Utiliser Microsoft Graph pour augmenter la recherche Microsoft avec des données personnalisées
Cet article décrit un modèle d’intégration Microsoft Graph courant pour un scénario métier qui nécessite l’ajout de données d’entreprise personnalisées à la Recherche Microsoft et aux expériences Microsoft 365 Copilot. Les données personnalisées sont ingérées dans le stockage Microsoft 365 non structuré et ajoutées à différents index de recherche.
Ce scénario non interactif présente les exigences suivantes :
- Type d’intégration de données, car il fournit uniquement des données personnalisées et n’utilise pas la fonctionnalité Microsoft 365 dans les applications clientes.
- Flux de données entrants entre l’application et Microsoft 365.
- Volume de données élevé pour l’indexation.
- Traitement par lot et planification des données pour le chargement et l’ingestion, ce qui entraîne une latence accrue des données.
La meilleure option pour ce scénario consiste à utiliser des connecteurs Microsoft Graph. Le diagramme suivant illustre l’architecture de cette solution.
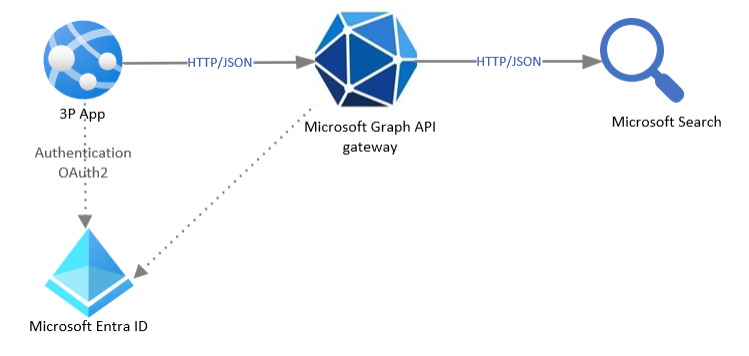
Composants de la solution
L’architecture de cette solution comprend les composants suivants :
- Azure App Service, qui vous permet de créer et d’héberger des applications web, des travaux planifiés et des API RESTful dans votre langage de programmation préféré, sans avoir à gérer l’infrastructure. Il offre une mise à l’échelle automatique et une haute disponibilité, prend en charge Windows et Linux, et permet des déploiements automatisés à partir de GitHub, d’Azure DevOps ou de n’importe quel dépôt Git.
- Microsoft Entra ID, qui est nécessaire pour gérer l’authentification pour Microsoft Graph et prend en charge les autorisations déléguées et d’application pour activer le flux OAuth.
- API RESTful Microsoft Graph, y compris les connecteurs, accessibles via un seul point de terminaison :
https://graph.microsoft.com. - Application personnalisée qui implémente une logique personnalisée.
Considérations
Les considérations suivantes prennent en charge l’utilisation de ce modèle d’intégration :
Disponibilité : l’application cliente envoie régulièrement des données via les API Microsoft Graph. L’application cliente non interactive effectue des requêtes et charge les données à une fréquence contrôlée par l’environnement client et limitée par la limitation des connecteurs Microsoft Graph.
Latence : l’application cliente utilise les API de connecteurs Microsoft Graph synchrones et attend une réponse, mais une certaine latence peut se produire en fonction des conditions réseau et de la charge sur le service Microsoft Graph.
Scalabilité : l’application cliente est limitée à 30 connexions avec pas plus de 50 000 000 éléments par locataire, donc la scalabilité est limitée. Si le volume de données est important, le traitement synchrone peut devenir un défi et un obstacle.
Complexité de la solution : cette solution peut utiliser des connecteurs créés par des éditeurs de logiciels indépendants (ISV), mais si elle accède aux SDK Microsoft Graph ou aux API Microsoft Graph, elle doit sérialiser les données personnalisées dans le format requis pour les connecteurs. Cela offre de la flexibilité, mais augmente également la complexité. Cette solution peut donc aller de faible à moyenne complexité.