Runtimes Apache Spark dans Fabric
Microsoft Fabric Runtime est une plateforme intégrée à Azure basée sur Apache Spark qui permet l’exécution et la gestion d’expériences d’ingénierie et de science des données. Il combine des composants clés provenant de sources internes et open source, offrant ainsi aux clients une solution complète. Pour plus de simplicité, nous faisons référence à Microsoft Fabric Runtime optimisé par Apache Spark sous le nom de Fabric Runtime.
Principaux composants de Fabric Runtime :
Apache Spark – une puissante bibliothèque informatique distribuée open source qui permet des tâches de traitement et d’analyse de données à grande échelle. Apache Spark fournit une plateforme polyvalente et hautes performances pour les expériences d’ingénierie des données et de science des données.
Delta Lake : une couche de stockage open source qui apporte des transactions ACID et d’autres fonctionnalités de fiabilité des données à Apache Spark. Intégré à Fabric Runtime, Delta Lake améliore les capacités de traitement des données et garantit la cohérence des données sur plusieurs opérations simultanées.
Le moteur d’exécution natif est une amélioration transformatrice pour les charges de travail Apache Spark, offrant des gains de performances significatifs en exécutant directement des requêtes Spark sur l’infrastructure lakehouse. Intégré en toute transparence, il ne nécessite aucune modification du code et évite le verrouillage du fournisseur, prenant en charge les formats Parquet et Delta entre les API Apache Spark dans Runtime 1.3 (Spark 3.5). Ce moteur augmente la vitesse des requêtes jusqu'à quatre fois plus vite que Spark OSS traditionnel, comme le montre le benchmark TPC-DS 1TB, réduisant ainsi les coûts opérationnels et améliorant l'efficacité des différentes tâches liées aux données, notamment l'ingestion de données, l'ETL, l'analyse et les requêtes interactives. Basé sur Meta’s Velox et Intel’s Apache Gluten, il optimise l’utilisation des ressources lors de la gestion de divers scénarios de traitement de données.
Packages de niveau par défaut pour Java/Scala, Python et R – packages prenant en charge divers langages et environnements de programmation. Ces packages sont automatiquement installés et configurés, ce qui permet aux développeurs d’appliquer leurs langages de programmation préférés pour les tâches de traitement des données.
Microsoft Fabric Runtime repose sur un système d’exploitation open source robuste, ce qui garantit la compatibilité avec les exigences du système et de diverses configurations matérielles.
Vous trouverez ci-dessous une comparaison complète des composants clés, notamment les versions d’Apache Spark, les systèmes d’exploitation pris en charge, Java, Scala, Python, Delta Lake et R, pour les runtimes basés sur Apache Spark au sein de la plateforme Microsoft Fabric.
Conseil
Utilisez toujours la version la plus récente du runtime GA pour votre charge de travail de production, qui est actuellement Runtime 1.3.
| Runtime 1.1 | Runtime 1.2 | Runtime 1.3 | |
|---|---|---|---|
| phase de déploiement | EOSA | GA | GA |
| Apache Spark | 3.3.1 | 3.4.1 | 3.5.0 |
| Système d’exploitation | Ubuntu 18.04 | Mariner 2.0 | Mariner 2.0 |
| Java | 8 | 11 | 11 |
| Scala | 2.12.15 | 2.12.17 | 2.12.17 |
| Python | 3.10 | 3.10 | 3.11 |
| Delta Lake | 2.2.0 | 2.4.0 | 3.2 |
| R | 4.2.2 | 4.2.2 | 4.4.1 |
Visitez Runtime 1.1, Runtime 1.2 ou Runtime 1.3pour explorer tous les détails, les nouvelles fonctionnalités, les améliorations et les scénarios de migration pour la version de runtime spécifique.
Optimisations de Fabric
Dans Microsoft Fabric, le moteur Spark et les implémentations Delta Lake incorporent des fonctionnalités et des optimisations spécifiques à la plateforme. Ces fonctionnalités sont conçues pour utiliser des intégrations natives dans la plateforme. Il est important de noter que toutes ces fonctionnalités peuvent être désactivées pour obtenir une fonctionnalité de Spark standard et de Delta Lake. Les runtimes Fabric pour Apache Spark comprennent les éléments suivants :
- Version open source complète d’Apache Spark.
