Visualisation du Notebook dans Microsoft Fabric
Microsoft Fabric est un service d’analytique intégré qui accélère la découverte d’insights sur les entrepôts de données et les systèmes d’analytique de Big Data. La visualisation des données dans les notebooks est un élément clé qui vous permet de mieux interpréter vos données. Il permet de faciliter la compréhension des données volumineuses et petites pour les humains. Elle facilite également la détection des modèles, des tendances et des valeurs hors norme dans des groupes de données.
Lorsque vous utilisez Apache Spark dans Fabric, vous avez diverses options intégrées pour vous aider à visualiser vos données, notamment les options de graphique de notebook Fabric et l’accès à des bibliothèques open source connues.
Lorsque vous utilisez un notebook Fabric, vous pouvez convertir votre tableau de résultats en un graphique personnalisé à l’aide des options de graphique. Ici, vous pouvez visualiser vos données sans avoir à écrire de code.
Commande de visualisation intégrée — fonction display()
La fonction de visualisation intégrée Fabric vous permet de transformer les DataFrames Apache Spark, les DataFrames Pandas et les résultats des requêtes SQL en visualisations de données de format enrichi.
Vous pouvez utiliser la fonction afficher sur les dataframes créés dans PySpark et Scala à partir des DataFrames Spark ou des fonctions RDD (Resilient Distributed Datasets) pour produire l'affichage des tableaux et des graphiques des dataframes.
