Ingérer des données dans votre entrepôt à l'aide de pipelines de données
S'applique à : ✅ Entrepôt dans Microsoft Fabric
Les pipelines de données offrent une alternative à l’utilisation de la commande COPY via une interface graphique utilisateur. Un pipeline de données constitue un regroupement logique d’activités qui exécutent ensemble une tâche d’ingestion des données. Les pipelines vous permettent de gérer les activités d’extraction, de transformation et de chargement (ETL) au lieu de les gérer individuellement.
Dans ce tutoriel, vous allez créer un pipeline qui charge des exemples de données dans un entrepôt dans Microsoft Fabric.
Remarque
Certaines fonctionnalités d’Azure Data Factory ne sont pas disponibles dans Microsoft Fabric, mais les concepts sont interchangeables. Vous pouvez en savoir plus sur Azure Data Factory et les pipelines en consultant Pipelines et activités dans Azure Data Factory et Azure Synapse Analytics. Pour obtenir un guide de démarrage rapide, consultez Démarrage rapide : créer votre premier pipeline pour copier des données.
Créer un pipeline de données
Pour créer un pipeline, accédez à votre espace de travail, sélectionnez le bouton +Nouveau, puis Pipeline de données.
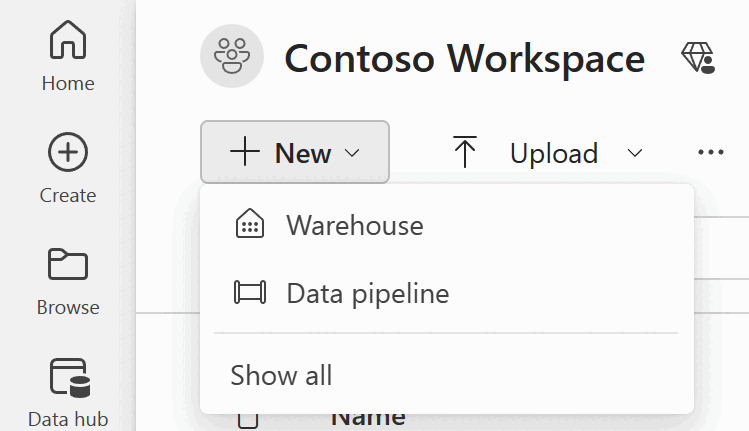
Pour créer un pipeline, accédez à votre espace de travail, sélectionnez le bouton + Nouvel Élement et sélectionnez Pipeline de données.
- Dans votre espace de travail, sélectionnez
+ Nouvel élément et recherchez la carte de pipeline de donnéesdans la section Obtenir des données . - Vous pouvez également sélectionner Créer dans le volet de navigation. Recherchez la carte Data pipeline (pipeline de données) dans la section Data Factory.
- Dans votre espace de travail, sélectionnez
Dans la boîte de dialogue Nouveau pipeline, indiquez un nom pour votre nouveau pipeline, puis sélectionnez Créer.
Vous arriverez dans la zone de canevas du pipeline, où vous trouverez des options pour commencer.
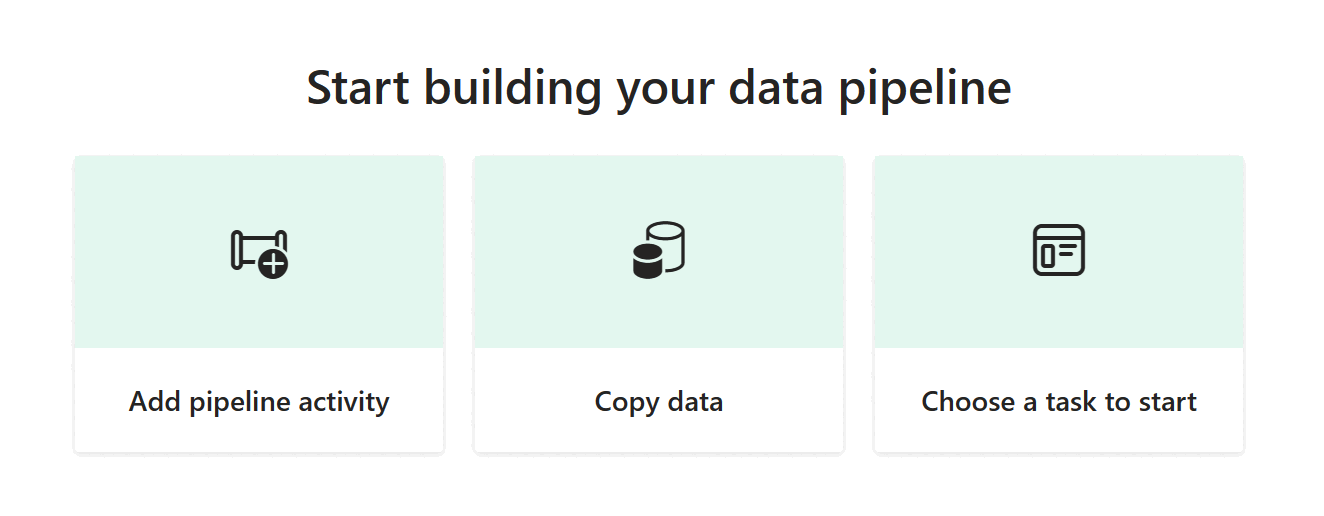
Sélectionnez l’option Assistant de copie de données pour lancer l’assistant de copie.