- Collection de près de 100 améliorations distinctes et intégrées du niveau de performance des requêtes. Ces améliorations comprennent des fonctionnalités telles que la mise en cache des partitions (activant le cache de partition FileSystem pour réduire les appels de metastore) et la jointure croisée des projections de sous-requête scalaire.
- Cache intelligent intégré.
Au sein de Fabric Runtime pour Apache Spark et Delta Lake, il existe des capacités de rédacteur natives qui ont deux objectifs clés :
- Elles offrent un niveau de performance différencié pour l’écriture de charges de travail et l’optimisation du processus d’écriture.
- Leur valeur par défaut est définie sur Optimisation V-Order des fichiers de format Delta Parquet. L’optimisation V-Order Delta Lake est indispensable pour fournir un niveau de performance supérieur en lecture dans tous les moteurs Fabric. Pour obtenir une compréhension plus approfondie sur son fonctionnement et sa gestion, reportez-vous à l’article dédié sur Optimisation de la table Delta Lake et V-Order.
Prise en charge de plusieurs runtimes
Fabric prend en charge plusieurs runtimes, offrant aux utilisateurs la flexibilité de basculer de l’un à l’autre en toute transparence et réduisant le risque d’incompatibilité ou d’interruption.
Par défaut, tous les nouveaux espaces de travail utilisent la dernière version de runtime, qui est actuellement Runtime 1.3.
Pour modifier la version du runtime au niveau de l’espace de travail, accédez à Paramètres de l’espace de travail>Data Engineering/Science>Spark. Sous l’onglet Environnement, sélectionnez votre version d’exécution souhaitée dans les options disponibles. Sélectionnez Enregistrer pour confirmer votre sélection.
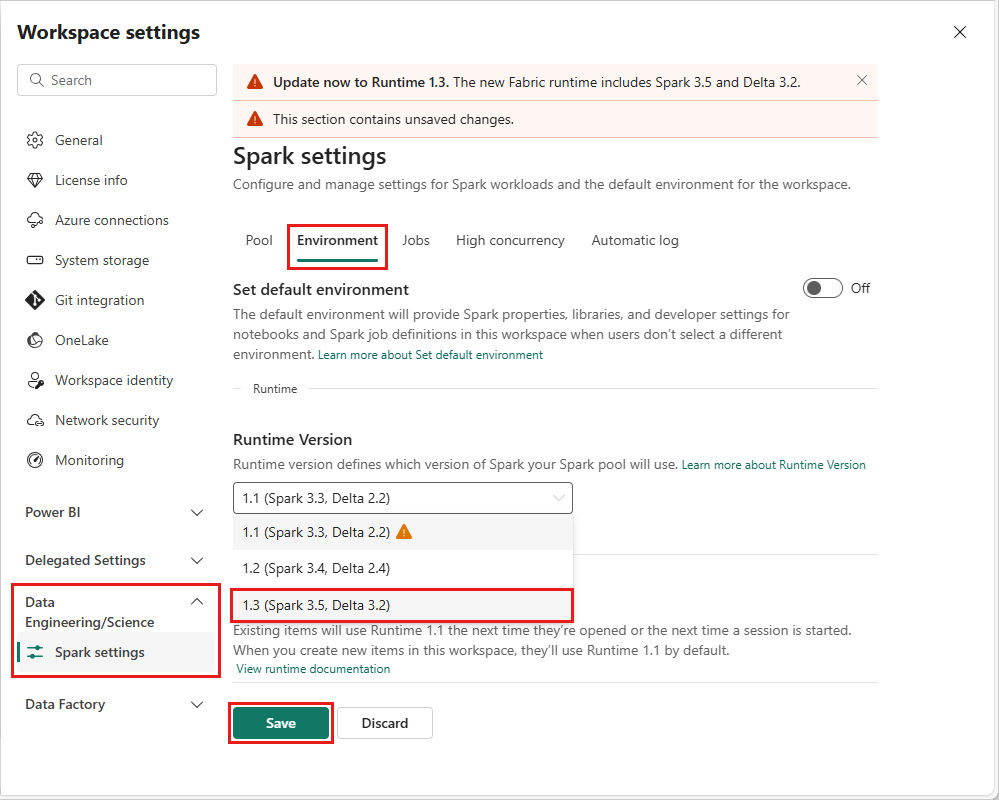
Une fois cette modification effectuée, tous les éléments créés par le système dans l’espace de travail, notamment des lakehouses, des SJD et des notebooks, fonctionnent en utilisant la nouvelle version sélectionnée de runtime au niveau de l’espace de travail à compter de la prochaine session Spark. Si vous utilisez actuellement un notebook avec une session existante pour un travail ou toute tâche liée à un lakehouse, cette session Spark continue telle quelle. Toutefois, à compter de la prochaine session ou du prochain travail, la version de runtime sélectionnée est appliquée.