Vous pouvez spécifier le nombre de lignes du dataframe en cours de rendu. La valeur par défaut est 1 000. Le widget de sortie Affichage du notebook prend en charge l’affichage et le profil 1 000 lignes d’un DataFrame au maximum.

Vous pouvez utiliser la fonction de filtre dans la barre d’outils globale pour filtrer efficacement les données qui correspondent à votre règle personnalisée, la condition est appliquée à la colonne spécifiée et le résultat du filtre reflète à la fois en mode table et en mode graphique.

La sortie de l’instruction SQL adopte le même widget de sortie avec display() par défaut.
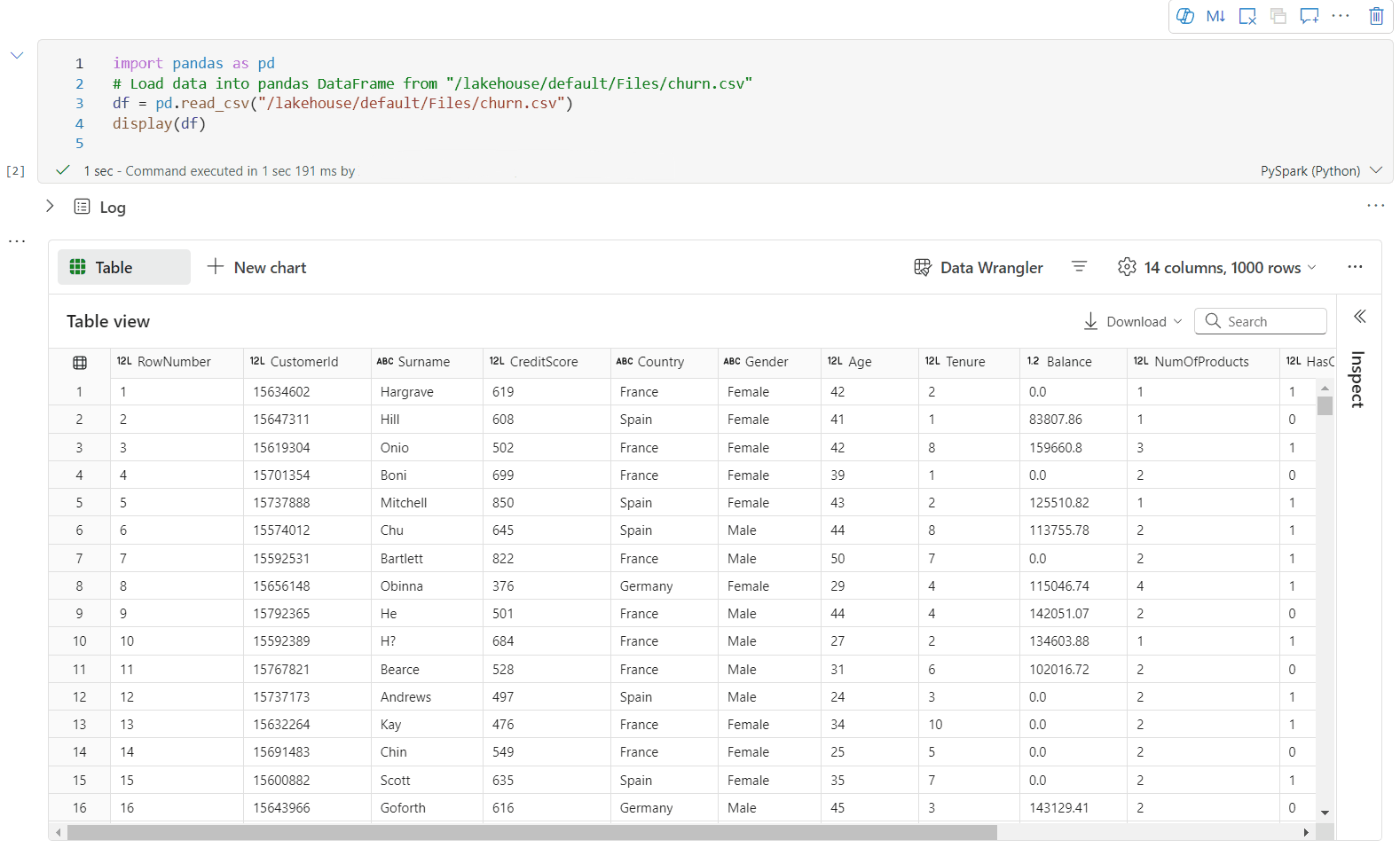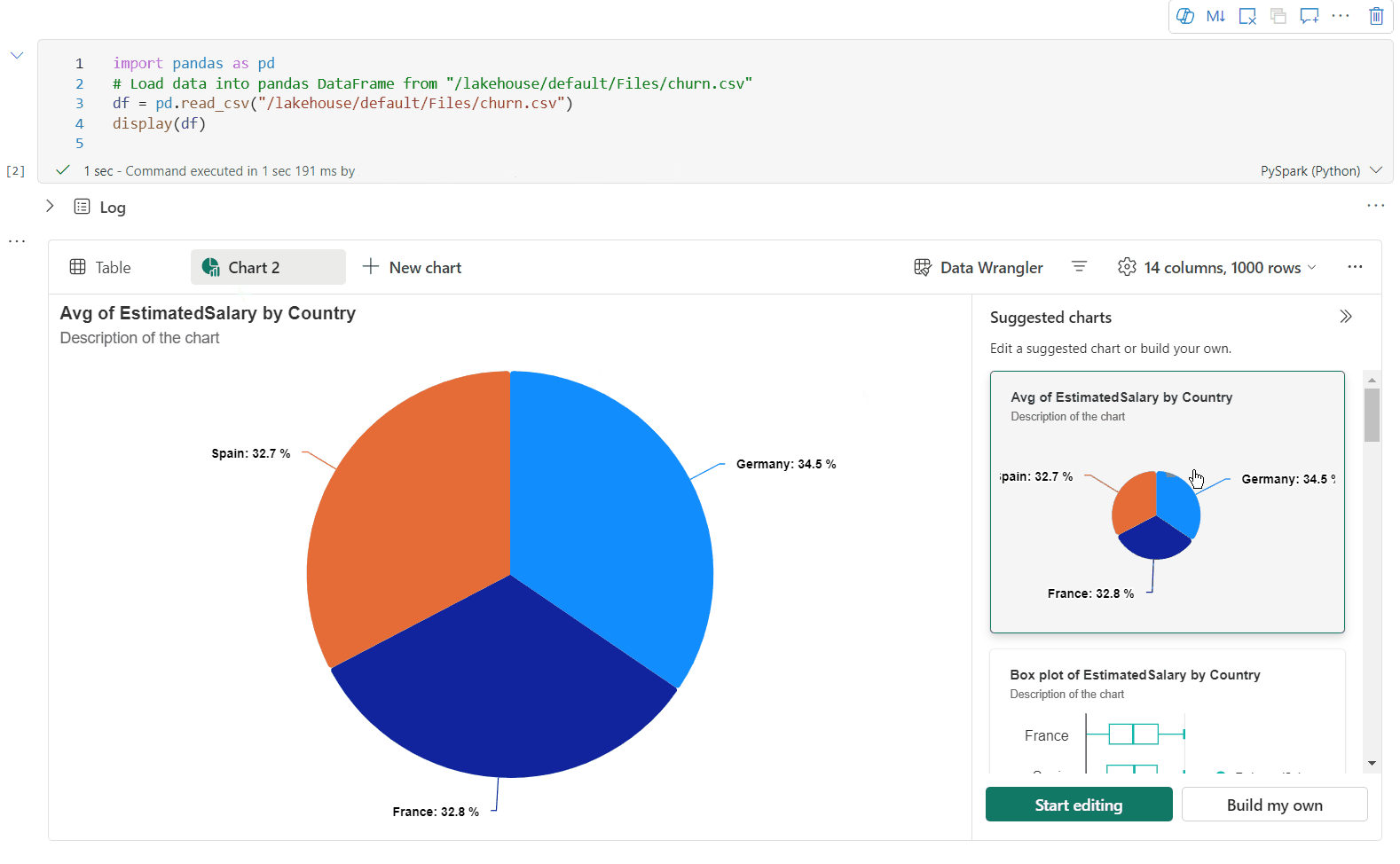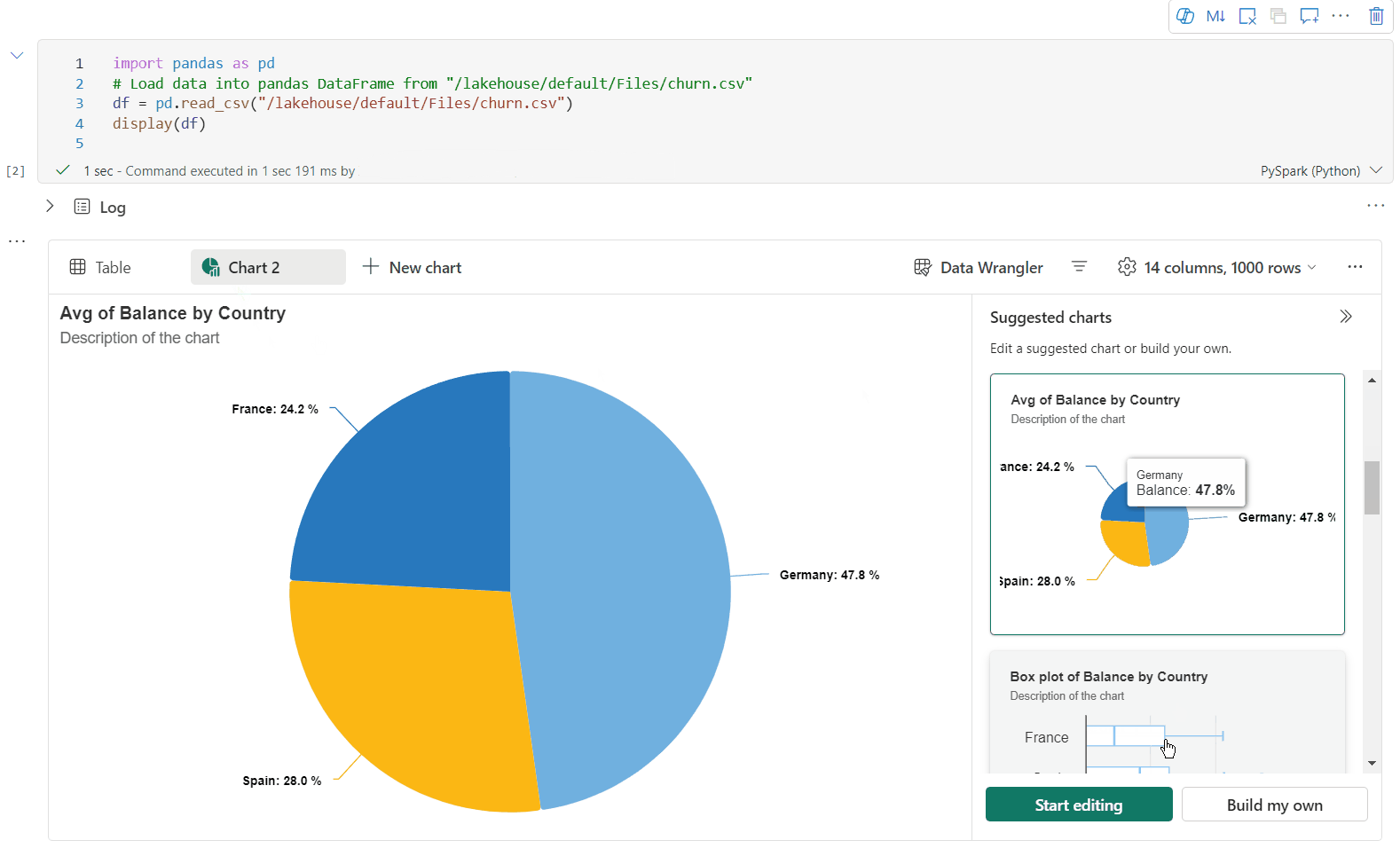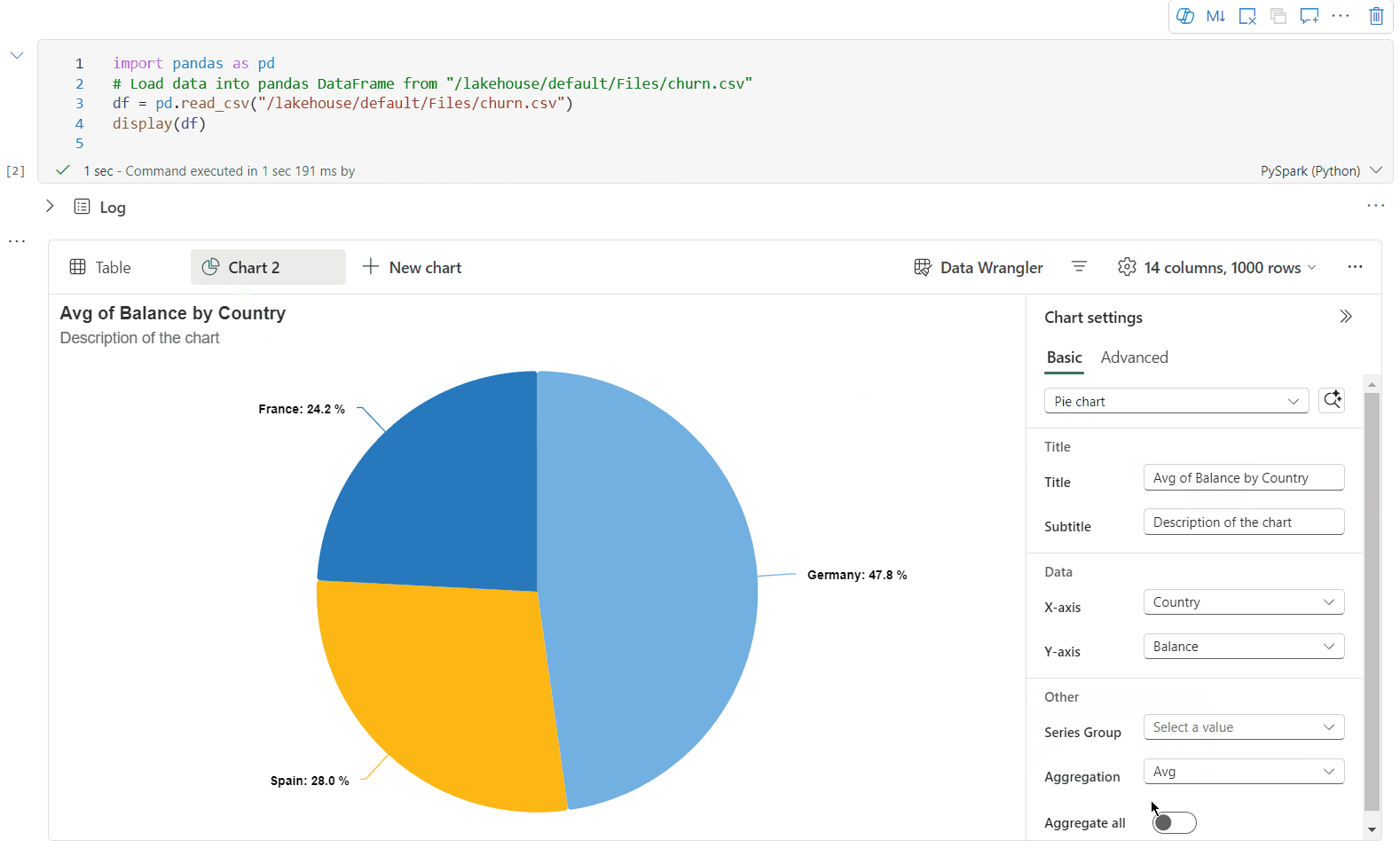
Visualisation d'un tableau d'une trame données riches
Prise en charge gratuite de la sélection sur l’affichage de la table
La visualisation du tableau est affichée par défaut lors de l'utilisation de la commande display(). La préversion complète du dataframe dans le notebook offre une fonction de sélection gratuite conçue pour améliorer l’expérience d’analyse des données grâce à des fonctionnalités de sélection flexibles et intuitives. Cette fonctionnalité permet aux utilisateurs d’interagir avec des trames de données plus efficacement et d’obtenir des insights plus approfondis avec facilité.
Sélection de colonnes
- colonne unique: cliquez sur l’en-tête de colonne pour sélectionner l’intégralité de la colonne.
