Destinations de données Dataflow Gen2 et paramètres managés
Une fois que vous avez nettoyé et préparé vos données avec Dataflow Gen2, vous souhaitez placer vos données dans une destination. Pour ce faire, vous pouvez utiliser les fonctionnalités de destination de données dans Dataflow Gen2. Avec cette fonctionnalité, vous pouvez choisir parmi différentes destinations, telles qu’Azure SQL, Fabric Lakehouse, etc. Dataflow Gen2 écrit ensuite vos données dans la destination, et à partir de là, vous pouvez utiliser vos données pour une analyse et des rapports supplémentaires.
La liste suivante contient les destinations de données prises en charge.
- Bases de données Azure SQL
- Azure Data Explorer (Kusto)
- Fabric Lakehouse
- Fabric Warehouse
- Base de données Fabric KQL
- Base de données SQL Fabric
Points d’entrée
Chaque requête de données de votre Dataflow Gen2 peut avoir une destination de données. Les fonctions et les listes ne sont pas prises en charge ; vous ne pouvez l’appliquer qu’aux requêtes tabulaires. Vous pouvez spécifier la destination des données pour chaque requête individuellement, et vous pouvez utiliser plusieurs destinations différentes dans le flux de données.
Il existe trois points d’entrée principaux pour spécifier la destination des données :
Par le biais du ruban supérieur.
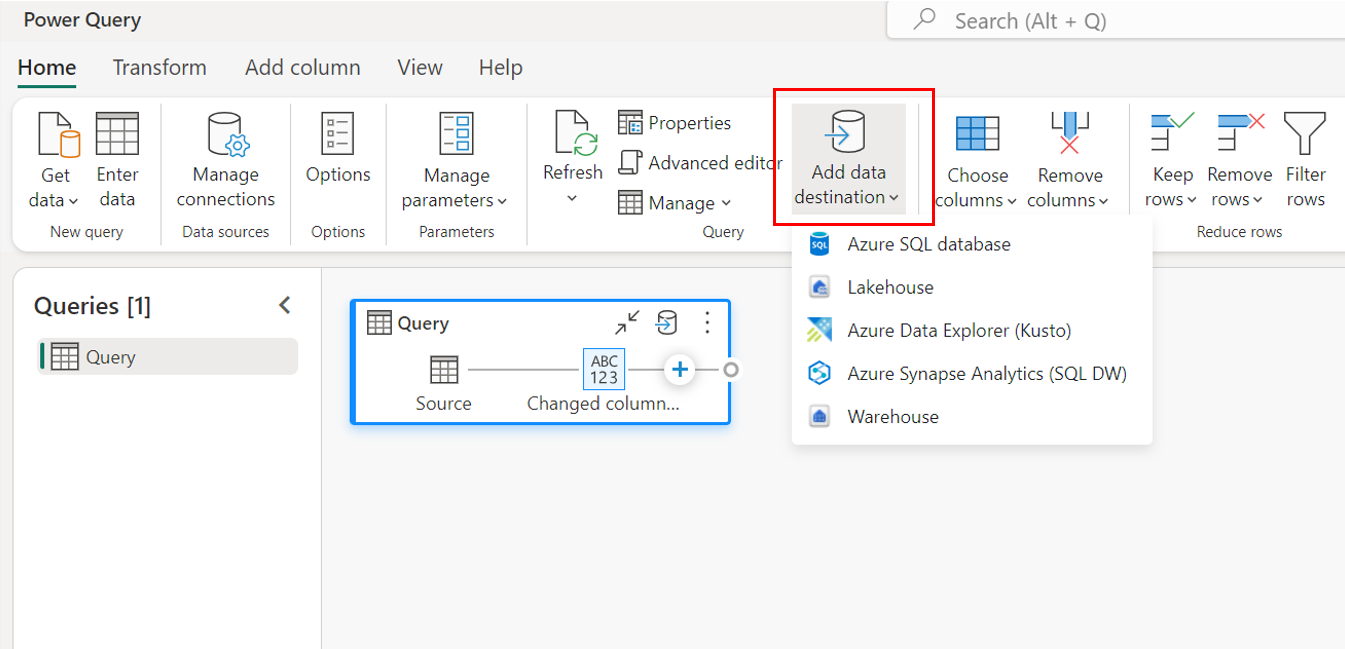
Par le biais des paramètres de requête.
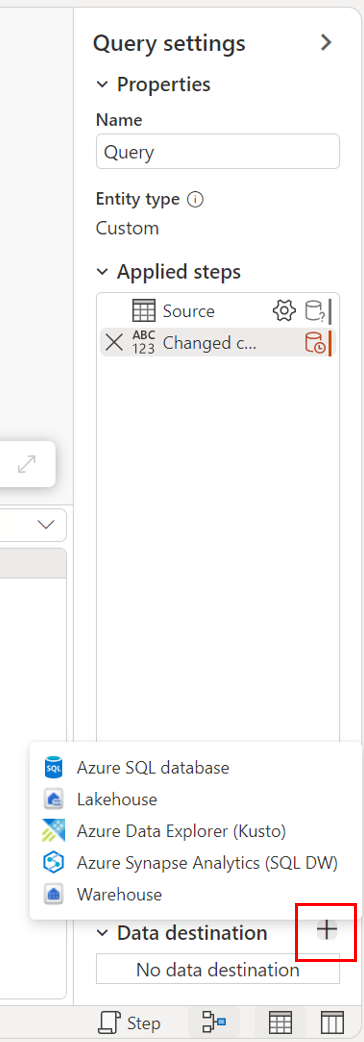
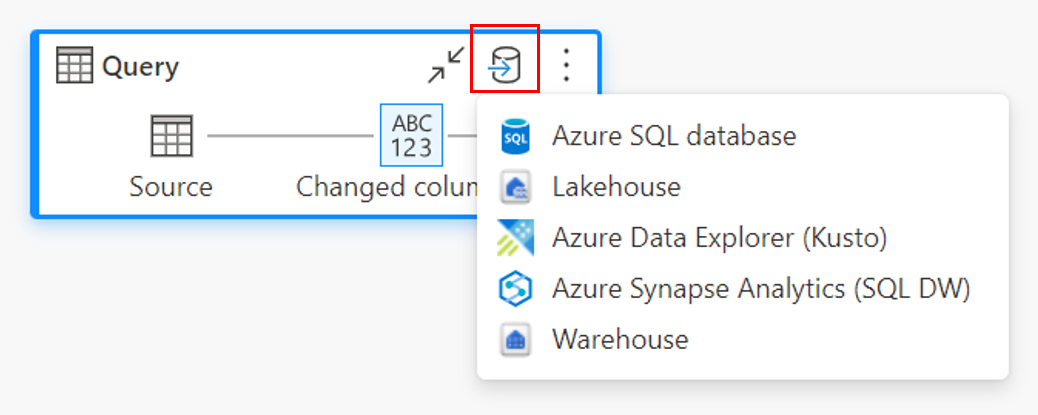
Par le biais de la vue de diagramme.
