that can improve the overall health of members and patients.
Data management challenges
Healthcare and life sciences industries are complex and dynamic environments that require a high degree of integration and interoperability to function effectively. A primary challenge with this industry is that the data is traditionally siloed, with different providers and organizations that use different systems and technologies. The absence of integration and interoperability between these systems and technologies lead to inefficiencies, errors, and a lack of continuity in care for patients. These common data management challenges include:
- Data silos: The lack of data sharing between different systems leads to data silos. Healthcare providers have difficulty accessing and sharing patient data, which can lead to a lack of continuity of care.
- Lack of standardization: Healthcare organizations and life sciences companies use different systems and technologies, making it difficult to communicate and exchange data seamlessly.
- Complexity of systems: Healthcare and life sciences systems are increasingly complex and a challenge to integrate and interoperate data effectively. This challenge leads to increased costs and delays in care delivery.
- Malformed or missing data: Malformed or missing data compromise the accuracy and reliability of insights derived from this data.
- Security and privacy concerns: The security and privacy of patient data is critical to healthcare providers and life sciences companies. Sharing data across different systems can increase the risk of data breaches and compromise patient privacy.
- Industry regulations: Healthcare and life sciences industries have the most stringent industry regulations on data handling that makes data sharing and access difficult.
- De-identification of non-uniform data: De-identification of data is often required by law which is difficult and time-consuming.
- Geographically unique datasets: It's difficult to transform geographically unique datasets, such as population health data, for research.
Data management stages
Managing large data effectively involves various stages. Each stage is equally important to generate high quality, actionable insights using the underlying data. The following sections outline the major stages.
Discovery
Data discovery in healthcare and life sciences involves identifying data sources, data formats (such as structured and unstructured), and accessing them. Real-world data and real-world evidence are a few ways to discover data. Real-world data refers to data routinely collected from various sources outside of traditional clinical trials. These sources include electronic health records, claims and billing activities, prescription data, data from wearables, and data collected via patient surveys, or other patient-generated methods. The following image illustrates the most common health care data based on their taxonomy and data standards:

