Planification de votre migration à partir d’Azure Data Factory
Microsoft Fabric est le produit SaaS d’analytique des données de Microsoft qui regroupe tous les produits d’analytique de pointe de Microsoft en une seule expérience utilisateur. Fabric Data Factory fournit l’orchestration de flux de travail, le déplacement des données, la réplication des données et la transformation des données à grande échelle avec des fonctionnalités similaires trouvées dans Azure Data Factory (ADF). Si vous avez des investissements ADF existants que vous souhaitez moderniser vers Fabric Data Factory, ce document est utile pour vous aider à comprendre les considérations, stratégies et approches de migration.
La migration des services PaaS ETL/DI d'Azure tels que ADF &, les pipelines Synapse et les flux de données, peut offrir plusieurs avantages importants :
- Les nouvelles fonctionnalités de pipeline intégrées, notamment les activités de messagerie et Teams, permettent un routage facile des messages pendant l’exécution du pipeline.
- Les fonctionnalités intégrées d’intégration et de livraison continue (CI/CD) (pipelines de déploiement) ne nécessitent pas d’intégration externe avec les référentiels Git.
- L’intégration de l’espace de travail à votre lac de données OneLake permet une gestion simple de l’analytique à volet unique.
- L’actualisation de vos modèles de données sémantiques est facile dans Fabric avec une activité de pipeline entièrement intégrée.
Microsoft Fabric est une plateforme intégrée pour les données d’entreprise en libre-service et gérées par l’informatique. Avec une croissance exponentielle des volumes de données et de la complexité, les clients Fabric demandent des solutions d’entreprise qui sont mises à l’échelle, sont sécurisées, faciles à gérer et accessibles à tous les utilisateurs au sein des plus grandes organisations.
Ces dernières années, Microsoft a investi des efforts importants pour fournir des fonctionnalités cloud évolutives à Premium. À cette fin, Data Factory dans Fabric permet instantanément à un vaste écosystème de développeurs d’intégration de données et de solutions d’intégration de données qui ont été créées au fil des décennies pour appliquer l’ensemble complet des fonctionnalités et des fonctionnalités qui vont bien au-delà des fonctionnalités comparables disponibles dans les générations précédentes.
Naturellement, les clients demandent s’il existe une opportunité de consolider en hébergeant leurs solutions d’intégration de données dans Fabric. Les questions courantes sont les suivantes :
- Toutes les fonctionnalités dont nous dépendons fonctionnent-elles dans les pipelines Fabric ?
- Quelles sont les fonctionnalités disponibles uniquement dans les pipelines Fabric ?
- Comment migrer des pipelines existants vers des pipelines Fabric ?
- Quelle est la feuille de route de Microsoft pour l’ingestion des données d’entreprise ?
Différences de plateforme
Lorsque vous migrez une instance ADF entière, il existe de nombreuses différences importantes à prendre en compte entre ADF et Data Factory dans Fabric, ce qui devient important lorsque vous migrez vers Fabric. Nous explorons plusieurs de ces différences importantes dans cette section.
Pour une compréhension plus détaillée du mappage fonctionnel des différences de fonctionnalités entre Azure Data Factory et Fabric Data Factory, reportez-vous à Comparer Data Factory dans Fabric et Azure Data Factory.
Runtimes d’intégration
Dans ADF, les runtimes d’intégration sont des objets de configuration qui représentent le calcul utilisé par ADF pour terminer votre traitement des données. Ces propriétés de configuration incluent la région Azure pour le calcul cloud et les tailles de calcul Spark pour le traitement des flux de données. D'autres types d'IR incluent des IR auto-hébergés (SHIR) pour la connectivité des données sur site, des IR SSIS pour l'exécution de packages SQL Server Integration Services, et des IR cloud compatibles Vnet.