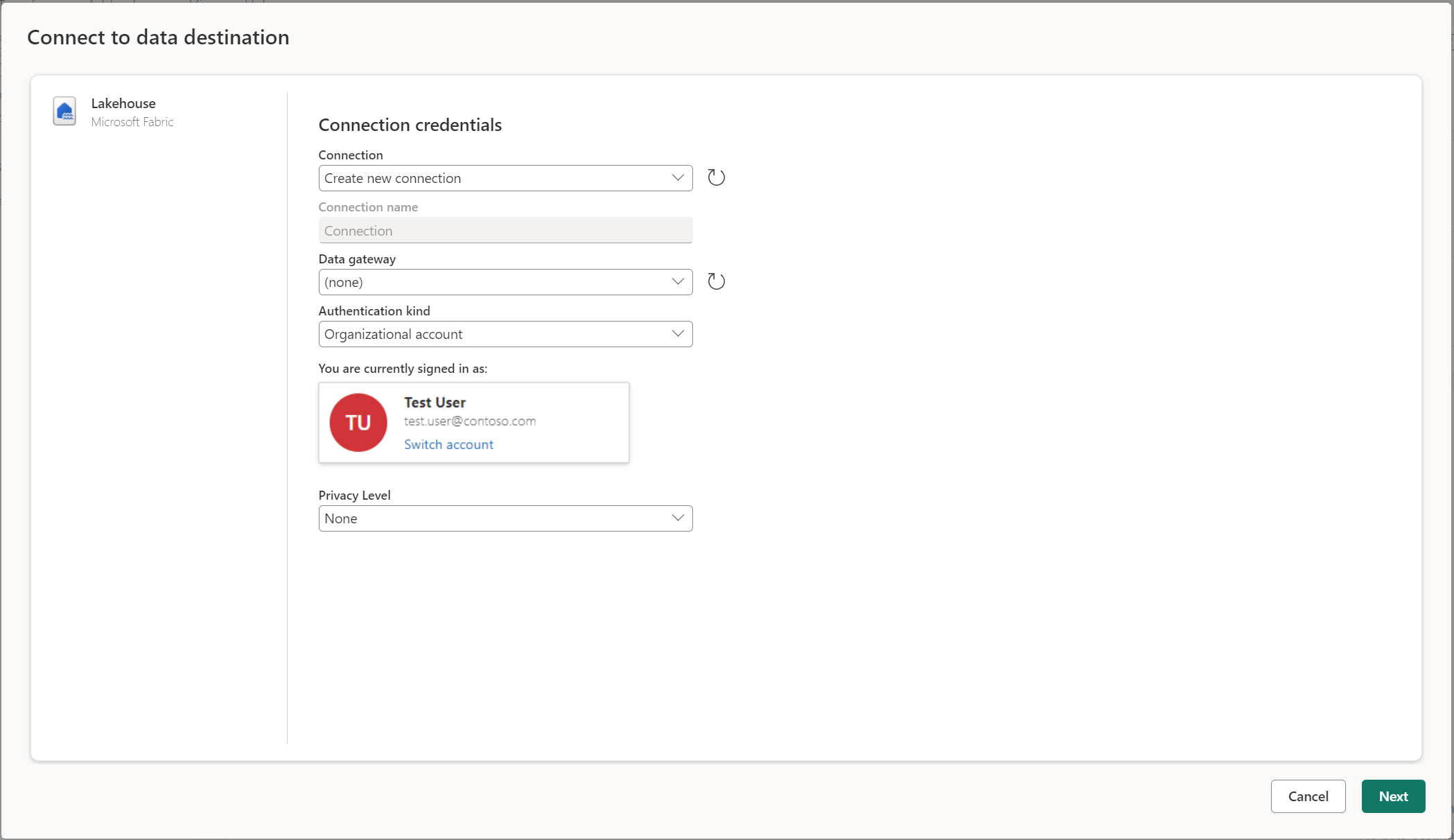
Se connecter à la destination des données
Se connecter à la destination des données est similaire à la connexion à une source de données. Les connexions peuvent être utilisées pour lire et écrire vos données, étant donné que vous disposez des autorisations appropriées sur la source de données. Vous devez créer une nouvelle connexion ou choisir une connexion existante, puis sélectionner Suivant.
Créer une nouvelle table ou choisir une table existante
Lors du chargement dans votre destination de données, vous pouvez créer une table ou choisir une table existante.
Créer une table
Lorsque vous choisissez de créer une nouvelle table, pendant l’actualisation de Dataflow Gen2, une nouvelle table est créée dans votre destination de données. Si la table est supprimée à l’avenir en accédant manuellement à la destination, le flux de données recrée la table lors de l’actualisation suivante du flux de données.
