Prise en charge de T-SQL dans les notebooks Microsoft Fabric
La fonctionnalité de notebook T-SQL dans Microsoft Fabric vous permet d’écrire et d’exécuter du code T-SQL dans un notebook. Vous pouvez utiliser des notebooks T-SQL pour gérer des requêtes complexes et écrire une meilleure documentation Markdown. Elle permet aussi l’exécution directe de T-SQL sur un point de terminaison d’entrepôt ou d’analytique SQL connecté. En ajoutant un point de terminaison d’entrepôt de données ou d’analytique SQL à un notebook, les développeurs T-SQL peuvent exécuter des requêtes directement sur le point de terminaison connecté. Les analystes BI peuvent également effectuer des requêtes portant sur plusieurs bases de données pour collecter des insights auprès de plusieurs entrepôts et points de terminaison d’analytique SQL.
La plupart des fonctionnalités existantes des notebooks sont disponibles pour les notebooks T-SQL. Il s’agit notamment de la conversion en graphiques des résultats des requêtes, de la co-création de notebooks, de la planification d’exécutions régulières et du déclenchement d’une exécution dans des pipelines d’intégration de données.
Important
Cette fonctionnalité est en version préliminaire.
Dans cet article, vous apprendrez comment :
- Créer un notebook T-SQL
- Ajouter un point de terminaison d’entrepôt de données ou d’analytique SQL à un notebook
- Créer et exécuter du code T-SQL dans un notebook
- Utiliser les fonctionnalités des graphiques pour représenter graphiquement les résultats des requêtes
- Enregistrer la requête en tant que vue ou en tant que table
- Exécuter des requêtes portant sur plusieurs entrepôts
- Ignorer l’exécution du code non-T-SQL
Créer un notebook T-SQL
Pour commencer à utiliser cette expérience, vous pouvez créer un notebook T-SQL de la manière suivante :
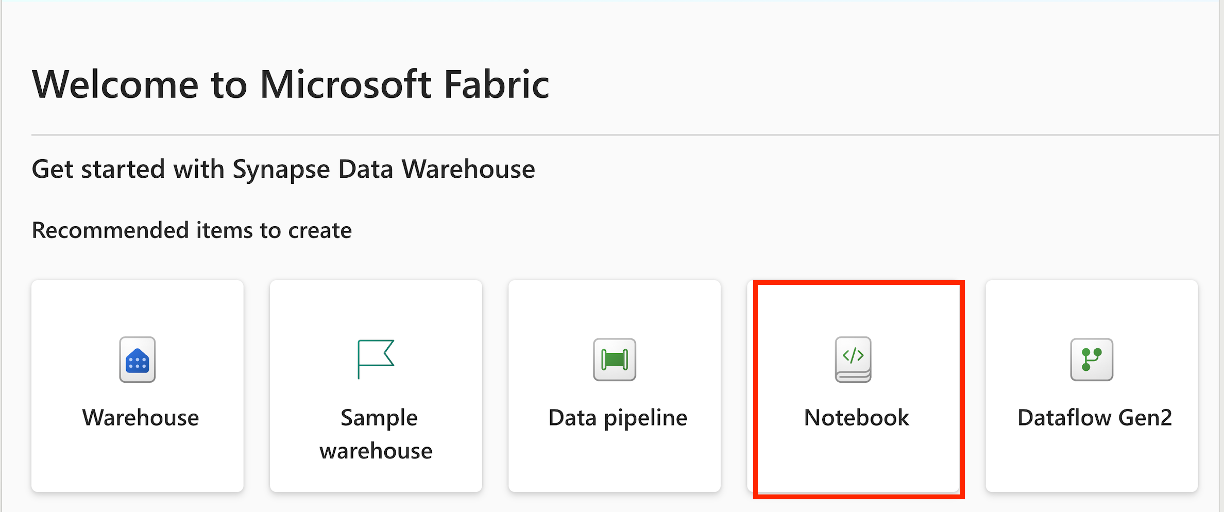
Créez un bloc-notes T-SQL à partir de l’espace de travail Fabric : sélectionnez Nouvel élément, puis choisissez notebook dans le volet qui s’ouvre.