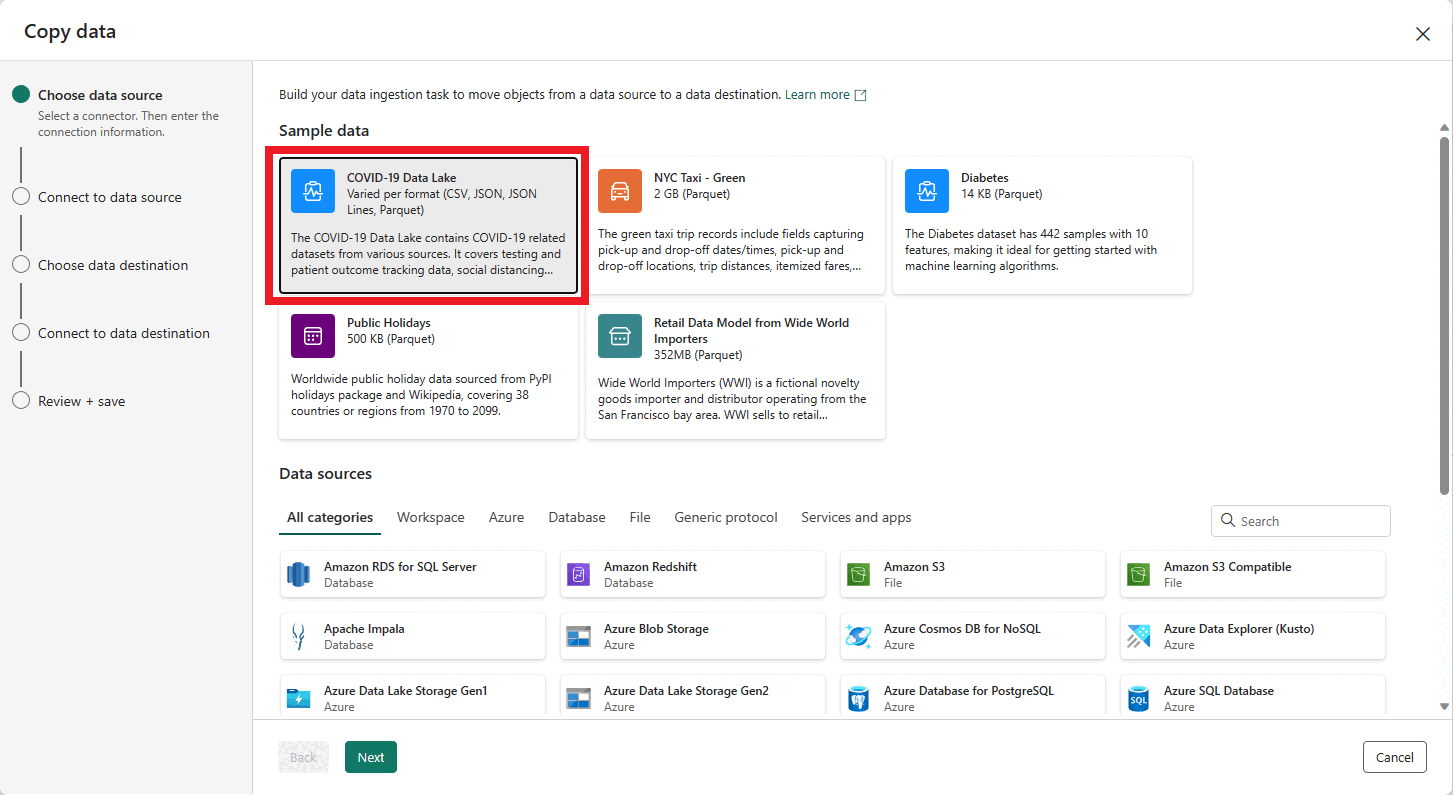
La première page de l’assistant Copier des données vous permet de choisir vos propres données à partir de différentes sources de données, ou de sélectionner l’un des exemples fournis pour commencer. Sélectionnez Exemples de données dans la barre de menu de cette page. Pour ce tutoriel, nous allons utiliser l’échantillon COVID-19 Data Lake. Sélectionnez cette option, puis Suivant.