Par défaut, le nom de votre table est identique au nom de votre requête. Si vous avez des caractères non valides dans le nom de votre table que la destination ne prend pas en charge, le nom de la table est automatiquement ajusté. Par exemple, de nombreuses destinations ne prennent pas en charge les espaces ou les caractères spéciaux.
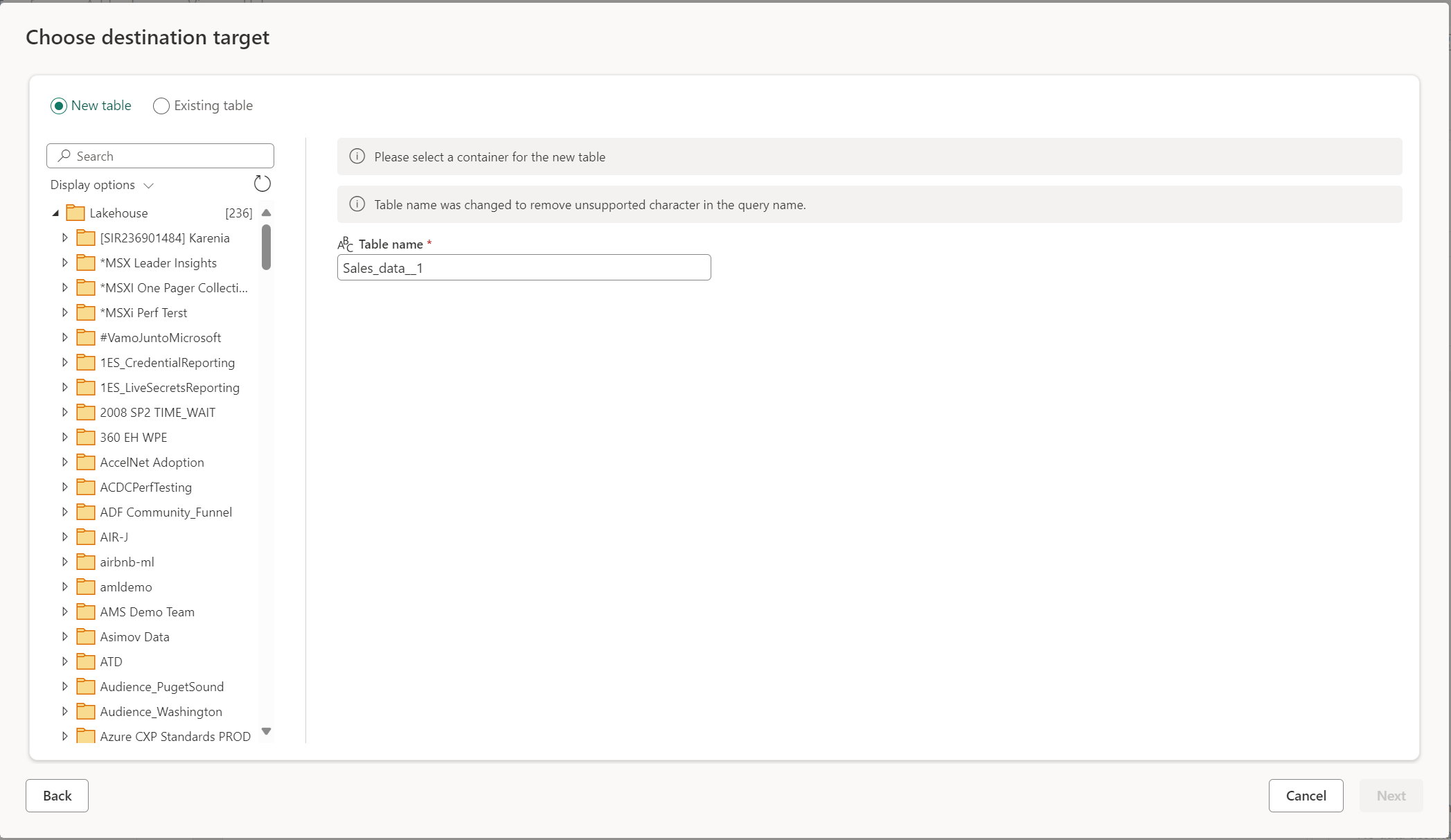
Ensuite, vous devez sélectionner le conteneur de destination. Si vous avez choisi l’une des destinations de données Fabric, vous pouvez utiliser le navigateur pour sélectionner l’artefact Fabric dans lequel vous souhaitez charger vos données. Pour les destinations Azure, vous pouvez spécifier la base de données lors de la création de la connexion ou sélectionner la base de données dans l’expérience du navigateur.
