Intégrer OneLake à Azure Synapse Analytics
Azure Synapse est un service d’analyse illimité qui rassemble l’entreposage de données d’entreprise et l’analyse Big Data. Ce tutoriel montre comment se connecter à OneLake à l’aide d’Azure Synapse Analytics.
Écrire des données à partir de Synapse à l’aide d’Apache Spark
Suivez ces étapes pour utiliser Apache Spark afin d’écrire des exemples de données dans OneLake à partir d’Azure Synapse Analytics.
Ouvrez votre espace de travail Synapse et créez un pool Apache Spark avec vos paramètres préférés.
Créez un notebook Apache Spark.
Ouvrez le notebook, définissez la langue sur PySpark (Python) et connectez-le à votre pool Spark nouvellement créé.
Dans un onglet distinct, accédez à votre lakehouse Microsoft Fabric et recherchez le dossier Tables de niveau supérieur.
Cliquez avec le bouton droit sur le dossier Tables et sélectionnez Propriétés.
Copiez le chemin ABFS à partir du volet propriétés.
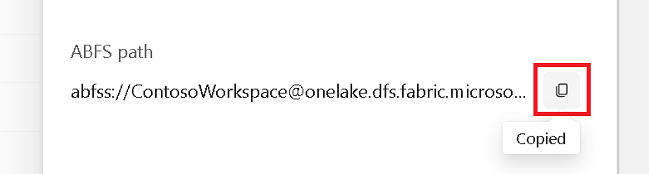
Revenez dans le bloc-notes Azure Synapse, dans la première nouvelle cellule de code, et indiquez le chemin lakehouse. Ce lakehouse est l’endroit où vos données sont écrites ultérieurement. Exécutez la cellule.
# Replace the path below with the ABFS path to your lakehouse Tables folder. oneLakePath = 'abfss://WorkspaceName@onelake.dfs.fabric.microsoft.com/LakehouseName.lakehouse/Tables'Dans une nouvelle cellule de code, chargez les données d’un jeu de données ouvert Azure dans un dataframe. Ce jeu de données est celui que vous chargez dans votre lakehouse. Exécutez la cellule.
yellowTaxiDf = spark.read.parquet('wasbs://nyctlc@azureopendatastorage.blob.core.windows.net/yellow/puYear=2018/puMonth=2/*.parquet') display(yellowTaxiDf.limit(10))Dans une nouvelle cellule de code, filtrez, transformez ou préparez vos données. Pour ce scénario, vous pouvez réduire votre jeu de données pour un chargement plus rapide, joindre d’autres jeux de données ou filtrer des résultats spécifiques. Exécutez la cellule.
filteredTaxiDf = yellowTaxiDf.where(yellowTaxiDf.tripDistance>2).where(yellowTaxiDf.passengerCount==1) display(filteredTaxiDf.limit(10))Dans une nouvelle cellule de code, à l’aide de votre chemin OneLake, écrivez votre dataframe filtré dans une nouvelle table Delta-Parquet dans votre lakehouse Fabric. Exécutez la cellule.
filteredTaxiDf.write.format("delta").mode("overwrite").save(oneLakePath + '/Taxi/')Enfin, dans une nouvelle cellule de code, vérifiez que vos données ont été correctement écrites en lisant votre fichier récemment chargé à partir de OneLake. Exécutez la cellule.
lakehouseRead = spark.read.format('delta').load(oneLakePath + '/Taxi/') display(lakehouseRead.limit(10))
Félicitations ! Vous pouvez désormais lire et écrire des données dans OneLake à l’aide d’Apache Spark dans Azure Synapse Analytics.
Lire des données à partir de Synapse à l’aide de SQL
Suivez ces étapes pour utiliser SQL serverless afin de lire les données de OneLake à partir d’Azure Synapse Analytics.
Ouvrez un lakehouse Fabric et identifiez une table que vous souhaitez interroger à partir de Synapse.
Cliquez avec le bouton droit sur la table et sélectionnez Propriétés.
Copiez le chemin ABFS de la table.
Ouvrez votre espace de travail Synapse dans Synapse Studio.
Un nouveau script SQL est alors créé.
Dans l’éditeur de requête SQL, entrez la requête suivante, en remplaçant
ABFS_PATH_HEREpar le chemin que vous avez copié précédemment.SELECT TOP 10 * FROM OPENROWSET( BULK 'ABFS_PATH_HERE', FORMAT = 'delta') as rows;Exécutez la requête pour afficher les 10 premières lignes de votre table.
Félicitations ! Vous pouvez désormais lire des données à partir de OneLake à l’aide de SQL serverless dans Azure Synapse Analytics.