- Plusieurs colonnes: Après avoir sélectionné une seule colonne, maintenez la touche 'Maj' enfoncée, puis cliquez sur un autre en-tête de colonne pour sélectionner plusieurs colonnes.
Sélection de lignes
- ligne unique: cliquez sur un en-tête de ligne pour sélectionner la ligne entière.
- Plusieurs lignes: Après avoir sélectionné une seule ligne, maintenez la touche « Majuscule » enfoncée, puis cliquez sur un autre en-tête de ligne pour sélectionner plusieurs lignes.
aperçu du contenu de cellule: affichez un aperçu du contenu des cellules individuelles pour obtenir un aperçu rapide et détaillé des données sans avoir à écrire de code supplémentaire.
résumé de colonne: obtenez un résumé de chaque colonne, y compris la distribution des données et les statistiques clés, pour comprendre rapidement les caractéristiques des données.
sélection de zone libre: sélectionnez n’importe quel segment continu du tableau pour obtenir une vue d’ensemble du total des cellules sélectionnées et des valeurs numériques dans la zone sélectionnée.
Copie du contenu sélectionné: dans tous les cas de sélection, vous pouvez rapidement copier le contenu sélectionné à l’aide du raccourci « Ctrl + C ». Les données sélectionnées sont copiées au format CSV, ce qui facilite le traitement dans d’autres applications.
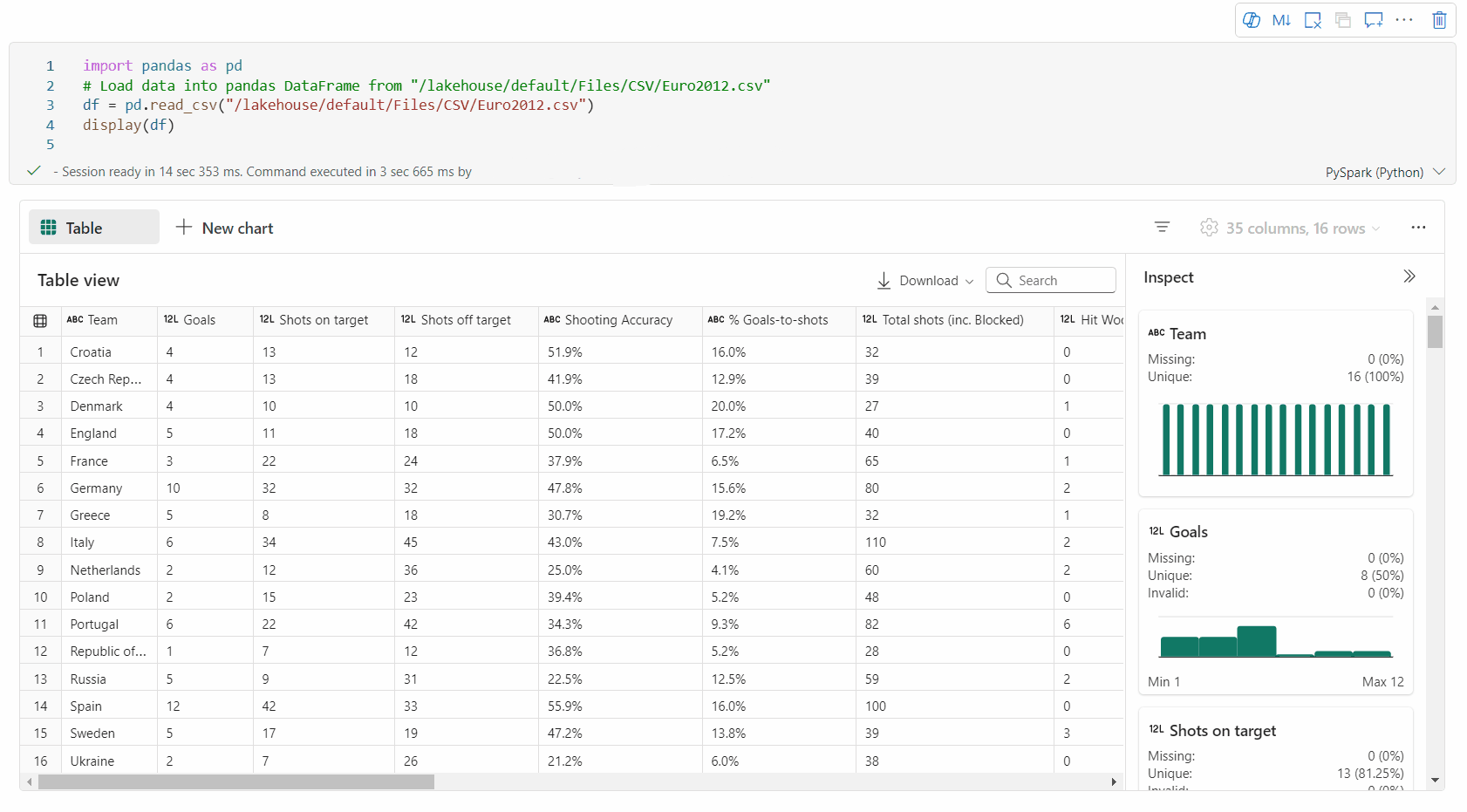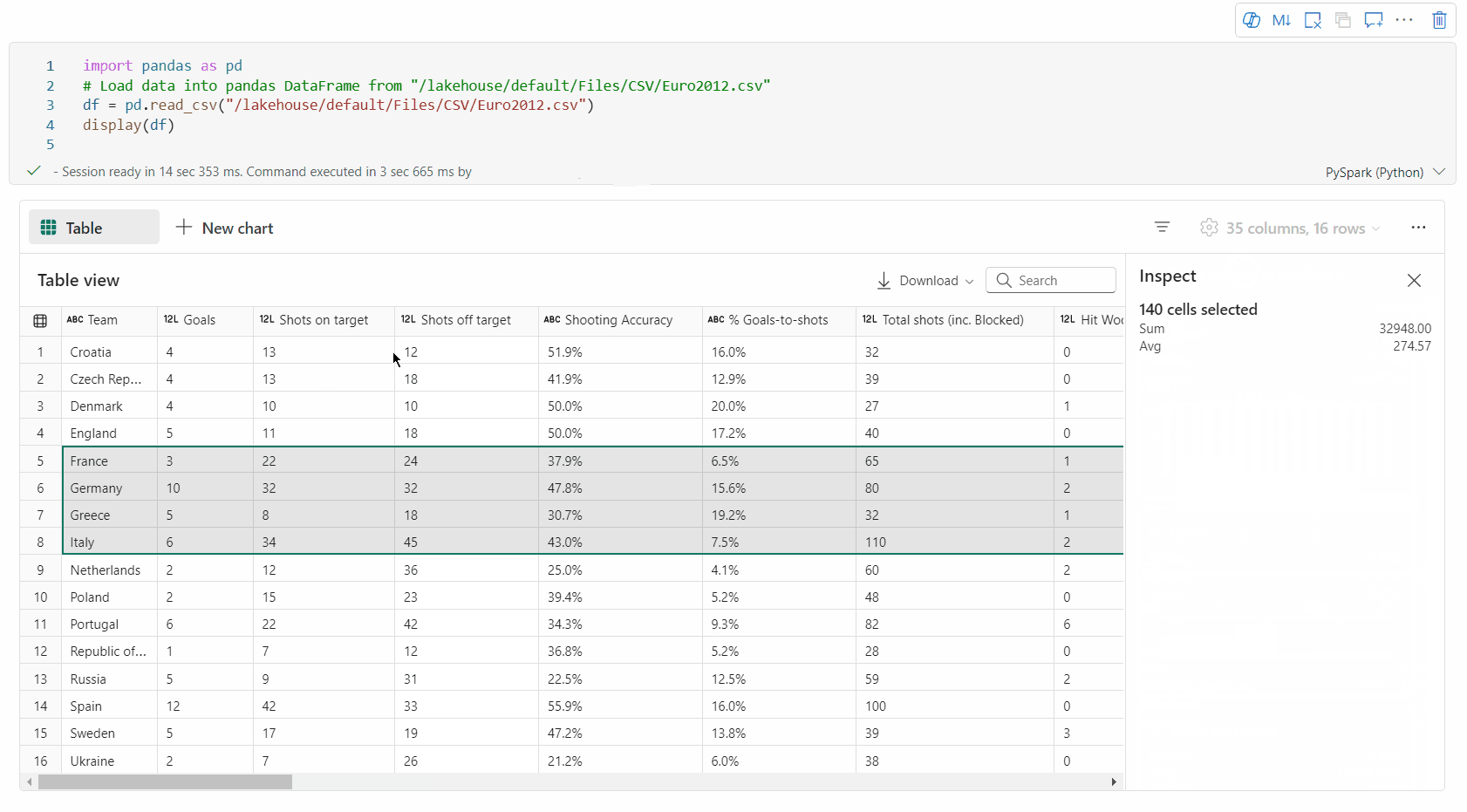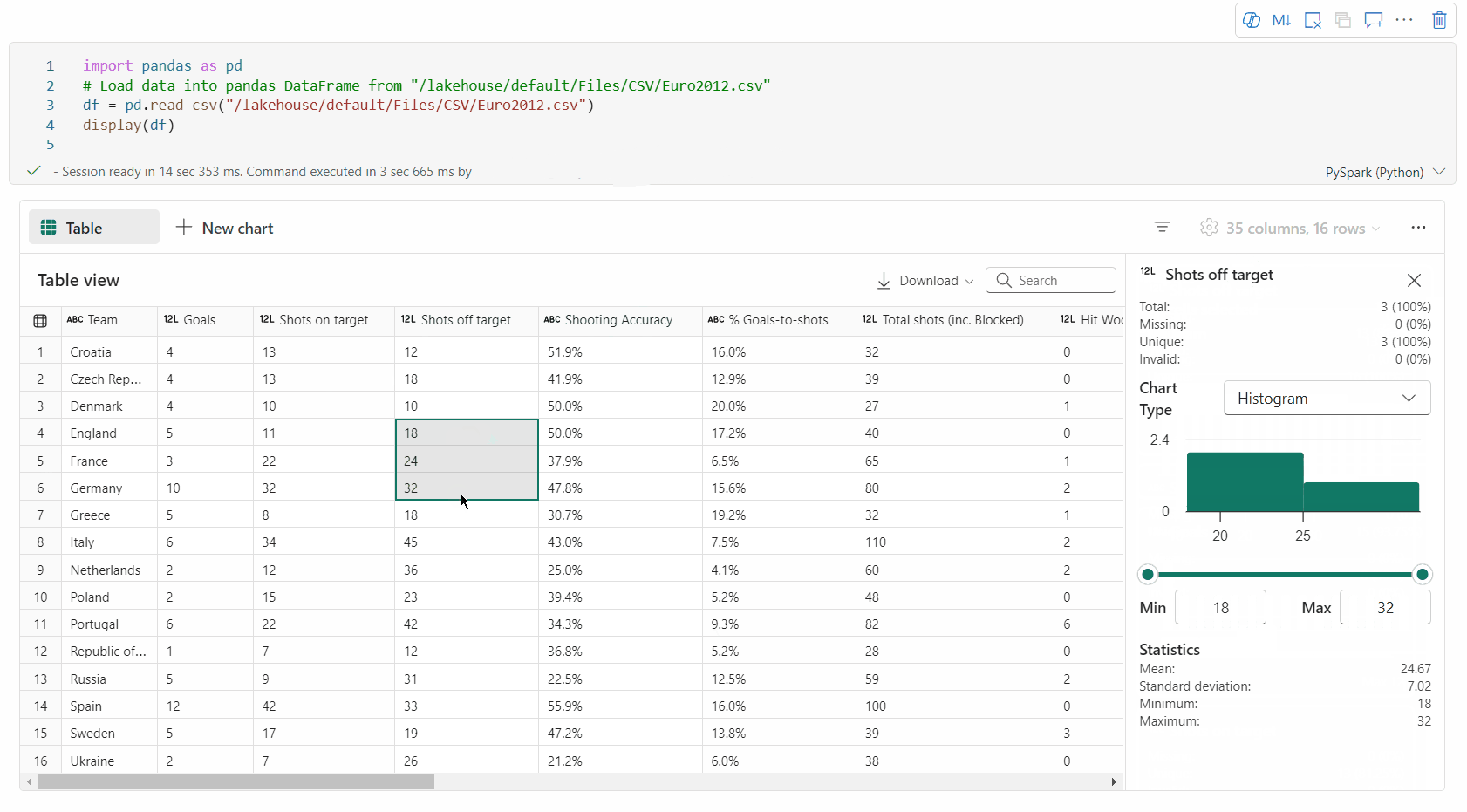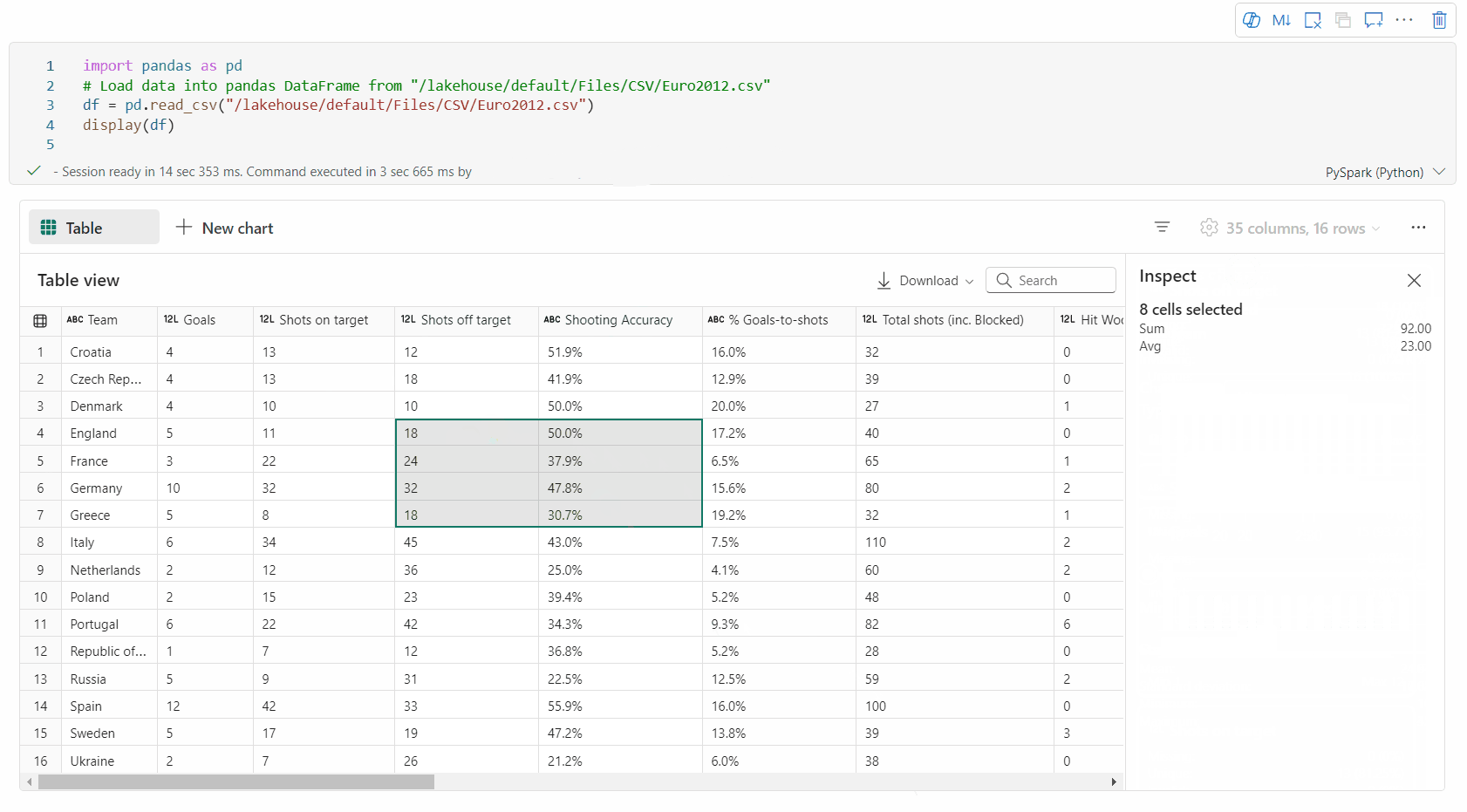
Prise en charge du profilage des données via le volet Inspecter
