Utiliser le serveur d’historique Apache Spark étendu pour déboguer et diagnostiquer des applications Apache Spark
Cet article vous guide dans l’utilisation du serveur d’historique Apache Spark étendu pour déboguer et diagnostiquer des applications Apache Spark terminées et en cours d’exécution.
Accéder au serveur d’historique Apache Spark
Le serveur d'historique Apache Spark est l'interface utilisateur Web pour les applications Spark terminées et en cours d'exécution. Vous pouvez ouvrir l’interface utilisateur Web (IU) d’Apache Spark à partir du bloc-notes d’indicateur de progression ou de la page de détails de l’application Apache Spark.
Ouvrez l'interface utilisateur Web Spark à partir du bloc-notes d'indicateur de progression
Lorsqu'une tâche Apache Spark est déclenchée, le bouton permettant d'ouvrir l'interface utilisateur Web Spark se trouve dans l'option Plus d'action de l'indicateur de progression. Sélectionnez Spark web UI et attendez quelques secondes, puis la page Spark UI apparaît.

Ouvrez l'interface utilisateur Web Spark à partir de la page de détail de l'application Apache Spark
L'interface utilisateur Web Spark peut également être ouverte via la page de détails de l'application Apache Spark. Sélectionnez Hub de surveillance sur le côté gauche de la page, puis sélectionnez une application Apache Spark. La page de détail de l'application s'affiche.

Pour une application Apache Spark dont l'état est en cours d'exécution, le bouton affiche Spark UI. Sélectionnez Spark UI et la page Spark UI apparaît.

Pour une application Apache Spark dont le statut est terminé, le statut terminé peut être Arrêté, Échec, Annulé ou Terminé. Le bouton affiche le serveur d'historique Spark. Sélectionnez le serveur d'historique Spark et la page de l'interface utilisateur Spark s'affiche.

Onglet Graph dans le serveur d’historique Apache Spark
Sélectionnez l’ID du travail à afficher. Ensuite, sélectionnez Graph dans le menu des outils pour obtenir l’affichage du graphique du travail.
Vue d’ensemble
Vous pouvez voir une vue d’ensemble de votre travail dans le graphique du travail ainsi généré. Par défaut, le graphique affiche tous les travaux. Vous pouvez filtrer cet affichage par ID de travail.

Afficher
Par défaut, l’affichage Progress (Progression) est sélectionné. Vous pouvez vérifier le flux de données en sélectionnant Read (Lues) ou Written (Écrites) dans le menu déroulant Display (Affichage).

Le nœud Graph affiche les couleurs indiquées dans la légende de la carte thermique.

Lecture
Pour lire la tâche, sélectionnez Playback (Lecture). Vous pouvez sélectionner Stop (Arrêter) à tout moment. Les couleurs des travaux affichent différents états lors de la relecture :
| Couleur | Signification |
|---|---|
| Vert | Succeeded : le travail s’est correctement effectué. |
| Orange | Nouvelle tentative : instances de tâches qui ont échoué mais qui n'affectent pas le résultat final de la tâche. Ces tâches comportaient des instances dupliquées ou renouvelées qui peuvent réussir ultérieurement. |
| Bleu | Running : la tâche est en cours d’exécution. |
| White | En attente ou ignoré : la tâche est en attente d’exécution, ou la phase a été ignorée. |
| Rouge | Échoué : la tâche a échoué. |
L'image suivante montre les couleurs d'état vert, orange et bleu.

L'image suivante montre les couleurs d'état vert et blanc.

L'image suivante montre les couleurs d'état rouge et verte.

Remarque
Le serveur d'historique Apache Spark permet la lecture de chaque travail terminé (mais n'autorise pas la lecture des travaux incomplets).
Zoom
Utilisez la molette de la souris pour effectuer un zoom avant/arrière du graphe de travail, ou sélectionnez Zoom to fit (Zoom d’ajustement) pour l’adapter à la taille de l’écran.

Info-bulles
Pointez sur un nœud de graphique pour afficher l’info-bulle en cas d’échec de tâches, puis sélectionnez une phase pour ouvrir la page correspondante.

