Modifications apportées à la haute disponibilité et à la résilience des sites par rapport aux versions précédentes de Exchange Server
Exchange Server 2013 et versions ultérieures utilisent des DAG et des copies de base de données de boîtes aux lettres (ainsi que d’autres fonctionnalités telles que la récupération d’élément unique, les stratégies de rétention et les copies de base de données en retard) pour fournir une haute disponibilité, une résilience de site et une protection des données natives Exchange. La plateforme de haute disponibilité, la banque d’informations Exchange et le moteur de stockage extensible (ESE) ont tous été améliorés depuis Exchange 2010 pour fournir une disponibilité et une gestion moins complexe, et pour réduire les coûts. Ces améliorations sont les suivantes :
Réduction des IOPS : cela vous permet d’utiliser des disques plus volumineux en termes de capacité et d’IOPS aussi efficacement que possible.
Disponibilité managée : avec la disponibilité managée, la surveillance interne et les fonctionnalités orientées récupération sont étroitement intégrées pour éviter les défaillances, restaurer les services de manière proactive et démarrer automatiquement les basculements de serveur ou alerter les administrateurs pour qu’ils prennent des mesures. L'accent est mis sur le suivi et la gestion de l'expérience utilisateur final plutôt que simplement sur le temps d'activité du serveur et des composants pour contribuer à la conservation d'une disponibilité permanente du service.
Magasin géré : le magasin géré est le nom des processus de magasin d’informations réécrits dans Exchange 2013 ou version ultérieure. Le magasin géré est écrit en C# et étroitement intégré au service de réplication Microsoft Exchange (MSExchangeRepl.exe) pour offrir une plus grande disponibilité grâce à une résilience améliorée.
Prise en charge de plusieurs bases de données par disque : les améliorations vous permettent de prendre en charge plusieurs bases de données (combinaisons de copies actives et passives) sur le même disque, en utilisant ainsi des disques plus volumineux en termes de capacité et d’IOPS aussi efficacement que possible.
AutoReseed : la fonctionnalité de reseeding automatique vous permet de restaurer rapidement la redondance de base de données après une défaillance du disque. Si un disque est défectueux, la copie de la base de données stockée sur ce disque est copiée à partir de la copie de base de données active vers un disque de rechange sur le même serveur. Si plusieurs copies de bases de données ont été stockées sur le disque défectueux, elles peuvent toutes être automatiquement réamorcées sur un disque de rechange. Cela permet des réamorçages plus rapides, car les bases de données actives se trouvent probablement sur de multiples serveurs et les données sont copiées de manière parallèle.
Récupération automatique après défaillance du stockage: cette fonctionnalité se situe dans la continuité des innovations lancées par Exchange 2010 afin de permettre une récupération système après des défaillances qui affectent la résilience ou la redondance. Exchange inclut désormais davantage de comportements de récupération pour de longues durées d’E/S, une consommation de mémoire excessive par MSExchangeRepl.exe et des cas graves où le système est dans un état si mauvais que les threads ne peuvent pas être planifiés.
Améliorations de la copie en retard : les copies en retard peuvent désormais prendre soin d’elles-mêmes dans une certaine mesure à l’aide de la lecture automatique du journal. Les copies en retard vont automatiquement réduire les fichiers journaux dans différentes situations, telles que les mises à jour correctives de page et les scénarios d’espace disque insuffisant. Si le système détecte que la mise à jour corrective de page est nécessaire pour une copie en retard, les journaux sont automatiquement réexécutés dans la copie différée pour effectuer une mise à jour corrective de page. Les copies retardées appelleront également cette fonction de relecture automatique lorsque le seuil d'espace disque faible a été atteint et lorsque la copie retardée a été détectée comme étant la seule copie disponible pendant une période spécifique. En outre, les copies en retard peuvent utiliser le filet de sécurité, ce qui facilite grandement la récupération ou l’activation.
Améliorations apportées aux alertes de copie unique : l’alerte de copie unique introduite dans Exchange 2010 n’est plus un script planifié distinct. Elle est maintenant intégrée aux composants de disponibilité gérée au sein du système et constitue une fonction native dans Exchange.
Configuration automatique du réseau DAG : les réseaux DAG peuvent être configurés automatiquement par le système en fonction des paramètres de configuration. En plus des options de configuration manuelle, les DAG peuvent aussi faire la distinction entre les réseaux de réplication et MAPI, et configurer des réseaux DAG automatiquement.