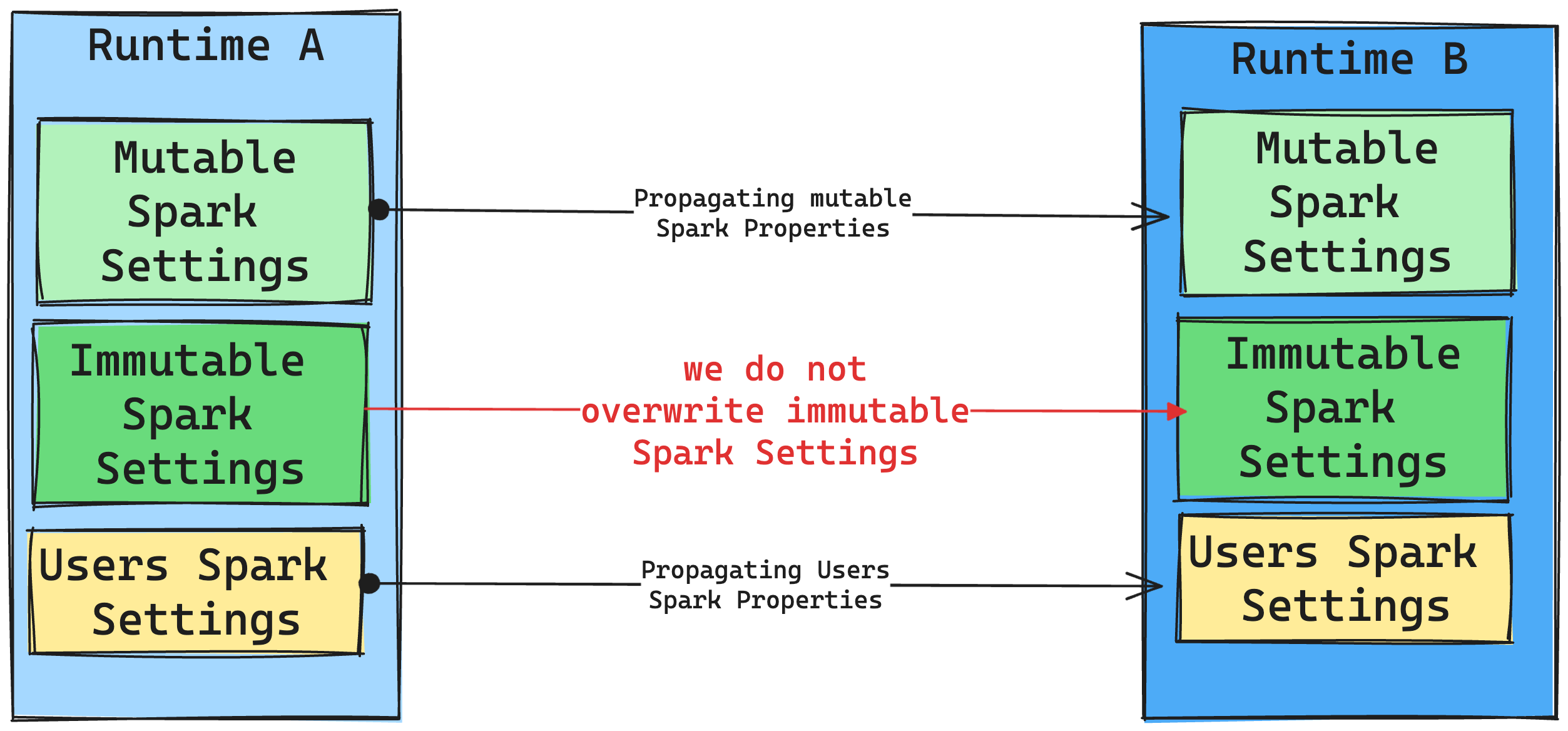
Conséquences des modifications apportées au runtime sur les paramètres Spark
Nous nous efforçons en général de migrer tous les paramètres Spark. Cependant, si nous identifions que le paramètre Spark n’est pas compatible avec Runtime B, nous émettons un message d’avertissement et évitons d’implémenter le paramètre.