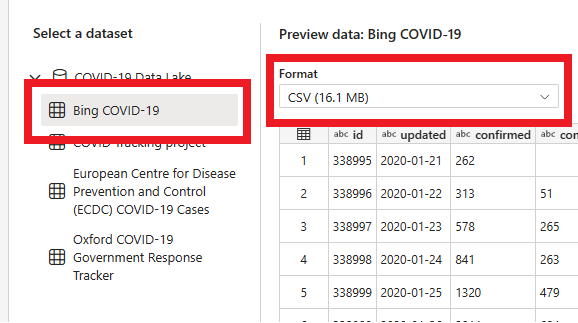
Dans la page suivante, vous pouvez sélectionner un jeu de données, le format de fichier source et afficher un aperçu du jeu de données sélectionné. Sélectionnez Bing COVID-19, le format CSV, puis sélectionnez suivant.
La page suivante, Destination des données, vous permet de configurer le type l’espace de travail de destination. Nous allons charger des données dans un entrepôt dans notre espace de travail. Sélectionnez l’entrepôt souhaité dans la liste déroulante, puis Suivant.
La dernière étape pour configurer la destination consiste à fournir un nom à la table de destination et à configurer les mappages de colonnes. Ici, vous pouvez choisir de charger les données dans une nouvelle table ou dans une table existante, fournir un schéma et des noms de table, modifier les noms de colonnes, supprimer des colonnes ou modifier leurs mappages. Vous pouvez accepter les valeurs par défaut ou ajuster les paramètres selon votre préférence.
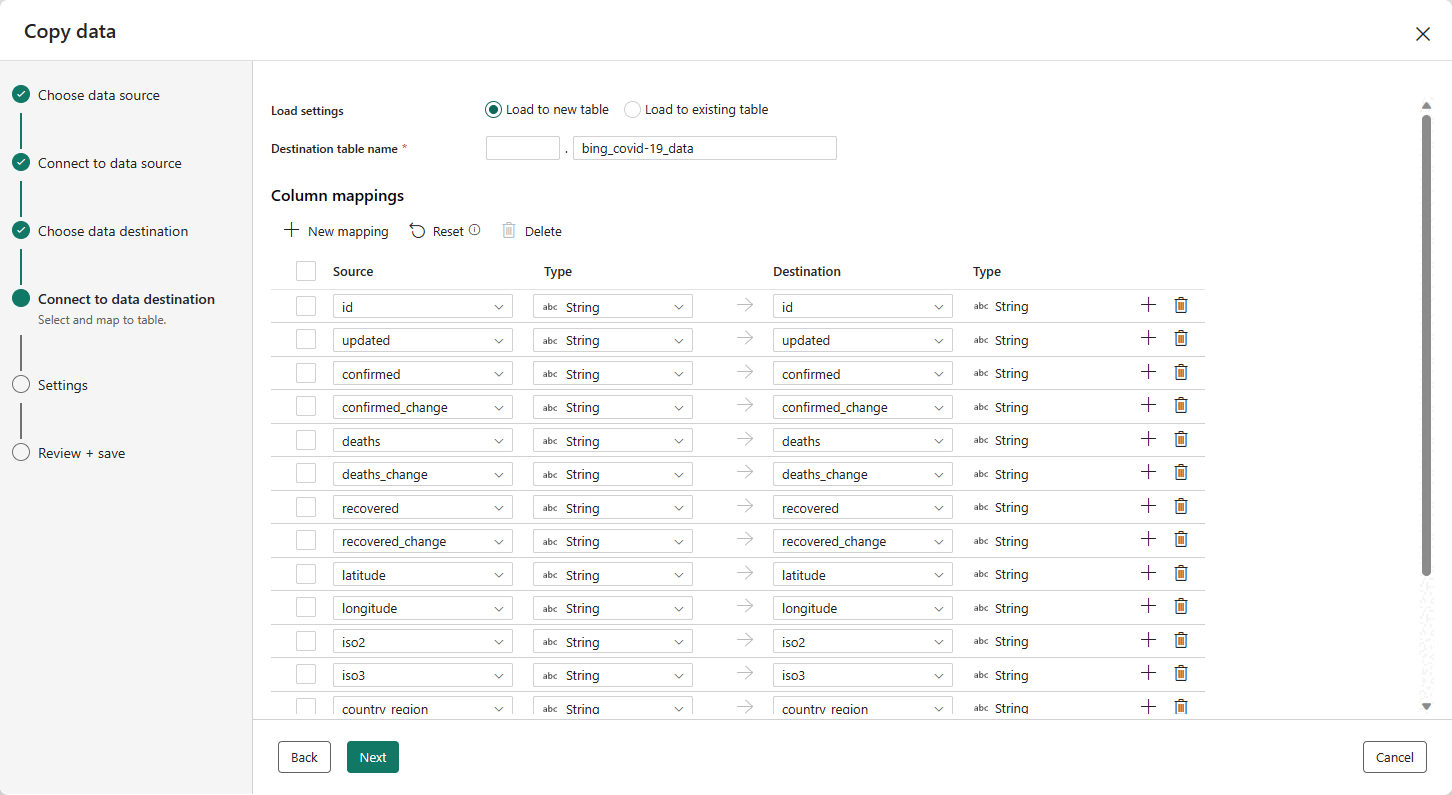
Lorsque vous avez terminé d’examiner les options, sélectionnez Suivant.