Réduction des IOPS
Dans Exchange 2010, les copies de base de données passives ont une faible profondeur de point de contrôle, ce qui est nécessaire pour un basculement rapide. En outre, la copie passive effectue une pré-lecture agressive des données pour suivre une profondeur de point de contrôle de 5 mégaoctets (Mo). En raison de l’utilisation d’une faible profondeur de point de contrôle et de ces opérations de pré-lecture agressives, les IOPS d’une copie de base de données passive sont égales aux IOPS pour une copie active dans Exchange 2010.
Dans Exchange 2013 ou version ultérieure, le système peut fournir un basculement rapide tout en utilisant une profondeur de point de contrôle élevée sur la copie passive (100 Mo). Puisque les copies passives ont une profondeur de point de contrôle de 100 Mo, elles ont été déréglées pour ne plus être aussi agressives. En raison de l’augmentation de la profondeur du point de contrôle et de la désajustation des pré-lectures agressives, les IOPS pour une copie passive représentent environ 50 % des IOPS de copie active.
La définition d'une plus grande profondeur de point de contrôle sur la copie passive génère également d'autres changements. Lors du basculement dans Exchange 2010, le cache de base de données est vidé, car la base de données est convertie d'une copie passive en une copie active. À compter d’Exchange 2013, la journalisation ESE a été réécrite afin que le cache soit conservé pendant la transition de passif à actif. Comme ESE n'a pas besoin de vider le cache, vous bénéficiez d'un basculement rapide.
Une autre modification a été apportée au processus de maintenance de base de données en arrière-plan. Ce processus traite désormais environ 1 à 2 Mo par seconde et par copie.
En raison de ces modifications, Exchange offre désormais une réduction significative des E/S par seconde par rapport à Exchange 2010.
Disponibilité gérée
La disponibilité managée est l’intégration de la supervision active intégrée et de la plateforme de haute disponibilité Exchange. Avec la disponibilité managée, le système peut déterminer quand basculer une base de données en fonction de l’intégrité du service. La disponibilité managée est une infrastructure interne déployée dans les services d’accès au client (frontend) et les services principaux sur les serveurs de boîtes aux lettres. La disponibilité managée comprend trois principaux composants asynchrones qui effectuent constamment un travail :
Le premier composant est le moteur de sonde, qui est responsable de la prise de mesures sur le serveur et de la collecte des données. Les résultats de ces mesures sont transmis au deuxième composant, le moniteur.
Le moniteur contient toute la logique métier utilisée par le système en fonction de ce qui est considéré comme sain sur les données collectées. Comme un moteur de reconnaissance de suites logiques, le moniteur recherche les différentes suites logiques sur toutes les mesures collectées, puis détermine ce qu'il considère comme intègre.
Enfin, il y a le moteur de répondeur, qui est responsable des actions de récupération.
En cas d'état défectueux, la première action consiste à essayer de récupérer le composant. Cela peut inclure des actions de récupération à plusieurs étapes ; par exemple :
Redémarrez le pool d’applications.
Redémarrez le service.
Redémarrez le serveur.
Mettez le serveur hors connexion afin qu’il n’accepte plus le trafic.
En cas d'échec des actions de récupération, le système réaffecte le problème à un utilisateur au moyen de notifications dans le journal des événements.
La disponibilité gérée est implémentée sous la forme de deux services :
Service Exchange Health Manager (MSExchangeHMHost.exe) : il s’agit d’un processus de contrôleur utilisé pour gérer les processus de travail. Il est utilisé pour créer, exécuter, démarrer et arrêter le processus de travail selon les besoins. Il est également utilisé pour récupérer le processus de travail en cas de blocage afin d'empêcher que le processus de travail soit un point de défaillance unique.
Processus du worker Exchange Health Manager (MSExchangeHMWorker.exe) : il s’agit du processus de travail responsable de l’exécution des tâches d’exécution.
La disponibilité managée utilise le stockage persistant pour effectuer ses fonctions :
Les fichiers de configuration XML sont utilisés pour initialiser les définitions d'éléments de travail lors du démarrage du processus de travail.
Le registre est utilisé pour stocker des données d'exécution, telles que des signets.
L'infrastructure de journal des événements du canal Crimson est utilisée pour stocker les résultats d'éléments de travail.
Pour plus d’informations sur la disponibilité managée, consultez Disponibilité managée.
