Actualisation incrémentielle des sources de données Data Lake Storage
L’actualisation incrémentielle des sources de données basées sur Azure Data Lake Storage offre les avantages suivants :
- Actualisations plus rapides - Seules les données modifiées ont été actualisées. Par exemple, vous pouvez actualiser uniquement les cinq derniers jours d’un historique jeu de données.
- Fiabilité accrue - Avec des actualisations plus petites, vous n’avez pas besoin de maintenir les connexions aux systèmes sources volatils aussi longtemps, ce qui réduit le risque de problèmes de connexion.
- Réduction de la consommation de ressources - Actualiser uniquement un sous-ensemble de vos données totales permet une utilisation plus efficace des ressources informatiques et diminue l’empreinte environnementale.
Configurer l’actualisation incrémentielle de sources de données Azure Data Lake Storage
Microsoft recommande le format Delta Lake pour obtenir les meilleures performances et résultats lors de l’utilisation de jeux de données volumineux. Customer Insights - Data fournit un connecteur optimisé pour les données au format Delta Lake. Les processus internes tels que l’unification sont optimisés pour ne traiter de manière incrémentale que les données modifiées, ce qui réduit les temps de traitement.
Pour utiliser l’ingestion et l’actualisation incrémentielles pour une table Data Lake, configurez cette table lors de l’ajout ou de la modification de la source de données Azure Data Lake. Le dossier de données de table doit contenir les dossiers suivants :
- FullData : Dossier avec les fichiers de données contenant les enregistrements initiaux
- IncrementalData : Dossier avec des dossiers de hiérarchie date/heure au format aaaa/mm/jj/hh contenant les mises à jour incrémentielles. Les dossiers année, mois, jour et heure devraient contenir respectivement quatre et deux chiffres. hh représente l'heure UTC des mises à jour et contient les dossiers Upserts et Deletes. Upserts contient des fichiers de données avec des mises à jour d'enregistrements existants ou de nouveaux enregistrements. Deletes contient des fichiers de données avec des enregistrements à supprimer.
Ordre de traitement des données incrémentielles
Le système traite les fichiers dans le dossier IncrementalData à la fin de l’heure UTC spécifiée. Par exemple, si le système commence à traiter l’actualisation incrémentielle le 21 janvier 2023 à 8 h 15, tous les fichiers qui se trouvent dans le dossier 2023/01/21/07 (représentant les fichiers de données stockés de 7 h à 8 h) sont traités. Tous les fichiers du dossier 2023/01/21/08 (représentant l’heure actuelle où les fichiers sont toujours en cours de génération) ne sont pas traités avant la prochaine exécution.
S’il existe deux enregistrements pour une clé primaire, une mise à jour et une suppression, Customer Insights - Data utilise l’enregistrement avec la dernière date de modification. Par exemple, si l’horodatage de suppression est 2023-01-21T08:00:00 et que l’horodatage de mise à jour est 2023-01-21T08:30:00, il utilise l’enregistrement de mise à jour. Si la suppression s’est produite après l’upsert, le système suppose que l’enregistrement est supprimé.
Configurer l’actualisation incrémentielle pour les sources de données Azure Data Lake
Lors de l’ajout ou de la modification d’une source de données, accédez au volet Attributs de la table.
Examinez les attributs. Assurez-vous qu’un attribut de date de création ou de dernière mise à jour est configuré avec dateTime pour le format de date et Calendar.Date pour le type de sémantique. Modifiez l’attribut si nécessaire, puis sélectionnez Terminé.
Dans le volet Sélectionner les tables, modifiez la table. La case Ingestion incrémentielle est cochée.
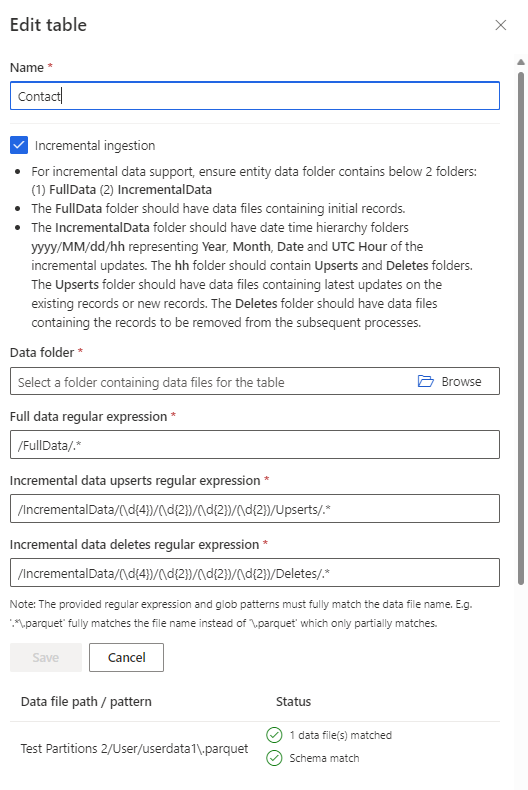
- Accédez au dossier racine qui contient les fichiers .csv ou .parquet pour les données complètes, les mises à jour de données incrémentielles et les suppressions de données incrémentielles.