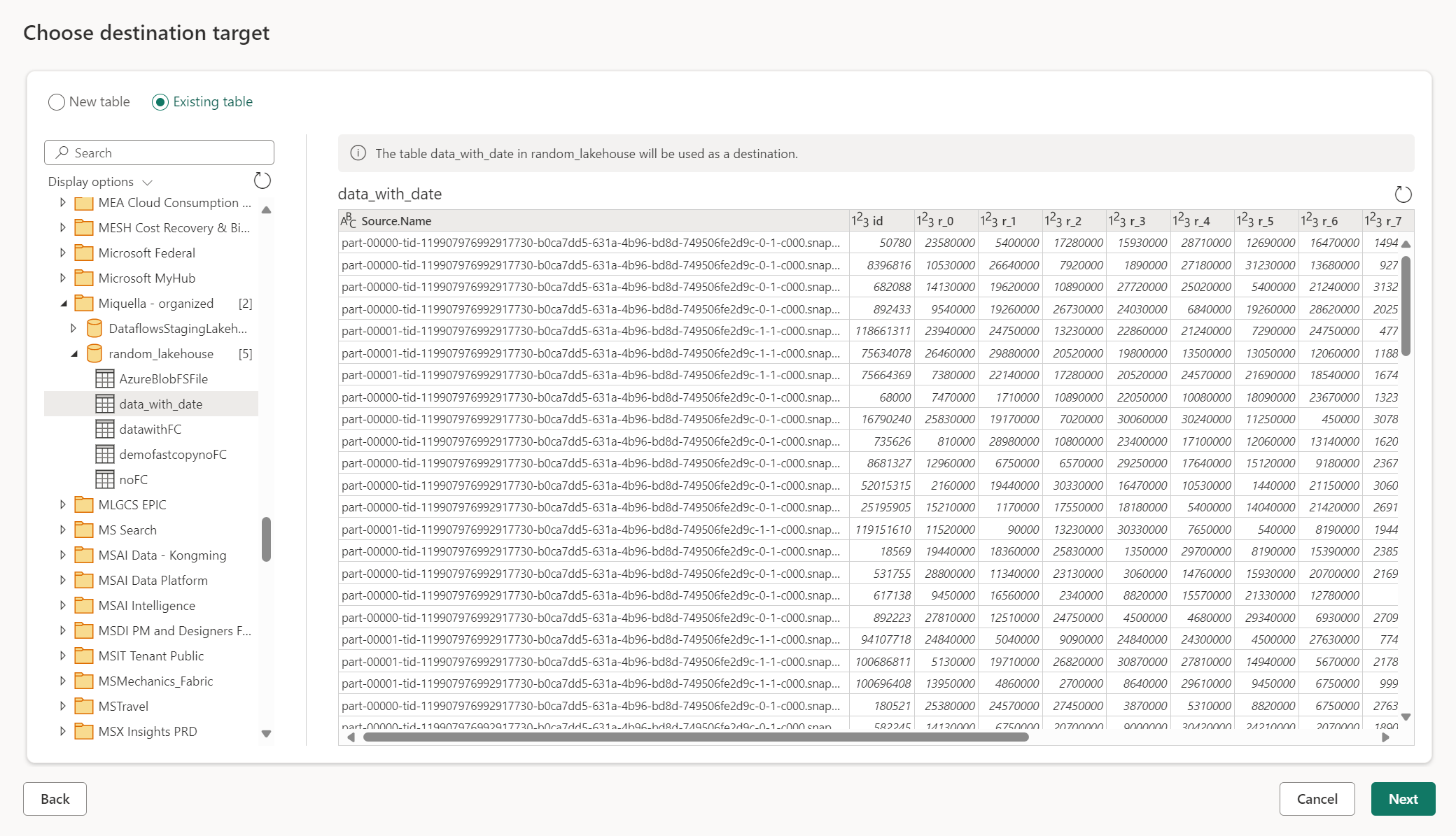
Utiliser une table existante
Pour choisir une table existante, utilisez le bouton bascule en haut du navigateur. Lorsque vous choisissez une table existante, vous devez choisir à la fois l’artefact/la base de données Fabric et la table à l’aide du navigateur.
Lorsque vous utilisez une table existante, la table ne peut pas être recréée dans un scénario quelconque. Si vous supprimez la table manuellement de la destination de données, Dataflow Gen2 ne recrée pas la table lors de la prochaine actualisation.
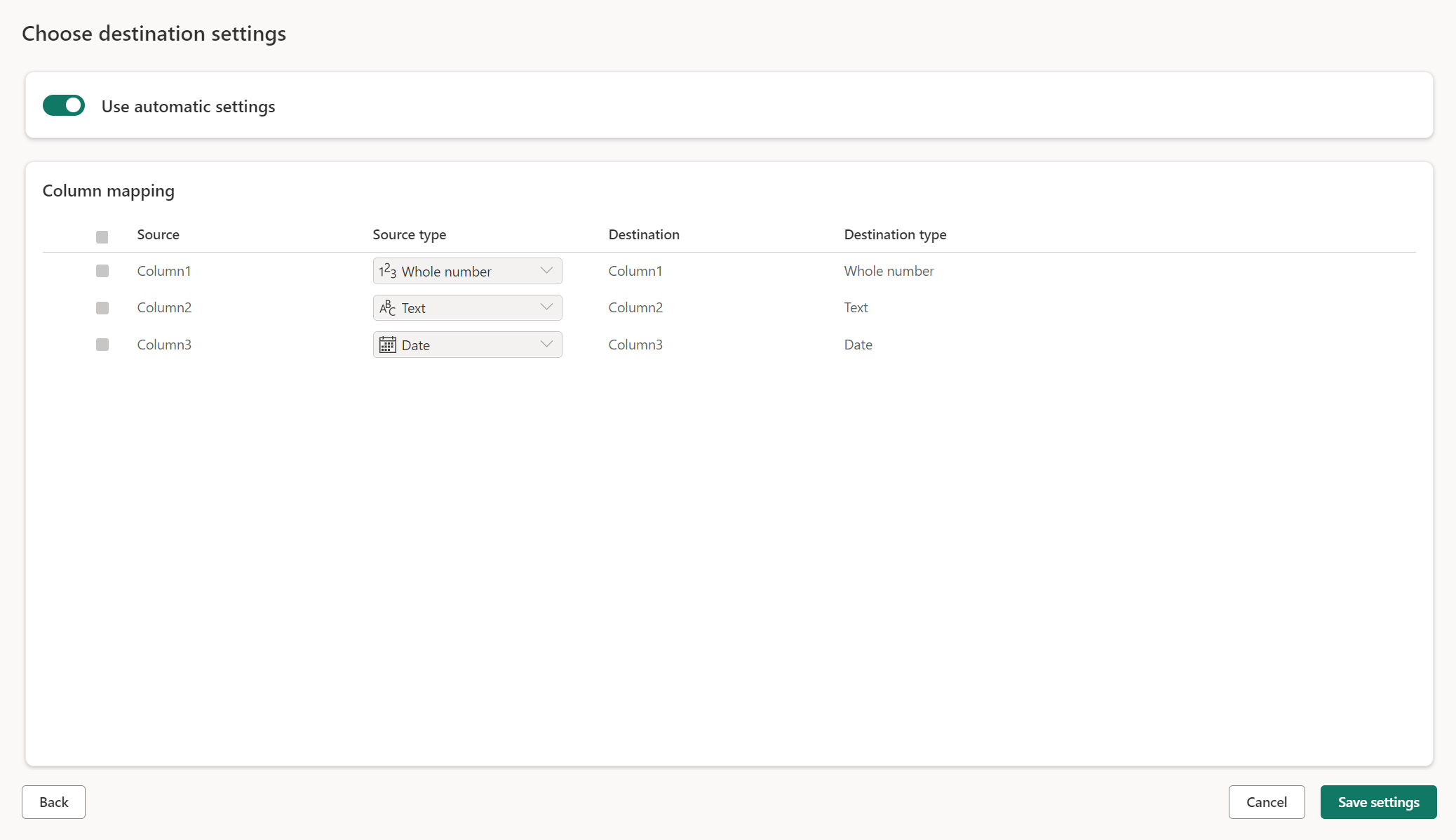
Paramètres managés pour les nouvelles tables
Lorsque vous chargez dans une nouvelle table, les paramètres automatiques sont activés par défaut. Si vous utilisez les paramètres automatiques, Dataflow Gen2 gère le mappage pour vous. Les paramètres automatiques fournissent le comportement suivant :
Remplacement de la méthode de mise à jour : les données sont remplacées à chaque actualisation du flux de données. Toutes les données de la destination sont supprimées. Les données de la destination sont remplacées par les données de sortie du flux de données.
