Tutoriel : Ingérer des données dans un entrepôt
S'applique à :✅ Entrepôt dans Microsoft Fabric
Dans ce tutoriel, découvrez comment ingérer des données à partir de Microsoft Azure Storage dans un entrepôt pour créer des tables.
Remarque
Ce tutoriel fait partie d’un scénario de bout en bout. Pour suivre ce didacticiel, vous devez d’abord suivre ces didacticiels :
Ingérer des données
Dans cette tâche, découvrez comment ingérer des données dans l’entrepôt pour créer des tables.
Vérifiez que l’espace de travail que vous avez créé dans le premier didacticiel est ouvert.
Dans le volet d’accueil de l’espace de travail, sélectionnez + Nouvel élément pour afficher la liste complète des types d’éléments disponibles.
Dans la liste, dans la section Obtenir des données, sélectionnez l'élément de type pipeline de données.
Dans la fenêtre Nouveau pipeline, dans la zone Nom, entrez
Load Customer Data.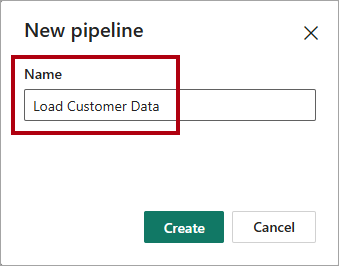
Pour approvisionner le pipeline, sélectionnez Créer. La configuration est terminée lorsque la page d'accueil Construire un pipeline de données s'affiche.
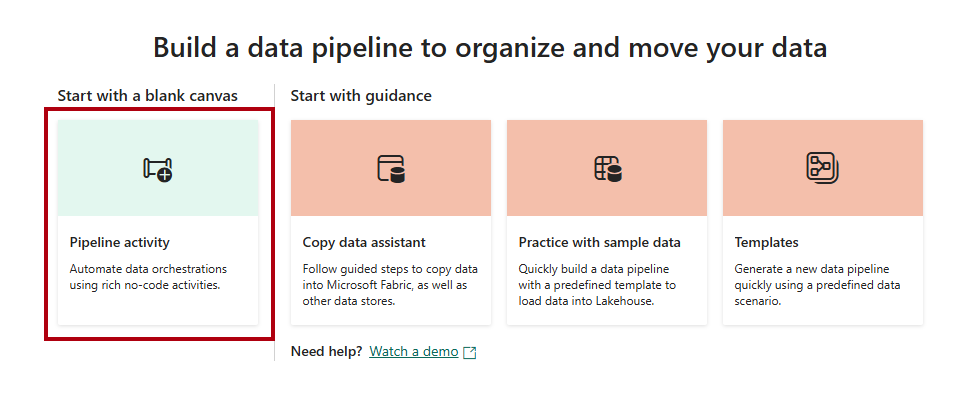
Dans la page d'accueil du pipeline de données, sélectionnez Activité du pipeline.
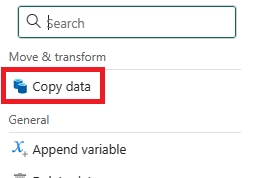
Dans le menu, dans la section Déplacer et transformer, sélectionnez Copier des données.
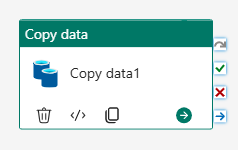
Dans le canevas de conception de pipeline, sélectionnez l'activité Copier les données.
Pour configurer l’activité, dans la page
Général , dans la zone Nom, remplacez le texte par défaut par . 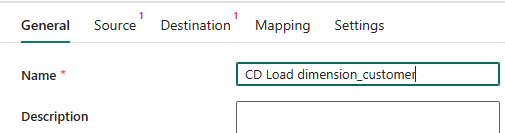
Dans la page Source, dans la liste déroulante Connexion, sélectionnez Autres pour afficher toutes les sources de données disponibles, y compris celles dans le catalogue OneLake .
Sélectionnez + Nouveau pour créer une source de données.
Recherchez, puis sélectionnez, Blobs Azure.
Dans la page Connecter la source de données, dans la zone Nom du compte ou URL, entrez
https://fabrictutorialdata.blob.core.windows.net/sampledata/.Notez que la liste déroulante Nom de connexion est automatiquement renseignée et que le type d’authentification est défini sur anonyme.