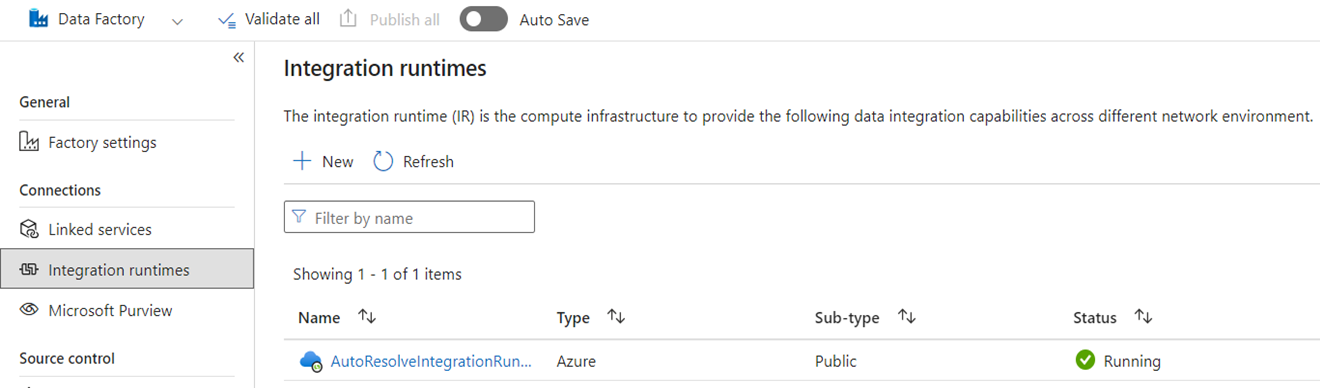
Microsoft Fabric est un produit SaaS (software-as-a-service), tandis que ADF est un produit PaaS (platform-as-a-service). Ce que signifie cette distinction en termes de runtimes d’intégration, c’est que vous n’avez pas besoin de configurer quoi que ce soit pour utiliser des pipelines ou des flux de données dans Fabric, car la valeur par défaut consiste à utiliser le calcul basé sur le cloud dans la région où se trouvent vos capacités Fabric. Les SSIS IRs n'existent pas dans Fabric et pour la connectivité de données sur site, vous utilisez un composant spécifique à Fabric appelé passerelle de données locale (OPDG). Et pour la connectivité basée sur un réseau virtuel aux réseaux sécurisés, vous utilisez la passerelle de données de réseau virtuel dans Fabric.
Lors de la migration d'ADF vers Fabric, vous n'avez pas besoin de migrer les IRs Azure de réseau public (cloud). Vous devez recréer vos SHIR en tant qu'OPDG et les IR Azure activés par le réseau virtuel en tant que Passerelles de données du réseau virtuel.
Pipelines
Les pipelines sont le composant fondamental d’ADF, qui est utilisé pour le flux de travail principal et l’orchestration de vos processus ADF pour le déplacement des données, la transformation de données et l’orchestration des processus. Les pipelines dans Fabric Data Factory sont presque identiques à ADF, mais avec des composants supplémentaires qui correspondent bien au modèle SaaS basé sur Power BI. Cette similarité inclut des activités natives pour les e-mails, Teams et les actualisations de modèle sémantique.
La définition JSON des pipelines dans Fabric Data Factory diffère légèrement de ADF en raison des différences dans le modèle d’application entre les deux produits. En raison de cette différence, il n’est pas possible de copier/coller du pipeline JSON, d’importer/exporter des pipelines ou de pointer vers un dépôt Git ADF.
Lors de la reconstruction de vos pipelines ADF en tant que pipelines Fabric, vous utilisez essentiellement les mêmes modèles de flux de travail et compétences que ceux que vous avez utilisés dans ADF. La principale considération doit être liée aux services liés et aux jeux de données qui sont des concepts dans ADF qui n’existent pas dans Fabric.
Services liés
Dans ADF, les services liés définissent les propriétés de connectivité nécessaires pour se connecter à vos magasins de données pour le déplacement des données, la transformation des données et les activités de traitement des données. Dans Fabric, vous devez recréer ces définitions en tant que connexions qui sont des propriétés pour vos activités telles que la copie et les flux de données.
