Utiliser des tables Iceberg avec OneLake
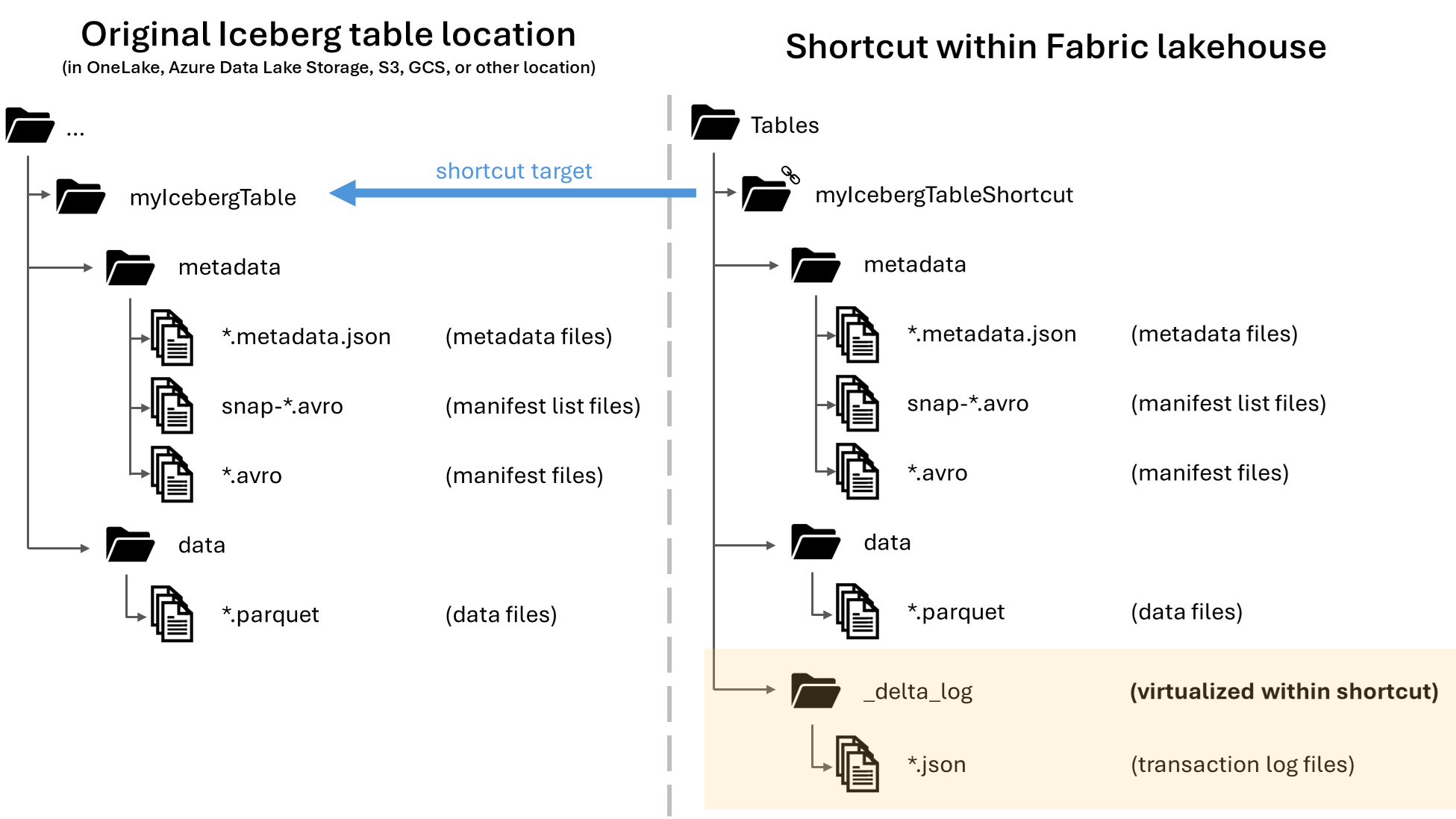
Dans Microsoft OneLake, vous pouvez créer des raccourcis vers vos tables Apache Iceberg, ce qui vous permet de les utiliser avec la grande variété de charges de travail Fabric. Ceci est rendu possible par le biais d’une fonctionnalité appelée virtualisation des métadonnées, qui permet aux tables Iceberg d’être interprétées comme des tables Delta Lake du point de vue du raccourci. Lorsque vous créez un raccourci vers un dossier de table Iceberg, OneLake génère automatiquement les métadonnées Delta Lake correspondantes (le journal Delta) pour cette table, ce qui rend les métadonnées Delta Lake accessibles via le raccourci.