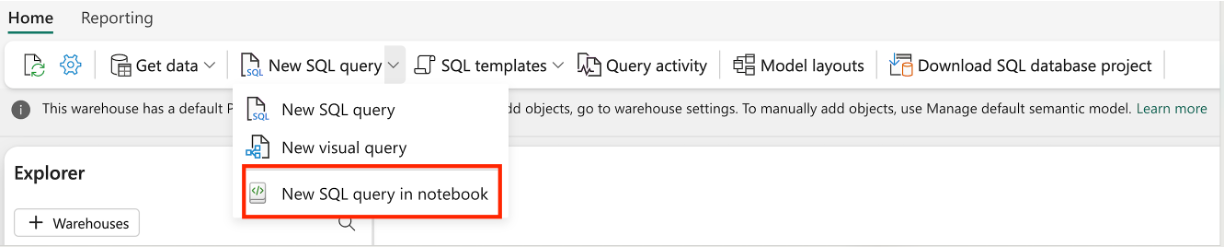
Créez un notebook T-SQL à partir d’un éditeur d’entrepôt existant : accédez à un entrepôt existant et, dans le ruban de navigation supérieur, sélectionnez nouvelle requête SQL, puis nouveau notebook de requête T-SQL.
Une fois le notebook créé, T-SQL est défini comme langage par défaut. Vous pouvez ajouter des points de terminaison d’entrepôt de données ou d’analytique SQL depuis l’espace de travail actuel dans votre notebook.
Ajouter un point de terminaison d’entrepôt de données ou d’analytique SQL à un notebook
Pour ajouter un point de terminaison d’entrepôt de données ou d’analytique SQL dans un notebook, dans l’éditeur de notebook, sélectionnez le bouton + Sources de données, puis sélectionnez Entrepôts de données. Dans le panneau Hub de données, sélectionnez le point de terminaison d’entrepôt de données ou d’analytique SQL auquel vous souhaitez vous connecter.

Définir un entrepôt principal
Vous pouvez ajouter plusieurs entrepôts ou points de terminaison d’analytique SQL dans le notebook, l’un d’eux étant défini comme principal. L’entrepôt principal exécute le code T-SQL. Pour le définir, accédez à l’Explorateur d’objets, sélectionnez ... en regard de l’entrepôt, puis choisissez Définir comme principal.
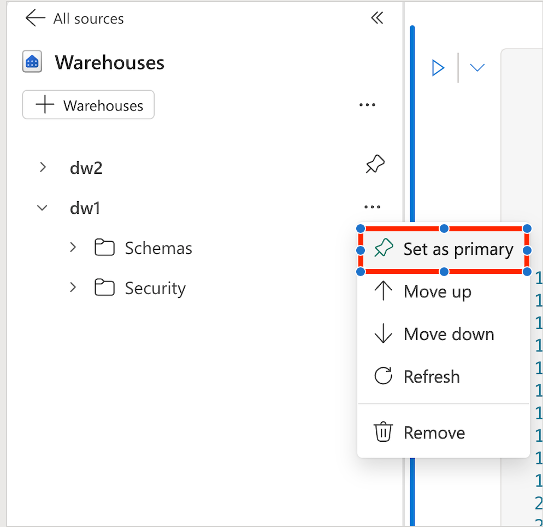
Pour les commandes T-SQL qui prennent en charge le nommage en trois parties, l’entrepôt principal est utilisé comme entrepôt par défaut si aucun entrepôt n’est spécifié.
Créer et exécuter du code T-SQL dans un notebook
Pour créer et exécuter du code T-SQL dans un notebook, ajoutez une nouvelle cellule et définissez T-SQL comme langage de la cellule.

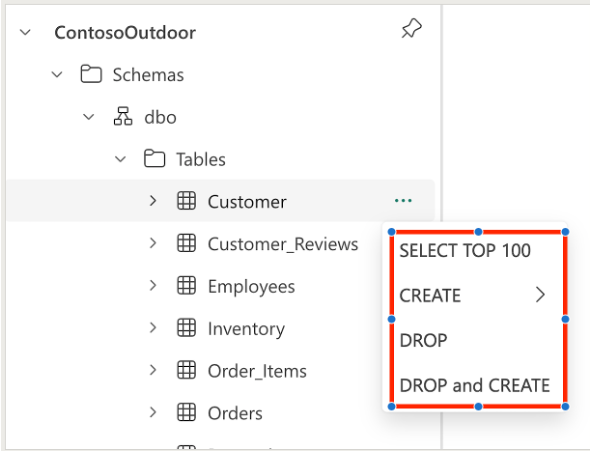
Vous pouvez générer automatiquement du code T-SQL en utilisant le modèle de code à partir du menu contextuel de l’Explorateur d’objets. Les modèles suivants sont disponibles pour les notebooks T-SQL :
- Sélectionner les 100 premiers
- Créer une table
- Créer en tant que sélection
- Supprimer
- Déposer et créer
Vous pouvez exécuter une cellule de code T-SQL en sélectionnant le bouton Exécuter dans la barre d’outils de la cellule ou exécuter toutes les cellules en sélectionnant le bouton Exécuter tout dans la barre d’outils.