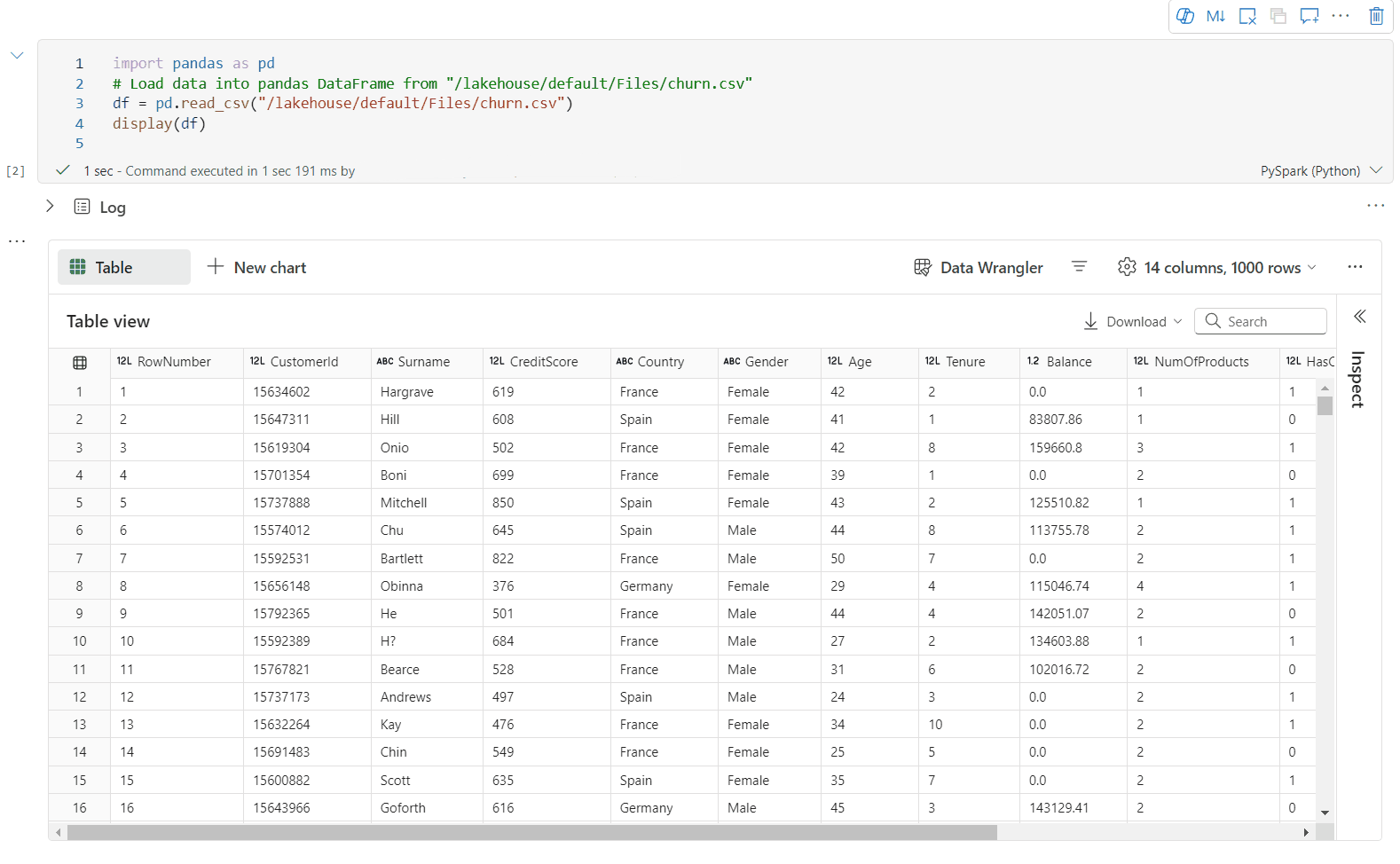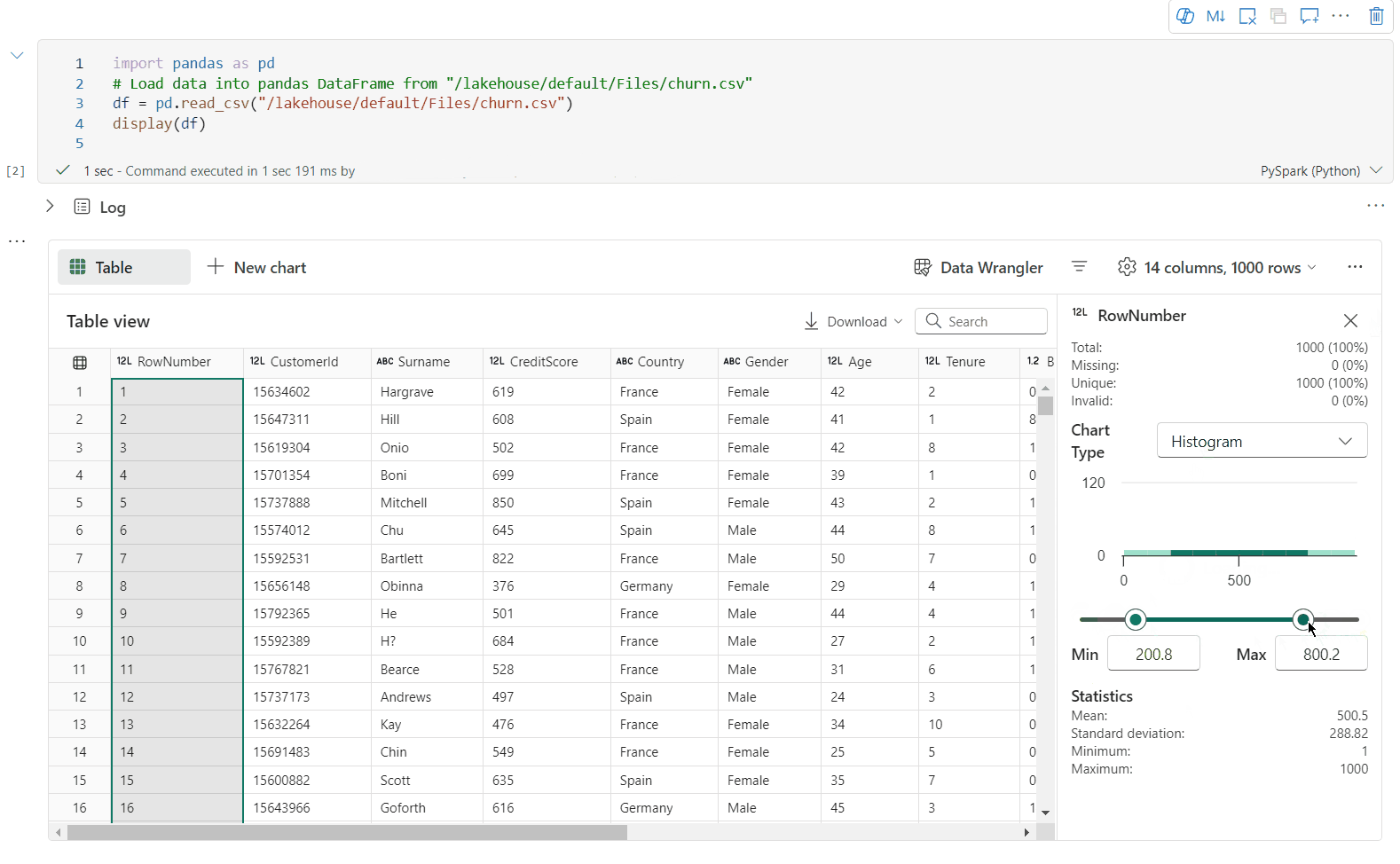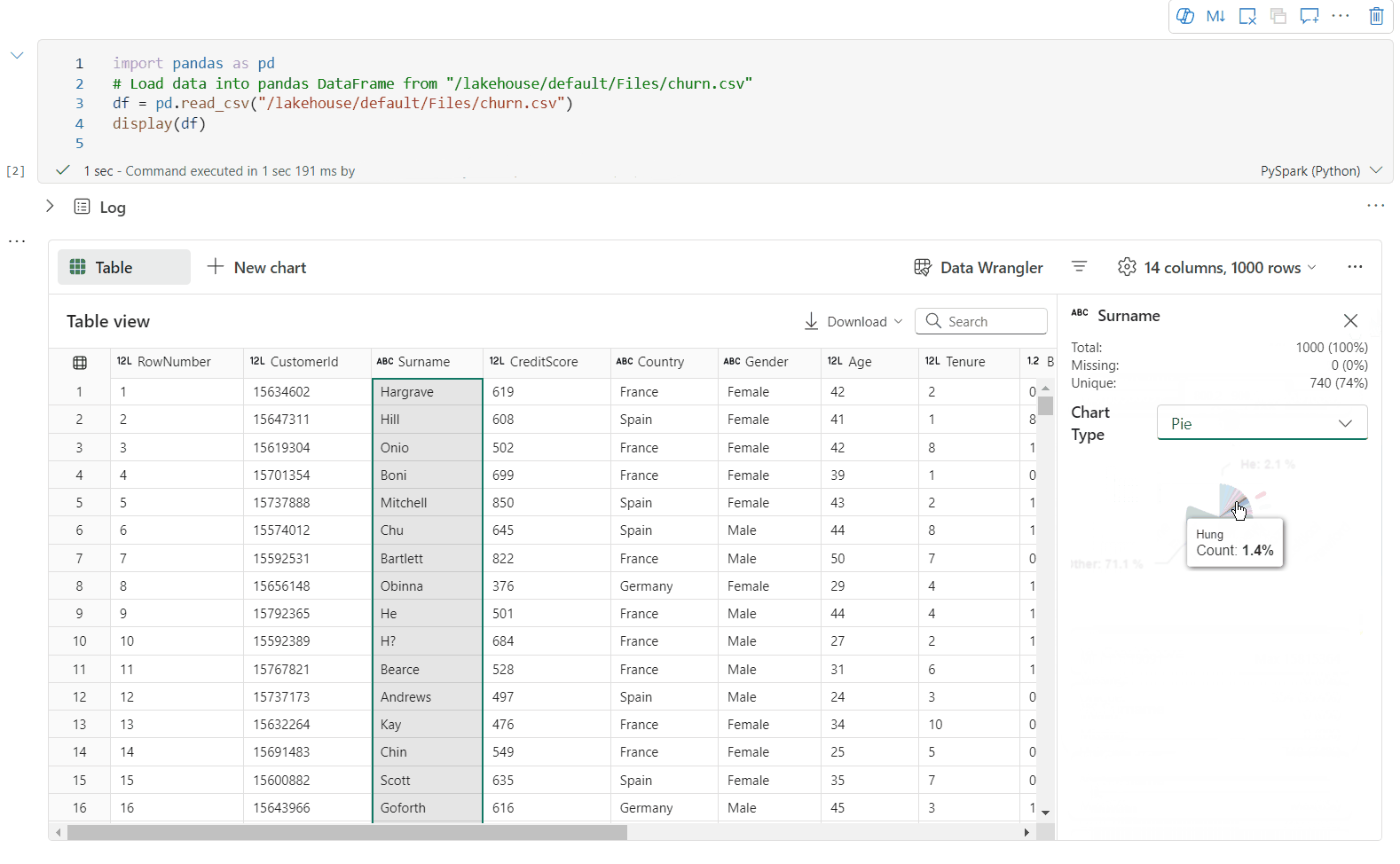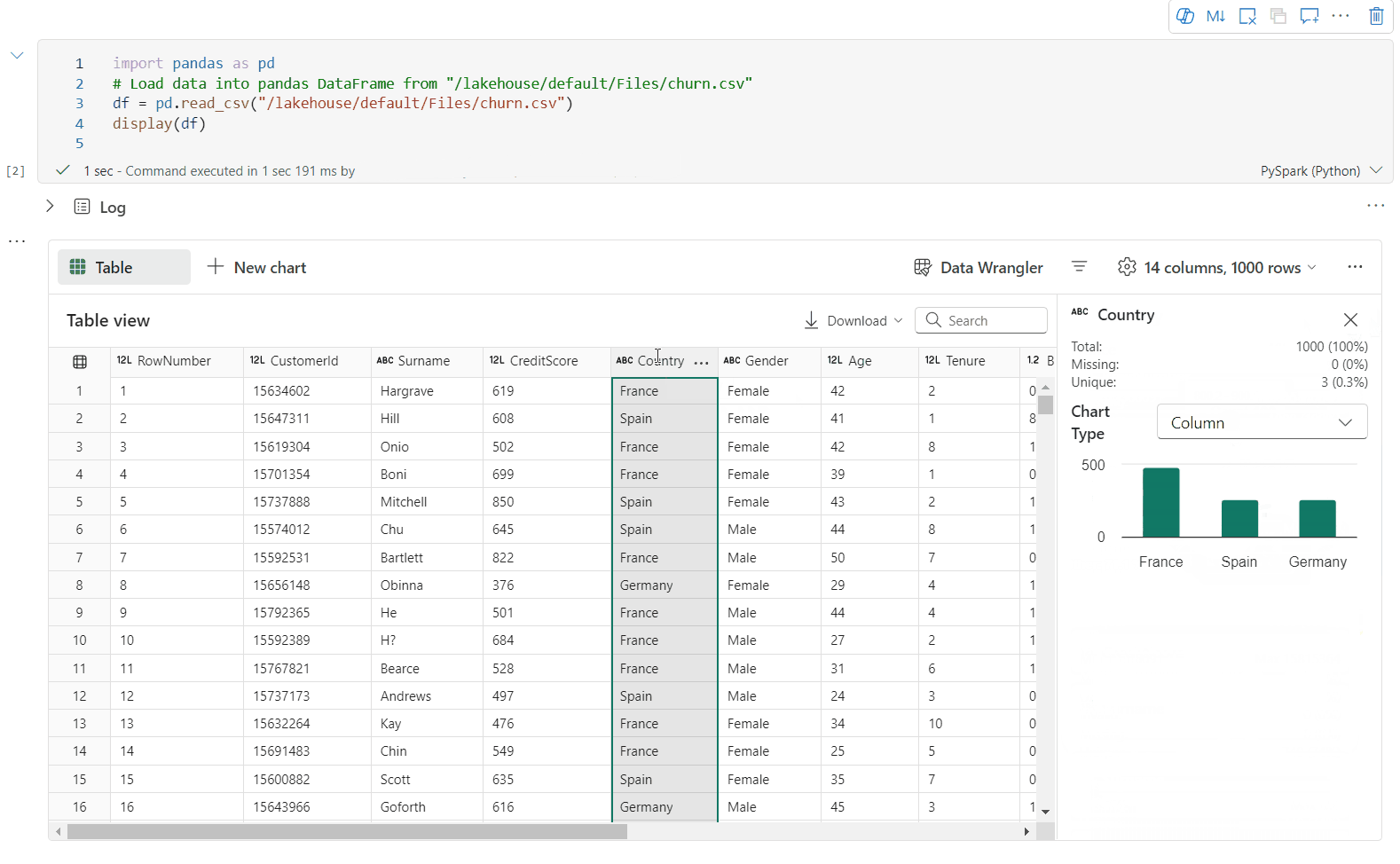
Vous pouvez profiler votre dataframe en cliquant sur le bouton Inspecter. Cette option fournit la distribution des données synthétisées et présente les statistiques de chaque colonne.
Chaque carte du volet latéral « Inspecter » correspond à une colonne de la trame de données. Vous pouvez obtenir plus de détails en cliquant sur la carte ou en sélectionnant une colonne dans le tableau.
Vous pouvez afficher les détails de la cellule en cliquant sur la cellule du tableau. Cette fonctionnalité est utile lorsque le dataframe contient un type de chaîne long de contenu.
Nouvelle visualisation graphique enrichie des DataFrames
Remarque
Actuellement, la fonctionnalité est en préversion.
La vue graphique améliorée est disponible sur la commande display(). Il offre une expérience plus intuitive et puissante pour visualiser vos données à l’aide de la commande display().
Vous pouvez maintenant ajouter jusqu’à cinq graphiques dans un widget de sortie display() en sélectionnant Nouveau graphique, ce qui vous permet de créer plusieurs graphiques basés sur différentes colonnes, et de comparer facilement des graphiques.
Vous pouvez obtenir une liste de recommandations de graphiques en fonction du DataFrame cible lors de la création de graphiques. Vous pouvez choisir de modifier un graphique recommandé ou de générer votre propre graphique à partir de zéro.