Important
Cette fonctionnalité est en préversion.
Bien que cet article inclut des conseils sur l’écriture de tables Iceberg de Snowflake vers OneLake, cette fonctionnalité est conçue de manière à opérer avec toutes les tables Iceberg avec des fichiers de données Parquet.
Créer un raccourci de table vers une table Iceberg
Si vous disposez déjà d’une table Iceberg dans un emplacement de stockage pris en charge par les raccourcis OneLake, effectuez ces étapes pour créer un raccourci et faire apparaître votre table Iceberg au format Delta Lake.
Localisez votre table Iceberg. Recherchez l’emplacement de stockage de votre table Iceberg, qui peut se trouver dans Azure Data Lake Storage, OneLake, Amazon S3, Google Cloud Storage ou un service de stockage compatible S3.
Remarque
Si vous utilisez Snowflake et que vous ne savez pas où votre table Iceberg est stockée, vous pouvez exécuter l’instruction suivante pour voir l’emplacement de stockage de votre table Iceberg.
SELECT SYSTEM$GET_ICEBERG_TABLE_INFORMATION('<table_name>');L’exécution de cette instruction retourne un chemin d’accès au fichier de métadonnées de la table Iceberg. Ce chemin d’accès vous indique quel compte de stockage contient la table Iceberg. Par exemple, voici les informations pertinentes pour trouver le chemin d’une table Iceberg stockée dans Azure Data Lake Storage :
{"metadataLocation":"azure://<storage_account_path>/<path_within_storage>/<table_name>/metadata/00001-389700a2-977f-47a2-9f5f-7fd80a0d41b2.metadata.json","status":"success"}Votre dossier de table Iceberg doit contenir un dossier
metadata, qui contient lui-même au moins un fichier se terminant par.metadata.json.Dans votre lakehouse Fabric, créez un raccourci dans la zone Tables d’un lakehouse sans schéma.
Remarque
Si vous voyez des schémas tels que
dbosous le dossier Tables de votre lakehouse, cela signifie que le lakehouse est compatible avec les schémas et n’est pas encore compatible avec cette fonctionnalité.
Pour le chemin d’accès cible de votre raccourci, sélectionnez le dossier de la table Iceberg. Le dossier de la table Iceberg contient les dossiers
metadataetdata.Une fois votre raccourci créé, cette table devrait être reflétée automatiquement en tant que table Delta Lake dans votre lakehouse, prête à être utilisée dans Fabric.
Si votre nouveau raccourci de table Iceberg n’apparaît pas comme une table utilisable, consultez la section Résolution des problèmes.
Écrire une table Iceberg dans OneLake à l’aide de Snowflake
Si vous utilisez Snowflake sur Azure, vous pouvez écrire des tables Iceberg dans OneLake en effectuant ces étapes :
Vérifiez que votre capacité Fabric se trouve au même emplacement Azure que votre instance Snowflake.
Identifiez l’emplacement de la capacité Fabric associée à votre lakehouse Fabric. Ouvrez les paramètres de l’espace de travail Fabric qui contient votre lakehouse.
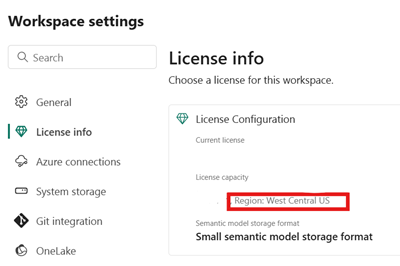
Dans le coin inférieur gauche de votre interface de compte Snowflake sur Azure, vérifiez la région Azure du compte Snowflake.
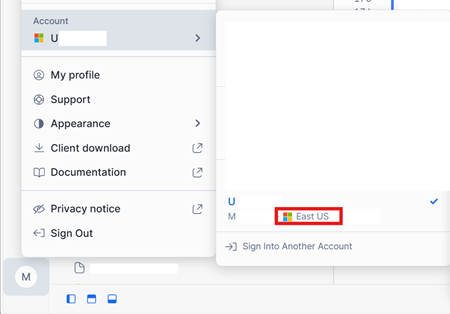
Si ces régions sont différentes, vous devez utiliser une capacité Fabric différente dans la même région que votre compte Snowflake.