La page suivante vous donne la possibilité d’utiliser la gestion intermédiaire ou de fournir des options avancées pour l’opération de copie de données (qui utilise la commande T-SQL COPY). Passez en revue les options sans les modifier, puis sélectionnez suivant.
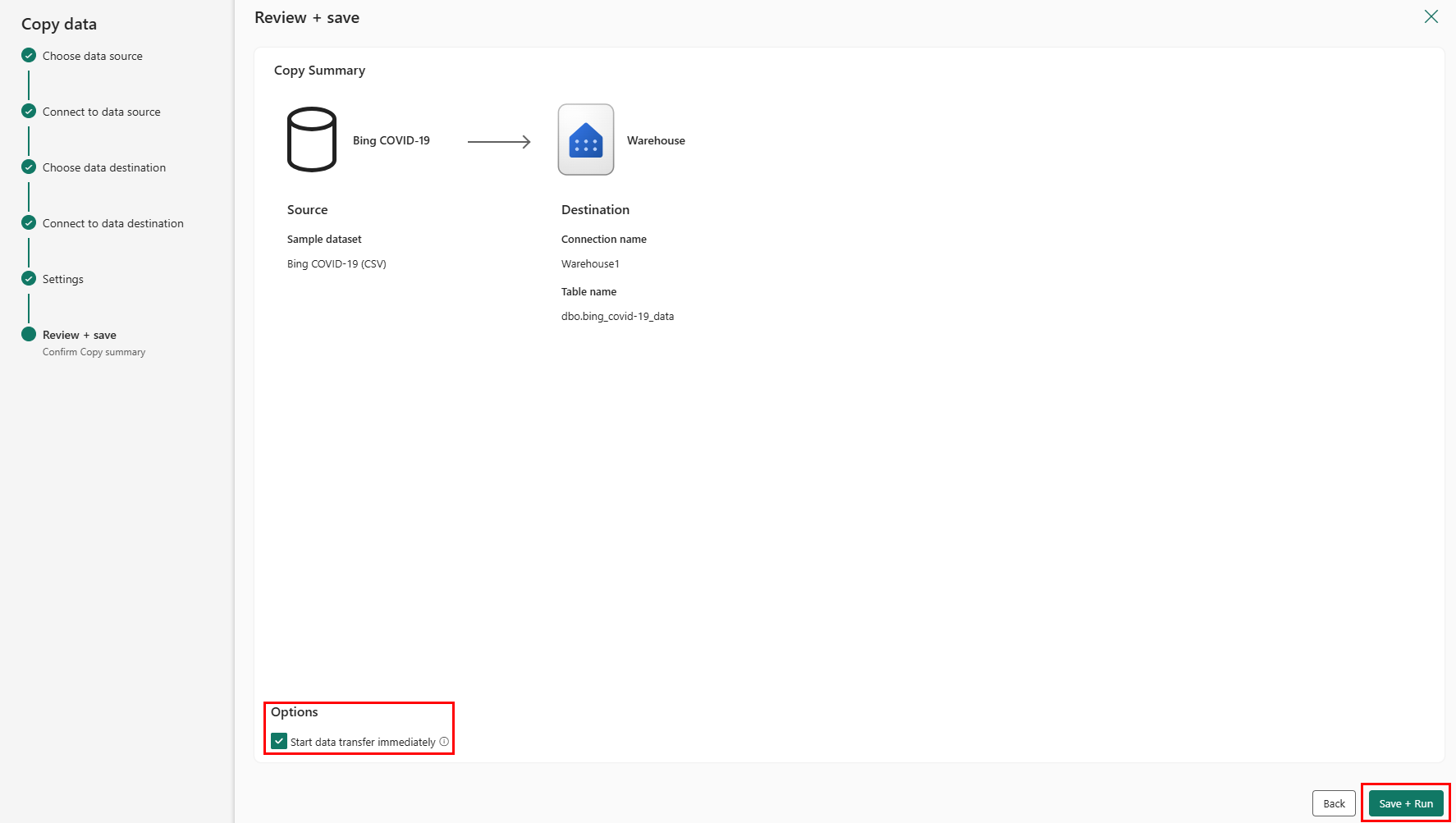
La dernière page de l’assistant propose un résumé de l’activité de copie. Sélectionnez l’option Démarrer le transfert de données immédiatement, puis sélectionnez Enregistrer + Exécuter.