Remarque
Chaque cellule de code est exécutée dans une session distincte, de sorte que les variables définies dans une cellule ne sont pas disponibles dans une autre cellule.
Dans une même cellule de code, il peut y avoir plusieurs lignes de code. L’utilisateur peut sélectionner une partie de ce code et exécuter seulement les éléments sélectionnés. Chaque exécution génère également une nouvelle session.
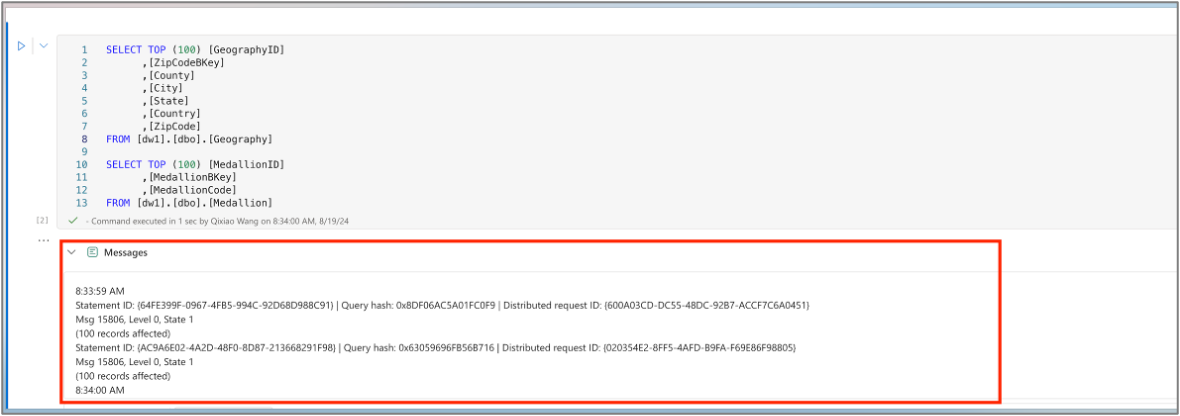
Une fois le code exécuté, développez le panneau des messages pour vérifier le résumé de l’exécution.