Banque gérée
Exchange 2010 et les versions antérieures prennent en charge l’exécution d’une seule instance du processus de banque d’informations (Store.exe) sur le rôle serveur de boîtes aux lettres. Cette instance de banque unique héberge toutes les bases de données sur le serveur : actives, passives, retardées et de récupération. Dans ces architectures Exchange, il existe peu d’isolation, voire aucune, entre les différentes bases de données hébergées sur un serveur de boîtes aux lettres. Un problème avec une seule base de données de boîtes aux lettres peut avoir un impact négatif sur toutes les autres bases de données, et les incidents résultant d'un endommagement de boîte aux lettres peuvent influer sur le service pour tous les utilisateurs dont les bases de données sont hébergées sur ce serveur.
Un autre défi avec une seule instance du Store est le manque de scalabilité du processeur avec le moteur de stockage extensible (ESE). L’ESE est bien mise à l’échelle vers 8 à 12 cœurs de processeur, mais au-delà, les problèmes de communication interprocesseur et de synchronisation du cache entraînent des performances négatives. Étant donné les serveurs d’aujourd’hui avec plus de 16 systèmes de cœurs disponibles, cela imposerait le défi administratif de gérer l’affinité de 8 à 12 cœurs pour ESE et d’utiliser les autres cœurs pour les processus non-Store (par exemple, Assistants, Search Foundation, Managed Availability, etc.). De plus, l’architecture précédente restreignait le scale-up pour le processus store.
Le processus Store.exe a considérablement évolué au fil des années, car Exchange Server lui-même a évolué, mais en tant que processus unique, sa scalabilité est limitée et représente un point de défaillance unique. En raison de ces limites, Store.exe a été supprimé dans Exchange 2013 et remplacé par le magasin géré.
Pour plus d'informations, voir Managed Store.
Plusieurs bases de données par volume
Bien que les améliorations apportées au stockage dans Exchange soient principalement conçues pour les configurations JBOD ,elles peuvent être utilisées par toutes les configurations de stockage prises en charge. L'une des fonctionnalités est la possibilité d'héberger plusieurs bases de données sur le même volume. Cette fonctionnalité vise à optimiser Exchange pour les grands disques. Ces optimisations permettent une utilisation beaucoup plus efficace des disques disposant d'une capacité élevée, d'E/S par seconde et de durées de réamorçage, et elles permettent de relever les défis associés à l'exécution dans une configuration de stockage JBOD :
Les tailles de base de données doivent pouvoir être gérées.
Les opérations de réamorçage doivent être rapides et fiables.
La capacité de stockage augmente, contrairement aux E/S par seconde.
Les disques qui hébergent les copies de base de données passives sont sous-utilisés pour ce qui est des E/S par seconde.
Les copies retardées ont des exigences de stockage asymétriques.
Vous avez peu de marge de manœuvre pour effectuer une récupération à partir d'un espace disque faible.
La tendance à l’augmentation de la capacité de stockage se poursuit. Par exemple, les recommandations exchange relatives à la taille maximale de la base de données (2 téraoctets) sur un lecteur de 8 téraoctets signifient que vous gaspilleriez plus de 5 téraoctets d’espace disque.
Une solution consisterait à agrandir les bases de données, mais cela empêche la gestion, car cela peut introduire de longues durées de reseed (y compris des temps de réseed non ingérables sur le plan opérationnel) et compromettre la fiabilité de la copie de cette quantité de données sur le réseau.
De plus, dans le modèle Exchange 2010, le disque qui stocke une copie passive est sous-exploité en E/S par seconde. En cas de copie passive retardée, non seulement le disque est sous-exploité en E/S par seconde, mais il est aussi asymétrique par sa taille, par rapport aux disques employés pour stocker les copies actives et passives non retardées.
Exchange 2013 et versions ultérieures ont été optimisés pour utiliser plus efficacement des disques volumineux (8 téraoctets) dans une configuration JBOD. Avec plusieurs bases de données par disque, vous pouvez désormais avoir des disques de même taille stockant plusieurs copies de base de données, y compris les copies en retard. L'objectif est de gérer la répartition des utilisateurs sur les différents volumes existants, ce qui vous permet de bénéficier d'une conception symétrique où, lors des opérations normales, chaque membre du DAG héberge une combinaison de copies actives, passives et parfois retardées sur les mêmes volumes.
Vous trouverez ci-dessous un exemple de configuration qui utilise plusieurs bases de données par volume.