Mappage managé : le mappage est managé pour vous. Lorsque vous devez apporter des modifications à vos données/votre requête pour ajouter une autre colonne ou modifier un type de données, le mappage est automatiquement ajusté pour cette modification lorsque vous republiez votre flux de données. Vous n’avez pas besoin d’accéder à l’expérience de destination des données chaque fois que vous apportez des modifications à votre flux de données, ce qui vous permet de modifier facilement le schéma lorsque vous republiez le flux de données.
Supprimer et recréer une table : pour autoriser ces modifications de schéma, chaque actualisation du flux de données de la table est supprimée et recréée. L’actualisation de votre flux de données peut entraîner la suppression de relations ou de mesures qui ont été ajoutées précédemment à votre table.
Remarque
Actuellement, le paramètre automatique n’est pris en charge que pour Lakehouse et la base de données Azure SQL en tant que destination de données.
Paramètres manuels
En désagrégant Utiliser les paramètres automatiques, vous obtenez un contrôle total sur la façon de charger vos données dans la destination des données. Vous pouvez apporter des modifications au mappage de colonnes en modifiant le type source ou en excluant toute colonne dont vous n’avez pas besoin dans votre destination de données.
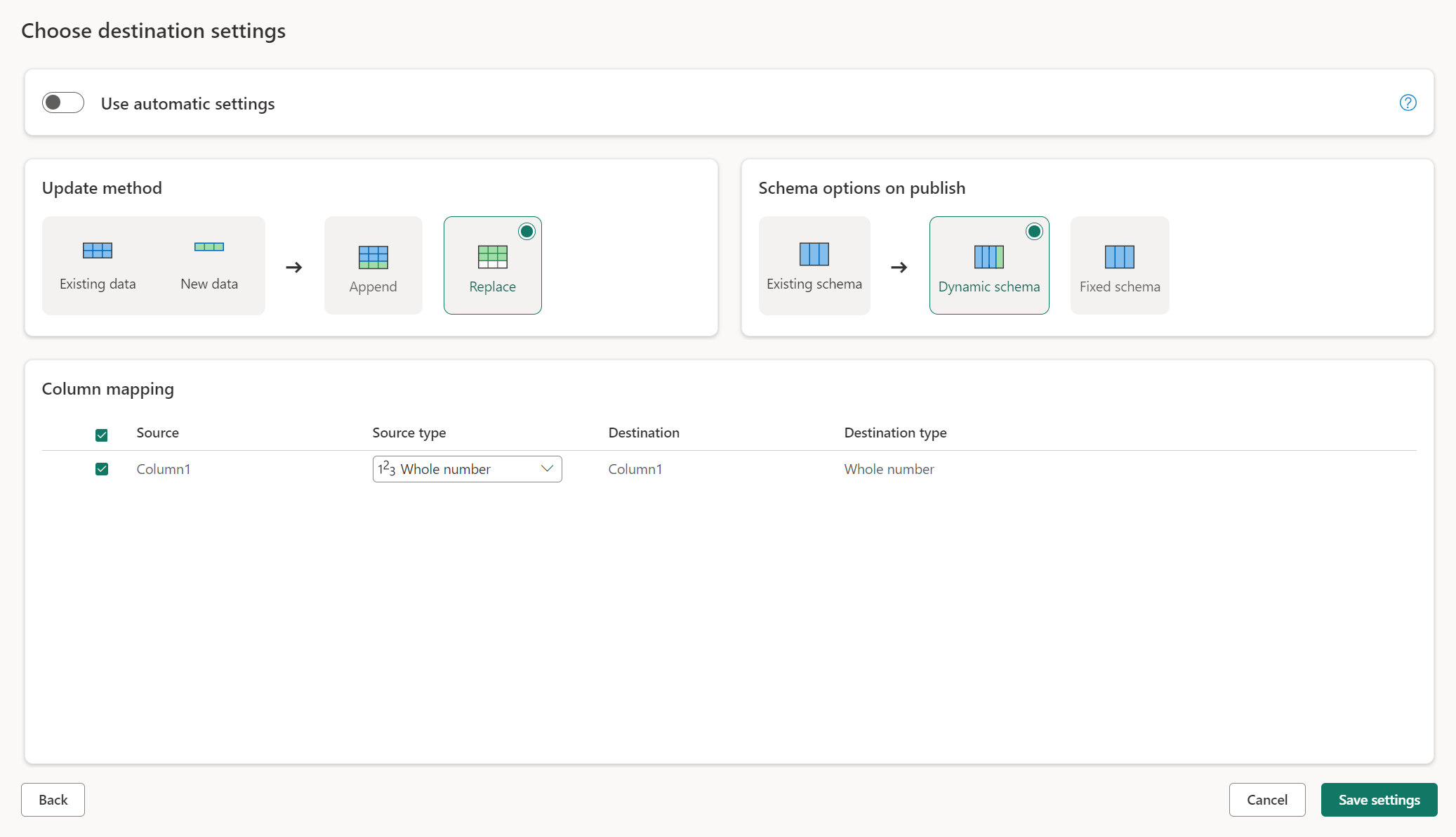
Méthodes de mise à jour
La plupart des destinations prennent en charge l’ajout et le remplacement en tant que méthodes de mise à jour. Toutefois, les bases de données Fabric KQL et Azure Data Explorer ne prennent pas en charge le remplacement comme méthode de mise à jour.