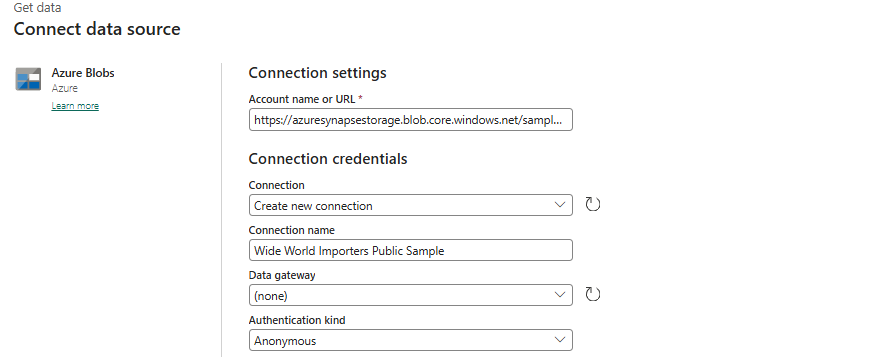
Sélectionnez Connecter.
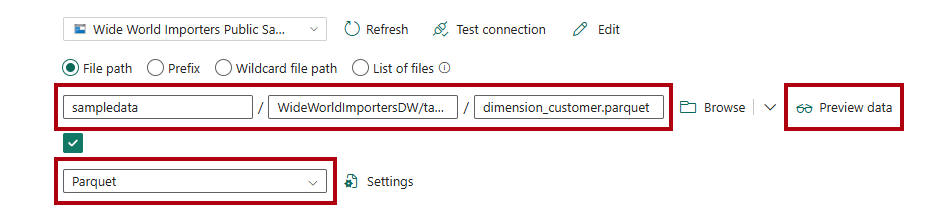
Dans la page Source, pour accéder aux fichiers Parquet dans la source de données, complétez les paramètres suivants :
Dans les zones Chemin d’accès au fichier, entrez :
chemin d’accès au fichier - Conteneur :
sampledataFile path - Directory :
WideWorldImportersDW/tablesFile path - File name :
dimension_customer.parquet
Dans la liste déroulante Format de fichier, sélectionnez Parquet.
Pour afficher un aperçu des données et tester qu’il n’existe aucune erreur, sélectionnez aperçu des données.
Dans la page Destination, dans la liste déroulante Connexion, sélectionnez l’entrepôt
Wide World Importers.Pour l’option Table, sélectionnez l'option Créer automatiquement une table.
Dans la première zone Table, insérez
dbo.Dans la deuxième case, entrez
dimension_customer.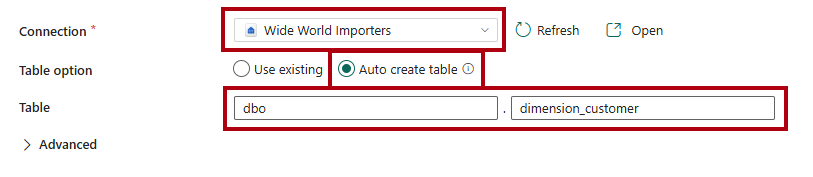
Dans le ruban Accueil, sélectionnez Exécuter.
Dans la boîte de dialogue Enregistrer et exécuter ?, sélectionnez Enregistrer et exécuter pour que le pipeline charge la table
dimension_customer.
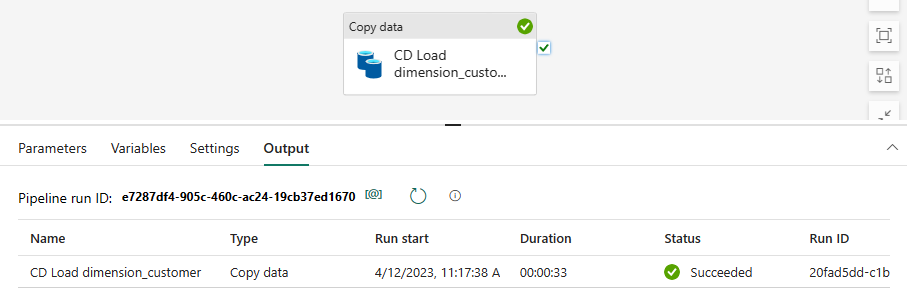
Pour surveiller la progression de l’activité de copie, passez en revue les activités d'exécution du pipeline sur la page Sortie (attendez qu'elle se termine avec un état terminé avec succès).




Étape suivante
tutoriel : Créer des tables avec T-SQL dans un d’entrepôt