Vous pouvez maintenant personnaliser votre visualisation en spécifiant les paramètres suivants. Les options de paramètre peuvent changer en fonction du type de graphique sélectionné :
Catégorie Paramètres de base Description Type de graphique La fonction d'affichage prend en charge un large éventail de types de graphiques, y compris les graphiques à barres, les nuages de points, les graphiques linéaires, les tableaux croisés dynamiques, etc. Titre Titre Titre du graphique. Titre Sous-titre Sous-titre du graphique avec plus de descriptions. Données Axe X Spécifier la clé du graphique. Données Axe Y Spécifier les valeurs du graphique. Légende Afficher la légende Activer/désactiver la légende. Légende Position Personnaliser la position de la légende. Other Groupe de séries Utilisez cette configuration afin de déterminer les groupes pour l’agrégation. Other Agrégation Utilisez cette méthode pour agréger les données dans votre visualisation. Other Empilé Configurer le style d’affichage du résultat. Remarque
Par défaut, la fonction display(df) ne prend que les 1 000 premières lignes des données pour afficher les graphiques. Sélectionnez Agrégation sur tous les résultats, puis sélectionnez Appliquer pour appliquer la génération de graphique à partir du DataFrame entier. Un travail Spark est déclenché lorsque le paramètre de graphique change. La fin du calcul et le rendu du graphique peuvent prendre plusieurs minutes.
Catégorie Paramètres avancés Description Couleur Thème Définir l’ensemble de couleurs de thème du graphique. Axe X Étiquette Spécifiez une étiquette sur l’axe X. Axe X Mise à l’échelle Spécifier la fonction d’échelle de l’axe X. Axe X Plage Spécifier la plage de valeurs de l’axe X. Axe Y Étiquette Spécifiez une étiquette sur l’axe Y. Axe Y Mise à l’échelle Spécifier la fonction d’échelle de l’axe Y. Axe Y Plage Spécifier la plage de valeurs de l’axe Y. Affichage Afficher les étiquettes Afficher/masquer les étiquettes de résultats sur le graphique. Les modifications des configurations prennent effet immédiatement et toutes les configurations sont enregistrées automatiquement dans le contenu du notebook.

Vous pouvez facilement renommer, dupliquer ou supprimer des graphiques dans le menu de l’onglet Graphique.
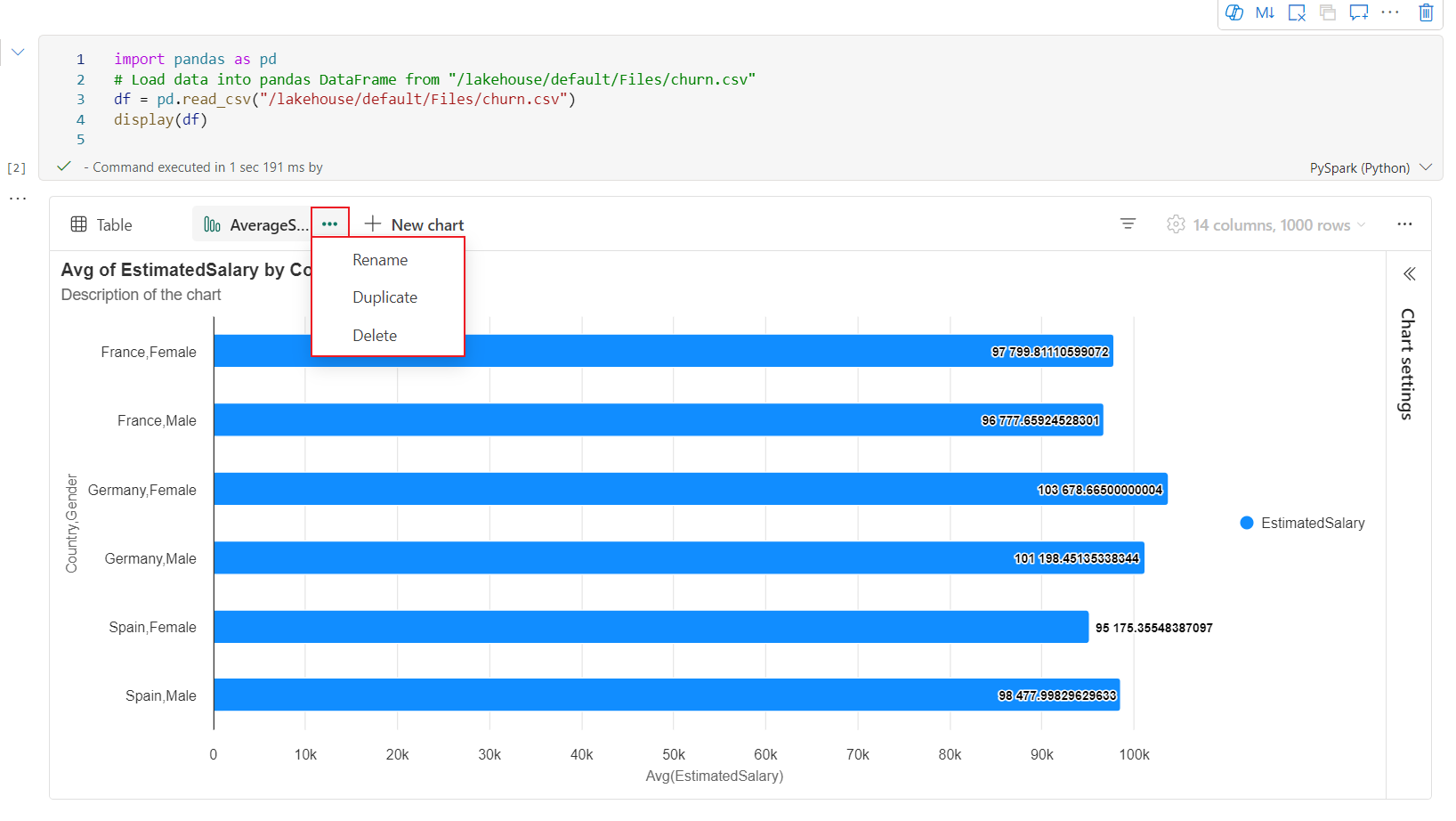
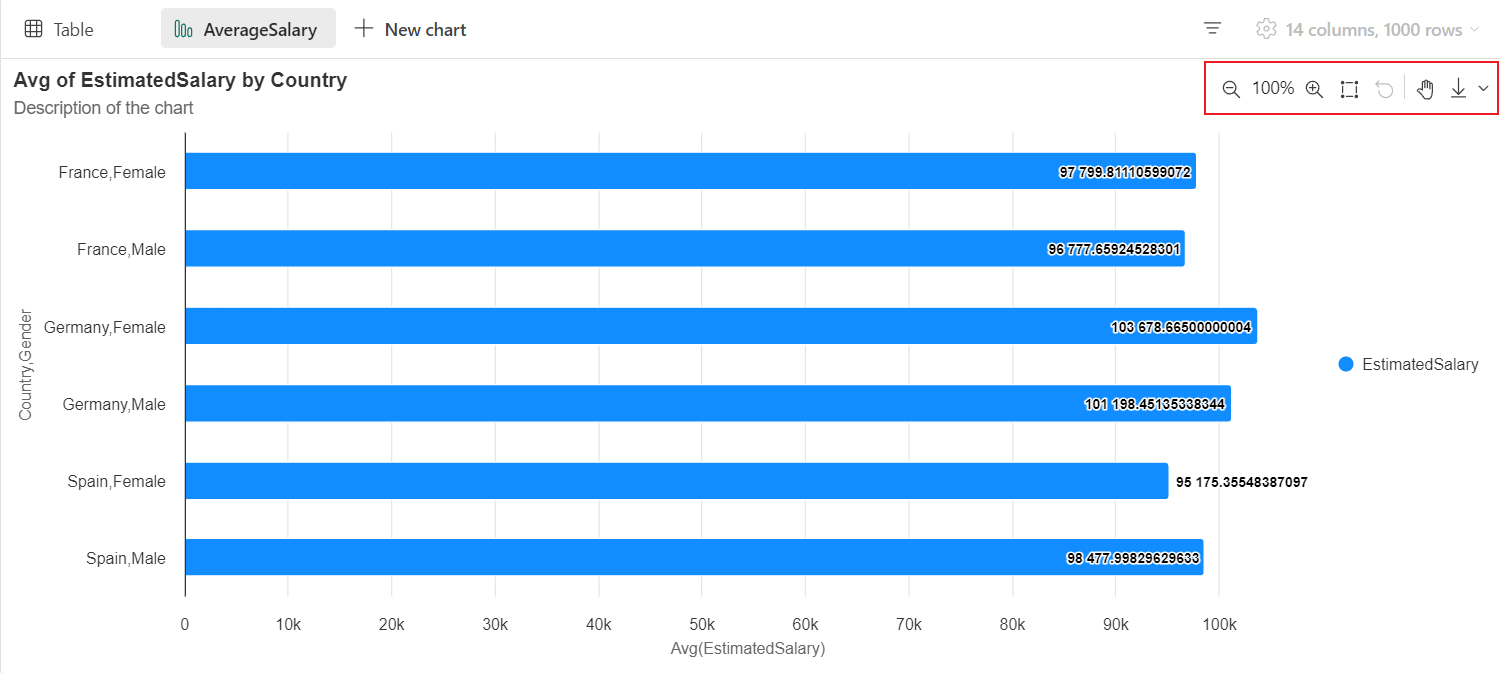
Une barre d’outils interactive est disponible dans la nouvelle expérience de graphique lorsque l’utilisateur pointe sur un graphique. Elle prend en charge des opérations telles que le zoom avant, le zoom arrière, la sélection pour zoomer, la réinitialisation, le panoramique, etc.



Vue graphique héritée
Remarque
La vue graphique héritée sera déconseillé dès la fin de la préversion de la nouvelle vue graphique.