Groupes de données
Les jeux de données définissent la forme, l’emplacement et le contenu de vos données dans ADF, mais n’existent pas en tant qu’entités dans Fabric. Pour définir des propriétés de données telles que les types de données, les colonnes, les dossiers, les tables, etc. dans les pipelines Fabric Data Factory, vous définissez ces caractéristiques inline dans les activités du pipeline et dans l’objet Connection référencé précédemment dans la section Service lié.
Flux de données
Dans Data Factory pour Fabric, le terme dataflows fait référence aux activités de transformation de données sans code, tandis que dans ADF, la même fonctionnalité est appelée flux de données. Les dataflows Fabric Data Factory ont une interface utilisateur basée sur Power Query, qui est utilisée dans l’activité Power Query ADF. Le calcul utilisé pour exécuter des flux de données dans Fabric est un moteur d’exécution natif qui peut effectuer un scale-out pour la transformation de données à grande échelle à l’aide du nouveau moteur de calcul Fabric Data Warehouse.
Dans ADF, les flux de données sont basés sur l’infrastructure Synapse Spark et définis à l’aide d’une interface utilisateur de construction qui utilise un langage spécifique au domaine sous-jacent (DSL) appelé script de flux de données. Ce langage de définition diffère considérablement des dataflows basés sur Power Query dans Fabric qui utilisent un langage de définition appelé M pour définir leur comportement. En raison de ces différences dans les interfaces utilisateur, les langages et les moteurs d’exécution, Fabric flux de données et ADF les flux de données ne sont pas compatibles et vous devez recréer vos flux de données ADF en tant que flux de données Fabric lors de la mise à niveau de vos solutions vers Fabric.
Déclencheurs
Les déclencheurs signalent à ADF d'exécuter un pipeline sur une planification horaire, des fenêtres temporelles glissantes, des événements de fichiers ou des événements personnalisés. Ces fonctionnalités sont similaires dans Fabric, bien que l’implémentation sous-jacente soit différente.
Dans Fabric, les déclencheurs pour n'existent qu'en tant que concept de pipeline. Le cadre plus large qu'utilisent les déclencheurs de pipeline dans Fabric est connu sous le nom de Data Activator, qui est un sous-système d'événements et d'alertes des fonctionnalités d'intelligence en temps réel dans Fabric.
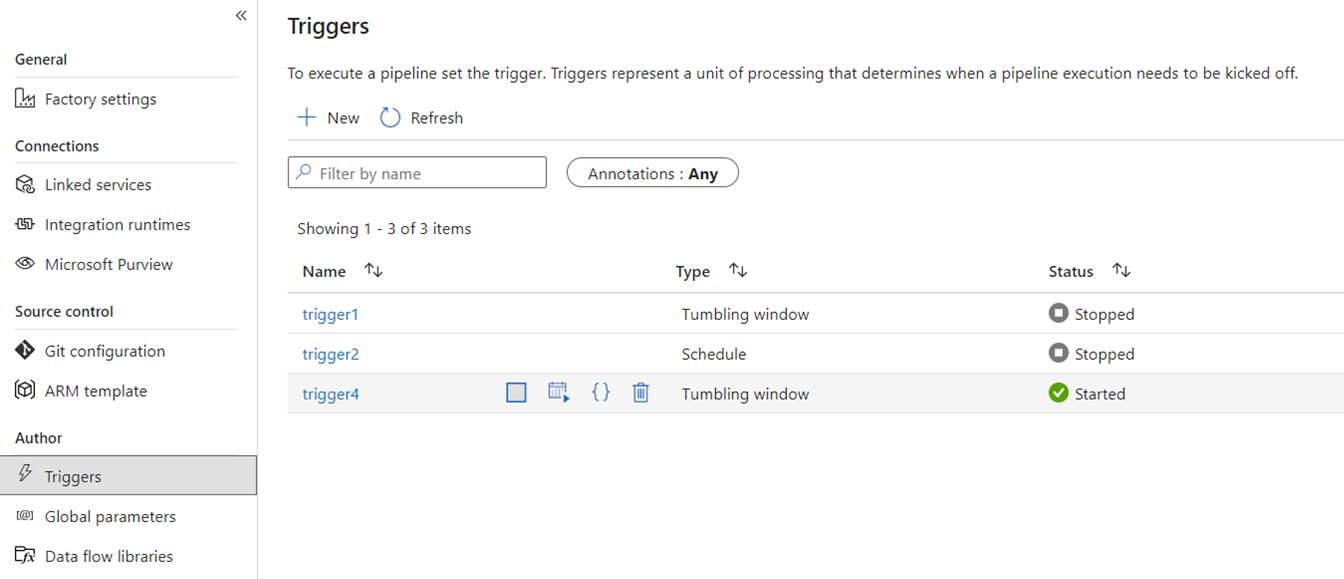
Fabric Data Activator a des alertes qui peuvent être utilisées pour créer des déclencheurs d'événements de fichier et des déclencheurs d'événements personnalisés. Bien que les déclencheurs de calendrier soient une entité distincte dans Fabric appelée calendriers. Ces planifications sont au niveau de la plateforme dans Fabric et ne sont pas spécifiques aux pipelines. Ils ne sont pas non plus appelés déclencheurs dans Fabric.