Ouvrez le menu de la zone Fichiers de votre lakehouse, sélectionnez Propriétés, puis copiez l’URL (chemin d’accès HTTPS) de ce dossier.
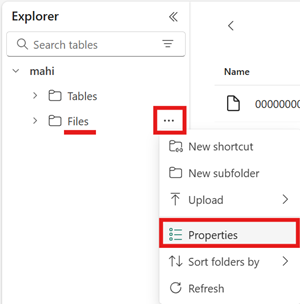
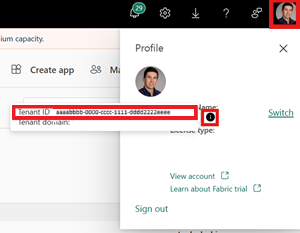
Identifiez votre ID de locataire Fabric. Sélectionnez votre profil utilisateur dans le coin supérieur droit de l’interface utilisateur de Fabric, puis pointez sur la bulle d’informations en regard de votre nom de locataire. Copiez l’ID de locataire.
Dans Snowflake, configurez votre
EXTERNAL VOLUMEà l’aide du chemin d’accès au dossier Files dans votre lakehouse. Vous trouverez ici plus d’informations sur la configuration des volumes externes Snowflake.Remarque
Snowflake exige que le schéma d’URL soit
azure://; veillez donc à remplacerhttps://parazure://.CREATE OR REPLACE EXTERNAL VOLUME onelake_exvol STORAGE_LOCATIONS = ( ( NAME = 'onelake_exvol' STORAGE_PROVIDER = 'AZURE' STORAGE_BASE_URL = 'azure://<path_to_Files>/icebergtables' AZURE_TENANT_ID = '<Tenant_ID>' ) );Dans cet exemple, toutes les tables créées à l’aide de ce volume externe sont stockées dans le lakehouse Fabric, dans le dossier
Files/icebergtables.Maintenant que votre volume externe est créé, exécutez la commande suivante pour récupérer l’URL de consentement et le nom de l’application utilisée par Snowflake pour écrire dans OneLake. Cette application est utilisée par tout autre volume externe dans votre compte Snowflake.
DESC EXTERNAL VOLUME onelake_exvol;La sortie de cette commande retourne les propriétés
AZURE_CONSENT_URLetAZURE_MULTI_TENANT_APP_NAME. Prenez note des deux valeurs. Le nom de l’application multilocataire Azure ressemble à<name>_<number>, mais vous devez uniquement capturer la partie<name>.Ouvrez l’URL de consentement obtenue à l’étape précédente dans un nouvel onglet de navigateur. Si vous souhaitez continuer, consentez aux autorisations d’application requises, si vous y êtes invité.
De retour dans Fabric, ouvrez votre espace de travail et sélectionnez Gérer l’accès, puis Ajouter des personnes ou des groupes. Accordez à l’application utilisée par votre volume externe Snowflake les autorisations nécessaires pour écrire des données dans des lakehouses dans votre espace de travail. Nous vous recommandons d’accorder le rôle Contributeur.
De retour dans Snowflake, utilisez votre nouveau volume externe pour créer une table Iceberg.
CREATE OR REPLACE ICEBERG TABLE MYDATABASE.PUBLIC.Inventory ( InventoryId int, ItemName STRING ) EXTERNAL_VOLUME = 'onelake_exvol' CATALOG = 'SNOWFLAKE' BASE_LOCATION = 'Inventory/';Avec cette instruction, un nouveau dossier de table Iceberg nommé Inventory est créé dans le chemin d’accès au dossier défini dans le volume externe.
Ajoutez des données à votre table Iceberg.
INSERT INTO MYDATABASE.PUBLIC.Inventory VALUES (123456,'Amatriciana');Pour finir, dans la zone Tables du même lakehouse, vous pouvez créer un raccourci OneLake vers votre table Iceberg. Grâce à ce raccourci, votre table Iceberg apparaît sous la forme d’une table Delta Lake et peut être consommée dans les charges de travail Fabric.
Dépannage
Les conseils suivants peuvent vous aider à garantir la compatibilité de vos tables Iceberg avec cette fonctionnalité :
Vérifier la structure de dossiers de votre table Iceberg
Ouvrez votre dossier Iceberg dans l’outil d’explorateur de stockage de votre choix, puis vérifiez la liste des répertoires de votre dossier Iceberg dans son emplacement d’origine. Vous devez voir une structure de dossiers comme celle de l’exemple suivant.