Remplacer : lors de chaque actualisation du flux de données, vos données sont supprimées de la destination et remplacées par les données de sortie du flux de données.
Ajouter : à chaque actualisation du flux de données, les données de sortie du flux de données sont ajoutées aux données existantes dans la table de destination de données.
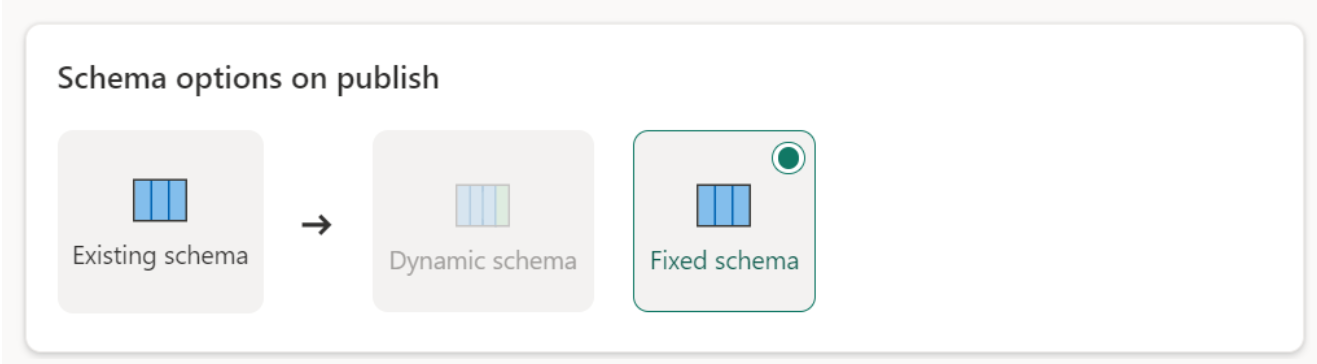
Options de schéma lors de la publication
Les options de schéma lors de la publication s’appliquent uniquement lorsque la méthode de mise à jour est remplacée. Lorsque vous ajoutez des données, les modifications apportées au schéma ne sont pas possibles.
Schéma dynamique : lorsque vous choisissez un schéma dynamique, vous autorisez les modifications de schéma dans la destination des données lorsque vous republiez le flux de données. Puisque vous n’utilisez pas de mappage managé, vous devez toujours mettre à jour le mappage de colonnes dans le flux de destination du flux de données lorsque vous apportez des modifications à votre requête. Lorsque le flux de données est actualisé, votre table est supprimée et recréée. L’actualisation de votre flux de données peut entraîner la suppression de relations ou de mesures qui ont été ajoutées précédemment à votre table.
Schéma fixe : lorsque vous choisissez un schéma fixe, les modifications de schéma ne sont pas possibles. Lorsque le flux de données est actualisé, seules les lignes de la table sont supprimées et remplacées par les données de sortie du flux de données. Toutes les relations ou mesures sur la table restent intactes. Si vous apportez des modifications à votre requête dans le flux de données, la publication du flux de données échoue si elle détecte que le schéma de requête ne correspond pas au schéma de destination des données. Utilisez ce paramètre lorsque vous ne prévoyez pas de modifier le schéma et que vous avez des relations ou des mesures ajoutées à votre table de destination.
Remarque
Lors du chargement de données dans l’entrepôt, seul le schéma fixe est pris en charge.
Types de sources de données prises en charge par destination
| Types de données pris en charge par emplacement de stockage | DataflowStagingLakehouse | Sortie Azure DB (SQL) | Sortie de Azure Explorateur de données | Sortie Fabric Lakehouse (LH) | Sortie de l'entrepôt de tissus (WH) | Sortie (SQL) de base de données SQL Fabric |
|---|---|---|---|---|---|---|
| Action | Non | Non | Non | Non | Non | Non |
| Tout | Non | Non | Non | Non | Non | Non |
| Binary | Non | Non | Non | Non | Non | Non |
| Devise | Oui | Oui | Oui | Oui | No | Oui |
| DateTimeZone | Oui | Oui | Oui | No | Non | Oui |
| Durée | Non | Non | Oui | No | Non | Non |
| Fonction | Non | Non | Non | Non | Non | Non |
| Aucune | Non | Non | Non | Non | Non | Non |
| Null | Non | Non | Non | Non | Non | Non |
| Temps | Oui | Oui | No | Non | Non | Oui |
| Type | Non | Non | Non | Non | Non | Non |
| Structuré (Liste, Enregistrement, Tableau) | Non | Non | Non | Non | Non | Non |
Rubriques avancées
Utilisation de la mise en lots avant le chargement vers une destination
Pour améliorer les performances du traitement des requêtes, la mise en lots peut être utilisée dans Dataflows Gen2 pour utiliser le calcul Fabric pour exécuter vos requêtes.