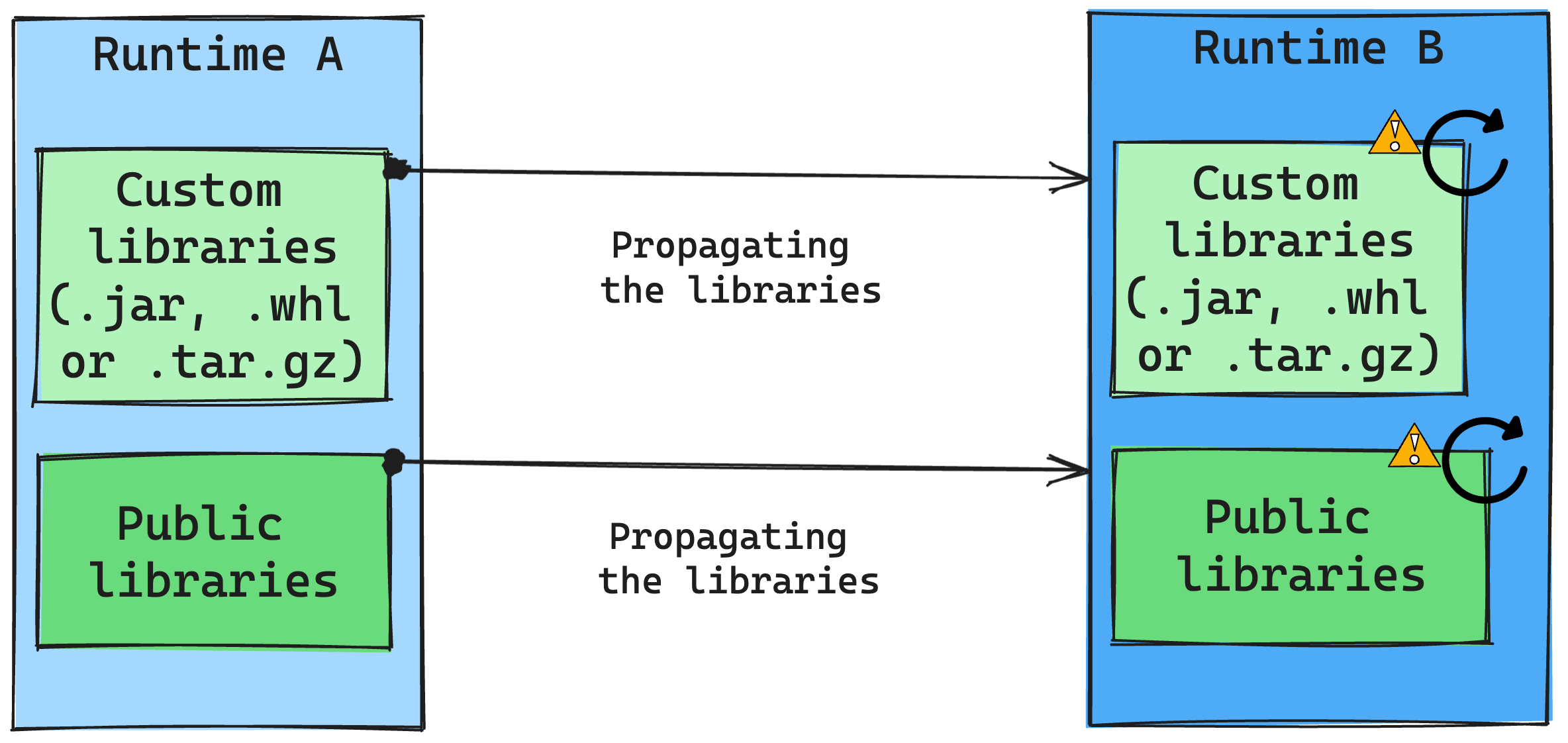
Conséquences des modifications apportées au runtime sur la gestion de la bibliothèque
En général, notre approche est de migrer toutes les bibliothèques de Runtime A à Runtime B, y compris les runtimes publics et personnalisés. Si les versions Python et R restent inchangées, les bibliothèques doivent fonctionner correctement. Toutefois, pour les fichiers Jars, il existe une forte probabilité qu’ils ne fonctionnent pas en raison d’altérations dans les dépendances et d’autres facteurs tels que les modifications dans Scala, Java, Spark et le système d’exploitation.
L’utilisateur est responsable de la mise à jour ou du remplacement de bibliothèques qui ne fonctionnent pas avec le Runtime B. En cas de conflit, c’est-à-dire quand le Runtime B inclut une bibliothèque initialement définie dans le Runtime A, notre système de gestion de bibliothèques tente de créer la dépendance nécessaire pour le Runtime B en fonction des paramètres de l’utilisateur. Toutefois, le processus de création échoue si un conflit se produit. Dans le journal des erreurs, les utilisateurs peuvent voir quelles bibliothèques provoquent des conflits et apporter des ajustements à leurs versions ou spécifications.
Mettre à jour le protocole Delta Lake