Pour migrer vos déclencheurs d’ADF vers Fabric, pensez à reconstruire vos déclencheurs de planification en de simples planifications qui deviennent des propriétés de vos pipelines Fabric. Pour tous les autres types de déclencheurs, utilisez le bouton Déclencheurs à l’intérieur du pipeline Fabric ou utilisez l’activateur de données en mode natif dans Fabric.
Débogage
Le débogage de pipelines est plus simple dans Fabric que dans ADF. Cette simplicité est due au fait que les pipelines Fabric Data Factory n’ont pas de concept distinct de mode de débogage que vous trouvez dans les pipelines ADF et les flux de données. Au lieu de cela, lorsque vous générez votre pipeline, vous êtes toujours en mode interactif. Pour tester et déboguer vos pipelines, vous devez uniquement sélectionner le bouton de lecture dans la barre d’outils de l’éditeur de pipeline lorsque vous êtes prêt dans votre cycle de développement. Les pipelines dans Fabric n'incluent pas le débogage jusqu'à ce que le modèle pas à pas de débogage interactif. Au lieu de cela, dans Fabric, vous utilisez l’état de l’activité et définissez uniquement les activités que vous souhaitez tester comme actives tout en définissant toutes les autres activités sur inactives pour obtenir les mêmes modèles de test et de débogage. Reportez-vous à la vidéo suivante qui explique comment réaliser cette expérience de débogage dans Fabric.
Capture de données modifiées
La Change Data Capture (CDC) dans ADF est une fonctionnalité en préversion qui facilite le déplacement rapide des données de manière incrémentielle en utilisant les fonctionnalités CDC de vos magasins de données côté source. Pour migrer vos artefacts CDC vers Fabric Data Factory, vous recréez ces artefacts en tant que Copier le travail éléments dans votre espace de travail Fabric. Cette fonctionnalité offre des fonctionnalités similaires de déplacement incrémentiel des données avec une interface utilisateur facile à utiliser sans nécessiter de pipeline, comme dans ADF CDC. Pour plus d'informations, voir l’ activité Copy pour Data Factory in Fabric.
Azure Synapse Link
Bien qu’il ne soit pas disponible dans ADF, les utilisateurs de pipeline Synapse utilisent fréquemment Azure Synapse Link pour répliquer des données à partir de bases de données SQL vers leur lac de données en approche clé en main. Dans Fabric, vous recréez les artefacts Azure Synapse Link en tant qu’éléments de mise en miroir dans votre espace de travail. Pour plus d’informations, consultez la mise en miroir des bases de données pour Fabric.