Configuration utilisant plusieurs bases de données par volume
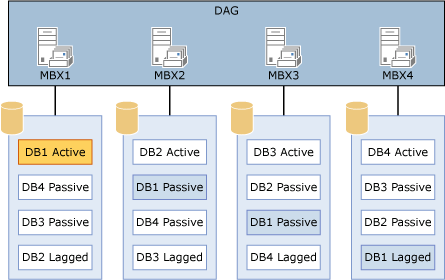
La configuration dans le diagramme fournit une conception symétrique. Les quatre serveurs ont les quatre mêmes bases de données, qui sont toutes hébergées sur un seul disque par serveur. L'élément clé est que le nombre de copies de chaque base de données dont vous disposez doit être égal au nombre de copies de base de données sur chaque disque.
Dans la configuration du diagramme, il existe quatre copies de chaque base de données : une copie active, deux copies passives et une copie en retard. Puisqu'il existe quatre copies de chaque base de données, la bonne configuration est celle qui comporte quatre copies par volume.
En outre, la préférence d'activation est configurée afin d'être équilibrée dans le DAG et sur chaque serveur. Par exemple :
La copie active aura une valeur de préférence d’activation de 1.
La première copie passive aura une valeur de préférence d’activation de 2.
La deuxième copie passive aura une valeur de préférence d’activation de 3.
La copie en retard aura une valeur de préférence d’activation de 4.
Outre une meilleure distribution des utilisateurs sur les volumes existants, un autre avantage de l’utilisation de plusieurs bases de données par disque est une réduction du temps de restauration de la protection des données pour les défaillances nécessitant une nouvelle installation (par exemple, une défaillance de disque).
À mesure que la taille d'une base de données augmente, son réamorçage prend de plus en plus de temps. Par exemple, le réamorçage d'une base de données de 2 téraoctets peut prendre 23 heures, alors que le réamorçage d'une base de données de 8 téraoctets peut prendre jusqu'à 93 heures (presque 4 jours). Les deux amorçages se produiraient à une fréquence moyenne de 20 Mo par seconde. Cela signifie généralement qu'une base de données de très grande taille ne peut pas être amorcée dans un délai raisonnable sur le plan opérationnel.
Dans un scénario impliquant une seule copie de base de données par disque, l'opération d'amorçage est effectivement liée à la source, car elle amorce toujours le disque à partir d'une seule source.
En divisant le volume en plusieurs copies de base de données et en stockant sur des membres de DAG distincts la copie active des bases de données passives d'un volume donné, le système n'est plus lié à la source dans le contexte de réamorçage du disque. Lorsqu'un disque défectueux est remplacé, il peut être réamorcé depuis plusieurs sources. Cela permet au système de réamorcer et de restaurer la protection des données pour ces bases de données dans un délai beaucoup plus court.
Lorsque vous utilisez plusieurs bases de données par volume, nous vous recommandons de suivre les meilleures pratiques et exigences suivantes :
Utilisez une seule partition de disque logique unique par disque physique. Ne créez pas plusieurs partitions sur le disque. Chaque copie de base de données et ses fichiers compagnons (tels que les journaux des transactions et l'index de contenu) doivent être hébergés dans un répertoire unique de la partition unique.
Le nombre de copies de base de données configurées par volume doit être égal au nombre de copies de chaque base de données. Par exemple, si vous avez quatre copies de vos bases de données, vous devez utiliser quatre copies de base de données par volume.
Les copies de base de données doivent avoir les mêmes voisins. (par exemple, elles doivent toutes partager le même disque sur chaque serveur.)
La préférence d’activation sur le DAG doit être équilibrée afin que chaque copie de base de données sur un disque ait une valeur unique de préférence d’activation.
AutoReseed
La réinsétion automatique (également appelée AutoReseed) remplace ce qui est normalement une action pilotée par l’administrateur en réponse à une défaillance du disque, à un événement d’altération de la base de données ou à un autre problème qui nécessite une nouvelle installation d’une copie de base de données. La fonctionnalité AutoReseed permet de restaurer automatiquement la redondance de base de données après une défaillance de disque par le biais de disques de rechange qui ont été configurés sur le système.
Pour plus d'informations, voir Fonctionnalité AutoReseed. Pour obtenir la procédure détaillée de configuration de la fonctionnalité AutoReseed, voir Configuration d'AutoReseed pour un groupe de disponibilité de base de données.
Récupération automatique suite à des défaillances de stockage
La récupération automatique après des défaillances de stockage permet au système de récupérer après des défaillances qui affectent la résilience ou la redondance. En plus des comportements de vérification d’erreur introduits dans Exchange 2010, Exchange inclut désormais des comportements de récupération supplémentaires pour des temps d’E/S longs, une consommation de mémoire excessive par le service de réplication Microsoft Exchange (MSExchangeRepl.exe) et des cas graves où les threads ne peuvent pas être planifiés.