Lorsque la mise en lots est activée sur vos requêtes (comportement par défaut), vos données sont chargées dans l’emplacement de mise en lots, qui est un Lakehouse interne accessible uniquement par les flux de données eux-mêmes.
L'utilisation d'emplacements de simulation peut améliorer les performances dans certains cas où le repli de la requête vers le point de terminaison d'analytique SQL est plus rapide que dans le traitement de la mémoire.
Lorsque vous chargez des données dans le Lakehouse ou dans des destinations autres que l'entrepôt, nous désactivons par défaut la fonction de simulation afin d'améliorer les performances. Lorsque vous les chargez dans la destination des données, les données sont directement écrites dans cette destination sans passer par l'étape de simulation. Si vous souhaitez utiliser la phase de simulation pour votre requête, vous pouvez l'activer à nouveau.
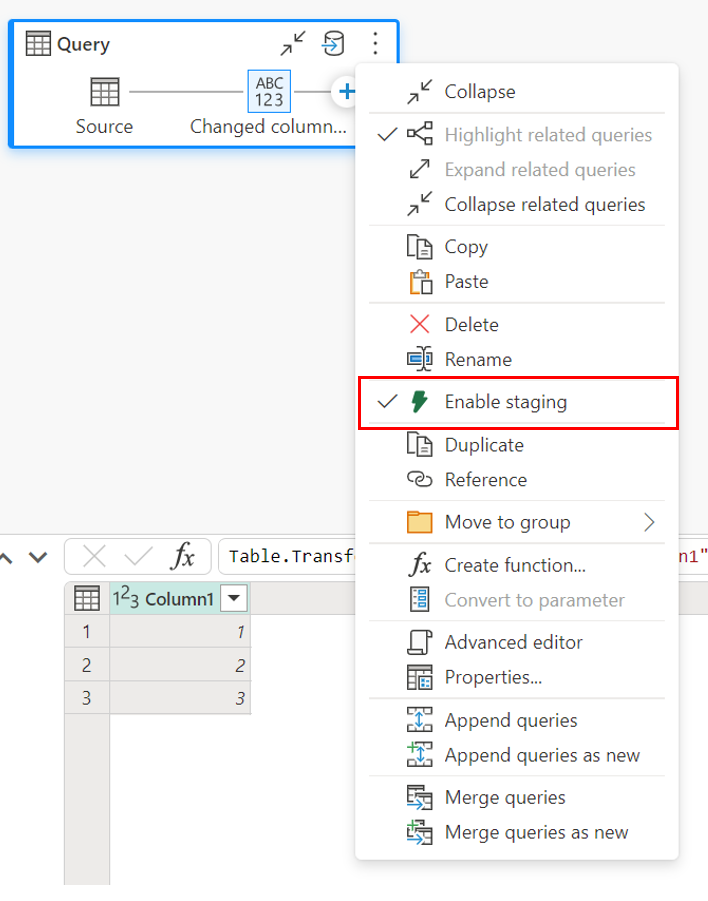
Pour activer la simulation, faites un clic droit sur la requête et activez la simulation en sélectionnant le bouton Activer la simulation. Votre requête passe alors au bleu.
Chargement des données dans l’entrepôt
Lorsque vous chargez des données dans l’entrepôt, la mise en lots est requise avant l’opération d’écriture dans la destination des données. Cette exigence améliore les performances. Actuellement, seul le chargement dans le même espace de travail que le flux de données est pris en charge. Vérifiez que la mise en lots est activée pour toutes les requêtes chargées dans l’entrepôt.
Lorsque la mise en lots est désactivée et que vous choisissez Entrepôt comme destination de sortie, vous recevez un avertissement pour activer la mise en lots avant de pouvoir configurer la destination des données.
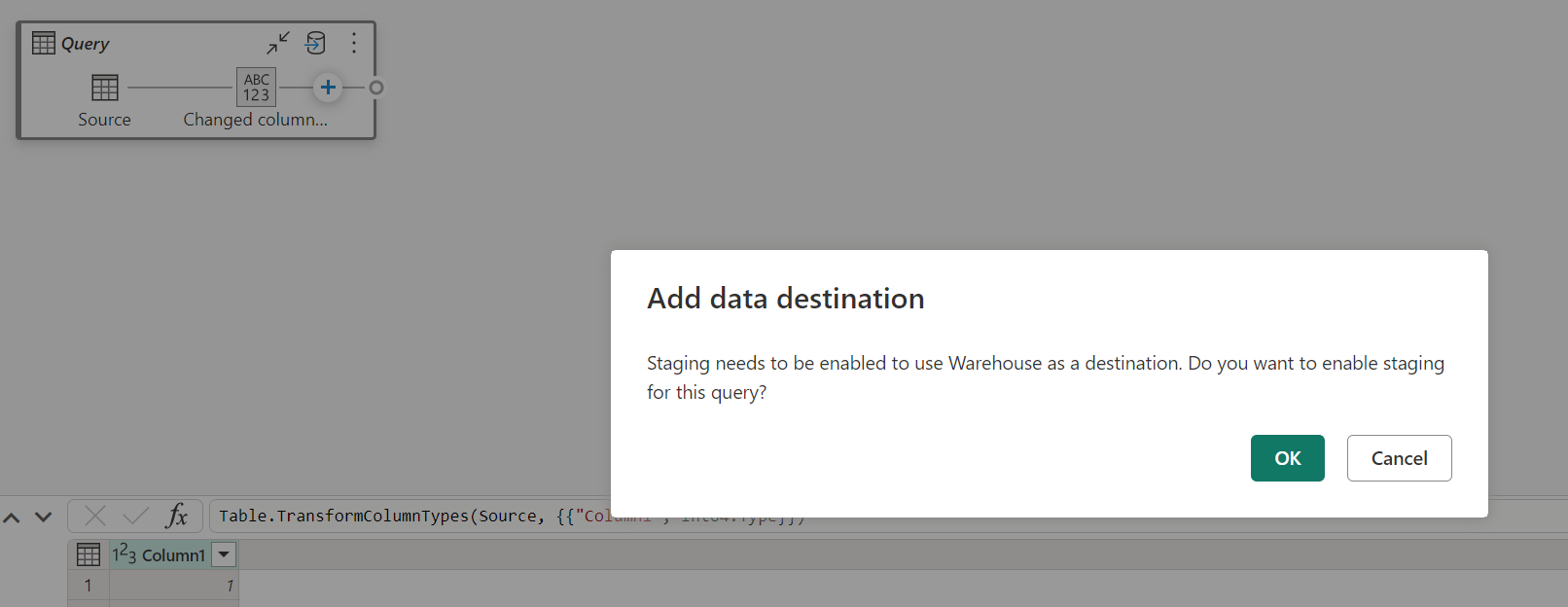
Si vous disposez déjà d’un entrepôt en tant que destination et que vous essayez de désactiver la mise en lots, un avertissement s’affiche. Vous pouvez supprimer l’entrepôt en tant que destination ou ignorer l’action de mise en lots.