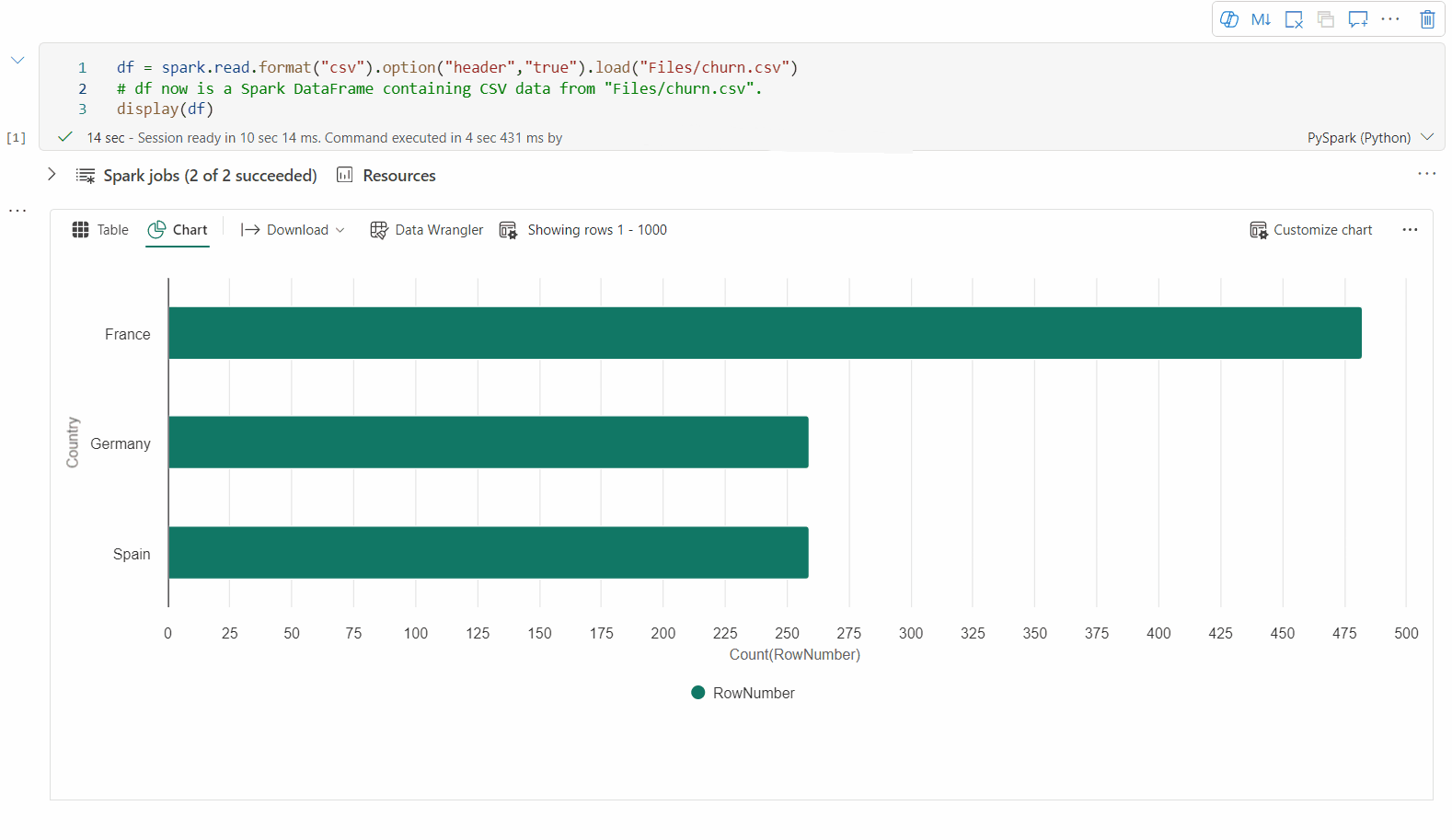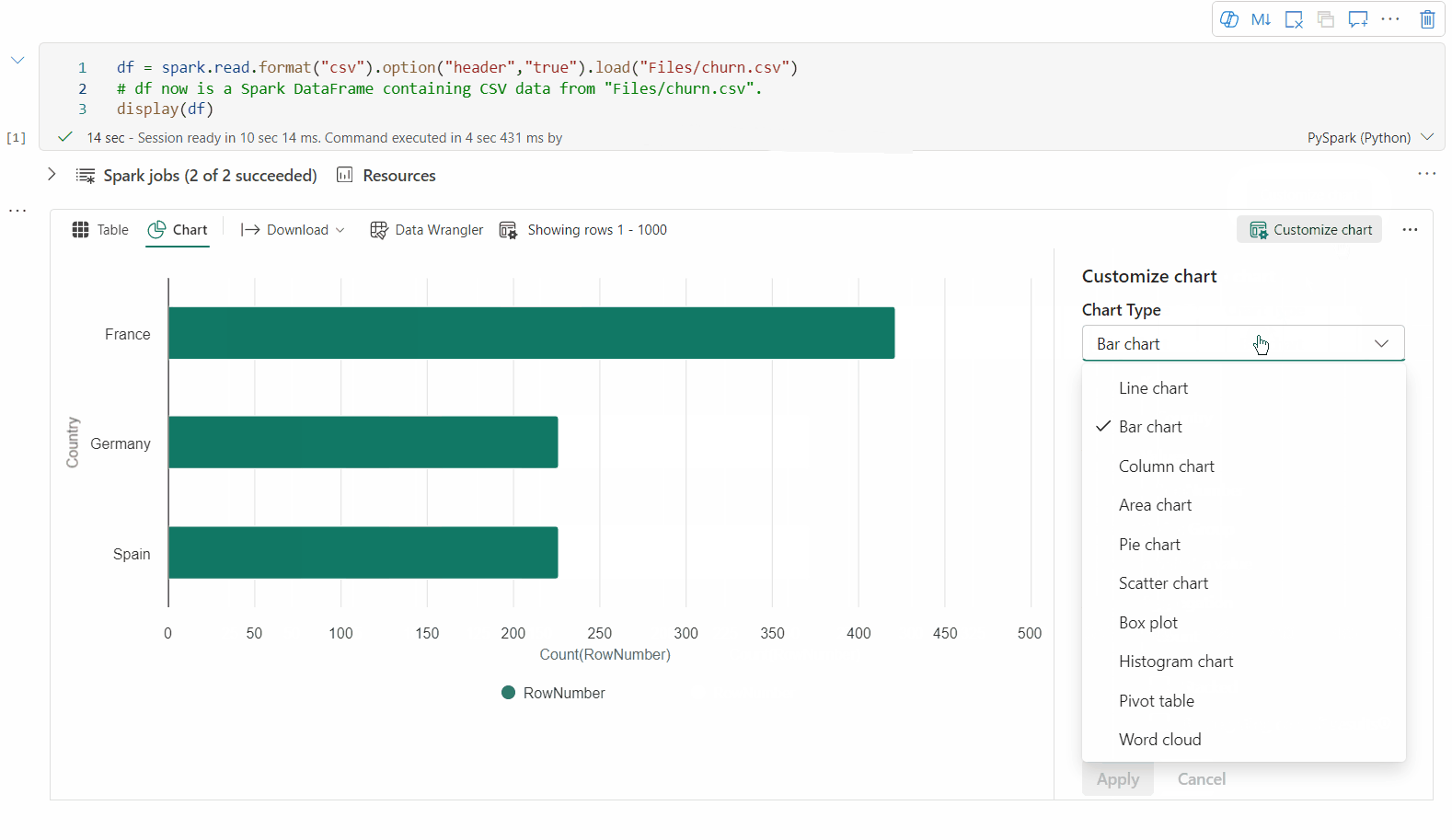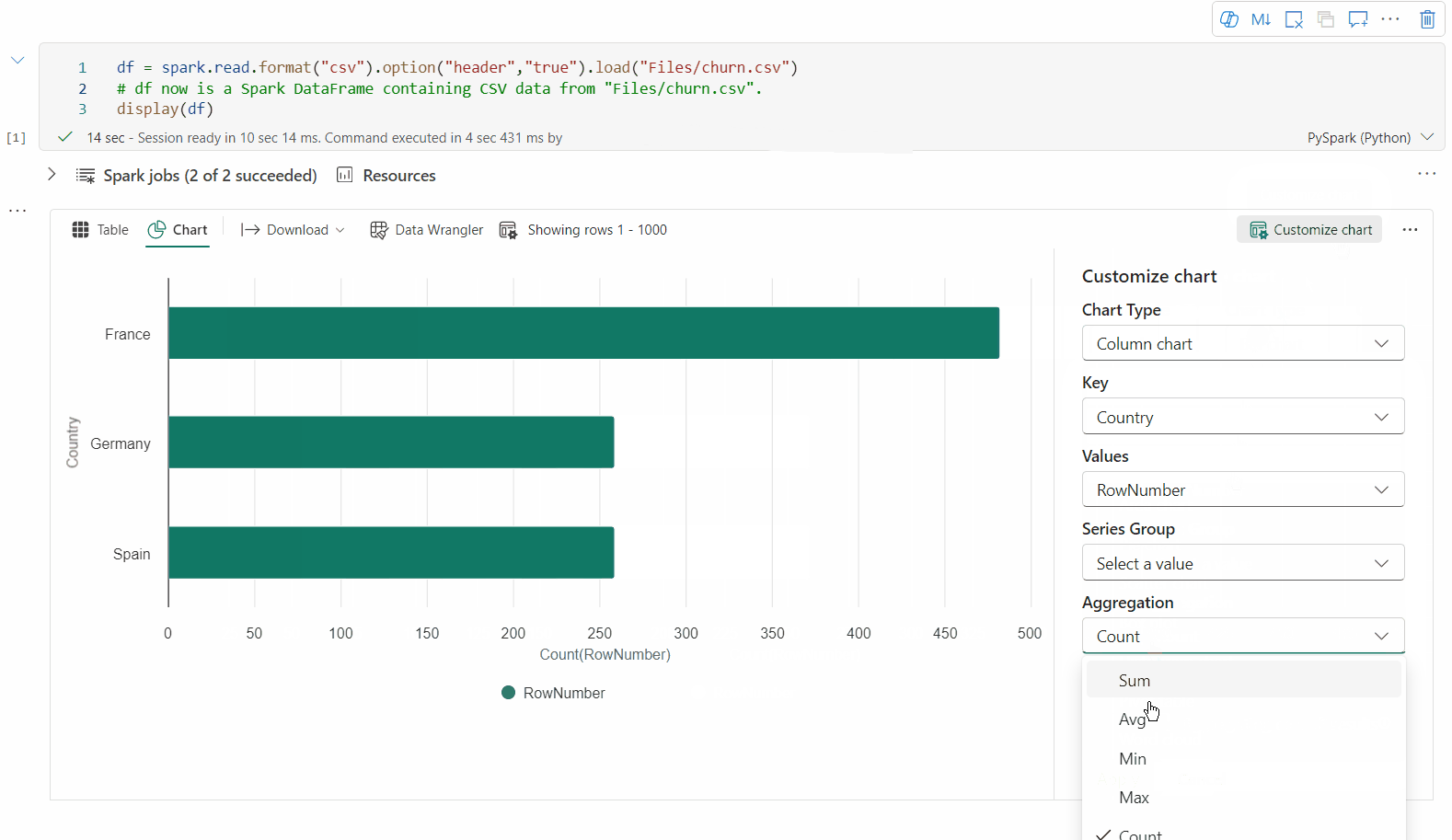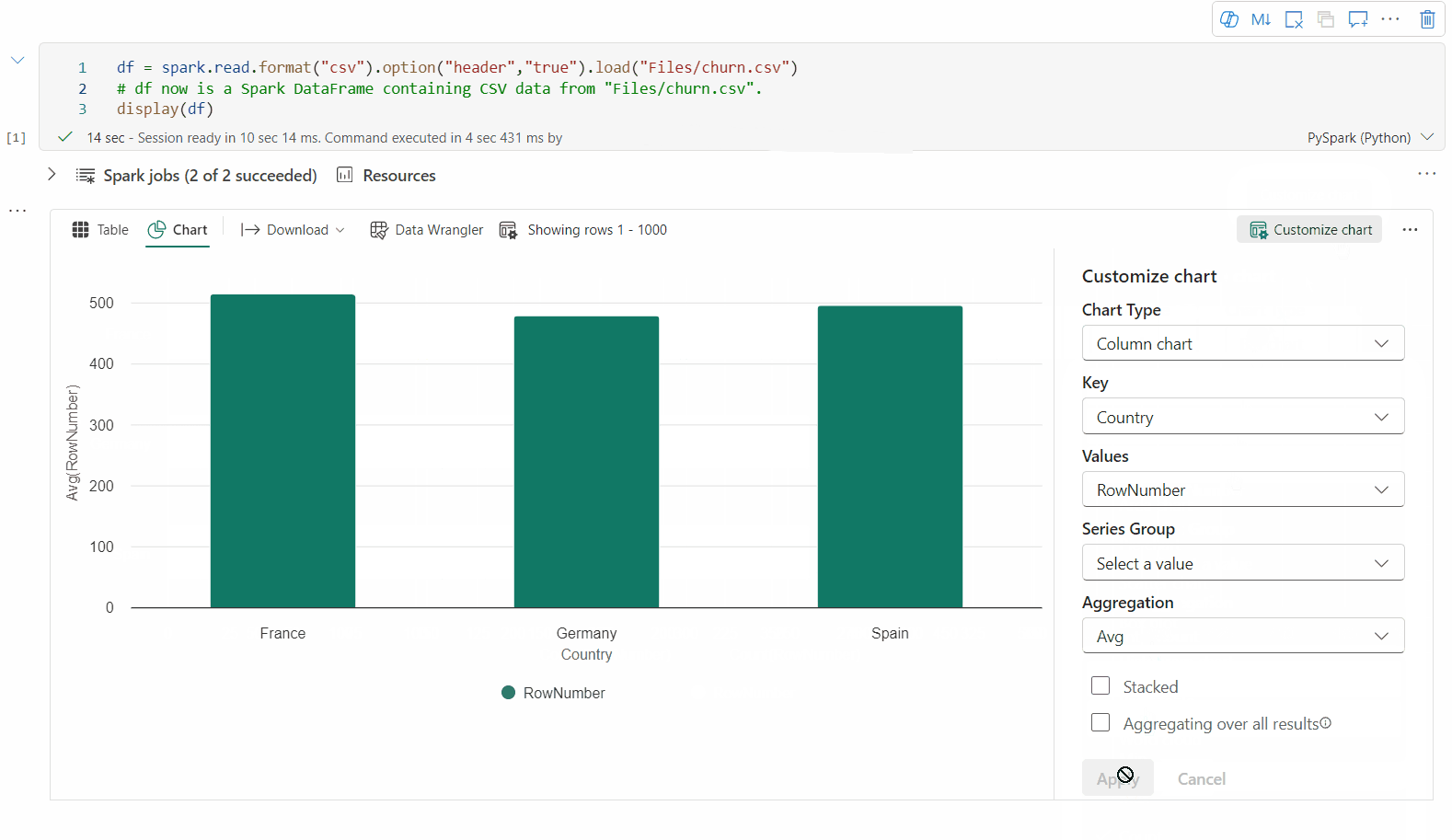
Vous pouvez revenir à la vue graphique héritée en désactivant « Nouvelle visualisation ». La nouvelle expérience est activée par défaut.
Une fois que vous avez une vue de table rendue, passez à la vue Graphique.
Le notebook Fabric recommande automatiquement des graphiques basés sur le DataFrame cible, afin de rendre le graphique significatif avec les insights de données.