Ingestion
Ingestion is the process of connecting, collecting, and controlling the flow of information from various data sources identified in the discovery stage. The following images illustrate Microsoft's data source options, such as Azure Functions, Azure Logic Apps, and Azure Data Factory, for ingesting different types of information.
Ingestion pipeline to ingest IoT data from medical devices such as smart wearables.
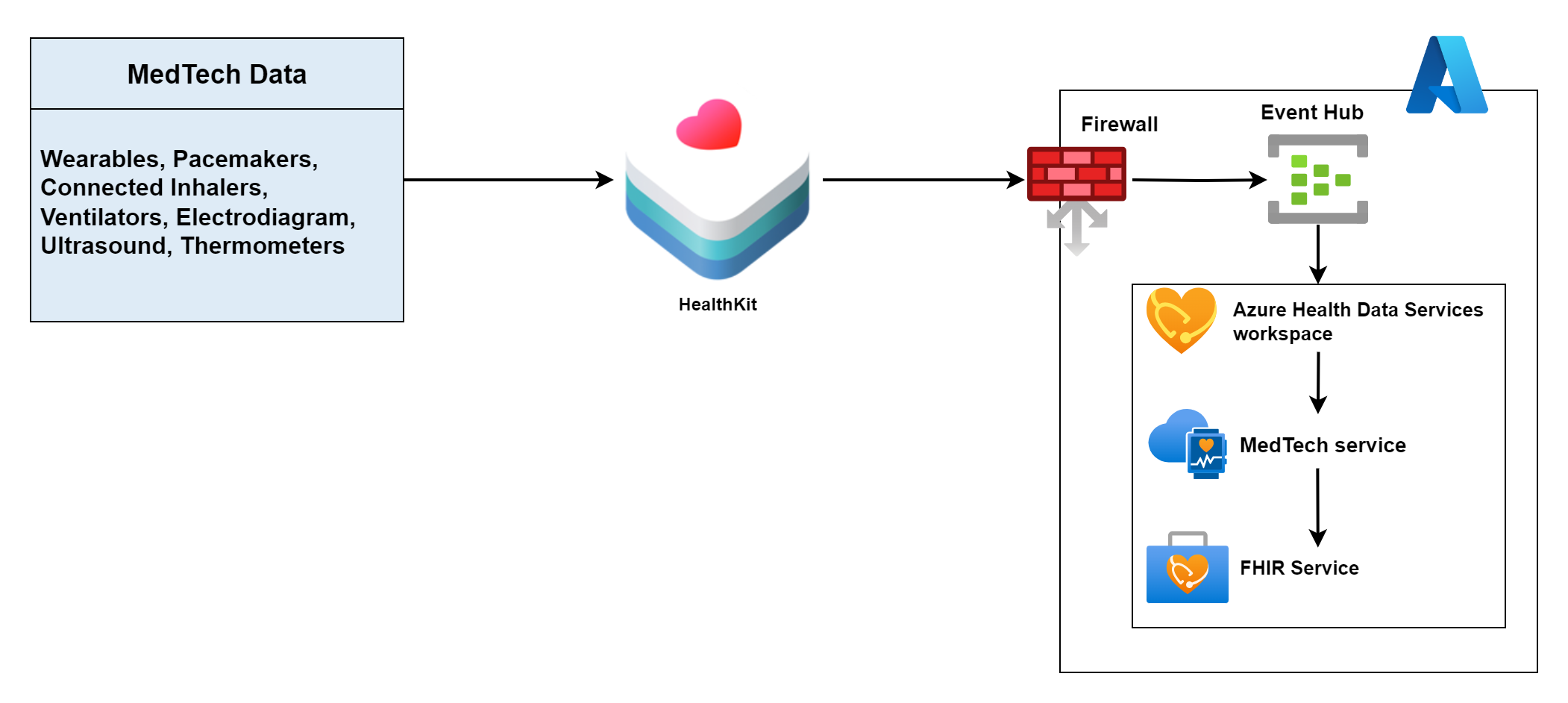
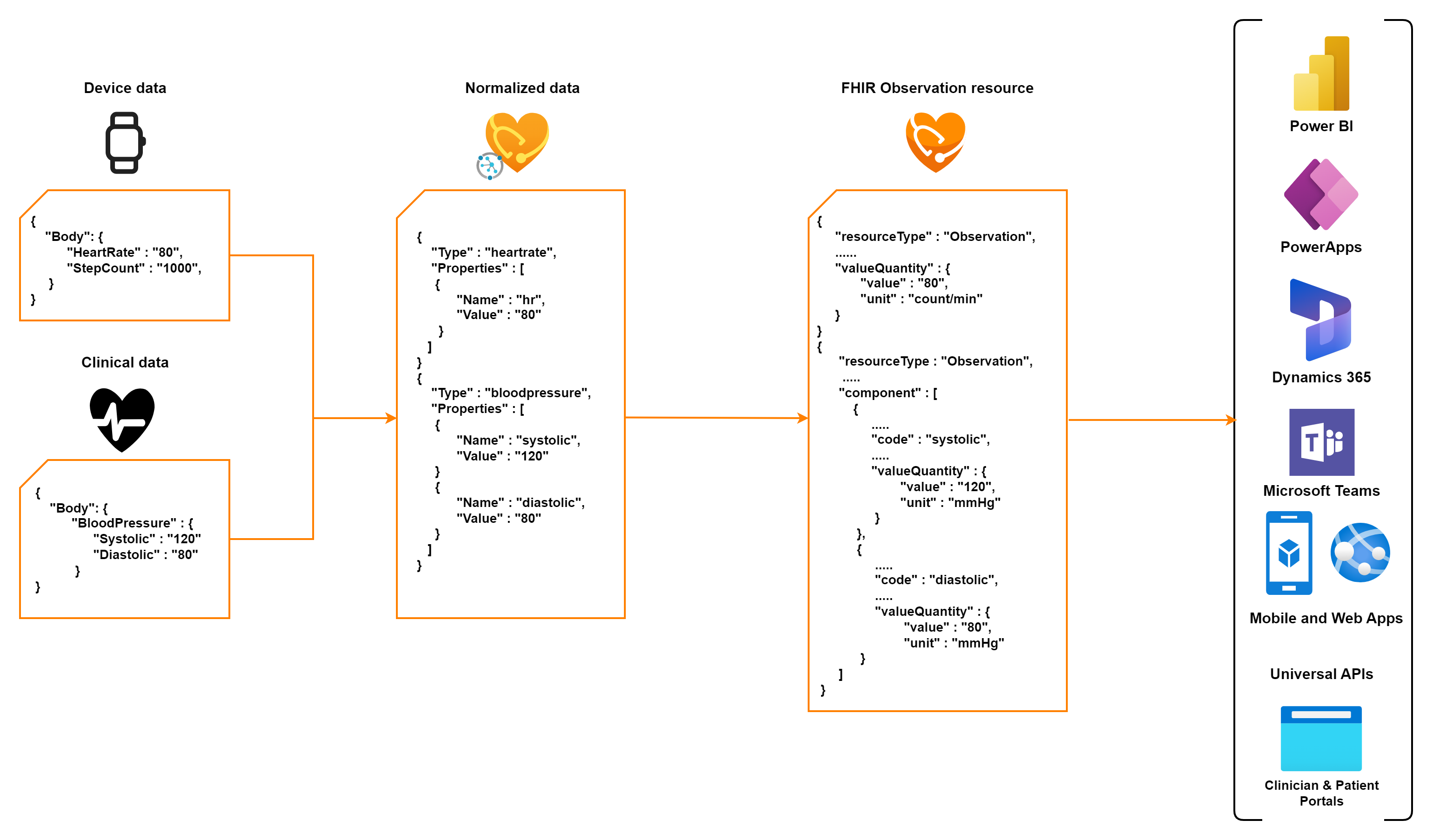
Medical device generated data might not always be in a standard format. Therefore, the data is first normalized and then stored in a FHIR server as a FHIR Observation resource. The MedTech service in Azure Health Data Services automatically performs the steps shown in the following diagram:
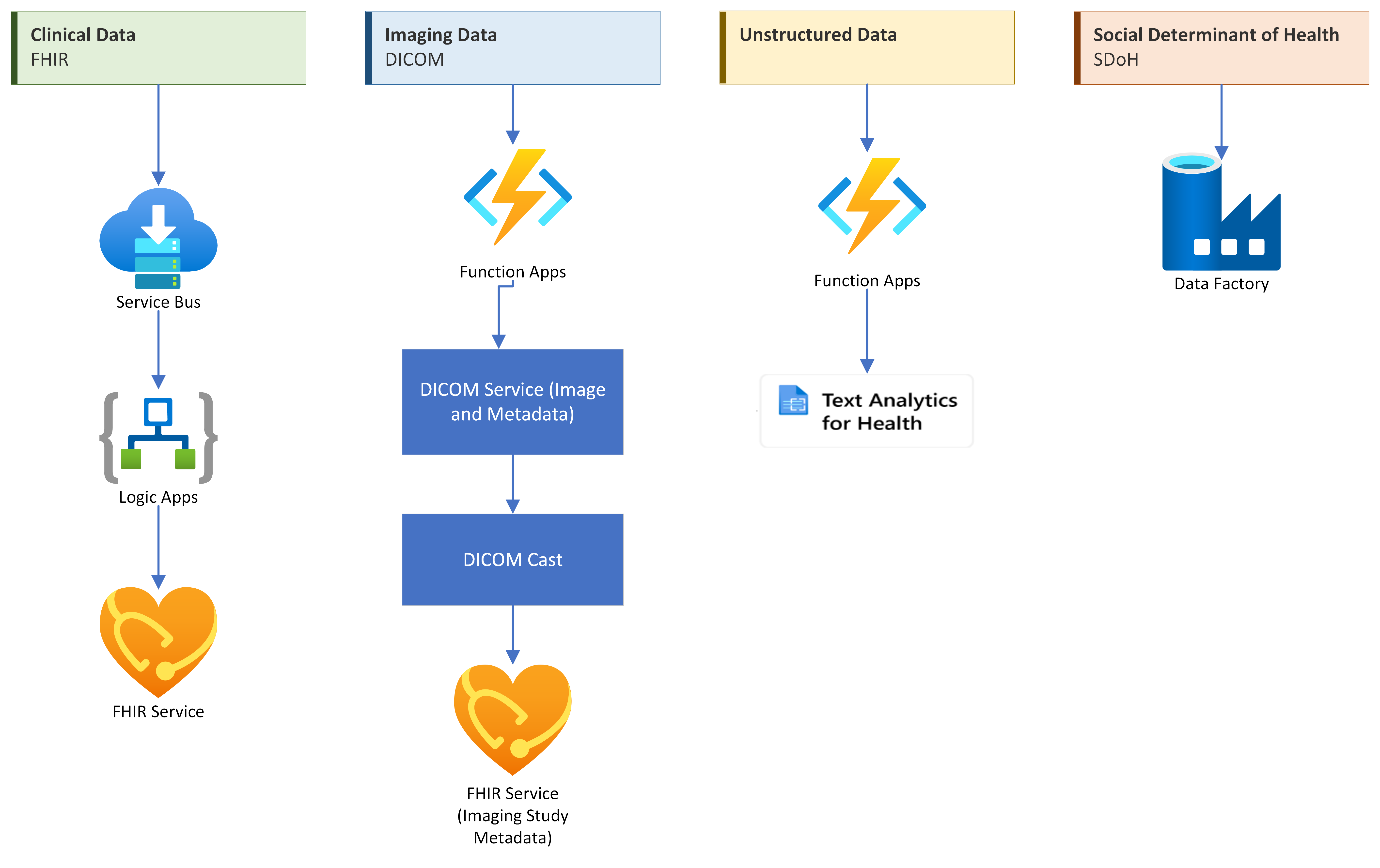
Ingestion pipeline to work with clinical data, DICOM (digital imaging and communications in medicine) data, unstructured data, and SDOH (social determinants of health).



Persistence
Storing ingested data on permanent storage is crucial. It allows other applications, such as a machine learning pipeline, to use and generate insights on the data. It also enables Power BI to visualize the distribution of data. Microsoft provides various data persistence platforms, such as Azure Data Lake storage, Azure Health Data Services, and Dataverse, to store your healthcare data. Microsoft also provides APIs such as FHIR service API, DICOM service, MedTech service, and Dataverse healthcare APIs to ingest data into the provided platform.


Integration
Integration refers to the process of unifying different systems, technologies, data sources, and processes to create a cohesive experience for patients, healthcare providers, and other stakeholders. Microsoft Cloud for Healthcare offers ready-to-use tools to integrate the Dataverse data repository with various healthcare data sources such as Azure Health Data Services and non-Microsoft FHIR servers. The following diagram illustrates the integration of FHIR data to Azure Databricks Delta Lake in Azure Health Data Services. For more information, see Connect FHIR Data to Azure Databricks Delta Lake in Azure Health Data Services.

Intelligence
Intelligence refers to the process of adding intelligence to data to draw deeper insights. Microsoft provides tools such as Azure Machine Learning, cognitive services, Azure Databricks, and Azure Synapse Analytics to add intelligence to healthcare data.
Analytics
Analytics involves analyzing healthcare data to uncover trends and patterns. You can use tools such as Power BI to visualize trends and patterns in healthcare data to improve clinical decision support and enhance operational efficacy.