Sous l’onglet du graphique du travail, une info-bulle et une petite icône s’affichent en regard des phases qui comprennent des tâches qui remplissent les conditions suivantes :
| Condition | Description |
|---|---|
| Asymétrie des données | Taille de lecture des données taille > moyenne de lecture des données de toutes les tâches à l'intérieur de cette étape * 2 et taille de lecture des données > 10 Mo. |
| Asymétrie temporelle | Temps d'exécution > temps d'exécution moyen de toutes les tâches à l'intérieur de cette étape * 2 et temps d'exécution > 2 minutes. |
![]()
Description du nœud de graphique
Le nœud de graphique du travail affiche les informations suivantes de chaque phase :
- Récompenses client
- Nom ou description
- Nombre total de tâches
- Lecture de données : somme de la taille d’entrée et de la taille de lecture aléatoire
- Écriture de données : la somme de la taille de sortie et de la taille des écritures aléatoires
- Durée d’exécution : durée entre l’heure de début de la première tentative et l’heure de fin de la dernière tentative
- Nombre de lignes : la somme des enregistrements d'entrée, des enregistrements de sortie, des enregistrements de lecture aléatoire et des enregistrements d'écriture aléatoire
- Progress
Remarque
Par défaut, le nœud de graphique de travail affiche les informations de la dernière tentative de chaque phase (à l’exception de la durée d’exécution de la phase). Toutefois, en cours de lecture, le nœud de graphique affiche les informations de chaque tentative.
La taille des données de lecture et d'écriture est de 1 Mo = 1000 Ko = 1000 * 1000 octets.
Fournir des commentaires
Pour signaler des problèmes, envoyez des commentaires en sélectionnant Envoyez-nous vos commentaires.

Nombre limite d’étapes
Pour les performances, par défaut, le graphique est disponible uniquement lorsque l’application Spark a moins de 500 étapes. Si les étapes sont trop nombreuses, il échoue avec une erreur semblable à celle-ci :
The number of stages in this application exceeds limit (500), graph page is disabled in this case.
Pour contourner ce problème, avant de démarrer une application Spark, appliquez cette configuration Spark pour augmenter la limite :
spark.ui.enhancement.maxGraphStages 1000
Toutefois, notez que cela peut entraîner des performances médiocres de la page et de l’API parce que le contenu peut être trop volumineux pour que le navigateur puisse l’extraire et l’afficher.
Explorer l’onglet Diagnostic dans le serveur d’historique Apache Spark
Pour accéder à l’onglet Diagnostic, sélectionnez un ID de travail. Sélectionnez ensuite Diagnostic dans le menu des outils pour ouvrir la vue Diagnostic du travail. L’onglet du diagnostic comprend Data Skew (Asymétrie des données), Time Skew (Asymétrie temporelle) et Executor Usage Analysis (Analyse de l’utilisation de l’exécuteur).
Vérifiez l’asymétrie des données, l’asymétrie temporelle et l’analyse de l’utilisation des exécuteurs en sélectionnant l’onglet correspondant.

Asymétrie des données
Lorsque vous sélectionnez l’onglet Data Skew (Asymétrie des données), les tâches asymétriques correspondante sont affichées en fonction des paramètres spécifiés.
Spécifier les paramètres : la première section affiche les paramètres qui sont utilisés pour détecter l’asymétrie des données. La règle par défaut est : les données de tâche lues sont supérieures à trois fois la moyenne des données de tâche lues et les données de tâche lues sont supérieures à 10 Mo. Si vous souhaitez définir votre propre règle pour les tâches asymétriques, vous pouvez choisir vos paramètres. Les sections Skewed Stage(Phase asymétrique) et Skew Chart (Graphe d’asymétrie) sont actualisées en conséquence.
Étape asymétrique – La deuxième section affiche les étapes, qui ont des tâches asymétriques répondant aux critères précédemment spécifiés. S'il existe plusieurs tâches asymétriques dans une étape, le tableau des étapes asymétriques affiche uniquement la tâche la plus asymétrique (par exemple, les données les plus importantes pour l'asymétrie des données).
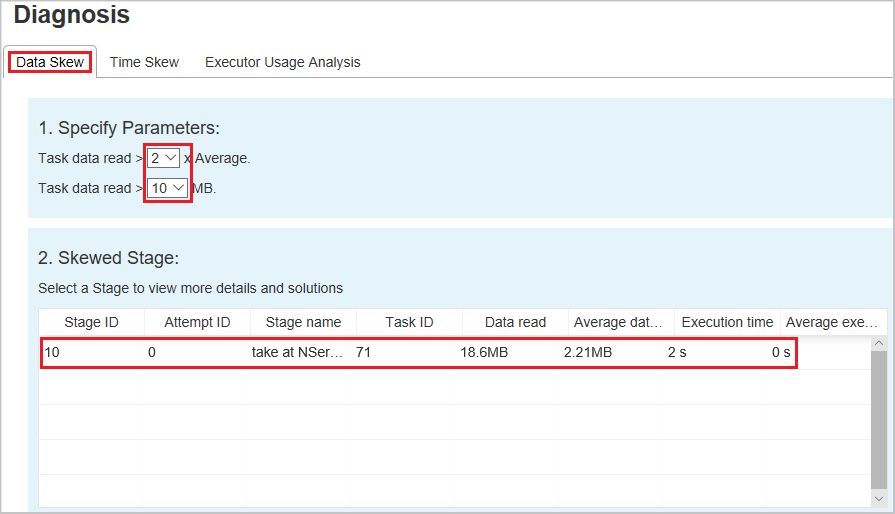
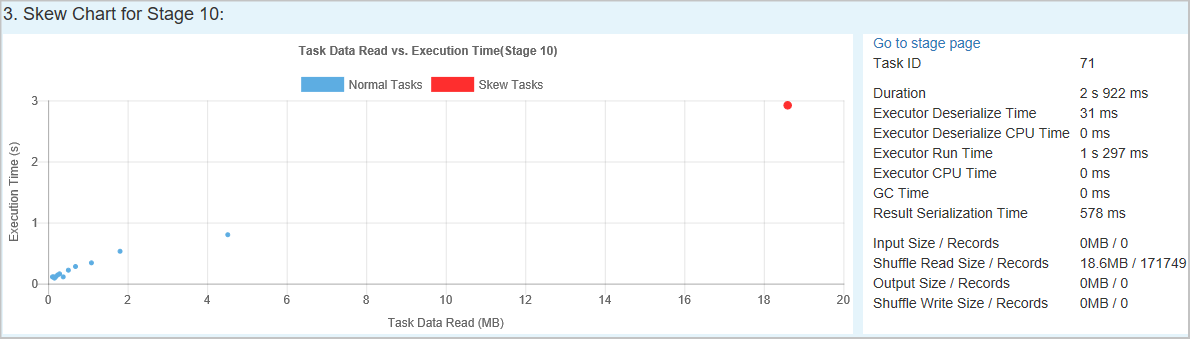
Graphique asymétrique – Lorsqu'une ligne de la table des étapes asymétriques est sélectionnée, le graphique asymétrique affiche davantage de détails sur la distribution des tâches en fonction de la lecture des données et du temps d'exécution. Les tâches asymétriques sont marquées en rouge et les tâches normales sont marquées en bleu. Le graphique affiche jusqu’à 100 exemples de tâches et les détails des tâches s’affichent dans le volet inférieur droit.