Vous pouvez désormais personnaliser votre visualisation en spécifiant les valeurs suivantes :
Configuration Description Type de graphique La fonction d'affichage prend en charge un large éventail de types de graphiques, y compris les graphiques à barres, les nuages de points, les graphiques linéaires, etc. Clé Spécifiez la plage de valeurs pour l'axe des x. Valeur Spécifiez la plage de valeurs pour les valeurs de l'axe y. Groupe de séries Utilisez cette configuration afin de déterminer les groupes pour l’agrégation. Agrégation Utilisez cette méthode pour agréger les données dans votre visualisation. Les configurations sont enregistrées automatiquement dans le contenu de sortie du notebook.
Remarque
Par défaut, la fonction display(df)
prend uniquement les 1 000 premières lignes des données pour afficher les graphiques. Sélectionnez Agrégation sur tous les résultats, puis sélectionnez Appliquer pour appliquer la génération de graphique à partir du DataFrame entier. Un travail Spark est déclenché lorsque le paramètre de graphique change. La fin du calcul et le rendu du graphique peuvent prendre plusieurs minutes. Lorsque le travail est terminé, vous pouvez afficher et interagir avec votre visualisation finale.

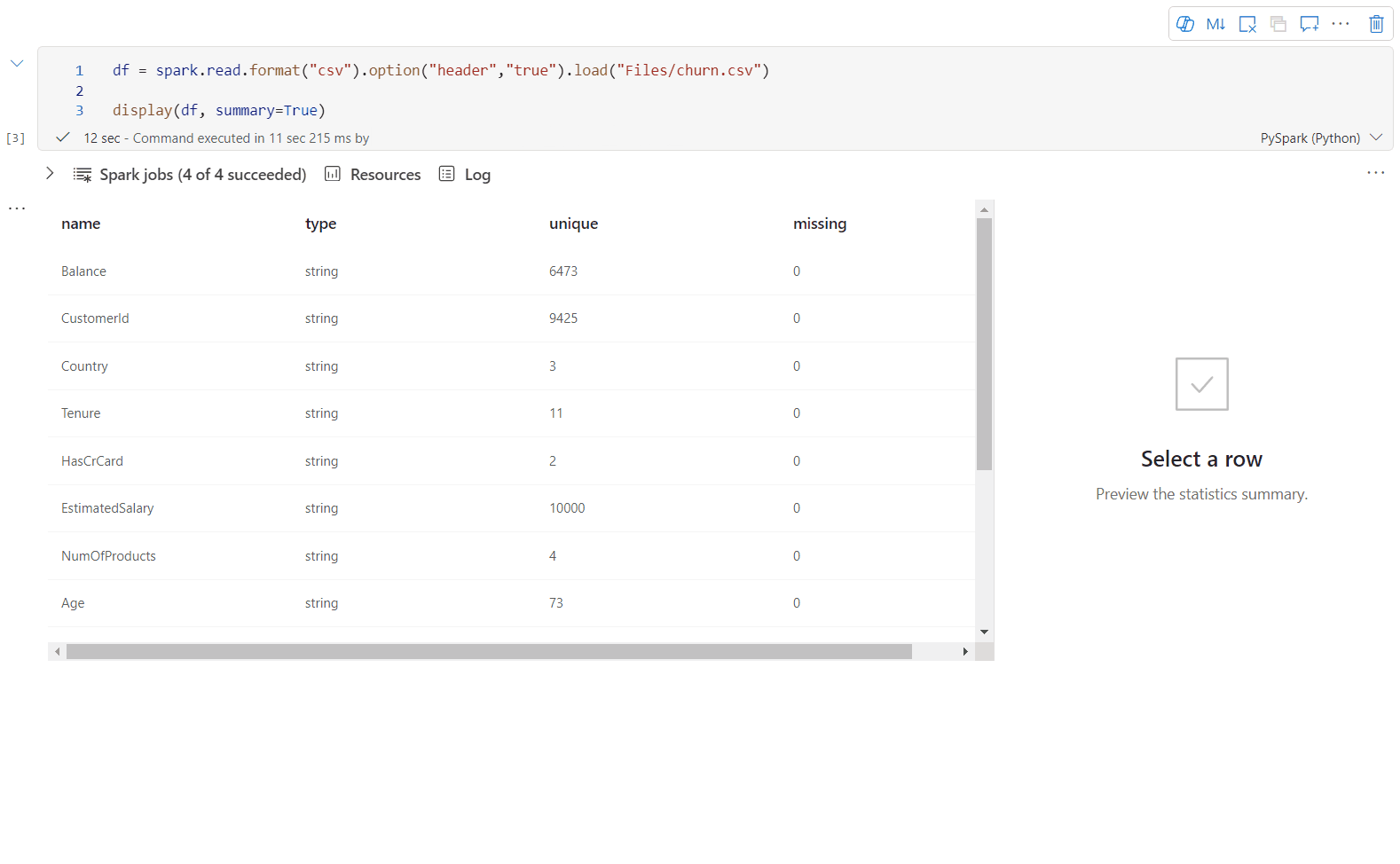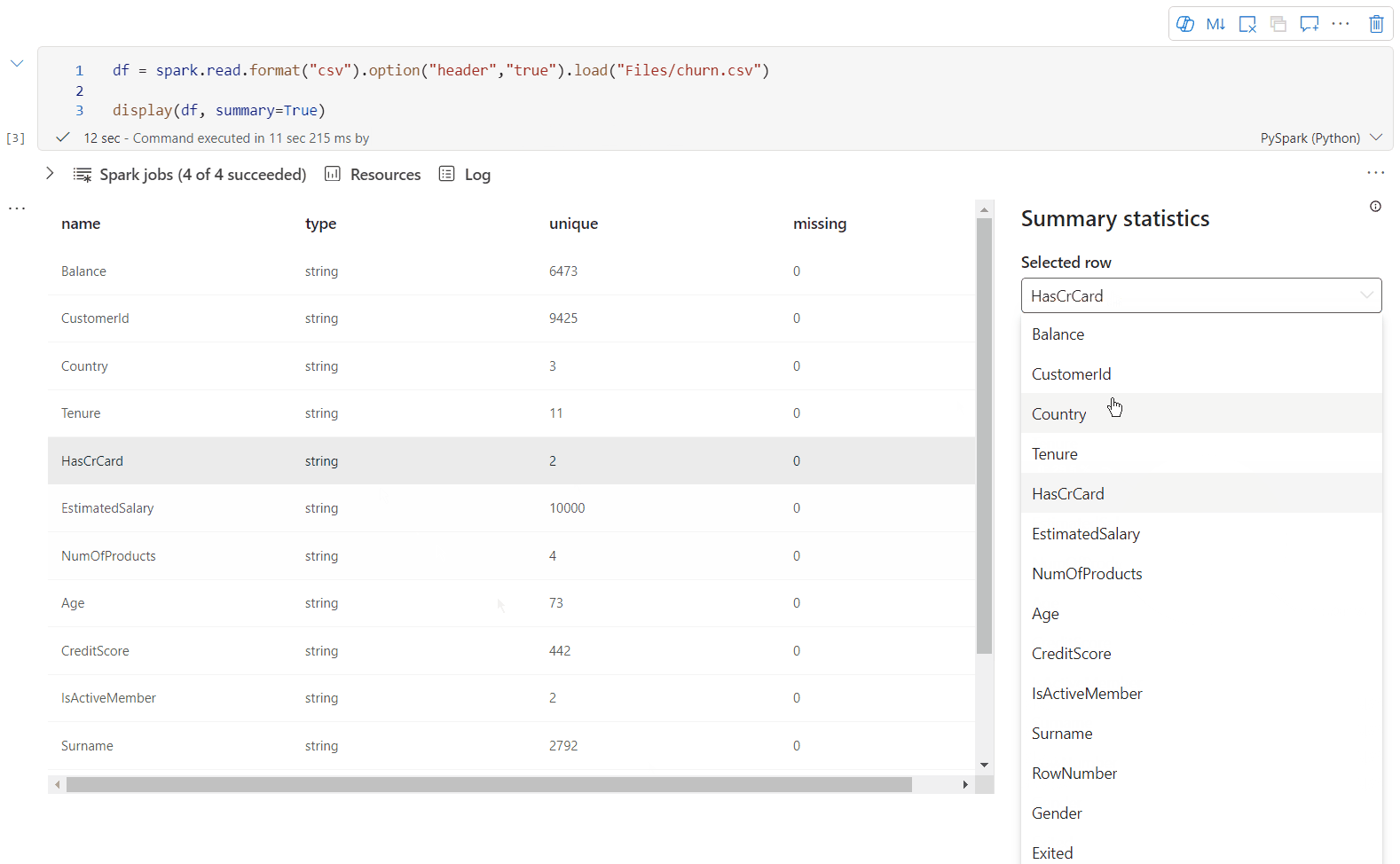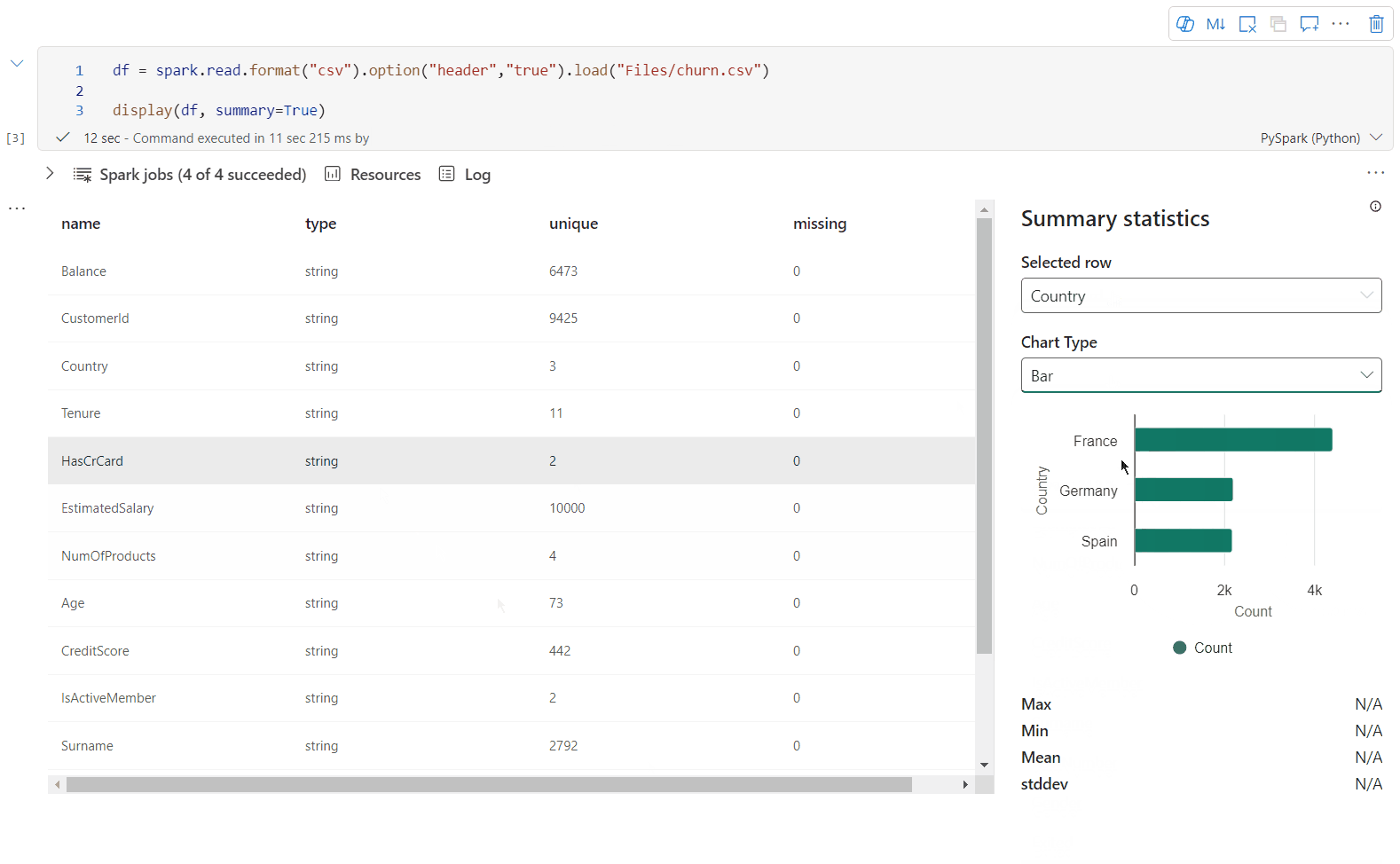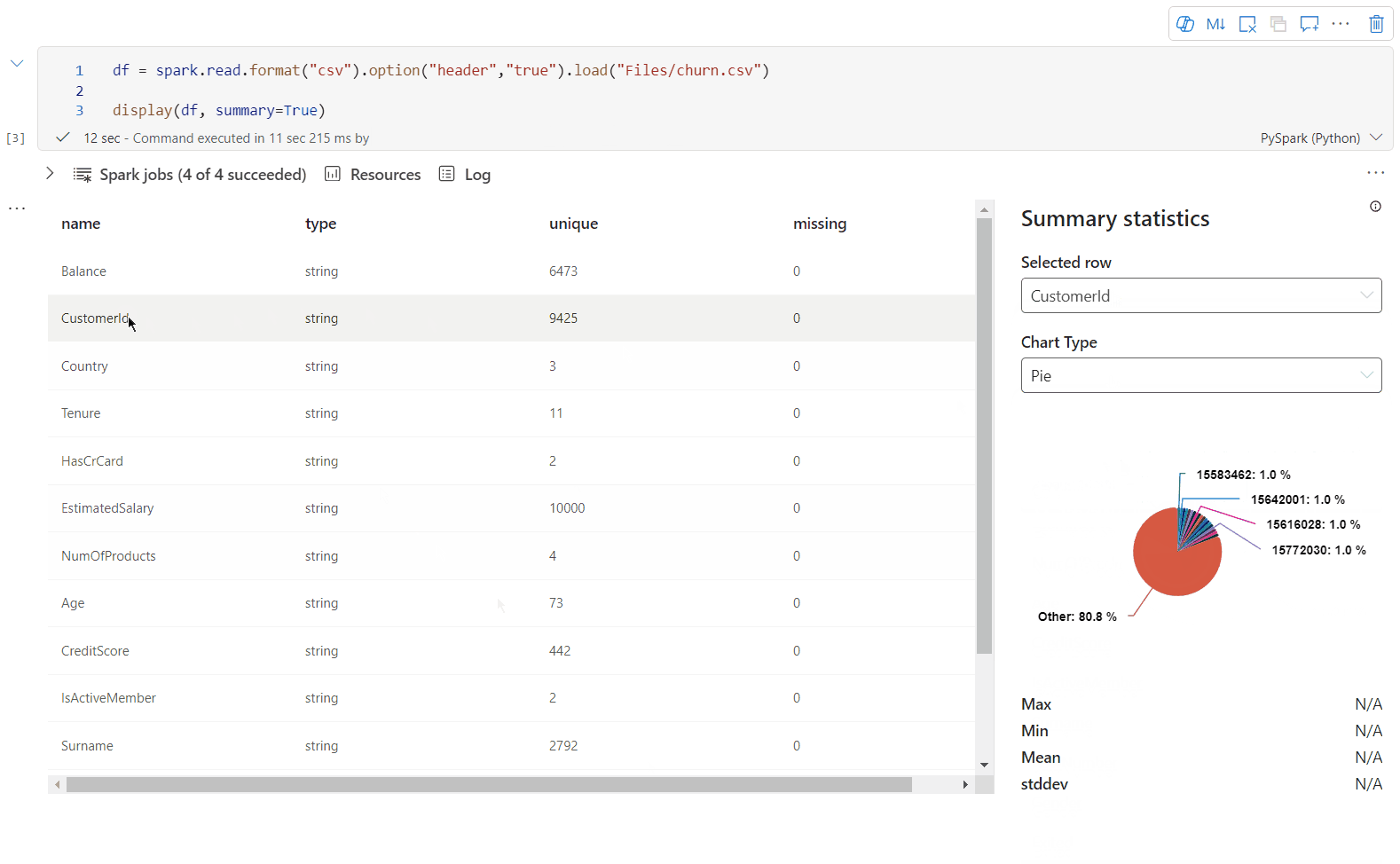
Vue de synthèse display()
Utilisez display(df, summary = true) pour consulter la synthèse des statistiques d’un DataFrame Apache Spark donné. La synthèse comprend le nom de colonne, le type de colonne, les valeurs uniques et les valeurs manquantes pour chaque colonne. Vous pouvez également sélectionner une colonne spécifique pour voir sa valeur minimale, sa valeur maximale, sa valeur moyenne et son écart type.