- Entrez l’extension pour les données complètes et les deux fichiers incrémentiels (.csv ou .parquet).
- Pour les fichiers .csv, sélectionnez le délimiteur de colonne et si vous voulez la première ligne du fichier comme en-tête de colonne.
- Cliquez sur Enregistrer.
Pour Dernière mise à jour, sélectionnez l’attribut d’horodatage de date.
Si la Clé primaire n’est pas sélectionnée, sélectionnez-la. La clé primaire est un attribut unique à la table. Pour qu’un attribut soit une clé primaire valide, il ne doit inclure aucune valeur en double, aucune valeur manquante, ni aucune valeur nulle. Les attributs de type de données chaîne, entier et GUID sont pris en charge en tant que clés primaires.
Sélectionnez Fermer, puis enregistrez et fermez le volet.
Continuez en ajoutant ou en modifiant la source de données.
Exécuter une actualisation complète ponctuelle pour les sources de données Azure Data Lake
Après avoir configuré une actualisation incrémentielle pour les sources de données Azure Data Lake, il arrive parfois que les données doivent être traitées avec une actualisation complète. Le dossier de données complètes configuré pour l’actualisation incrémentielle doit contenir l’emplacement des données complètes.
Lors de la modification de source de données, accédez au volet Sélectionner des tables et modifiez la table que vous souhaitez actualiser.
Dans le volet Modifier la table , faites défiler jusqu’à la case à cocher Exécuter une actualisation complète ponctuelle et sélectionnez-la.
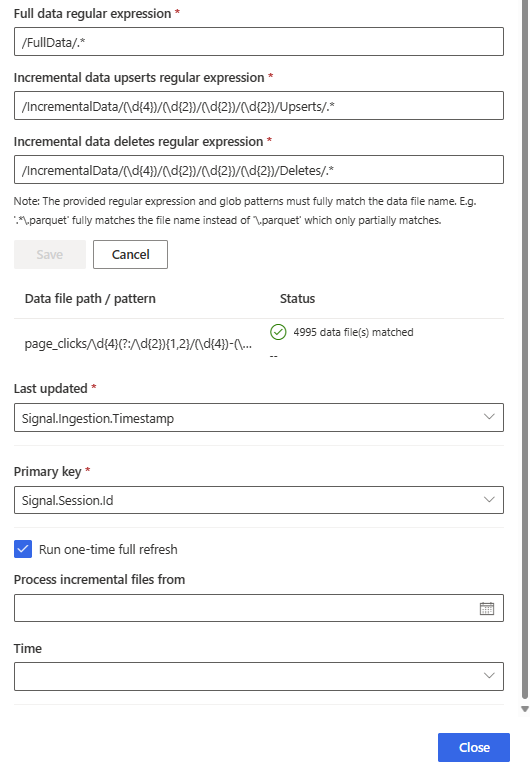
Pour Traiter les fichiers incrémentaux à partir de, spécifiez la date et l’heure de conservation des fichiers incrémentiels. Cela permet de traiter les données complètes plus les données incrémentielles à partir de la date et de l’heure spécifiées. Par exemple, si vous souhaitez effectuer une actualisation/renvoi partiel des données jusqu’à fin novembre tout en conservant les données incrémentielles de début décembre à aujourd’hui (30 décembre), saisissez le 1er décembre. Pour remplacer toutes les données et ignorer les données du dossier incrémentiel, spécifiez une date ultérieure.
Sélectionnez Fermer, puis enregistrez et fermez le volet.
Sélectionnez Enregistrer pour appliquer vos modifications et revenir à la page Sources de données. Le source de données est en état Actualisé et effectue une actualisation complète.