Les fonctionnalités Delta Lake sont toujours à compatibilité descendante pour veiller à ce que les tables créées dans une version Delta Lake antérieure peuvent interagir en toute transparence avec des versions supérieures. Cependant, quand certaines fonctionnalités sont activées (par exemple, en utilisant la méthode delta.upgradeTableProtocol(minReaderVersion, minWriterVersion), la compatibilité ascendante avec des versions Delta Lake antérieures peut être compromise. Dans ces instances, il est essentiel de modifier des charges de travail faisant référence à des tables mises à niveau pour qu’elles s’alignent sur une version Delta Lake qui maintient la compatibilité.
Chaque table Delta est associée à une spécification de protocole pour définir les fonctionnalités qu’elle prend en charge. Les applications qui interagissent avec la table, que ce soit pour la lecture ou l’écriture, s’appuient sur cette spécification de protocole pour déterminer si elles sont compatibles avec l’ensemble des fonctionnalités de la table. Si une application ne dispose pas de la possibilité de gérer une fonctionnalité répertoriée comme prise en charge dans le protocole de la table, elle ne peut pas lire ou écrire dans cette table.
La spécification de protocole est divisée en deux composants distincts : le protocole de lecture et le protocole d’écriture. Visitez la page « Comment Delta Lake gère-t-il la compatibilité des fonctionnalités ? » pour en savoir plus.