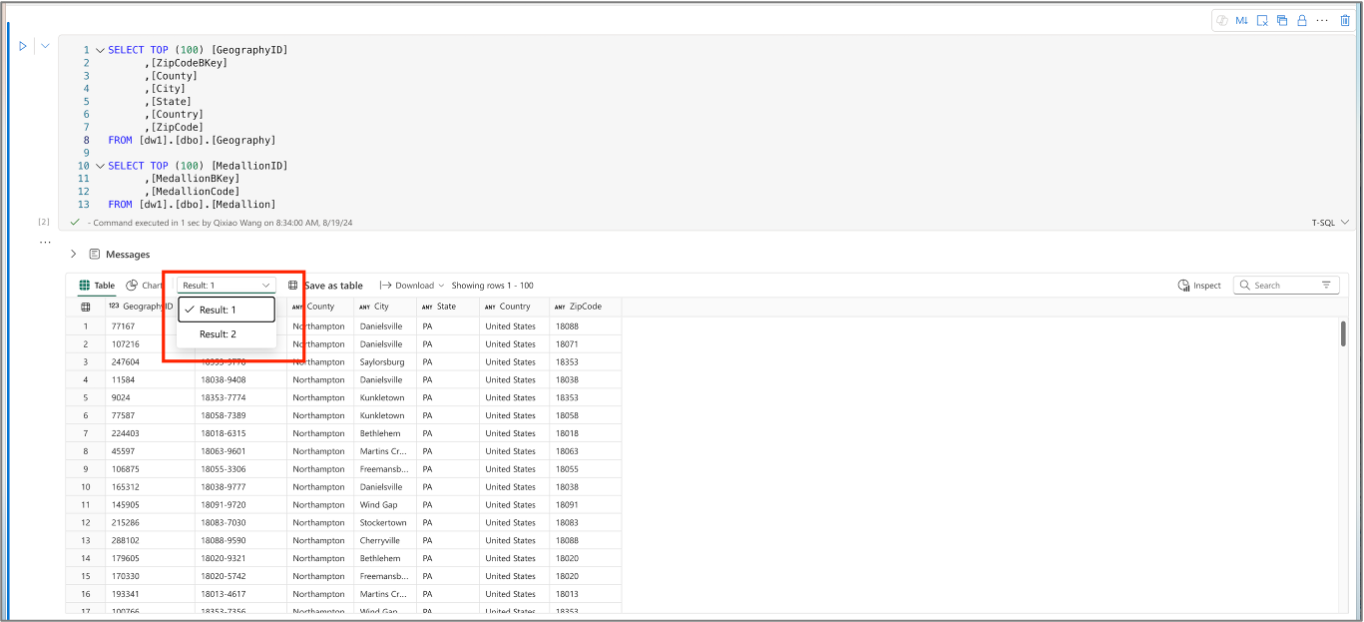
L’onglet Table liste les enregistrements du jeu de résultats retourné. Si l’exécution contient plusieurs jeux de résultats, vous pouvez passer de l’un à l’autre via le menu déroulant.
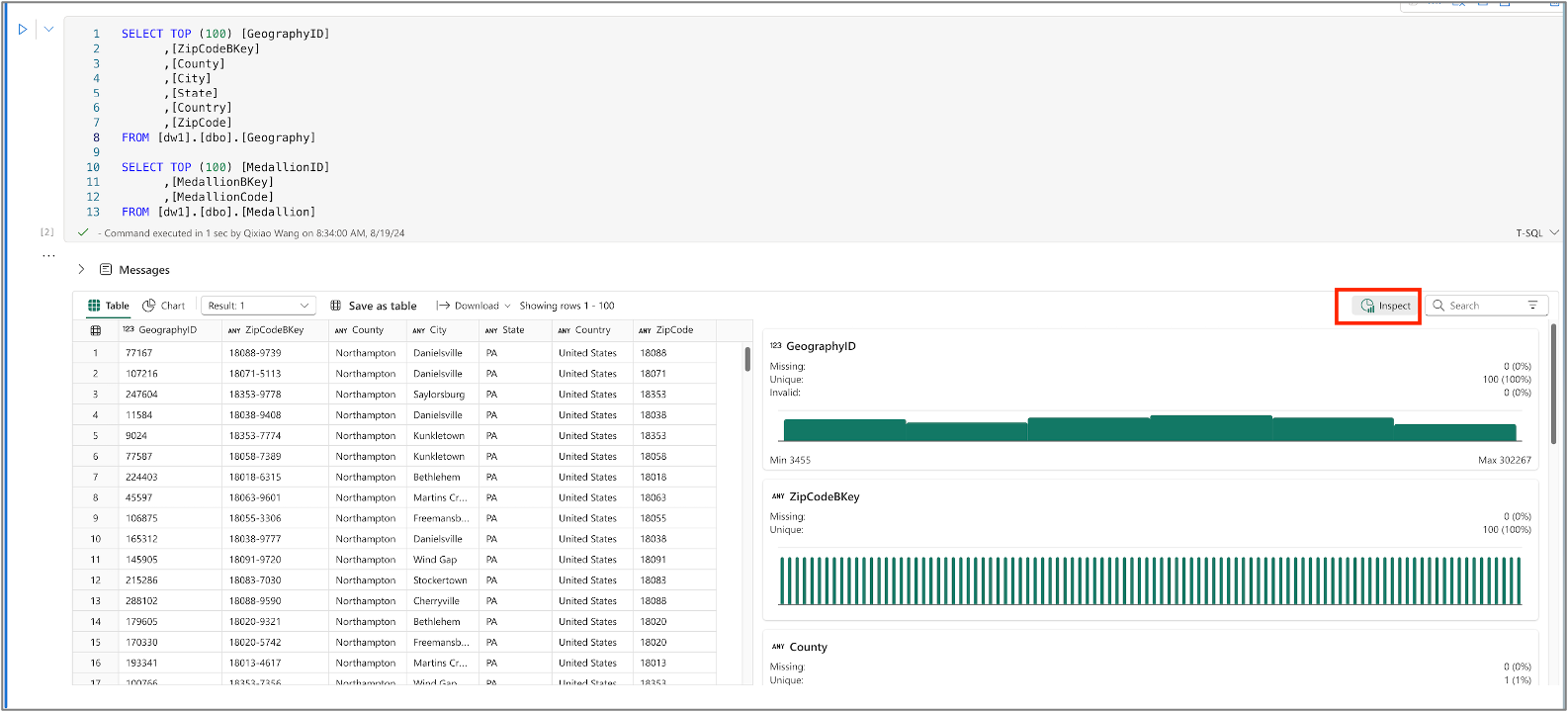
Utiliser les fonctionnalités des graphiques pour représenter graphiquement les résultats des requêtes
En cliquant sur Inspecter, vous pouvez voir les graphiques qui représentent la qualité et la distribution des données de chaque colonne.