../
|-- MyIcebergTable123/
|-- data/
|-- snow_A5WYPKGO_2o_APgwTeNOAxg_0_1_002.parquet
|-- snow_A5WYPKGO_2o_AAIBON_h9Rc_0_1_003.parquet
|-- metadata/
|-- 00000-1bdf7d4c-dc90-488e-9dd9-2e44de30a465.metadata.json
|-- 00001-08bf3227-b5d2-40e2-a8c7-2934ea97e6da.metadata.json
|-- 00002-0f6303de-382e-4ebc-b9ed-6195bd0fb0e7.metadata.json
|-- 1730313479898000000-Kws8nlgCX2QxoDHYHm4uMQ.avro
|-- 1730313479898000000-OdsKRrRogW_PVK9njHIqAA.avro
|-- snap-1730313479898000000-9029d7a2-b3cc-46af-96c1-ac92356e93e9.avro
|-- snap-1730313479898000000-913546ba-bb04-4c8e-81be-342b0cbc5b50.avro
Si vous ne voyez pas le dossier de métadonnées, ou si vous ne voyez pas de fichiers avec les extensions indiquées dans cet exemple, il se peut que vous n’ayez pas de table Iceberg générée correctement.
Vérifier le journal de conversion
Lorsqu’une table Iceberg est virtualisée en tant que table Delta Lake, un dossier nommé _delta_log/ se trouve à l’intérieur du dossier de raccourci. Ce dossier contient les métadonnées du format Delta Lake (le journal Delta) après la conversion réussie.
Ce dossier inclut également le fichier latest_conversion_log.txt, qui contient les détails relatifs à la réussite ou à l’échec de la dernière tentative de conversion.
Pour afficher le contenu de ce fichier après avoir créé votre raccourci, ouvrez le menu du raccourci de la table Iceberg sous la zone Tables de votre lakehouse et sélectionnez Afficher les fichiers.
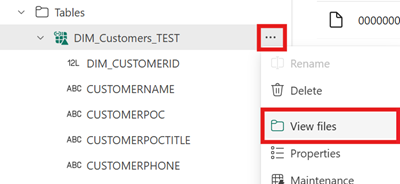
Vous devez voir une structure comme celle de l’exemple suivant :
Tables/
|-- MyIcebergTable123/
|-- data/
|-- <data files>
|-- metadata/
|-- <metadata files>
|-- _delta_log/ <-- Virtual folder. This folder doesn't exist in the original location.
|-- 00000000000000000000.json
|-- latest_conversion_log.txt <-- Conversion log with latest success/failure details.
Ouvrez le fichier journal de conversion pour afficher les détails relatifs à l’heure ou à l’échec de la dernière conversion. Si vous ne voyez pas de fichier journal de conversion, cela signifie que la conversion n’a pas été tentée.
Si la conversion n’a pas été tentée
Si vous ne voyez pas de fichier journal de conversion, cela signifie que la conversion n’a pas été tentée. Voici deux raisons courantes pour lesquelles la conversion n’est pas tentée :
Le raccourci n’a pas été créé au bon endroit.
Pour qu’un raccourci vers une table Iceberg soit converti au format Delta Lake, il doit être placé directement sous le dossier Tables d’un lakehouse sans schéma. Vous ne devez pas placer le raccourci dans la section Fichiers ou sous un autre dossier si vous souhaitez que la table soit automatiquement virtualisée en tant que table Delta Lake.
Le chemin d’accès cible du raccourci n’est pas le chemin d’accès du dossier Iceberg.
Lorsque vous créez le raccourci, le chemin d’accès du dossier que vous sélectionnez dans l’emplacement de stockage cible doit uniquement être le dossier de la table Iceberg. Ce dossier contient les dossiers
metadataetdata.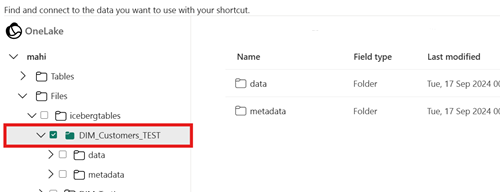
Limitations et considérations
Gardez à l’esprit les limitations temporaires suivantes lorsque vous utilisez cette fonctionnalité :
Types de données prises en charge
Les types de données de colonne Iceberg suivants sont mappés à leurs types Delta Lake correspondants à l’aide de cette fonctionnalité.