SQL Server Integration Services (SSIS)
SSIS est l’outil d’intégration de données local et d’ETL fourni par Microsoft avec SQL Server. Dans ADF, vous pouvez transférer vos packages SSIS dans le cloud à l’aide de l’environnement d'exécution SSIS ADF. Dans Fabric, nous n’avons pas le concept d’IR, donc cette fonctionnalité n’est pas possible aujourd’hui. Toutefois, nous travaillons à l’activation de l’exécution du package SSIS en mode natif à partir de Fabric, que nous espérons apporter au produit bientôt. En attendant, la meilleure façon d’exécuter des packages SSIS dans le cloud avec Fabric Data Factory consiste à lancer un environnement d'intégration SSIS dans votre usine ADF, puis à invoquer un pipeline ADF pour exécuter vos packages SSIS. Vous pouvez appeler à distance un pipeline ADF depuis vos pipelines Fabric en utilisant l'activité de pipeline d'invocation décrite dans la section suivante.
Activité d’appel de pipeline
Une activité courante utilisée dans les pipelines ADF est Exécuter l'activité du pipeline qui vous permet d'appeler un autre pipeline dans votre usine. Dans Fabric, nous avons amélioré cette activité en tant qu’activité de pipeline Invoke. Reportez-vous à la documentation sur l’activité d'appel de la chaîne de traitement.
Cette activité est utile pour les scénarios de migration dans lesquels vous avez de nombreux pipelines ADF qui utilisent des fonctionnalités spécifiques à ADF telles que les flux de données de mappage ou SSIS. Vous pouvez gérer ces pipelines as-is dans des pipelines ADF ou même Synapse, puis appeler ce pipeline en ligne à partir de votre nouveau pipeline Fabric Data Factory en utilisant l'activité d'invocation de pipeline et en pointant vers le pipeline de l'usine distante.
Exemples de scénarios de migration
Les scénarios suivants sont des scénarios de migration courants que vous pouvez rencontrer lors de la migration d’ADF vers Fabric Data Factory.
Scénario n°1 : Pipelines ADF et flux de données
Les principaux cas d’usage des migrations d’usine sont basés sur la modernisation de votre environnement ETL du modèle PaaS de fabrique ADF vers le nouveau modèle SaaS Fabric. Les éléments de fabrique principaux à migrer sont des pipelines et des flux de données. Il existe plusieurs éléments de fabrique fondamentaux que vous devez planifier pour la migration en dehors de ces deux éléments de niveau supérieur : services liés, runtimes d’intégration, jeux de données et déclencheurs.
- Les services liés doivent être recréés dans Fabric en tant que connexions dans vos activités de pipeline.
- Les jeux de données n’existent pas dans Factory. Les propriétés de vos jeux de données sont représentées en tant que propriétés dans les activités de pipeline telles que copier ou rechercher, tandis que les connexions contiennent d’autres propriétés de jeu de données.
- Les runtimes d’intégration n’existent pas dans Fabric. Toutefois, vos RIs auto-hébergés peuvent être recréés à l'aide de passerelles de données locales (OPDG) sur Fabric et de RIs de réseau virtuel Azure en tant que passerelles de réseau virtuel managées sur Fabric.
- Ces activités de pipeline ADF ne sont pas incluses dans Fabric Data Factory :
- Data Lake Analytics (U-SQL) : cette fonctionnalité est un service Azure déconseillé.
- Activité de validation : l’activité de validation dans ADF est une activité d’assistance que vous pouvez reconstruire facilement dans vos pipelines Fabric à l’aide d’une activité Get Metadata, d’une boucle de pipeline et d’une activité If.
- Power Query - Dans Fabric, tous les dataflows sont générés à l’aide de l’interface utilisateur Power Query. Vous pouvez donc simplement copier et coller votre code M à partir de vos activités Power Query ADF et les générer en tant que flux de données dans Fabric.