Enregistrer la requête en tant que vue ou en tant que table
Vous pouvez utiliser le menu Enregistrer en tant que table pour enregistrer les résultats de la requête dans la table en utilisant la commande CTAS. Pour utiliser ce menu, sélectionnez le texte de la requête dans la cellule de code, puis sélectionnez le menu Enregistrer en tant que table.
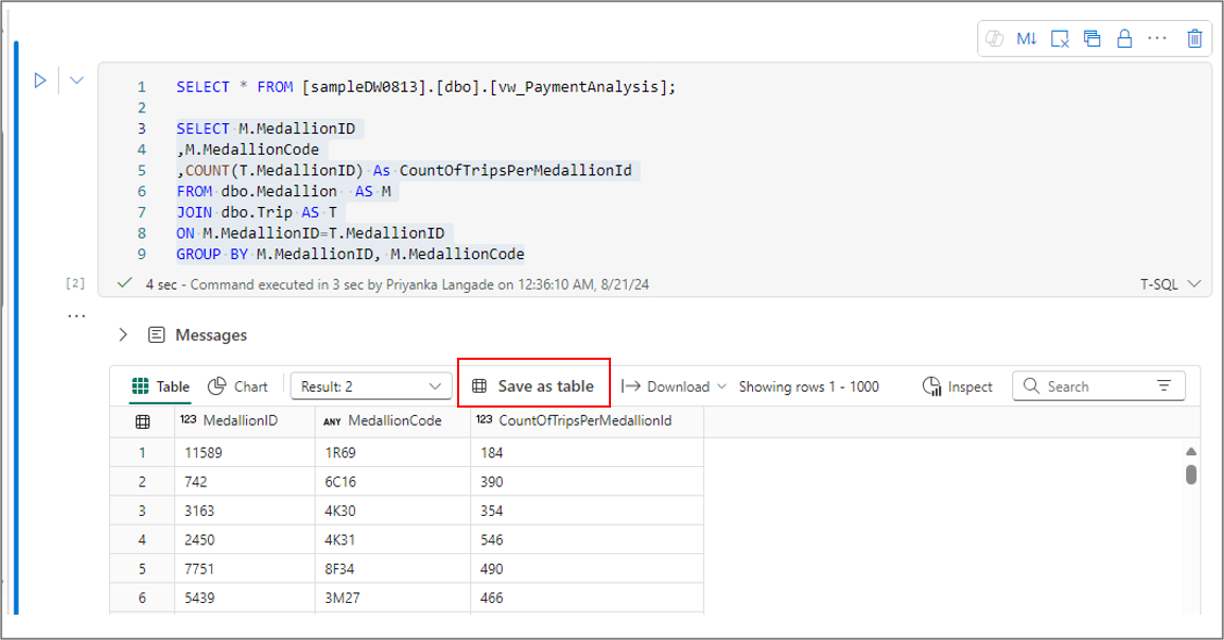
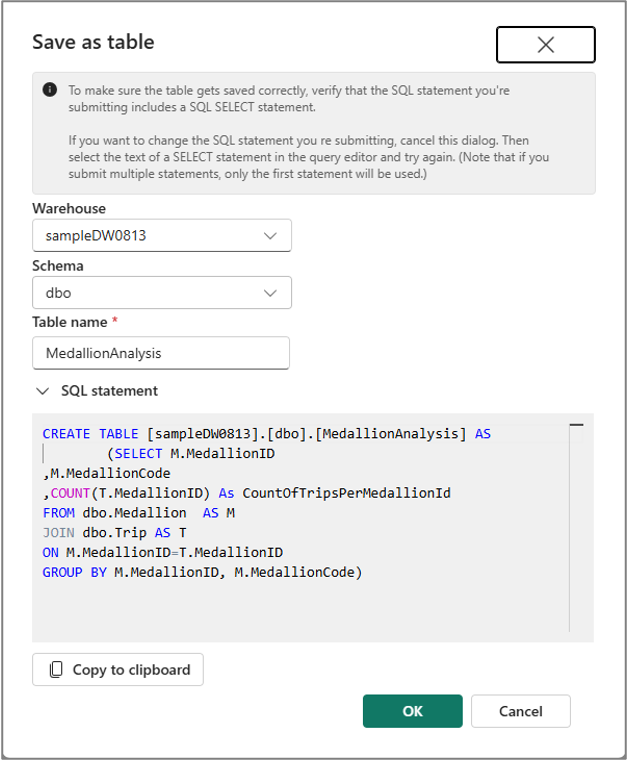
De même, vous pouvez créer une vue à partir du texte de votre requête sélectionné en utilisant