Nettoyage de votre destination de données Lakehouse
Lorsque vous utilisez Lakehouse comme destination de Dataflow Gen2 dans Microsoft Fabric, il est essentiel d’opérer une maintenance régulière afin de garantir un niveau de performance optimal et une gestion efficace du stockage. Le nettoyage de votre destination de données fait partie des tâches de maintenance essentielles. Ce processus permet de supprimer les anciens fichiers qui ne sont plus référencés par le journal des tables Delta, ce qui optimise les coûts de stockage et préserve l’intégrité de vos données.
Pourquoi le nettoyage est important
- Optimisation du stockage : au fil du temps, les tables Delta accumulent des fichiers anciens qui n’ont plus d’utilité. Le nettoyage permet d’éliminer ces fichiers et ainsi de libérer de l’espace de stockage et de réduire les coûts.
- Amélioration des performances : la suppression des fichiers inutiles peut contribuer à améliorer le niveau de performance des requêtes dans la mesure où le nombre de fichiers à analyser pendant les opérations de lecture est réduit.
- Intégrité des données : en veillant à conserver uniquement les fichiers importants, vous contribuez à préserver l’intégrité de vos données et ainsi à éviter des problèmes potentiels liés à des fichiers non validés susceptible d’occasionner des échecs de lecture ou une altération des données de tables.
Comment nettoyer votre destination de données
Pour nettoyer vos tables Delta dans Lakehouse, procédez comme suit :
- Accédez à votre Lakehouse : depuis votre compte Microsoft Fabric, accédez au Lakehouse souhaité.
- Accédez à la maintenance des tables : dans l’explorateur Lakehouse, cliquez avec le bouton droit sur la table dont vous souhaitez effectuer la maintenance, ou accédez au menu contextuel via les points de suspension.
- Sélectionnez les options de maintenance : choisissez l’entrée de menu Maintenance, puis sélectionnez l’option Nettoyer.
- Exécutez la commande de nettoyage : définissez le seuil de rétention (la valeur par défaut est de 7 jours) et exécutez la commande de nettoyage en sélectionnant Exécuter maintenant.
Bonnes pratiques
- Période de rétention : définissez un intervalle de rétention d’au moins 7 jours pour éviter que les anciens instantanés et les fichiers non validés soient supprimés prématurément, ce qui pourrait nuire à la lecture et à l’enregistrement simultanés des tables.
- Maintenance régulière : planifiez un nettoyage régulier dans le cadre de votre routine de maintenance des données pour que vos tables Delta restent optimisées et prêtes pour l’analytique.
En incorporant le nettoyage dans votre stratégie de maintenance des données, vous avez l’assurance que votre destination Lakehouse reste efficace, économique et fiable pour vos opérations de flux de données.
Si vous souhaitez en savoir plus sur la maintenance des tables dans Lakehouse, veuillez consulter la documentation sur la maintenance des tables Delta.
Nullable
Dans certains cas, lorsque vous avez une colonne pouvant accepter la valeur Null, elle est détectée par Power Query comme non-nullable et lors de l’écriture dans la destination de données, le type de colonne n’est pas nullable. Pendant l’actualisation, l’erreur suivante se produit :
E104100 Couldn't refresh entity because of an issue with the mashup document MashupException.Error: DataFormat.Error: Error in replacing table's content with new data in a version: #{0}., InnerException: We can't insert null data into a non-nullable column., Underlying error: We can't insert null data into a non-nullable column. Details: Reason = DataFormat.Error;Message = We can't insert null data into a non-nullable column.; Message.Format = we can't insert null data into a non-nullable column.
Pour forcer les colonnes pouvant accepter la valeur Null, vous pouvez essayer les étapes suivantes :
Supprimez la table de la destination des données.
Supprimez la destination des données du flux de données.
Accédez au flux de données et mettez à jour les types de données à l’aide du code Power Query suivant :
Table.TransformColumnTypes( #"PREVIOUS STEP", { {"COLLUMNNAME1", type nullable text}, {"COLLUMNNAME2", type nullable Int64.Type} } )Ajoutez la destination de données.
Conversion des types de données et mise à l'échelle
Dans certains cas, le type de données dans le flux de données diffère de ce qui est pris en charge dans la destination des données. Nous avons mis en place des conversions par défaut afin de garantir que vous puissiez toujours obtenir vos données dans la destination des données :
| Destination | Flux de données Type de données | Type de données de destination |
|---|---|---|
| Fabric Warehouse | Int8.Type | Int16.Type |