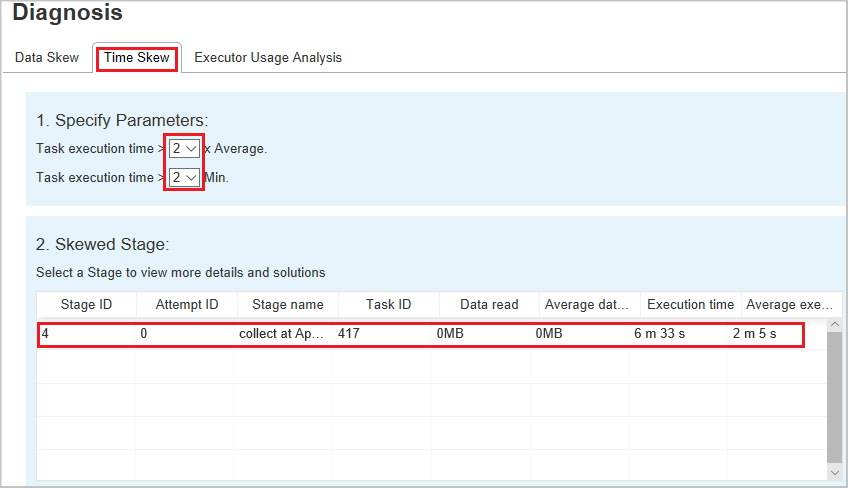
Asymétrie temporelle
L’onglet Time Skew affiche les tâches asymétriques en fonction de la durée d’exécution des tâches.
Spécifier les paramètres – La première section affiche les paramètres utilisés pour détecter le décalage temporel. Par défaut, les critères de détection de l’asymétrie temporelle sont les suivants : la durée d’exécution de la tâche est plus de trois fois supérieure à la durée d’exécution moyenne et supérieure à 30 secondes. Vous pouvez changer les paramètres en fonction de vos besoins. L'étape asymétrique et le graphique asymétrique affichent les informations sur les étapes et les tâches correspondantes, tout comme l'onglet Data Skew décrit précédemment.
Sélectionnez Asymétrie temporelle pour afficher les résultats filtrés dans la section Phase asymétrique, en fonction des paramètres définis dans la section Spécifier les paramètres. Sélectionnez un élément dans la section Skewed Stage, puis le graphique correspondant est rédigé dans la section 3 et les détails de la tâche sont affichés dans le panneau inférieur droit.

Analyse de l’utilisation des exécuteurs
Cette caractéristique est désormais déconseillée dans Fabric. Si vous souhaitez toujours utiliser cette solution de contournement, accédez à la page en ajoutant explicitement "/executorusage" derrière le chemin d'accès "/diagnostic" dans l'URL, comme ceci :