Même dans les environnements JBOD, les contrôleurs de baies de stockage peuvent rencontrer des problèmes, tels qu'un arrêt ou un blocage. Le tableau suivant répertorie les fonctionnalités qui fournissent des fonctionnalités de détection et de récupération d’E/S bloquées qui fournissent une résilience améliorée.
| Nom | Chèque | Action | Seuil |
|---|---|---|---|
| Détection des E/S bloquées de la base de données ESE | ESE recherche la présence d'E/S exceptionnelles | Génère un élément de défaillance dans le canal Crimson pour redémarrer le serveur | 240 secondes |
| Pulsation du canal des éléments défectueux | S'assure que les éléments de défaillance peuvent être écrits vers le canal Crimson et lus à partir de ce dernier | Le service de réplication contrôle la pulsation du canal Crimson et redémarre le serveur suite à des défaillances | 30 secondes |
| Pulsation de disque système | Vérifie l'état du disque système du serveur | Envoie régulièrement des E/S non mises en mémoire tampon au disque système ; redémarre le serveur à l'expiration du délai de pulsation | 120 secondes |
Exchange 2013 et versions ultérieures améliore la résilience du serveur et du stockage en incluant des comportements pour d’autres conditions graves. Ces conditions et comportements sont décrits dans le tableau suivant.
| Nom | Chèque | Action | Seuil |
|---|---|---|---|
| État du système incorrect | Aucun thread, y compris les threads non gérés, ne peut être planifié | Redémarrer le serveur | 302 secondes |
| Temps d'E/S élevés | Mesures de la latence de fonctionnement des E/S | Redémarrer le serveur | 41 secondes |
| Utilisation de la mémoire du service de réplication | Mesurer la plage de travail de MSExchangeRepl.exe | 1 : Événement de journal 4395 dans le canal crimson avec une demande d’arrêt de service 2 : Lancer l’arrêt de MSExchangeRepl.exe 3 : Si l’arrêt du service échoue, redémarrez le serveur |
4 gigaoctets (Go) |
| Événement système 129 (réinitialisation du bus) | Vérifier la présence de l'événement 129 dans les journaux des événements système | Redémarrer le serveur | Lorsque l'événement se produit |
| Blocage de la base de données de cluster | Les mises à jour du Gestionnaire de mises à jour globales sont bloquées | Redémarrer le serveur | Lorsque l’événement se produit |
Améliorations apportées à la copie retardée
Les améliorations apportées à la copie retardée incluent l’intégration à Safety Net et la lecture automatique des fichiers journaux dans certains scénarios. Le filet de sécurité a été introduit dans Exchange 2013 pour remplacer la fonctionnalité Exchange 2010 appelée benne à ordures de transport. Le réseau de sécurité est similaire à la benne à ordures de transport, car il s’agit d’une file d’attente de remise associée au service de transport sur un serveur de boîtes aux lettres. Cette file d'attente stocke les copies des messages qui ont été correctement remis à la base de données de boîtes aux lettres active sur le serveur de boîtes aux lettres. Chaque base de données de boîtes aux lettres active sur le serveur de boîtes aux lettres a sa propre file d'attente qui stocke les copies des messages remis. Vous pouvez spécifier la durée pendant laquelle Safety Net stocke les copies des messages correctement remis avant leur expiration et leur suppression automatique.
Safety Net assume une certaine responsabilité de la redondance de l’ombre dans les environnements DAG. Dans les environnements DAG, la redondance de l’ombre n’a pas besoin de conserver une autre copie du message remis dans une file d’attente fantôme pendant qu’elle attend que le message remis soit répliqué sur les copies passives des bases de données de boîtes aux lettres sur les autres serveurs de boîtes aux lettres dans le DAG. La copie du message remis est déjà stockée dans Safety Net. La redondance de l’ombre peut donc redéliser le message à partir de Safety Net si nécessaire.
Avec Safety Net, l’activation d’une copie de base de données en retard devient plus facile. Par exemple, supposons qu'il existe une copie retardée dont le délai d'attente de relecture est de 2 jours. Dans ce cas, vous devez configurer Safety Net pour une période de 2 jours. Si vous rencontrez une situation dans laquelle vous devez utiliser votre copie en retard, vous pouvez :
Suspendez la réplication vers celui-ci.