- Si vous utilisez une fonctionnalité de pipeline ADF qui n'est pas disponible dans Fabric Data Factory, utilisez l'activité de pipeline Invoke dans Fabric pour appeler vos pipelines existants dans ADF.
- Les activités de pipeline ADF suivantes sont combinées dans une activité à usage unique :
- Activités Azure Databricks (Notebook, Jar, Python)
- Azure HDInsight (Hive, Pig, MapReduce, Spark, Streaming)
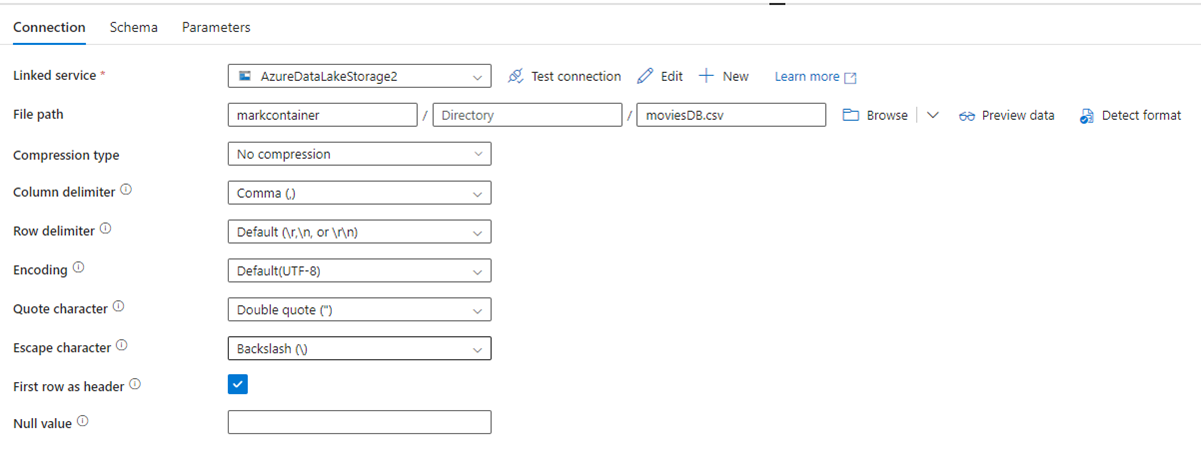
L’image suivante montre la page de configuration du jeu de données ADF, avec son chemin d’accès de fichier et ses paramètres de compression :
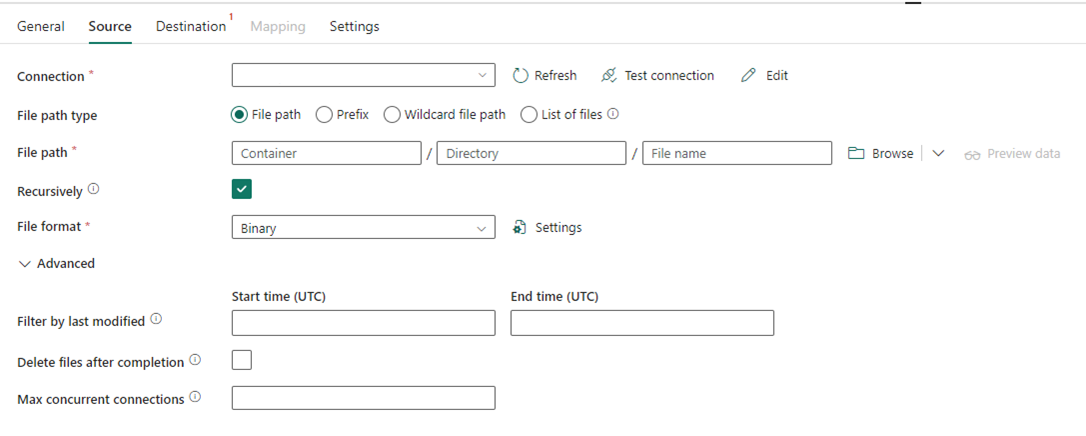
L’image suivante montre la configuration de l’activité de copie pour Data Factory dans Fabric, où la compression et le chemin d’accès au fichier sont inline dans l’activité :
Scénario n°2 : ADF avec CDC, SSIS et Airflow
Les fonctionnalités CDC & Airflow dans ADF sont en avant-première, tandis que SSIS dans ADF est disponible depuis de nombreuses années. Chacune de ces fonctionnalités répond à différents besoins d’intégration des données, mais nécessitent une attention particulière lors de la migration d’ADF vers Fabric. Dans Fabric, la capture de données modifiées (CDC) est un concept ADF de niveau supérieur et cette fonctionnalité apparaît comme tâche de copie.