Type de colonne Iceberg Type de colonne Delta Lake Commentaires intintegerlonglongConsultez Problème de largeur de type. floatfloatdoubledoubleConsultez Problème de largeur de type. decimal(P, S)decimal(P, S)Consultez Problème de largeur de type. booleanbooleandatedatetimestamptimestamp_ntzLe type de données Iceberg timestampne contient pas d’informations de fuseau horaire. Le type Delta Laketimestamp_ntzn’est pas entièrement pris en charge dans les charges de travail Fabric. Nous vous recommandons d’utiliser des horodatages avec des fuseaux horaires inclus.timestamptztimestampDans Snowflake, pour utiliser ce type, spécifiez timestamp_ltzcomme type de colonne lors de la création de la table Iceberg. Vous trouverez ici plus d’informations sur les types de données Iceberg pris en charge dans Snowflake.stringstringbinarybinaryProblème de largeur de type
Si vous utilisez Snowflake pour écrire votre table Iceberg et que la table contient des types de colonnes
INT64,doubleouDecimalavec précision >= 10, il se peut que la table Delta Lake virtuelle résultante ne soit pas consommable par tous les moteurs Fabric. Des erreurs telles que la suivante peuvent s’afficher :Parquet column cannot be converted in file ... Column: [ColumnA], Expected: decimal(18,4), Found: INT32.Nous recherchons une solution à ce problème.
Solution de contournement : Si vous utilisez l’interface utilisateur d’aperçu de la table Lakehouse et que vous voyez ce problème, vous pouvez résoudre cette erreur en basculant vers l’affichage de point de terminaison SQL (en haut à droite, sélectionnez l’affichage Lakehouse et basculez vers le point de terminaison SQL) et en affichant un aperçu de la table à partir de là. Si vous revenez ensuite à l’affichage de Lakehouse, l’aperçu de table doit s’afficher correctement.
Si vous exécutez un notebook ou un travail Spark et que vous rencontrez ce problème, vous pouvez résoudre cette erreur en définissant la configuration Spark
spark.sql.parquet.enableVectorizedReadersurfalse. Voici un exemple de commande PySpark à exécuter dans un notebook Spark :spark.conf.set("spark.sql.parquet.enableVectorizedReader","false")Le stockage des métadonnées de table iceberg n’est pas portable
Les fichiers de métadonnées d’une table Iceberg se font référence les uns aux autres à l’aide de références de chemins d’accès absolus. Si vous copiez ou déplacez le contenu du dossier d’une table Iceberg vers un autre emplacement sans réécrire les fichiers de métadonnées Iceberg, la table devient illisible par les lecteurs Iceberg, y compris cette fonctionnalité OneLake.
Solution de contournement :
Si vous devez déplacer votre table Iceberg vers un autre emplacement pour utiliser cette fonctionnalité, utilisez l’outil qui a écrit initialement la table Iceberg pour écrire une nouvelle table Iceberg à l’emplacement souhaité.
Les tables icebergs doivent être plus profondes que le niveau racine
Le dossier de la table Iceberg dans le stockage doit se trouver dans un répertoire plus profond que le niveau compartiment ou conteneur. Les tables iceberg stockées directement dans le répertoire racine d’un compartiment ou d’un conteneur ne peuvent pas être virtualisées au format Delta Lake.
Nous travaillons à une amélioration afin de supprimer cette exigence.
Solution de contournement :
Vérifiez que toutes les tables Iceberg sont stockées dans un répertoire plus profond que le répertoire racine d’un compartiment ou d’un conteneur.
Les dossiers de table Iceberg ne doivent contenir qu’un seul ensemble de fichiers de métadonnées
Si vous supprimez et recréez une table Iceberg dans Snowflake, les fichiers de métadonnées ne sont pas nettoyés. Ce comportement prend en charge la fonctionnalité
UNDROPdans Snowflake. Toutefois, étant donné que votre raccourci pointe directement vers un dossier et que ce dossier comporte désormais plusieurs ensembles de fichiers de métadonnées, nous ne pouvons pas convertir la table tant que vous n’avez pas supprimé les fichiers de métadonnées de l’ancienne table.Actuellement, la conversion est tentée dans ce scénario, ce qui peut entraîner l’affichage d’anciennes informations de schéma et de contenu de table dans la table Delta Lake virtualisée.