Copiez-la deux fois (pour conserver la nature du décalage de la base de données et pour créer une copie supplémentaire au cas où vous en avez besoin).
Prenez une copie et ignorez tous les fichiers journaux, à l’exception de ceux de la plage requise.
Montez la copie, ce qui déclenche l'envoi d'une demande automatique à Safety Net pour remettre de nouveau les messages électroniques des deux derniers jours.
Grâce à Safety Net, vous n'avez pas besoin de rechercher le point de départ de l'endommagement. Vous recevez le courrier électronique des deux derniers jours, moins les données habituellement perdues lors d'un basculement avec perte.
Les copies retardées peuvent désormais se gérer elles-mêmes en appelant la relecture automatique des journaux pour lire les fichiers journaux dans certains scénarios :
Lorsque le seuil d'espace disque faible est atteint
Lorsque la copie retardée est physiquement endommagée et doit faire l'objet d'une mise à jour corrective de pages
Quand il y a moins de trois copies intègres disponibles (actives ou passives uniquement, les copies de base de données retardées ne sont pas comptées) pendant plus de 24 heures
Dans Exchange 2010, la mise à jour corrective de pages n'était pas disponible pour les copies retardées. Dans Exchange 2013 ou version ultérieure, la mise à jour corrective des pages est disponible pour les copies en retard via cette fonctionnalité de lecture automatique. Si le système détecte qu'une mise à jour corrective de page est nécessaire pour une copie retardée, les journaux sont automatiquement relus dans la copie retardée pour exécuter la mise à jour corrective de page. Les copies retardées appellent également cette fonction de relecture automatique lorsque le seuil d'espace disque faible est atteint et lorsque la copie retardée a été détectée comme étant la seule copie disponible pendant une période spécifique.
Le comportement de lecture de copie retardée est désactivé par défaut, mais peut être activé en exécutant la commande suivante :
Set-DatabaseAvailabilityGroup <DAGName> -ReplayLagManagerEnabled $true
Une fois activée, la lecture a lieu lorsque le nombre de copies est inférieur à trois. Vous pouvez modifier la valeur 3 par défaut en changeant la valeur de registre DWORD suivante :
HKLM\Software\Microsoft\ExchangeServer\v15\Replay\Parameters\ReplayLagManagerNumAvailableCopies
Pour activer la lecture pour les seuils d'espace disque faible, vous devez configurer l'entrée de registre suivante :
HKLM\Software\Microsoft\ExchangeServer\v15\Replay\Parameters\ReplayLagLowSpacePlaydownThresholdInMB
Après avoir configuré un de ces paramètres de registre, redémarrez le service de gestion des groupes de disponibilité de base de données (DAG) Microsoft Exchange pour que les modifications prennent effet.
Prenons l’exemple d’un environnement dans lequel une base de données donnée a quatre copies (trois copies à haut niveau de disponibilité et une copie avec décalage) et où le paramètre par défaut est utilisé pour ReplayLagManagerNumAvailableCopies. Si une copie non retardée est hors de service pour une raison quelconque (elle est par exemple suspendue, etc.), la copie retardée lira automatiquement ses fichiers journaux dans les 24 heures.
Améliorations apportées à l’alerte de copie unique
Garantir que vos serveurs fonctionnent de manière fiable et que les copies de votre base de données de boîtes aux lettres sont saines sont les principaux objectifs des opérations de messagerie Exchange quotidiennes. Vous devez surveiller activement le matériel, le système d’exploitation Windows et les services Exchange.
Toutefois, dans un environnement de résilience de boîte aux lettres Exchange, il est important de surveiller l’intégrité et l’état du DAG et des copies de votre base de données de boîtes aux lettres. Il est particulièrement essentiel d’effectuer une gestion des risques de redondance des données et de surveiller les périodes pendant lesquelles une base de données répliquée ne peut être qu’une seule copie. Cela est essentiel dans les environnements qui n’utilisent pas RAID (Redundant Array of Independent Disks) et déploient plutôt des configurations JBOD. Dans un environnement RAID, une seule défaillance de disque n’affecte pas la copie de la base de données de boîte aux lettres active. Toutefois, dans un environnement JBOD, une seule défaillance de disque déclenche un basculement de base de données.