le menu Enregistrer en tant que vue dans la barre de commandes de la cellule.
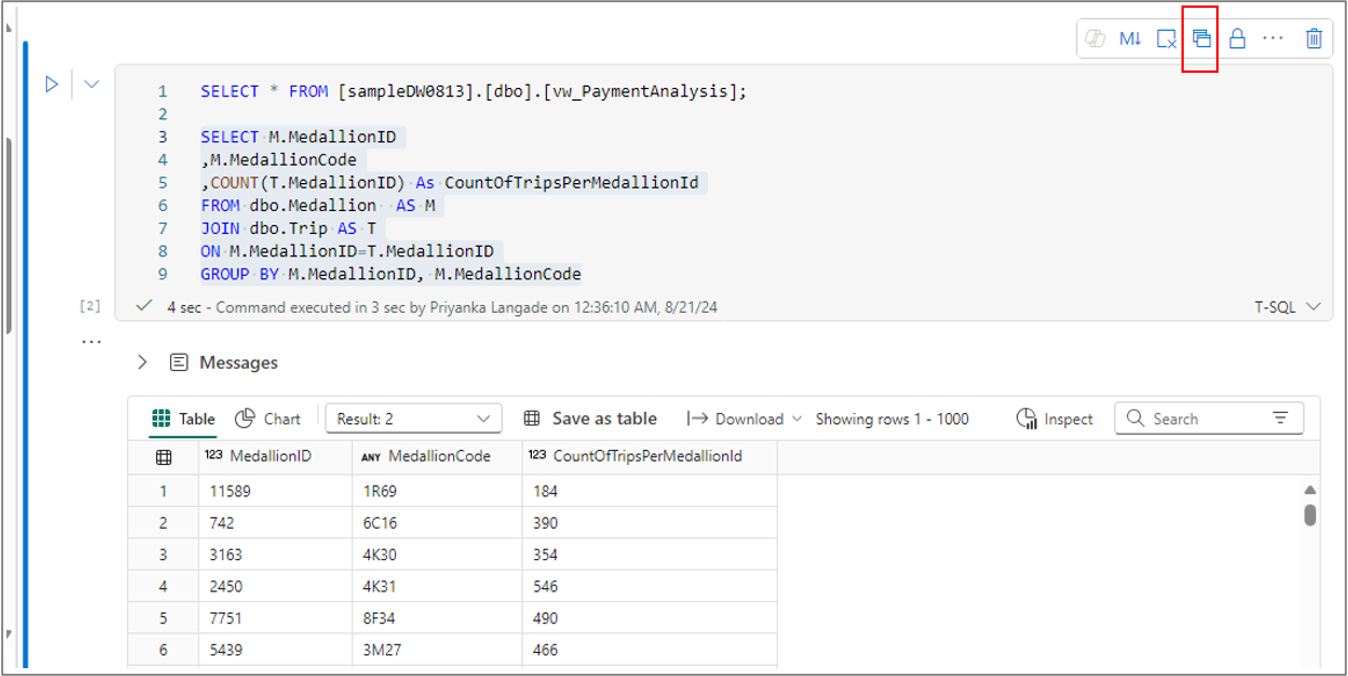
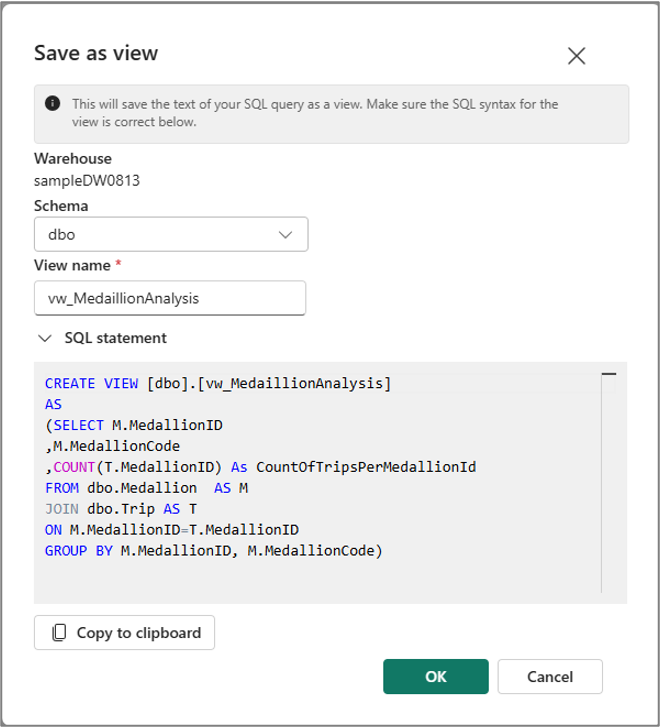
Remarque
Comme les menus Enregistrer en tant que table et Enregistrer en tant que vue sont disponibles seulement pour le texte de requête sélectionné, vous devez sélectionner le texte de la requête avant d’utiliser ces menus.
La fonctionnalité Créer une vue ne prend pas en charge le nommage en trois parties : la vue est donc toujours créée dans l’entrepôt principal en définissant l’entrepôt comme entrepôt principal.