Vous êtes dirigé vers la zone de canevas du pipeline, où une nouvelle activité Copier des données est déjà configurée pour vous. Le pipeline commence à s’exécuter automatiquement. Vous pouvez superviser l’état de votre pipeline dans le volet Sortie :
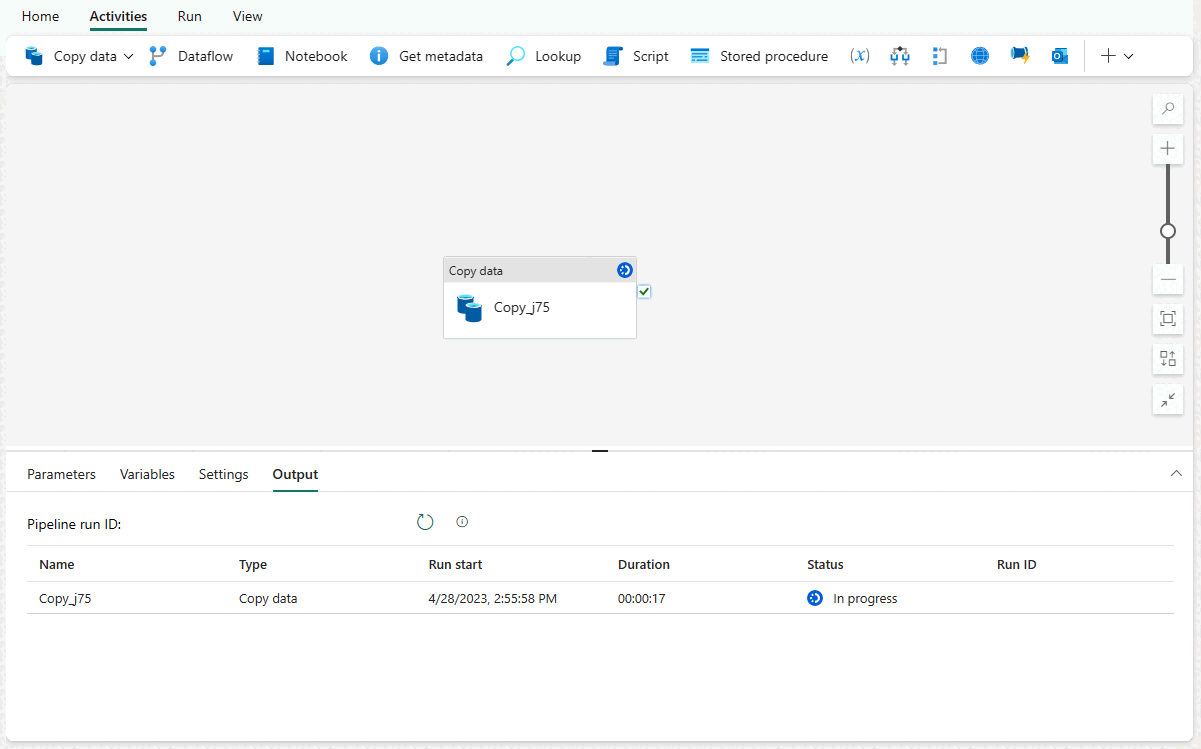
Après quelques secondes, votre pipeline se termine. Revenez à votre entrepôt. Vous pouvez sélectionner votre table pour afficher un aperçu des données et confirmer que l’opération de copie s’est terminée.




Pour plus d’informations sur l’ingestion de données dans votre entrepôt dans Microsoft Fabric, consultez :
- Ingestion de données dans l’entrepôt
- Ingérer des données dans votre entrepôt à l’aide de l’instruction COPY
- Ingérer des données dans votre entrepôt à l’aide de Transact-SQL