Le script CheckDatabaseRedundancy.ps1 a été introduit dans Exchange 2010. Comme son nom l’indique, l’objectif du script était de surveiller la redondance des bases de données de boîtes aux lettres répliquées en validant qu’il existe au moins deux copies configurées, saines et actuelles, et d’alerter un administrateur via la génération du journal des événements lorsqu’une seule copie saine d’une base de données répliquée existe. Dans ce cas, les copies actives et passives sont comptabilisées lors de la détermination de la redondance.
Les conditions de copie unique incluent, entre autres :
Échec de la réplication d'une copie active vers une copie passive.
Échec de toutes les copies passives ; cela inclut les états FailedAndSuspended et Failed, en plus des états d'intégrité où la copie se trouve derrière lors de la relecture ou de la copie de journal. Les copies différées ne sont pas considérées comme étant en retard si elles sont dans un délai de 10 minutes pour relire leurs journaux jusqu’à leur période de décalage.
Échec de l'identification précise par le système de la génération actuelle du journal de la copie active.
Puisque la priorité absolue des administrateurs est de savoir quand il ne reste plus qu'une seule copie intègre d'une base de données, le script CheckDatabaseRedundancy.ps1 a été remplacé par une fonctionnalité native intégrée faisant partie du groupe d'intégrité DataProtection de la disponibilité gérée.
La fonctionnalité native alerte toujours les administrateurs par le biais de notifications de journal des événements, et pour distinguer les alertes Exchange 2013 ou ultérieures d’Exchange 2010, Exchange utilise désormais les ID d’événement suivants :
Événement 4138 (alerte rouge)
Événement 4139 (alerte verte)
La fonctionnalité native a été améliorée pour réduire le bruit d’alerte qui se produit lorsque plusieurs bases de données sur le même serveur entrent dans une seule condition de copie. Dans Exchange 2010, les alertes de copie unique étaient générées par base de données. Par conséquent, un problème à l’échelle du serveur qui affectait plusieurs bases de données et plusieurs copies de base de données peut provoquer des tempêtes d’alerte. Étant donné que plusieurs défaillances sont à l’échelle du serveur (par exemple, des problèmes de contrôleur ou de mémoire), il y avait de fortes chances qu’une tempête d’alerte se produise pour chaque incident de serveur.
Les alertes sont désormais générées par serveur. Lorsqu’une panne affecte un serveur entier et que la redondance des données devient menacée pour plusieurs copies de base de données, une seule alerte par serveur est générée.
Configuration automatique de réseau DAG
Un réseau DAG regroupe un ou plusieurs sous-réseaux utilisés soit pour le trafic de réplication, soit pour le trafic MAPI. Chaque DAG contient au maximum un réseau MAPI et aucun, un ou plusieurs réseaux de réplication.
Dans Exchange 2010, les réseaux DAG initiaux (par exemple, DAGNetwork01 et DAGNetwork02) ont été créés par le système en fonction des sous-réseaux énumérés par le service de cluster. Si vous aviez plusieurs réseaux et que les interfaces d’un réseau spécifié (par exemple, le réseau MAPI) se trouvaient sur le même sous-réseau, peu de configuration supplémentaire était nécessaire. Toutefois, si les interfaces d’un réseau spécifié se trouvaient sur plusieurs sous-réseaux, vous deviez effectuer une tâche appelée réduction des réseaux DAG.
Dans Exchange 2013 ou version ultérieure, la réduction des réseaux DAG n’est plus nécessaire. Exchange utilise toujours les mêmes mécanismes de détection pour faire la distinction entre les réseaux MAPI et de réplication, mais il réduit désormais automatiquement les réseaux DAG selon les besoins.
En outre, par défaut, les réseaux DAG sont désormais gérés automatiquement par le système. Pour afficher les propriétés réseau du DAG à l’aide du Centre d’administration Exchange (EAC), vous devez configurer le DAG pour le contrôle réseau manuel en modifiant les propriétés du DAG à l’aide du CAE ou en utilisant l’applet de commande Set-DatabaseAvailabilityGroup pour définir le paramètre ManualDagNetworkConfiguration sur $true.