Nous travaillons sur un correctif où la conversion échoue si plusieurs ensembles de fichiers de métadonnées sont détectés dans le dossier de métadonnées de la table Iceberg.
Solution de contournement :
Pour veiller à ce que la table convertie reflète la version correcte de la table :
- Vérifiez que vous ne stockez pas plusieurs tables Iceberg dans le même dossier.
- Nettoyez tout contenu d’un dossier de table Iceberg après l’avoir supprimé, avant de recréer la table.
Les modifications apportées aux métadonnées ne sont pas immédiatement reflétées
Si vous apportez des modifications de métadonnées à votre table Iceberg, telles que l’ajout d’une colonne, la suppression d’une colonne, le changement de nom d’une colonne ou la modification d’un type de colonne, la table peut ne pas être reconvertie tant qu’une modification de données (comme l’ajout d’une ligne de données) n’a pas été apportée.
Nous travaillons sur un correctif qui récupère le fichier de métadonnées le plus récent qui inclut la dernière modification des métadonnées.
Solution de contournement :
Après avoir effectué la modification du schéma de votre table Iceberg, ajoutez une ligne de données ou apportez toute autre modification aux données. Après cette modification, vous devriez être en mesure d’actualiser et d’afficher la vue la plus récente de votre table dans Fabric.
Les espaces de travail avec schéma ne sont pas encore pris en charge
Si vous créez un raccourci Iceberg dans un lakehouse avec schéma, la conversion ne se produit pas pour ce raccourci.
Nous travaillons à une amélioration pour supprimer cette limitation.
Solution de contournement :
Utilisez un lakehouse sans schéma avec cette fonctionnalité. Vous pouvez configurer ce paramètre lors de la création du lakehouse.
Limitation relative à la disponibilité régionale
Cette fonctionnalité n’est pas encore disponible dans les régions suivantes :
- Qatar Centre
- Norvège Ouest
Solution de contournement :
Les espaces de travail attachés aux capacités Fabric dans d’autres régions peuvent utiliser cette fonctionnalité. Consultez la liste complète des régions où Microsoft Fabric est disponible.
Les liaisons privées ne sont pas prises en charge
Cette fonctionnalité n’est actuellement pas prise en charge pour les locataires ou les espaces de travail pour lesquels les liaisons privées sont activées.
Nous travaillons à une amélioration pour supprimer cette limitation.
Limitation relative à la taille des tables
Il existe une limitation temporaire de la taille de la table Iceberg prise en charge par cette fonctionnalité. Le nombre maximal de fichiers de données Parquet pris en charge est d’environ 5 000 fichiers de données, ou environ 1 milliard de lignes (la limite rencontrée en premier s’applique).
Nous travaillons à une amélioration pour supprimer cette limitation.
Les raccourcis OneLake doivent être dans la même région
Il existe une limitation temporaire concernant l’utilisation de cette fonctionnalité avec des raccourcis qui pointent vers des emplacements OneLake : l’emplacement cible du raccourci doit se trouver dans la même région que le raccourci lui-même.
Nous travaillons à une amélioration afin de supprimer cette exigence.
Solution de contournement :
Si vous avez un raccourci OneLake vers une table Iceberg dans un autre lakehouse, vérifiez que l’autre lakehouse est associé à une capacité dans la même région.
commutateur de locataire autorisant l’accès externe
Nous avons une limitation temporaire qui exige que les « Les utilisateurs peuvent accéder aux données stockées dans OneLake avec des applications externes à Fabric » paramètre de locataire à activer.
Si ce paramètre de locataire est désactivé, la virtualisation des tables Iceberg au format Delta Lake ne réussit pas.
Solution de contournement :
Demandez à l'administrateur de votre locataire Fabric d'activer le paramètre de locataire « Les utilisateurs peuvent accéder aux données stockées dans OneLake avec des applications externes à Fabric », si possible.
Les tables Iceberg doivent être en copie sur écriture (et non pas en fusion en lecture)
Actuellement, les tables Iceberg doivent être de copie en écriture. Cela signifie qu’ils ne peuvent pas contenir de fichiers de suppression ou être de fusion en lecture.
Snowflake produit actuellement copie sur écriture tables Iceberg, mais d’autres auteurs d’icebergs peuvent suivre une approche différente.
Nous travaillons sur la prise en charge des tables Iceberg de fusion en lecture.
Contenu connexe
- En savoir plus sur Fabric et sécurité OneLake.
- Apprenez-en davantage sur les raccourcis OneLake.