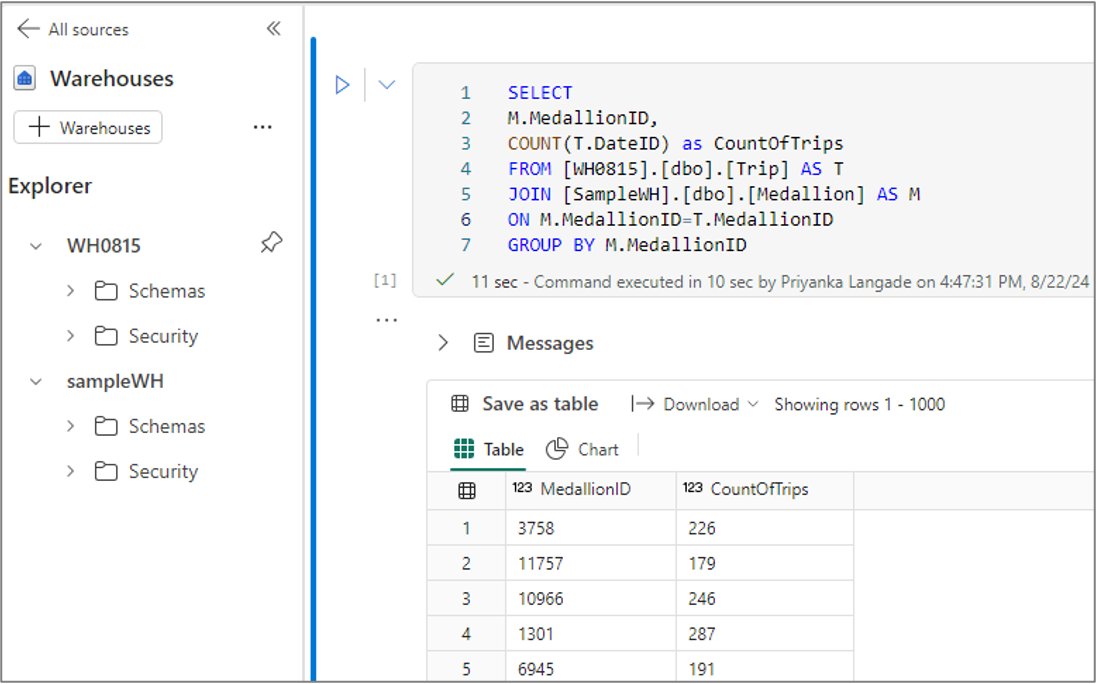
Requête portant sur plusieurs entrepôts
Vous pouvez exécuter une requête portant sur plusieurs entrepôts en utilisant un nommage en trois parties. Le nommage en trois parties est constitué du nom de base de données, du nom de schéma et du nom de table. Le nom de base de données est le nom du point de terminaison d’entrepôt ou d’analytique SQL, le nom de schéma est le nom du schéma et le nom de table est le nom de la table.