Modifications apportées à la sélection de la meilleure copie
La sélection de la meilleure copie (Best Copy Selection, BCS) est un processus d’algorithme interne permettant de rechercher la meilleure copie d’une base de données individuelle à activer, en fonction d’une liste de copies potentielles disponibles pour l’activation, de leur intégrité et de leur état. Active Manager sélectionne la meilleure copie disponible (et non bloquée) pour qu'elle devienne la nouvelle copie de base de données active en cas d'échec de la copie existante, ou si un administrateur effectue un basculement non ciblé. Dans Exchange 2010, le processus de sélection de la meilleure copie (BCS) a évalué plusieurs aspects de chaque copie de base de données pour déterminer la meilleure copie à activer. Il s'agit notamment des points suivants :
Longueur de la file d'attente de copie
Longueur de la file d'attente de relecture
État de la base de données
État de l'index de contenu
Dans Exchange 2013 ou version ultérieure, Active Manager effectue les mêmes vérifications bcs et phases pour déterminer l’intégrité de la réplication, mais il inclut désormais également l’utilisation d’une contrainte de l’ordre décroissant des états d’intégrité. Suite à ces modifications, BCS se nomme désormais BCSS (Best Copy and Server Selection).
BCSS inclut plusieurs nouveaux contrôles d’intégrité qui font désormais partie des composants intégrés de surveillance de la disponibilité managée dans Exchange. Active Manager effectue quatre vérifications supplémentaires (répertoriées dans l’ordre dans lequel elles sont effectuées) :
Tout sain : recherche un serveur hébergeant une copie de la base de données affectée qui a tous les composants de surveillance dans un état sain.
Jusqu’à normal sain : recherche un serveur hébergeant une copie de la base de données affectée qui a tous les composants de surveillance avec une priorité normale dans un état sain.
Tout mieux que la source : recherche un serveur hébergeant une copie de la base de données affectée dont l’état des composants de surveillance est meilleur que celui du serveur actuel hébergeant la copie affectée.
Identique à la source : recherche un serveur hébergeant une copie de la base de données affectée qui a des composants de surveillance dans un état identique à celui du serveur actuel hébergeant la copie affectée.
Si BCSS est appelé suite à un basculement déclenché par un composant de surveillance de disponibilité gérée (par exemple, via un répondeur à basculement), le système applique une contrainte obligatoire supplémentaire selon laquelle l'intégrité du composant du serveur cible doit être meilleure que celle du serveur sur lequel le basculement s'est produit. Par exemple, si un échec de Outlook sur le web (anciennement Appelé Outlook Web App) déclenche un basculement de disponibilité managée via un répondeur de basculement, BCSS doit sélectionner un serveur hébergeant une copie de la base de données affectée sur laquelle Outlook sur le web est sain.
Service de gestion des groupes de disponibilité de base de données (DAG)
Exchange 2013 CU2 ou version ultérieure inclut le service de gestion du DAG Microsoft Exchange (MSExchangeDAGMgmt). Ce service contient la fonctionnalité de surveillance DAG interne qui se trouvait précédemment dans le service de réplication Microsoft Exchange (MSExchangeRepl).
Groupes de disponibilité de base de données (DAG) sans point d’accès administratif de cluster
Tous les DAG sur les serveurs Exchange exécutant Windows Server 2008 R2 ou Windows Server 2012 nécessitent au moins une adresse IP sur chaque sous-réseau inclus dans le réseau MAPI. Les adresses IP attribuées au DAG sont utilisées par le cluster du DAG avec le point d'accès administratif du cluster (également appelé nom du réseau de cluster) pour permettre la résolution du nom et la connectivité au cluster (ou plus précisément, la connectivité au membre du cluster qui détient actuellement le groupe de ressources principal du cluster) à l'aide du nom de cluster.
Windows Server 2012 R2 ou version ultérieure vous permet de créer un cluster de basculement sans point d’accès administratif. Les clusters de basculement Windows sans points d'accès administratif ont les caractéristiques suivantes :
Aucune adresse IP n’est affectée au cluster. Il n’y a donc aucune ressource d’adresse IP dans le groupe de ressources principal du cluster.
Aucun nom de réseau n’est affecté au cluster, il n’y a donc aucune ressource de nom réseau dans le groupe de ressources de base du cluster.
Le nom du cluster n’est pas inscrit dans DNS et le nom du cluster n’est pas résolu sur le réseau.
Un objet de nom de cluster (CNO) n’est pas créé dans Active Directory.
Vous ne pouvez pas gérer le cluster de basculement Windows à l’aide de l’outil Gestion du cluster de basculement. Au lieu de cela, vous devez utiliser Windows PowerShell et exécuter les applets de commande PowerShell sur les membres individuels du cluster.
Exchange 2013 SP1 ou version ultérieure s’exécutant sur Exchange sur Windows Server 2012 R2 ou version ultérieure vous permet de créer un DAG sans point d’accès administratif de cluster. Pour plus d'informations, consultez les rubriques Création de groupes de disponibilité de base de données et Créer un groupe de disponibilité de base de données.