displayHTML() option
Les notebooks Fabric prennent en charge les graphiques HTML à l’aide de la fonction displayHTML.
L’image suivante est un exemple de création de visualisations à l’aide de D3.js.

Pour créer cette visualisation, exécutez le code suivant.
displayHTML("""<!DOCTYPE html>
<meta charset="utf-8">
<!-- Load d3.js -->
<script src="https://d3js.org/d3.v4.js"></script>
<!-- Create a div where the graph will take place -->
<div id="my_dataviz"></div>
<script>
// set the dimensions and margins of the graph
var margin = {top: 10, right: 30, bottom: 30, left: 40},
width = 400 - margin.left - margin.right,
height = 400 - margin.top - margin.bottom;
// append the svg object to the body of the page
var svg = d3.select("#my_dataviz")
.append("svg")
.attr("width", width + margin.left + margin.right)
.attr("height", height + margin.top + margin.bottom)
.append("g")
.attr("transform",
"translate(" + margin.left + "," + margin.top + ")");
// Create Data
var data = [12,19,11,13,12,22,13,4,15,16,18,19,20,12,11,9]
// Compute summary statistics used for the box:
var data_sorted = data.sort(d3.ascending)
var q1 = d3.quantile(data_sorted, .25)
var median = d3.quantile(data_sorted, .5)
var q3 = d3.quantile(data_sorted, .75)
var interQuantileRange = q3 - q1
var min = q1 - 1.5 * interQuantileRange
var max = q1 + 1.5 * interQuantileRange
// Show the Y scale
var y = d3.scaleLinear()
.domain([0,24])
.range([height, 0]);
svg.call(d3.axisLeft(y))
// a few features for the box
var center = 200
var width = 100
// Show the main vertical line
svg
.append("line")
.attr("x1", center)
.attr("x2", center)
.attr("y1", y(min) )
.attr("y2", y(max) )
.attr("stroke", "black")
// Show the box
svg
.append("rect")
.attr("x", center - width/2)
.attr("y", y(q3) )
.attr("height", (y(q1)-y(q3)) )
.attr("width", width )
.attr("stroke", "black")
.style("fill", "#69b3a2")
// show median, min and max horizontal lines
svg
.selectAll("toto")
.data([min, median, max])
.enter()
.append("line")
.attr("x1", center-width/2)
.attr("x2", center+width/2)
.attr("y1", function(d){ return(y(d))} )
.attr("y2", function(d){ return(y(d))} )
.attr("stroke", "black")
</script>
"""
)
Incorporer un rapport Power BI dans un notebook
Important
Cette fonctionnalité est actuellement en PRÉVERSION. Ces informations concernent une version préliminaire d’un produit susceptible d’être sensiblement modifié avant d’atteindre la disponibilité générale. Microsoft ne donne aucune garantie, expresse ou implicite, concernant les informations fournies ici.
Le package Powerbiclient Python est maintenant pris en charge en mode natif dans les notebooks Fabric. Vous n’avez pas besoin d’effectuer de configuration supplémentaire (comme le processus d’authentification) sur les notebooks Fabric du runtime Spark 3.4. Importez simplement powerbiclient, puis poursuivez votre exploration. Pour en savoir plus sur l’utilisation du package powerbiclient, consultez la documentation powerbiclient.
Powerbiclient prend en charge les fonctionnalités clés suivantes.
Rendre un rapport Power BI existant
Vous pouvez facilement incorporer et interagir avec des rapports Power BI dans vos notebooks avec seulement quelques lignes de code.
L’image suivante est un exemple de rendu d’un rapport Power BI existant.

Exécutez le code suivant pour rendre un rapport Power BI existant.
from powerbiclient import Report
report_id="Your report id"
report = Report(group_id=None, report_id=report_id)
report
Créer des visuels de rapport à partir d’un DataFrame Spark
Vous pouvez utiliser un DataFrame Spark dans votre notebook pour générer rapidement des visualisations perspicaces. Vous pouvez également sélectionner Enregistrer dans le rapport incorporé pour créer un élément de rapport dans un espace de travail cible.
L’image suivante est un exemple de QuickVisualize() d’un DataFrame Spark.

Exécutez le code suivant pour rendre un rapport à partir d’un DataFrame Spark.
# Create a spark dataframe from a Lakehouse parquet table
sdf = spark.sql("SELECT * FROM testlakehouse.table LIMIT 1000")
# Create a Power BI report object from spark data frame
from powerbiclient import QuickVisualize, get_dataset_config
PBI_visualize = QuickVisualize(get_dataset_config(sdf))
# Render new report
PBI_visualize
Créer des visuels de rapport à partir d’un DataFrame pandas
Vous pouvez également créer des rapports basés sur un DataFrame pandas dans un notebook.
L’image suivante est un exemple de QuickVisualize() à partir d’un DataFrame pandas.

Exécutez le code suivant pour rendre un rapport à partir d’un DataFrame Spark.
import pandas as pd
# Create a pandas dataframe from a URL
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv")
# Create a pandas dataframe from a Lakehouse csv file
from powerbiclient import QuickVisualize, get_dataset_config
# Create a Power BI report object from your data
PBI_visualize = QuickVisualize(get_dataset_config(df))
# Render new report
PBI_visualize
Bibliothèques populaires
Lorsqu’il s’agit de la visualisation des données, Python propose plusieurs bibliothèques de graphisme qui sont dotées de nombreuses fonctionnalités différentes. Par défaut, chaque pool Apache Spark dans Fabric contient un ensemble de bibliothèques open source organisées et connues.
Matplotlib
Vous pouvez restituer des bibliothèques de traçage standard, comme Matplotlib, en utilisant les fonctions de rendu intégrées pour chaque bibliothèque.
L’image suivante est un exemple de création d’un graphique à barres à l’aide de Matplotlib.


Exécutez l'exemple de code suivant pour dessiner ce graphique à barres.
# Bar chart
import matplotlib.pyplot as plt
x1 = [1, 3, 4, 5, 6, 7, 9]
y1 = [4, 7, 2, 4, 7, 8, 3]
x2 = [2, 4, 6, 8, 10]
y2 = [5, 6, 2, 6, 2]
plt.bar(x1, y1, label="Blue Bar", color='b')
plt.bar(x2, y2, label="Green Bar", color='g')
plt.plot()
plt.xlabel("bar number")
plt.ylabel("bar height")
plt.title("Bar Chart Example")
plt.legend()
plt.show()
Bokeh
Vous pouvez afficher des bibliothèques HTML ou interactives, comme bokeh, en utilisant le displayHTML(df).
L’image suivante est un exemple de traçage de glyphes sur une carte en utilisant bokeh.

Pour dessiner cette image, exécutez l’exemple de code suivant.
from bokeh.plotting import figure, output_file
from bokeh.tile_providers import get_provider, Vendors
from bokeh.embed import file_html
from bokeh.resources import CDN
from bokeh.models import ColumnDataSource
tile_provider = get_provider(Vendors.CARTODBPOSITRON)
# range bounds supplied in web mercator coordinates
p = figure(x_range=(-9000000,-8000000), y_range=(4000000,5000000),
x_axis_type="mercator", y_axis_type="mercator")
p.add_tile(tile_provider)
# plot datapoints on the map
source = ColumnDataSource(
data=dict(x=[ -8800000, -8500000 , -8800000],
y=[4200000, 4500000, 4900000])
)
p.circle(x="x", y="y", size=15, fill_color="blue", fill_alpha=0.8, source=source)
# create an html document that embeds the Bokeh plot
html = file_html(p, CDN, "my plot1")
# display this html
displayHTML(html)
Plotly
Vous pouvez afficher des bibliothèques HTML ou interactives, comme Plotly, en utilisant la commande displayHTML() .
Pour dessiner cette image, exécutez l’exemple de code suivant.

from urllib.request import urlopen
import json
with urlopen('https://raw.githubusercontent.com/plotly/datasets/master/geojson-counties-fips.json') as response:
counties = json.load(response)
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv",
dtype={"fips": str})
import plotly
import plotly.express as px
fig = px.choropleth(df, geojson=counties, locations='fips', color='unemp',
color_continuous_scale="Viridis",
range_color=(0, 12),
scope="usa",
labels={'unemp':'unemployment rate'}
)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
# create an html document that embeds the Plotly plot
h = plotly.offline.plot(fig, output_type='div')
# display this html
displayHTML(h)
Pandas
Vous pouvez afficher la sortie HTML de DataFrames pandas comme sortie par défaut. Les notebooks Fabric affichent automatiquement le contenu HTML stylisé.

import pandas as pd
import numpy as np
df = pd.DataFrame([[38.0, 2.0, 18.0, 22.0, 21, np.nan],[19, 439, 6, 452, 226,232]],
index=pd.Index(['Tumour (Positive)', 'Non-Tumour (Negative)'], name='Actual Label:'),
columns=pd.MultiIndex.from_product([['Decision Tree', 'Regression', 'Random'],['Tumour', 'Non-Tumour']], names=['Model:', 'Predicted:']))
df