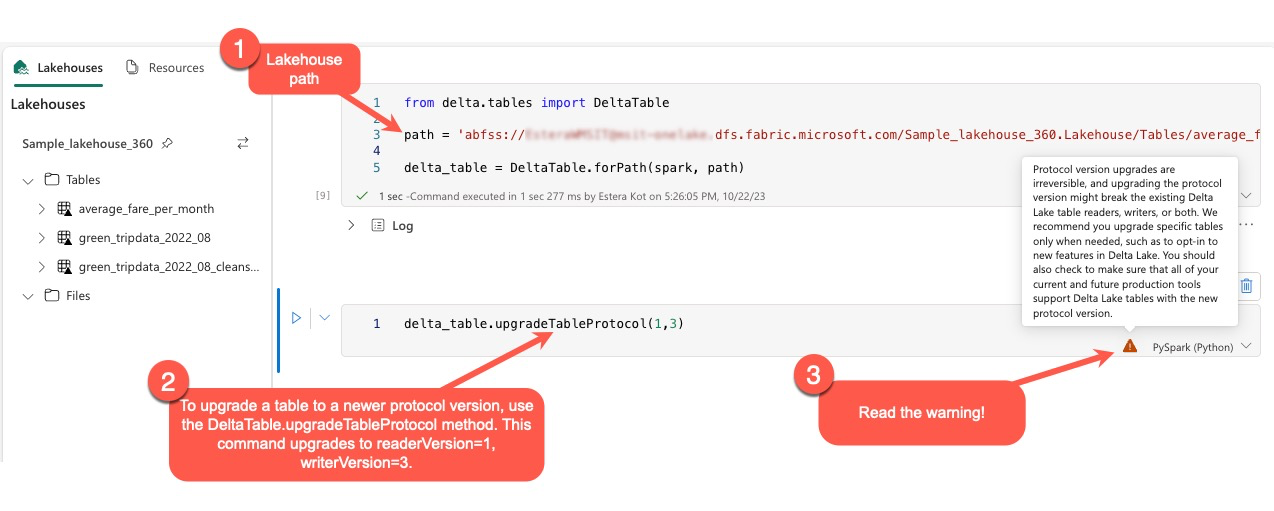
Les utilisateurs peuvent exécuter la commande delta.upgradeTableProtocol(minReaderVersion, minWriterVersion) dans l’environnement PySpark, et dans Spark SQL et Scala. Cette commande leur permet de lancer une mise à jour sur la table Delta.
Il est important de noter que lors de l’exécution de cette mise à niveau, les utilisateurs reçoivent un avertissement indiquant que la mise à niveau de la version de protocole Delta est un processus non réversible. Cela signifie qu’une mise à jour exécutée ne peut pas être annulée.
Les mises à niveau de protocole peuvent potentiellement affecter la compatibilité des rédacteurs, des lecteurs de table Delta Lake existants, ou des deux. Par conséquent, nous vous conseillons d’agir avec prudence et de mettre à niveau la version de protocole uniquement si cela est nécessaire, comme dans le cas de l’adoption de nouvelles fonctionnalités dans Delta Lake.
En outre, les utilisateurs doivent vérifier que tous les processus et charges de travail de production actuels et futurs sont compatibles avec les tables Delta Lake en utilisant la nouvelle version de protocole pour veiller à une transition transparente et éviter toute interruption potentielle.
Modifications de Delta 2.2. par rapport à Delta 2.4
Dans Fabric Runtime, version 1.3 et Fabric Runtime, version 1.2 les plus récentes, le format de table par défaut (spark.sql.sources.default) est désormais delta. Dans les versions précédentes de Fabric Runtime, version 1.1 et sur toutes celles de Synapse Runtime pour Apache Spark contenant Spark 3.3 ou une version antérieure, le format de table par défaut était défini comme parquet. Consultez le tableau suivant incluant les détails de configuration Apache Spark pour découvrir les différences entre Azure Synapse Analytics et Microsoft Fabric.
Toutes les tables créées en utilisant Spark SQL, PySpark, Scala Park et Spark R, chaque fois que le type de table est omis, créent une table comme delta par défaut. Si des scripts définissent le format de table de manière explicite, il sera respecté. La commande USING DELTA dans les commandes créer une table de Spark devient redondante.
Les scripts qui attendent ou supposent un format de table parquet doivent être révisés. Les commandes suivantes ne sont pas prises en charge dans les tables Delta :
ANALYZE TABLE $partitionedTableName PARTITION (p1) COMPUTE STATISTICSALTER TABLE $partitionedTableName ADD PARTITION (p1=3)ALTER TABLE DROP PARTITIONALTER TABLE RECOVER PARTITIONSALTER TABLE SET SERDEPROPERTIESLOAD DATAINSERT OVERWRITE DIRECTORYSHOW CREATE TABLECREATE TABLE LIKE