Airflow est la fonctionnalité Apache Airflow gérée par le cloud ADF et est également disponible dans Fabric Data Factory. Vous devez être en mesure d’utiliser le même dépôt source Airflow ou de prendre vos DAGs et copier/coller le code dans l’offre Fabric Airflow avec peu à aucune modification requise.
Scénario n°3 : Migration de Data Factory avec Git vers Fabric
Il est courant, bien qu’il ne soit pas nécessaire, que vos fabriques ADF ou Synapse et vos espaces de travail soient connectés à votre propre fournisseur Git externe dans ADO ou GitHub. Dans ce scénario, vous devez migrer vos éléments de fabrique et d’espace de travail vers un espace de travail Fabric, puis configurer l’intégration Git sur votre espace de travail Fabric.
Fabric fournit deux méthodes principales pour activer CI/CD, toutes deux au niveau de l'espace de travail : l'intégration Git, où vous apportez votre propre dépôt Git dans ADO et vous y connectez depuis Fabric, et les pipelines de déploiement intégrés, où vous pouvez promouvoir le code vers des environnements supérieurs sans avoir besoin d'apporter votre propre Git.
Dans les deux cas, votre dépôt Git existant à partir d’ADF ne fonctionne pas avec Fabric. Au lieu de cela, vous devez pointer vers un nouveau repo, ou démarrer un nouveau pipeline de déploiement dans Fabric, et reconstruire les artefacts de votre pipeline dans Fabric.
Monter vos instances ADF existantes directement dans un espace de travail Fabric
Auparavant, nous avons parlé de l'utilisation de l'activité Invocation de Pipeline de Fabric Data Factory comme mécanisme pour maintenir les investissements de pipeline ADF existants et les appeler en ligne à partir de Fabric. Dans Fabric, vous pouvez adopter ce concept similaire une étape plus loin et monter l’ensemble de la fabrique à l’intérieur de votre espace de travail Fabric en tant qu’élément Fabric natif.
Pour plus d’informations sur le montage de scénarios d’utilisation, consultez scénarios de collaboration et de distribution de contenu.
Le montage de votre fabrique de données Azure à l’intérieur de votre espace de travail Fabric offre de nombreux avantages à prendre en compte. Si vous débutez avec Fabric et que vous souhaitez conserver vos usines côte à côte dans le même volet de verre, vous pouvez les monter dans Fabric afin que vous puissiez gérer les deux à l’intérieur de Fabric. L’interface utilisateur ADF complète est désormais disponible à partir de votre fabrique montée, où vous pouvez surveiller, gérer et modifier entièrement vos éléments de fabrique ADF à partir de l’espace de travail Fabric. Cette fonctionnalité facilite grandement la migration de ces éléments vers Fabric en tant qu’artefacts Fabric natifs. Cette fonctionnalité est principalement destinée à faciliter l’utilisation et permet de visualiser facilement vos fabriques ADF dans votre espace de travail Fabric. Toutefois, l’exécution réelle des pipelines, des activités, des runtimes d’intégration, etc., se produit toujours à l’intérieur de vos ressources Azure.
Contenu connexe
considérations relatives à la migration d’ADF vers Data Factory dans Fabric