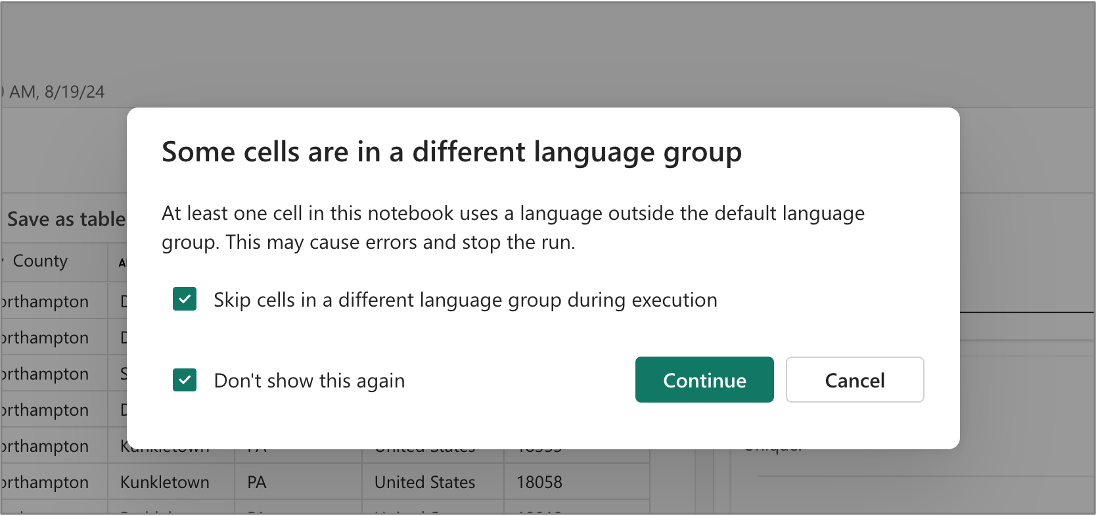
Ignorer l’exécution du code non-T-SQL
Dans le même notebooks, il est possible de créer des cellules de code qui utilisent des langages différents. Par exemple, une cellule de code PySpark peut précéder une cellule de code T-SQL. Dans ce cas, l’utilisateur peut choisir d’ignorer l’exécution du code PySpark pour le notebook T-SQL. Cette boîte de dialogue s’affiche quand vous exécutez toutes les cellules de code en cliquant sur le bouton Exécuter tout dans la barre d’outils.
Limitations de la version préliminaire publique
- Les cellules de paramètre ne sont pas encore prises en charge dans les notebooks T-SQL. Le paramètre passé depuis le pipeline ou le planificateur ne peut pas être utilisé dans un notebook T-SQL.
- La fonctionnalité Exécution récente n’est pas encore prise en charge dans les notebooks T-SQL. Vous devez utiliser la fonctionnalité actuelle de surveillance d’entrepôt de données pour vérifier l’historique des exécutions du notebook T-SQL. Pour plus d’informations, consultez l’article Surveiller Data Warehouse.
- L’URL de surveillance dans l’exécution des pipelines n’est pas encore prise en charge dans les notebooks T-SQL.
- La fonctionnalité d’instantané n’est pas encore prise en charge dans les notebooks T-SQL.
- Git et le déploiement de pipeline ne sont pas encore pris en charge dans les notebooks T-SQL.
Contenu connexe
Pour obtenir plus d’informations sur les notebooks Fabric, consultez les articles suivants.
- Qu’est-ce que l’entreposage de données dans Microsoft Fabric ?
- Des questions ? Essayez de demander à la Communauté Fabric.
- Vous avez des suggestions ? Contribuez des idées pour améliorer Fabric.