The following image displays the complete lifecycle of healthcare data:

The following image illustrates the MedTech data lifecycle:

Data management solutions offered by Microsoft
Microsoft offers a wide range of tools to handle and manage healthcare data. The following table provides a comprehensive list of tools to manage healthcare data. For more information, follow the reference link corresponding to each tool.
| Data stage | Tools | Description | Benefits | Reference link |
|---|---|---|---|---|
| Ingestion | FHIR-Bulk Loader and Export | An Azure Function app solution that ingests and exports FHIR data. | FHIR-Bulk Loader can import hundreds of thousands of files per hour. | FHIR-Bulk Loader and Export |
| Ingestion | FHIR Converter | Enables conversion of health data from legacy to FHIR standard. | Supports the following conversions: HL7v2 to FHIR, C-CDA to FHIR, JSON to FHIR, FHIR STU3 to FHIR R4 | FHIR Converter |
| Ingestion | HealthKitOnFhir | A Swift library that automates the export of Apple HealthKit Data to a FHIR server. | HealthKit data can be routed through the IoMT FHIR Connector for Azure for grouping high frequency data and reduce the number of Observation resources generated. You can also directly export the data to a FHIR server (appropriate for low frequency data). | HealthKitOnFhir |
| Persistence | Microsoft Cloud for Healthcare data model | Microsoft Clouds for Healthcare data models are based on the Fast Healthcare Interoperability Resources (FHIR) standards framework and are easily deployable in a Dataverse environment. | It eases implementation of new use cases and workflows without redefining the healthcare data architecture. The FHIR-based models make Dynamics 365 implementations for healthcare customers easier, faster, and more secure. | Data model overview |
| Persistence | Dataverse healthcare APIs | Supports writing FHIR data to Dataverse entities and reading data from Dataverse entities in FHIR format. | Automatically handles transformation of FHIR data to common data model and vice-versa. | Overview of Dataverse healthcare APIs |
| Persistence | Azure Health Data Services | A managed platform as a service (PaaS) which provides a unified platform to store FHIR, DICOM, and MedTech data. | Enables secure and compliant paths to ingest, persist, and connect healthcare data in the cloud. | What is Azure Health Data Services? |
| Integration | Data integration toolkit | Provides an extensive collection of entity maps and attribute maps, built to conform to the HL7 FHIR specification, which are deployed as Dataverse records. | Highly configurable to accommodate various solution requirements. | Overview of data integration toolkit |
| Integration | Virtual health data tables | Supports bringing data directly from a FHIR server into Microsoft Cloud for Healthcare solutions without permanently storing the data in Dataverse entities. | Avoids duplication of data and saves storage costs. | Overview of virtual health data tables |
| Intelligence | Text Analytics for Health | An Azure AI Language API service that uses machine learning intelligence to extract and label medical information from unstructured text such as doctor's notes, discharge summaries, clinical documents, and electronic health records. | Performs named entity recognition, relation extraction, entity linking, and assertion detection, all with a single API call. | What is Text Analytics for health? |
| Analytics | FHIR Service Analytics with Azure Databricks Delta Lake Analytics | Delta Lake is a storage framework that enables building a Lakehouse architecture on top of existing data lake technologies. Azure Health Data Services enables Lakehouse architectures by exporting parquet files of FHIR data which align to the open SQL on FHIR standard. | Combines your FHIR data with other datasets and enables metadata management and data versioning. | FHIR Service Analytics with Azure Databricks Delta Lake Analytics |
| Testing | Synthea | A synthetic patient generator that models medical histories to create realistic yet synthetic patient data and health records across all aspects of healthcare. | The data is free from cost, privacy, and security restrictions, allowing unrestricted use in academia, research, industry, and government. | Synthea wiki |
Related information
There are several commonly used architectures on the Microsoft Cloud for Healthcare platform for working with healthcare data. You can use these architectures as references to customize your solutions for managing healthcare data. For more information, see Microsoft Cloud for Healthcare reference architectures..